项目背景
Boost库是C++中一个非常重要的开源库. 它实现了许多C++标准库中没有涉及的特性和功能, 一度成为了C++标准库的拓展库. C++新标准的内容, 很大一部分脱胎于Boost库中.
Boost库的高质量代码 以及 提供了更多实用方便的C++组件, 使得Boost库在C++开发中会被高频使用
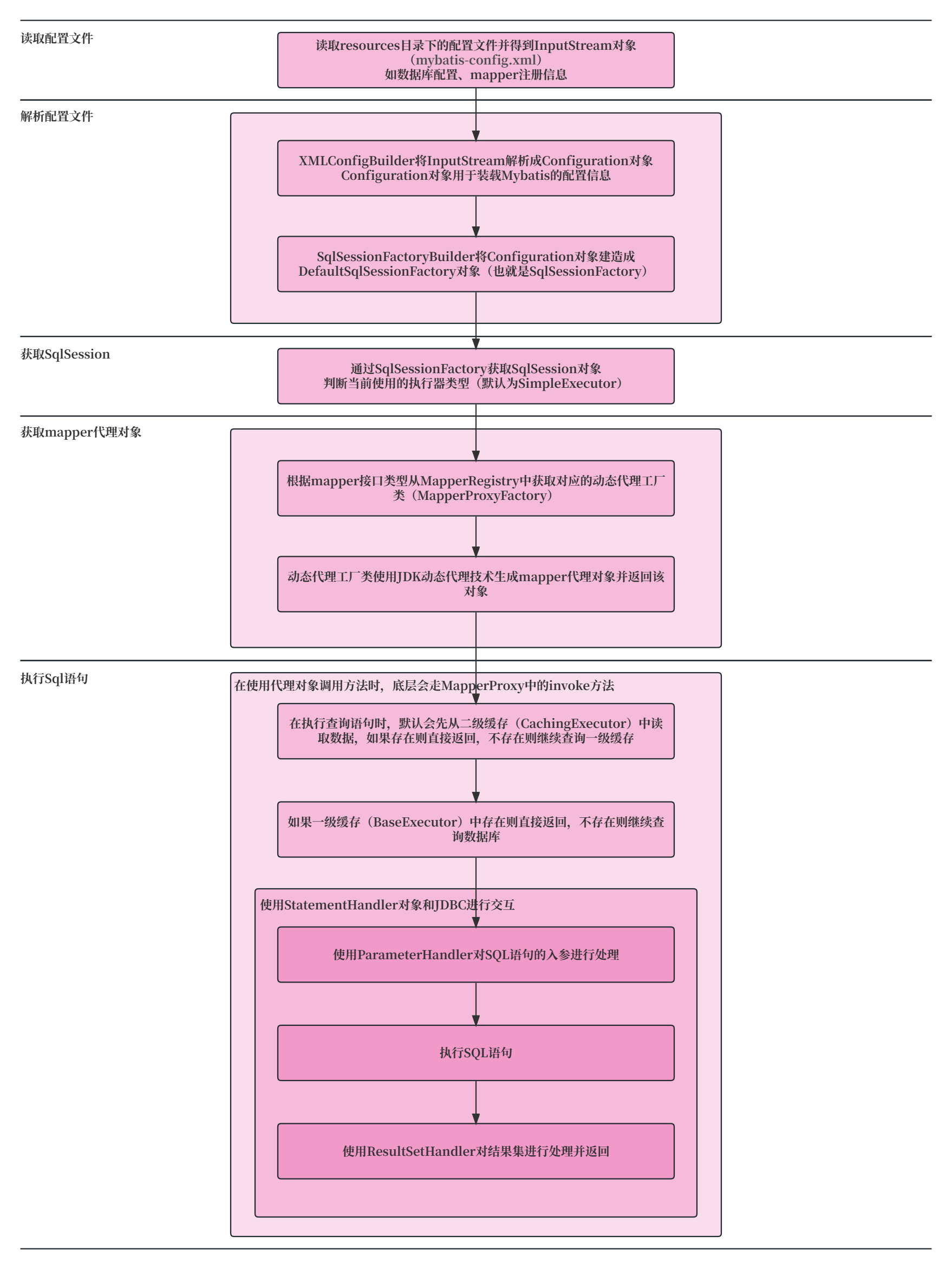
为方便开发者学习使用, Boost库官网(boost.org)也提供了不同版本库组件的相关介绍文档, 但是Boost库的官网在相当长一段时间都是没有站内搜索的. 应该是近两个月左右才 实现了站内搜索 的功能:

但是, Boost库官网实现的站内搜索是全局的搜索, 很多时候大部分开发者只需要查看某个组件的文档用以学习.
此时 使用Boost官方提供的站内搜索也是很不方便的, 而且也不支持选择版本来获取相关文档:
所以就有了本项目的出现, 为Boost库指定版本提供文档的站内搜索
搜索引擎相关宏观原理
我们每个人一定都使用过搜索引擎, 一般人常用的一定有: Bing、百度、Google…
使用搜索引擎搜索一定的内容, 出现的页面一般是这样的:
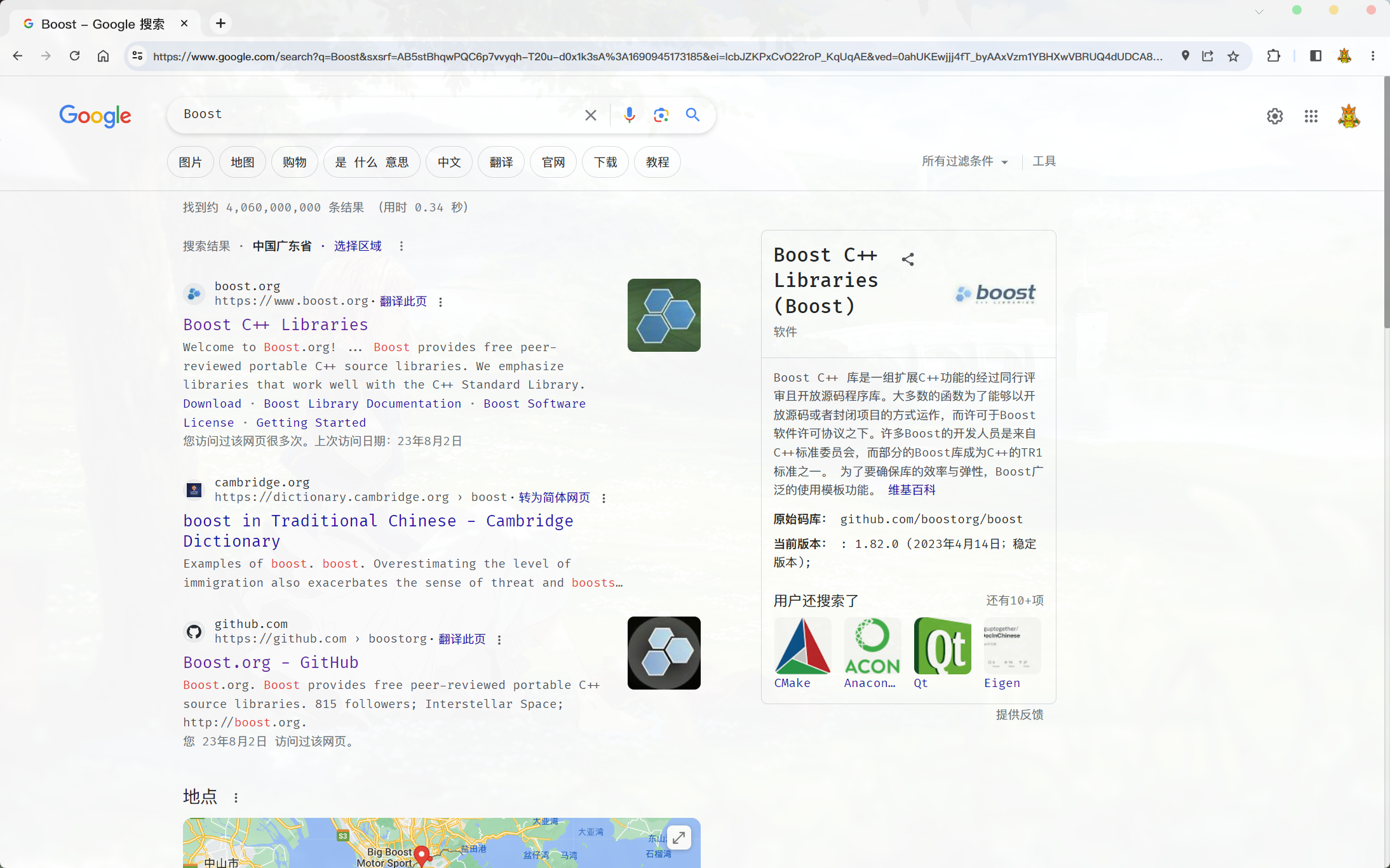
其中最主要的部分是这样的:

搜索引擎通常会将搜索到的内容, 以: 网页的标题(title)、网页的简单摘要(Content)、即将跳转到的网页的网址(url) 为一个单元的形式展现出来. 并且, 包含的搜索的 关键字会被高亮显示
其他搜索引擎也是大同小异:

那么, 搜索引擎是如何做这整个过程的呢?
首先要明白, 输入关键字 点击搜索的这个行为, 其实是在创建并向服务器发送http/https请求的行为.
在客户端输入关键词, 点击搜索. 创建请求, 携带关键词向服务器发送请求.
服务器接收到请求之后, 根据关键词 在服务器检索索引 获取所有相关的html的内容, 然后 将获取到的多个网页内容(title、content、url), 拼接构建成一个新的网页 响应回客户端.
整个过程中最重要的过程在于: 检索索引
关于索引, 实际是一个帮助快速查找数据的数据结构. 根据关键词 检索索引, 就是在数据结构中查找关键词相关的数据.
索引, 是在 搜索引擎服务启动之前 服务器提前建立好的. 搜索引擎服务启动之后, 可以直接通过索引来检索数据.
搜索引擎索引的建立步骤一般是这样的:
- 爬虫程序爬取网络上的内容, 获取网页等数据
- 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
- 对提取的文本进行分词、处理, 得到词条
- 根据词条生成索引, 包括正排索引、倒排索引等
建立好索引之后, 搜索引擎服务就可以根据关键词 检索索引 获取相关数据.
这一整个流程, 即为 搜索引擎的相关宏观原理
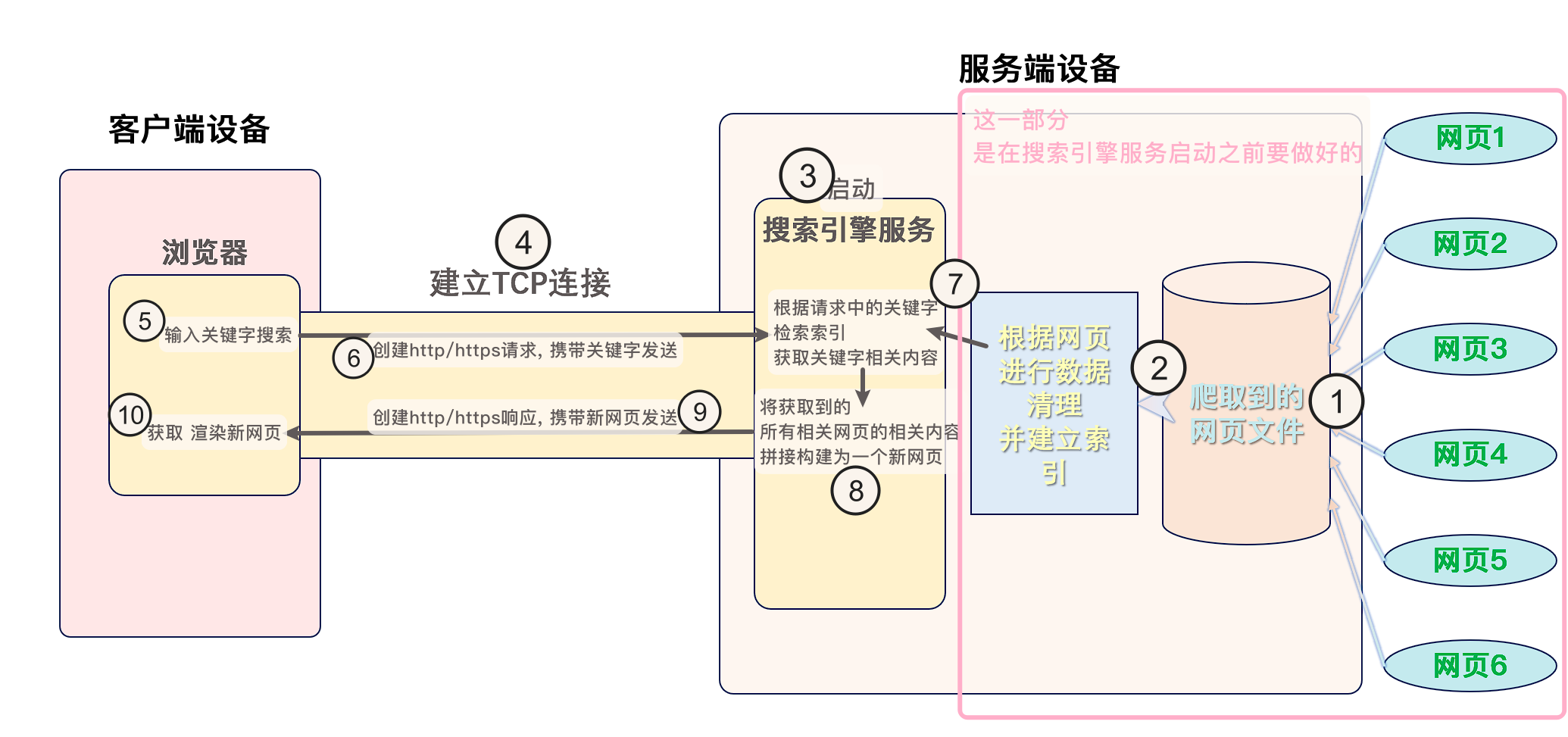
大致的流程 以及 宏观原理图, 可以根据这一张图来理解
服务端需要做的第一个工作是爬取网页.
但是本项目中不需要, 因为是站内文档搜索, 官方提供的也有Boost库的相关源码文件, 其中就包括了Boost库的文档html文件.
Boost库源码下载
https://boostorg.jfrog.io/artifactory/main/release/
这是Boost库的源码发布页. 我们可以直接找到指定版本获取下载链接, 将文件下载到服务器中:
wget https://boostorg.jfrog.io/artifactory/main/release/1.82.0/source/boost_1_82_0.tar.gz
获取到源码压缩文件之后, 执行tar -zxvf boost_1_82_0.tar.gz解压
然后就获取了Boost库源码:

其中, 所有的文档html文件都在 doc//html/目录下:

统计了一下, 此目录下(包括子目录) 一共有8563个html文件, 这些都是Boost库提供的文档
Boost库站内文档搜索 所需技术栈 以及 项目环境
技术栈:
- 后端:
C/C++C++11STLBoost库Jsoncppcppjiebacpp-httplib - 前端:
htmlcssjsjQueryAjax
项目环境:
Centos 7云服务器neovimgcc(g++)makefile
清理 分词 和 索引
实现一个搜索引擎, 最重要的地方在于 建立索引
建立索引, 就是建立 文档与关键词之间的的映射
清理文档文件
所以在建立索引之前, 要 先清理文档中对搜索无用的无效数据. 在html文件中, 无效数据就是html的各种标签:
<!-- 各种成对的标签 -->
<html></html>
<head></head>
<body></body>
<div></div>
<!-- 各种单独的标签 -->
<link>
<meta>
<img>

标签中, <和>之间的内容都是对搜索来说无效的内容. 而对于成对的标签来说 >和<之间的内容则是有效的内容.
简单点来说, 标签内部的数据 是对搜索无效的数据, 标签外的数据是对搜索有效的数据.
简单的举例子:
<div><p class="copyright">Copyright © 2005, 2006 Eric Niebler</p></div>
<div class="toc">
<p><b>Table of Contents</b></p>
其中有效的数据是: Copyright © 2005, 2006 Eric Niebler 和 Table of Contents
其他的都属于标签内的数据, 都是对搜索无效的, 因为浏览器不会将标签内的数据值渲染出来, 那是一些属性.
分词
清理完文档中对搜索无用的无效数据之后, 就可以对文档的内容 进行分词.
分词, 就是将一句话中可用作关键字的词语分割开, 比如:
-
博主买了一些小米和南瓜
分词就可能会分为:
博主买一些小米南瓜小米和南瓜 -
博主做了小米南瓜粥吗
分词就可能会分为:
博主做小米南瓜南瓜粥小米南瓜粥
将可用作关键词的词汇组合或分开并汇总, 停止词不考虑, 就是分词.
停止词, 就是搜索中没有明显作用的词:
了 的 吗 呢 a the ...
索引
每个文件都有文件名 也就是文件ID, 文件内容包含了关键词. 将文件名和关键词之间建立映射关系, 就是建立索引.
以下以两个文件为例
-
文件1: 博主买了一些小米和南瓜
-
文件2: 博主做了小米南瓜粥吗
正排索引
正排索引, 是 从文件ID找到文件关键词:
| 文件ID | 内容关键词 |
|---|---|
| 文件1 | 博主 买 一些 小米 南瓜 小米和南瓜 |
| 文件2 | 博主 做 小米 南瓜 南瓜粥 小米南瓜粥 |
可以看作, 文件ID是Key 用于查找, 内容关键词是Value 是被找到的内容. 建立正排索引可以不对文件内容做分词
此项目中, 建立正派索引时不对文件内容做分词处理
倒排索引
与正排索引相反.
倒排索引, 是 从文件关键词找到文件ID. 并且, 会将所有文档中的关键词进行汇总去重:
| 关键词(唯一) | 涉及的文件ID(文件权重) |
|---|---|
博主 | 文件1、文件2 |
买 | 文件1 |
一些 | 文件1 |
小米 | 文件1、文件2 |
南瓜 | 文件1、文件2 |
小米和南瓜 | 文件1 |
做 | 文件2 |
南瓜粥 | 文件2 |
小米南瓜粥 | 文件2 |
可以看作, 关键词是Key 用于查找, 文件ID是Value 是被找到的内容.
项目中, 正排索引和倒排索引都需要建立并使用.
模拟整个查找到检索索引再到响应的流程:
输入关键词 --> “博主” --> 先在倒排索引检索 --> 获取"文件1""文件2"文件ID --> 再根据获取的文件ID在正排索引中检索 --> 检索到相关文件的文件内容(title、content、url) --> 根据内容构建新网页 --> 响应新网页
本片文章介绍了项目背景, 从下一篇文章开始开始编写项目代码
感谢阅读~