进化
前些日子,有人发了这样一张图,揶揄现在的 AI 检测器。说是「魔法战胜了魔法」。
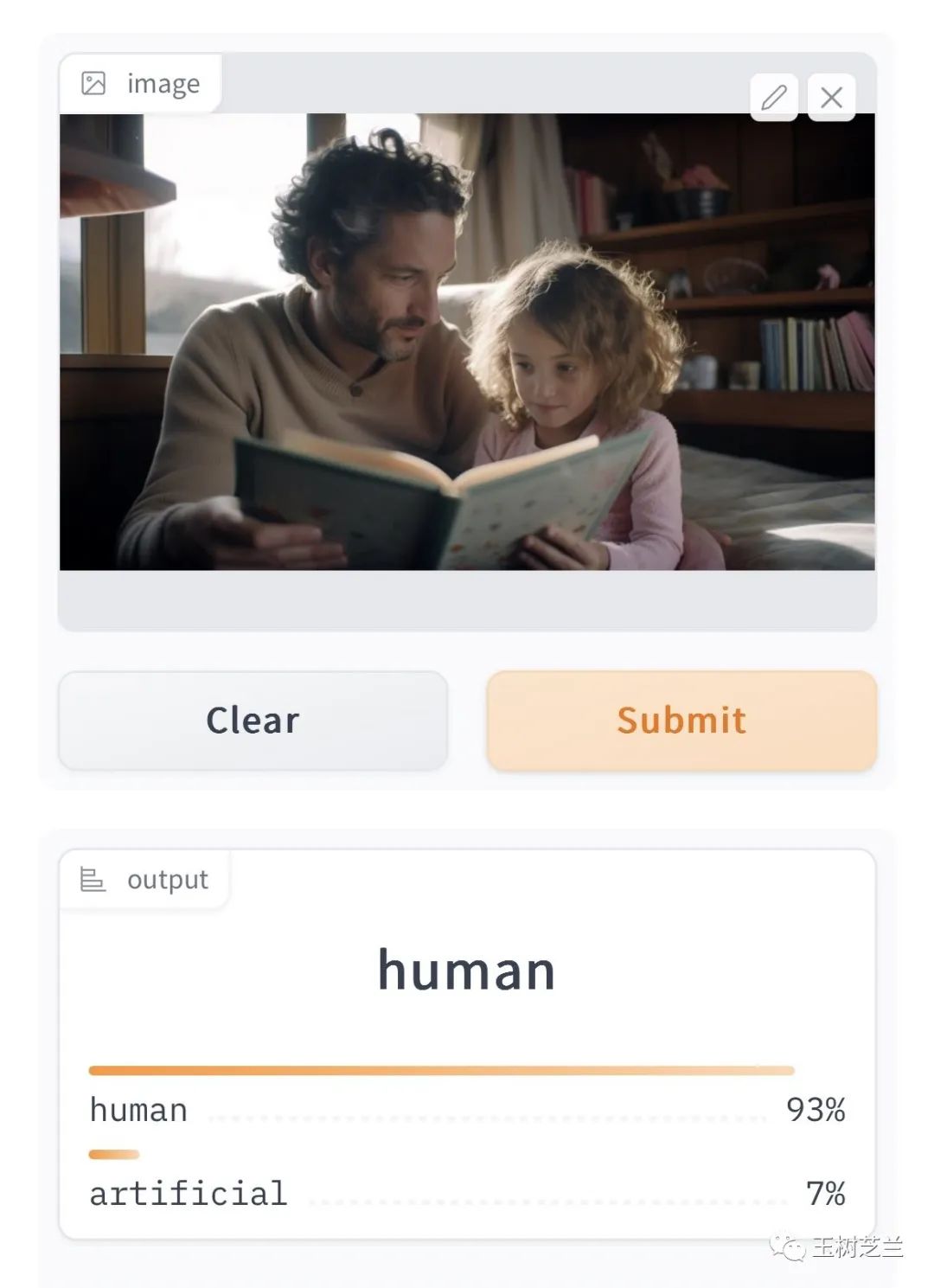
这张图,是用 AI 生成的。但是 AI 检测器显然没有发现。在它看来,这张图片「天然成分」有93%;人工智能生成的可能性,只有7%。
这是个错误的判断,但是我们也不要因此嘲笑 AI 。毕竟你第一眼看到这张图片时,真的能分辨出这是 AI 画出来的吗?
当然了,要控制 AI 绘图结果,还是有一定门槛的。要不然也不会有 prompt (提示语)交易市场 的存在。
一个好的提示语可以卖出很多份,每份也够一顿午餐的钱。所以,这个职业,确实也给不少人提供了赚钱的机会。

然而,就在今天,情况陡然发生了变化。Midjourney 又一次进化,支持了一个新的功能,叫做 /describe 。
这个新功能一经发布,一石激起千层浪。AI 绘画领域的爱好者们立即展开了尝试,随后就是声浪巨大的讨论。
这功能是干啥用的?
简单来说,你给 Midjourney 一幅画,它立即把对应的 prompt 给你写出来。这样一来,你可以用 prompt 绘制类似的图片,或者依照自己的意思,对图片中的元素进行微调。
常言道「光说不练假把式」,我这就给你做个测试。
尝试
我从网上搜来了一张爱因斯坦的照片,不是很清晰。

(图片来源:网址)
然后我就把这张照片丢进了 Midjourney 的 /describe 功能界面。
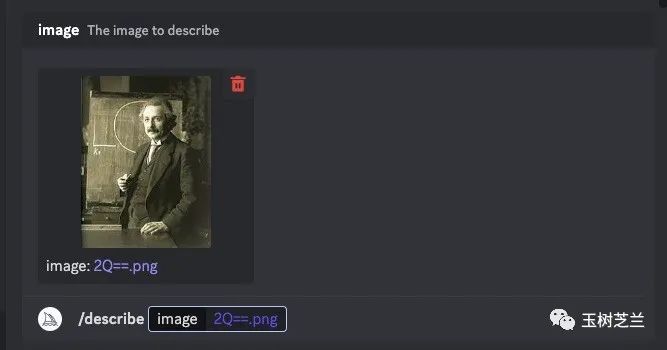
很快,Midjourney 的 prompt 就生成完毕了。有 4 个备选方案。
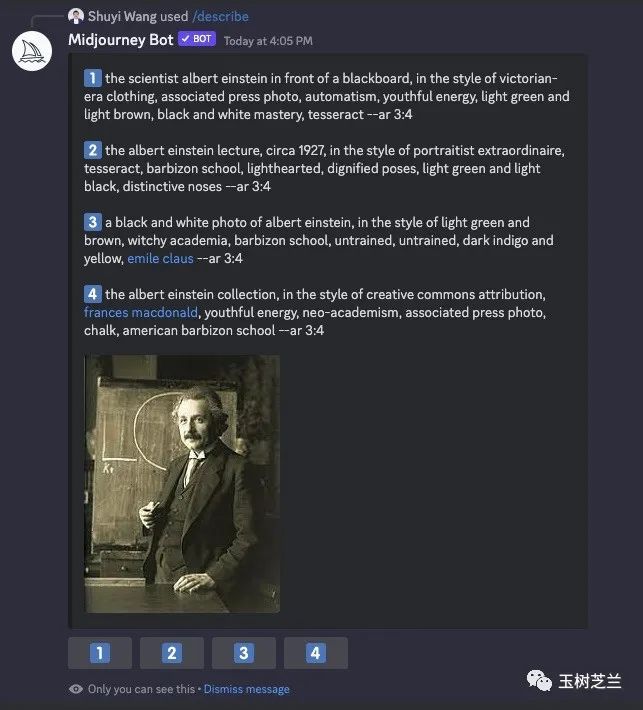
提示语列表是这样的:
the scientist albert einstein in front of a blackboard, in the style of victorian-era clothing, associated press photo, automatism, youthful energy, light green and light brown, black and white mastery, tesseract --ar 3:4 (阿尔伯特·爱因斯坦科学家站在黑板前,穿着维多利亚时代的服装,与自动主义、青春活力、浅绿色和浅棕色、黑白精通以及四维超立方体相关。这是一张美联社的照片,画面比例为3:4。)
the albert einstein lecture, circa 1927, in the style of portraitist extraordinaire, tesseract, barbizon school, lighthearted, dignified poses, light green and light black, distinctive noses --ar 3:4 (阿尔伯特·爱因斯坦的演讲,大约在1927年,以肖像画家特瑟拉克、巴比松学派、轻松庄重的姿势、浅绿色和淡黑色为风格,鼻子突出--AR 3:4。)
a black and white photo of albert einstein, in the style of light green and brown, witchy academia, barbizon school, untrained, untrained, dark indigo and yellow, emile claus --ar 3:4 (一张阿尔伯特·爱因斯坦的黑白照片,风格为浅绿色和棕色的巫术学院、巴比松派、未受过训练的暗靛蓝和黄色,埃米尔·克劳斯--ar 3:4。)
the albert einstein collection, in the style of creative commons attribution, frances macdonald, youthful energy, neo-academism, associated press photo, chalk, american barbizon school --ar 3:4 (阿尔伯特·爱因斯坦收藏,采用创意共享署名风格,弗朗西丝·麦克唐纳,青春活力,新学院主义,美联社照片,粉笔画,美国巴比松学派--ar 3:4)
我想你已经猜到了,上面提示语里的中文,也是 ChatGPT 翻译出来的。
看看这些详细到琐碎风格描述,如果没有 Midjourney 的描述,我这个艺术门外汉不可能会形容的。
上面图片下方有 4 个选项,分别对应不同的提示语。
咱们先试试第一个好了。这是绘制的结果:
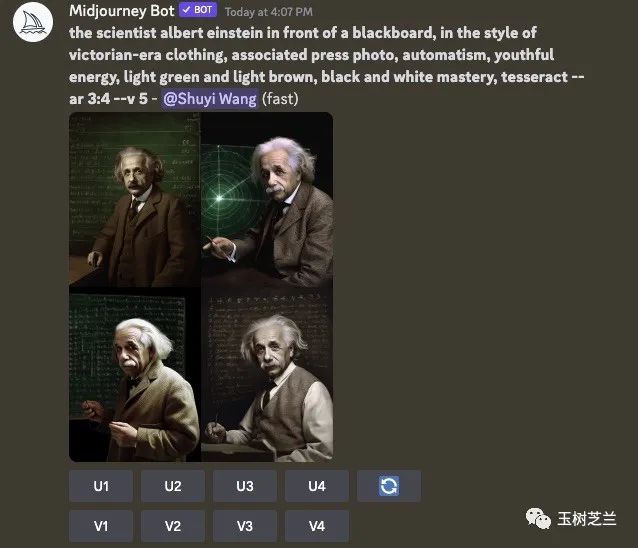
虽然跟原作比起来有不小的差异,但是爱因斯坦的辨识度没问题,对吧?而且你看下面的大图,照片也清晰多了。
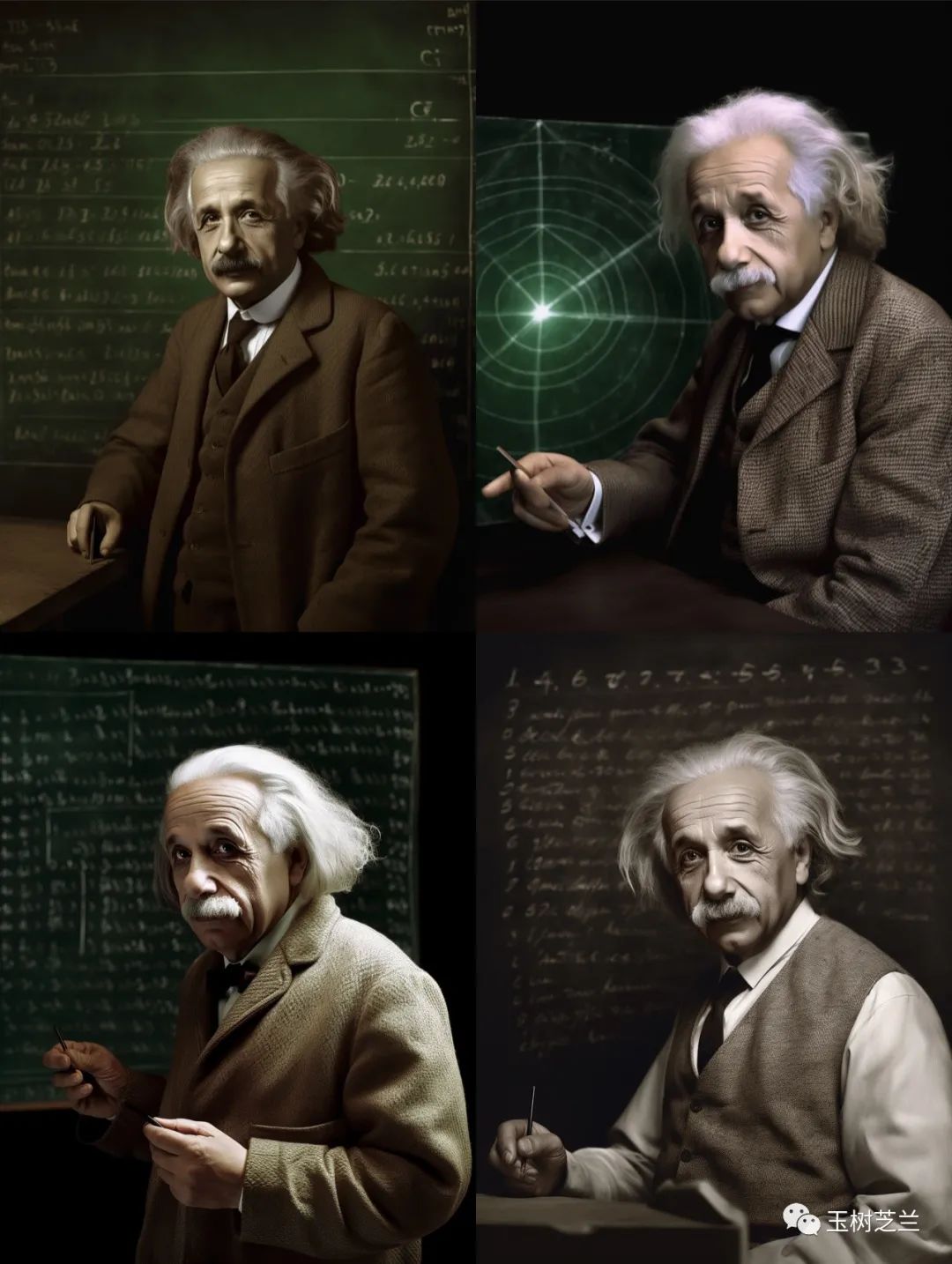
这是第二组,辨识度依然非常高。只是背景被消除了。
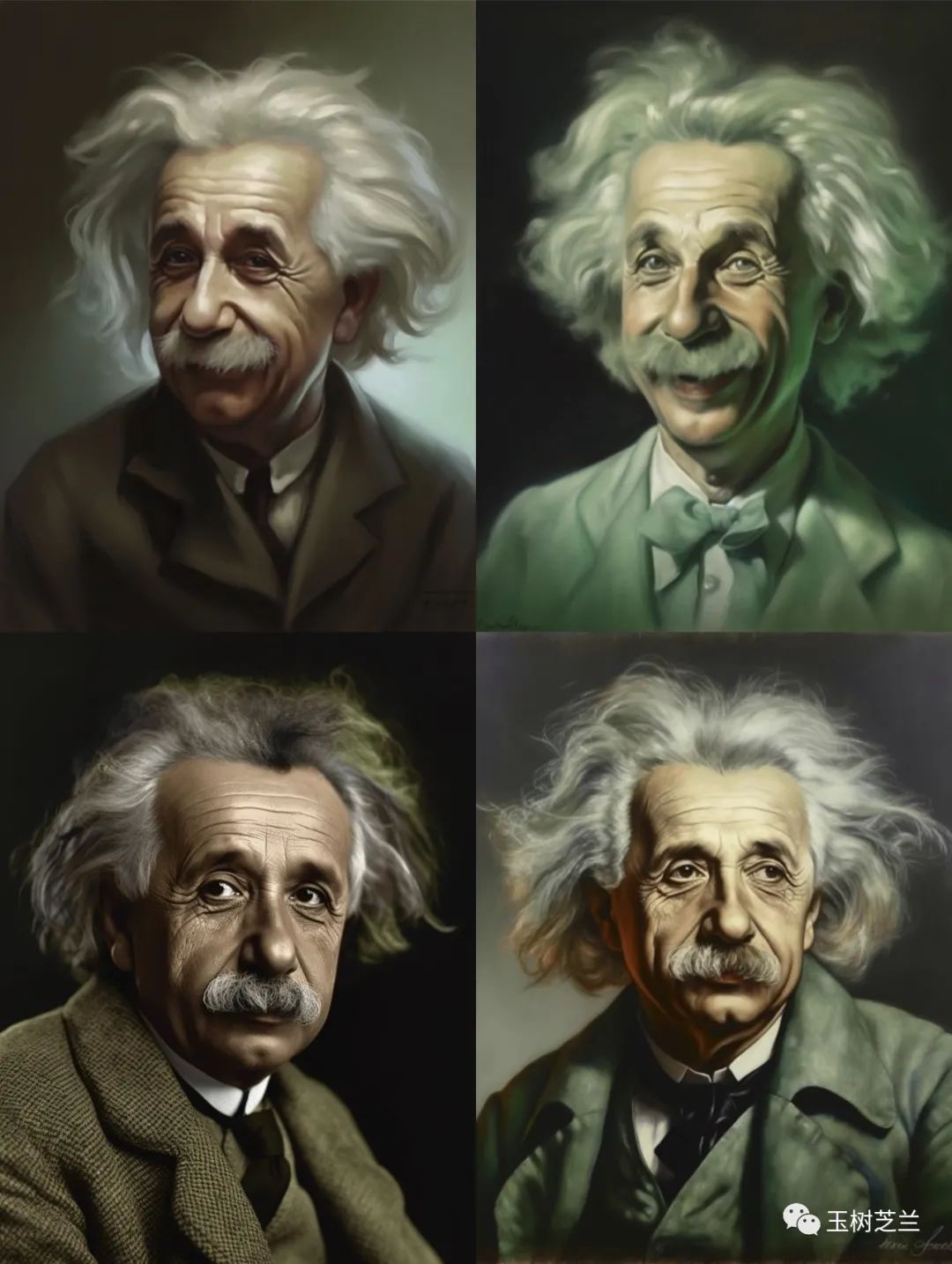
下面是第三组,场景更换了。

我更喜欢其中的第三张,真的好像一张老照片的样子。我说不出来哪儿好,但就是觉得「顺眼」,哈哈。
下面这 4 张,就颇为「艺术」了,我没有相关知识储备,就不予置评了。

总体而言,你觉得画得如何?
我在朋友圈里看到不少人惊叹,说以后付费图库生意恐怕不会像从前那么红火了。
但是,这还只是问题的一部分。很自然就有人继续联想 —— 既然有了 prompt ,那么就有了快速微调的可能。调整图片改变意思,门槛非常低。
例如我拿出来了第一个备选 prompt ,然后恶作剧一般加上了三个单词 holding an iPhone,提示语成了这样:
the scientist albert einstein in front of a blackboard holding an iPhone, in the style of victorian-era clothing, associated press photo, automatism, youthful energy, light green and light brown, black and white mastery, tesseract --ar 3:4 --v 5(阿尔伯特・爱因斯坦科学家站在黑板前,手持 iPhone,穿着维多利亚时代的服装风格,与自动写作、青春活力、浅绿色和浅棕色、黑白掌握以及四维超立方体相联系 --AR 3:4。)
而画出来的图片,就成了这个样子:

我觉得图 1 最为自然,你觉得呢?
这还不算完,下面咱们尝试使用第二组 prompt,只不过我又加了几个词,这次我不说,你自己找:
the albert einstein lecture, holding a cat, circa 1927, in the style of portraitist extraordinaire, tesseract, barbizon school, lighthearted, dignified poses, light green and light black, distinctive noses --ar 3:4 --v 5 (阿尔伯特・爱因斯坦在 1927 年左右拿着一只猫做演讲,风格类似于画家 Tesseract 的巴比松学派作品,姿态轻松庄重,颜色为浅绿和浅黑,鼻子很有特点。--ar 3:4 --v 5)
画出来就这样了:

你喜欢其中哪一张?
有人迅速脑补了这种方案的应用场景,然后说以后照片都信不得了。随便加点儿内容,虚假信息就「有图有真相」了。
你觉得真有那么严重吗?
进一步测试
咱们不能凭空臆断,还是做个尝试吧。
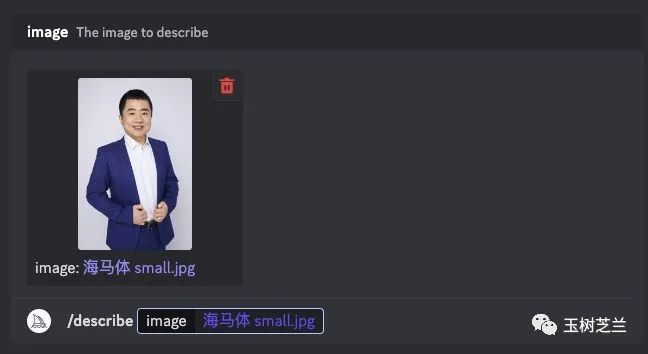
拿别人举例子似有不妥,还是用我自己的照片好了。
我把自己的标准照扔了进去。
很快,Midjourney 反馈给我以下的候选 prompt 。
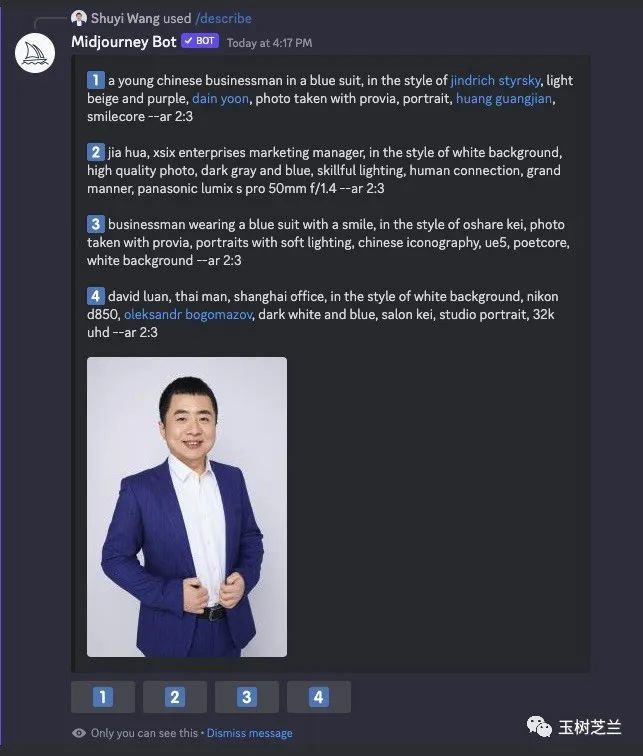
a young chinese businessman in a blue suit, in the style of jindrich styrsky, light beige and purple, dain yoon, photo taken with provia, portrait, huang guangjian, smilecore --ar 2:3(一位年轻的中国商人穿着蓝色西装,风格类似于金德里希·斯特尔斯基(Jindrich Styrsky),衣服颜色为浅米色和紫色,照片使用Provia拍摄,是一张肖像照片。他名叫黄光健,面容微笑。--ar 2:3)
jia hua, xsix enterprises marketing manager, in the style of white background, high quality photo, dark gray and blue, skillful lighting, human connection, grand manner, panasonic lumix s pro 50mm f/1.4 --ar 2:3(嘉华,XSIX企业市场经理,在白色背景、高质量照片、深灰和蓝色风格下,技巧娴熟的光线处理,人性化连接,大气的方式展现了松下Lumix S Pro 50mm f/1.4 --ar 2:3。)
businessman wearing a blue suit with a smile, in the style of oshare kei, photo taken with provia, portraits with soft lighting, chinese iconography, ue5, poetcore, white background --ar 2:3(穿着蓝色西装微笑的商人,风格为oshare kei,使用provia拍摄的照片,柔和的灯光下的肖像,中国图案设计元素、ue5、诗人核心主题,在白色背景下--宽高比2:3。)
david luan, thai man, shanghai office, in the style of white background, nikon d850, oleksandr bogomazov, dark white and blue, salon kei, studio portrait, 32k uhd --ar 2:3(大卫·鸾,泰国人,在上海办公室工作,以白色背景为风格,使用尼康D850相机拍摄,奥列克桑德尔·博戈马佐夫(Oleksandr Bogomazov)的黑白和蓝色调,Salon Kei(沙龙Kei)的工作室肖像照片。32K UHD--AR 2:3。)
这几条提示语,真的把我给看乐了 —— 为啥还要坚持给我起个不认识的名字啊?而且,我哪里像泰国人了?
算了,不管它,开始画就好。这是第一张的绘图过程记录。
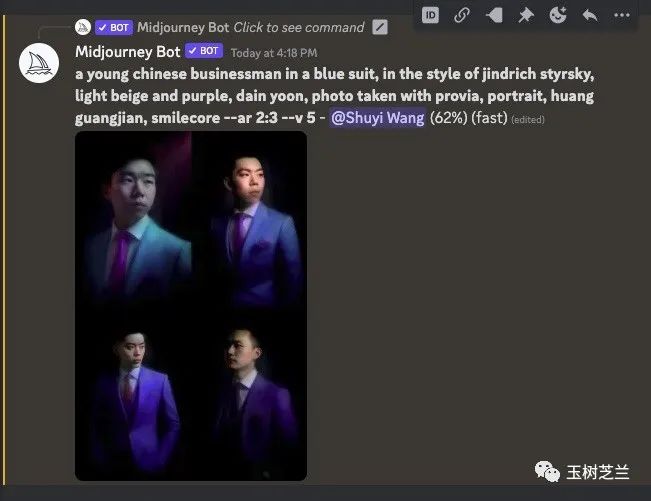
这是绘制的结果:

小伙儿挺帅啊,可惜不像我啊!😂
这是第三组:

怎么看,怎么觉得第二张眼熟,好像在哪儿见过啊。
第四组:

看来,似乎 Midjourney 真的把我画成了泰国人。
你问我第二组哪儿去了?
别着急,在这儿呢:

这姑娘挺漂亮的。可是这「图片到 prompt 再到图片」的还原度,也太离谱了吧!
虽然画的人物就没有一个像我的,但是 prompt 里面似乎确实把握了「肖像照」的精髓。是吧?
那么,有没有可能利用「肖像照」的场景设定,再把人物画得更加相似一些呢?我于是又展开了进一步的尝试。
混合
这一步尝试的方法,是借用《如何用 Midjourney 绘制你自己的皮克斯风格头像?》这篇文章里给你展示过的方法,把原始图片链接加入到提示语中,并且加大原始图片的权重。
我觉得上面第三组提示语效果更符合预期,于是就用它来改造。在提示语的最前面,我加上了原始图片链接,然后加上了 --iw 1.5 参数,以提升原始图片权重。
https://media.discordapp.net/ephemeral-attachments/1092492867185950852/1092724565811146822/small.jpg?width=406&height=610 businessman wearing a blue suit with a smile, in the style of oshare kei, photo taken with provia, portraits with soft lighting, chinese iconography, ue5, poetcore, white background --ar 2:3 --iw 1.5
这是绘制的结果:

我觉得,除了不像自己以外,没啥大毛病。于是我决定继续加大原始图片权重,把上面提示语中的 --iw 1.5 替换成 --iw 2 ,这已经是最大取值了。
https://media.discordapp.net/ephemeral-attachments/1092492867185950852/1092724565811146822/small.jpg?width=406&height=610 businessman wearing a blue suit with a smile, in the style of oshare kei, photo taken with provia, portraits with soft lighting, chinese iconography, ue5, poetcore, white background --ar 2:3 --iw 2
这次绘制的结果,是这样的:

看着都挺眼熟,只是…… 不像我啊。
你觉得呢?
到这里,我会不会很失望呢?不,我稍稍放心了。
至少在近期,要想拿我这样普通人的照片加以修改,还让别人看不出来,门槛足够高。
当然,这样的阶段能维持多久?我没有任何信心。
讨论
看到这里,你可能会有个疑惑:
为什么爱因斯坦的原始照片这么不清楚,绘制出来却怎么都像;我用了自己的清晰标准照片,一个劲儿尝试增大原画权重,却怎么都画不像呢?
其实从 Midjourney 自动生成的 prompt 里面,你不难看到一些端倪。回顾一下,这是爱因斯坦的:
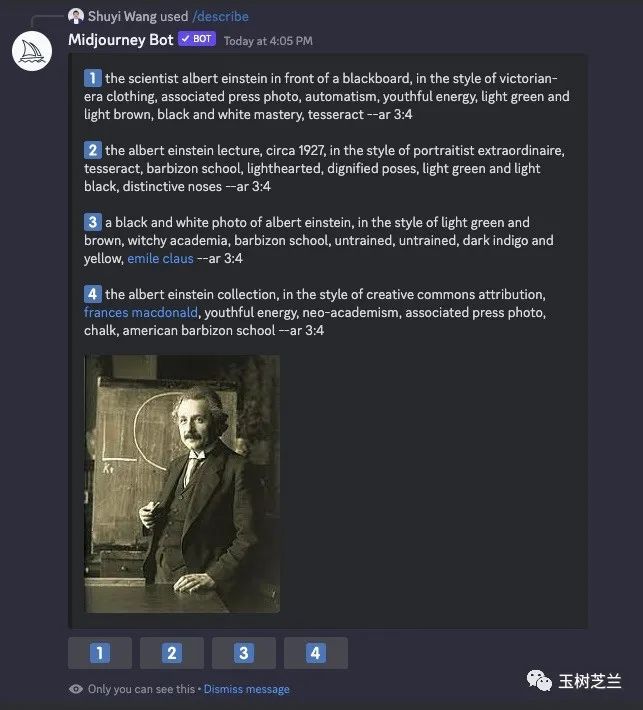
这是我的:
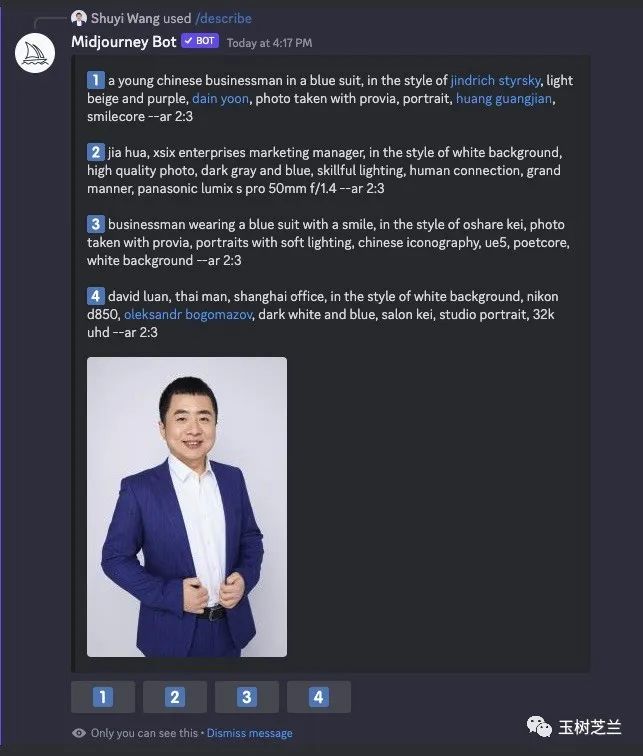
两相对比,你不难发现,爱因斯坦的名字,Midjourney 给出提示语中是自动识别的。而我呢?Midjourney 发现,这家伙是个 nobody ,随便给他起个名字好了,嘉华或者大卫・鸾叫啥都成(估计就相当于「石头」和「狗剩儿」),甚至有的条目干脆连名字都懒得起了。
这个差别看似不起眼,但是很能说明问题。因为许多图片领域的大模型,训练时都使用了一个 58.5 亿张的图片文本对应数据集,叫做 LAION-5B。

这图片数据里,什么种类都有。爱因斯坦在里面出现过,所以模型对他老人家记忆深刻,一个名字就能唤起。当然,还有很多名人,甚至是如今的体育明星,Midjourney 也都熟悉。
所以,你知道现在谁最担心 Midjourney 搞怪了吧?
反正不是嘉华或者大卫・鸾。你说是吧?
小结
这篇文章,我给你介绍了 Midjourney 新功能 —— 用图片自动生成提示语,然后绘制或微调类似图形。通过咱们演示的实验步骤,你应该已经观察到了它的能力和不足。你是不是已跃跃欲试了?
如果你能把自己的标准照用 Midjourney 绘制得惟妙惟肖,欢迎把提示语和技巧分享给大伙儿。AI 快速发展的当下,咱们一起学习进步。
点赞 +「在看」,转发给你身边有需要的朋友。收不到推送?那是因为你只订阅,却没有加星标。
欢迎订阅我的小报童付费专栏,每季度更新不少于10篇文章。目前价格优惠。

如果有问题咨询,或者希望加入社群和热爱钻研的小伙伴们一起讨论,订阅知识星球吧。不仅包括小报童的推送内容,还可以自由发帖与提问。之前已经积累下的帖子和问答,就有数百篇。足够你好好翻一阵子。

若文中部分链接可能无法正常显示与跳转,可能是因为微信公众平台的外链限制。如需访问,请点击文末「阅读原文」链接,查看链接齐备的版本。
延伸阅读
AI 帮我找卡片挺好,但能不能帮我创作出新的相关卡片啊?
摸索那么多工具后,怎样才能避免「效率成瘾」?
世界很大,英语不好的你如何去看看?
自己录制和剪辑视频,如何解决占用空间过大的问题?
想打造个性化高效工作流,可不会编程怎么办?