本文是《用go实现解释器》的读书笔记

https://malred-blogmalred.github.io/2023/06/03/ji-suan-ji-li-lun-ji-shu-ji/shi-ti/go-compile/yong-go-yu-yan-shi-xian-jie-shi-qi/go-compiler-1/#toc-heading-6![]() http://个人博客该笔记地址
http://个人博客该笔记地址
github.com/malred/malang![]() http://代码仓库
http://代码仓库
1. 词法分析
1.1 词法分析
为了解释源代码,需要将其转换为易于理解的形式, 最终对代码求值之前, 需要两次转换源代码的表示形式
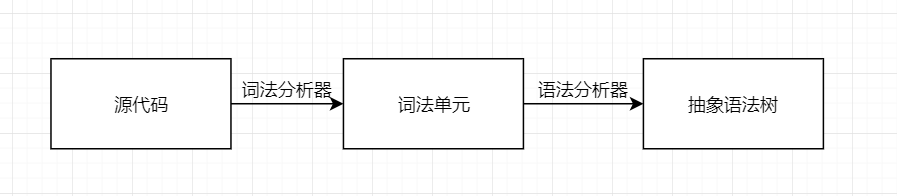
词法分析器的作用如下:
let x = 5 + 5; -> [LET,INDENTIFIER(“x”),EQUAL_SIGN,INTERGER(5),PLUS_SIGN,INTERGER(5),SEMICOLON] 设 x = 5 + 5;-> [LET,INDENTIFIER(“X”),EQUAL_SIGN,INTERGER(5),PLUS_SIGN,INTERGER(5),SEMICOLON]
不同词法分析器生成的词法单元会有区别
-
空白字符不会被识别(python 等语言会)
-
完整的词法分析器还可将行列号和文件名附加到词法单元中,后续语法分析可以更好地报错
1.2 定义词法单元
先定义词法分析器输出的词法单元 这是要解析的语句段(Monkey 语言)
let five = 5;
let ten = 10;let add = fn(x,y) {x + y;
}let result = add(five, ten);-
数字都是整数,按字面量处理,并赋予单独的类型
-
变量名和数字等语言,统一用作标识符
-
还有一些看着像标识符的,但实际是关键字,会特殊处理
定义 Token 数据结构,属性有 1.词法单元类型;2.字面量 词法单元类型定义为字符串,消耗一些性能,但是调试使用方便
// token/token.go
package token// 词法单元类型
type TokenType string// 词法单元
type Token struct {Type TokenType// 字面量Literal string
}将词法单元类型定义为常量
const (// 特殊类型ILLEGAL = "ILLEGAL" // 未知字符EOF = "EOF" // 文件结尾// 标识符+字面量IDENT = "IDENT" // add, foobar, x, yINT = "INT" // 1343456// 运算符ASSIGN = "="PLUS = "+"// 分隔符COMMA = ","SEMICOLON = ";"LPAREN = "("RPAREN = ")"LBRACE = "{"RBRACE = "}"// 关键字FUNCTION = "FUNCTION"LET = "LET"
) 1.3 词法分析器
词法分析器接收源代码(字符串),然后调用 NextToken()逐个遍历字符进行词法分析 生产环境,将文件名和行号附加到词法单元,最好使用 io.Reader 加上文件名来初始化词法分析器
// lexer/lexer.go
package lexertype Lexer struct {input stringposition int // 输入的字符串中的当前位置(指向当前字符)readPosition int // 输入的字符串中的当前读取位置(指向当前字符串之后的一个字符(ch))ch byte // 当前正在查看的字符
}func New(input string) *Lexer {l := &Lexer{input: input}return l
}// 读取下一个字符
func (l *Lexer) readChar() {if l.readPosition >= len(l.input) {l.ch = 0 // NUL的ASSII码(0)} else {// 读取l.ch = l.input[l.readPosition]}// 前移l.position = l.readPositionl.readPosition += 1
}-
readChar 的作用是读取 input 中下个字符,然后将索引前推,NUL 字符的 ASCII 码是 0,表示”尚未读取任何内容”或”文件结尾”
-
该分析器只支持 ASCII 字符,不能支持所有 Unicode 字符,如果要支持,则 l.ch 要改为 rune 类型,并且要修改读取下一个字符的方式,字符也有可能会是多字节,l.input[l.readPosition]将无法工作
在 New 中调用 readChar 以初始化
func New(input string) *Lexer {l := &Lexer{input: input}// 初始化 l.ch,l.position,l.readPositionl.readChar()return l
}第一版 NextToken
// lexer/lexer.go
package lexerimport ("go-monkey-compiler/token"
)// 创建词法单元的方法
func newToken(tokenType token.TokenType, ch byte) token.Token {return token.Token{Type: tokenType,Literal: string(ch),}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Tokenswitch l.ch {case '=':tok = newToken(token.ASSIGN, l.ch)case ';':tok = newToken(token.SEMICOLON, l.ch)case '(':tok = newToken(token.LPAREN, l.ch)case ')':tok = newToken(token.RPAREN, l.ch)case ',':tok = newToken(token.COMMA, l.ch)case '+':tok = newToken(token.PLUS, l.ch)case '{':tok = newToken(token.LBRACE, l.ch)case '}':tok = newToken(token.RBRACE, l.ch)case 0:tok.Literal = ""tok.Type = token.EOF}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input := `=+(){},;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.ASSIGN, "="},{token.PLUS, "+"},{token.LPAREN, "("},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RBRACE, "}"},{token.COMMA, ","},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got==%q", i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got==%q", i, tt.expectedLiteral, tok.Literal)}}}go test ./lexer

添加标识符/关键字/数字的处理
// lexer/lexer.go
// 判断读取到的字符是不是字母
func isLetter(ch byte) bool {return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_'
}// 读取字母(标识符/关键字)
func (l *Lexer) readIdentifier() string {position := l.positionfor isLetter(l.ch) {// 如果接下来还有字母,就一直移动指针到不是字母l.readChar()}return l.input[position:l.position]
}func (l *Lexer) NextToken() token.Token {var tok token.Tokenswitch l.ch {// ...default:if isLetter(l.ch) {tok.Literal = l.readIdentifier()tok.Type = token.LookupIdent(tok.Literal)return tok} else {tok = newToken(token.ILLEGAL, l.ch)}}l.readChar()return tok
}在 token.go 里添加识别关键字和用户定义标识符的方法
// 关键字map
var keywords = map[string]TokenType{"fn": FUNCTION,"let": LET,
}func LookupIdent(ident string) TokenType {// 从关键字map里找,找到了就说明是关键字if tok, ok := keywords[ident]; ok {return tok}// 标识符return IDENT
}此时如果遇到空白字段,会报错 IDENT!=ILLEGAL,需要添加跳过空格的方法
// lexer/lexer.go// 跳过空格
func (l *Lexer) skipWhitespace() {for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {l.readChar()}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {// ...}// ...
}现在添加将数字转为词法单元的功能 数字的识别还可以是浮点数/16 进制/8 进制等,但是书中为了教学而简化了
// 跳过空格
func (l *Lexer) skipWhitespace() {for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {l.readChar()}
}// 判断是否是数字
func isDigit(ch byte) bool {return '0' <= ch && ch <= '9'
}// 读取数字
func (l *Lexer) readNumber() string {// 记录起始位置position := l.positionfor isDigit(l.ch) {l.readChar()}return l.input[position:l.position]
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {// ...default:if isLetter(l.ch) {tok.Literal = l.readIdentifier()tok.Type = token.LookupIdent(tok.Literal)// 因为readIdentifier会调用readChar,所以提前return,不需要后面再readCharreturn tok} else if isDigit(l.ch) {tok.Type = token.INTtok.Literal = l.readNumber()return tok} else {tok = newToken(token.ILLEGAL, l.ch)}}l.readChar()return tok
}拓展测试用例,处理开头提到的那个 Monkey 代码段
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x,y) {x + y;};let result = add(five, ten);`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got==%q", i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got==%q", i, tt.expectedLiteral, tok.Literal)}}}1.4 拓展词法单元和词法分析器
添加对 == ! != - / * < > 和关键字 true false if else return 的支持 可分为
-
单字符语法单元(如-,!)
-
双字符语法单元(如==) <- 后续添加支持
-
关键字语法定义(如 return)
添加对- / * < > 的支持 token 常量中添加新定义
const (// ...// 运算符ASSIGN = "="PLUS = "+"MINUS = "-"BANG = "!"ASTERISK = "*"SLASH = "/"LT = "<"GT = ">"// ...
)lexer.go 的 switch 中添加新的词法单元生成
// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {case '=':tok = newToken(token.ASSIGN, l.ch)case '+':tok = newToken(token.PLUS, l.ch)case '-':tok = newToken(token.MINUS, l.ch)case '!':tok = newToken(token.BANG, l.ch)case '/':tok = newToken(token.SLASH, l.ch)case '*':tok = newToken(token.ASTERISK, l.ch)case '<':tok = newToken(token.LT, l.ch)case '>':tok = newToken(token.GT, l.ch)// ...}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}进一步拓展,添加新关键字的解析 true false if else return 将新关键字分别添加到 token 的常量列表和 keywords 关键字 map 里
const (// ...// 关键字FUNCTION = "FUNCTION"LET = "LET"TRUE = "TRUE"FALSE = "FALSE"IF = "IF"ELSE = "ELSE"RETURN = "RETURN"
)// 关键字map
var keywords = map[string]TokenType{"fn": FUNCTION,"let": LET,"true": TRUE,"false": FALSE,"if": IF,"else": ELSE,"return": RETURN,
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;if (5 < 10) {return true;} else {return false;}`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.IF, "if"},{token.LPAREN, "("},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.TRUE, "true"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.ELSE, "else"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.FALSE, "false"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}拓展,添加对!=和==的支持 添加常量
const (// ...EQ = "=="NOT_EQ = "!="// ...
)因为每次读入一个字符,所以不能直接 case !=来判别,应该复用!和=的判断分支,根据下一个字符来决定是返回=还是==
// 向前查看一个字符,但是不移动指针
func (l *Lexer) peekChar() byte {if l.readPosition >= len(l.input) {return 0} else {return l.input[l.readPosition]}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {case '=':if l.peekChar() == '=' {// 记录当前ch (=)ch := l.chl.readChar()literal := string(ch) + string(l.ch)tok = token.Token{Type: token.EQ, Literal: literal}} else {tok = newToken(token.ASSIGN, l.ch)}// ...case '!':if l.peekChar() == '=' {// 记录当前ch (!)ch := l.chl.readChar()literal := string(ch) + string(l.ch)tok = token.Token{Type: token.NOT_EQ, Literal: literal}} else {tok = newToken(token.BANG, l.ch)}// ...}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;if (5 < 10) {return true;} else {return false;}10 == 10;10 != 9;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.IF, "if"},{token.LPAREN, "("},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.TRUE, "true"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.ELSE, "else"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.FALSE, "false"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.INT, "10"},{token.EQ, "=="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.INT, "10"},{token.NOT_EQ, "!="},{token.INT, "9"},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}1.5 编写 REPL
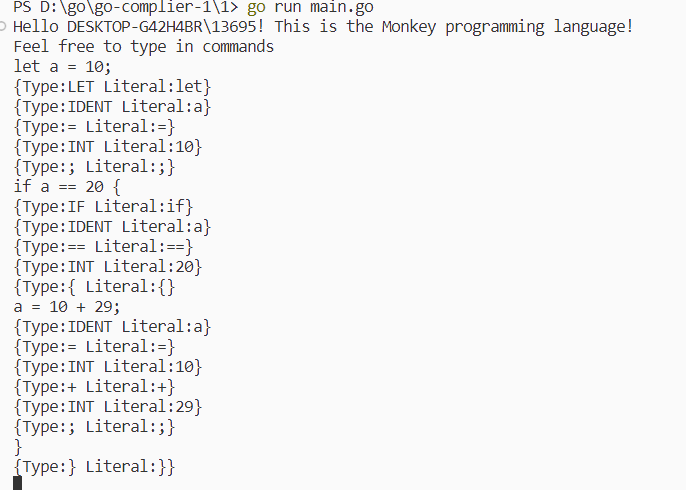
REPL 即 Read-Eval-Print-Loop(读取-求值-打印循环) REPL 读取输入,传给解释器求值,任何输出,并重复之前的步骤 这里是输入源代码,然后每次读取一行,直到遇到 EOF,期间输出词法生成器生成的词法单元
// repl/repl.go
package replimport ("bufio""fmt""go-monkey-compiler/token""go-monkey-compiler/lexer""io"
)const PROMPT = ">> "func Start(in io.Reader, out io.Writer) {scanner := bufio.NewScanner(in)for {scanned := scanner.Scan()if !scanned {return}line := scanner.Text()l := lexer.New(line)for tok := l.NextToken(); tok.Type != token.EOF; tok = l.NextToken() {fmt.Fprintf(out, "%+v\n", tok)}}
}创建 main.go,启动 REPL
// main.go
package mainimport ("fmt""go-monkey-compiler/repl""os""os/user"
)func main() {user, err := user.Current()if err != nil {panic(err)}fmt.Printf("Hello %s! This is the Monkey programming language!\n", user.Username)fmt.Printf("Feel free to type in commands\n")repl.Start(os.Stdin, os.Stdout)
}测试