目录
🍁🍁背景
🌷🌷网络结构
🎅🎅损失函数
🌼🌼动量蒸馏
🌺🌺下游任务结果
📒📒Grad-CAM 特征可视化
🚦🚦代码
🎨1.预训练customdata
🎨2.图文检索
🎨3.VQA
🎨4.VE
🎨5.vg
🎨6.NLVR2
整理不易,欢迎一键三连!!!
出处:跟BLIP一样salesforce,同一个单位,准确来讲,先有ALBEF(2021),再有BLIP(2022)。
代码地址:code
论文地址:paper
官方博客:blog
🍁🍁背景
限制1:以 CLIP 和 code 为代表的方法学习单峰图像编码器和文本编码器,并在表示学习任务上取得了令人印象深刻的性能。然而,它们缺乏对图像和文本之间复杂交互进行建模的能力,因此它们不擅长需要细粒度图像文本理解的任务。
限制2:UNITER[4]代表的方法采用多模态编码器对图像和文本进行联合建模。然而,多模态转换器的输入包含未对齐的基于区域的图像特征和单词标记嵌入。由于视觉特征和文本特征驻留在各自的空间中,因此多模态编码器学习对它们的交互进行建模具有挑战性。此外,大多数方法使用预先训练的目标检测器进行图像特征提取,这既昂贵又计算昂贵。
限制 3:用于预训练的数据集主要由从网络收集的噪声图像文本对组成。广泛使用的预训练目标,例如掩码语言模型(MLM),很容易过度拟合噪声文本,从而损害表示学习。
为了解决这些限制,我们提出了 ALign BEfore Fuse ( ALBEF )
🌷🌷网络结构
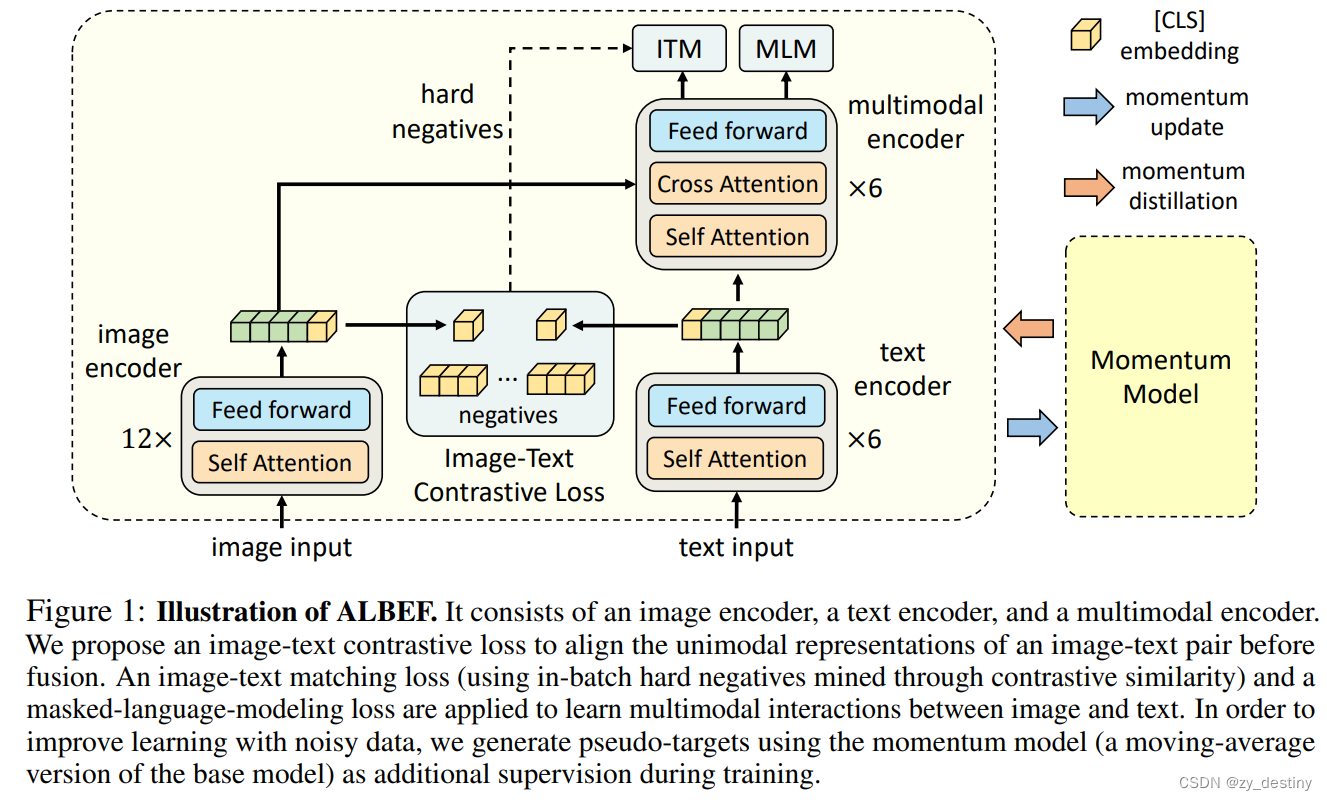
ALBEF 包含图像编码器(ViT-B/16)、文本编码器(BERT 的前 6 层)和多模态编码器(BERT 的后 6 层,带有额外的交叉注意力层)。我们通过联合优化以下三个目标来预训练 ALBEF:
目标 1:图像-文本对比学习应用于单流图像编码器和文本编码器。它将图像特征和文本特征对齐,并训练单模态编码器以更好地理解图像和文本的语义。
目标2:应用于多模态编码器的图像文本匹配,预测一对图像和文本是正(匹配)还是负(不匹配)。我们提出了对比硬负例挖掘,它选择具有更高对比相似性的信息负例。
目标 3:应用于多模态编码器的掩码语言建模。我们随机屏蔽文本标记,并训练模型使用图像和屏蔽文本来预测它们。
🎅🎅损失函数
损失函数也就由3部分组成:
- ITC(image-text contrastive loss):图像-文本对比损失
- ITM(image-text matching):图像-文本匹配损失
- MLM(masked language modeling):掩码语言模型损失
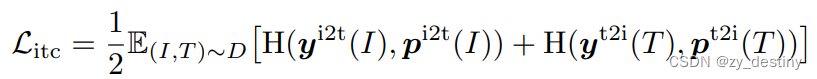
![]()

🌼🌼动量蒸馏
本文的另外一个 创新点就是动量蒸馏,从网络收集的图像文本对通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中未描述的实体。为了从噪声数据中学习,我们提出了动量蒸馏,其中我们使用动量模型来生成图像文本对比学习和掩蔽语言建模的伪目标。下图显示了图像的伪正文本示例,它产生了“年轻女子”和“树”等新概念。我们还从互信息最大化的角度提供了理论解释,表明动量蒸馏可以解释为为每个图像-文本对生成视图。


简单理解动量蒸馏就是通过动量更新得到伪label的过程,因为在图文对比的时候,可能会有一些负样本的pair对也存在一定的相关性,而掩码建模的任务中,可能也会存在更好的描述来代替mask掉的文本。这里动量蒸馏的意思是用动量模型的结果来在一定程度上修正gt,而动量模型的概念来自于Moco。
🌺🌺下游任务结果
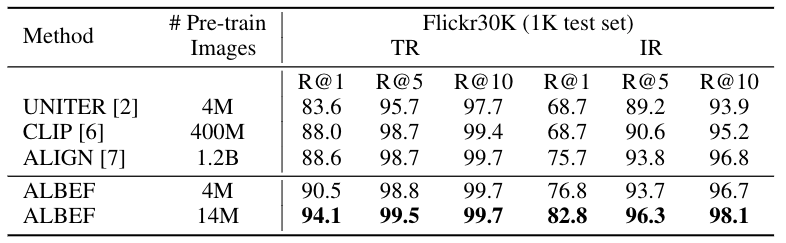
零样本图文检索结果
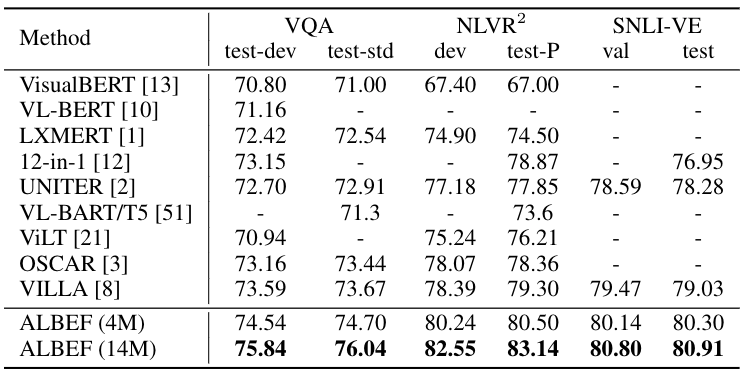
视觉问答 (VQA)、自然语言视觉理解 (NLVR) 和视觉蕴含 (SNLI-VE) 的结果
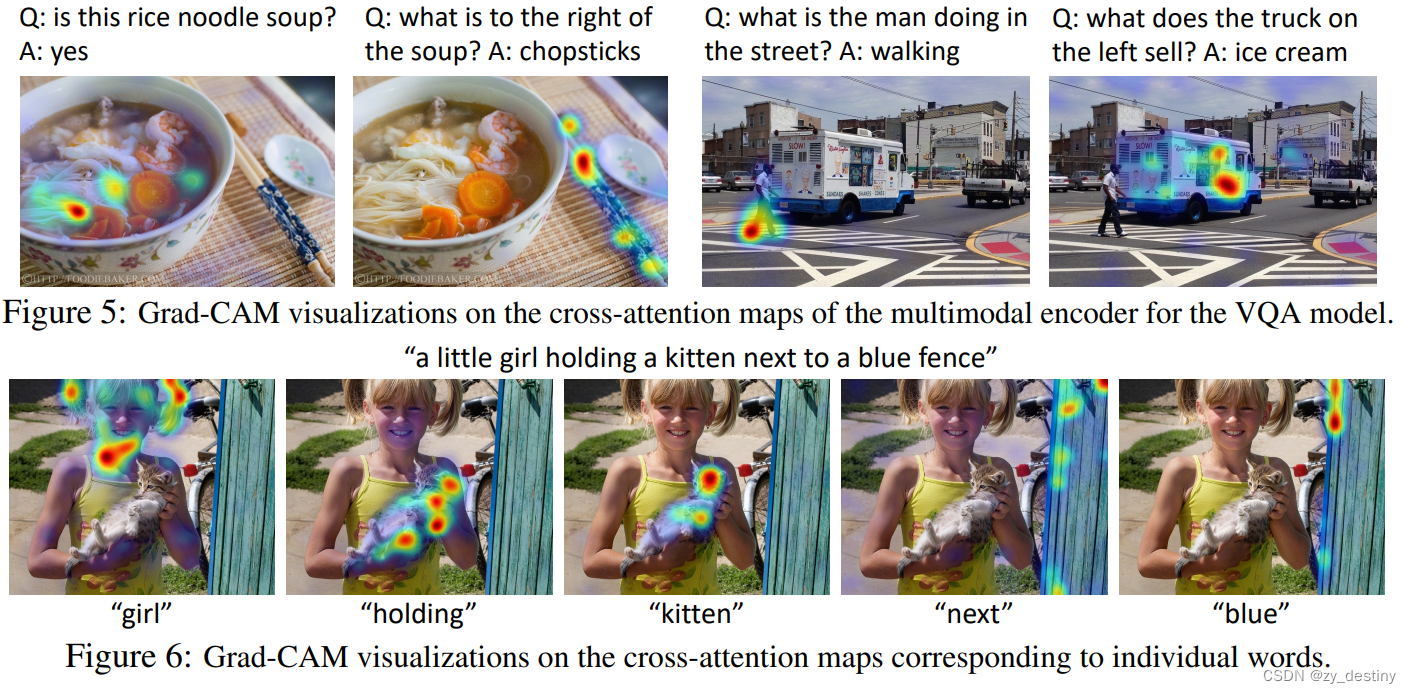
📒📒Grad-CAM 特征可视化
我们发现 ALBEF 隐式地学习了对象、属性和关系的准确基础,尽管没有接受任何边界框注释的训练。我们使用 Grad-CAM 来探测多模态编码器的交叉注意力图,并在弱监督视觉基础任务上取得了最先进的结果。下图显示了一些可视化示例。

🚦🚦代码
🎨1.预训练customdata
python -m torch.distributed.launch --nproc_per_node=8 --use_env Pretrain.py --config ./configs/Pretrain.yaml --output_dir output/Pretrain 🎨2.图文检索
#Image-Text Retrieval:
#Download MSCOCO or Flickr30k datasets from the original websites.
#Download and extract the provided dataset json files.
#In configs/Retrieval_coco.yaml or configs/Retrieval_flickr.yaml, set the paths for the #json files and the image path.
#Finetune the pre-trained checkpoint using 8 A100 GPUs:
python -m torch.distributed.launch --nproc_per_node=8 --use_env Retrieval.py \
--config ./configs/Retrieval_flickr.yaml \
--output_dir output/Retrieval_flickr \
--checkpoint [Pretrained checkpoint]🎨3.VQA
#VQA:
#Download VQA v2 dataset and Visual Genome dataset from the original websites.
#Download and extract the provided dataset json files.
#In configs/VQA.yaml, set the paths for the json files and the image paths.
#Finetune the pre-trained checkpoint using 8 A100 GPUs:
python -m torch.distributed.launch --nproc_per_node=8 --use_env VQA.py \
--config ./configs/VQA.yaml \
--output_dir output/vqa \
--checkpoint [Pretrained checkpoint]🎨4.VE
#Visual Entailment:
#Download SNLI-VE dataset from the original website.
#Download and extract the provided dataset json files.
#In configs/VE.yaml, set the paths for the json files and the image path.
#Finetune the pre-trained checkpoint using 8 A100 GPUs:
python -m torch.distributed.launch --nproc_per_node=8 --use_env VE.py \
--config ./configs/VE.yaml \
--output_dir output/VE \
--checkpoint [Pretrained checkpoint]🎨5.vg
#Visual Grounding on RefCOCO+:
#Download MSCOCO dataset from the original website.
#Download and extract the provided dataset json files.
#In configs/Grounding.yaml, set the paths for the json files and the image path.
#Finetune the pre-trained checkpoint using 8 A100 GPUs:
python -m torch.distributed.launch --nproc_per_node=8 --use_env Grounding.py \
--config ./configs/Grounding.yaml \
--output_dir output/RefCOCO \
--gradcam_mode itm \
--block_num 8 \
--checkpoint [Pretrained checkpoint]🎨6.NLVR2
#预训练python -m torch.distributed.launch --nproc_per_node=8 --use_env Pretrain_nlvr.py \
--config ./configs/NLVR_pretrain.yaml \
--output_dir output/NLVR_pretrain \
--checkpoint [Pretrained checkpoint]#训练python -m torch.distributed.launch --nproc_per_node=8 --use_env NLVR.py \
--config ./configs/NLVR.yaml \
--output_dir output/NLVR \
--checkpoint [TA pretrained checkpoint]整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷
![[JavaScript游戏开发] 绘制冰宫宝藏地图、人物鼠标点击移动、障碍检测](https://img-blog.csdnimg.cn/f6af768ffacd4764b475e8140d6bb74b.png)