微服务架构已成为云数据中心的基本服务架构。但目前关于微服务系统弹性缩放的研究大多是基于服务或实例级别的水平缩放,忽略了能够充分利用单台服务器资源的细粒度垂直缩放,从而导致资源浪费。为此,本文设计了主动式微服务细粒度弹性缩放算法。算法通过预测请求到达率对系统进行资源预配置。基于预测结果,应用平方根配置规则计算需求资源数量,进而利用垂直缩放的细粒度资源控制特性和水平缩放的高可用性对微服务进行伸缩。最后应用基于微服务依赖关系的实例迁移算法进一步降低资源开销。实验表明,本文提出的算法在优化微服务系统时延和开销方面取得了显著效果。
目录
4 算法仿真及结果分析
4.1 实验数据生成
4.2 数据预处理
4.3 实验参数设置
4.4 实验结果分析
4.4.1 GRU-LR-𝟒 − 𝛔预测算法性能分析 预测算法性能分析
4.4.2 垂直与水平相结合的缩放算法性能分析
4 算法仿真及结果分析
本实验对 GRU 预测模型的实现基于 Python3 完成,其他部分应用 java 语言完成仿真。
4.1 实验数据生成
本实验同时考虑五条微服务链在云数据中心的弹性缩放,每条服务链包含 5 个微服务。为了对动态缩放算法进行更全面的评估,本文通过 Abdullah 等人和李德方提出的负载生成方法为五条微服务链构建具有不同特征的请求到达率,并基于生成的请求到达率对预测模型和弹性缩放算法进行性能评估。本实验以 5 分钟为一个时隙,共生成 576 个时隙(即 48 小时)的请求到达率。
(1) 微服务链𝑜 1 :请求到达率线性增加。本实验采用公式(39)生成𝑜 1 的请求到达率。𝜇 1 (𝑢 + 1) = 𝜇 1 (𝑢 0 ) + 𝑢𝛥𝑏 + 𝑡 𝑑 𝑆𝑏𝑜𝑒(ℕ(0,1)) 。其中,𝜇 1 (𝑢 0 )即初始状态的请求到达率。𝑢表示第𝑢个时
隙,𝛥𝑏为固定值,本实验取 0.2。𝑡 𝑑 为随机噪声比例因子,取值为 0.5,𝜇 1 (𝑢 0 ) = 5。
(2) 微服务链𝑜 2 :请求到达率周期性变化。本实验采用公式(40)生成𝑜 2 的请求到达率
其中,𝛽是振幅,𝜇 2 (𝑢 0 )是初始状态的请求到达率,p表示周期。本实验中,𝛽 = 10,p = 200,𝜇 2 (𝑢 0 ) = 10。本实验采用 Gaussian 函数生成微服务链𝑜 3 、𝑜 4 和𝑜 5 的请求到达率。流量峰值可能出现在任意时刻,因此服务链的请求到达率是多个 Gaussian 函数的叠加。
(3) 微服务链𝑜 3 :请求到达率峰值集中在白天。
4.2 数据预处理
将数据输入到 GRU 中训练之前,需要先对数据进行标准化处理。标准化处理将数据统一缩放到指定范围内,以避免数据相差太大导致小数值被忽略,同时还可降低计算复杂度。本文采用极大极小值标准化( Max-min Normalization )方法将数据映射到区间[0,1]内。
4.3 实验参数设置
本实验对五条微服务链的请求流量分别应用 GRU 模型进行调参训练。其中,训练轮次、模型训练时进行梯度下降的每个 batch 中的样本数 batch_size 以及 Adam 算法的学习率分别为 30 、 64 、 0.001 。 GRU 神经网络隐藏层数取值为 1 ,隐藏层单元数在区间 [50,100] 内取值,时间步长在区间 [1,20]内取值,最终综合预测精度和训练预测时长。
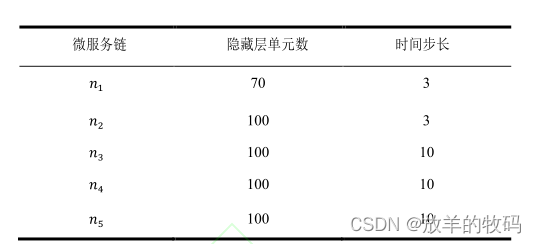
预测模型中应用线性回归进行短期流量预测的时间窗口𝑥 𝑡 取值为 3。动态缩放实验中,每条服务链包含5 个微服务,服务器核心对微服务的服务率在 5-10 之间变化,每台服务器最大核心数为 8.动态实验时隙个数T 取值为 50,SR Rule 中排队概率阈值δ默认取值为 0.1。
4.4 实验结果分析
4.4.1 GRU-LR-𝟒 − 𝛔预测算法性能分析 预测算法性能分析
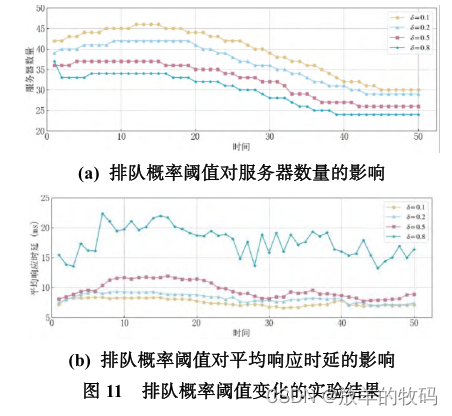
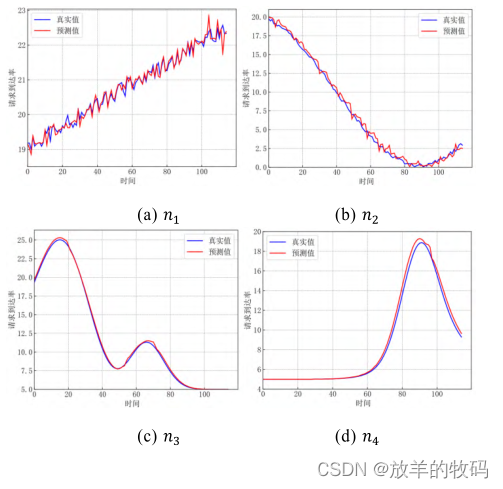
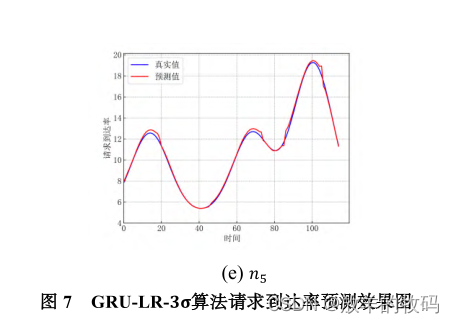
本文采用 GRU-LR-3σ算法对微服务请求到达率进行预测的效果如图 7 所示。从图 7 的预测效果图中可看出,对于具有不同特征的请求流量,通过 GRU-LR-3σ算法预测的到达率与真实到达率十分接近,GRU-LR-3σ算法的预测值在部分时刻略大于实际值,但总体来看二者相差并不大。因此,GRU-LR-3σ预测模型对预测的平均流量进行扩展可保留适当冗余资源以提升服务性能,但不会造成很大的资源浪费,这得益于 GRU-LR-3σ算法采用相对估计误差的标准差作为σ的取值,从而避免了过度的资源消耗。
4.4.2 垂直与水平相结合的缩放算法性能分析
本实验以首次适应降序放置算法( First FitDecreasing,FFD )和随机缩放算法( Random )为对比算法对本文提出的基于垂直和水平的相结合的微服务缩放算法( HABVH )进行性能评估,FFD 和 Random算法介绍如下:
(1) FFD:FFD 算法在进行服务扩展时,首先对服务器剩余核心数降序排序,然后从有序列表末尾开始寻找刚好能满足待扩展实例核心需求的服务器,如果搜索完有序列表后未找到适合的服务器,则重启服务器进行实例扩展。当实例需要收缩时,FFD 算法采用与HABVH 相同的实例收缩算法回收资源。
(2) Random:Random 算法从所有满足待扩展实例核心需求的服务器中随机选择一台服务器进行实例扩展,如果没有满足需求的服务器,则重启一台服务器。同样地,Random 算法也采用与 HABVH 相同的实例收缩算法回收资源。本实验选取生成的五个数据集的第 461 至第 511共 50 个时隙内的请求到达率作为动态实验的流量输入,微服务系统请求总到达率为五个数据集的请求到达率之和,时隙 461 至时隙 511 内的请求总到达率。
本文通过设置请求排队概率控制系统对用户的响应时延,为了展示不同排队概率约束下 HABVH 算法的性能,本实验评估了请求到达率为图 9 所示的总到达率,请求排队概率阈值δ分别设置为 0.1、0.2、0.5、0.8 时 HABVH 算法对微服务系统的优化结果,实验结果如图 11 所示。