基本介绍
上篇文章我们讲解了使用FastAPI+MemFire Cloud+LangChain进行GPT知识库开发的基本原理和关键路径的代码实现。目前完整的实现代码已经上传到了github,感兴趣的可以自己玩一下:
https://github.com/MemFire-Cloud/memfirecloud-qa
目前代码主要完成了如下一些基本功能:
- 使用FastAPI作为Web服务端框架完成了基本的Web服务端开发
- 使用MemFire Cloud作为向量数据和个人文档数据存储
- 使用LangChain进行AI应用开发,加载本地磁盘目录上的文档,计算embedding、存储到向量数据库
- 使用OpenAI的GPT模型,完成问答功能的实现
- 使用Next.js开发了一个简单的UI界面用于问答演示
本篇文章我们将介绍一下如何部署示例代码。
准备工作
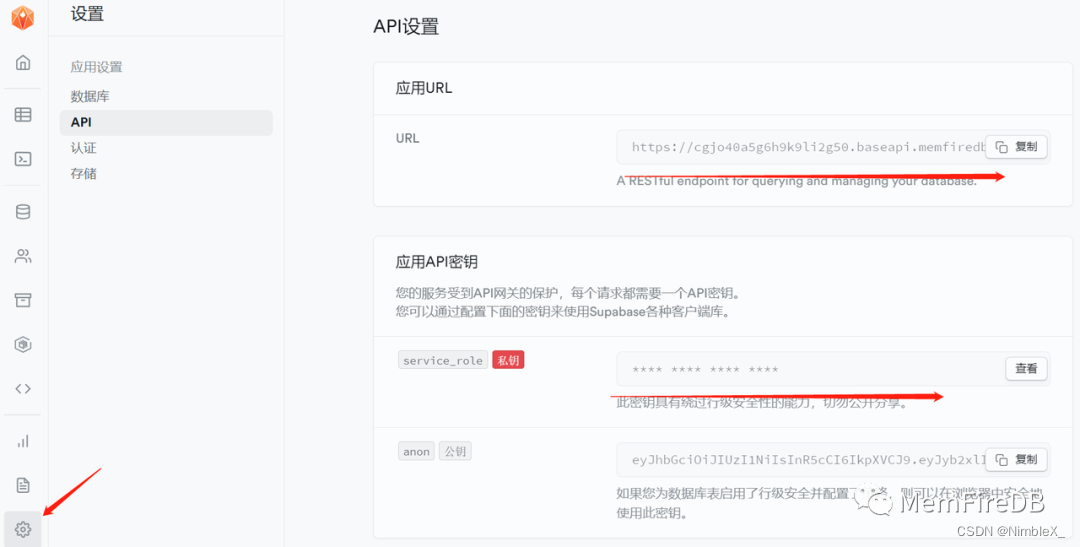
- 在MemFire Cloud上创建应用,后面需要用到应用的API URL和Service Role Key。可以在应用的应用设置->API页面找到相应的配置
- 创建应用后,在应用的SQL执行器页面执行如下脚本
-- Enable the pgvector extension to work with embedding vectors
create extension vector;-- Create a table to store your documents
create table documents (id uuid primary key,content text, -- corresponds to Document.pageContentmetadata jsonb, -- corresponds to Document.metadataembedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);CREATE FUNCTION match_documents(query_embedding vector(1536), match_count int)RETURNS TABLE(id uuid,content text,metadata jsonb,-- we return matched vectors to enable maximal marginal relevance searchesembedding vector(1536),similarity float)LANGUAGE plpgsqlAS $$# variable_conflict use_column
BEGINRETURN querySELECTid,content,metadata,embedding,1 -(documents.embedding <=> query_embedding) AS similarityFROMdocumentsORDER BYdocuments.embedding <=> query_embeddingLIMIT match_count;
END;
$$;
-
准备好用来测试的文档目录
默认需要将文档放到app/docs下,可以通过环境变量指定其他目录 -
准备好openai的账号
请参考网上教程申请一个openai账号,后面代码运行需要用到openai的API KEY
如何运行
linux 下运行
1.安装依赖
pip install -r app/requirements.txt
2.设置参数
SUPABASE_URL/SUPABASE_KEY分别对应应用URL和service_role密钥。注意service_role秘钥具有比较高的数据库操作权限,只能用于服务端配置,不要泄漏。
export DOCS_PATH=./docs
export SUPABASE_URL="your-api-url"
export SUPABASE_KEY="your-service-role-key"
export OPENAI_API_KEY="your-openai-api-key"
3.运行
uvicorn main:app --reload --host 0.0.0.0
docker运行
docker build -t memfirecloud-qa:v1 .
docker run -p 8000:80 \-e SUPABASE_URL="your-api-url" \-e SUPABASE_KEY="your-service-role-key" \-e OPENAI_API_KEY="your-openai-api-key" \-v ./docs:/docs \memfirecloud-qa:v1
windows下运行(没测试)
与linux类似,设置相关环境变量,然后运行:
uvicorn main:app --reload --host 0.0.0.0
如何访问
用浏览器访问: http://your-ip:8000/可以显示一个简单的问答页面
支持的参数配置
# 本地文档路径
export DOCS_PATH=./docs# memfire cloud 应用的API URL和Service role key
export SUPABASE_URL="your-api-url"
export SUPABASE_KEY="your-service-role-key"# 使用openai / baidu 的大模型
export QA_BACKEND="openai" # 默认值# openai 相关配置(QA_BACKEND=openai是需要)
export OPENAI_ORGANIZATION="your-openai-organization"
export OPENAI_API_KEY="your-openai-api-key"
export OPENAI_MODEL="gpt-3.5-turbo" # 默认值# 百度相关配置(QA_BACKEND=baidu时需要)
export BAIDU_API_KEY="your-baidu-api-key"
export BAIDU_API_SECRET="your-baidu-api-secret"
export BAIDU_MODEL="ERNIE-Bot-turbo" # 默认值
接下来可以做的事情
-
过滤掉重复文档,避免应用重启或者添加重复文档时重新计算embedding
-
程序运行中支持增量添加新文档,实时更新知识库
-
支持对话(chat),目前只是问答(QA),不能连续对话
-
支持百度文心一言的接口(已完成api的封装)
感兴趣的可以提交pr,一起完善功能。