对于我自己来说,该需求源自于分析Movielens-1m数据集的用户数据:
UserID::Gender::Age::Occupation::Zip-code
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
4::M::45::7::02460
5::M::25::20::55455
6::F::50::9::55117
我希望根据Zip-code计算出用户所在的州,然后在地图上显示每个州的用户数量。
那么应该这样写代码:
import pandas as pd
import geopandas as gpd
import plotly.express as px
from uszipcode import SearchEngine# 创建 SearchEngine 实例
search = SearchEngine()# 读取用户数据集
data = pd.read_csv('./users.dat', sep='::', engine='python',names=['UserID', 'Gender', 'Age', 'Occupation', 'Zip-code'])
data = data.dropna(subset=['Zip-code'])def get_state_name(zipcode):result = search.by_zipcode(zipcode)if result is None:return Noneelse:state_abbr = result.statereturn state_abbr
data['STATE_ABBR'] = data['Zip-code'].apply(get_state_name)# 计算每个Zip-code的用户数量
zip_counts = data['STATE_ABBR'].value_counts()
zip_counts_df = zip_counts.reset_index() # 将Series转换为DataFrame
zip_counts_df.columns = ['STATE_ABBR', 'COUNT'] # 重新命名列# 读取美国地图的shapefile
usa_map = gpd.read_file('./shapefile/USA_States.shp')# 将Zip-code数据与地图数据进行合并
# 简称合并使用STATE_ABBR,全称合并使用STATE_NAME
zip_geo = pd.merge(usa_map, zip_counts_df, on='STATE_ABBR')# 绘制地图
fig = px.choropleth(zip_geo,locations='STATE_ABBR',locationmode='USA-states',color='COUNT',scope='usa',hover_data=['COUNT'],color_continuous_scale='Reds',range_color=(0, zip_geo['COUNT'].max()),labels={'STATE_ABBR': 'User Count'})
fig.update_layout(title_text='Movielens User Distribution by State')
fig.show()
在上面的代码中,USA_States.shp可以在efrainmaps(https://www.efrainmaps.es/english-version/free-downloads/united-states/)下载。
效果如下,鼠标悬停到某个州,可以显示出州名称和对应的用户数量:
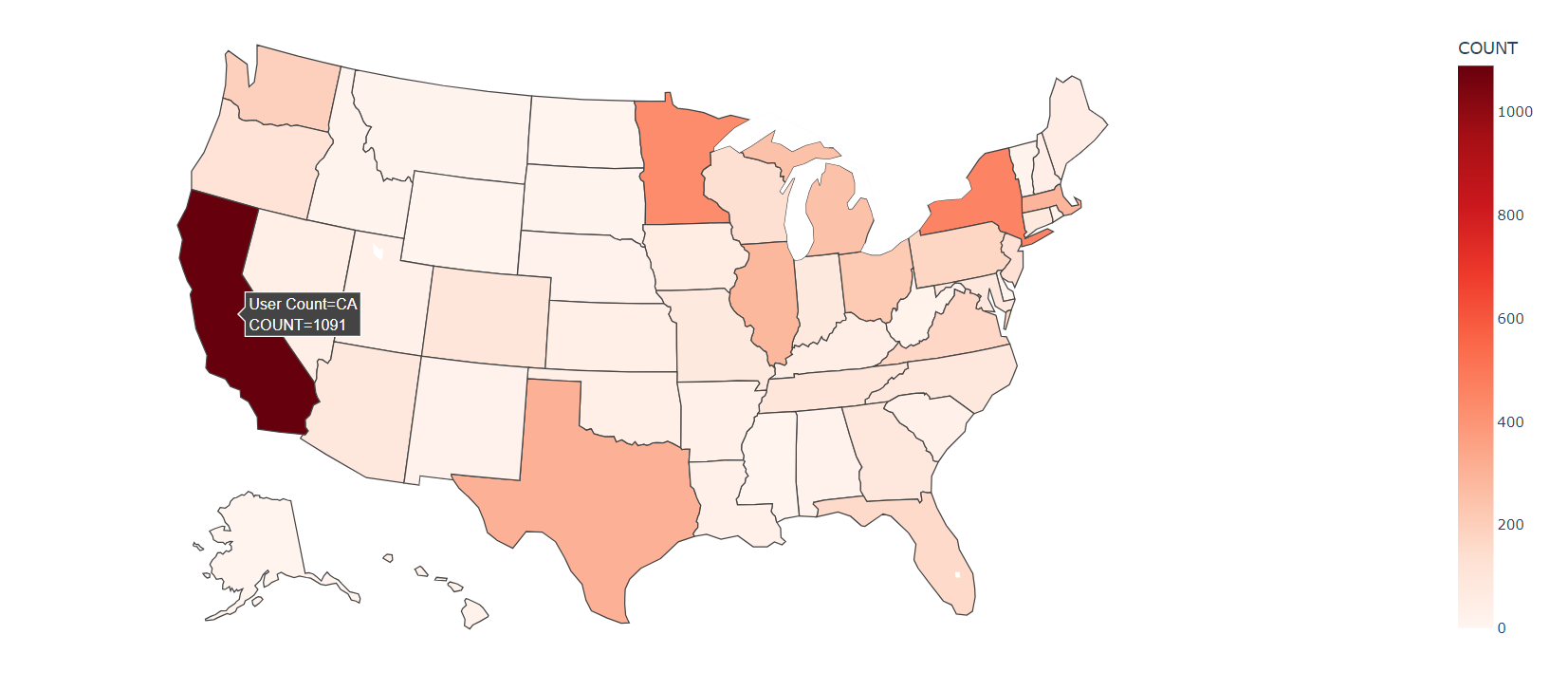
如果不希望显示州简称,可以创建州的简称与全称的映射,然后将Zip-code映射到州的全称,再显示地图:
# 创建州的简称与全称的映射
# 该映射字典涵盖了50个州、哥伦比亚特区、5个美国领土以及3个军邮邮编简称。
state_name_dict = {"AL": "Alabama","AK": "Alaska","AZ": "Arizona","AR": "Arkansas","CA": "California","CO": "Colorado","CT": "Connecticut","DE": "Delaware","FL": "Florida","GA": "Georgia","HI": "Hawaii","ID": "Idaho","IL": "Illinois","IN": "Indiana","IA": "Iowa","KS": "Kansas","KY": "Kentucky","LA": "Louisiana","ME": "Maine","MD": "Maryland","MA": "Massachusetts","MI": "Michigan","MN": "Minnesota","MS": "Mississippi","MO": "Missouri","MT": "Montana","NE": "Nebraska","NV": "Nevada","NH": "New Hampshire","NJ": "New Jersey","NM": "New Mexico","NY": "New York","NC": "North Carolina","ND": "North Dakota","OH": "Ohio","OK": "Oklahoma","OR": "Oregon","PA": "Pennsylvania","RI": "Rhode Island","SC": "South Carolina","SD": "South Dakota","TN": "Tennessee","TX": "Texas","UT": "Utah","VT": "Vermont","VA": "Virginia","WA": "Washington","WV": "West Virginia","WI": "Wisconsin","WY": "Wyoming","DC": "District of Columbia","AS": "American Samoa","GU": "Guam","MP": "Northern Mariana Islands","PR": "Puerto Rico","UM": "United States Minor Outlying Islands","VI": "Virgin Islands","AA": "Armed Forces Americas","AE": "Armed Forces Europe","AP": "Armed Forces Pacific"
}def get_state_name(zipcode):result = search.by_zipcode(zipcode)if result is None:return Noneelse:state_abbr = result.statestate_name = state_name_dict.get(state_abbr, None)return state_name
data['STATE_NAME'] = data['Zip-code'].apply(get_state_name)
# 后续代码同上,注意要将STATE_ABBR替换为STATE_NAME