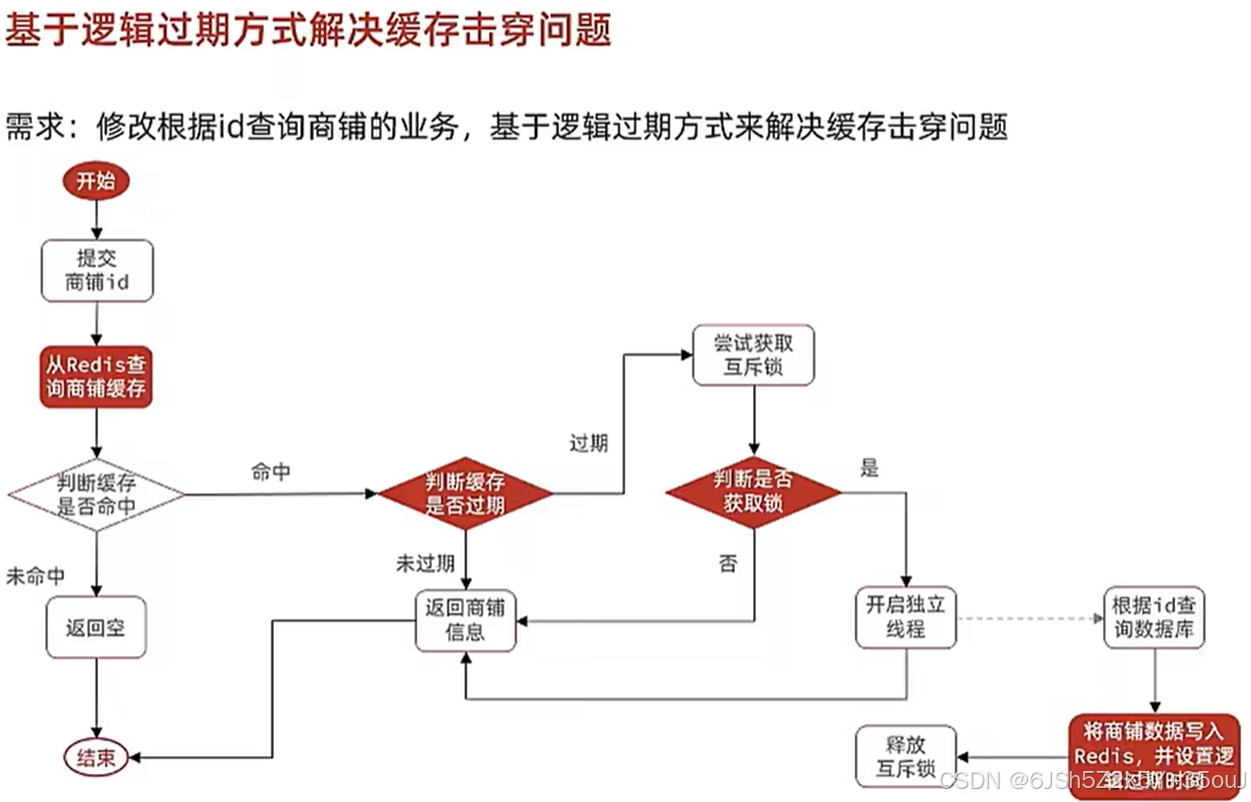
标题:奖励模型:解析大语言模型的关键工具
文章信息摘要:
奖励模型是理解和审核大语言模型(LLM)的重要工具,通过简单的评估方式提供了模型内部表征和性能的深入洞察。它不仅能静态比较模型表现,还可帮助诊断训练问题,为LLM研究提供独特视角,增强模型开发过程的透明度和可问责性。
==================================================
详细分析:
核心观点:奖励模型是理解和审核大语言模型(LLM)的重要工具,提供了一种简单而有力的方式来理解语言模型的表征。尽管直接偏好优化(DPO)等新方法兴起,奖励模型仍然具有独特价值,在LLM研究和应用中发挥着关键作用。
详细分析:
这个观点强调了奖励模型在理解和审核大语言模型(LLM)方面的重要性,主要包括以下几个方面:
-
简单而强大的评估工具:
奖励模型提供了一种简单的方式来评估文本质量,只需输入文本就能得到一个标量分数。这种简单性使其成为强大的审核工具。 -
无需提示的评估:
与需要复杂提示的LLM不同,奖励模型通常不需要提示就能直接评估文本。这简化了评估过程。 -
洞察模型内部表征:
通过分析奖励模型的输出,研究人员可以深入了解LLM如何在内部表征和处理语言。 -
静态比较能力:
奖励模型允许进行静态比较,例如评估模型在特定观点或偏见方面的表现。这为模型审核提供了重要工具。 -
环境模拟:
从强化学习的角度看,奖励模型模拟了环境的一部分,允许我们在任意状态下查询"环境"。 -
补充新方法:
尽管DPO等新方法兴起,奖励模型仍然提供了独特的见解,补充了这些方法。 -
问题诊断:
奖励模型可以帮助诊断LLM训练过程中的问题,如不完整响应的奖励变化大等。 -
偏好数据理解:
奖励模型提供了一种简单方法来理解偏好数据,有助于改进LLM训练。 -
accountability工具:
作为训练过程的中间产物,奖励模型可以增加LLM开发过程的透明度和可问责性。
总之,奖励模型为LLM研究提供了一个独特而有价值的视角,有助于我们更好地理解、改进和审核这些强大的AI系统。
==================================================