目录
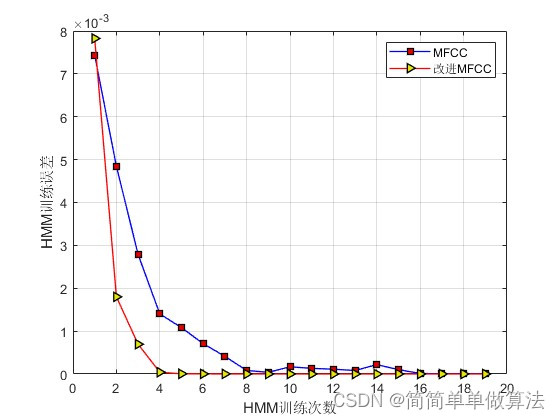
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
5.算法完整程序工程
1.算法运行效果图预览

2.算法运行软件版本
matlab2022A
3.部分核心程序
............................................................................
%hmm是已经建立好的声学模型库
load hmm.mat
for i=1:length(samples) isample=[];for k=1:length(samples{i})sample(k).wave=samples{i}{k};sample(k).data=[];[cepstra,aspectrum,pspectrum]= melfcc(sample(k).wave,Fs);mfcc_data{i}{k} = cepstra;end%训练后的声学模型库[hmm2{i},pout,tmp1,tmp2] = train(sample,Fs,[3 3 3 3]);
end
save R.mat hmm2 mfcc_data Fs
end%设置text
Text = ['1 1 1 1 1 0'];load R.mat
tic;
%%
%上下文相关HMM序列决策
indx = 0;
for i = 1:length(Text)if Text(i)==' 'elseindx = indx+1; data{indx} = [Text(i)]; end
enddatalist2=load('samples\datalist.txt');
flag = 1;
%调用模型和参数
for i = 1:length(data)indxx = find(datalist2 == str2num(data{i})); if isempty(indxx) == 1msgbox('未找到库中语料,无法合成'); flag = 0;endHmmused{i} = hmm2{indxx};%对应的语音参数Mfccused{i}= mfcc_data{indxx}{1};
end
.................................................................
y=y/max(y);
toc;
%最终滤波
figure;
subplot(211)
plot(y)
xlim([1,length(y)]);
subplot(212)
specgram(y,512,Fs); sound(y,Fs);
%保存合成后的声音wav文件
audiowrite('new.wav',y,Fs);
03_022m 4.算法理论概述
语音合成是计算机生成自然人类语音的过程,广泛应用于语音助手、语音导航、无障碍通信等领域。基于Mel频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)特征提取和隐马尔可夫模型(Hidden Markov Model,HMM)的语音合成算法,是一种有效的语音合成方法。本文将从数学公式、实现过程和应用领域三个方面详细介绍基于MFCC特征提取和HMM模型的语音合成算法。
理论:
-
MFCC特征提取: MFCC是一种用于语音和音频信号分析的特征提取方法,主要包括以下步骤:
a. 预加重: 对语音信号进行预处理,通过高通滤波器突出高频部分。
b. 分帧: 将语音信号分成短帧,通常每帧20-40毫秒。
c. 傅里叶变换: 对每帧语音信号进行傅里叶变换,将时域信号转换为频域信号。
d. Mel滤波器组: 将频谱图映射到Mel频率刻度上,使用一组Mel滤波器进行滤波。
e. 对数运算: 对Mel滤波器组输出取对数,得到对数Mel频率谱。
f. 离散余弦变换: 对对数Mel频率谱进行离散余弦变换,得到MFCC系数。
-
隐马尔可夫模型(HMM): HMM是一种用于建模时间序列数据的概率模型,用于描述观测序列与隐藏状态序列之间的关系。在语音合成中,HMM用于建模语音信号的时序特性,包括音素的时长和转换。
a. 状态集合: HMM模型包含多个隐藏状态,每个状态代表一个音素或声音单元。
b. 状态转移概率: 定义隐藏状态之间的转移概率,表示从一个状态转移到另一个状态的概率。
c. 观测概率: 定义每个状态生成观测符号(MFCC特征)的概率分布。
d. 初始状态概率: 定义初始时刻各隐藏状态的概率。
实现过程:
-
MFCC特征提取: 对输入的语音信号进行MFCC特征提取,得到每帧的MFCC系数作为输入特征。
-
HMM模型训练: 使用训练数据集,根据已知的音素标签,训练HMM模型的参数,包括状态转移概率、观测概率和初始状态概率。
-
语音合成: 对于待合成的文本,将文本转化为音素序列。然后,通过Viterbi算法等方法,根据HMM模型预测音素序列对应的隐藏状态序列。
-
合成语音重建: 根据预测的隐藏状态序列,利用HMM模型的观测概率,从每个状态生成对应的MFCC特征。
-
声码器生成: 使用声码器,如激励源声码器(Excitation Source Vocoder)或线性预测编码(Linear Predictive Coding,LPC)声码器,将MFCC特征转化为合成语音信号。
总结:
基于MFCC特征提取和HMM模型的语音合成算法能够实现高质量、自然流畅的语音合成。该算法通过从语音信号中提取MFCC特征,然后通过HMM模型建模时序特性,最终生成合成语音信号。在语音助手、无障碍通信、教育培训等领域,该算法都有着重要的应用价值,为人们提供更加便捷和自然的语音交互体验。随着深度学习和人工智能的发展,基于MFCC和HMM的语音合成算法将会得到更多创新和优化,进一步拓展其应用领域和性能。
5.算法完整程序工程
OOOOO
OOO
O