🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者
📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代
🌲文章所在专栏:RocketMQ
🤔 我当前正在学习微服务领域、云原生领域、消息中间件等架构、原理知识
💬 向我询问任何您想要的东西,ID:vnjohn
🔥觉得博主文章写的还 OK,能够帮助到您的,感谢三连支持博客🙏
😄 代词: vnjohn
⚡ 有趣的事实:音乐、跑步、电影、游戏
目录
- What is RocketMQ?
- 概念
- 消息模型(Message Model)
- 消息生产者(Producer)
- 消息消费者(Consumer)
- 主题(Topic)
- 代理服务器(Broker Server)
- 名字服务器(Name Server)
- 拉取式消费(Pull Consumer)
- 推动式消费(Push Consumer)
- 生产者组(Producer Group)
- 消费者组(Consumer Group)
- 集群消费(Clustering)
- 广播消费(Broadcasting)
- 普通顺序消息(Normal Ordered Message)
- 严格顺序消息(Strictly Ordered Message)
- 消息(Message)
- 标签(Tag)
- RocketMQ vs Kafka
- 搭建单节点 RocketMQ
- 搭建集群 RocketMQ
- 集群方式
- 准备工作
- 存储目录规划
- 配置文件调整
- 集群节点同步>更新配置
- 启动集群
- RocketMQ 控制台
- 总结
What is RocketMQ?
People subscribe to some of their favorites by applications. When an author publishes an article to the relevant section, we can receive relevant news feeds.
RocketMQ 是由阿里巴巴集团开发的一款分布式消息中间件。它是一个开源的、高吞吐量、低延迟的消息队列系统,用于在分布式系统中进行消息传递和异步通信
RocketMQ 主要特点如下:
- 高吞吐量:RocketMQ 能够处理大量消息,支持每秒百万级别的消息吞吐量,适合高并发场景
- 低延迟:RocketMQ 在消息的传递和处理上具有低延迟性能,适合实时数据处理和高性能要求的场景
- 分布式架构:RocketMQ 被设计成分布式架构,可以在多个服务器上部署,构建高可用、可扩展的消息系统
- 可靠性:RocketMQ 支持消息持久化,保证消息在发送和消费过程中的可靠性,不会因为丢失消息而导致数据丢失
- 支持多种消息模式:RocketMQ 支持多种消息模式,包括点对点(P2P)和发布-订阅(Pub/Sub)模式
- 提供消息顺序保证:RocketMQ 能够确保消息按照特定顺序进行传递、消费,保证业务的一致性
RocketMQ 被广泛应用于各种分布式系统中,特别适用于大规模的数据传输、解耦各个模块之间的通信。它在电商、金融、物流、社交等领域都得到了广泛应用,是一个成熟稳定的分布式消息中间件解决方案
概念
消息模型(Message Model)
RocketMQ 主要由 Producer、Broker、Consumer 三部分组成,其中 Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息;Broker 在实际的部署过程中对应一台服务器,每个 Broker 可以存储多个 Topic 消息,每个 Topic 消息也可以分片存储在不同的 Broker 中;Message Queue 用于存储消息的无力地址,每个 Topic 中消息地址存储于多个 Message Queue 中;ConsumerGroup 由多个 Consumer 实例构成
消息生产者(Producer)
负责生产消息,一般由业务系统负责生产消息;一个消息生产者会把业务应用系统里产生的消息发送到 Broker 服务器;RocketMQ 提供多种发送方式,同步发送、异步发送、顺序发送、单向发送;同步、异步方式均需要通过 Broker 返回确认信息,单向发送不需要
消息消费者(Consumer)
负责消费消息,一般是由后端系统负责异步消费;一个消息消费者会从 Broker 服务器拉取消息,并将其提供给应用程序;从用户应用的角度而言提供了两种消费形式:拉取消费、推动消费
主题(Topic)
表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是 RocketMQ 进行消息订阅的基本单位
代理服务器(Broker Server)
消息中转角色,负责存储消息、转发消息;代理服务器在 RocketMQ 系统中负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备;代理服务器也存储消息相关的元数据,包括消费者组、消费进度偏移和队列消息等
名字服务器(Name Server)
名字服务充当于路由消息的提供者,生产者或消费者能够通过名字服务查找各主题相应的 Broker IP 列表;多个 Namesrv 实例组成集群,但相互之间是独立的,没有信息交换
拉取式消费(Pull Consumer)
Consumer 消费的一种类型,应用程序主动调用 Consumer 拉消息方法从 Broker 服务器拉消息、主动权由应用程序控制;一旦获取了批量消息,应用就会启动消费过程
推动式消费(Push Consumer)
Consumer 消费的一种类型,该模式下 Broker 收到数据后会主动推送给消费端,该消费模式一般实时性较高
生产者组(Producer Group)
同一类 Producer 集合,这类 Producer 发送同一类消息且发送逻辑一致;若发送的是事务消息且原始生产者在发送之后崩溃,则 Broker 服务器会联系同一生产者组的其他生产者实例提交或回溯消费
消费者组(Consumer Group)
同一类 Consumer 集合,这类 Consumer 通常消费同一类消息且消费逻辑一致;消费者组使得在消息消费方面,实现负载均衡、容错的目标变得非常容易
消费者组的消费者实例必须订阅完全相同的 Topic,RocketMQ 支持两种消息模式:集群消费(Clustering)和广播消费(Broadcasting)
集群消费(Clustering)
集群消费模式下,相同 Consumer Group 中每个 Consumer 实例平均分摊消息
广播消费(Broadcasting)
广播消费模式下,相同 Consumer Group 中每个 Consumer 实例都接收全量的消息
普通顺序消息(Normal Ordered Message)
普通顺序消费模式下,消费者通过同一个消息队列(Topic 分区,称作为 Message Queue > 类比于 Kafka 中的 partition 角色)收到的消息是有顺序的,不同消息队列收到的消息则可能是无顺序的
严格顺序消息(Strictly Ordered Message)
严格顺序消费模式下,消费者收到的所有消息均是有顺序的
消息(Message)
消费系统所传输消息的物理载体,生产、消费数据的最小单位,每条消息都必须属于一个主题;RocketMQ 中每个消息拥有唯一的 Message ID,且可以携带具有业务标识的 Key,系统提供了通过 Message ID、Key 查询消息的功能
标签(Tag)
提供为消息设置的标志✅,用于同一个主题喜爱区分不同类型的消息,来自同一个业务单元的消息,可以根据不同业务目的在同一个主题下设置不同的标签;标签能够有效的保持代码的清晰度、连贯性,并优化 RocketMQ 提供的查询系统;消费者可以通过 Tag 实现对不通过子主题的不同消费逻辑,实现更好的扩展性
RocketMQ vs Kafka
RocketMQ、Kafka 都是一种消息中间件的解决方案,用于业务解耦、提供系统扩展性|可用性
在公司实际应用中,RocketMQ 更适用于作业务系统开发中之间的一种消息转发,Kafka 更适用于大数据量采集、吞吐消费的一种消费
一般是由大数据平台采用 Kafka 中间件投递业务消费,比如:C 端埋点事件上报,然后业务系统中针对对应的 Topic、Partition 进行消息的订阅,获取到消息以后,在业务系统内部对 Kafka 消息进行处理,同时应用在微服务体系架构下,或由当前所在的业务应用程序消费处理,或通过 RocketMQ 消息中间件进行业务消息的生产投递给 Broker,由其他的微服务应用程序进行消费处理该条业务消息;类比于下图所示

Kafka 开篇内容更多介绍可以详细阅读以下这篇文章:
Kafka 实战开篇-讲解架构模型、基础概念以及集群搭建
搭建单节点 RocketMQ
首先要下载好对应的 RocketMQ 可在 Linux 环境下可执行的包
RocketMQ 执行包下载仓库
如:rocketmq-all-4.9.3-bin-release.zip 2022-02-26 17:10 26M
将下载好包上传到 Linux 服务器上的某一个目录下,比如:/opt
1、解压可执行包:unzip rocketmq-all-4.9.3-bin-release.zip
2、跳转解压过后的根目录:cd /opt/rocketmq-4.9.3
3、启动 namesrv 名字服务器:nohup sh bin/mqnamesrv &,在 nohup.out 文件中会出现如下内容:
Java HotSpot(TM) 64-Bit Server VM warning: Using the DefNew young collector with the CMS collector is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: UseCMSCompactAtFullCollection is deprecated and will likely be removed in a future release.
The Name Server boot success. serializeType=JSON
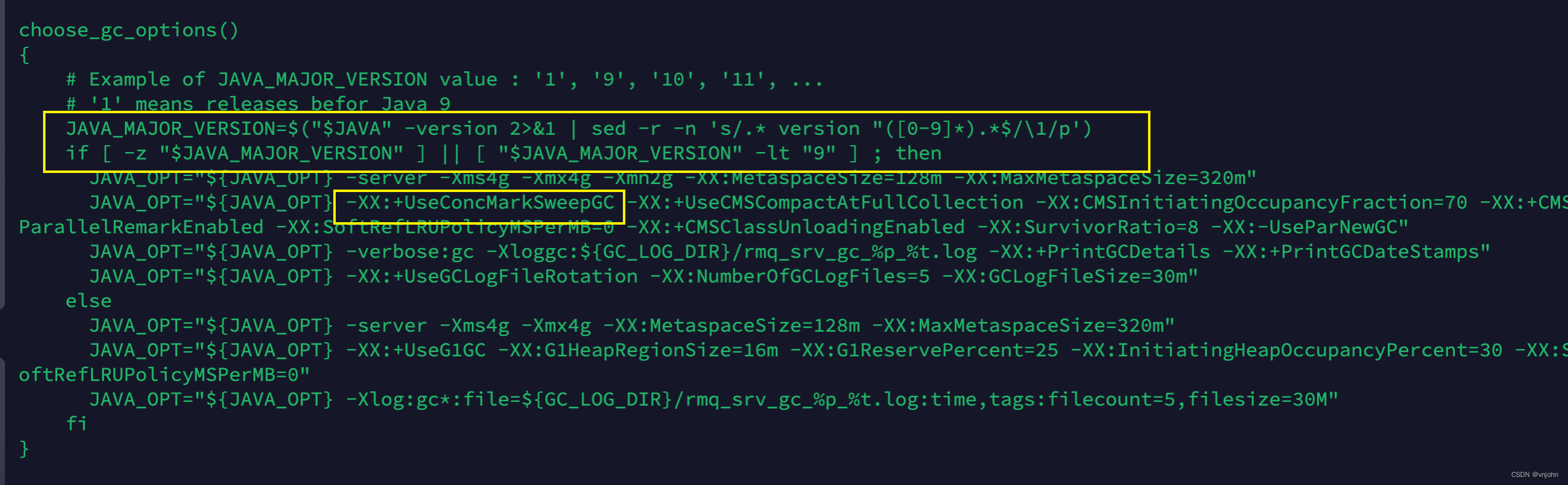
从输出的启动内容:The Name Server boot success. 可以看出名字服务器已经启动成功了
虽然 namesrv 启动成功了,但从输出的内容以及 bin/runserver.sh 脚本中,可以观察到,当 JDK 版本低于 9 时,它会使用 CMS 垃圾收集器,反之,会使用 G1 垃圾收集器,在这见证了我之前在讲解「优化内存利用:深入了解垃圾回收算法与回收器」文章时提到的点,UseCMSCompactAtFullCollection is deprecated and will likely be removed in a future release. 该提示告知我们 CMS 在 JDK 高版本 9 及以上会被移除掉
优化内存利用:深入了解垃圾回收算法与回收器
当然,若你想在 JDK8 中使用 G1 收集器启动 namesrv,只需要调整该 runserver.sh 脚本内容即可!
4、通过日志输出内容来验证名字服务器 namesrv 是否启动成功,观察:tail -f ~/logs/rocketmqlogs/namesrv.log 日志文件
在 namesrv.log 中看到’The Name Server boot success…',表示NameServer 已成功启动
5、启用 Broker:nohup sh bin/mqbroker -n localhost:9876 &
Broker 启动需要指定对应的 namesrv 是什么地址,localhost:9876 当前所在的 namesrv 地址信息,9876 是 namesrv 默认占有的端口
通过观察日志,发现 Broker 并未启动成功,观察 nohup.out 日志内容,发现错误信息如下:
Error: VM option 'UseG1GC' is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions. Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
告知我们在启用 G1 垃圾收集器,要开启 UnlockExperimentalVMOptions 参数 > 在 JDK8 版本中会出现该问题
既然知道原因了,那么就看在启动 broker 时是使用那个脚本即可
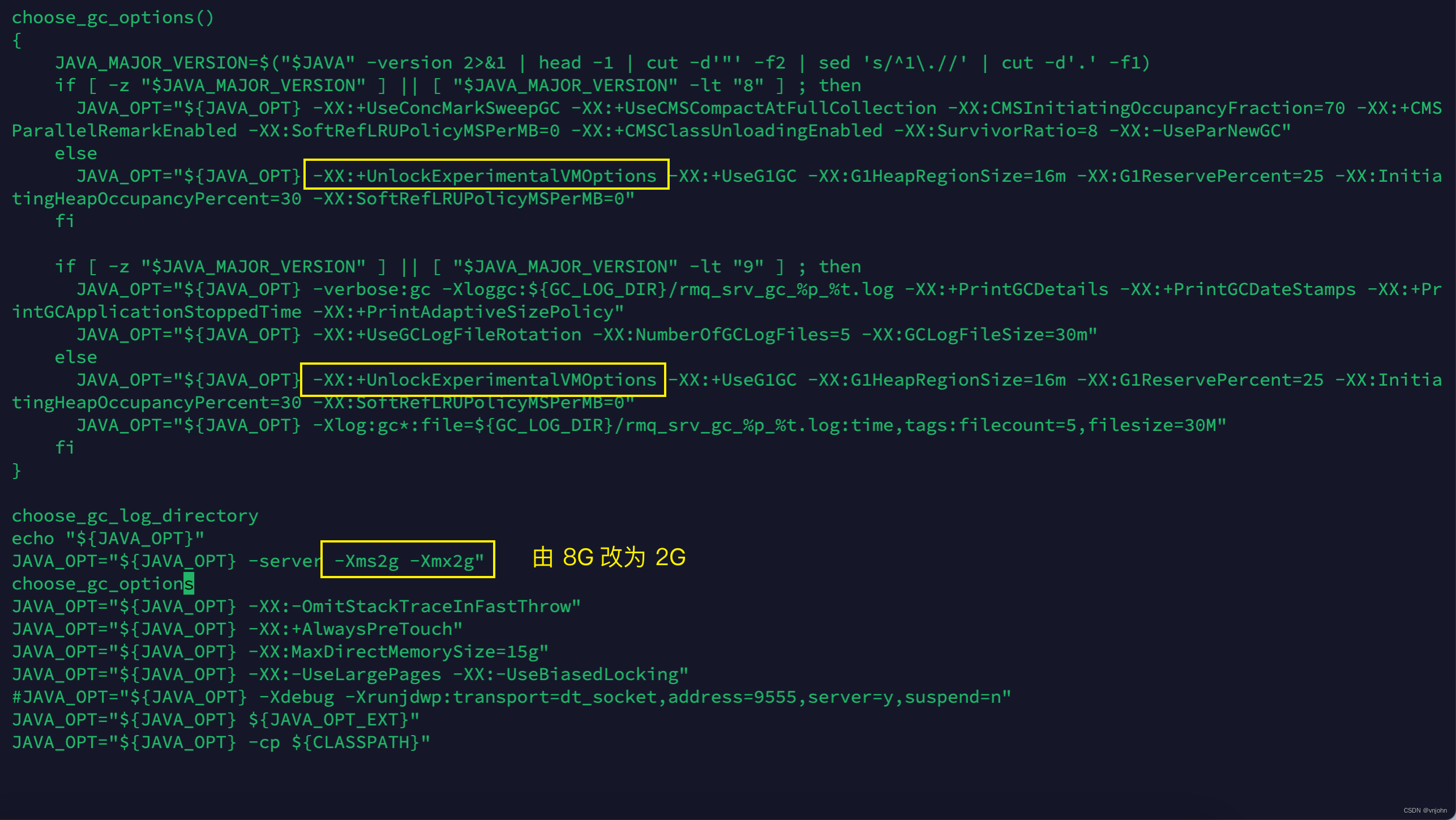
文件:bin/runserver.sh,修改内容如下图
1、追加参数 -XX:+UnlockExperimentalVMOptions 在 -XX:+UseG1GC 之前,不能放在其后面,不然会报同样的错误
2、调整最小堆最大堆内存大小,将 8G 调整为 2G,我所在的机器为 2核4G,无法为其分配 8G 内存,启动会报错:
error='Cannot allocate memory'
-XX:+UnlockExperimentalVMOptions:该参数的含义在于:解锁实验性参数,如果不加该标记,不会打印实验性参数
再次执行启动脚本:nohup sh bin/mqbroker -n localhost:9876 &,此时 broker 能正常使用
6、验证 broker 是否启动成功:tail -f ~/logs/rocketmqlogs/broker.log
The broker[node1, 172.16.249.10:10911] boot success. serializeType=JSON and name server is localhost:9876
此时可以在 broker.log 中看到 “The broker[brokerName,ip:port] boot success..”,这表明 broker 已成功启动
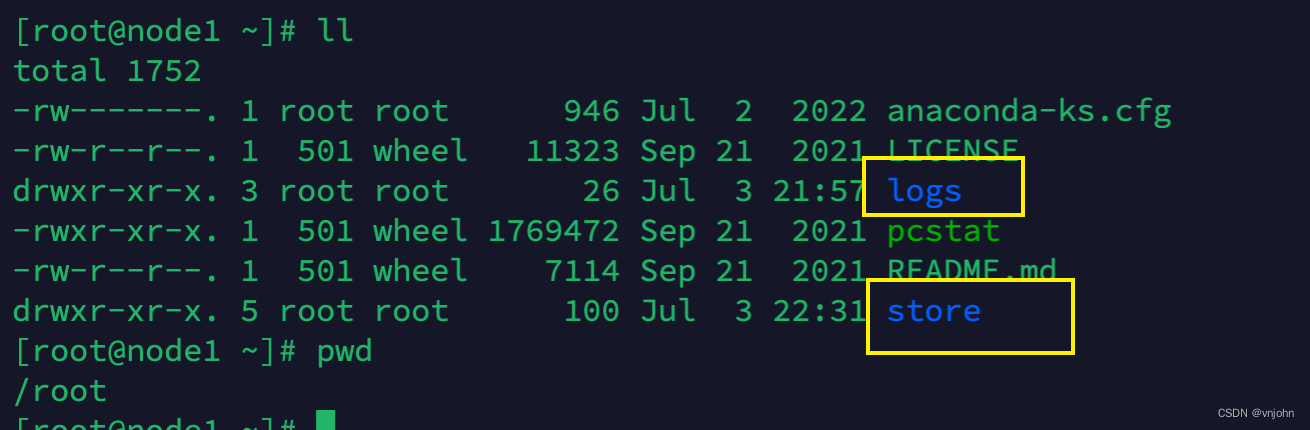
单节点搭建后默认日志、存储所在目录 > logs:日志目录、store:存储目录(commitlog,consumequeue,index)
搭建集群 RocketMQ
集群方式
搭建 RocketMQ 集群有几种方式,如下:
-
多 Master 模式:所有节点都是 master 主节点(2 或 3 个主节点)没有 slave 从节点的模式,该模式的优缺点如下:
优点:
1、配置简单
2、一个 master 节点的宕机或重启对应用程序没有影响
3、若消息是异步刷盘模式的情况下,会丢失少量消息;若消息是同步刷盘模式,不会丢失任何消息
4、在这种模式下,性能是最高的
缺点:
单台机器宕机时,该机器未被消费的消息,会直到机器恢复后才会订阅,会影响消息的实时性 -
多 Master 多 Slave 模式(异步复制):每个主节点搭配多个从节点,多对主从;HA 采用异步复制,主从节点之间会有消息延迟 > 毫秒级,该模式的优缺点如下:
优点:
1⃣️即使磁盘损坏,也只会丢失极少的消息,不会影响消息的实时性
2⃣️当主节点宕机时,消费者仍然可以消息从节点的消息,该过程对应用本身是透明的,不需要人为干预
3⃣️性能几乎与多 Master 模式一样高
缺点:主节点宕机、磁盘损坏时,会丢失少量的消息
-
多 Master 多 Slave 模式(同步双写):每个主节点配置多个从节点,多对主从;HA 采用同步双写,即只有消息成功写入到主节点并复制到多个从节点后,才会返回 OK 响应给应用程序,该模式的优缺点如下:
优点:
1⃣️数据、服务都没有单点故障
2⃣️在 Master 主节点关闭的情况下,消息也不会延迟
3⃣️服务可用性和数据可用性非常高
缺点:
1⃣️该模式下的性能低于异步复制模式(大约低 10%)
2⃣️发送单条消息的 RT 略高,目前 4.x 版本在 Master 节点宕机后,Slave 节点无法自动切换为 Master,
RocketMQ 5.0 开始支持自动主从切换的模式
准备工作
首先,准备四台虚拟机节点,搭建 2 主 2 从,采用「多 Master 多 Slave 模式(异步复制)」方式搭建集群
172.16.249.10 node1
172.16.249.11 node2
172.16.249.12 node3
172.16.249.13 node4
同时将每台机器上的 /etc/hosts 文件,追加以上内容
node1~node3:作为 Name Server 名字服务器
node1~node4:作为 Broker Server,node1~node2 作为 broke-a 主、从,node3~node4 作为 broker-b 主、从
存储目录规划
一般我们的数据都是存储在 Linux /var 目录中,以下来规划 RocketMQ 配置文件存储的目录:
store path 存储文件路径、logs path 日志文件路径
来通过以下命令来统一创建:
# 创建:/var/rocketmq/logs、/var/rocketmq/store 目录
# 创建:/var/rocketmq/store/commitlog、/var/rocketmq/store/index、/var/rocketmq/store/consumequeue 子目录
mkdir -p /var/rocketmq/{logs,store/{commitlog,index,consumequeue}}
配置文件调整
[root@node1 conf]# pwd
/opt/rocketmq-4.9.3/conf
[root@node1 conf]# vi broker.conf
跳转到 conf 目录下,调整或更新内容,如下:
brokerClusterName = DefaultCluster
# 主从名称要保持一致
brokerName = broker-a
# Master:0、Slave > 0
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
# 同步双写:SYNC_MASTER、异步复制:ASYNC_MASTER、SLAVE
brokerRole = ASYNC_MASTER
# 通过异步刷写方式来降低机器的磁盘 IO 瓶颈
flushDiskType = ASYNC_FLUSH
# node1~node3 namesrv 配置
namesrvAddr=172.16.249.10:9876;172.16.249.11:9876;172.16.249.12:9876
storePathRootDir=/var/rocketmq/store
storePathCommitLog=/var/rocketmq/store/commitlog
storePathIndex=/var/rocketmq/store/index
storePathConsumeQueue=/var/rocketmq/store/consumequeue
brokerName:node1、node2 改为 broker-a,node3、node4 改为 broker-b
brokerId:node1=0、node2=1、node3=0、node4=1
brokerRole:node1、node3 改为 ASYNC_MASTER,node2、node4 改为 SLAVE
更新所有 xml 配置文件的 RocketMQ 存储、日志根路径,可以通过 sed 命令统一修改,无须一个个文件去调整,如下:
# 将所有 ${user.home} 内容修改为 /var/rocketmq
sed -i 's#${user.home}#/var/rocketmq#g' *.xml
vim runbroker.sh 文件,调整 JAVA_OPT 参数内容,如下:
# 默认占用为 8G
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g"
集群节点同步>更新配置
当 node1~node4 可以复用于同样的配置内容时(只需要调整少量的配置)可以通过 scp 命令向其他服务节点进行文件传输,但每次传输时可能需要输入要传输节点的登录用户名、密码,所以为了方便,可以采用以下的方式生成 RSA 对称密钥.
在 node1 通过命令:ssh-keygen -t rsa 生成 RSA 对称密钥对,执行完生成内容大致如下:
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:qGADw4O+YYyVilyoUddL2yAMhwFJ0brRPO7skDB6KUY root@node1
The key's randomart image is:
+---[RSA 2048]----+
|o=*=o. |
|+.o=o + |
|=+*. o = |
|BOo+ o.. |
|BEB . . S |
|=++= . |
|o== . |
|.o.o |
| .. |
+----[SHA256]-----+
将 node1 生成的公共密钥:id_rsa.pub 内容,追加到 node2~node4 /root/.ssh 目录的 authorized_keys 文件中,如下:
# 无目录或无文件则新建
mkdir /root/.sshecho 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDM3UaJlfVy6ha7279aRWD5N+ZNzrBpDVOIueCL5GIPhj1pIK6r1q2O1uwtvCqiDlLK9pM4eTR7R53Xt7+XqqH1FmqRx1Q7HnEQLvOxZrDMdqNhiZE8/hnC0NkWZxJRfnUhkARXNQpE4sjF6UMHWsgehbEWxZ+12KwkO3r/q/iO2yKnlvmFKo3SUksoIZSfARdHBoPDLBCm5ml/OZ2IwwXc8xxz6lz3UgksjogYp3Wca9jQ5tF73qTI9UdOLsNETRWiZHwCMu0gSQYpk2TFQBX8AfeEQxNmZuhZ6W2mOzyonZUeSTMuLVOmJ28zqti1TxxUDRmB/1NVNR+eSt/RJ6JJ root@node1'
>> /root/.ssh/authorized_keys
如此,在执行 scp 命令时,不再每次都需要输入密码远程传输文件了
node1:cd /optscp -r ./rocketmq-4.9.3/ node02:/opt
scp -r ./rocketmq-4.9.3/ node03:/opt
scp -r ./rocketmq-4.9.3/ node04:/opt
启动集群
1、跳转 RocketMQ 根目录:cd /opt/rocketmq-4.9.3
2、启动 namesrv:nohup sh /opt/rocketmq-4.9.3/bin/mqnamesrv &
3、启动 broker:nohup sh /opt/rocketmq-4.9.3/bin/mqbroker -c /opt/rocketmq-4.9.3/conf/broker.conf > /dev/null 2>&1 &
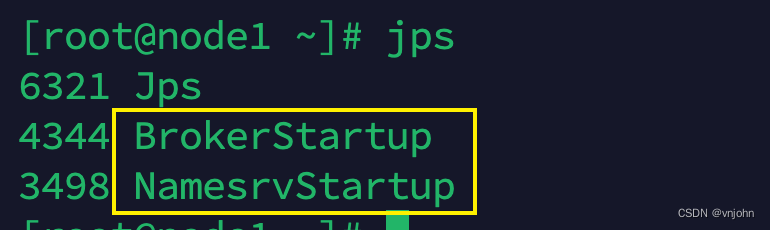
可以通过 jps 命令观察是否启动成功,若未出现以下内容时,可以观察对应的日志进行排查,错误应该会类比于我在「搭建单节点 RocketMQ」 所报出的错误
RocketMQ 控制台
在本篇文章,先介绍 RocketMQ 中一些核心的术语,方便后续在操作 RocketMQ 时能够快速理解
在这里,为了方便大家在业务系统中操作生产消息、消费消息、消费的进度,不用每次都通过命令的方式去查询,在这里,特意输出一下如何搭建一个 RocketMQ Dashboard 控制台能够实时观察进度,下面让我们来看如何在服务器上搭建好 Dashboard
首先,对于 RocketMQ 爱好者,在 GitHub 提供了可编译执行的项目,只需要调整少量的配置,然后打包部署到服务器上,可直接访问查看集群、Topic、消费者等信息
1、GitHub 下载可编译执行包:https://github.com/apache/rocketmq-dashboard/tree/master
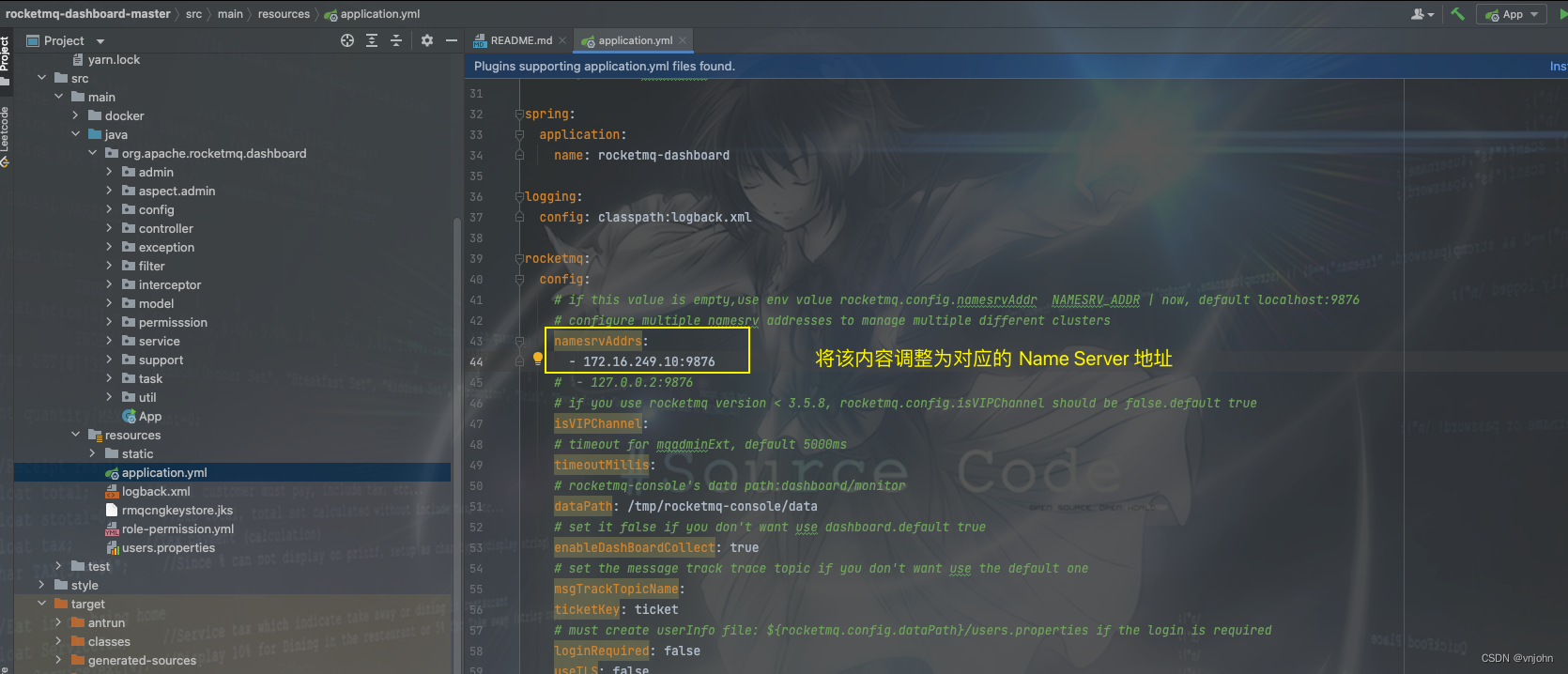
2、将代码 clone 下来,使用本地 IDE 工具打开,使用阿里云镜像 maven 加速编译好以后,调整 application.yml 相关的配置:
rocketmq:config:# if this value is empty,use env value rocketmq.config.namesrvAddr NAMESRV_ADDR | now, default localhost:9876# configure multiple namesrv addresses to manage multiple different clustersnamesrvAddrs:- 172.16.249.10:9876
3、执行打包命令:
# 代码在 IDE 编译完成以后,打包生成 jar 文件
mvn clean package -Dmaven.test.skip=true
4、部署 jar 包,命令如下:
# 将 jar 文件上传到 node4 节点上,通过以下命令启动好 jar 包
nohup java -jar rocketmq-dashboard-1.0.1-SNAPSHOT.jar /dev/null 2&>1 &
5、启动成功以后,访问 IP:PORT,跳转 Dashboard,访问地址:http://172.16.249.13:8080/#/
Dashboard 端口号可更改,默认配置的端口号为 8080
6、最后,查看 RocketMQ 集群是否已搭建好,如下图:
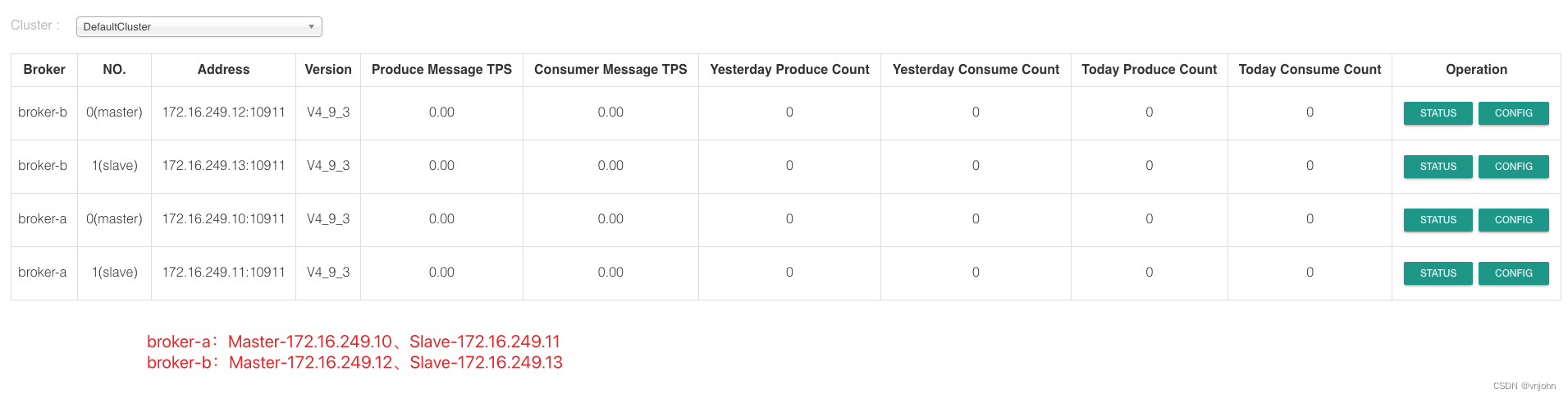
总结
该篇博文初介绍了 RocketMQ 「一个开源的、高吞吐量、低延迟的消息队列系统」它的一些基础的概念信息「消息模型、消息生产者、消息消费者、主题、代理服务器、名字服务器、消费模式:拉取、推送、消息、标签等」简要概述了 Kafka vs RocketMQ 之间的区别以及它们之间的巧妙结合,最后,作为开篇,环境是演示所有操作的前提,故总结了搭建 RocketMQ 单节点、集群节点的详细步骤,在 Linux 环境上可以直接服用此过程
RocketMQ 官方文档
RocketMQ 开发者指南
RocketMQ 4.9.x 部署架构、设置步骤
当然,可以通过官方提供的这些文章,自行学习,自我学习才是成长更快的一条路
🌟🌟🌟愿你我都能够在寒冬中相互取暖,互相成长,只有不断积累、沉淀自己,后面有机会自然就会破冰而行!
博文放在 RocketMQ 专栏里,欢迎订阅,会持续更新!
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
推荐专栏:Spring、MySQL,订阅一波不再迷路
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!