文章目录
- 一、背景
- 二、方法
- 2.1 基础内容
- 2.2 Region-aware Image-text Pretraining
- 2.3 Open-vocabulary Detector Finetuning
- 三、效果
- 3.1 细节
- 3.2 开放词汇目标检测效果
- 3.3 Image-text retrieval
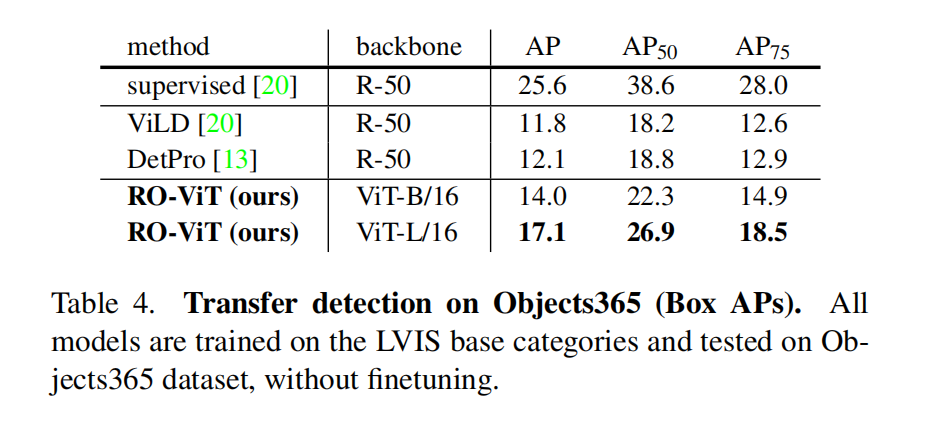
- 3.4 Transfer object detection
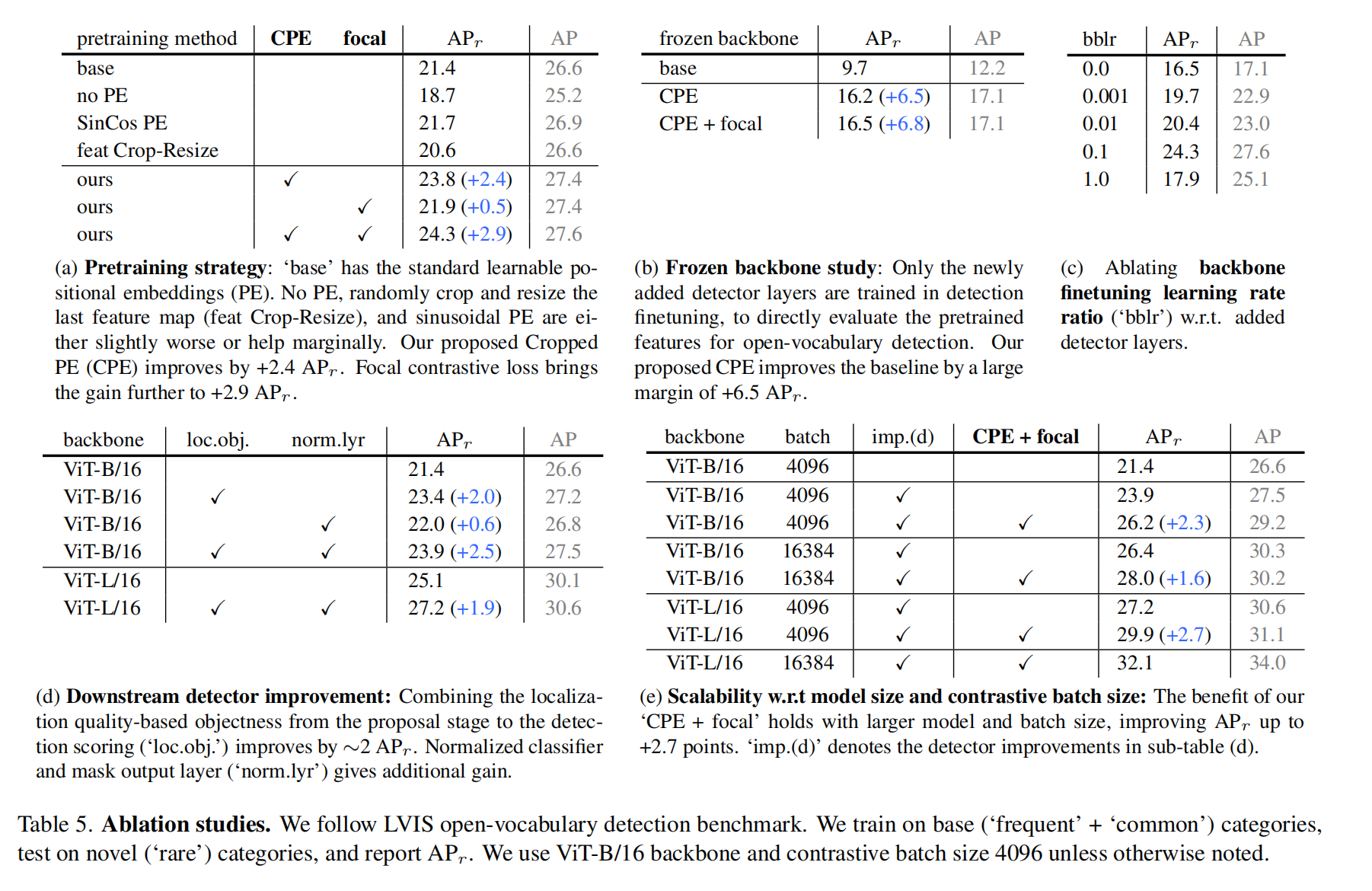
- 3.5 消融实验
论文:Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers
代码:暂无
出处:CVPR2023
贡献:
- 本文提出的 RO-ViT 解决了 image-text pretraining 到 open-vocabulary object finetuning 之间的 positional embedding 问题
- 证明了 image-text pretraining 使用 focal loss 比 CE loss 更好
- 使用 novel object proposals 提高了开放词汇目标检测 fine-tuning 效果
- 在 LVIS 上得到 SOTA 32.4 APr,超越了当前最好的方法 6.1 APr
一、背景
近期,open-vocabulary detection task (OVD) 得到了很多关注,其被提出是为了解决传统目标检测的限制性,开放词汇目标检测最大的特点是将类别看做 text embedding,而不是离散的 id,所以,开放词汇目标检测能够更灵活的预测在训练过程中没见过的类别。
现有的很多方法是使用大量的 image-text pairs 来进行预训练,为模型引入丰富的语义信息,很多方法用的是 CNN,但随着对图像理解的更强的需求和多模态任务的出现,使用 vision transformer 来实现也很重要
我们已知现有的方法很多都是使用预训练好的 vision-language model,然后再微调一下来解决 image-level 预训练和 object-level fine-tuning 之间的 gap
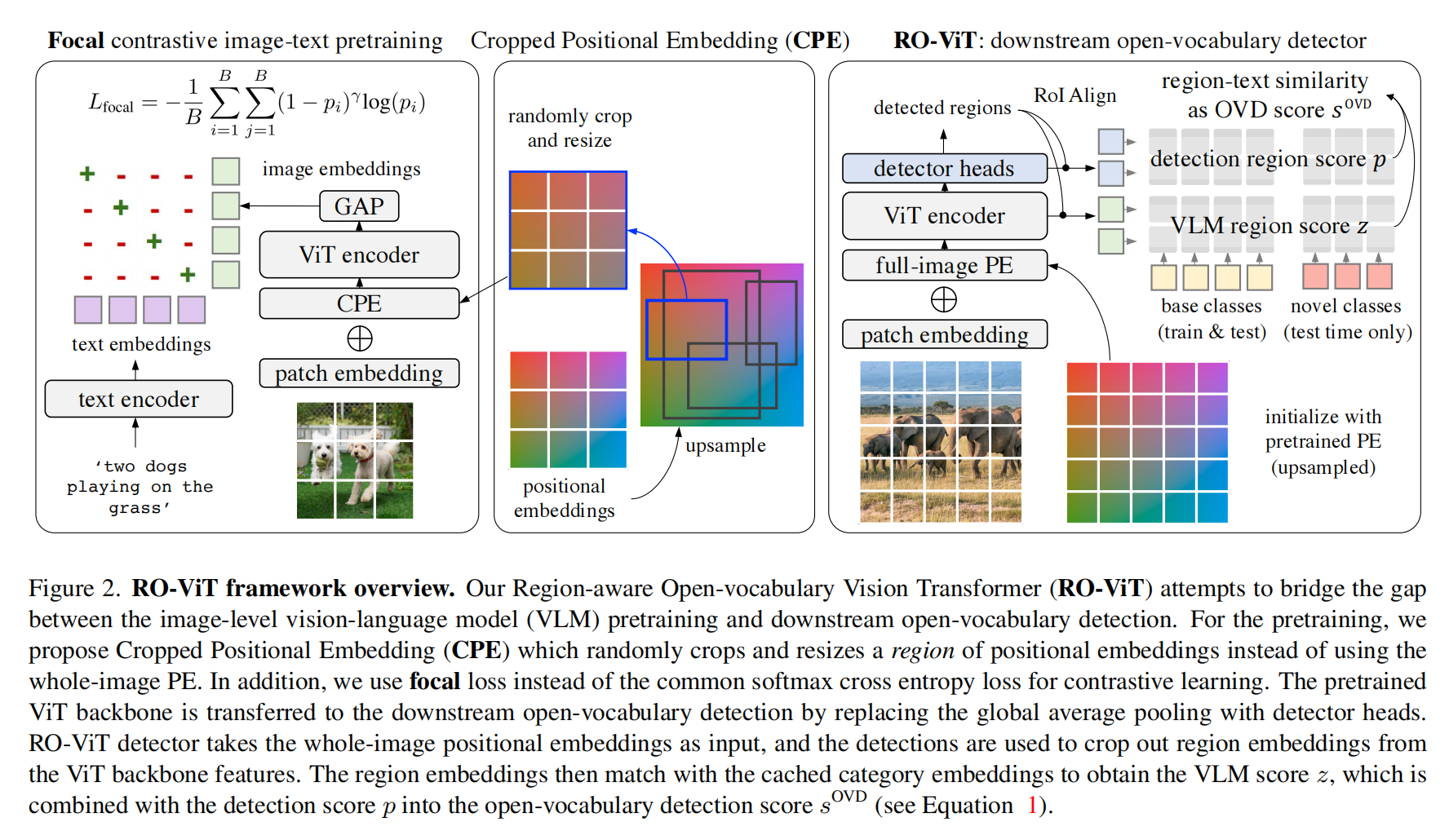
本文提出了 RO-ViT,将预训练好的 vision transformer 迁移到 region-aware 上来实现开放词汇的目标检测
本文和前面的方法最大的不同在于,本文作者探索了如何更好的使用 vision transformer 来预训练 VLMs,更好的适用于开放词汇检测
然后使用预训练的权重来初始化检测器的 backbone,将 backbone 冻住后训练检测器的 neck 和 head 等特殊部件
二、方法
2.1 基础内容
1、contrastive image-text pretraining
一般的对比学习都是 two-tower 的结构,由 image encoder 和 text encoder 构成
- image encoder:可以是 CNN 或者 ViT 的
- text encoer:一般是 transformer 的
对比学习的目标是在 embedding space 中,将一对儿的 image-text 距离拉近,非一对儿的 image-text 距离拉远
一般使用的 loss 是 softmax CE loss
2、开放词汇目标检测
使用基础类别训练,但是测试的时候需要同时能够检测基础类别和新类别
一般的方法就是将原本的固定尺寸的全连接分类器使用 text embedding 来替换,因为 text embedding 来自于预训练的 text encoder 中,所以预训练中的开放语义知识能很好的保留
作者对于 background 类别使用 “background” 词汇来作为类别词汇
训练过程中,作者会给每个 region r r r 计算对应的 detection score p i p_i pi,计算方法是计算 RoI-Align feature(region embedding)和基础类别的 text embedding 的 cosine similarity,然后使用 softmax 规范化
在测试过程中,text embedding 扩展到了基础类别和新类别的 embedding,并且加上了 background,在 ViT backbone的输出 feature map 上使用 RoI-Align 来获得region i i i 的 VLM embedding,并且计算这个区域 embedding 和 text embedding 的 cosine similarity,得到 region score z i z_i zi,detection score 计算如下, α , β ∈ [ 0 , 1 ] \alpha, \beta \in [0,1] α,β∈[0,1] 用了控制基础类别和新类别的 weights
作者使用预训练好的 ViT 模型来初始化 detector 的 backbone
2.2 Region-aware Image-text Pretraining
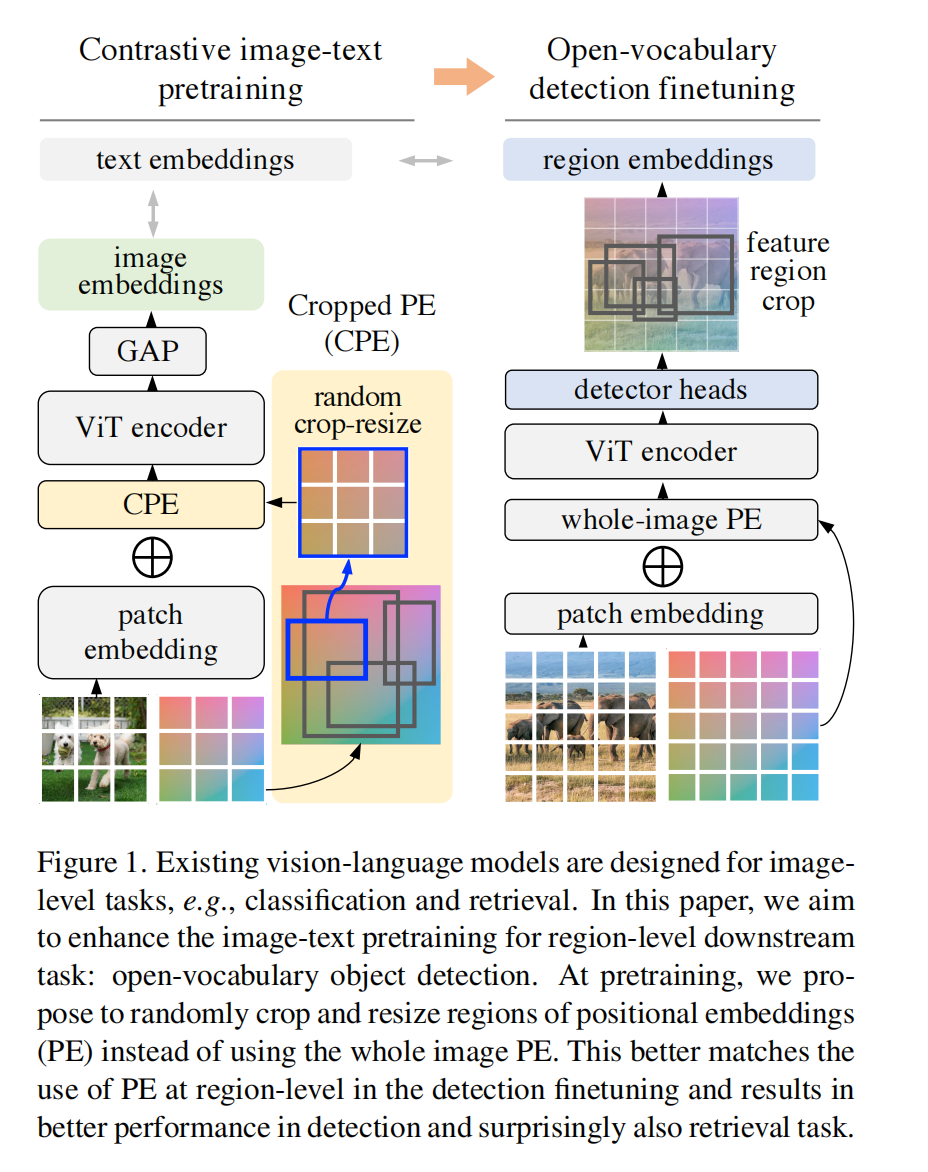
现有的 vision-language model 基本上都是使用整张图和 text 来进行匹配
然而,这种预训练没有考虑到 region-level 特征和 text token 之间的关系,而这种关系又对开发词汇目标检测很重要
所以,作者提出了一种新的 Cropped Positional Embedding(CPE)的方法来解决 image 和 region 之间的 gap,并且发现使用 focal loss 从难样本中挖掘很有益处
CPE:
- transformer 中,positional embedding 是很重要的,能够保留每个元素的相对位置,这种信息对下游的识别和定位任务都很重要
- 但现有的 contrastive pretraining 和 open-vocabulary detection fine-tuning 的 positional embedding 之间有一定的不对齐,pretraining 方法一般都在训练时对全图位置进行编码,在下游的任务也是使用全图的位置编码。但是 detection fine-tuning 中,需要将全图的位置编码泛化到 region 的编码
为了解决这个 gap,作者提出了 CPE,如图 2 所示:
- 首先,对于 pretraining,将 positional embedding 从图像大小(224)上采样到检测任务大小(如 1024)
- 然后,从上采样的 positional embedding 中随机 crop 一个 region 并 resize,来作为预训练时候的 image-level 的 positional embedding
- 这样一来,就能让模型将图像看做从更大的未知图像中随机 crop 出的 region,而非一个整图,能更好的适应于下游检测任务
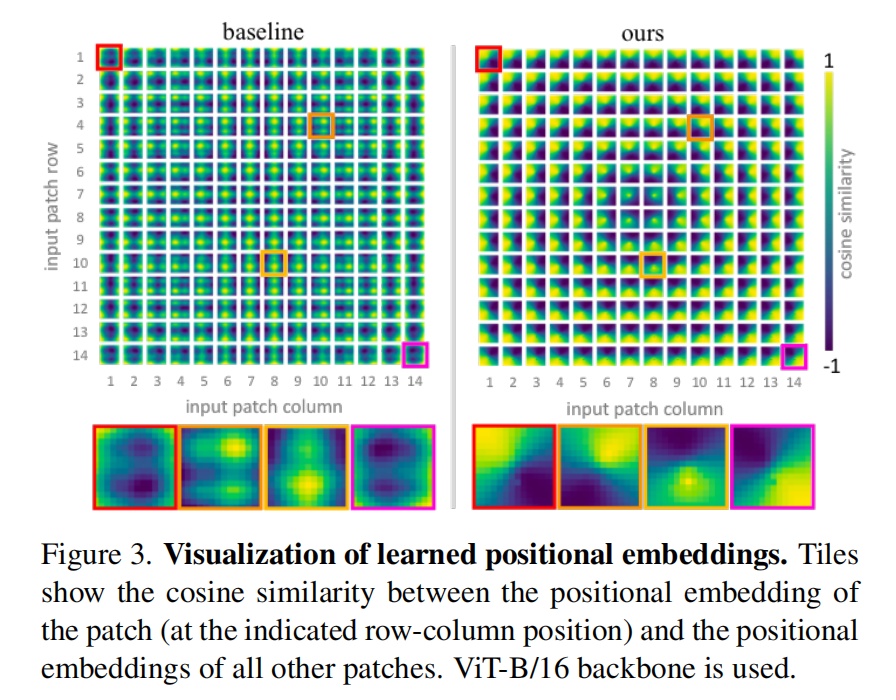
CPE 可视化:
- 每个小格子是一个 patch 和其他 patches 的余弦相似度
- 相近的 patches 有着更相似的位置编码
Focal loss:
作者认为更细致的控制 hard 样本的权重比使用 CE loss 更好
假设:
-
v i v_i vi 和 l i l_i li 是归一化后的 image embedding 和 text embedding
-
Image-to-text(I2T)对比学习 loss 分别设置为 CE loss 和 Focal loss 来对比,公式如下
-
Text-to-image(T2I)对比学习 loss 和 I2T 的是对称的

-
总 loss 是两个 loss 之和
2.3 Open-vocabulary Detector Finetuning
虽然 backbone 可以使用预训练权重来初始化,但检测器的 neck 和 head 还是全新的
现有的方法一般不会对新类或未标注的类进行 proposal generation
但本文提出了一个新的生成 proposal 的方法,使用 localization quality-based objectness(如 centerness 等)来衡量 proposal 的得分,而不是使用 object-or-not 的二分类得分来衡量
OVD score: S i O V D = o i δ . s i O V D S_i^{OVD}=o_i^{\delta} .s_i^{OVD} SiOVD=oiδ.siOVD, o i δ o_i^{\delta} oiδ 是预测的 objectness score
三、效果
3.1 细节
预训练:
- 本文的 pretraining 是作者从头训练的,使用 ViT-B/16 和 ViT-L/16 来作为 image encoder
- 输入图像大小为 224x224,patch size 为 16x16,共 14x14 个 positional embedding
- 为了生成 CPE,作者首先将 positional embedding 插值到 64x64,然后随机 crop 一个 region(scale ratio 为 [0.1,1.0],aspect ration 为 [0.5, 2.0]),然后将 region crop resize 为 14x14,驾到 patch embedding 上
- 在 ViT 最后一层使用 global average pooling 来得到 image embedding
- text encoder 是 12 层的 transformer,最长的 text encoder 是 64
- 数据集:LAION-2B [44]
下游检测的细节:
- LVIS: iters = 46.1k,img size =1024,batch = 256,SGD weight decay 1e-4,lr 0.36,momentum=0.9
- COCO:iters = 11.3k,img size =1024,batch = 128,SGD weight decay 1e-2,lr 0.02,momentum=0.9
- 使用 CLIP prompt 模版,对每个类别的 text embedding 求平均
- 在 RPN 阶段使用 OLN-RPN,使用 centerness 作为 objectness,每个位置上有一个 anchor,使用 IoU loss,RPN NMS 在训练时 threshold=0.7,测试时为 1.0
3.2 开放词汇目标检测效果
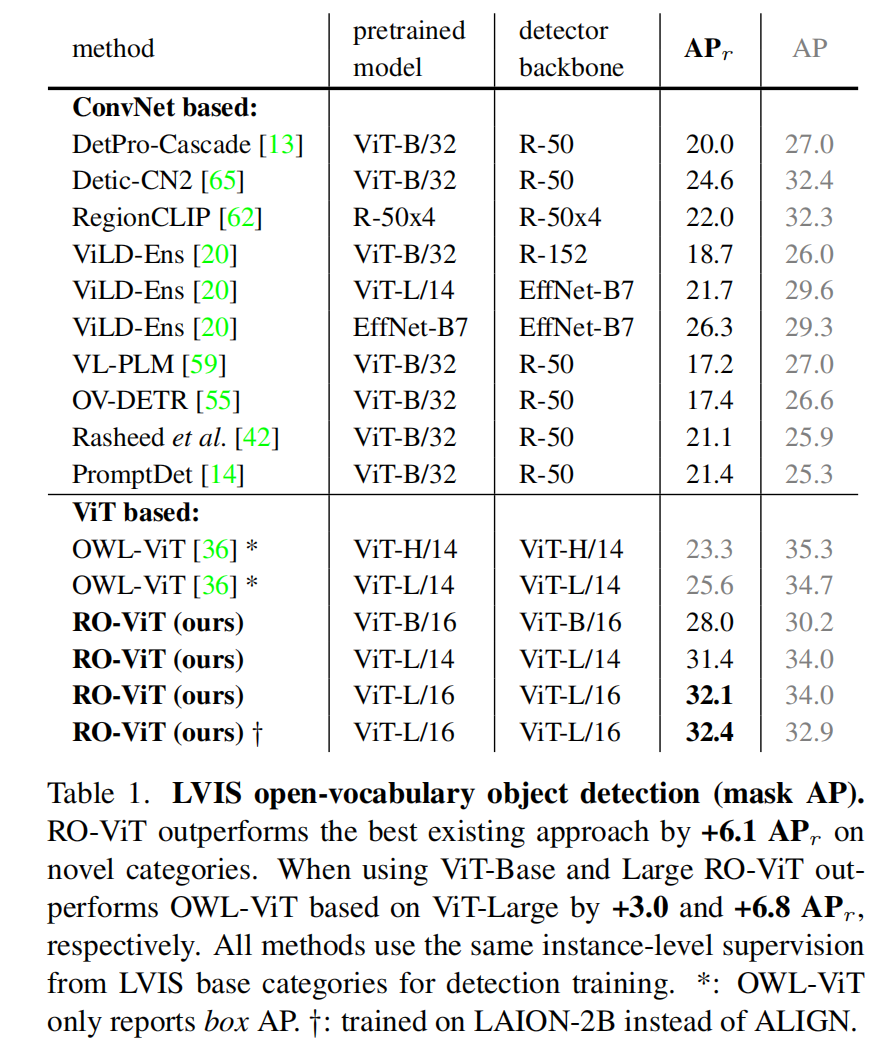
LVIS:
- 使用基础类别训练,rare 类别作为新类来测试,测试了 3 次取了平均
- APr 取得 32.4
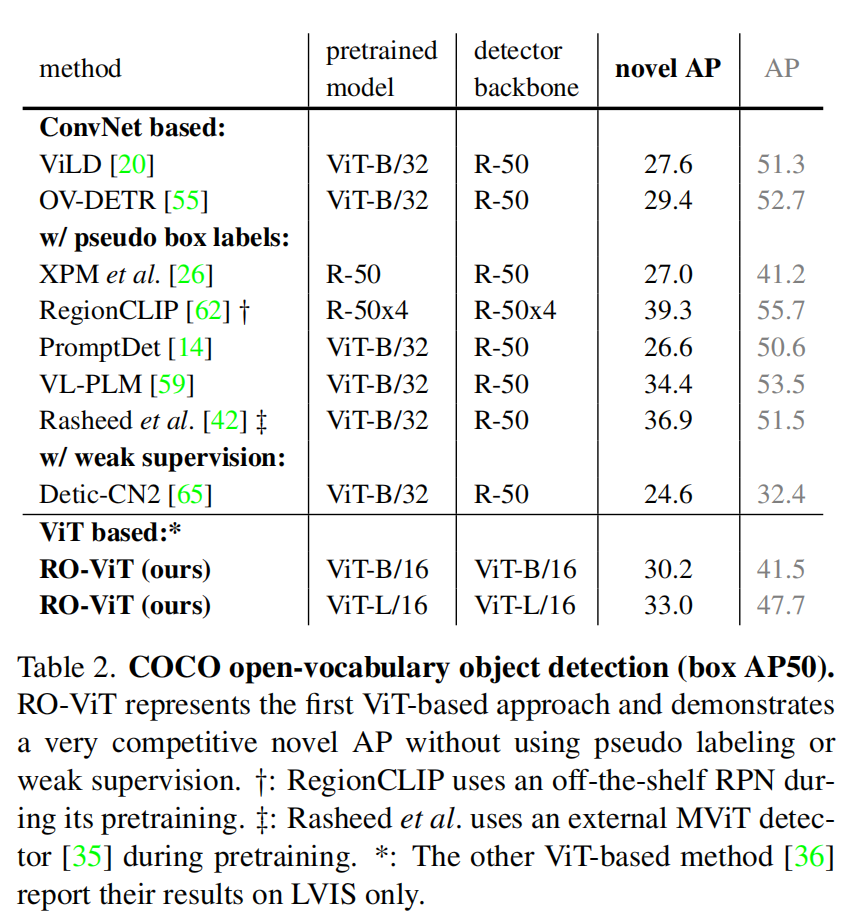
COCO:
- 使用 48 个基础类别训练,17 个新类测试
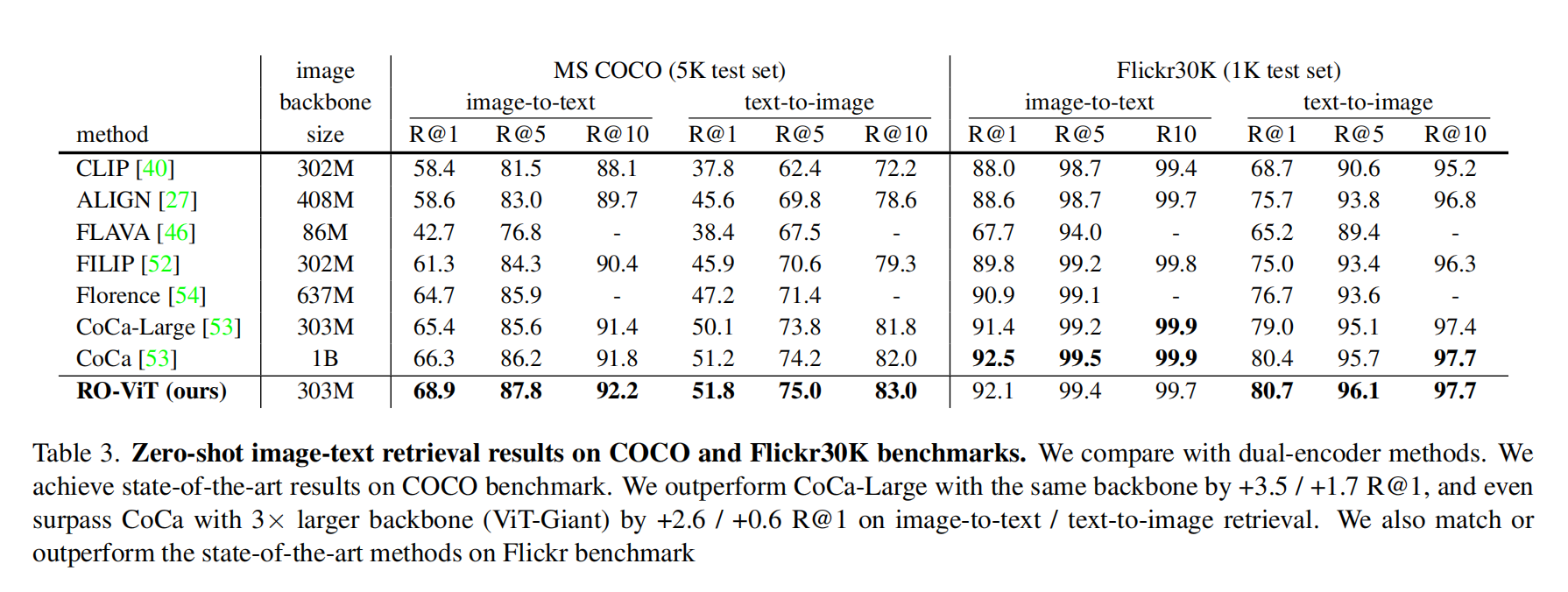
3.3 Image-text retrieval
zero-shot image-text retrieval on coco and Flickr30k
3.4 Transfer object detection
3.5 消融实验



![[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍...](https://img-blog.csdnimg.cn/img_convert/a0d24a580831ed4856a2c7d8331b55e8.png)