文章目录
- 1️⃣预备知识
- 2️⃣实现思路
- 🔸脚本预处理得到包含embedd和GT的npz
- 🔸编写Dataset类
- 3️⃣代码
- 🔸实现脚本预处理得到包含embedd和GT的npz代码
- 🔸实现Dataset的代码
1️⃣预备知识
欢迎订阅本专栏(为爱发电,限时免费),联系前三篇一起食用哈!上一篇讲了如何使用SAM接口完成一个训练流程,本篇只专注于如何处理包装自己的数据集。
流程如下:
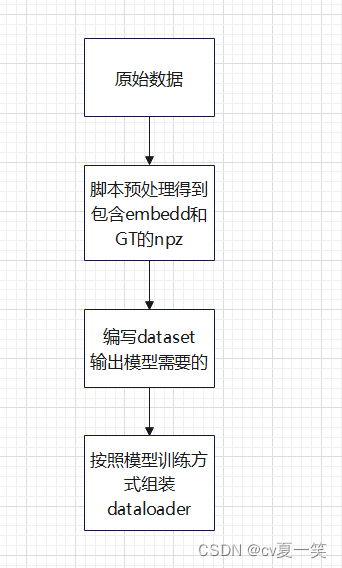
直接将图像编码器编码得到的embedding存入npz代表原始图像,是因为,我们有很多种训练策略,但每一次的编码过程是一摸一摸的,并且也是最耗时的一部分,所以,将其静态化,每次用的时候拿来解压。
由于比较粗糙并且没有做交叉验证,所以这里在原始图像存放路径的时候就划分好了训练测试,但一般自己的数据集还是做个交叉验证,在得到npz之后划分训练测试。
2️⃣实现思路
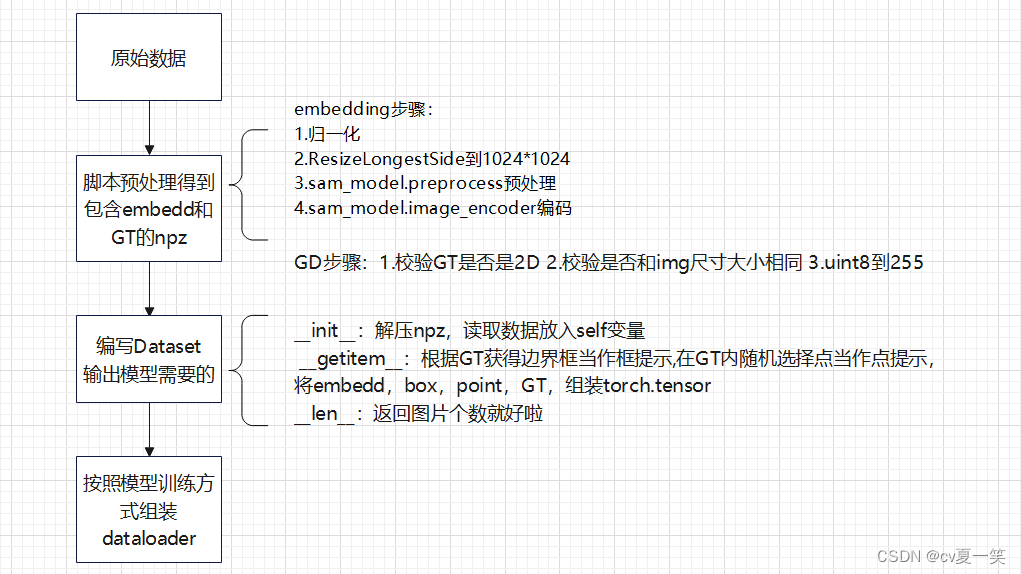
🔸脚本预处理得到包含embedd和GT的npz
embedding步骤:
1.归一化
2.ResizeLongestSide到1024*1024
3.sam_model.preprocess预处理
4.sam_model.image_encoder编码
GD步骤:1.校验GT是否是2D 2.校验是否和img尺寸大小相同 3.uint8到255
🔸编写Dataset类
init:解压npz,读取数据放入self变量
getitem:根据GT获得边界框当作框提示,在GT内随机选择点当作点提示, 将embedd,box,point,GT,组装torch.tensor
len:返回图片个数就好啦
3️⃣代码
🔸实现脚本预处理得到包含embedd和GT的npz代码
注释都在代码里吗,按行注释,我真贴心💓
import numpy as np
import os
join = os.path.join
from skimage import transform, io
from tqdm import tqdm
import torch
from segment_anything import sam_model_registry
from segment_anything.utils.transforms import ResizeLongestSide# GT存放路径,到文件夹
gt_path = "./"
# 组装好npz的保存路径
save_path = "./"
# 获取所有GT图像名称
names = sorted(os.listdir(gt_path))
os.makedirs(save_path, exist_ok=True)
model_type = 'vit_b'
checkpoint = 'xx/sam_vit_b_01ec64.pth'
device = 'cuda:0'
sam_model = sam_model_registry[model_type](checkpoint=checkpoint).to(device)
imgs = []
gts = []
img_embeddings = []
# image路径 到最后一层文件夹
img_path=""
for gt_name in tqdm(names):# 如果你是jpg改一下后缀image_name = gt_name.split('.')[0] + "png"# 读取GTgt_data = io.imread(join(gt_path, gt_name))# GT必须是2D,如果是3D就取前两通道if len(gt_data.shape) == 3:gt_data = gt_data[:, :, 0]assert len(gt_data.shape) == 2, 'GT must be 2D'# 尺寸转256数值转255gt_data = transform.resize(gt_data == 255, (256, 256), order=0,preserve_range=True, mode='constant')gt_data = np.uint8(gt_data)# 排除GT特别小的情况,这条可以不加if np.sum(gt_data) > 100:assert np.max(gt_data) == 1 and np.unique(gt_data).shape[0] == 2, 'GT must be 2D'image_data = io.imread(join(img_path, image_name))# 计算最大值最小值lower_bound, upper_bound = np.percentile(image_data, 0.5), np.percentile(image_data, 99.5)# 排除特别特殊的像素image_data_pre = np.clip(image_data, lower_bound, upper_bound)# 归一化image_data_pre = (image_data_pre - np.min(image_data_pre)) / (np.max(image_data_pre) - np.min(image_data_pre)) * 255.0image_data_pre[image_data == 0] = 0# 归一化image_data_pre = transform.resize(image_data_pre, (256, 256), order=3,preserve_range=True, mode='constant', anti_aliasing=True)image_data_pre = np.uint8(image_data_pre)imgs.append(image_data_pre)gts.append(gt_data)# SAM提供的resize到1024sam_transform = ResizeLongestSide(sam_model.image_encoder.img_size)resize_img = sam_transform.apply_image(image_data_pre)# resize_img是通道在后,sam要求通道在前,transposehi是对resize_img数组进行维度重排(dimension reordering)的操作。resize_img_tensor = torch.as_tensor(resize_img.transpose(2, 0, 1)).to(device)# 增加一个channel假装当作有一个batchsize输入到sam_model.image_encoderinput_image = sam_model.preprocess(resize_img_tensor[None, :, :, :]) # (1, 3, 1024, 1024)# 提前计算图像embeddingwith torch.no_grad():embedding = sam_model.image_encoder(input_image)img_embeddings.append(embedding.cpu().numpy()[0])# 上面数据已经处理好并存在数组了,需要数据字典存在npz中
# 沿着纵轴堆砌,每一个都是(256, 256, 3),堆起来是(n, 256, 256, 3)
imgs = np.stack(imgs, axis=0) # (n, 256, 256, 3)
gts = np.stack(gts, axis=0) # (n, 256, 256)
img_embeddings = np.stack(img_embeddings, axis=0) # (n, 1, 256, 64, 64)
# np的保存npz操作
np.savez_compressed(join(save_path, '.npz'), imgs=imgs, gts=gts, img_embeddings=img_embeddings)
🔸实现Dataset的代码
import numpy as np
import matplotlib.pyplot as plt
import osjoin = os.path.join
from tqdm import tqdm
import torch
from torch.utils.data import Dataset, DataLoader
import monai
from segment_anything import sam_model_registry
from segment_anything.utils.transforms import ResizeLongestSide
import randomtorch.manual_seed(2023)# 构造自己的Dataset继承Dataset类
class MyselfDataset(Dataset):def __init__(self, data_root):print("into init")self.data_root = data_root# 访问npz文件self.npz_files = sorted(os.listdir(self.data_root))# 去除npz里的数据self.npz_data = [np.load(join(data_root, f)) for f in self.npz_files]# 将取出来的数据放在变量保存self.ori_gts = np.vstack([d['gts'] for d in self.npz_data])self.img_embeddings = np.vstack([d['img_embeddings'] for d in self.npz_data])def __len__(self):return self.ori_gts.shape[0]def __getitem__(self, index):img_embed = self.img_embeddings[index]gt2D = self.ori_gts[index]# 获取非零点坐标y_indices, x_indices = np.where(gt2D > 0)# 获取GT坐标框x_min, x_max = np.min(x_indices), np.max(x_indices)y_min, y_max = np.min(y_indices), np.max(y_indices)# 在GT框加扰动H, W = gt2D.shapex_min = max(0, x_min - np.random.randint(0, 10))x_max = min(W, x_max + np.random.randint(0, 10))y_min = max(0, y_min - np.random.randint(0, 10))y_max = min(H, y_max + np.random.randint(0, 10))bboxes = np.array([x_min, y_min, x_max, y_max])# 在GT在5像素以内的地方随机选择两个背景点y_zero, x_zero = np.where(gt2D == 0)y_zero = np.unique(y_zero)x_zero = np.unique(x_zero)y_list = y_zero[(y_min - 5 < y_zero) & (y_zero < y_max + 5)]x_list = x_zero[(x_min - 5 < x_zero) & (x_zero < x_max + 5)]y1, y2 = random.choices(y_list, k=2)x1, x2 = random.choices(x_list, k=2)background_index1 = [x1, y1]background_index2 = [x2, y2]# 在GT内随机选择前景点foreground_index1, foreground_index2, foreground_index3 = random.choices(np.argwhere(gt2D == 1), k=3)# 将所有选择好的点添加到list,如果是单点,不需要直接返回点的index就好。pt_list_s = []pt_list_s.append(background_index1)pt_list_s.append(background_index2)pt_list_s.append(foreground_index1)pt_list_s.append(foreground_index2)pt_list_s.append(foreground_index3)points = pt_list_s# 0是背景1是前景points_labels = [0, 0, 1, 1, 1]return torch.tensor(img_embed).float(), torch.tensor(gt2D[None, :, :]).long(), torch.tensor(bboxes).float(), torch.tensor(points).float(), torch.tensor(points_labels).float()
之后连系上篇 【Segment Anything Model】SAM模型微调自定义数据集,更改混合提示方式:点,框,点框混合
在这里取值训练就好啦