文章目录
- 协议
- 序列化和反序列化
- 网络计算器
- protocol.hpp
- Server.hpp
- Server.cc
- Client.hpp
- Client.cc
- log.txt
- 通过结果再次理解通信过程
- Json
- 效果
协议
协议究竟是什么呢?首先得知道主机之间的网络通信交互的是什么数据,像平时使用聊天APP聊天可以清楚,用户看到的不仅仅是聊天的文字,还能够看到用户的头像昵称等其他属性。也就可以证明网络通信不仅仅是交互字符串那么简单。事实上网络通信还可能会通过一个结构化的数据去交互,例如聊天软件里,一台主机向另一台发送消息,这个消息里面就包含了头像等其他的数据。
一台主机发送数据会把所有的数据整合成一个结构化数据统一发送,而收到数据的主机再将这个结构化数据分解成原始的每个独立的数据。而为了确保主机之间收到数据后能够成功的分解,整合和分解两个过程必须是按照统一的约定来执行,而这个约定就是协议
序列化和反序列化
上述的将所有需要发送的数据整合到一起的过程就称为序列化过程,而分解的过程就称为反序列化过程
网络的通信就可以理解为:
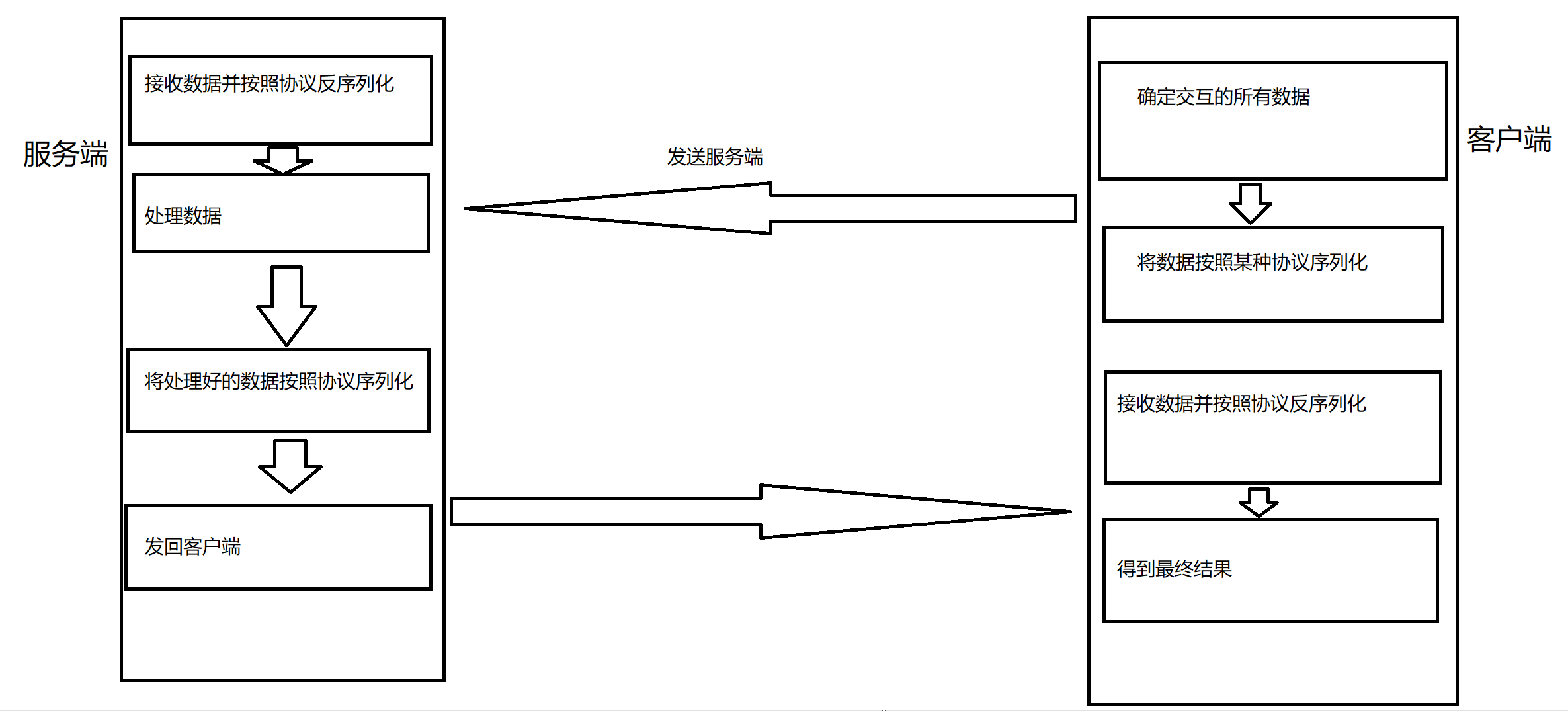
本篇文章就利用编写一个最简单的网络计算器来感受这个通信的过程
网络计算器
protocol.hpp
这个头文件用来编写协议及序列化反序列化的过程。
- 首先因为是一个计算器所以肯定需要两个数和一个计算符号,但是作为服务端不能要求客户怎么样去输入这个计算的格式,可能客户会输入 1+1 也可能会输入 1 + 1 。因此作为服务端要将客户的输入识别成自己的规定。这里就规定数 计算符号 数。所以可以先规定好分隔符,利用宏定义方便修改。
- 因为TCP是面向字节流的,所以要明确通信的数据的边界,不能读多也不能读少。因为对于TCP而言,它是全双工的,所以就会出现接收方来不及读,导致整个缓冲区里有大量的数据,因此就要规定好边界保证读到的是一个完整的数据
- 对于计算器而言,首先是要获得到需要计算的数据,然后处理得到计算结果。因此可以定义两个结构体,一个结构体负责发送请求也就是发送计算的数据,另一个结构体负责响应请求也就是处理计算结果。
- 在发送请求的结构体里保存了两个数和计算符号,但是由于需要网络通信,所以要在结构体里定义好序列化过程的方法。同时服务端拿到数据后要想处理数据就必须要先反序列化,所以结构体里也定义好反序列化过程的方法
- 在响应请求的结构体里,同样的服务端需要将计算好的数据发回给客户端也需要定义好序列化过程的方法,而客户端要获取数据也需要反序列化过程的方法
- 因为要确保读到的数据是完整的一个数据,因此可以定义一个函数,将序列化好的数据加上一个报头,也就是这个数据的长度,用来标识这个数据的长度,读的时候就可以根据长度的依据去读取。
- 当然因为这个报头并不是需要真正要传输的数据,所以需要再定义一个函数用来去掉这个报头
- 当两端读取到数据时就需要判断读到的是否是一个完整的数据。如果还没读到完整的数据就继续读。可以定义一个函数用来读取数据并且判断是否读到完整数据,这个依据就是读到的数据的长度是否和原数据的长度相等,这个原数据长度为报头加上正文加上分隔符的长度
#pragma once#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <jsoncpp/json/json.h>using namespace std;// 定义好分隔符
#define SEP " " // 一条数据里每个元素的分隔符
#define SEP_LEN strlen(SEP) // 分隔符的大小
#define LINE_SEP "\r\n" // 数据与数据的分隔符
#define LINE_SEP_LEN strlen(LINE_SEP) // 分隔符大小// 为通信的数据加上数据的长度和分割
// 确保每条数据都能精确的读取到,不读多也不读少
// "text.size()"\r\n"text"\r\n
string enlength(const string &text)
{string res = to_string(text.size());res += LINE_SEP;res += text;res += LINE_SEP;return res;
}// 将全部的一条数据去掉前面的数据长度
// 提取出原始数据
bool delength(const string &package, string *text)
{// 找到第一个元素分隔符,弃掉前面的长度auto pos = package.find(LINE_SEP);if (pos == string::npos)return false;// 确认正文的长度int len = stoi(package.substr(0, pos));// 从第一个分割符往后开始到记录的字符串长度就是原始的数据*text = package.substr(pos + LINE_SEP_LEN, len);return true;
}// 请求
class Request
{
public:int _x;int _y;char _op;Request(): _x(0), _y(0), _op('0'){}Request(int x, int y, char op): _x(x), _y(y), _op(op){}// 序列化过程// 因为通信的数据一开始分为了好几个独立的元素// 所以将这些独立的元素合并成一个数据bool serialize(string *out){*out = "";*out += to_string(_x);*out += SEP;*out += _op;*out += SEP;*out += to_string(_y);return true;}// 反序列化过程// 将合并的一整个数据分解回原始的几个独立数据bool unserialize(const string &in){auto left = in.find(SEP);auto right = in.rfind(SEP);if (left == string::npos || right == string::npos || left == right)return false;// 因为对于计算器而言,计算符号只有1位if (right - left - SEP_LEN != 1)return false;_x = stoi(in.substr(0, left));_y = stoi(in.substr(right + SEP_LEN));_op = in[left + SEP_LEN];return true;}
};// 响应请求
class Response
{
public:int _exitcode; // 返回码int _result; // 返回结果Response(): _exitcode(0), _result(0){}Response(int exitcode, int result): _exitcode(exitcode), _result(result){}bool serialize(string *out){*out = "";*out += to_string(_exitcode);*out += SEP;*out += to_string(_result);return true;}bool unserialize(const string &in){auto pos = in.find(SEP);if (pos == string::npos)return false;_exitcode = stoi(in.substr(0, pos));_result = stoi(in.substr(pos + SEP_LEN));return true;}
};// 读取数据并且判断是否是个完整的数据的方法
bool recvPackage(int sock, string &buff, string *text)
{char buffer[1024];while (1){ssize_t n = recv(sock, buffer, sizeof(buffer), 0);if (n > 0){// 找到报头和正文之间的分隔符buffer[n] = 0;buff += buffer;auto pos = buff.find(LINE_SEP);if (pos == string::npos)continue;// 拿到正文的长度int len = stoi(buff.substr(0, pos));// 判断inbuff的长度是否等于整个数据的长度// 如果相等说明读到了完成的数据int max_len = len + 2 * LINE_SEP_LEN + buff.substr(0, pos).size(); // 整个数据的长度if (buff.size() < max_len)continue;cout << "目前拿到的所有报文:\n" << buff << endl;// 到这一步说明至少有一个完整的数据// 将整个完整的数据传回指针*text = buff.substr(0, max_len);cout << "完整的报文:\n" << *text << endl;buff.erase(0, max_len);return true;}elsereturn false;}return true;
}
Server.hpp
服务端就定义一个函数将整个的读取、反序列化、计算、序列化、发送的过程全部编写好,然后服务端启动加上一个函数参数,也就是计算过程的函数。
#pragma once#include "log.hpp"
#include "Protocol.hpp"
#include <sys/types.h>
#include <sys/socket.h>
#include <cstring>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <functional>
#include <sys/types.h>
#include <sys/wait.h>typedef function<bool(const Request &req, Response &res)> func_t;void HandlerEntery(int sock, func_t func)
{string buff;while (1){// 读取// 需要保证读到的是一个完整的请求string req_text;if (!recvPackage(sock, buff, &req_text))return;cout << "带报头的请求: \n" << req_text << endl;// 将读到的数据的头部去掉,也就是数据长度string req_str;if (!delength(req_text, &req_str))return;cout << "原始数据: " << req_str << endl;// 对读到的原始数据进行反序列化Request req;if (!req.unserialize(req_str))return;// 将反序列化后的结果计算出来后// 将结果放到响应类对象里// 通过响应类对象提取到结果Response res;func(req, res);string res_str;// 得到响应类对象序列化结果res.serialize(&res_str);cout << "计算完成,结果序列化:" << res_str << endl;// 再将得到的结果加上报头// 也就是数据长度确保数据的精确读取// 得到最终的序列化数据res_str = enlength(res_str);cout << "构建完整序列化数据完成:\n" << res_str << endl;// 将最终的数据发送回去send(sock, res_str.c_str(), res_str.size(), 0);cout << "服务端发送完成" << endl;}
}class Server
{
public:Server(const uint16_t &port = 8000): _port(port){}void Init(){// 创建负责监听的套接字 面向字节流_listenSock = socket(AF_INET, SOCK_STREAM, 0);if (_listenSock < 0){LogMessage(FATAL, "create socket error!");exit(1);}LogMessage(NORMAL, "create socket %d success!", _listenSock);// 绑定网络信息struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = INADDR_ANY;if (bind(_listenSock, (struct sockaddr *)&local, sizeof(local)) < 0){LogMessage(FATAL, "bind socket error!");exit(3);}LogMessage(NORMAL, "bind socket success!");// 设置socket为监听状态if (listen(_listenSock, 5) < 0){LogMessage(FATAL, "listen socket error!");exit(4);}LogMessage(NORMAL, "listen socket success!");}void start(func_t func){while (1){// server获取建立新连接struct sockaddr_in peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);// 创建通信的套接字// accept的返回值才是真正用于通信的套接字_sock = accept(_listenSock, (struct sockaddr *)&peer, &len);if (_sock < 0){// 获取通信的套接字失败并不影响未来的操作,只是当前的链接失败而已LogMessage(ERROR, "accept socket error, next");continue;}LogMessage(NORMAL, "accept socket %d success", _sock);cout << "sock: " << _sock << endl;// 利用多进程实现pid_t id = fork();if (id == 0) // child{close(_listenSock);// 调用方法包括读取、反序列化、计算、序列化、发送HandlerEntery(_sock, func);close(_sock);exit(0);}close(_sock);// fatherpid_t ret = waitpid(id, nullptr, 0);if (ret > 0){LogMessage(NORMAL, "wait child success"); // ?}}}private:int _listenSock; // 负责监听的套接字int _sock; // 通信的套接字uint16_t _port; // 端口号
};
Server.cc
这个服务端的计算函数就通过结构体的对象去作为参数完成,因为需要的数据都在结构体里
#include "Server.hpp"
#include <memory>// 输出命令错误函数
void Usage(string proc)
{cout << "Usage:\n\t" << proc << " local_ip local_port\n\n";
}// 计算方式
bool cal(const Request &req, Response &res)
{res._exitcode = 0;res._result = 0;switch (req._op){case '+':res._result = req._x + req._y;break;case '-':res._result = req._x - req._y;break;case '*':res._result = req._x * req._y;break;case '/':{if (req._y == 0)res._exitcode = 1;elseres._result = req._x / req._y;}break;default:res._exitcode = 2;break;}return true;
}int main(int argc, char *argv[])
{// 启动服务端不需要指定IPif (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);unique_ptr<Server> server(new Server(port));// 服务端初始化server->Init();//服务端启动server->start(cal);return 0;
}
Client.hpp
客户端和服务端一样也需要接收发送,不过客户端是先发送再接收。并且上述提过因为客户的输入方式无法控制,所以要定义一个函数将客户输入的数据提取到两个数和计算符号才能够构造请求的结构体对象
#pragma once#include <iostream>
#include <string>
#include <cstring>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "log.hpp"
#include "Protocol.hpp"using namespace std;class Client
{
public:Client(const string &serverip, const uint16_t &port): _serverip(serverip), _port(port), _sock(-1){}void Init(){// 创建套接字_sock = socket(AF_INET, SOCK_STREAM, 0);if (_sock < 0){LogMessage(FATAL, "create socket error");exit(1);}// TCP的客户端也不需要显示绑定端口,让操作系统随机绑定// TCP的客户端也不需要监听,因为并没有去主动链接客户端,所以不需要accept// TCP的客户端也不需要监听,因为并没有去主动链接客户端,所以不需要accept}void start(){// 向服务端发起链接请求struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = inet_addr(_serverip.c_str());if (connect(_sock, (struct sockaddr *)&local, sizeof(local)) < 0)LogMessage(ERROR, "connect socket error");// 和服务端通信else{string line;string buffer;while (1){cout << "Please cin: " << endl;getline(cin, line);Request req = ParseLine(line);string text;req.serialize(&text);cout << "序列化后的数据:" << text << endl;string send_str = enlength(text);cout << "添加报头后的数据: \n" << send_str << endl;send(_sock, send_str.c_str(), send_str.size(), 0);// read// 拿到完整报文string package;if (!recvPackage(_sock, buffer, &package))continue;cout << "拿到的完整报文: \n" << package << endl;// 拿到正文string end_text;if (!delength(package, &end_text))continue;cout << "拿到的正文:" << end_text << endl;// 反序列化Response res;res.unserialize(end_text);cout << "exitCode: " << res._exitcode << " result: " << res._result << endl;}}}~Client(){if (_sock >= 0)close(_sock);}// 将客户输入的数据提取构造请求结构体对象Request ParseLine(const string &line){auto it = line.begin();// 提取左边的数字string left;while (it != line.end() && *it >= '0' && *it <= '9'){left += *it;++it;}int leftnum = atoi(left.c_str());// 提取符号while (it != line.end() && *it != '+' && *it != '-' && *it != '+' && *it != '/')++it;char op = *it;// 提取右边数字while (it != line.end() && (*it < '0' || *it > '9'))++it;string right;while (it != line.end() && *it >= '0' && *it <= '9'){right += *it;++it;}int rightnum = atoi(right.c_str());return Request(leftnum, rightnum, op);}private:int _sock;string _serverip;uint16_t _port;
};
Client.cc
#include "Client.hpp"
#include <memory>// 输出命令错误函数
void Usage(string proc)
{cout << "Usage:\n\t" << proc << " local_ip local_port\n\n";
}int main(int argc, char *argv[])
{// 再运行客户端时,输入的指令需要包括主机ip和端口号if (argc != 3){Usage(argv[0]);exit(1);}string serverip = argv[1];uint16_t port = atoi(argv[2]);unique_ptr<Client> client(new Client(serverip, port));client->Init();client->start();return 0;
}
log.txt
这里还加了一个记录日志的方法,可加可不加
#pragma once#include <iostream>
#include <string>
#include <cstdarg>
#include <ctime>
#include <unistd.h>using namespace std;#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4const char *to_levelstr(int level)
{switch (level){case DEBUG:return "DEBUG";case NORMAL:return "NORMAL";case WARNING:return "WARNING";case ERROR:return "ERROR";case FATAL:return "FATAL";default:return nullptr;}
}void LogMessage(int level, const char *format, ...)
{
#define NUM 1024char logpre[NUM];snprintf(logpre, sizeof(logpre), "[%s][%ld][%d]", to_levelstr(level), (long int)time(nullptr), getpid());char line[NUM];// 可变参数va_list arg;va_start(arg, format);vsnprintf(line, sizeof(line), format, arg);// 保存至文件FILE* log = fopen("log.txt", "a");FILE* err = fopen("log.error", "a");if(log && err){FILE *curr = nullptr;if(level == DEBUG || level == NORMAL || level == WARNING) curr = log;if(level == ERROR || level == FATAL) curr = err;if(curr) fprintf(curr, "%s%s\n", logpre, line);fclose(log);fclose(err);}
}
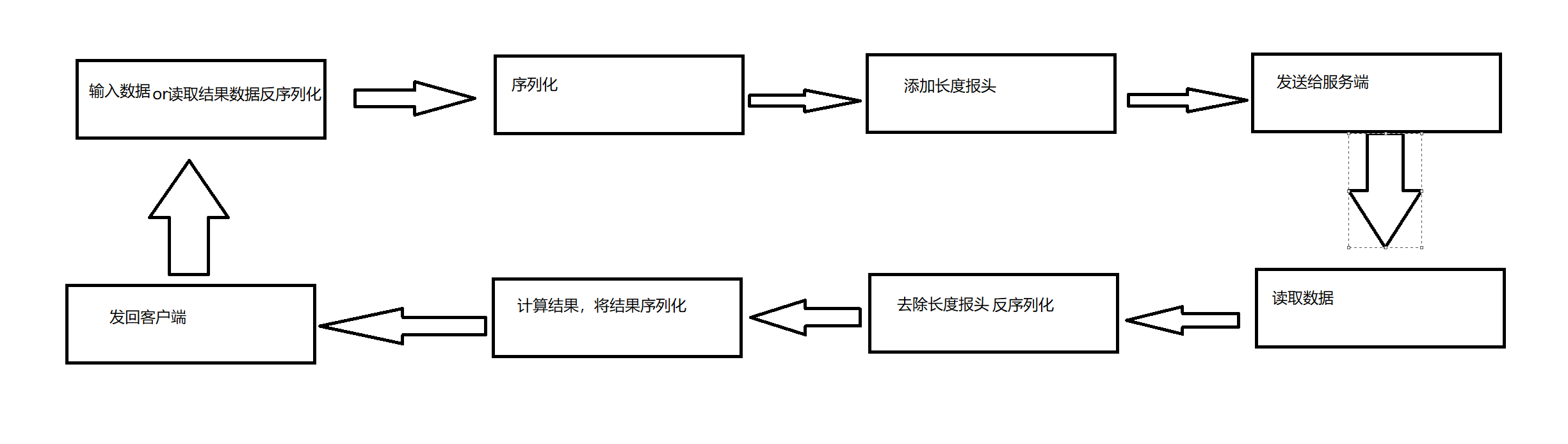
通过结果再次理解通信过程
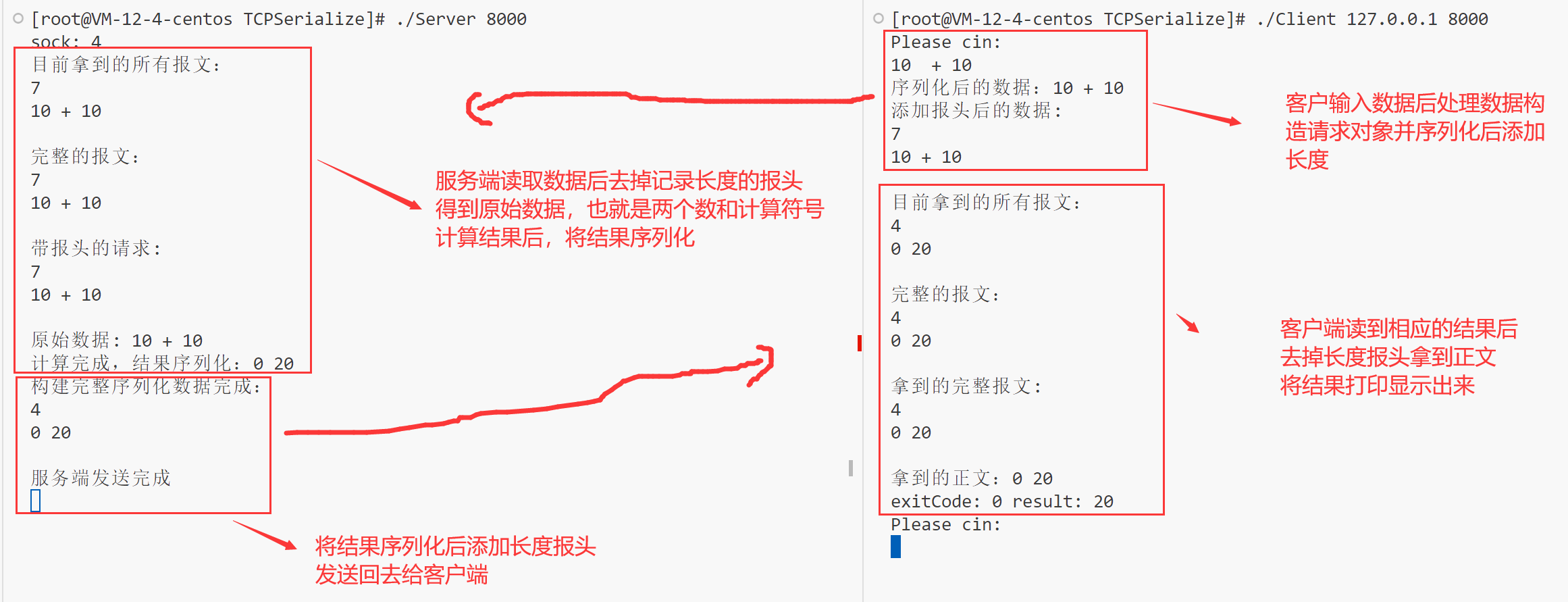
所以最终的流程可以分解为几个步骤:
Json
上面的序列化和反序列化过程呢都是自己定义的,所以看起来并不好看,而且可读性也不美观。
其实也会第三方库是帮我们做好了序列化和反序列化工作的,例如 Json,protobuf。因为Json的使用比较简单,所以这里就使用Json
首先需要安装第三方的 Jsoncpp的库
yum install jsoncpp-devel
安装好之后就可以使用第三方库了,需要注意因为是第三方库和线程库一样,编译的时候需要加上 -lJsoncpp的选项
肯定下面的代码注释就可以了解到Json的使用了,注:为了不修改上述的一些代码,下面使用条件编译,只看Json部分即可
// 请求
class Request
{
public:int _x;int _y;char _op;Request(): _x(0), _y(0), _op('0'){}Request(int x, int y, char op): _x(x), _y(y), _op(op){}// 序列化过程// 因为通信的数据一开始分为了好几个独立的元素// 所以将这些独立的元素合并成一个数据bool serialize(string *out){
#ifdef MYSELF*out = "";*out += to_string(_x);*out += SEP;*out += _op;*out += SEP;*out += to_string(_y);
#else// Value是万能类型// 需要先定义出对象Json::Value root;// Json是kv结构存储的,所以需要定义k值标识v值root["first"] = _x;root["second"] = _y;root["op"] = _op;// Json要写入值给别的变量也需要先定义对象// 写的对象类型可以有几种,这里采用FastWriterJson::FastWriter w;// 调用write方法就可以写入*out = w.write(root);
#endifreturn true;}// 反序列化过程// 将合并的一整个数据分解回原始的几个独立数据bool unserialize(const string &in){
#ifdef MYSELFauto left = in.find(SEP);auto right = in.rfind(SEP);if (left == string::npos || right == string::npos || left == right)return false;// 因为对于计算器而言,计算符号只有1位if (right - left - SEP_LEN != 1)return false;_x = stoi(in.substr(0, left));_y = stoi(in.substr(right + SEP_LEN));_op = in[left + SEP_LEN];
#else// 同样的需要先定义对象// 读的对象也需要定义Json::Value root;Json::Reader reader;// 调用读方法,将root的值读到in中reader.parse(in, root);// asInt表示切换为整形类型// 通过k值就可以得到v值_x = root["first"].asInt();_y = root["second"].asInt();_op = root["op"].asInt();
#endifreturn true;}
};// 响应请求
class Response
{
public:int _exitcode; // 返回码int _result; // 返回结果Response(): _exitcode(0), _result(0){}Response(int exitcode, int result): _exitcode(exitcode), _result(result){}bool serialize(string *out){
#ifdef MYSELF*out = "";*out += to_string(_exitcode);*out += SEP;*out += to_string(_result);
#elseJson::Value root;root["exitcode"] = _exitcode;root["result"] = _result;Json::FastWriter w;*out = w.write(root);
#endifreturn true;}bool unserialize(const string &in){
#ifdef MYSELFauto pos = in.find(SEP);if (pos == string::npos)return false;_exitcode = stoi(in.substr(0, pos));_result = stoi(in.substr(pos + SEP_LEN));
#elseJson::Value root;Json::Reader reader;reader.parse(in, root);_exitcode = root["exitcode"].asInt();_result = root["result"].asInt();
#endifreturn true;}
};
只需要更改序列化反序列化过程即可,外面的协定不需要改变
效果
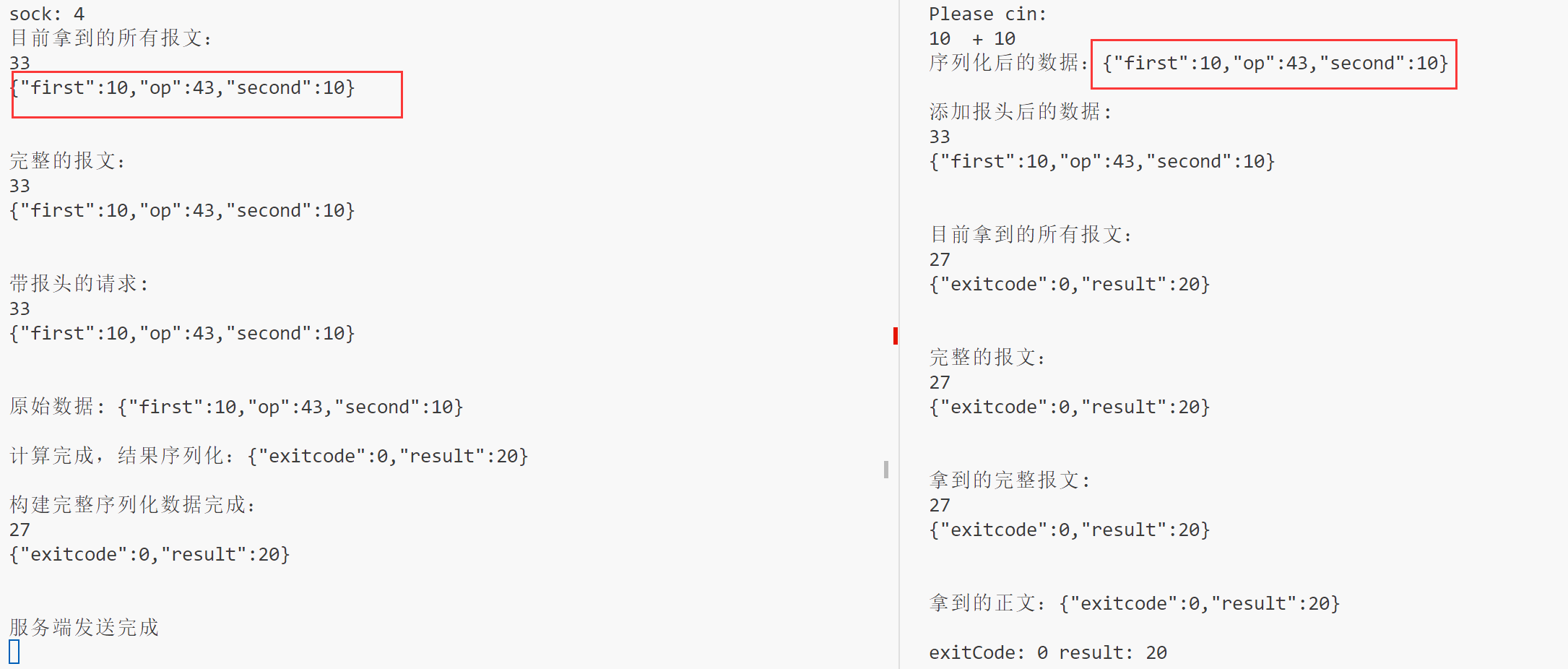
使用 Json序列化的就很美观





![[国产MCU]-BL602开发实例-开发环境搭建](https://img-blog.csdnimg.cn/0bec42d3b60745b79b1de19dd4fba1ca.png#pic_center)