目录
- 一、xpath
- 1.xpath插件的安装
- 2. xpath的基本使用
- (1)xpath的使用方法与基本语法(路径查询、谓词查询、内容查询(使用text查看标签内容)、属性查询、模糊查询、逻辑运算)
- (2)安装lxml库
- (3)代码的演示
- 3.获取百度网站的百度一下
- 4.站长素材(含懒加载、如何下载其中的高清图)
- 二、JsonPath
- 1.JsonPath的基本介绍
- (1)引
- (2)jsonpath的安装及使用方式
- (3)代码演示
- 2.jsonpath解析淘票票
- 三、BeautifulSoup(即bs4)
- 1.bs4的基本使用
- (1)基本简介(作用与优缺点)
- (2)安装以及创建
- (3)节点定位
- (4)节点信息
- (5)代码演示(详细语法请看代码,含注释,比如函数find、find_all、select、按属性class寻找标签时需要使用“class_”)
- 2.bs4爬取星巴克数据
说明:该文章是学习 尚硅谷在B站上分享的视频 Python爬虫教程小白零基础速通的 p51-104而记录的笔记,笔记来源于本人,关于python基础可以去CSDN上阅读本人学习黑马程序员的笔记。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。另外,本人完善了部分小内容,比如bs4爬取星巴克数据部分,本人把爬取图片的代码补充完整了。 请合法合理使用爬虫,不爬取任何涉密以及涉及隐私的内容,合理控制请求次数,爬取的内容未经授权请不要用于商用,保护自己,免受牢狱之灾。
之前在urlib的学习中,我们能将网页的网页源码爬取下来。但是我们我们仅仅需要其中的部分数据,此时就需要引入新的概念——解析。目前使用最多的解析方法包括xpath、JsonPath、BeautifulSoup等。
一、xpath
1.xpath插件的安装
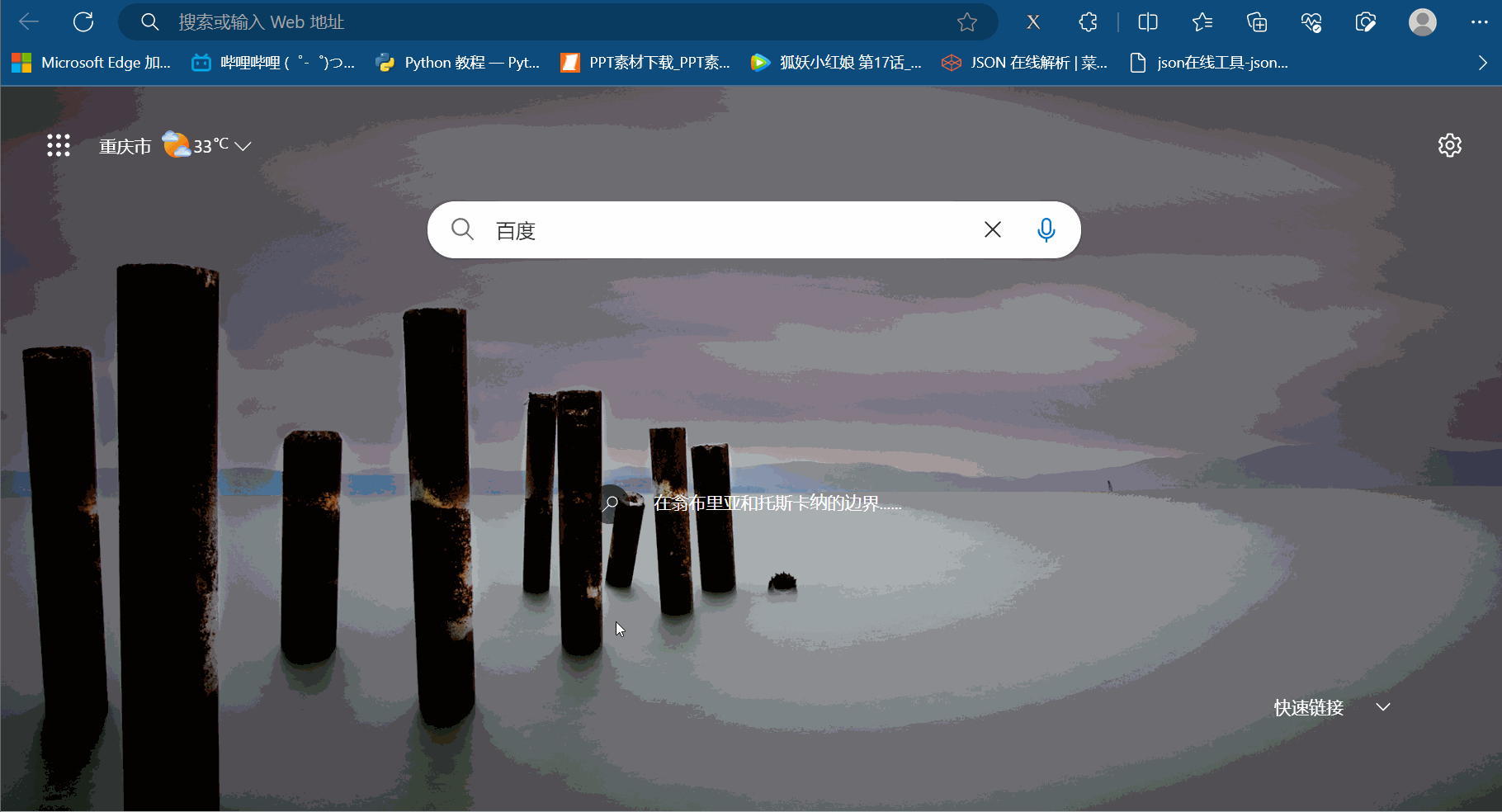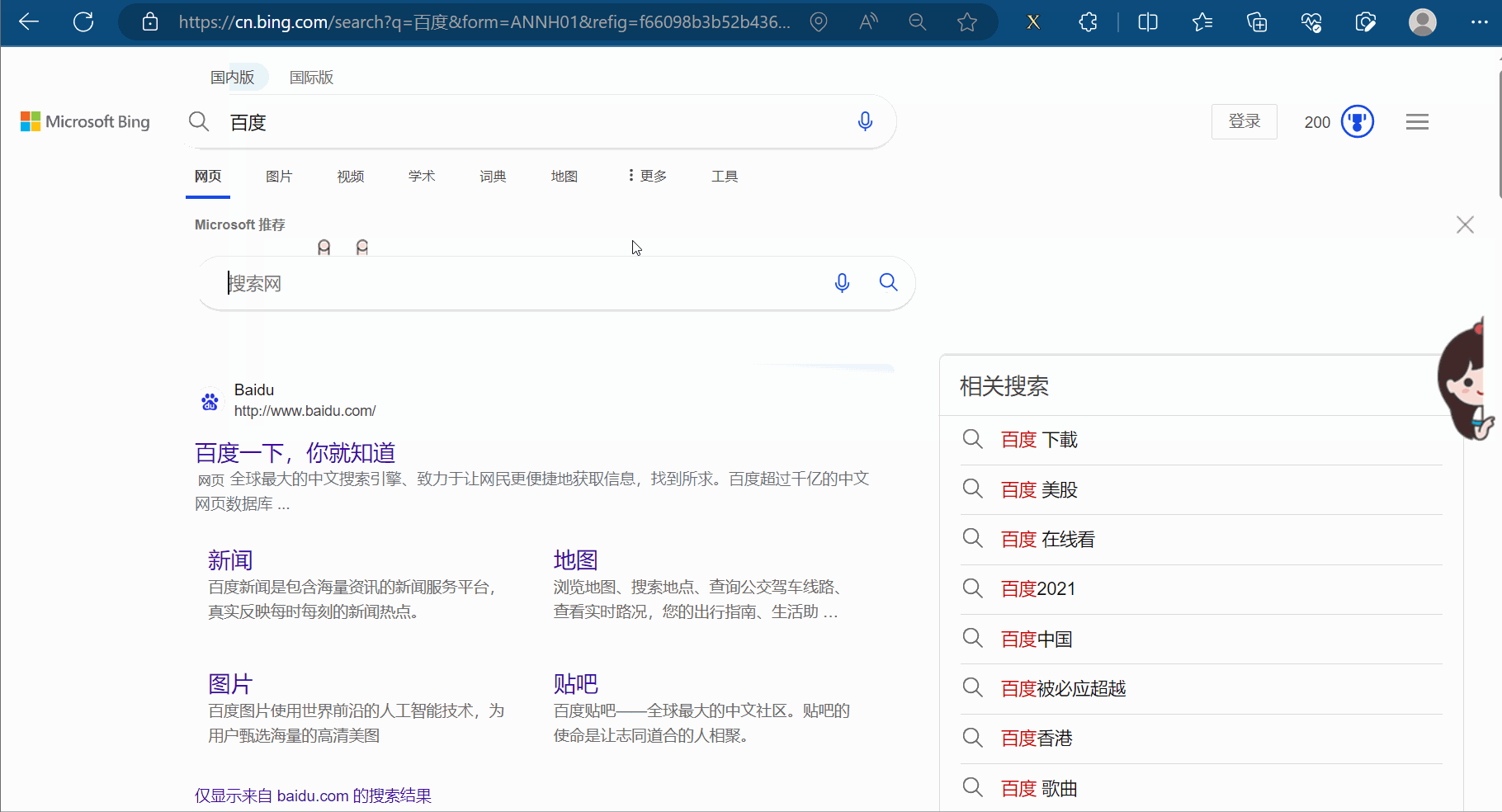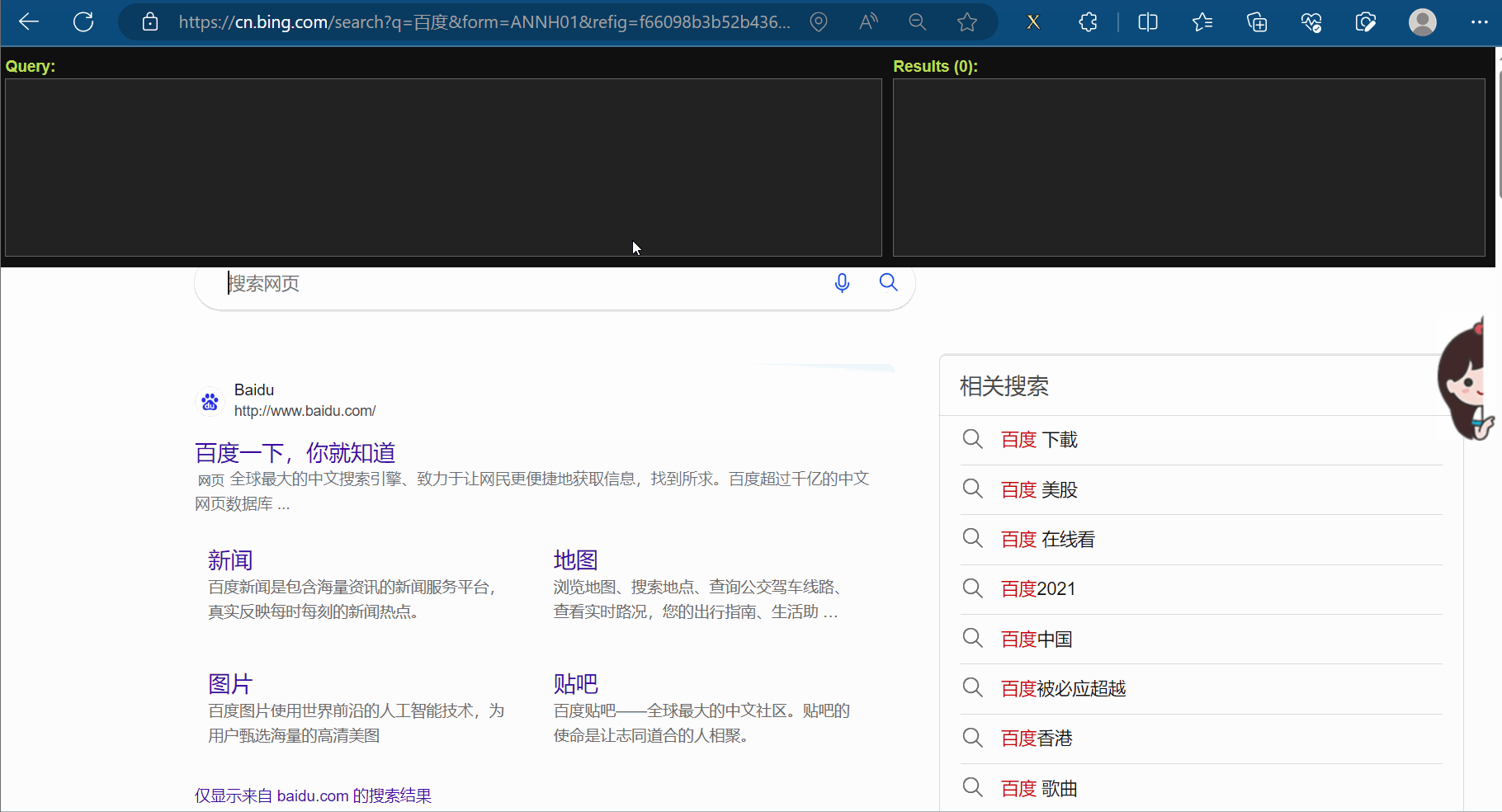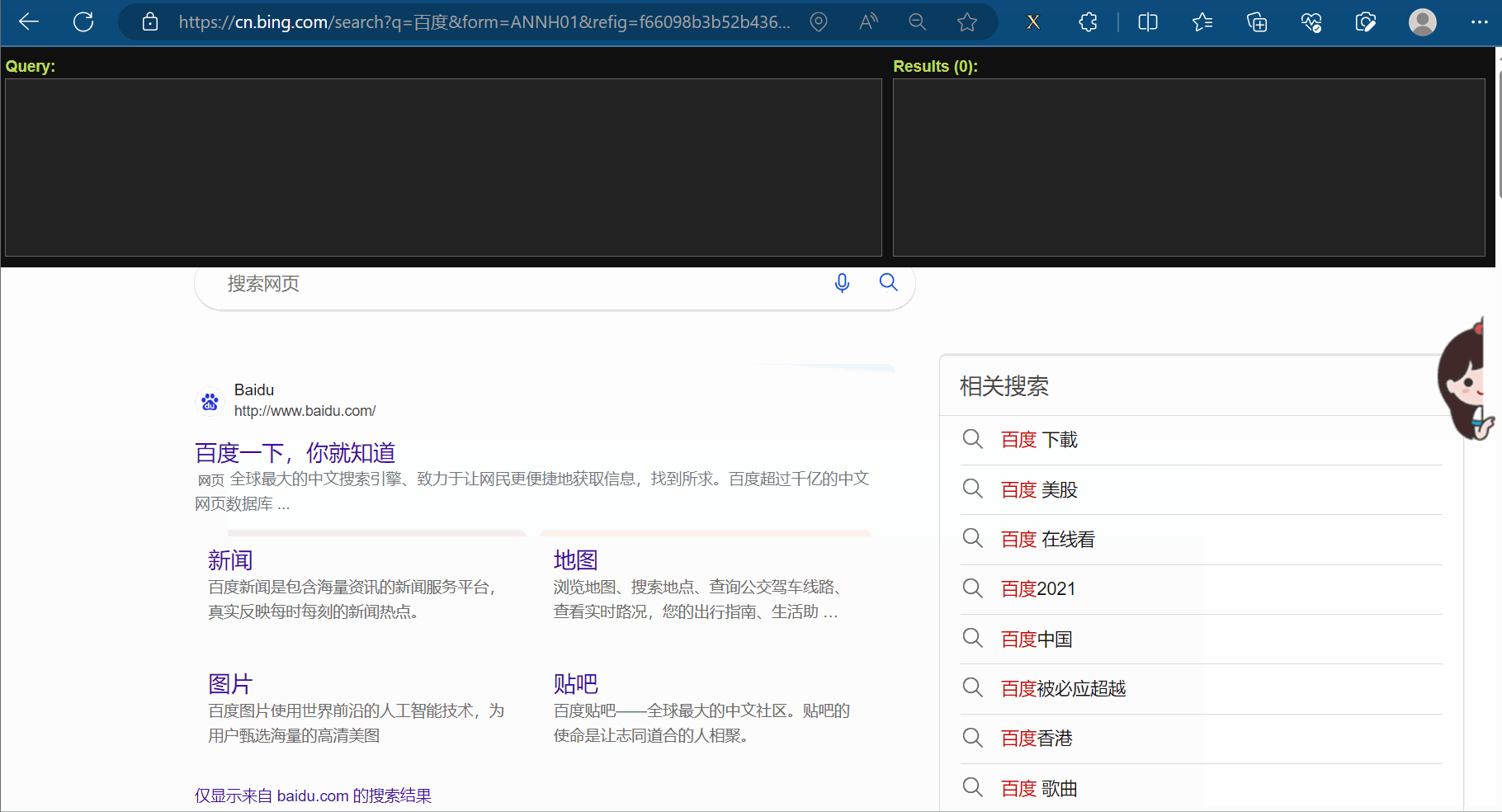
使用xpath之前,需要安装xpath插件。在使用该插件时,会弹出一个小黑框,在里面写xpath的路径,并判断xpath路径是否正确。本次以Edge浏览器为例进行介绍,如下几张图所示(由于原始的xpath的快捷键与Edge冲突,故本次使用的插件是经过修改的,来源于在Edge中使用Xpath——更改快捷键,请到对应链接里去下载xpath插件)。
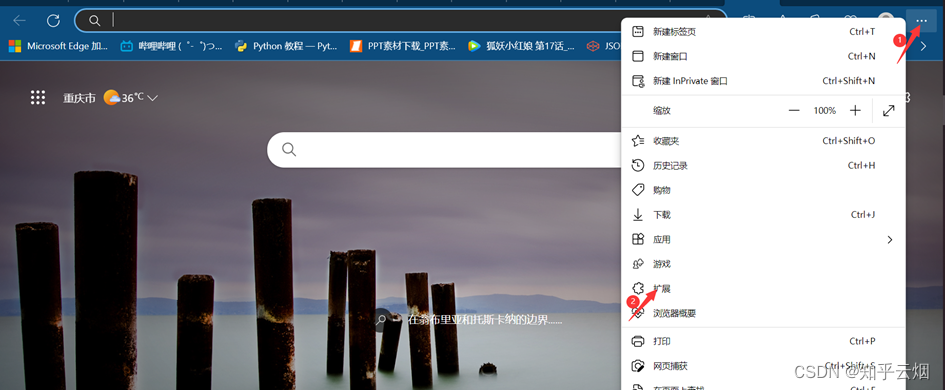
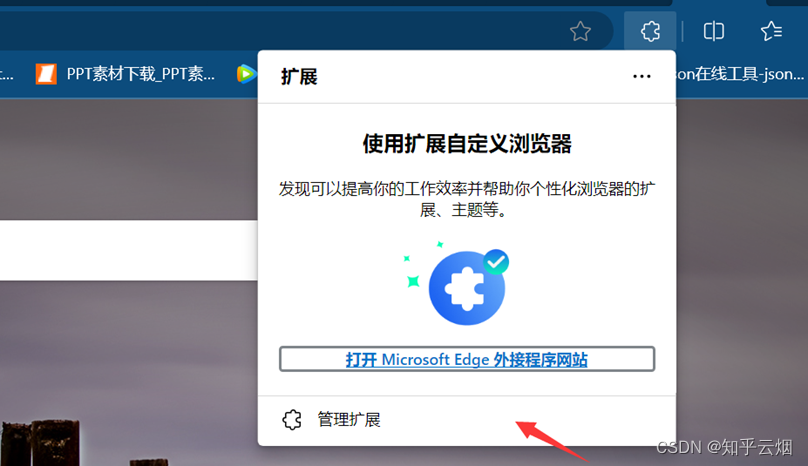
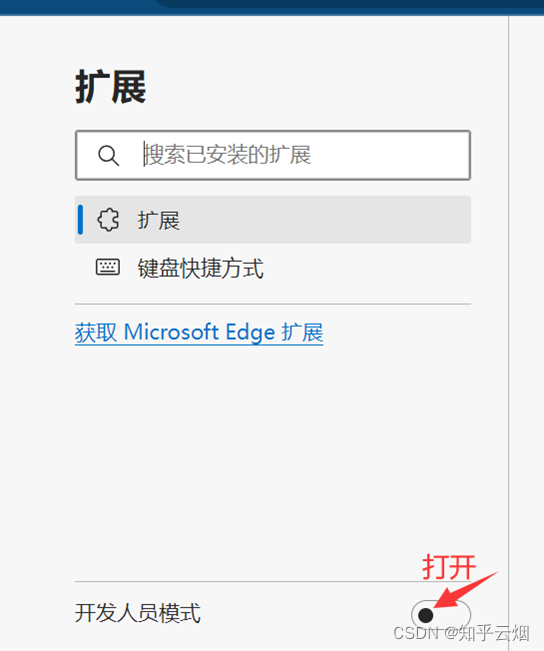
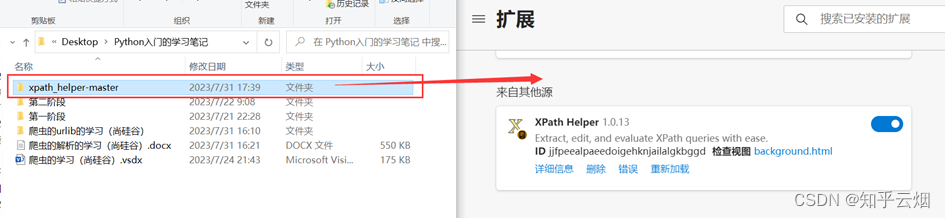
注意,安装完xpath插件后,需重新打开浏览器,进而进行使用。如下图,重新打开浏览器,随便点击一个网页,然后使用快捷键Ctr+Alt+X即可弹出一个小黑框,说明xpath安装成功。另外,关闭xpath也是使用快捷键Ctr+Alt+X。
2. xpath的基本使用
(1)xpath的使用方法与基本语法(路径查询、谓词查询、内容查询(使用text查看标签内容)、属性查询、模糊查询、逻辑运算)
xpath是用于获取网页源码部分数据的一种方式,它的使用方法如图所示,具体使用参考代码的演示。









(2)安装lxml库
使用xpath还需要到当前的项目文件里安装lxml库,具体方法如图所示(安装命令为“pip install lxml -i https://pypi.mirrors.ustc.edu.cn/simple/”)。
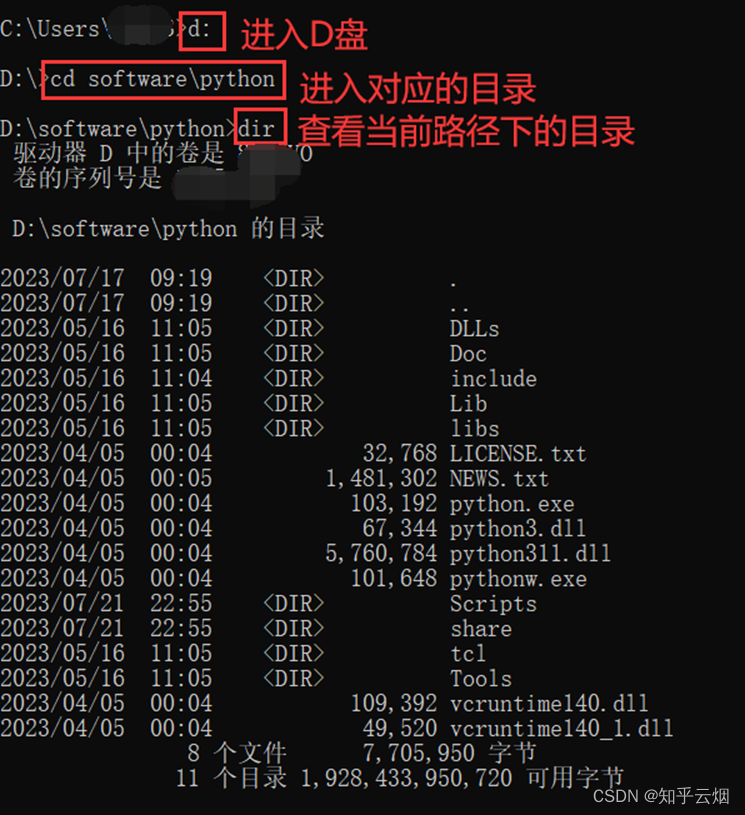



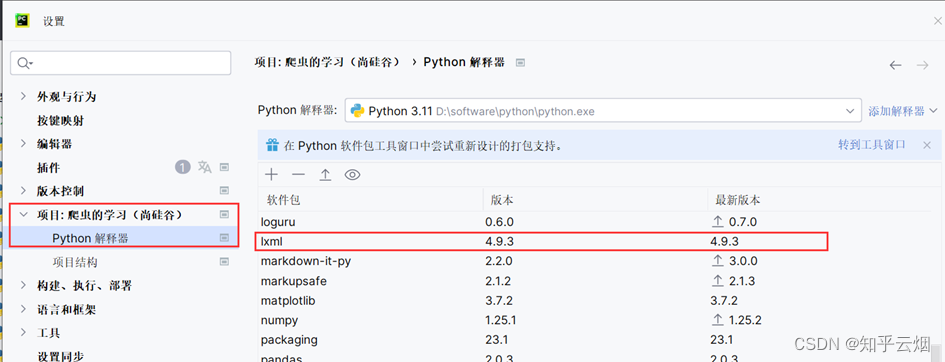
安装完成后,如下图所示,相应位置可看到对应的版本。
(3)代码的演示
如下图所示,创建两个文件夹,名为“爬虫的urlib”和“爬虫的解析”,然后按住Ctr不放,选中之前的文件,并利用快捷键Ctr+X与Ctr+V将它们移到文件夹“爬虫的urlib”中。
如下图,在文件夹“爬虫的解析”中创建文件“070_xpath的基本使用.py”。
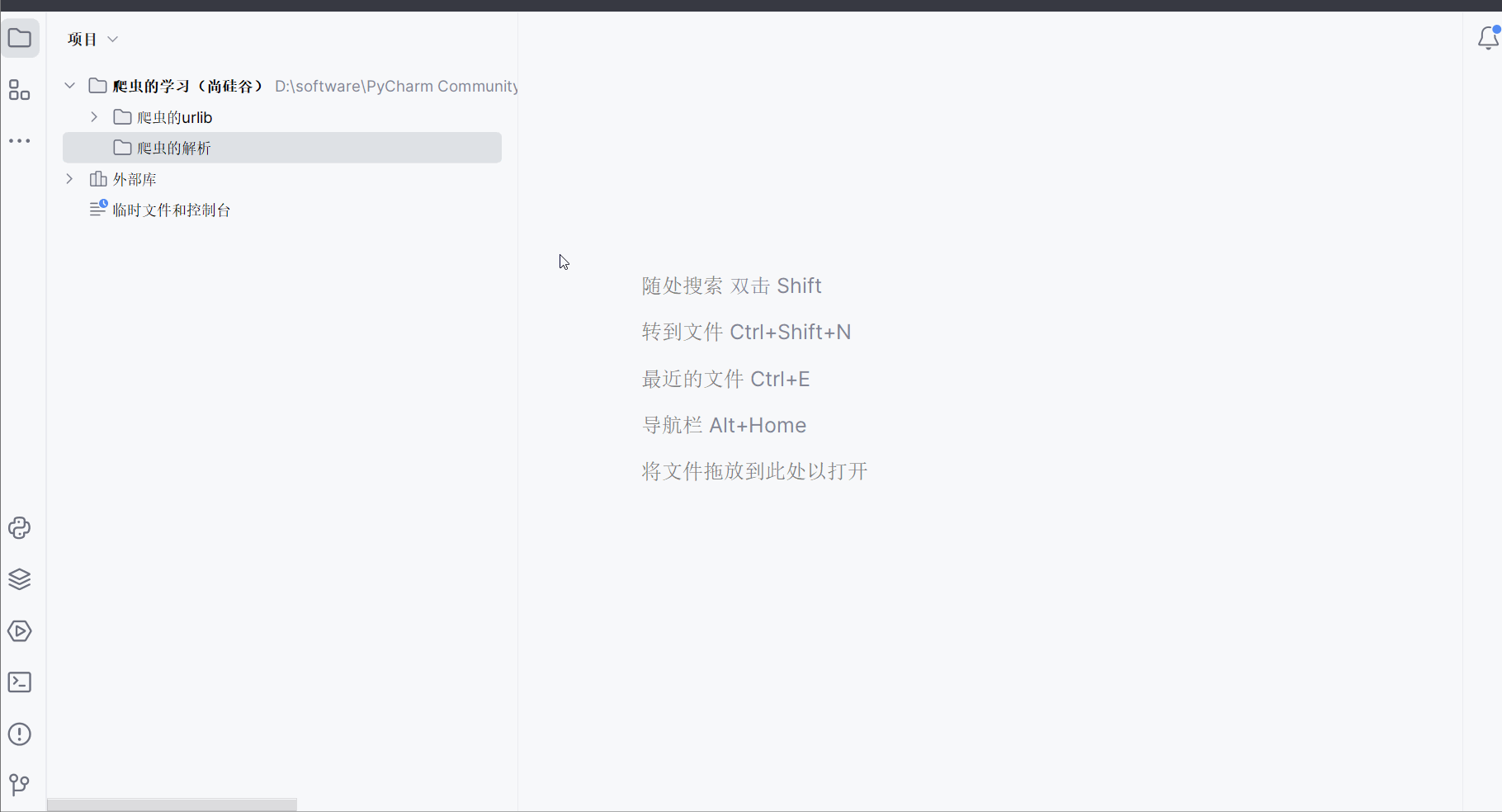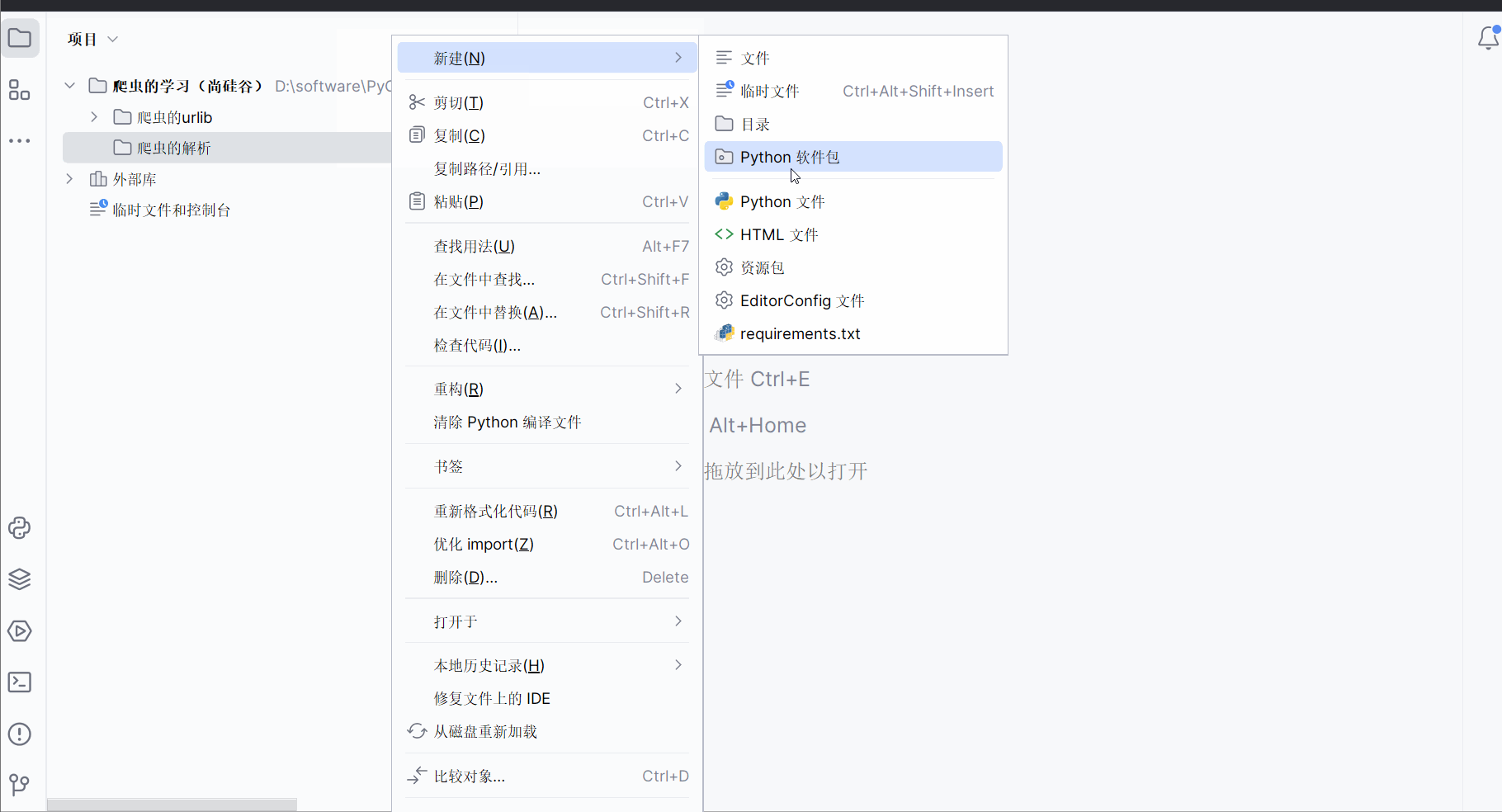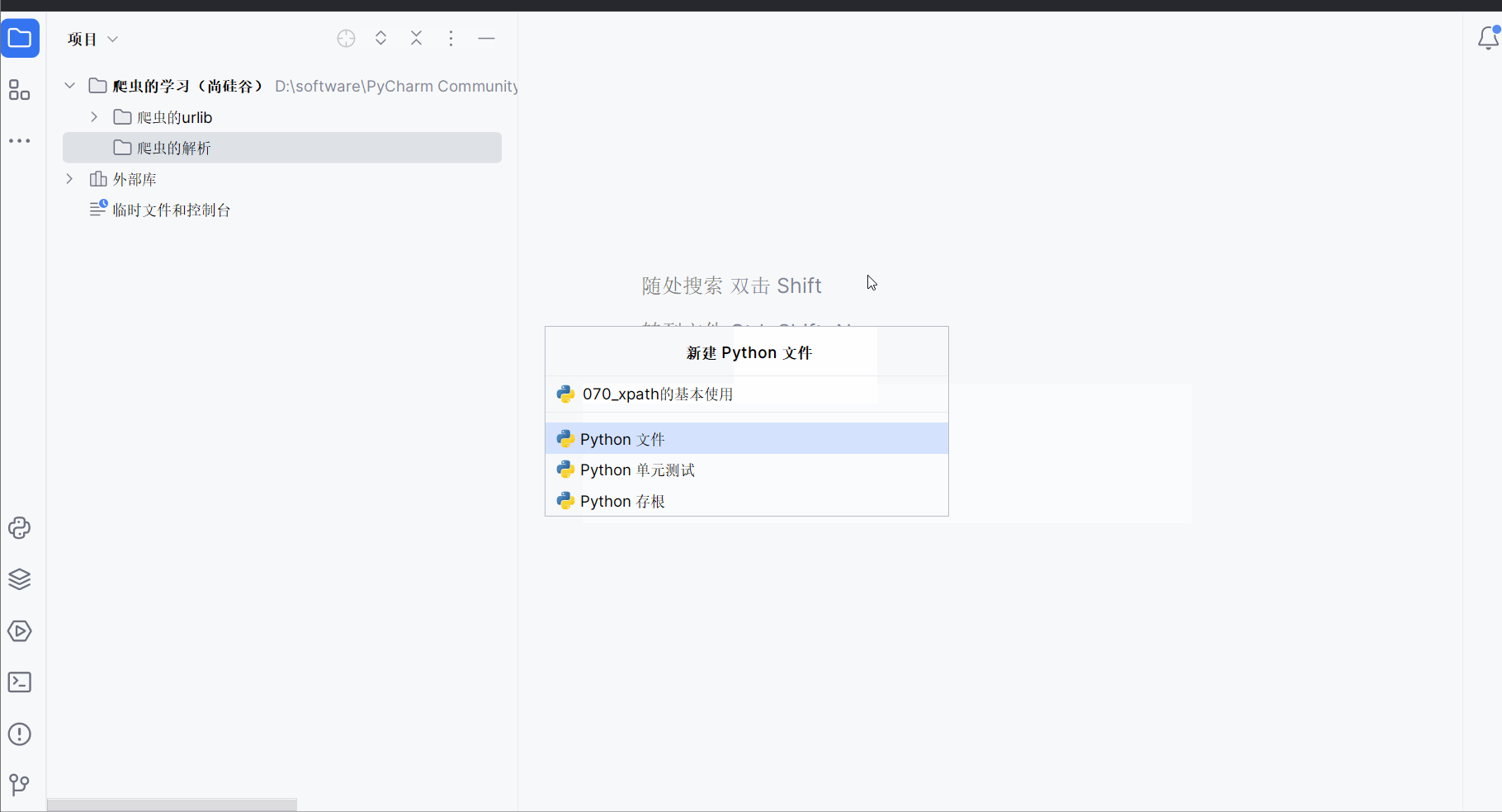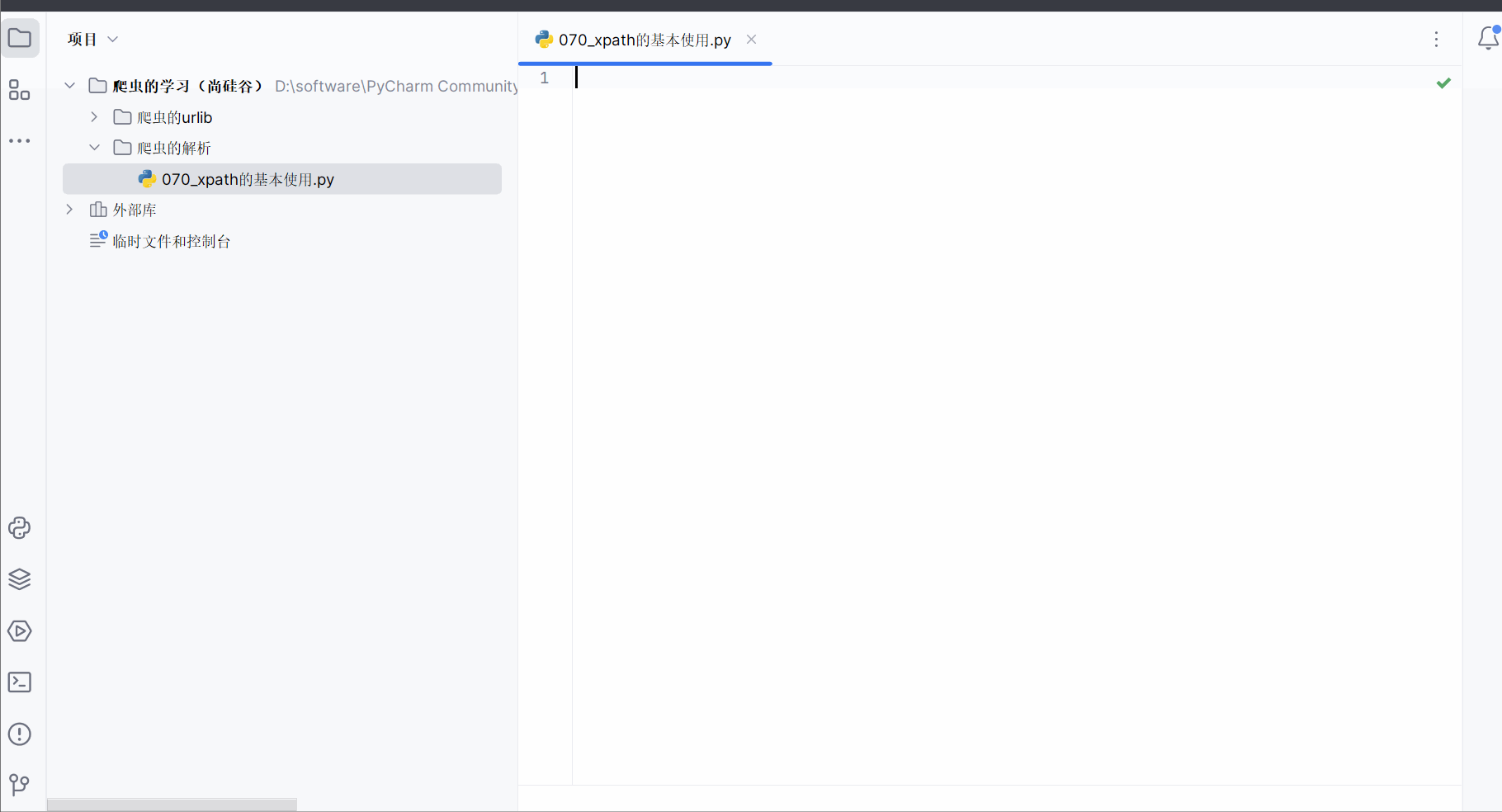
由于本次需要演示xpath解析本地文件以及服务器响应的数据(其实本节没有涉及解析服务器响应的数据,是下一节的内容,不过序号都写上并且截图了,懒得改了),故如下图,创建一个名为“070_xpath的基本使用”的html文件。

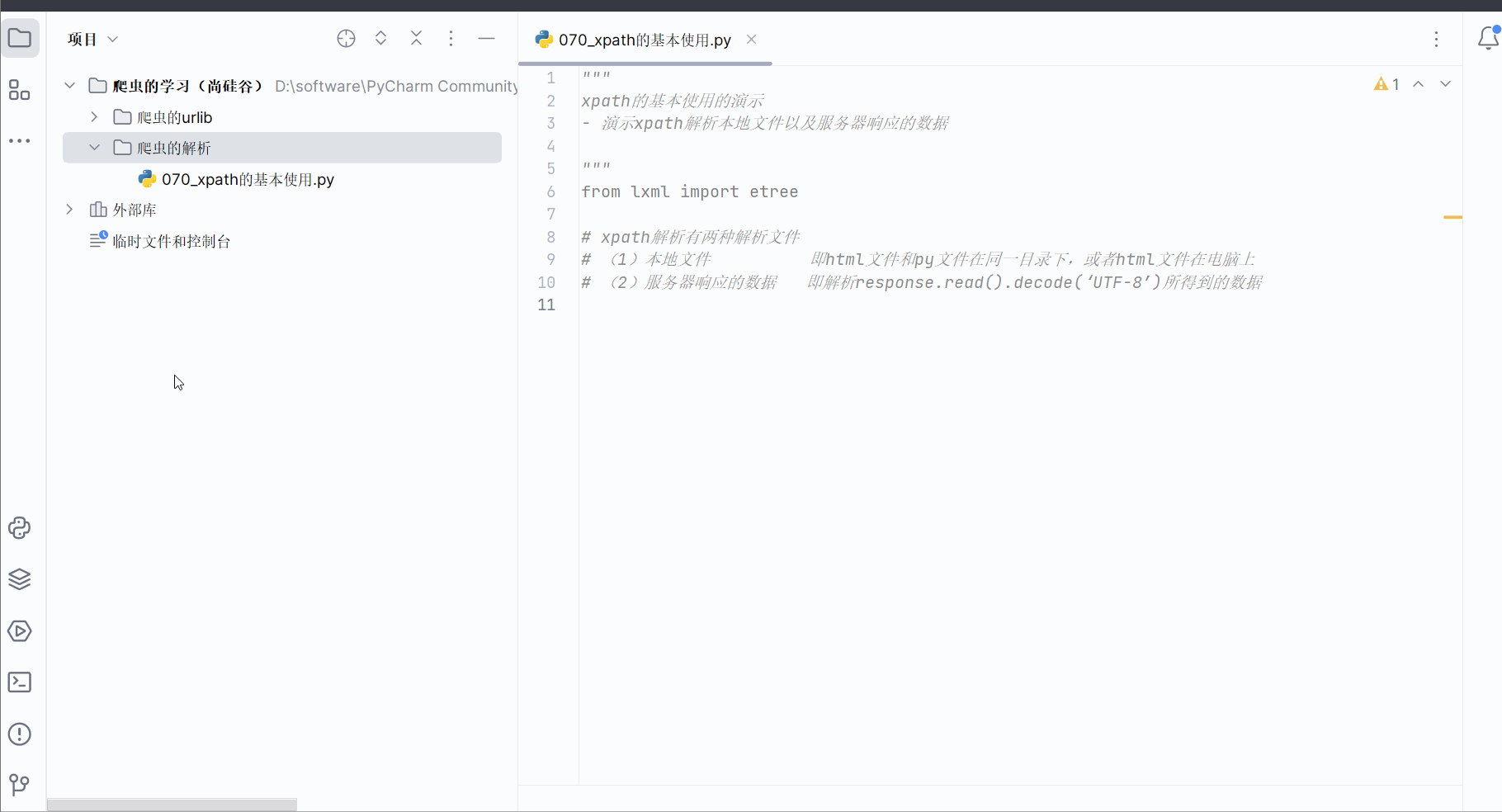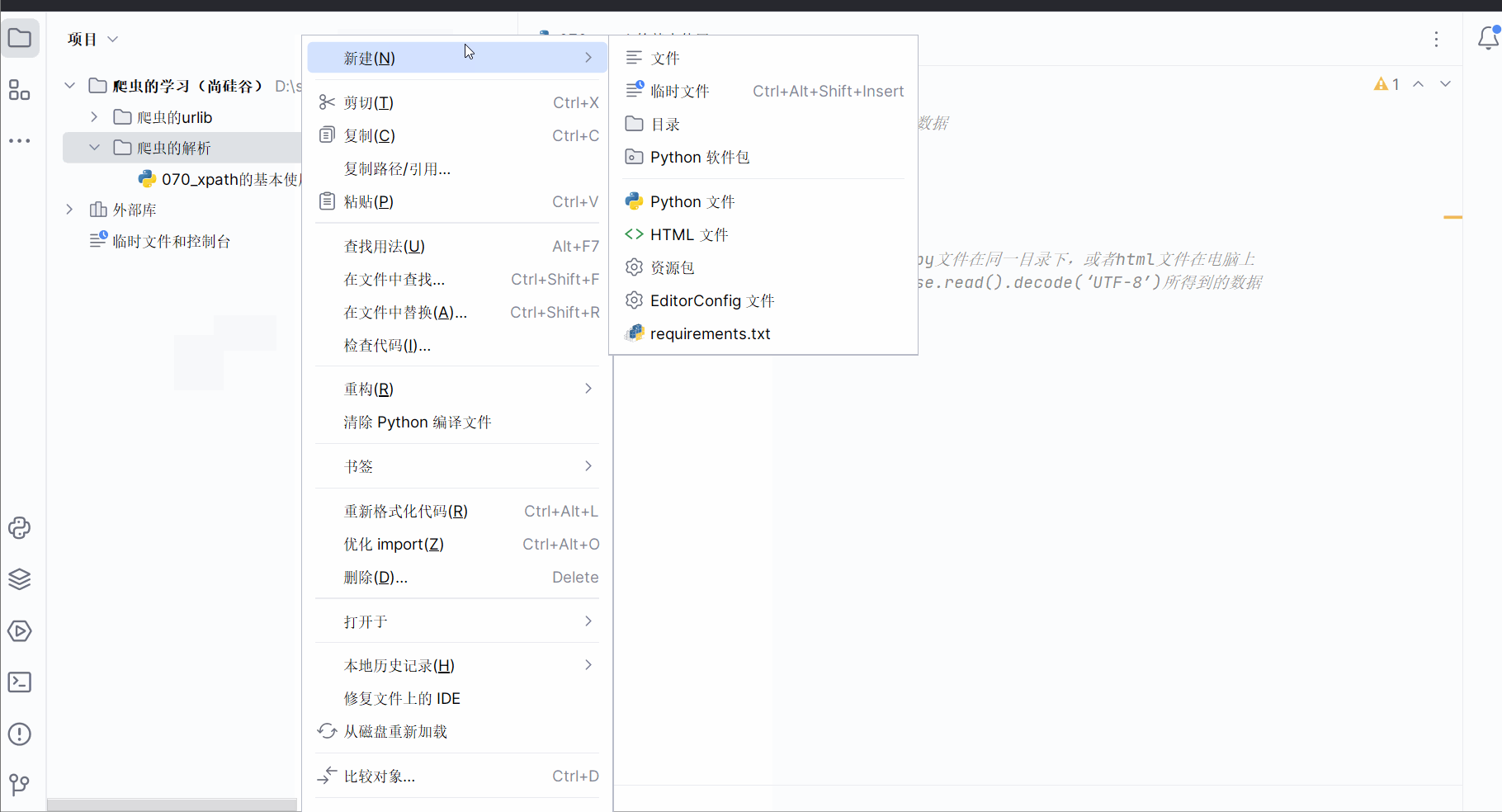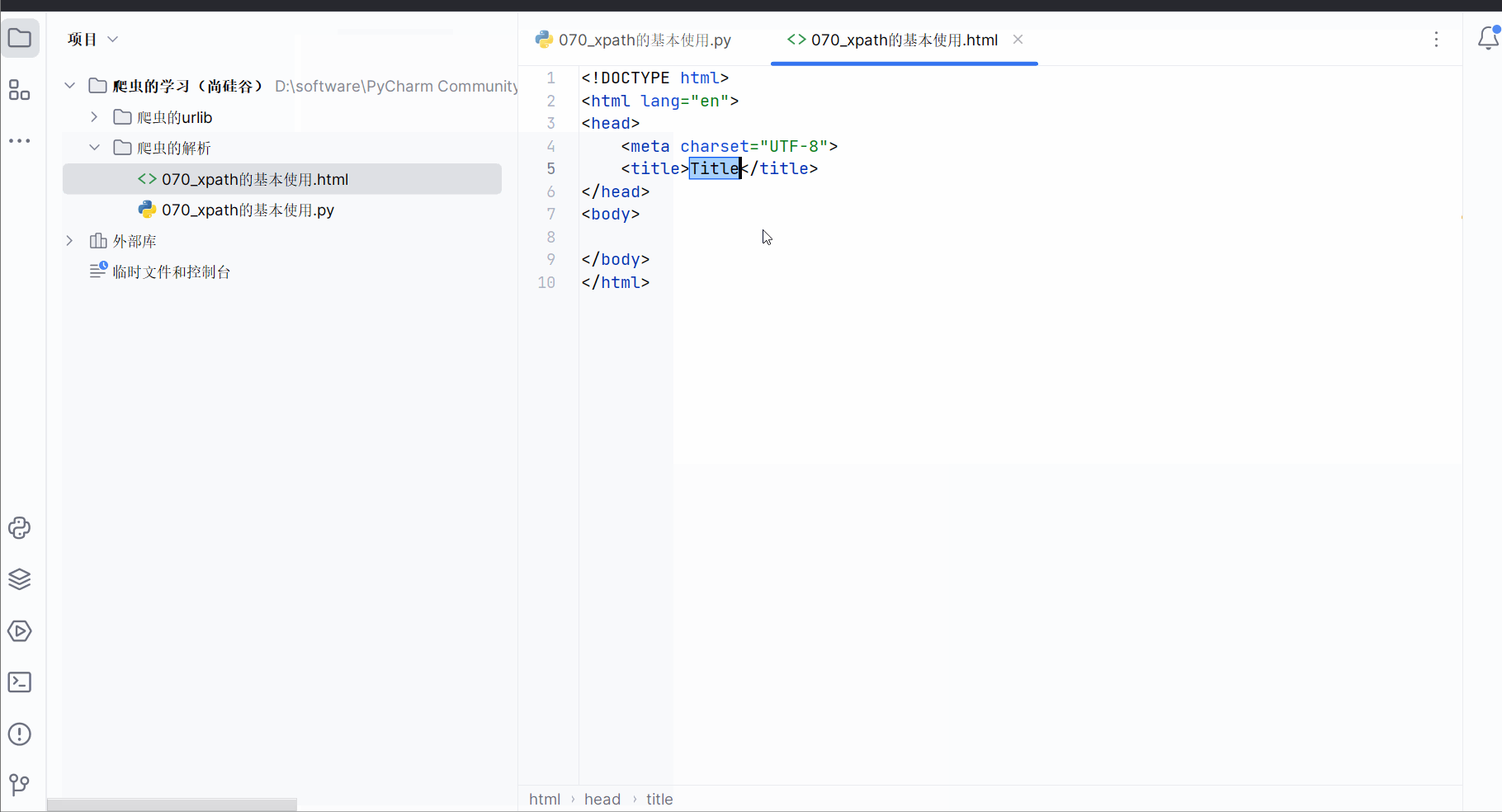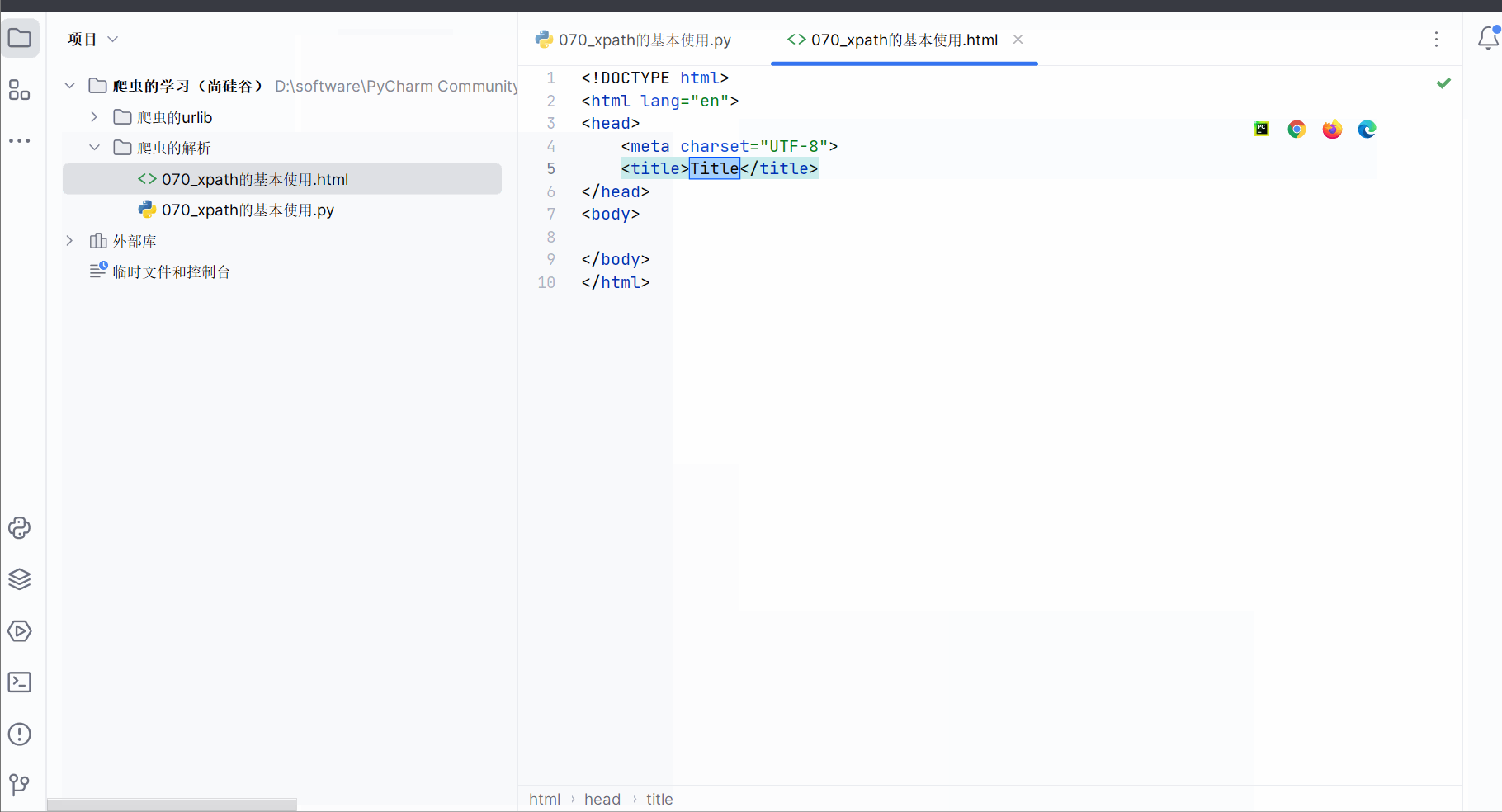
在名为“070_xpath的基本使用”的html文件中输入如下代码,假设本次需要获“北京、上海、深圳、武汉”这几个城市。注意:xpath解析严格遵守html规范,meta也需要成对出现,故需要加上“/”表示结束。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li>北京</li><li>上海</li><li>深圳</li><li>武汉</li></ul><ul><li>大连</li><li>锦州</li><li>沈阳</li></ul>
</body>
</html>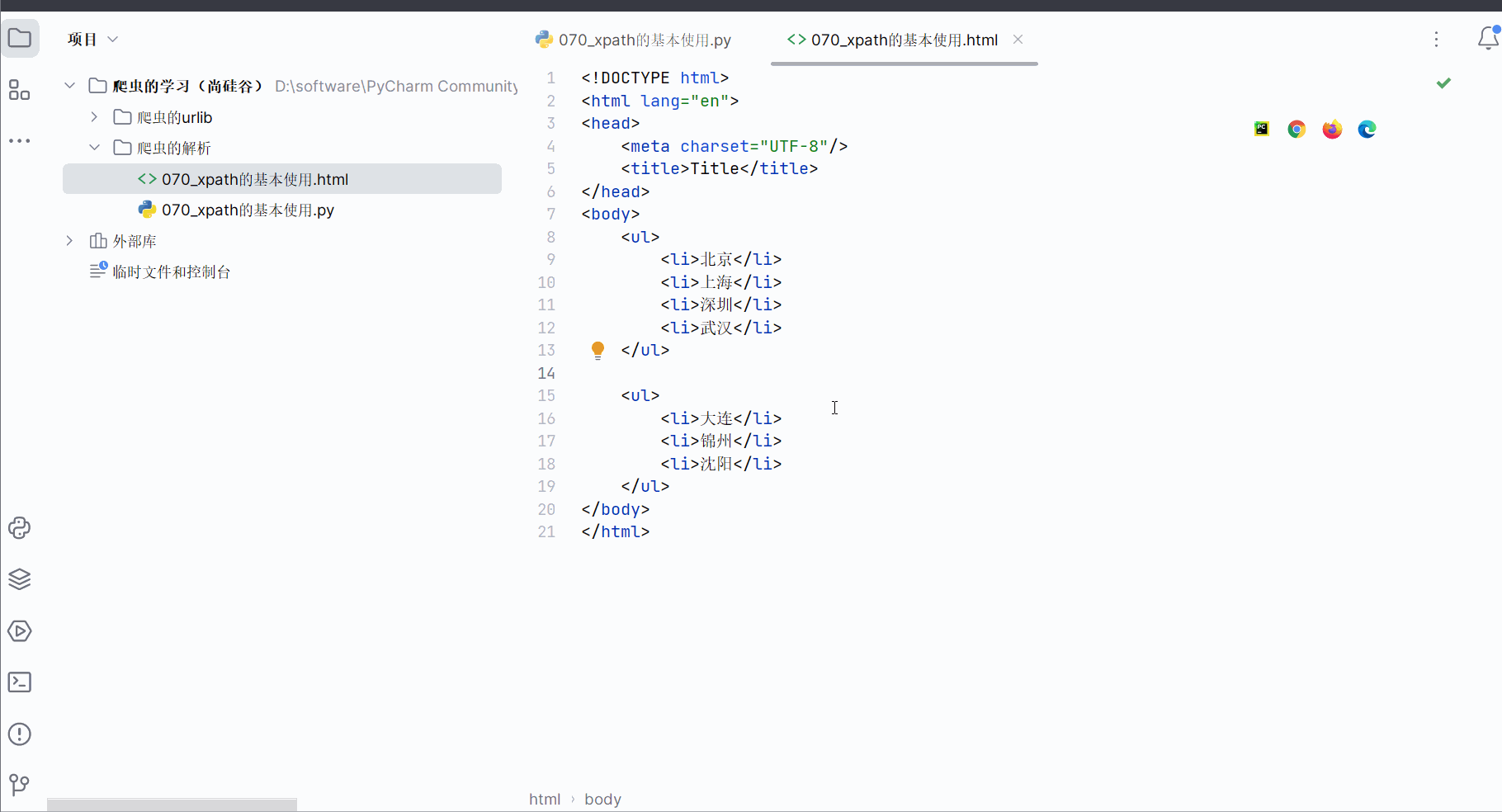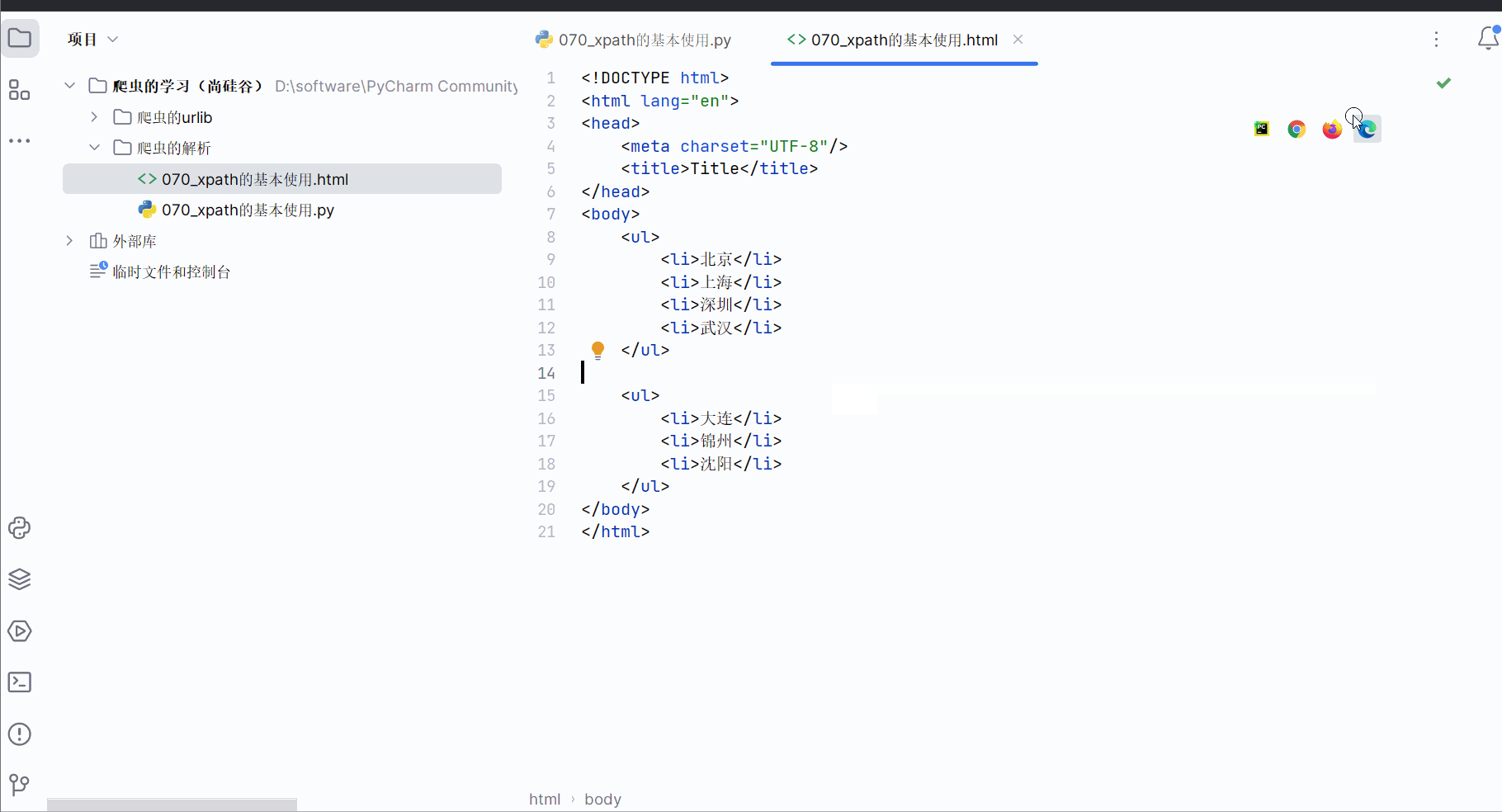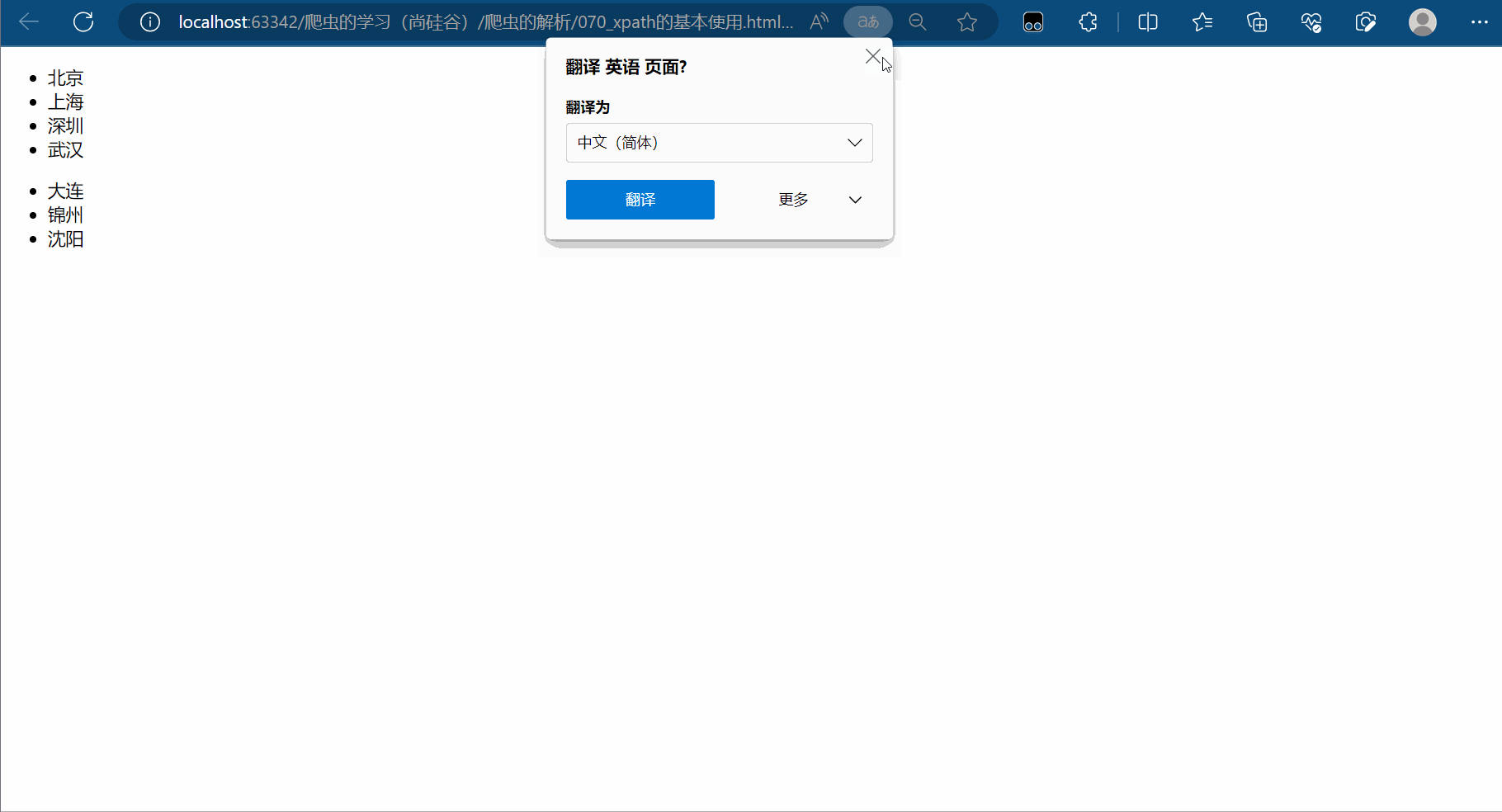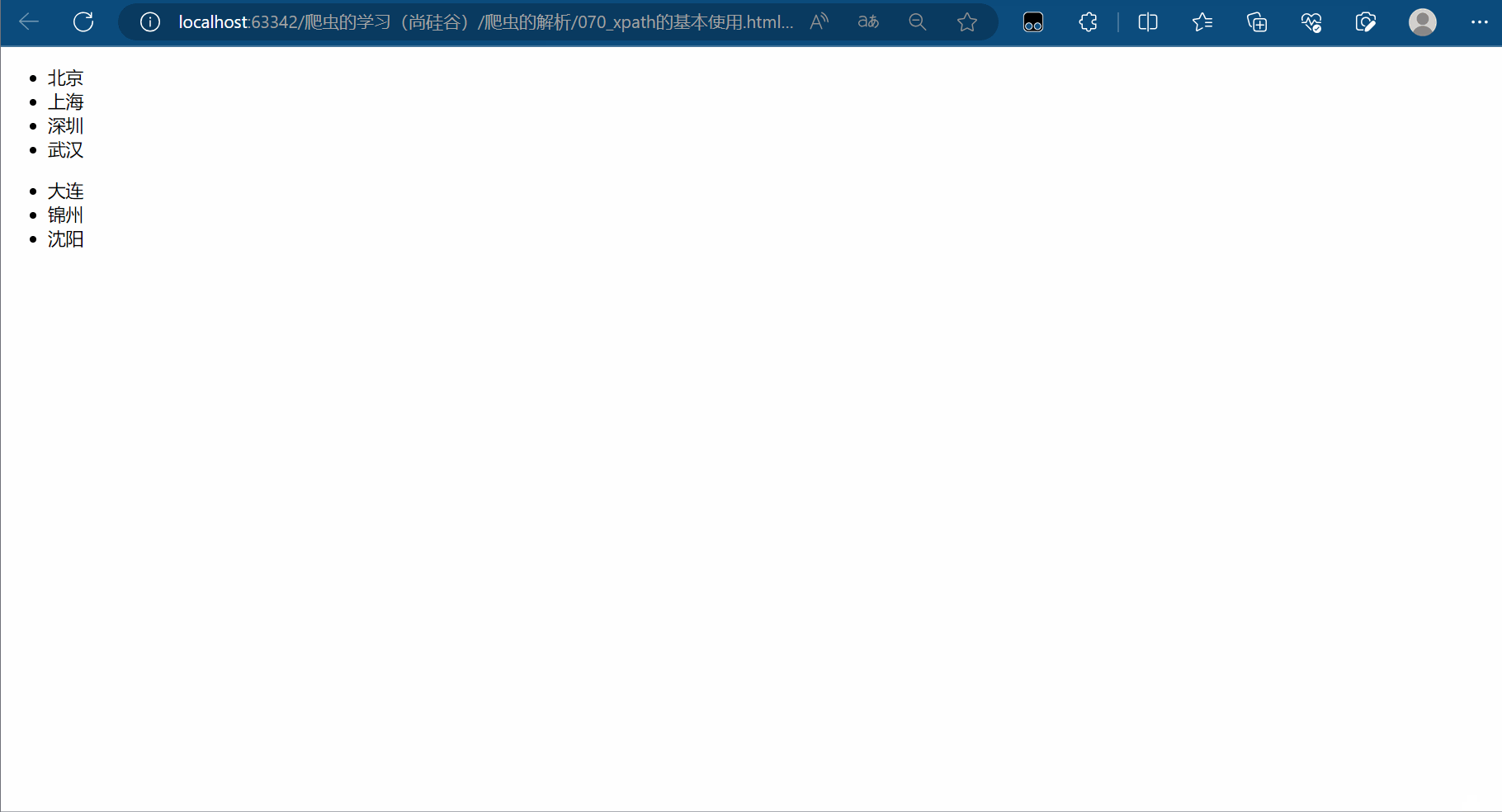
编辑代码并运行,学习路径查询的语法。
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# 1.1 路径查询 tree.xpath('xpath路径')
li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li
print(li_list)
print(len(li_list))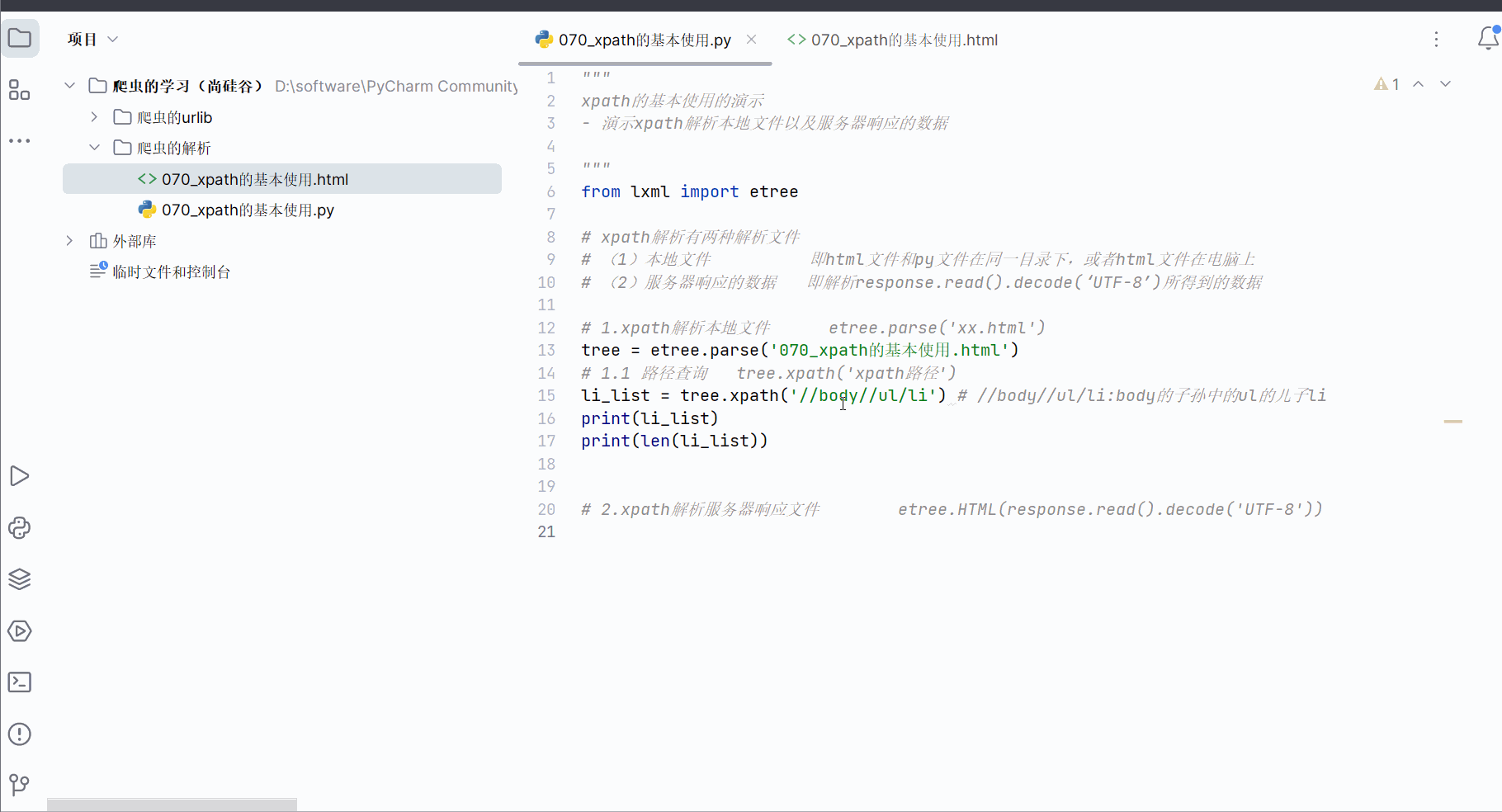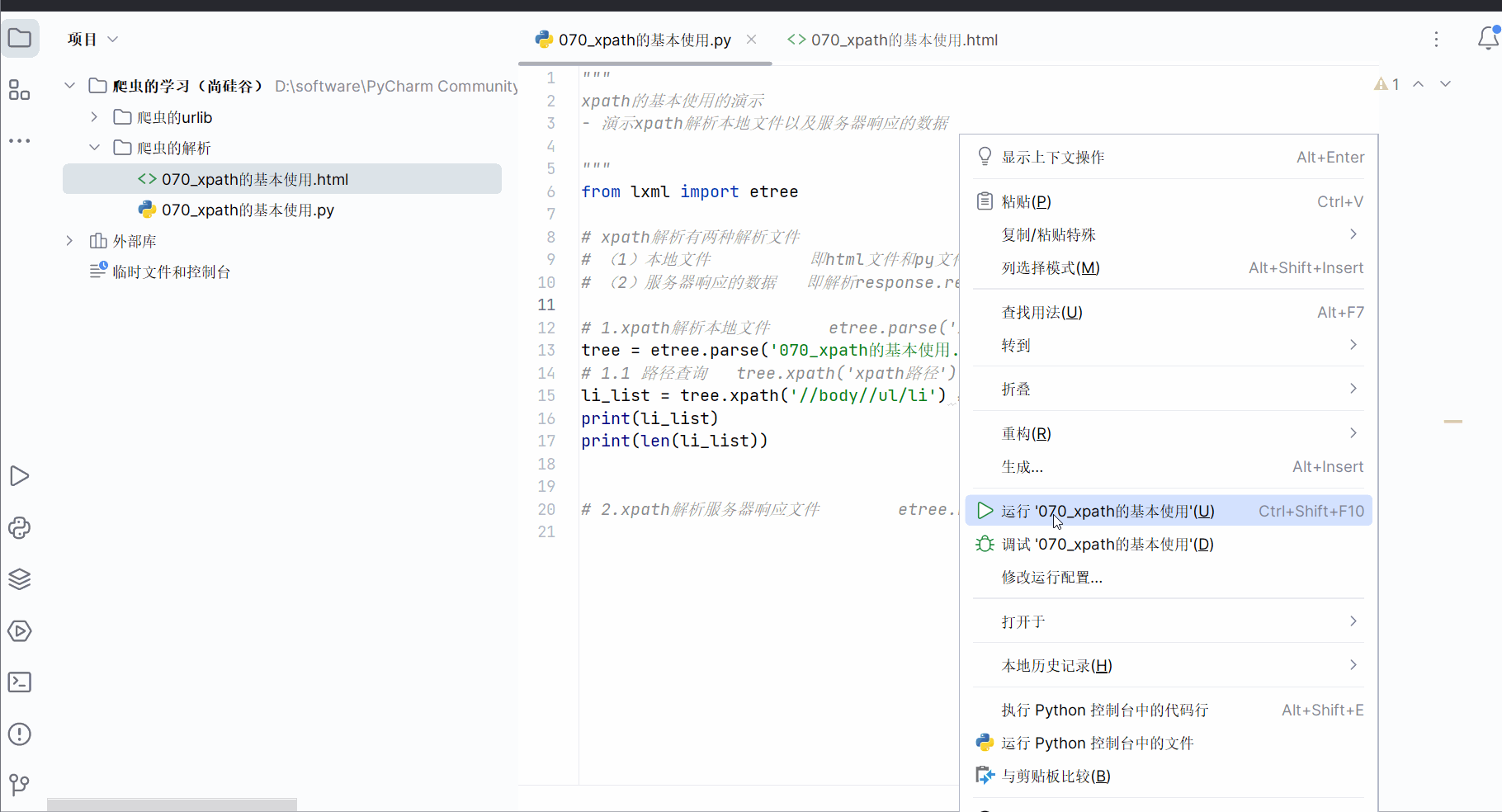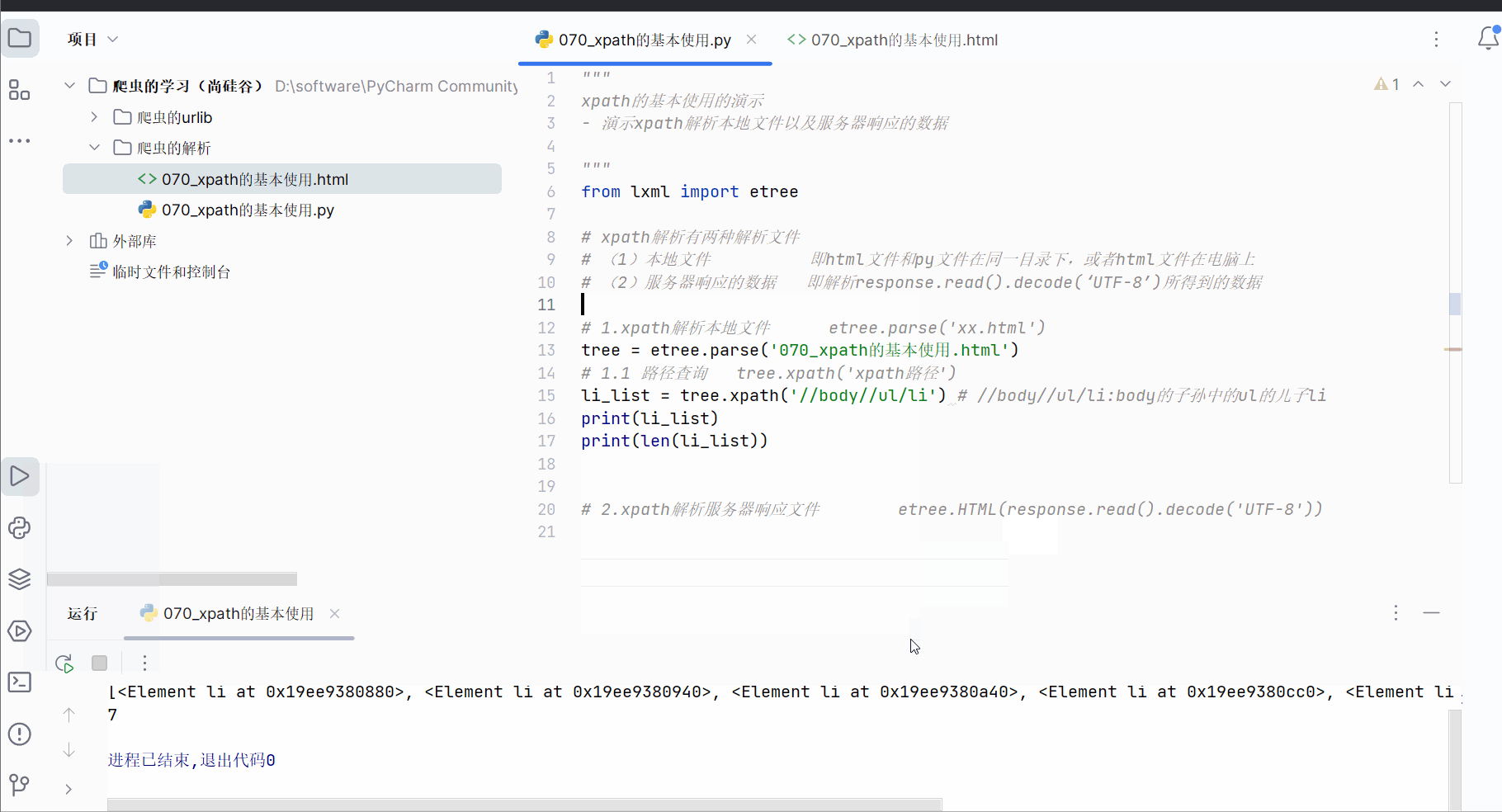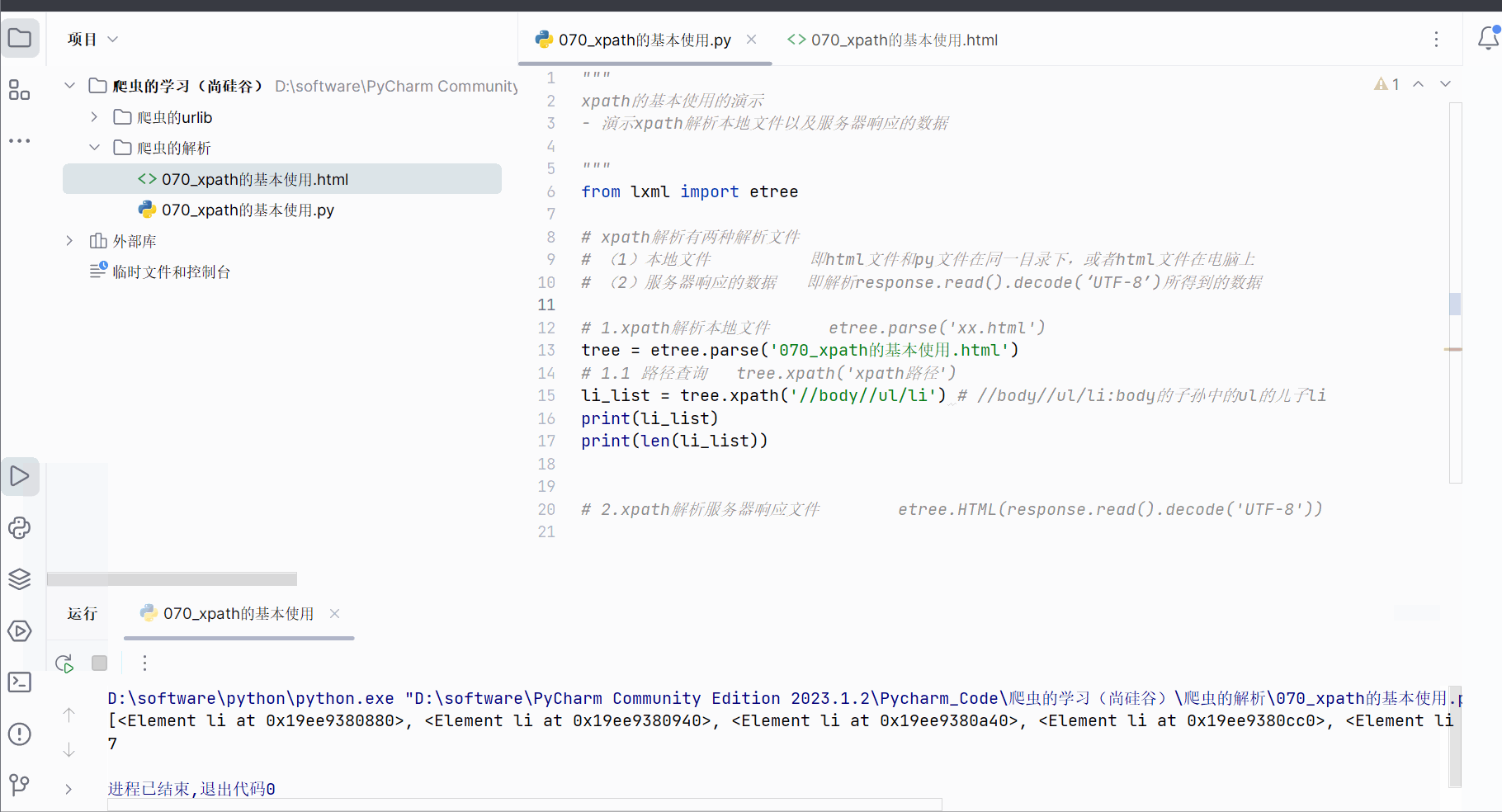
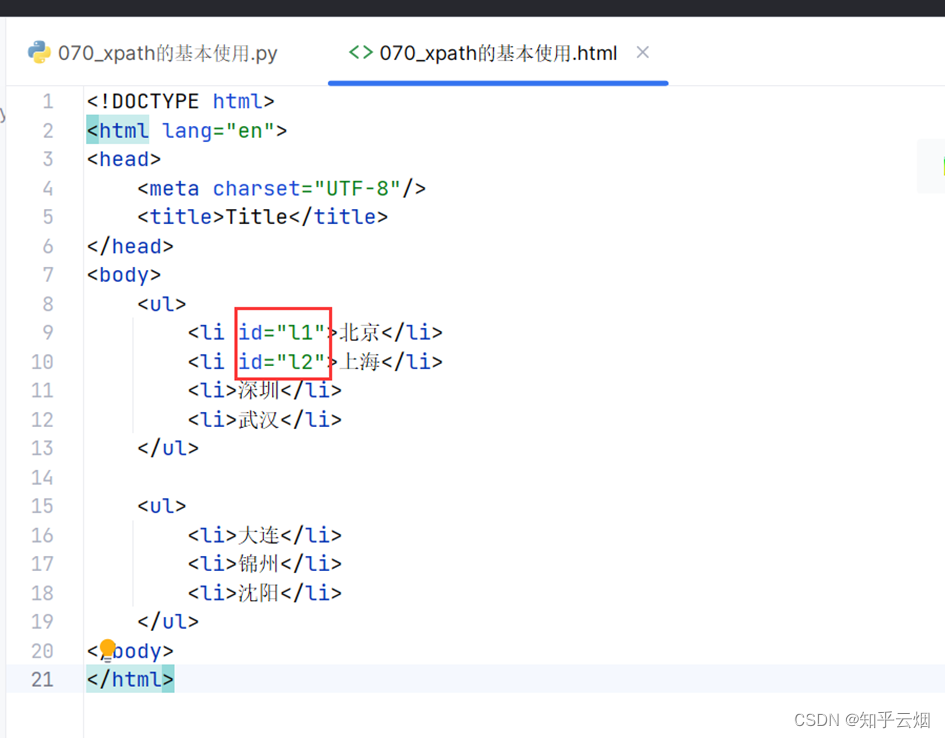
如下图,在html文件中给两个城市各加一个id。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="l1">北京</li><li id="l2">上海</li><li>深圳</li><li>武汉</li></ul><ul><li>大连</li><li>锦州</li><li>沈阳</li></ul>
</body>
</html>编辑代码并运行,学习谓词查询的语法。
"""
xpath的基本使用的演示
- 演示xpath解析本地文件以及服务器响应的数据"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
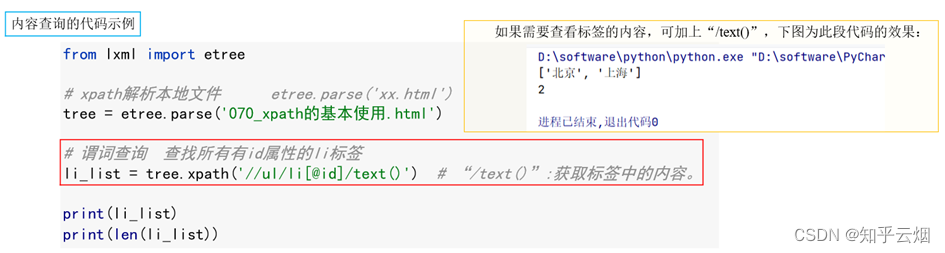
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询 查找所有有id属性的li标签
li_list = tree.xpath('//ul/li[@id]')
print(li_list)
print(len(li_list))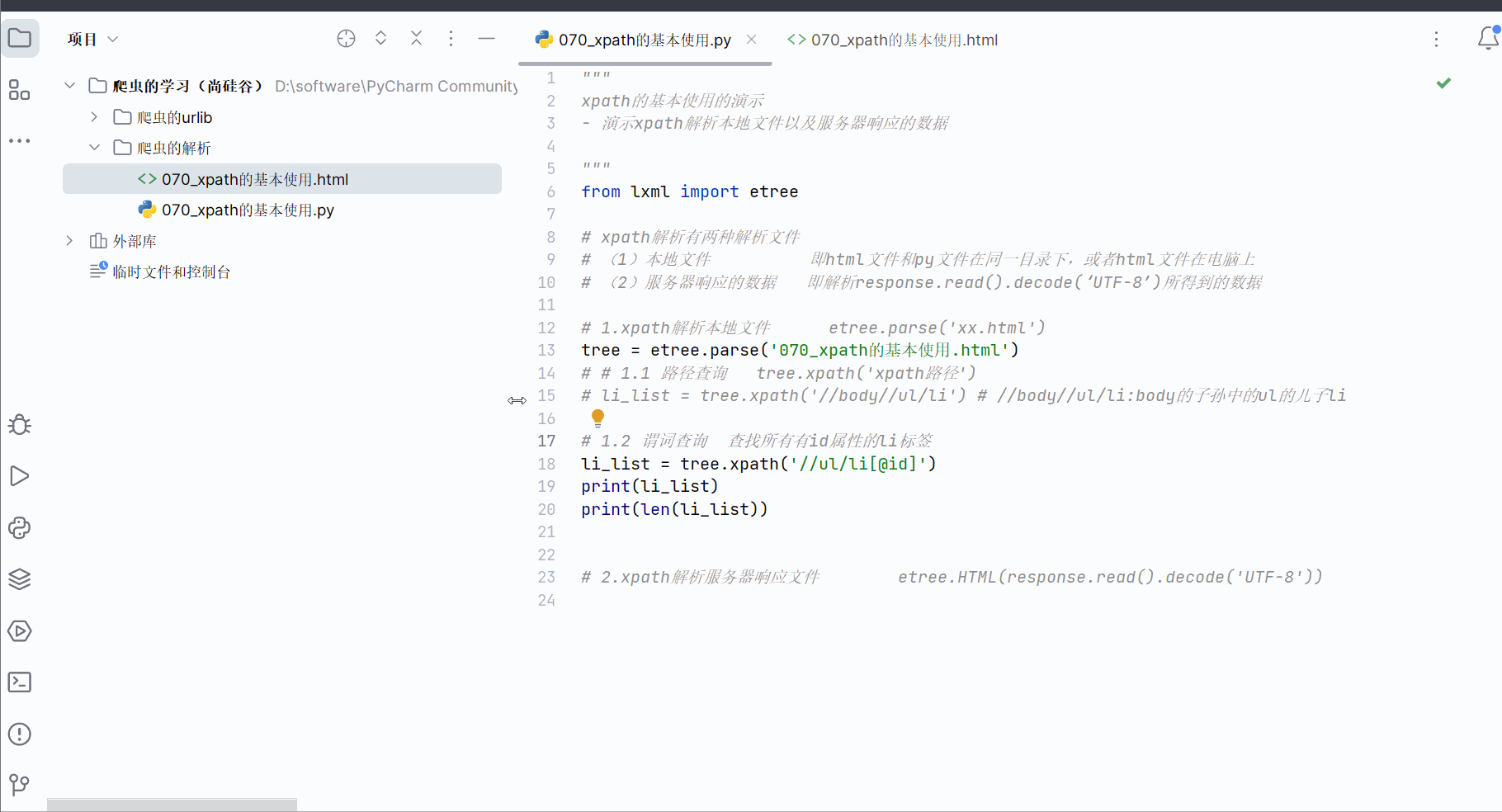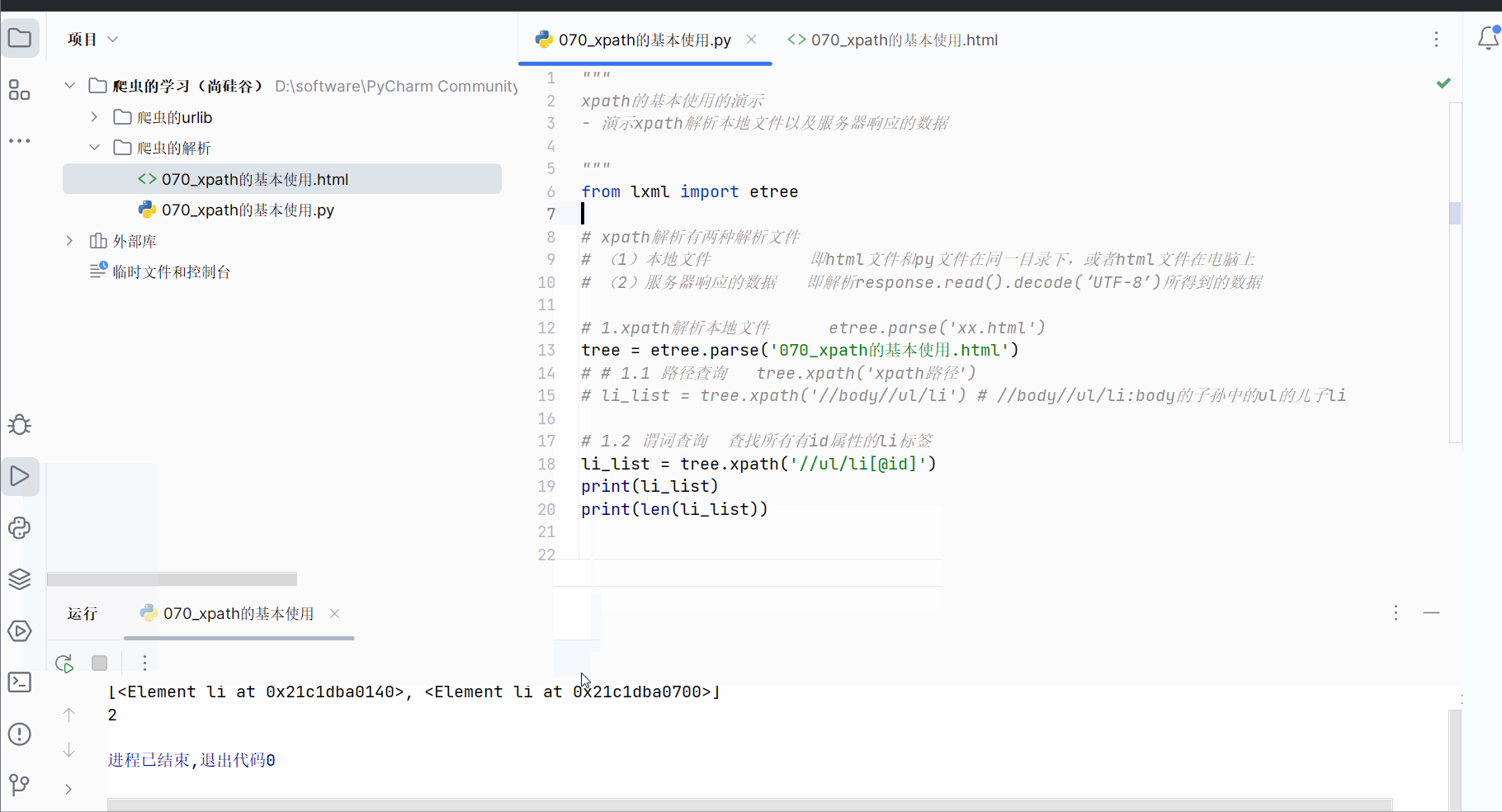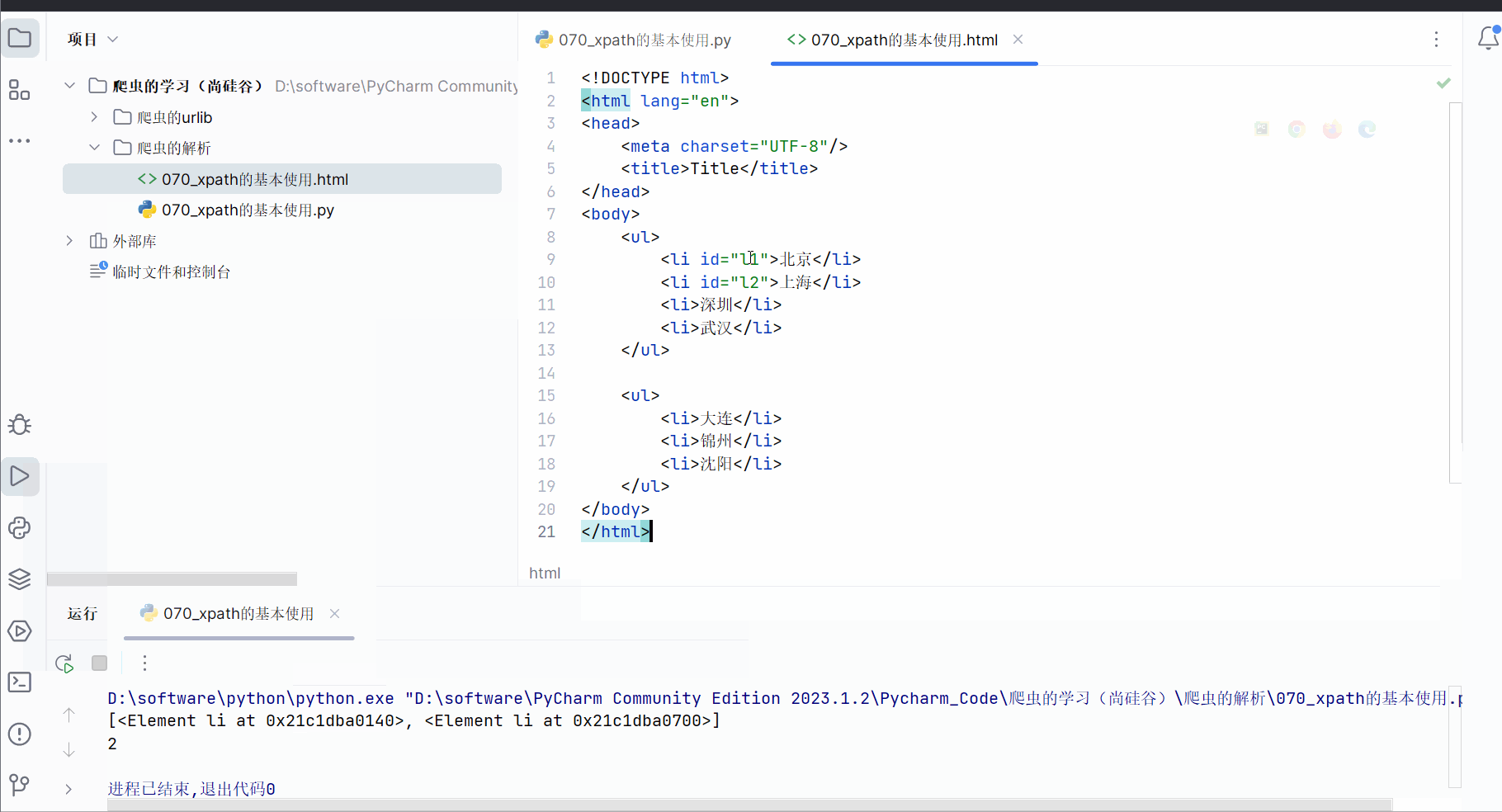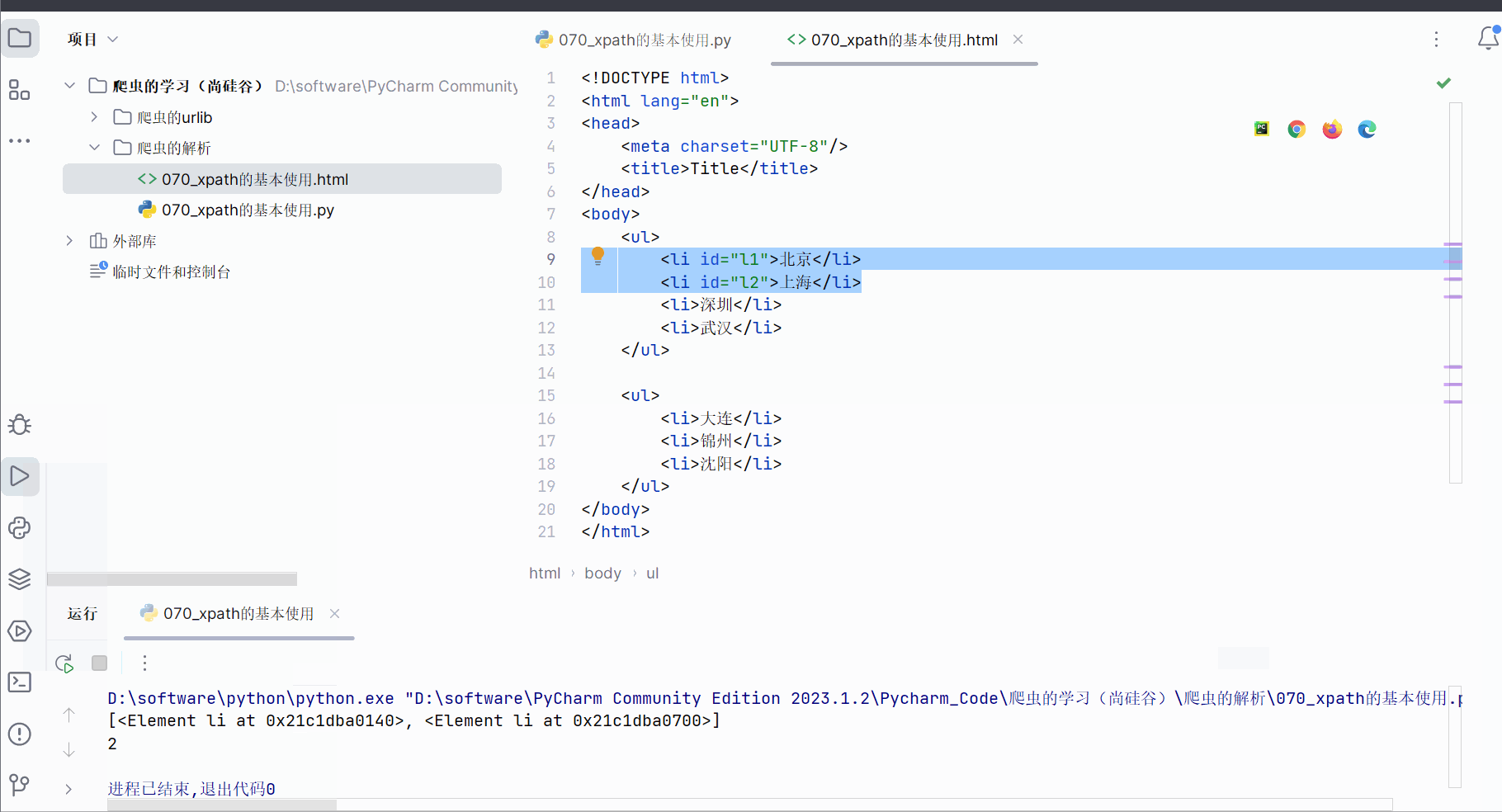
如果需要查看标签的内容,可加上“/text()”。
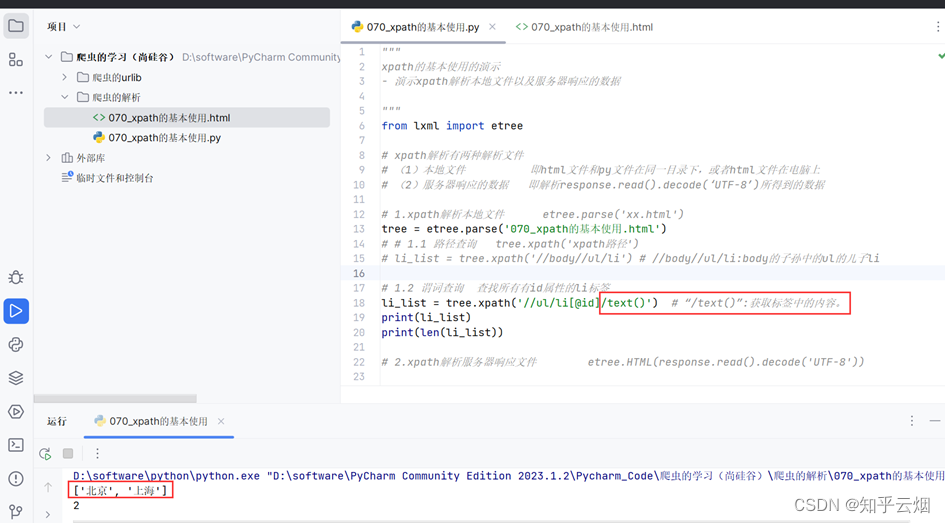
为了找到id为“l1”的li标签,继续使用谓词查询。
"""
xpath的基本使用的演示
- 演示xpath解析本地文件以及服务器响应的数据"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询
# # 查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]/text()') # “/text()”:获取标签中的内容。
# 找到id为“l1”的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)
print(len(li_list))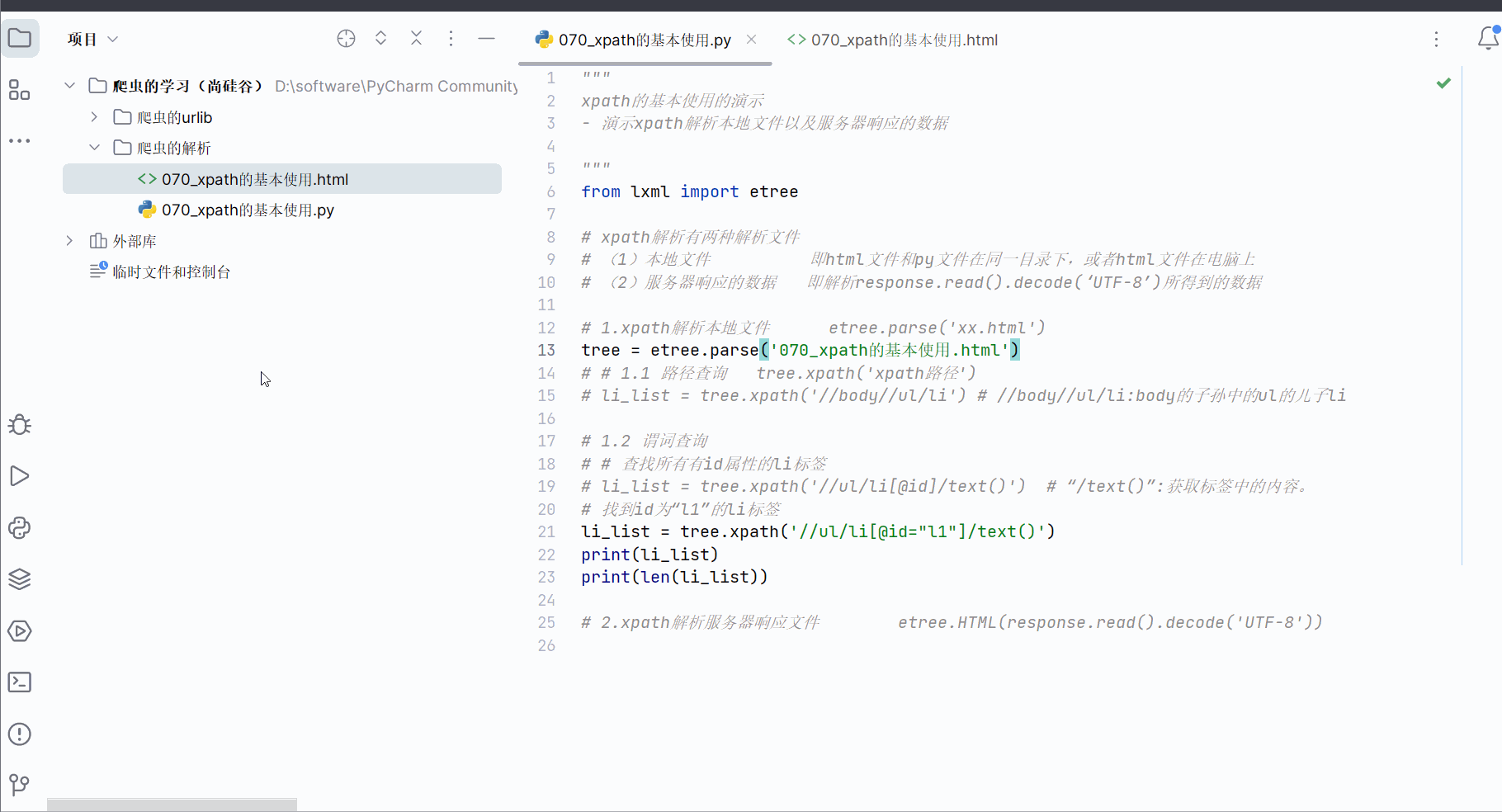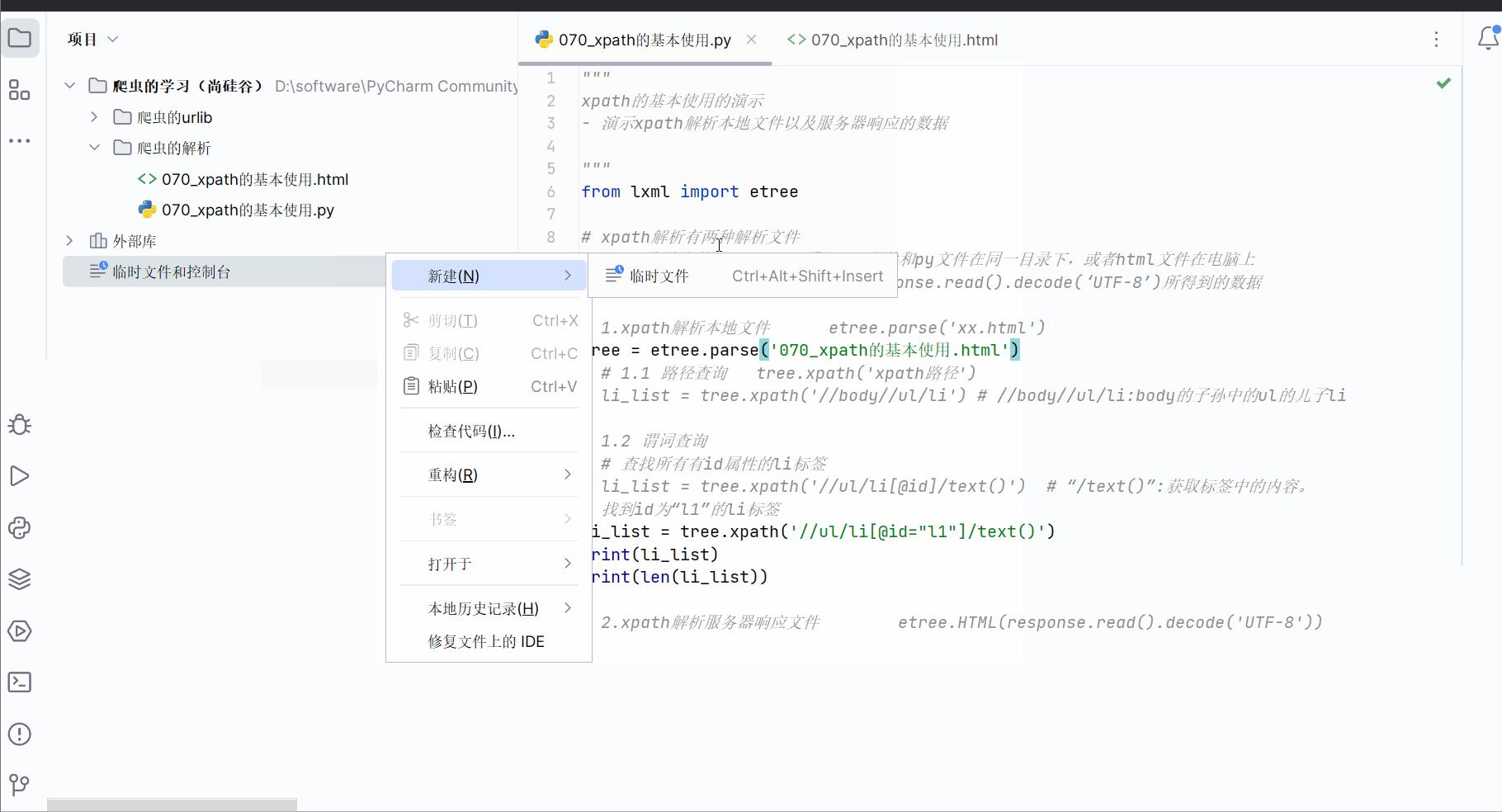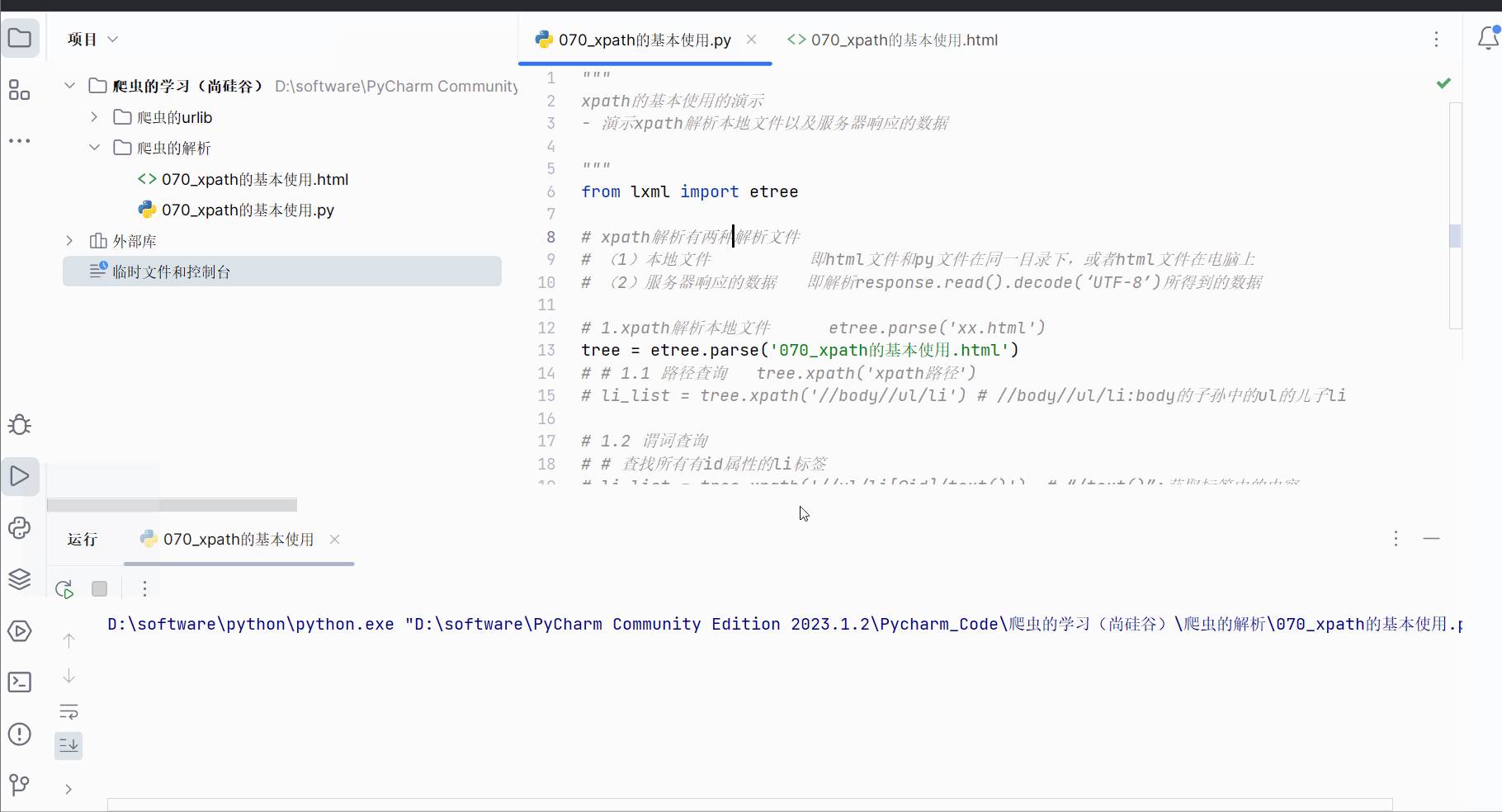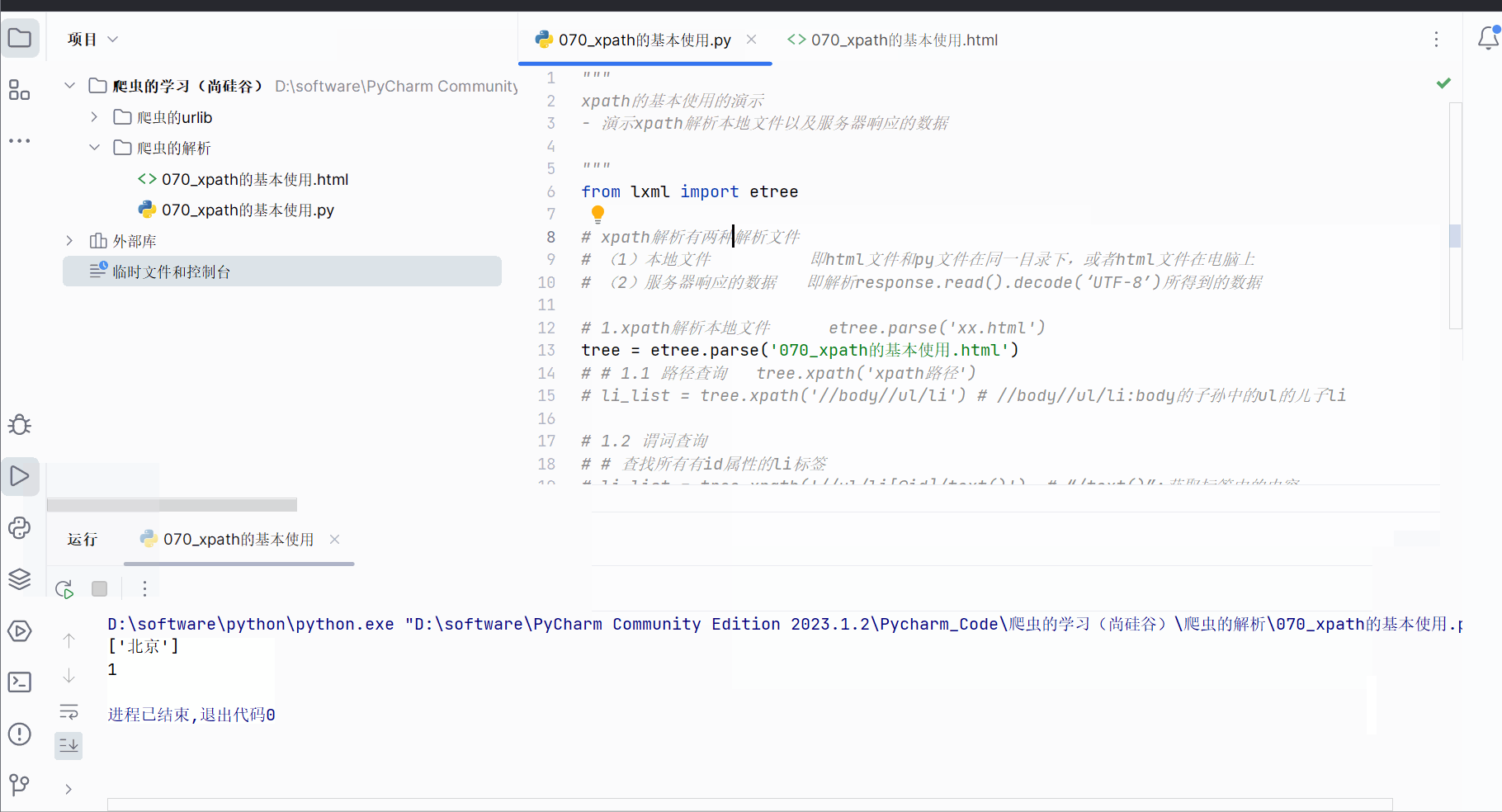
在html文件里添加一个li的class的属性值。
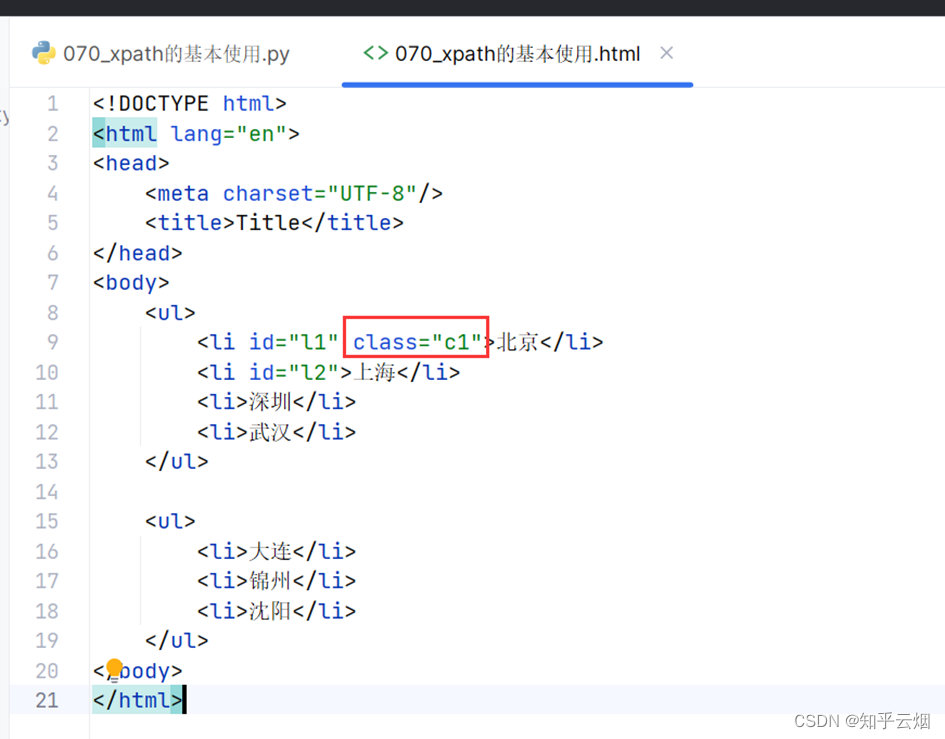
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="l1" class="c1">北京</li><li id="l2">上海</li><li>深圳</li><li>武汉</li></ul><ul><li>大连</li><li>锦州</li><li>沈阳</li></ul>
</body>
</html>然后进行编程,使用属性查询,查找到id为“l1”的li标签的class的属性值。
"""
xpath的基本使用的演示
- 演示xpath解析本地文件以及服务器响应的数据"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询
# # 查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]/text()') # “/text()”:获取标签中的内容。
# 找到id为“l1”的li标签 注意引号的问题
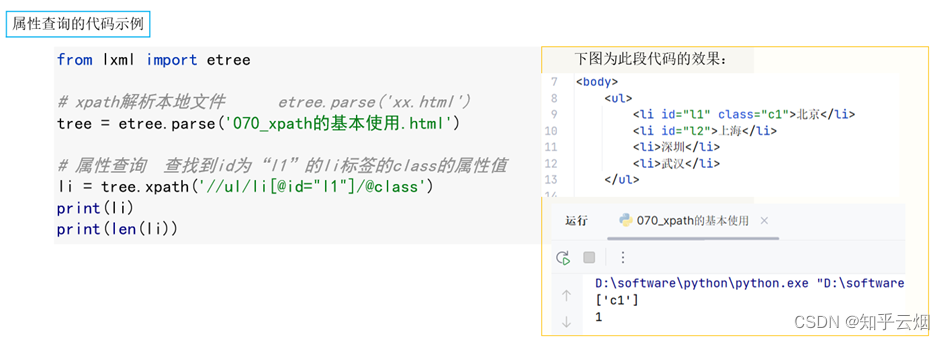
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')# 1.3 属性查询 查找到id为“l1”的li标签的class的属性值
li = tree.xpath('//ul/li[@id="l1"]/@class')
print(li)
print(len(li))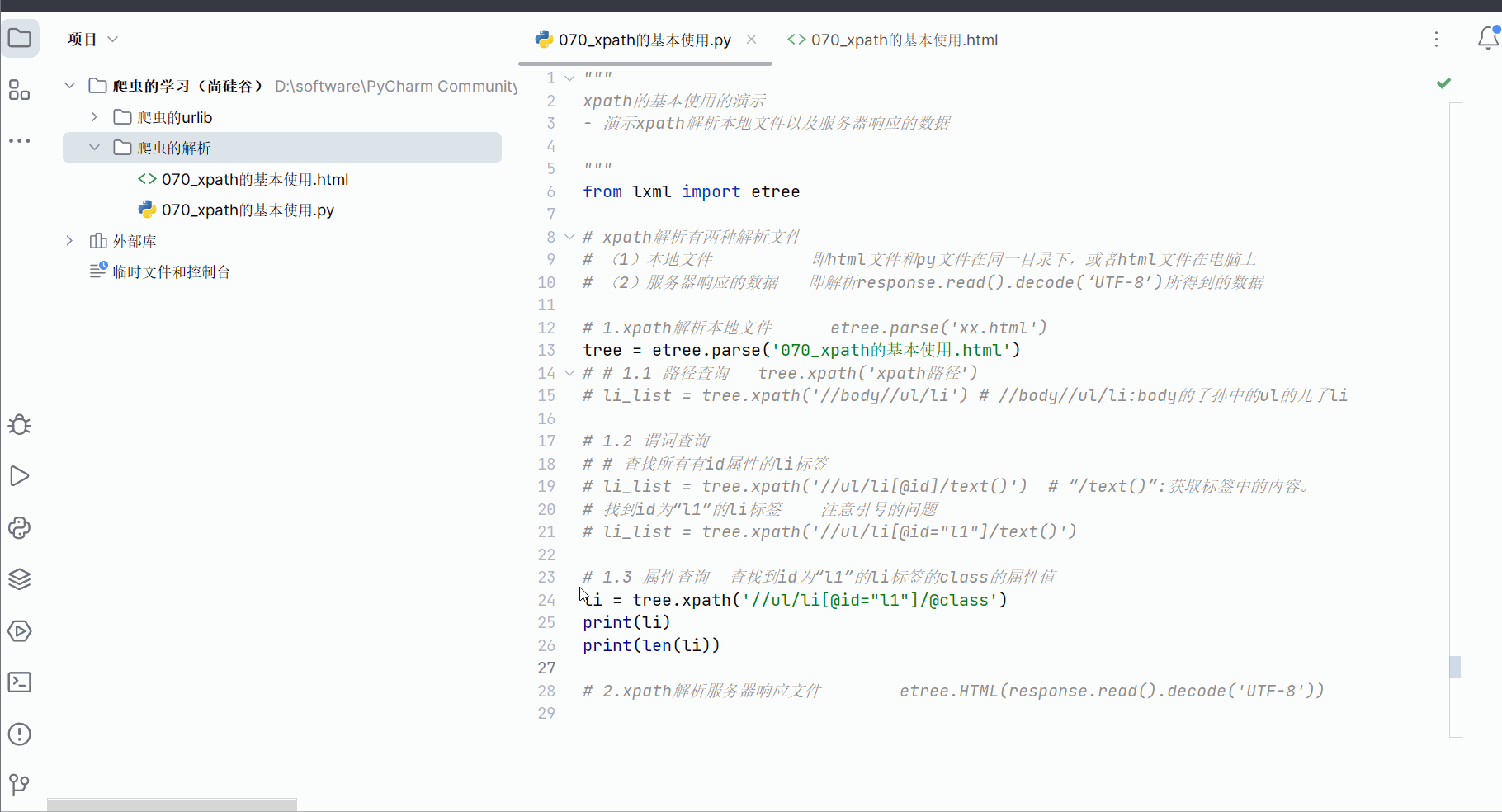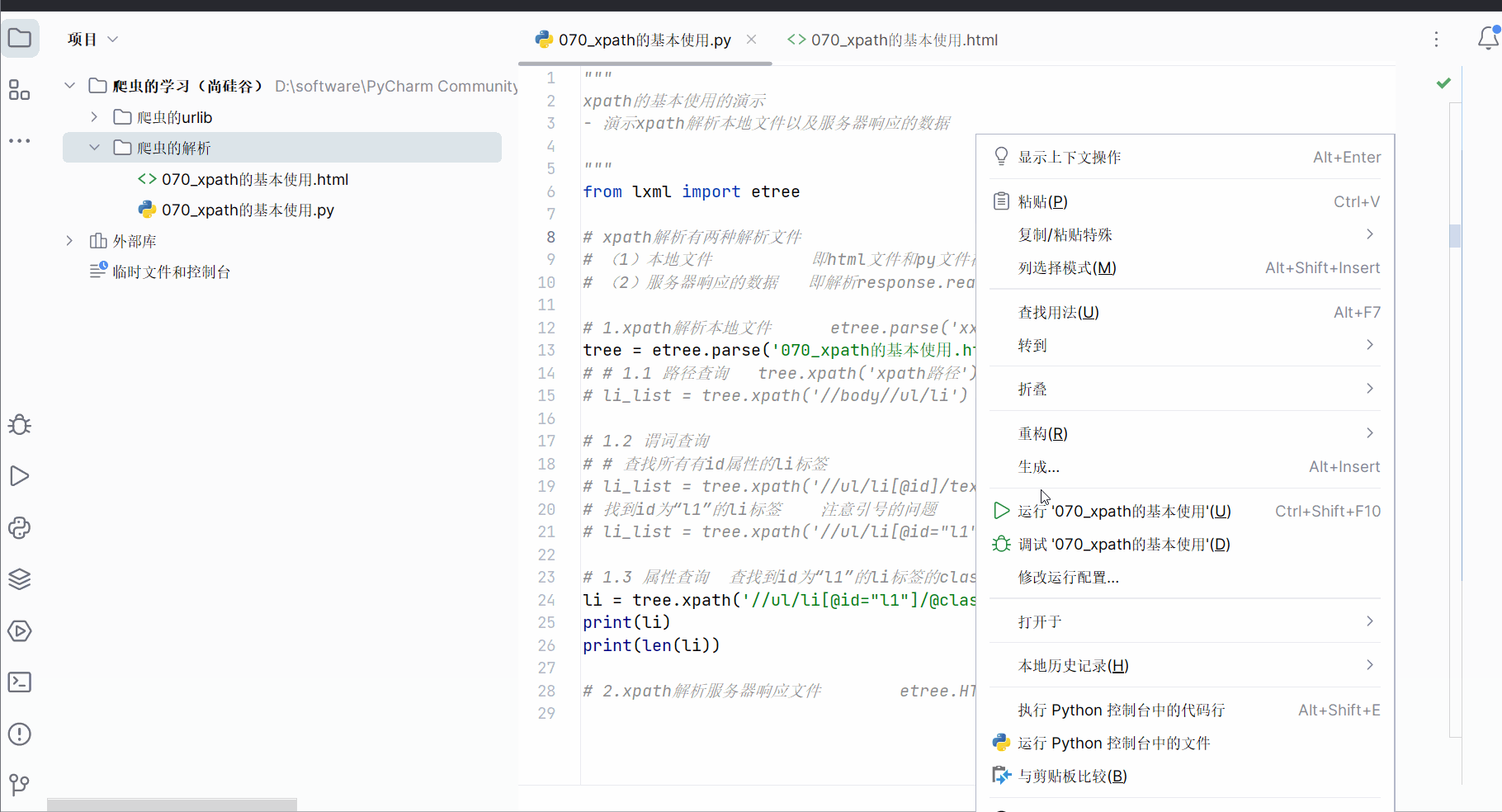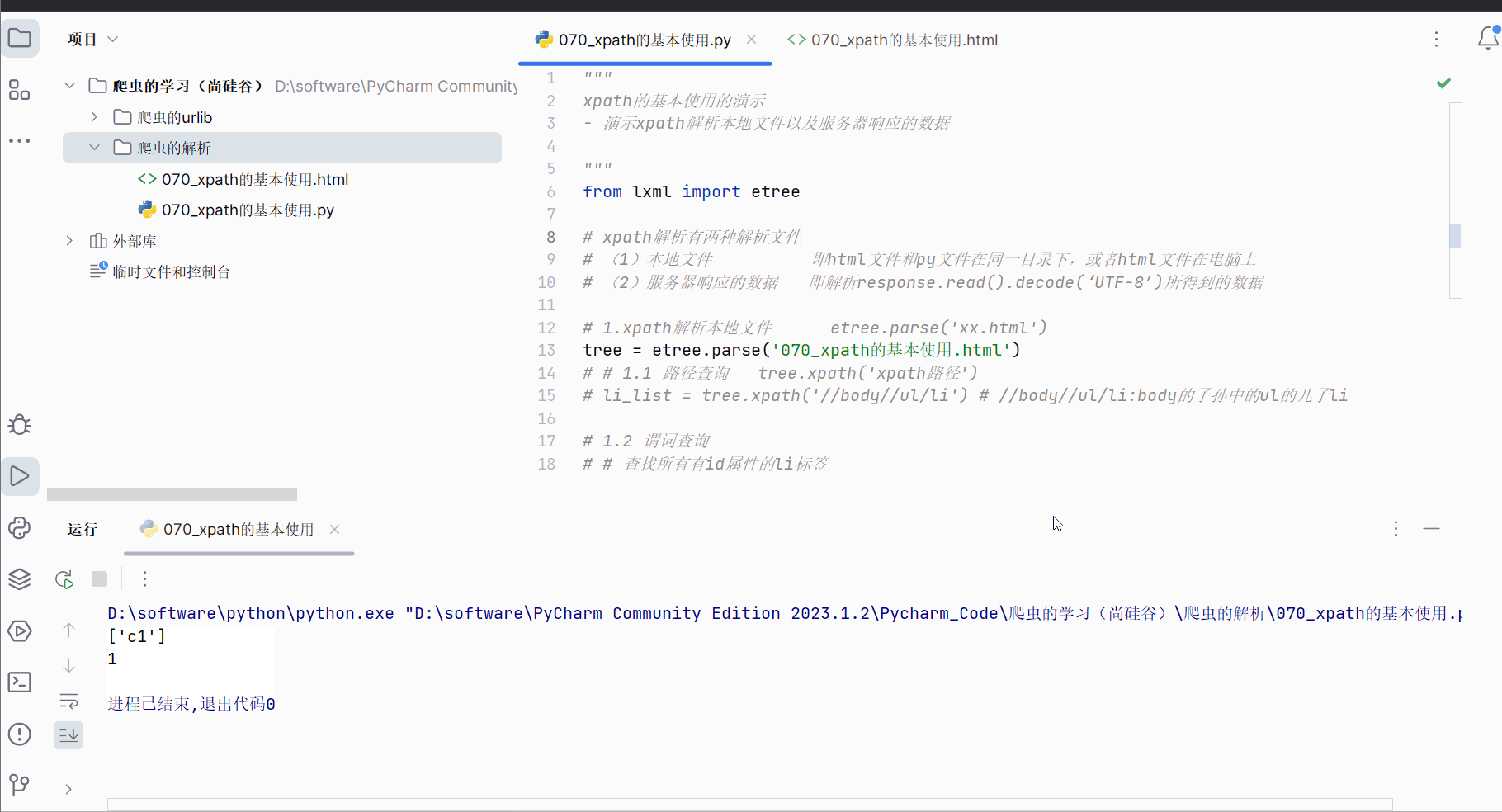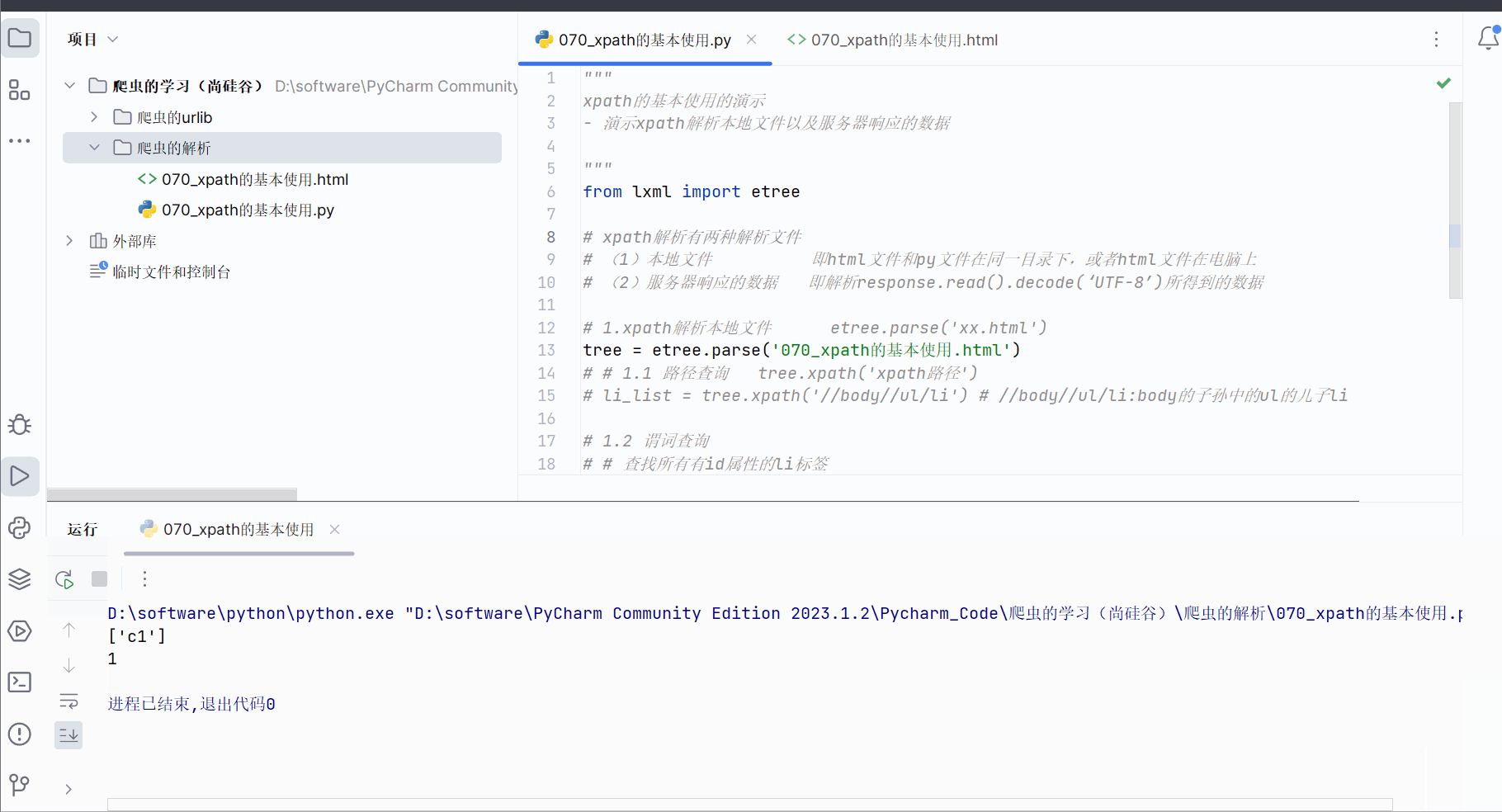
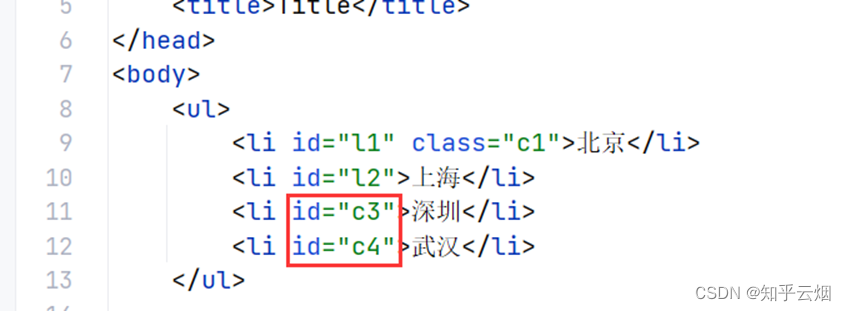
如下图,在html文件中给其他一些城市加一些id属性。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="l1" class="c1">北京</li><li id="l2">上海</li><li id="c3">深圳</li><li id="c4">武汉</li></ul><ul><li>大连</li><li>锦州</li><li>沈阳</li></ul>
</body>
</html>然后使用模糊查询查找id中包含“l”的li标签。
"""
xpath的基本使用的演示
- 演示xpath解析本地文件以及服务器响应的数据
"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询(含内容查询)
# # 查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]/text()') # “/text()”:获取标签中的内容。
# 找到id为“l1”的li标签 注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')# 1.3 属性查询 查找到id为“l1”的li标签的class的属性值
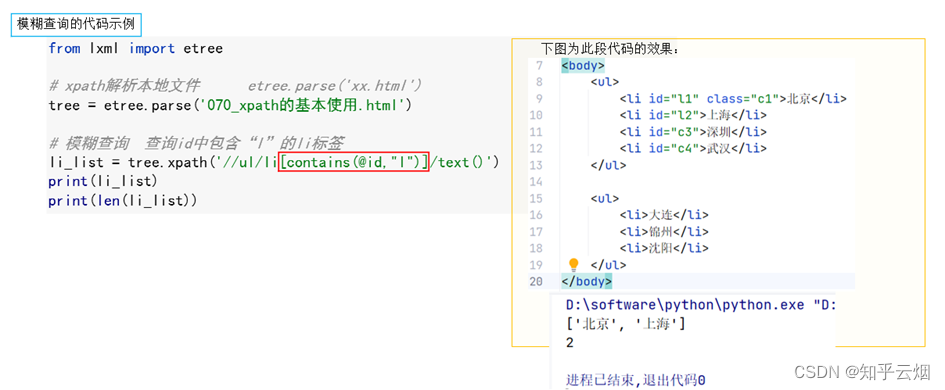
# li = tree.xpath('//ul/li[@id="l1"]/@class')# 1.4 模糊查询 查询id中包含“l”的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
print(len(li_list))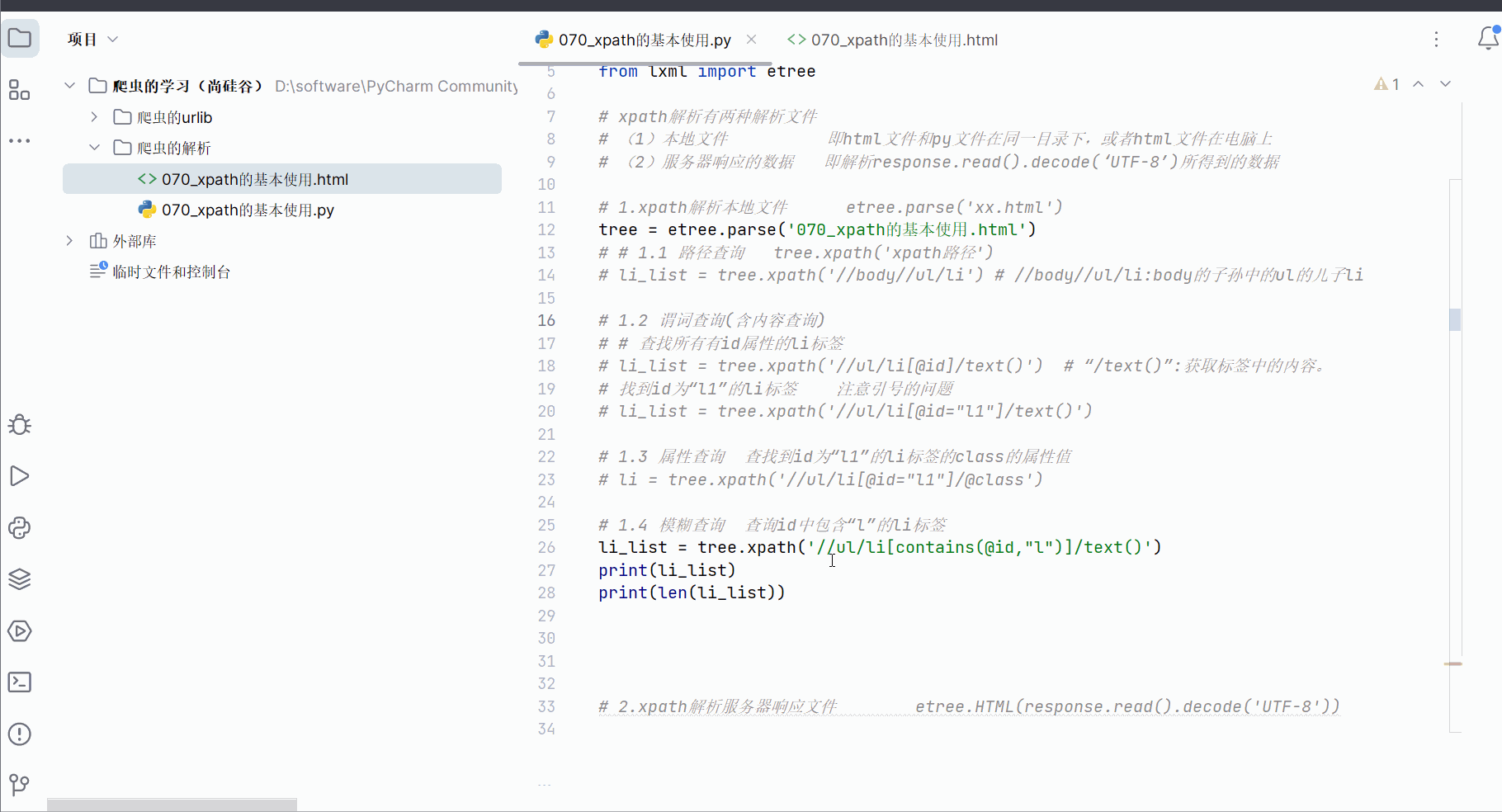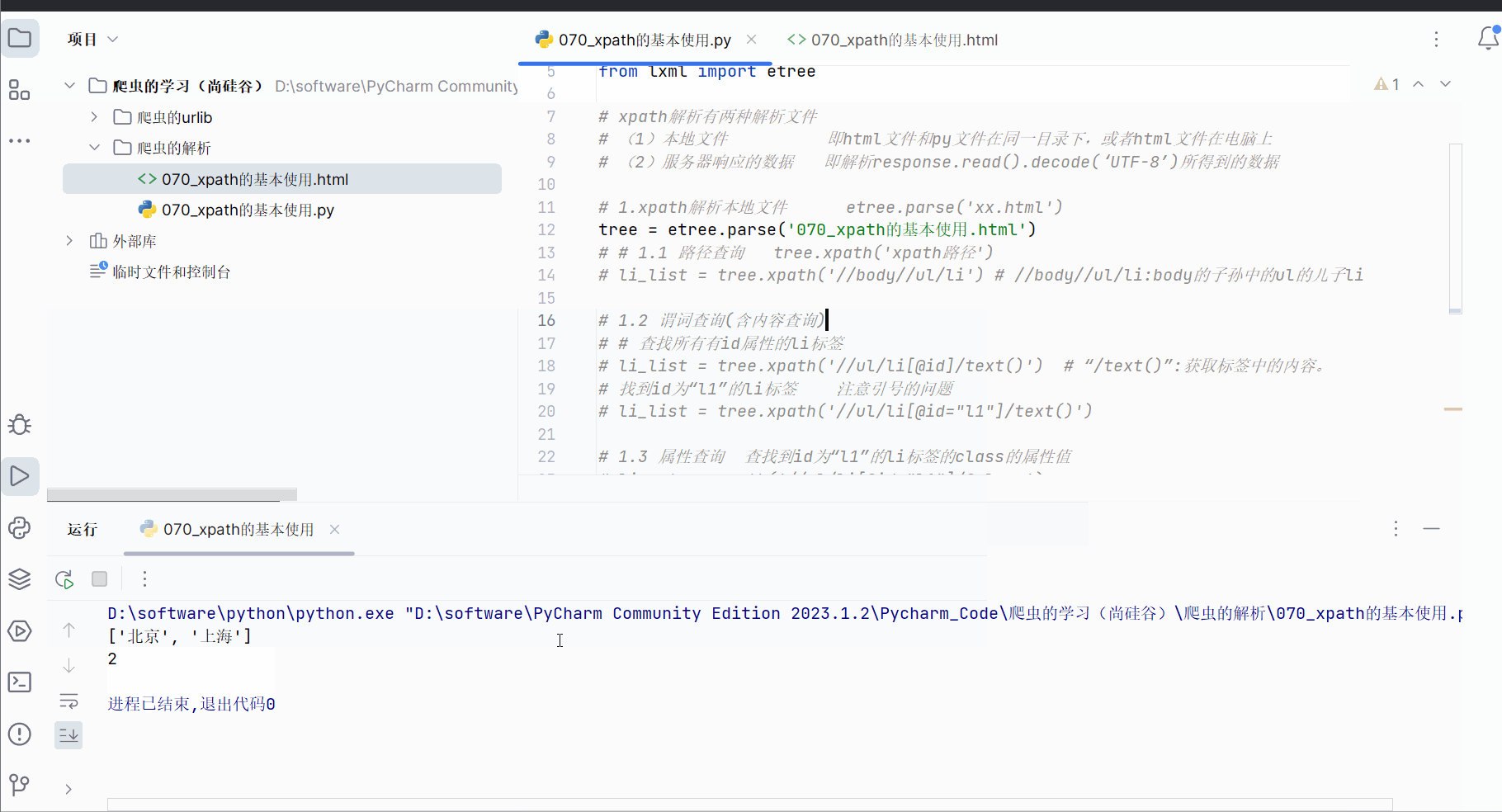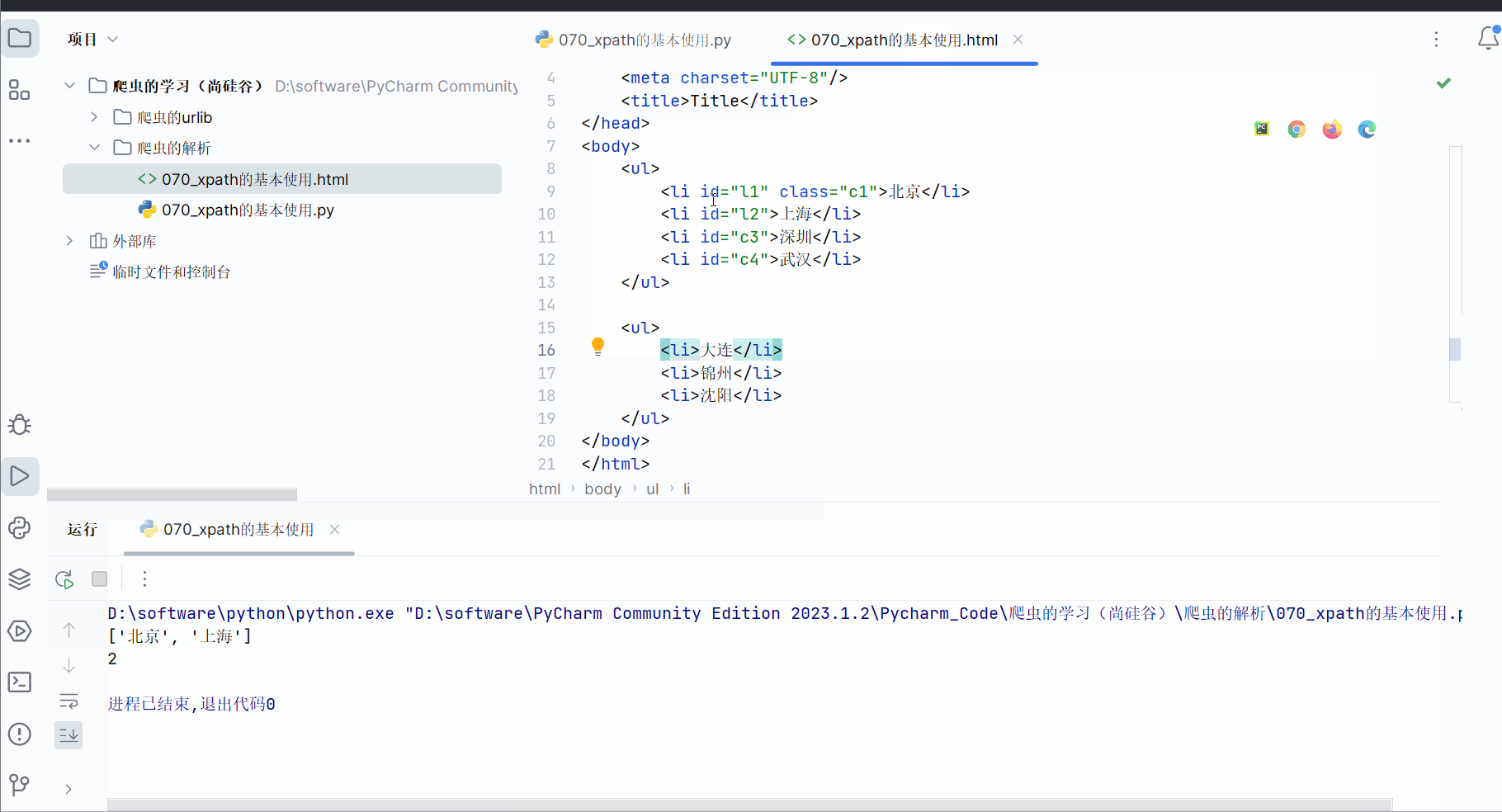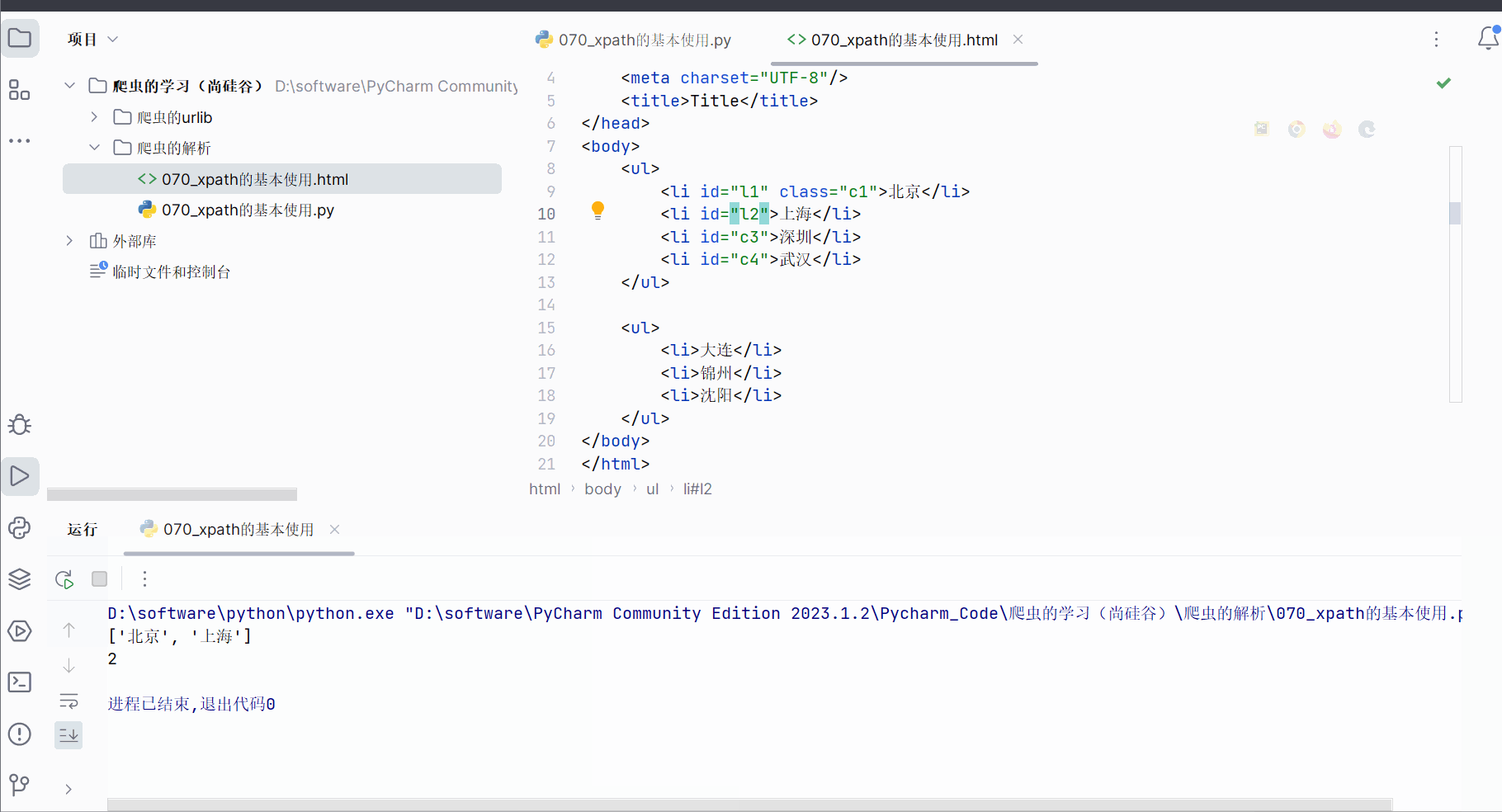
然后再使用模糊查询查找id的属性值以“c”为开头的li标签。
"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询(含内容查询)
# # 查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]/text()') # “/text()”:获取标签中的内容。
# 找到id为“l1”的li标签 注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')# 1.3 属性查询 查找到id为“l1”的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')# 1.4 模糊查询
# 查询id中包含“l”的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查找id的属性值以“c”为开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)
print(len(li_list))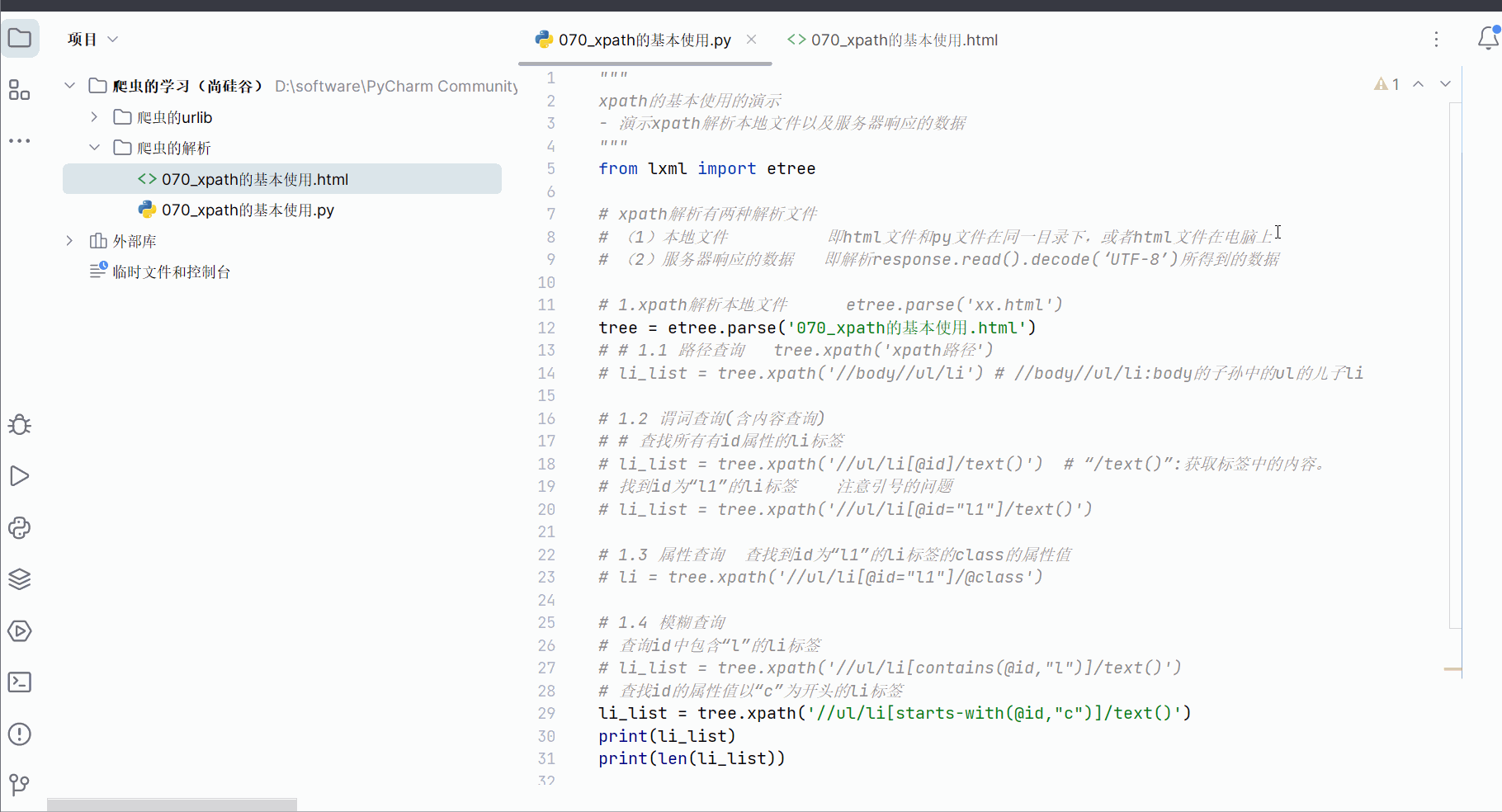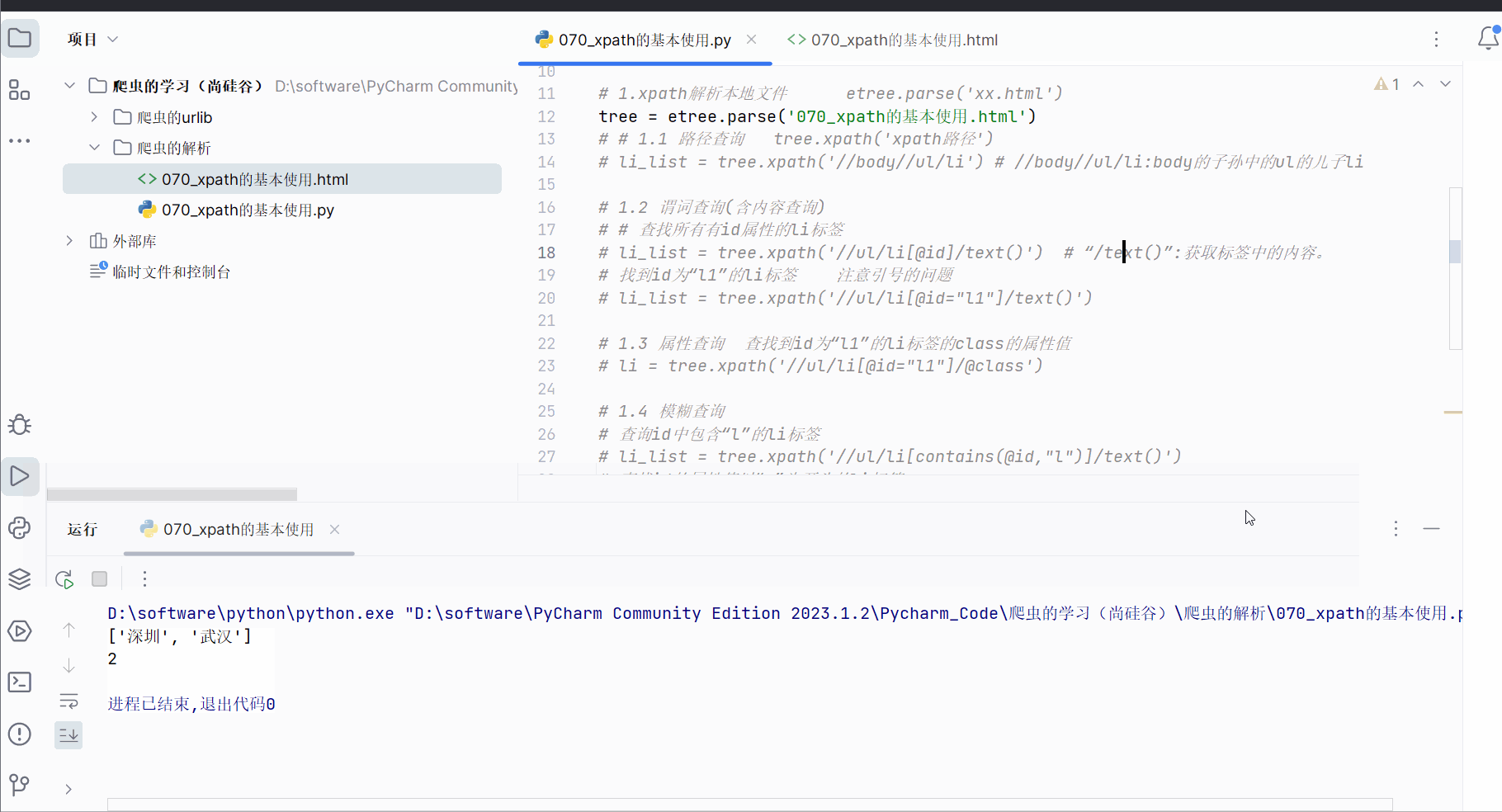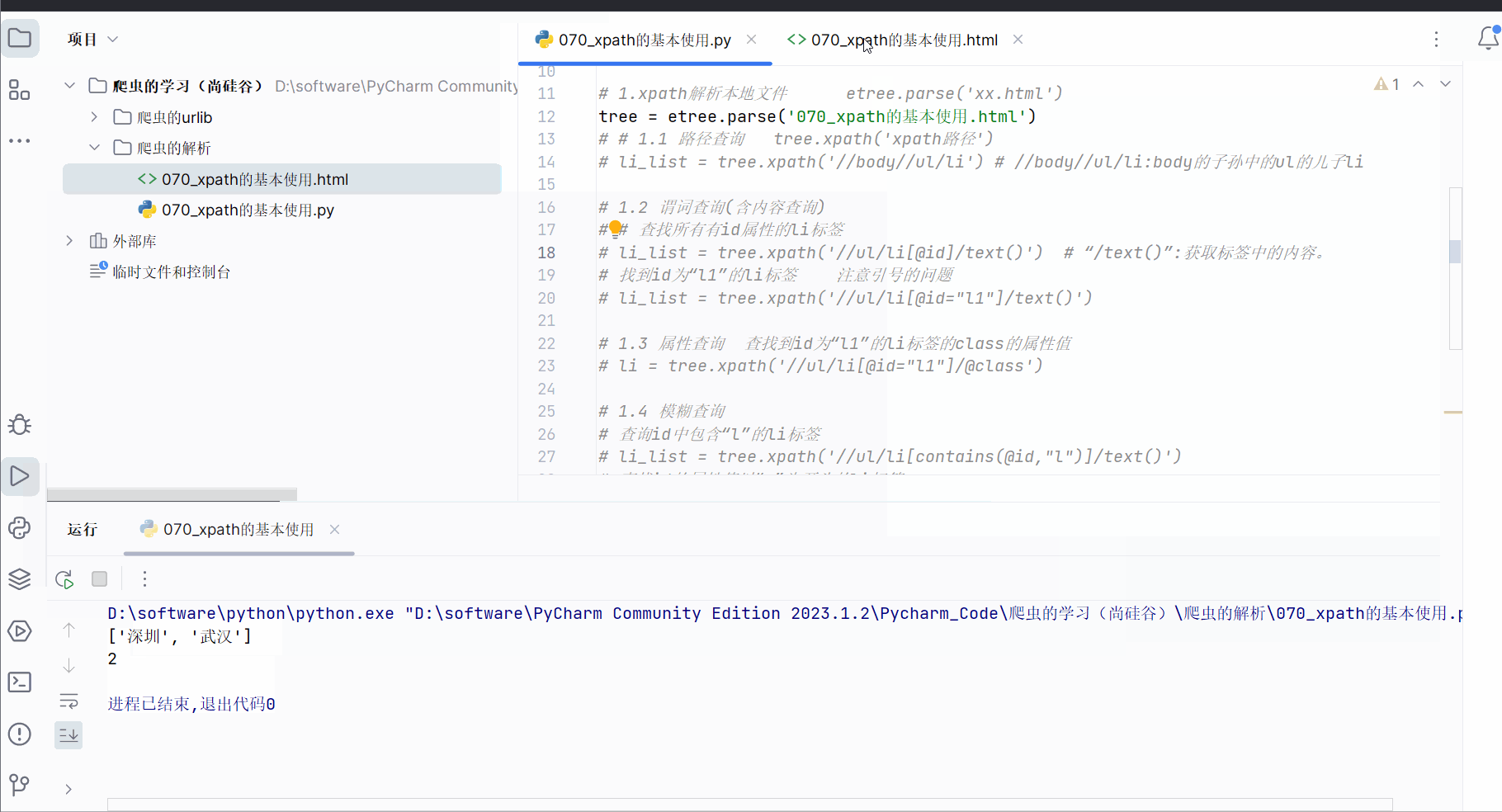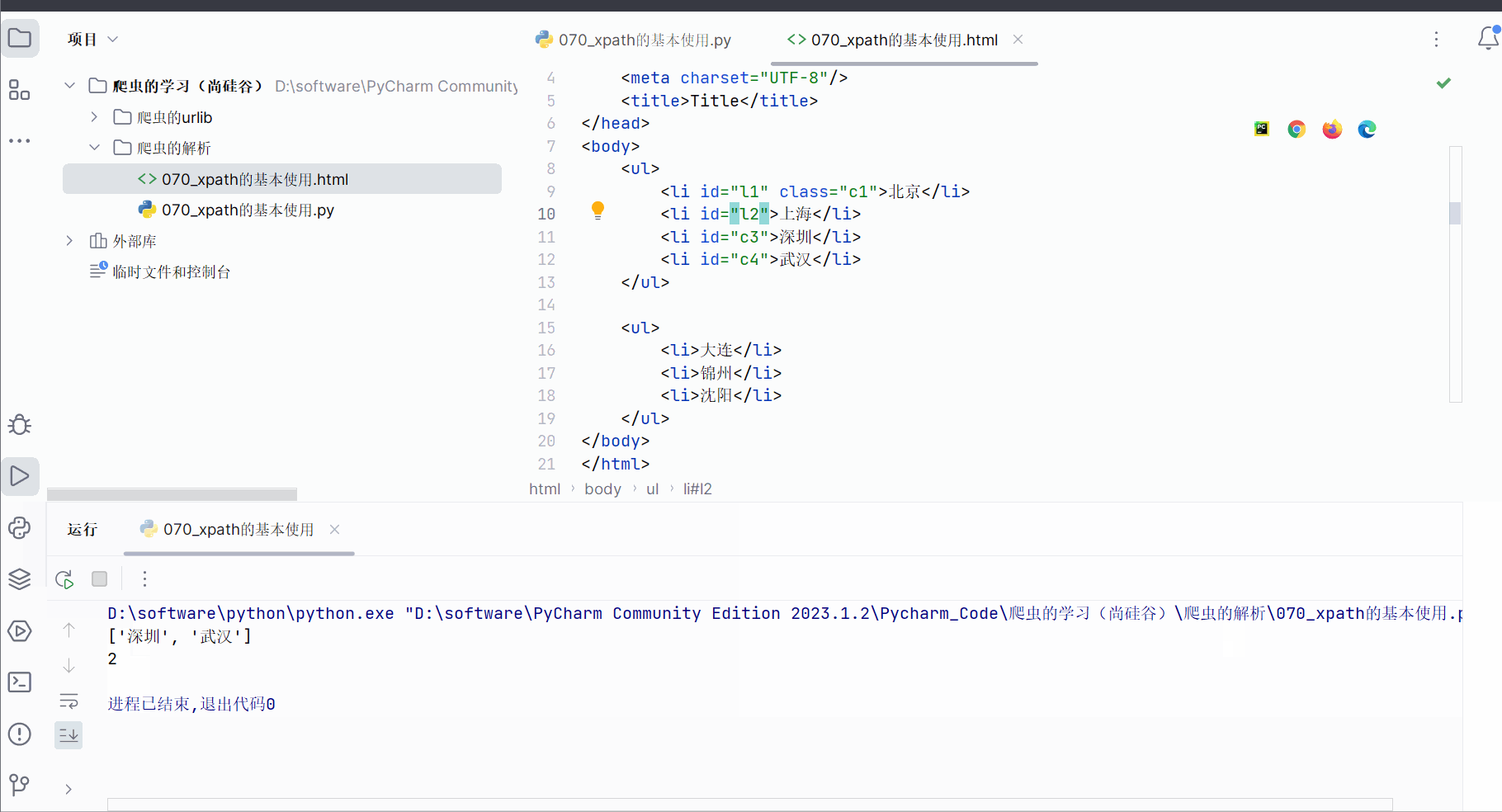
如下进行编程,学会使用逻辑查询的语法。
"""
xpath的基本使用的演示
- 演示xpath解析本地文件以及服务器响应的数据
"""
from lxml import etree# xpath解析有两种解析文件
# (1)本地文件 即html文件和py文件在同一目录下,或者html文件在电脑上
# (2)服务器响应的数据 即解析response.read().decode(‘UTF-8’)所得到的数据# 1.xpath解析本地文件 etree.parse('xx.html')
tree = etree.parse('070_xpath的基本使用.html')
# # 1.1 路径查询 tree.xpath('xpath路径')
# li_list = tree.xpath('//body//ul/li') # //body//ul/li:body的子孙中的ul的儿子li# 1.2 谓词查询(含内容查询)
# # 查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]/text()') # “/text()”:获取标签中的内容。
# 找到id为“l1”的li标签 注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')# 1.3 属性查询 查找到id为“l1”的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')# 1.4 模糊查询
# 查询id中包含“l”的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查找id的属性值以“c”为开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')# 1.5 逻辑运算
# 和运算 查询id为”l1“且class为”c1“的数据
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
print(li_list)
print(len(li_list))
# 或运算 查询id为”l1“或class为”c1“的数据,支持标签的或运算,不支持属性里面的或运算
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
print(li_list)
print(len(li_list))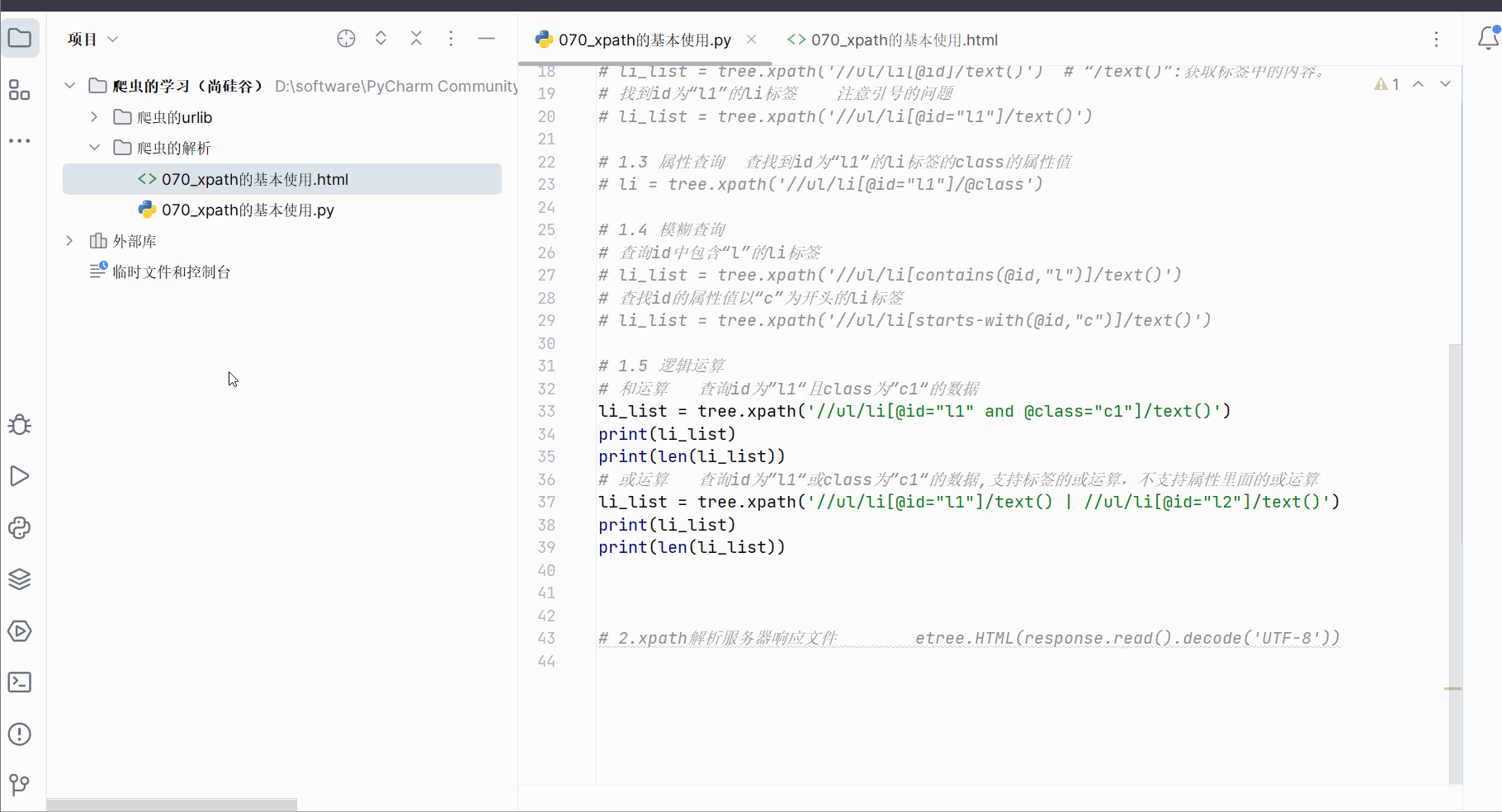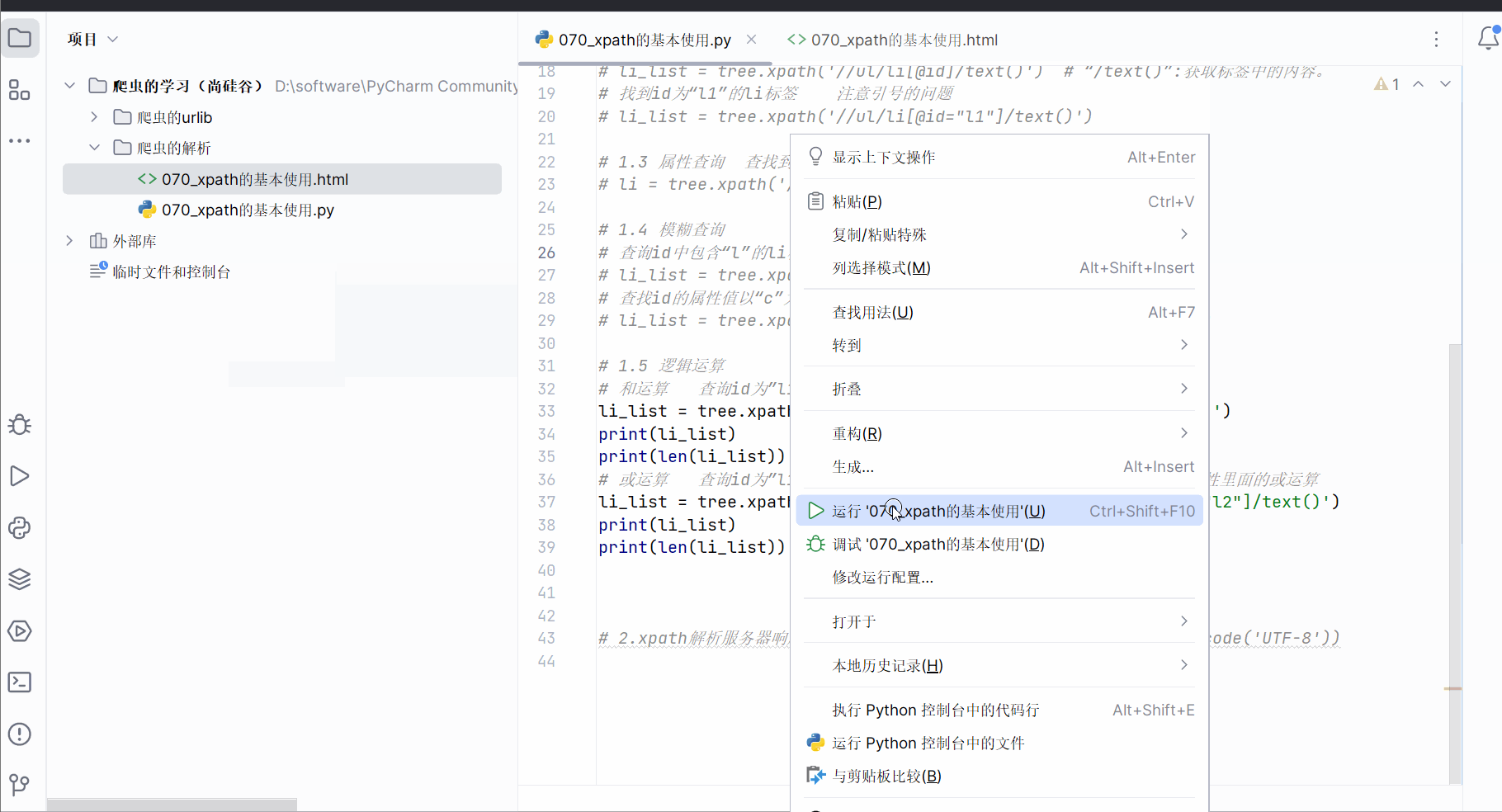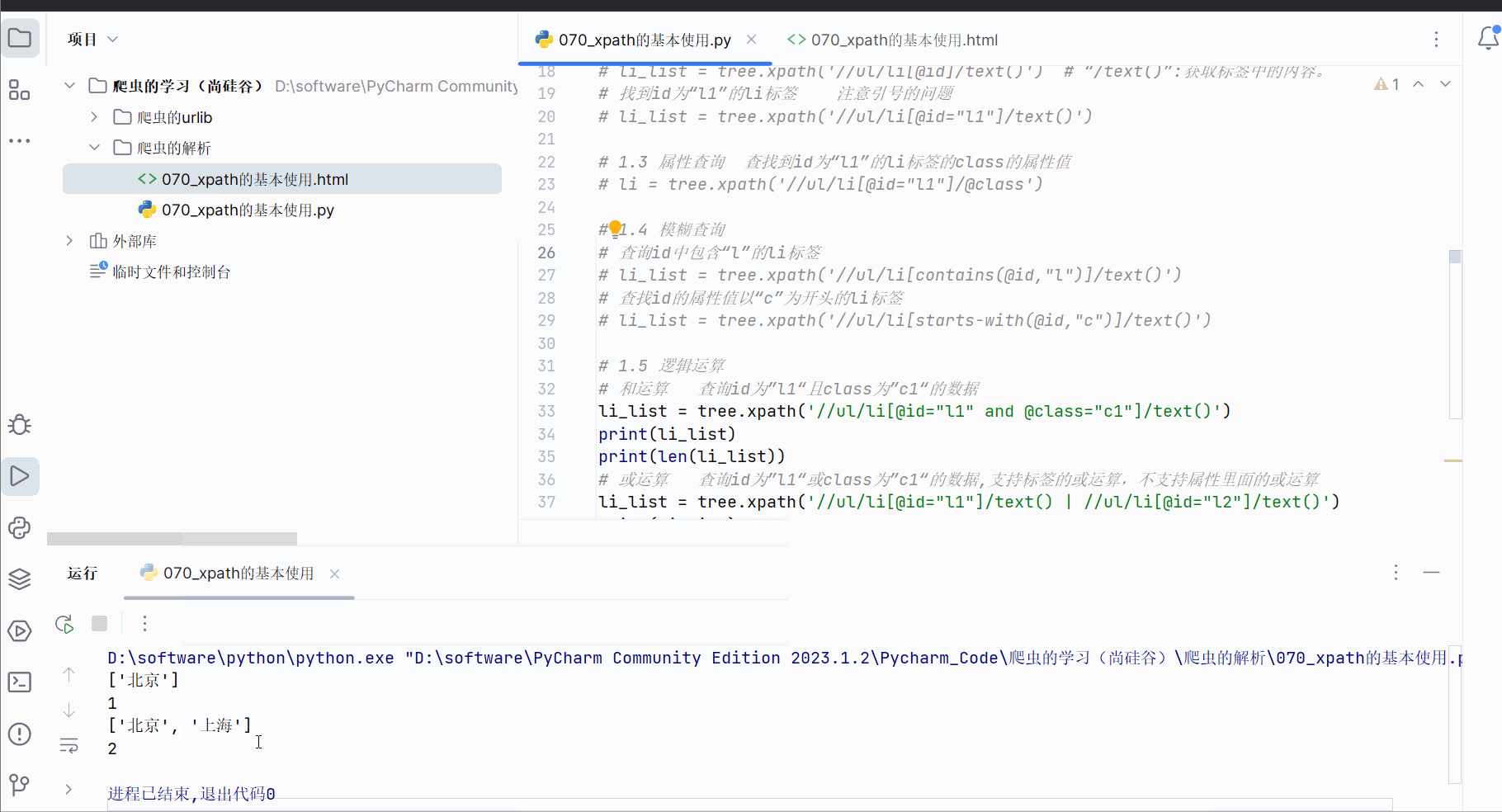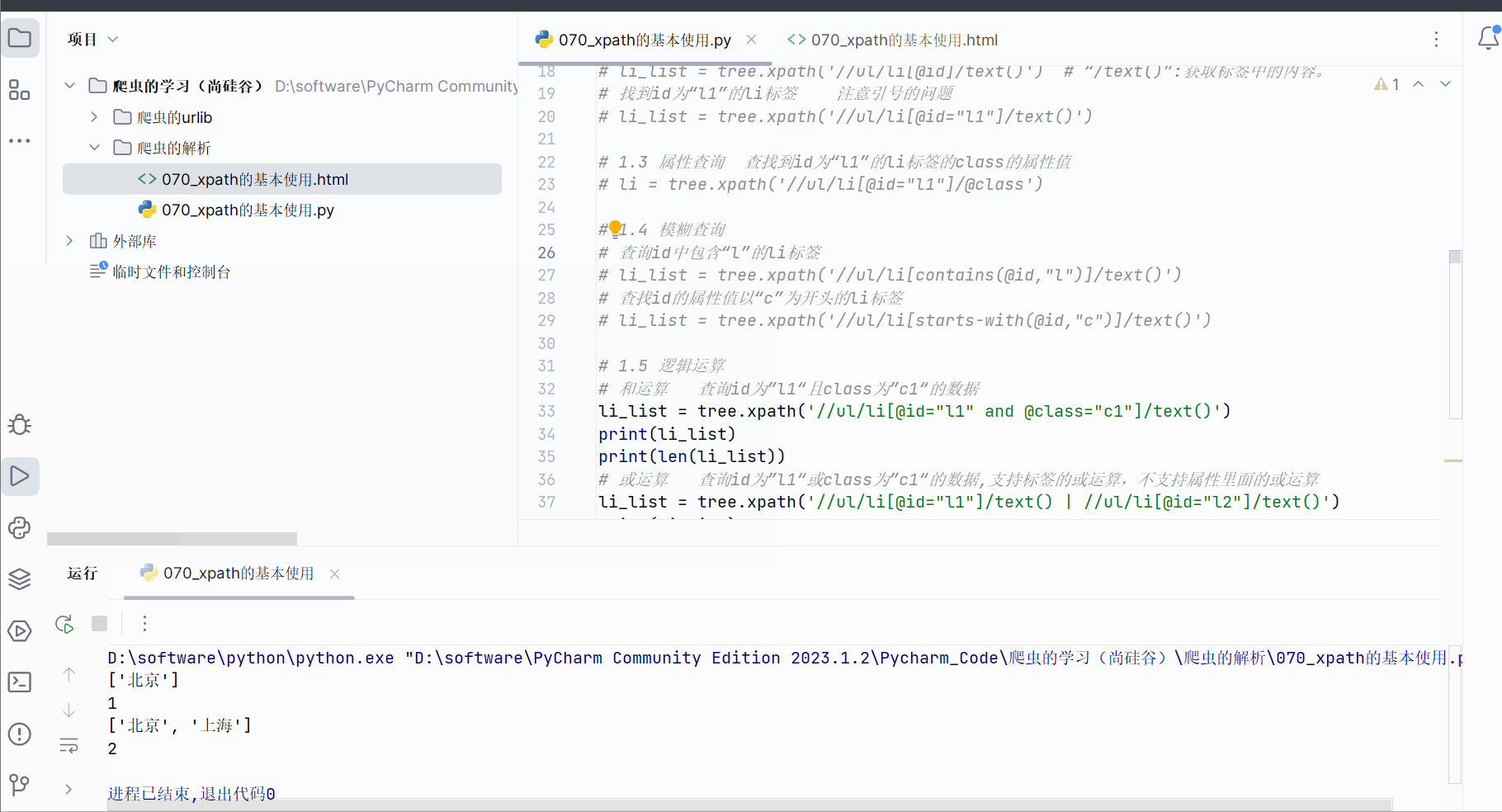
3.获取百度网站的百度一下
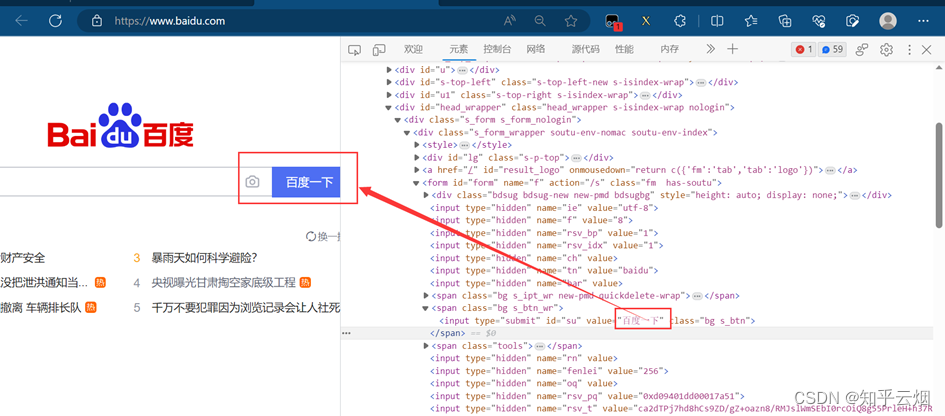
如下图所示,本次将演示获取百度网站的“百度一下”四个字,主要包括三个步骤。
# 1.获取网页源码
# 2.解析 解析服务器响应的文件 etree.HTML
# 3.打印
首先,创建文件“071_获取百度网站的百度一下.py”。
先编写获取网页源码的代码,使用搜索快捷键Crt+F找到我们需要获取的“百度一下”。
"""
获取百度网站的百度一下的演示
"""
import urllib.request# 1.获取网页源码
url = 'https://www.baidu.com/'
# 请求头
headers = {'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('UTF-8')
print(content)# 2.解析 解析服务器响应的文件 etree.HTML# 3.打印
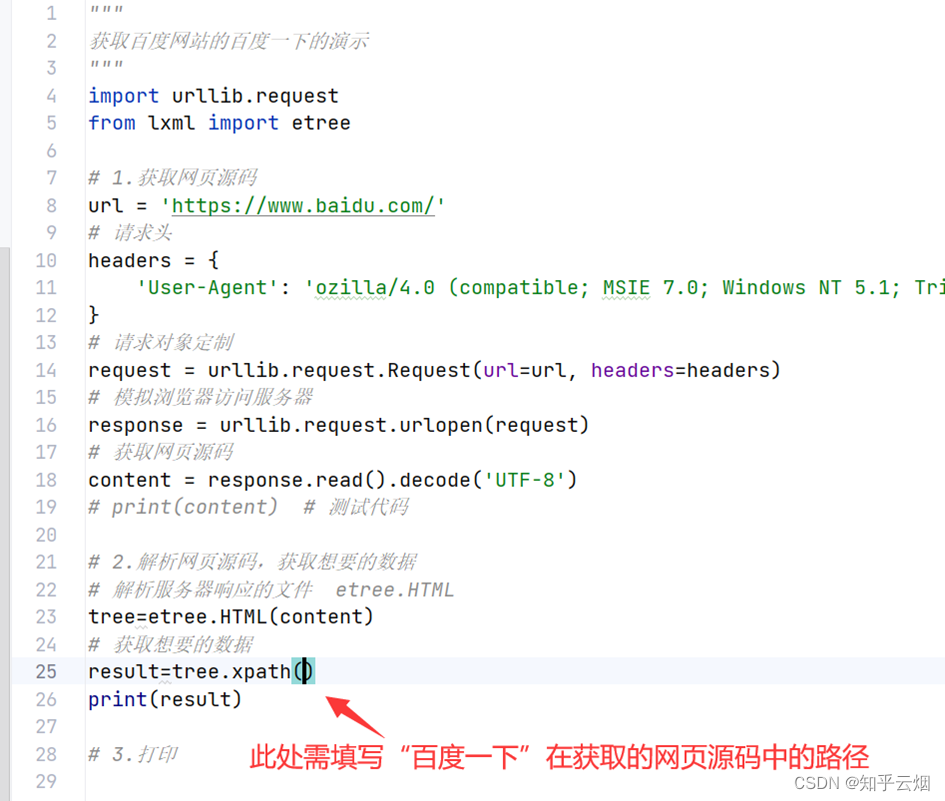
当代码编写到如图所示的位置时,需填写“百度一下”在网页源码中的路径。
本次需要用到之前安装的xpath插件。在使用该插件时,会弹出一个小黑框,在里面写xpath路径,并判断xpath路径是否正确。
如下图,打开检查,使用快捷键Ctr+Alt+X打开插件xpath。
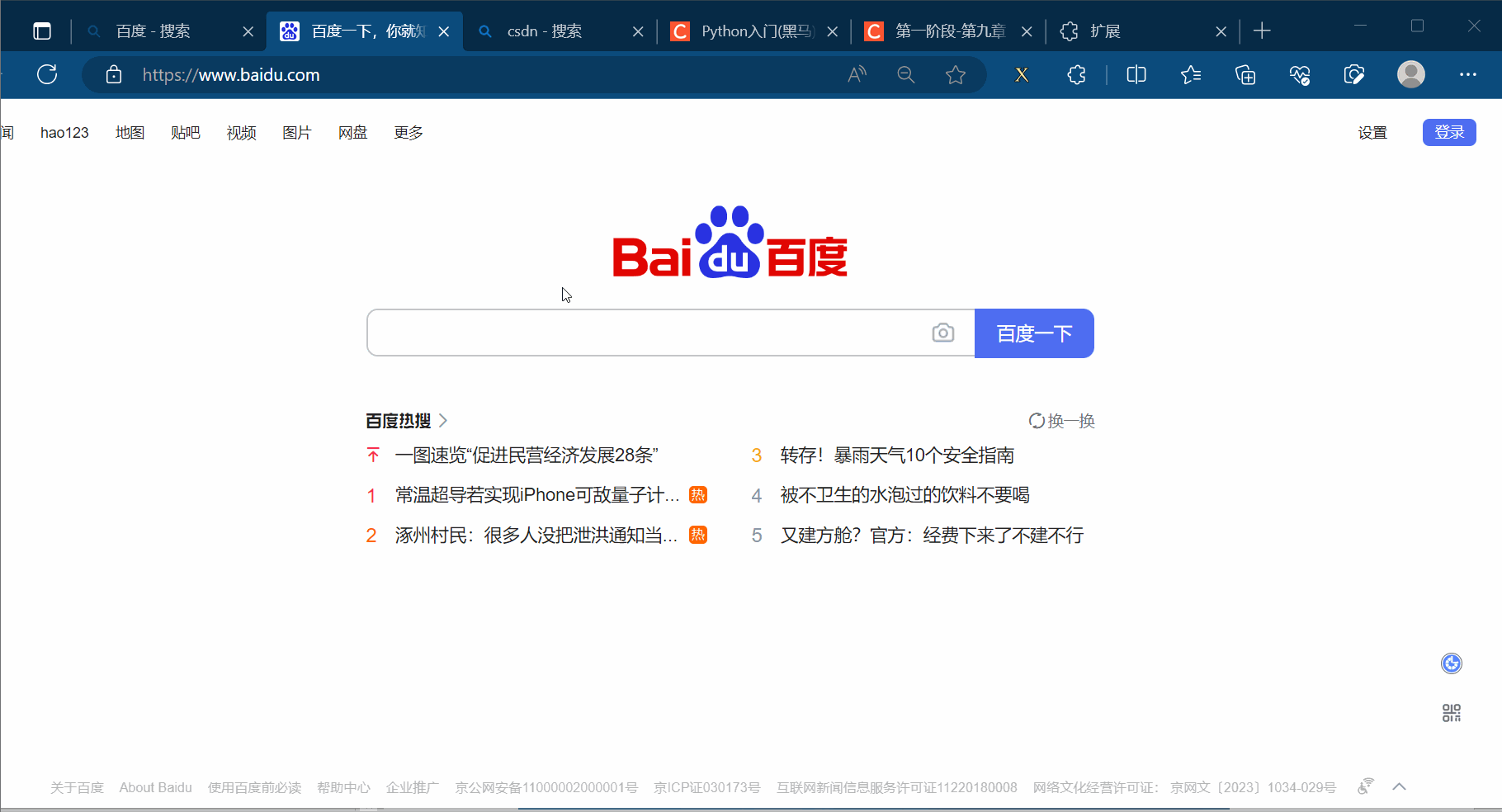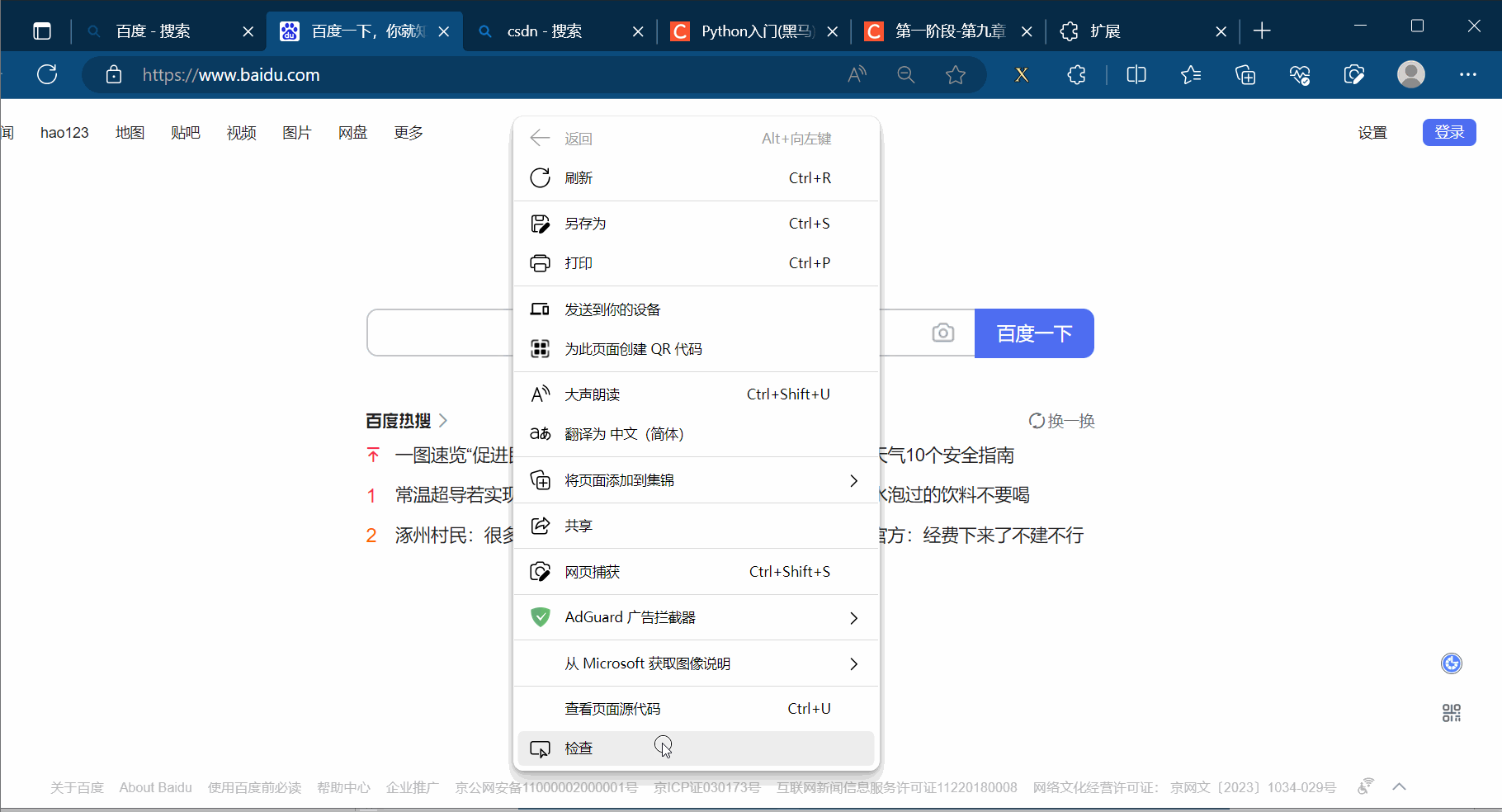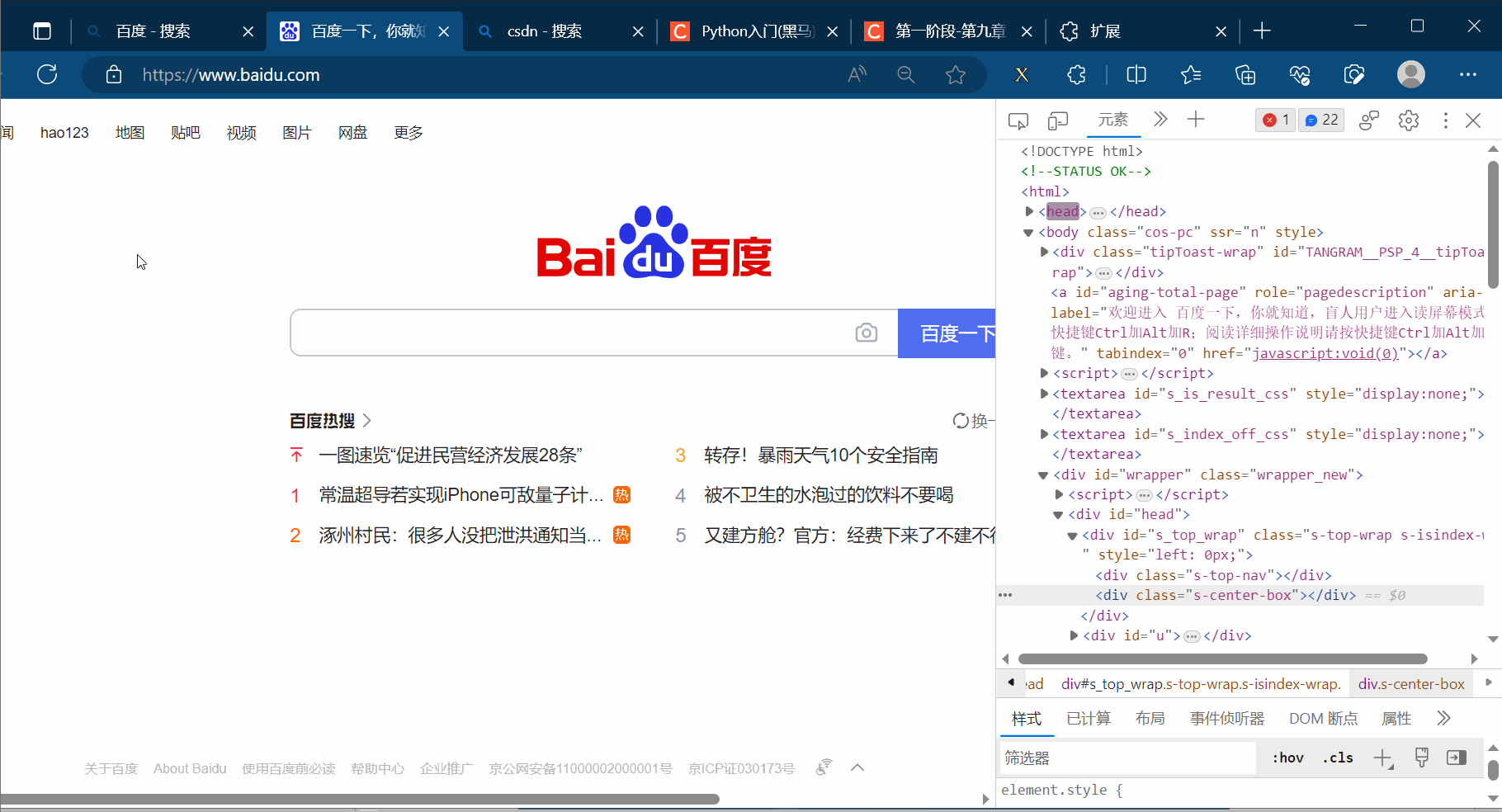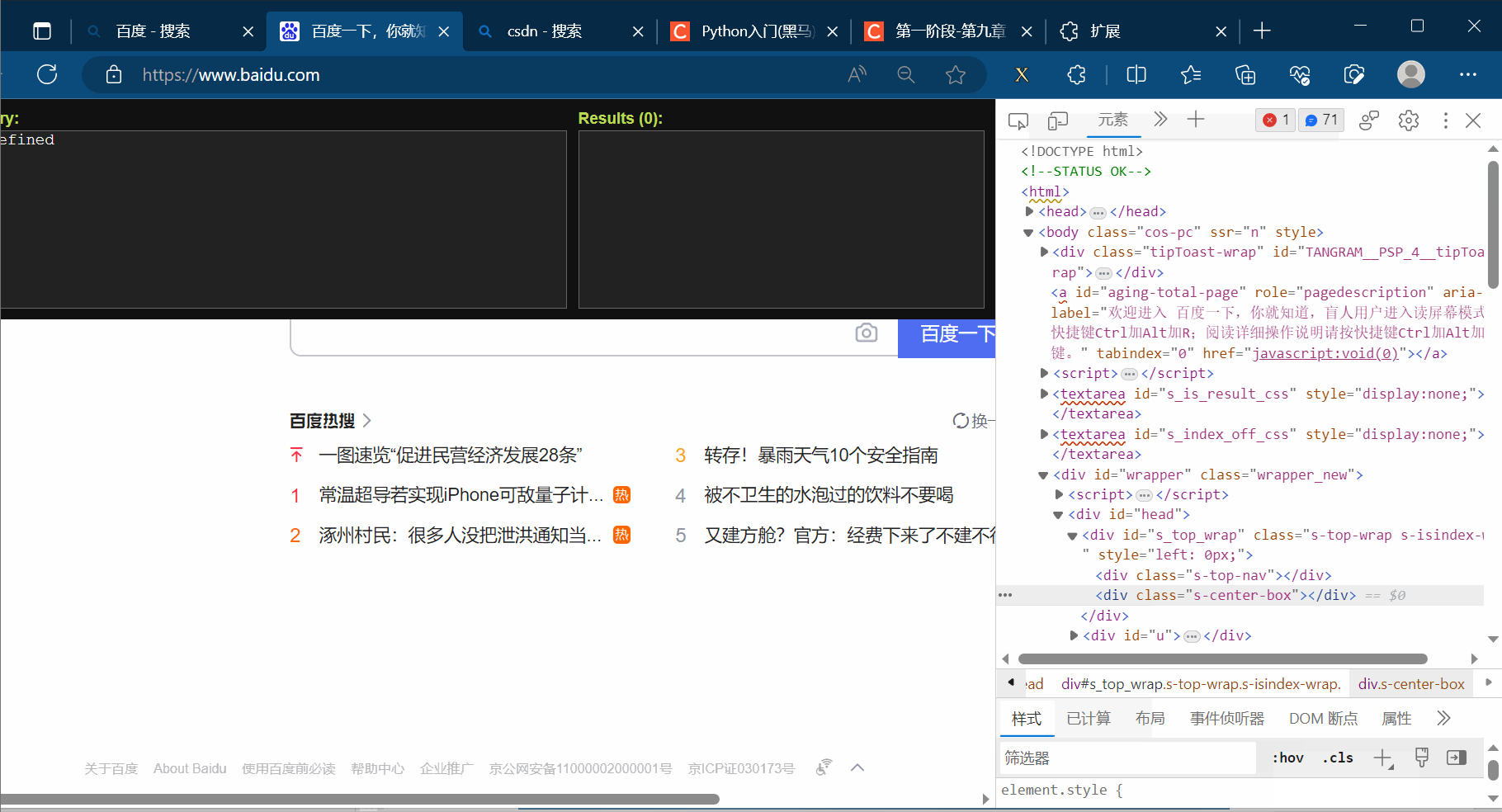
如下图,先定位到“百度一下”对应的位置。另外,由于id是唯一的,本次利用这个特性在插件xpath中填写相应路径,然后就会显示出我们需要的“百度一下”。
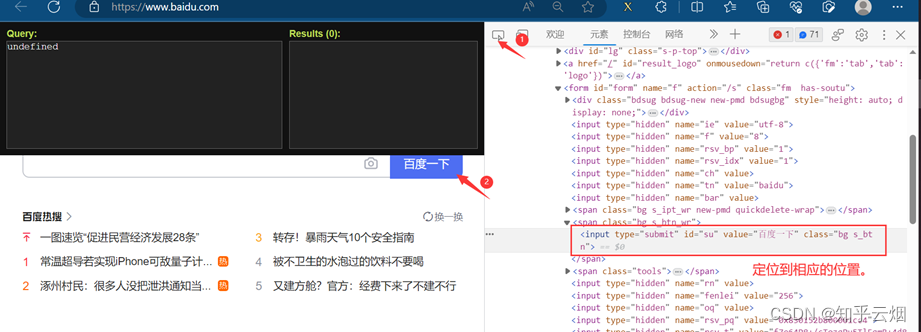
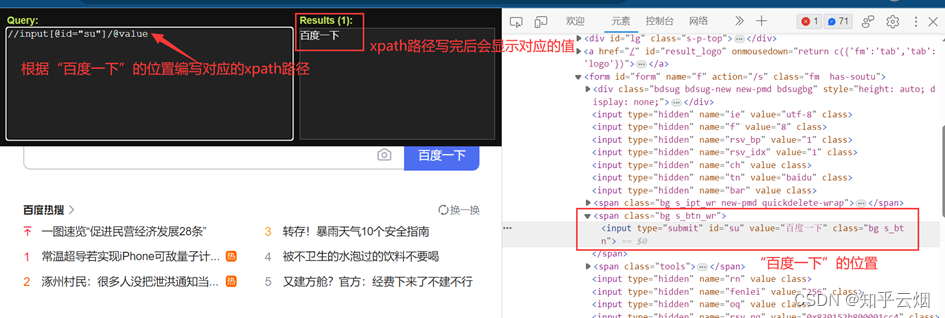
或者如下图所示,也能获取对应的xpath路径。

获取到xpath路径后,继续编写代码并运行。
"""
获取百度网站的百度一下的演示
"""
import urllib.request
from lxml import etree# 1.获取网页源码
url = 'https://www.baidu.com/'
# 请求头
headers = {'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('UTF-8')
# print(content) # 测试代码# 2.解析网页源码,获取想要的数据
# 解析服务器响应的文件 etree.HTML
tree = etree.HTML(content)
# 获取想要的数据
result = tree.xpath('//input[@id="su"]/@value')# 3.打印
# xpath的返回值是一个列表类型的数据
print(result[0])
4.站长素材(含懒加载、如何下载其中的高清图)
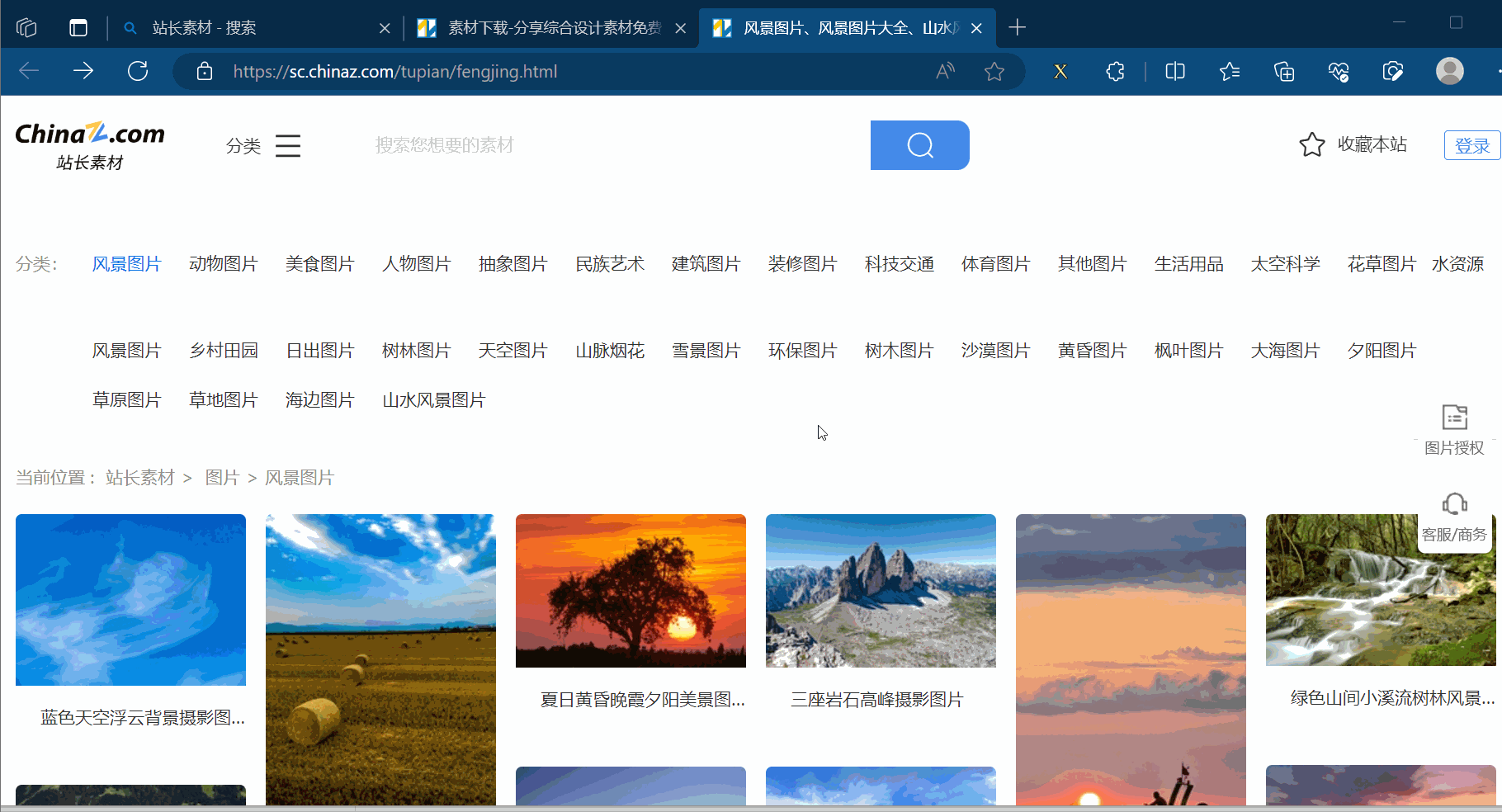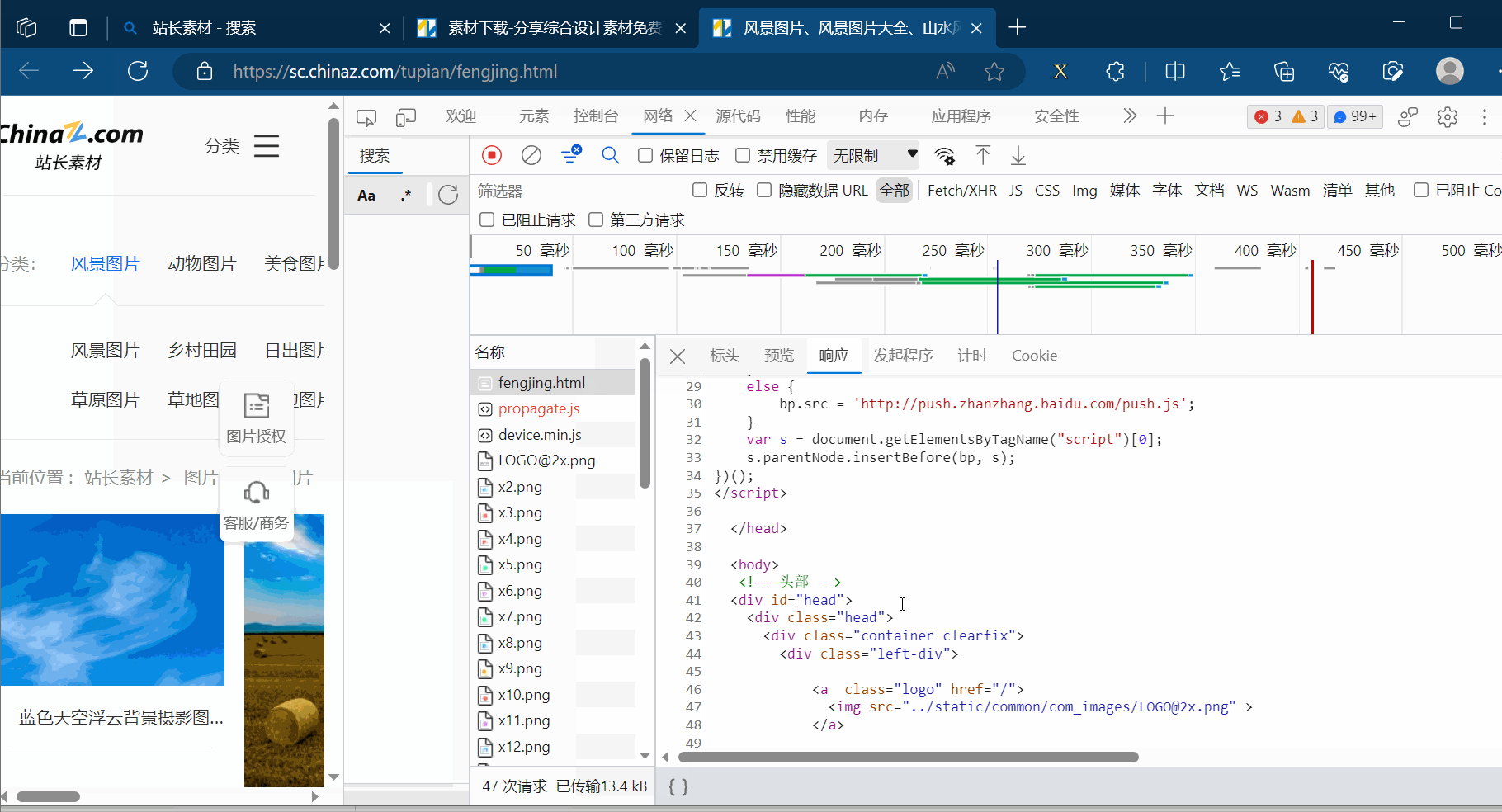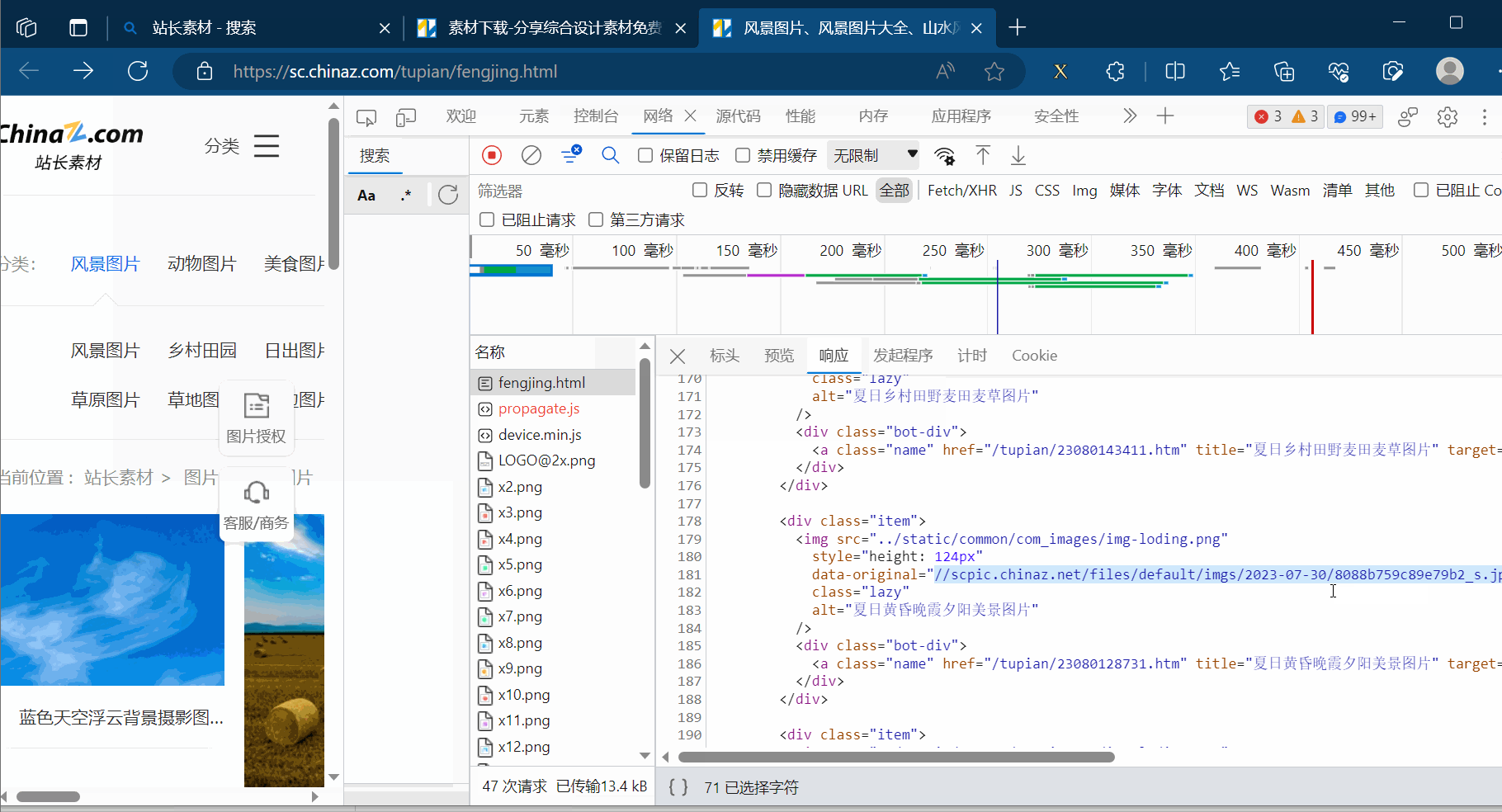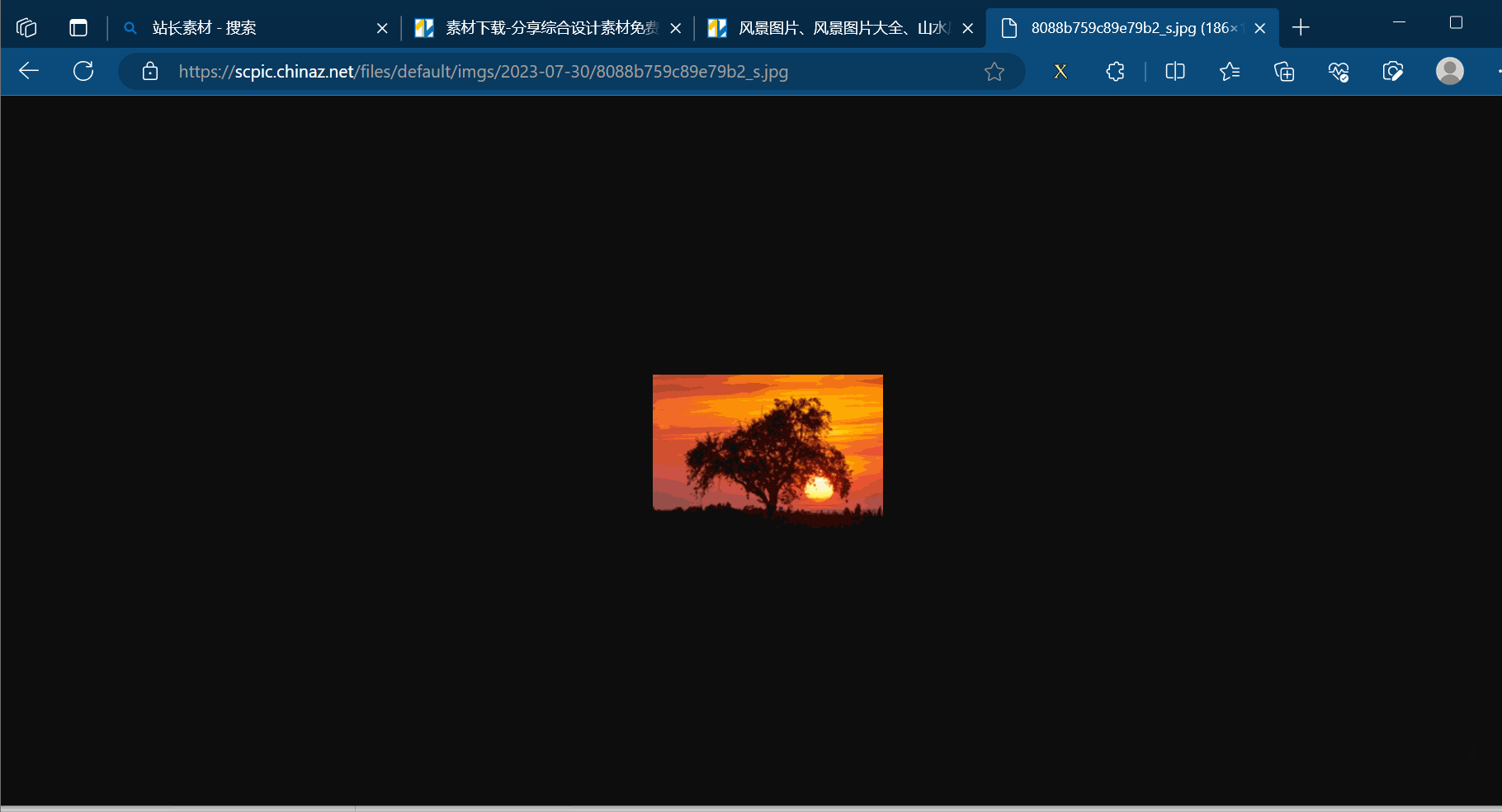
本次将通过xpath解析来获取“站长素材”的网站(“https://sc.chinaz.com/”)的高清图片里的前10页的风景图片。
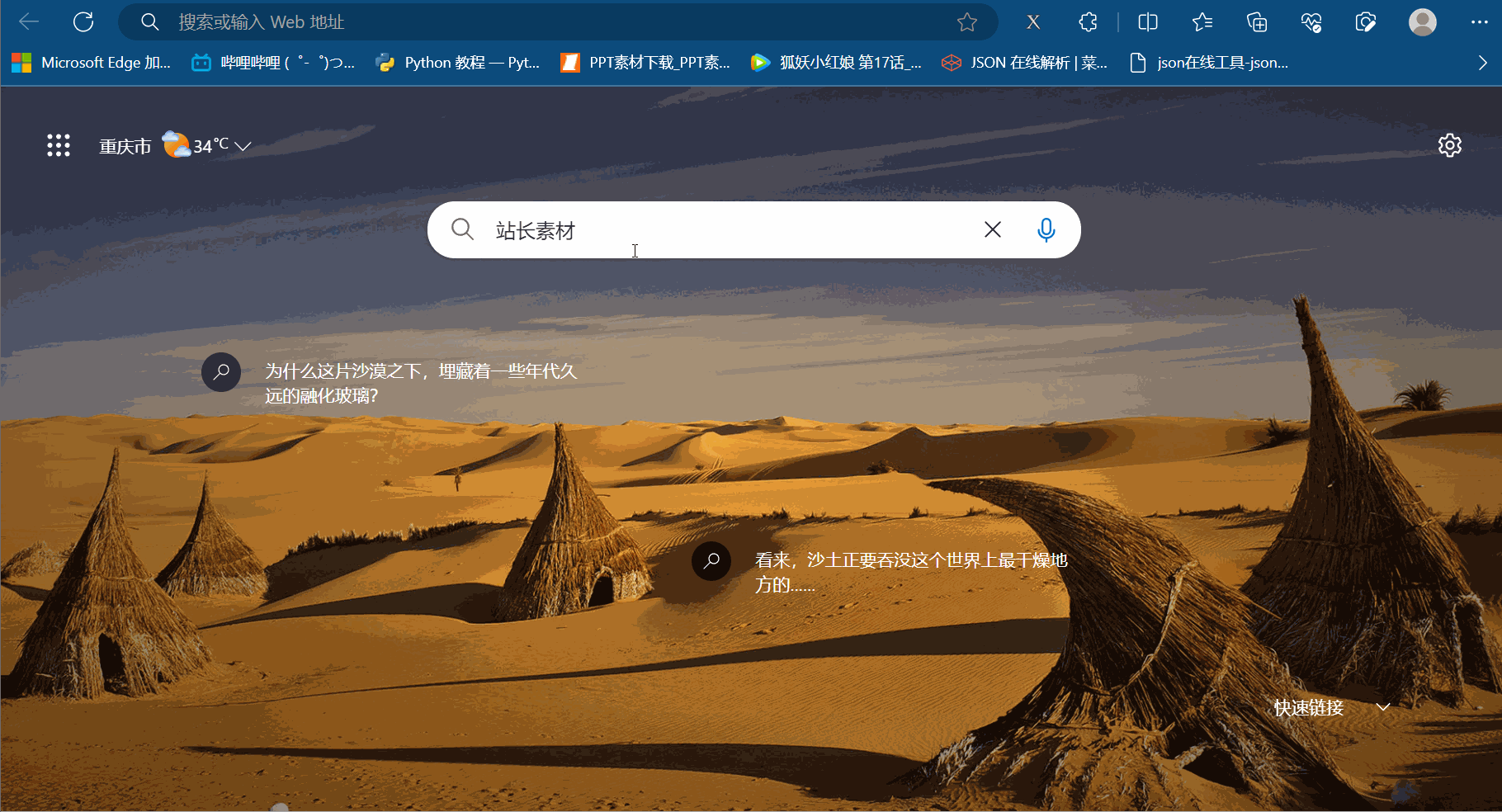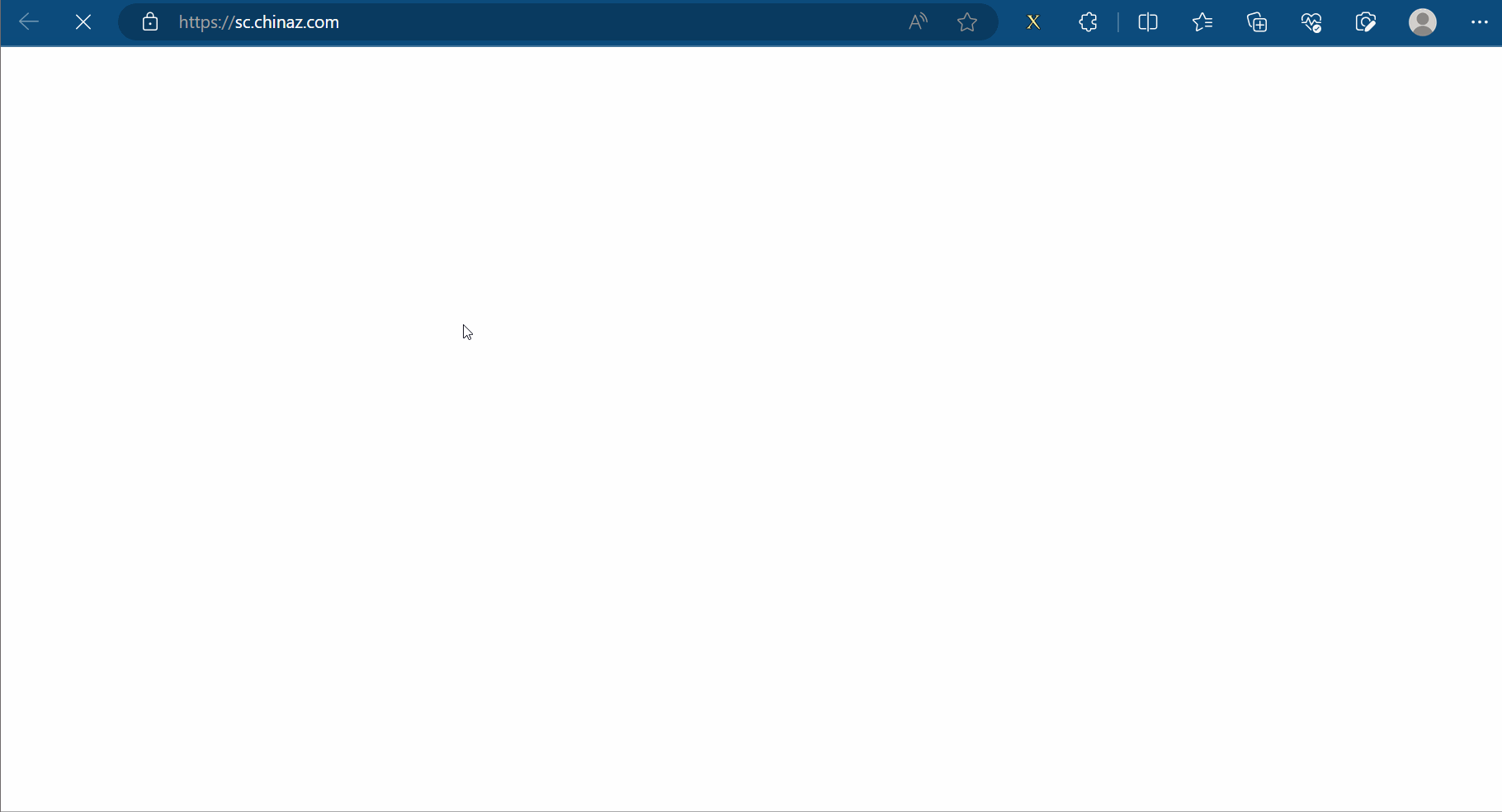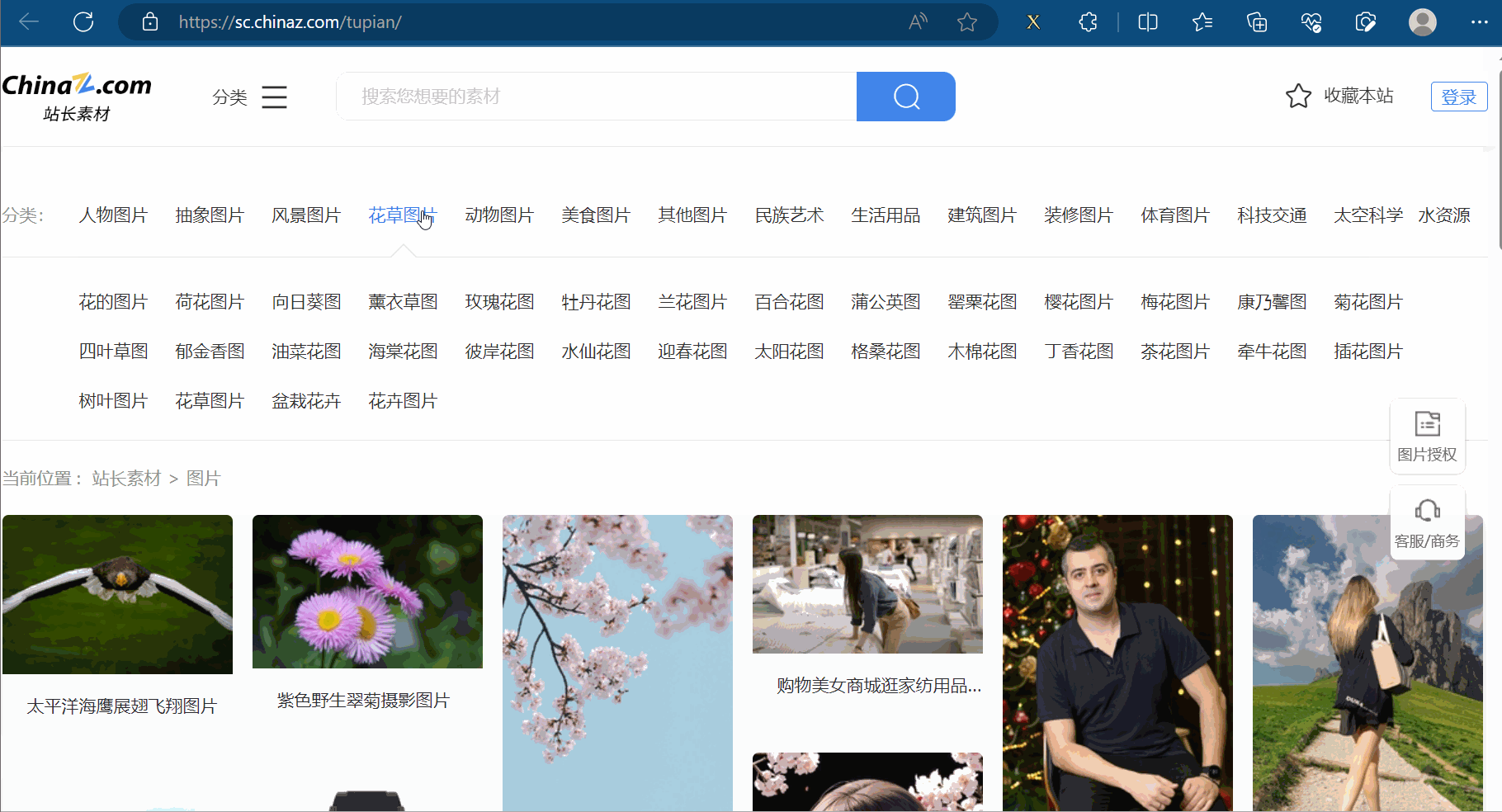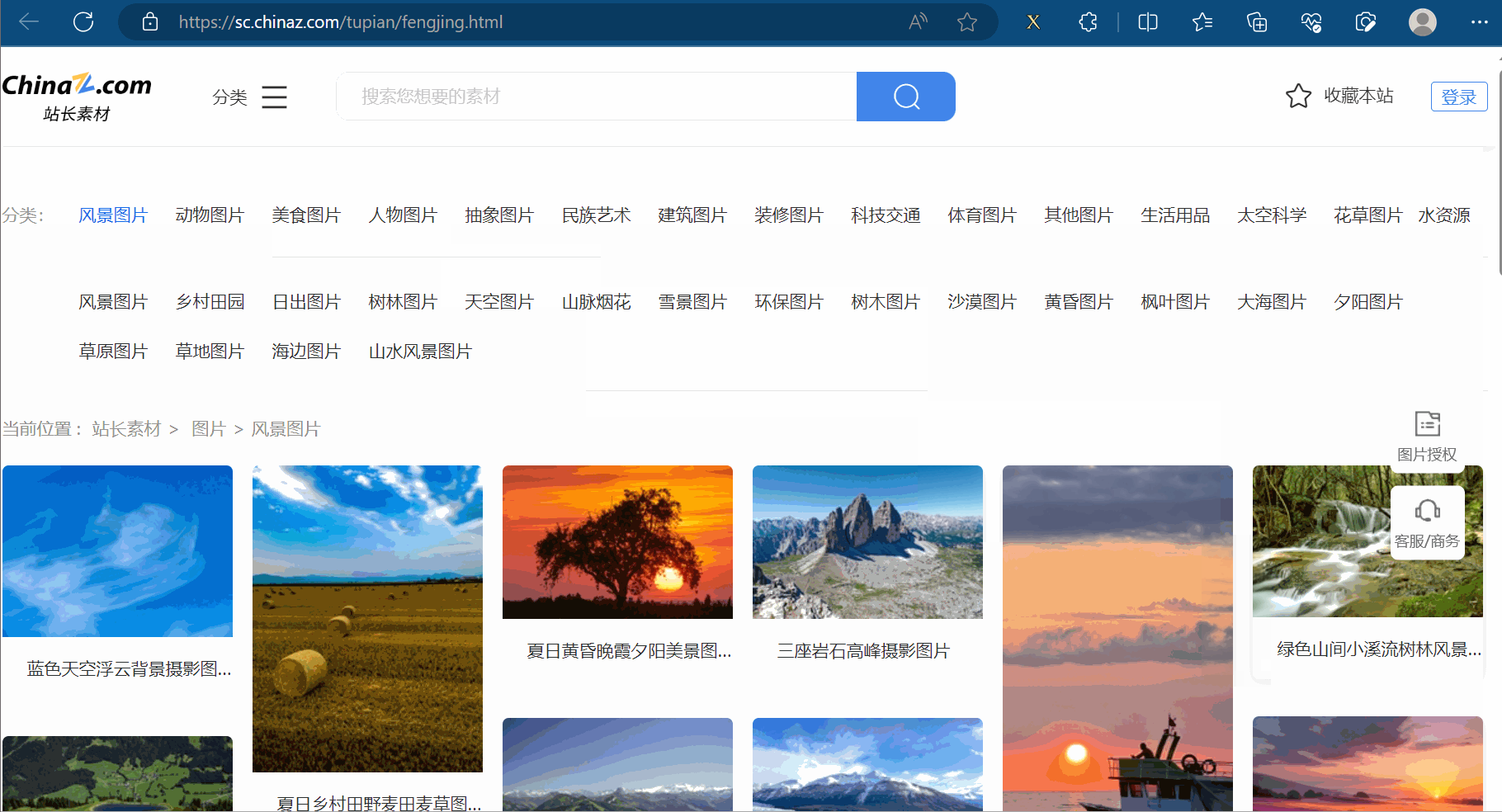
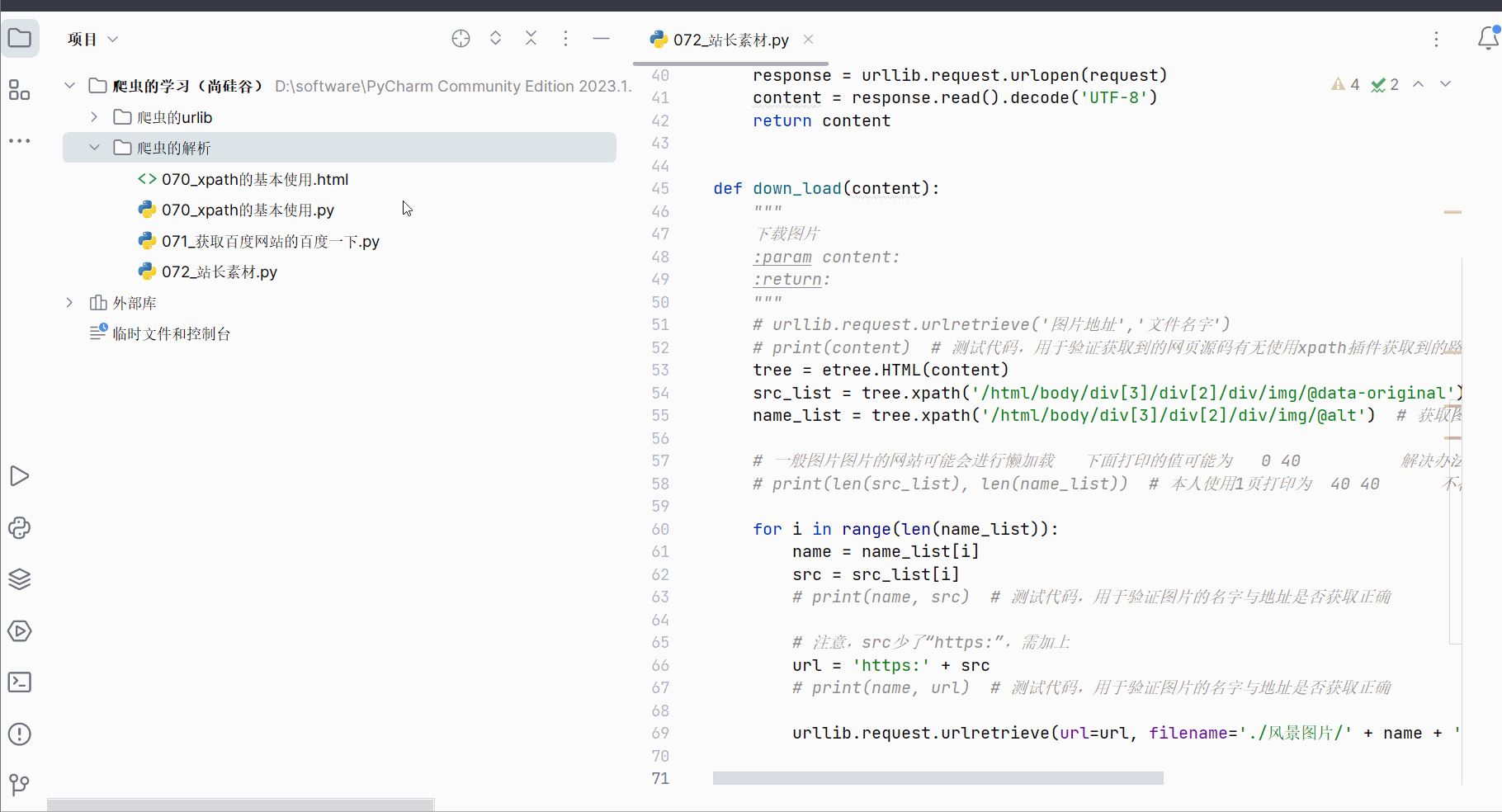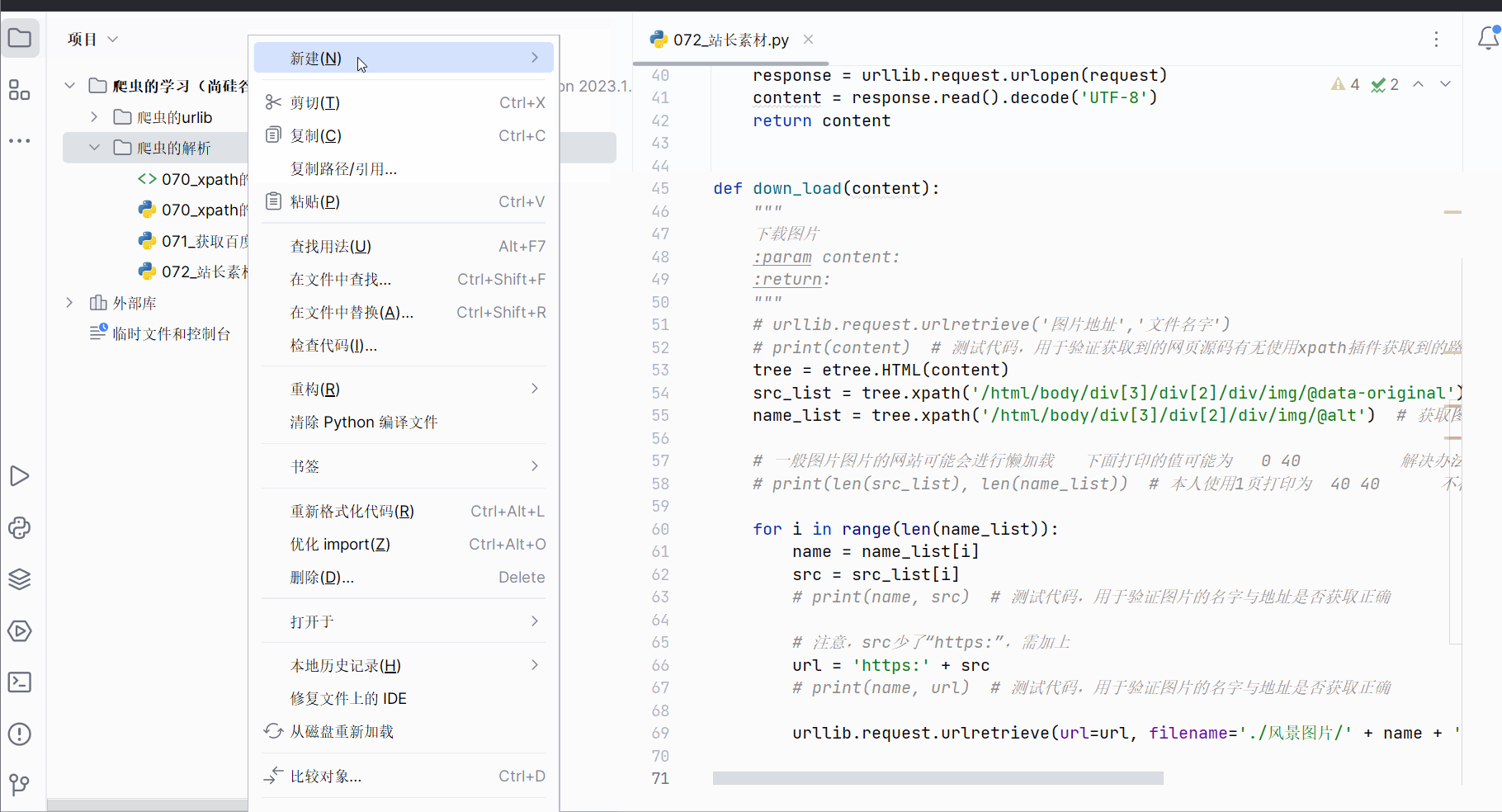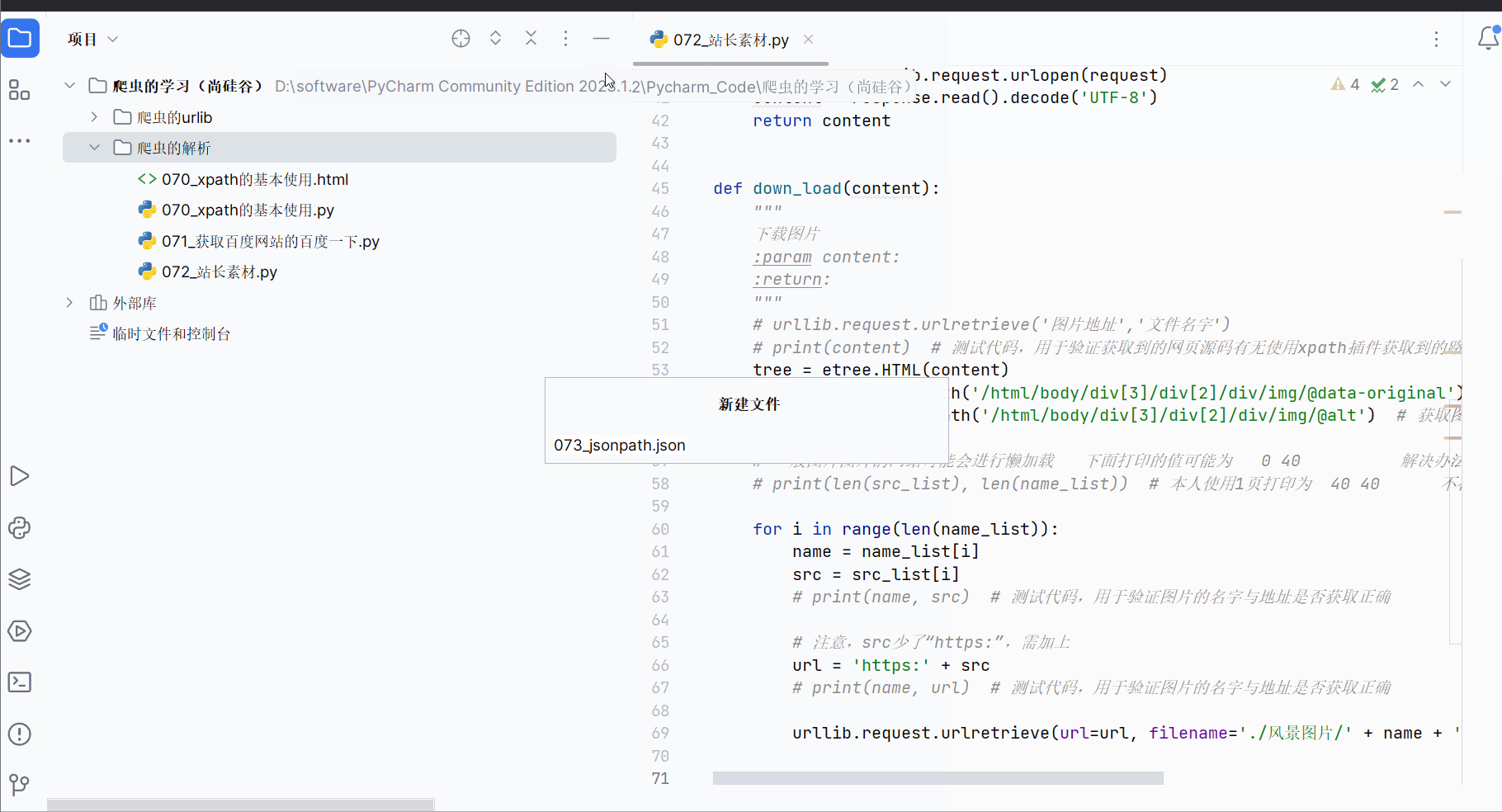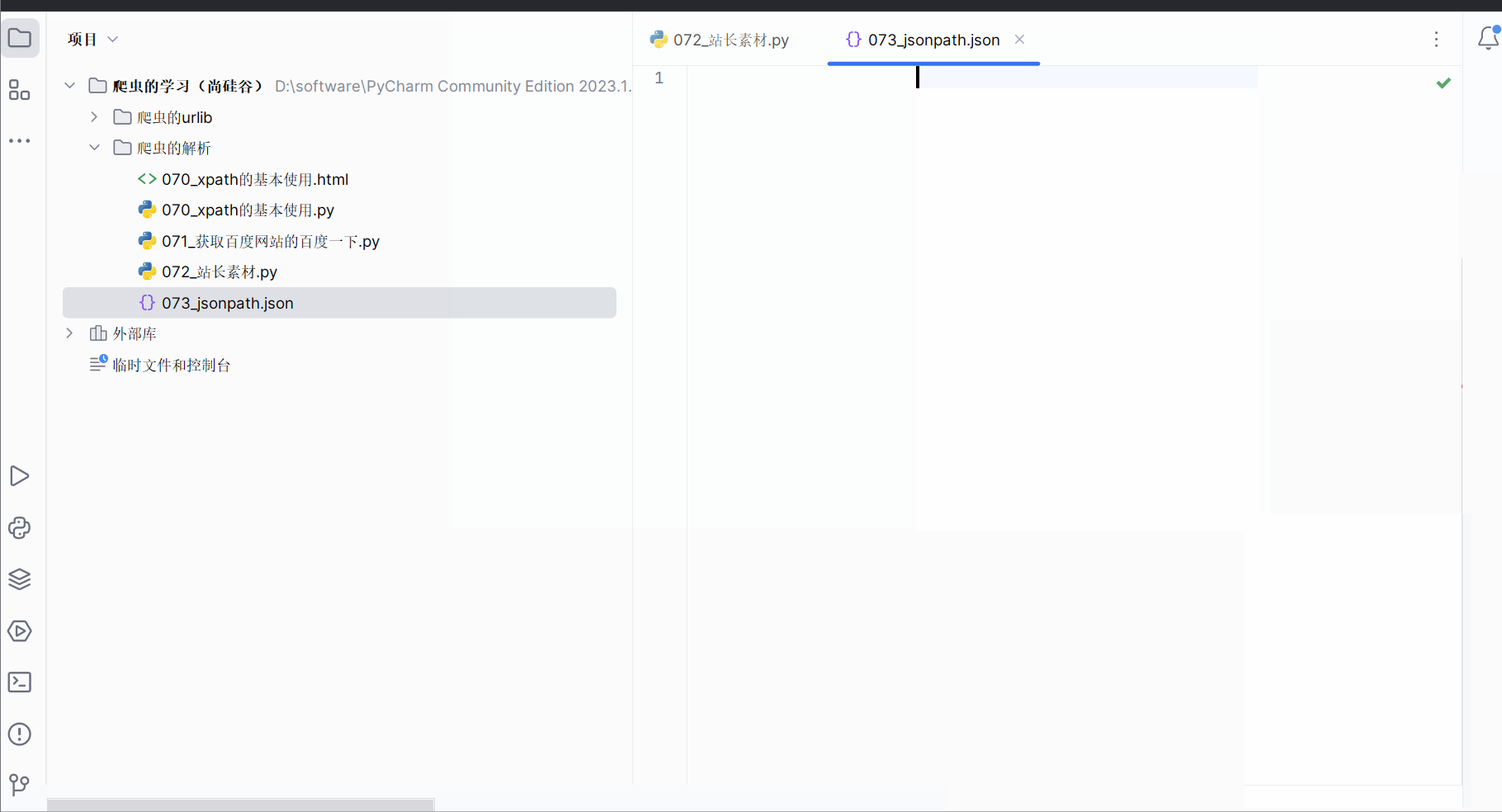
首先,创建文件“072_站长素材.py”。
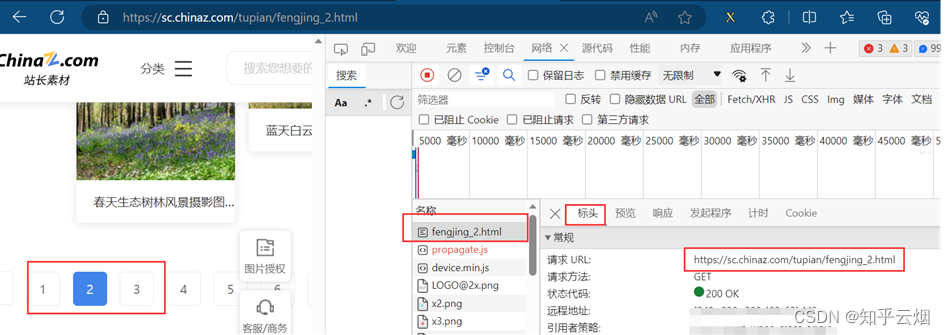
如下图所示,打开检查的网络。然后刷新一下,找到图片第一页对应的请求链接,在新的网页中打开验证一下。之后将该链接复制到PyCharm中。同理,将第2页、第3页的链接复制到PyCharm中,并观察这几个请求地址的区别。

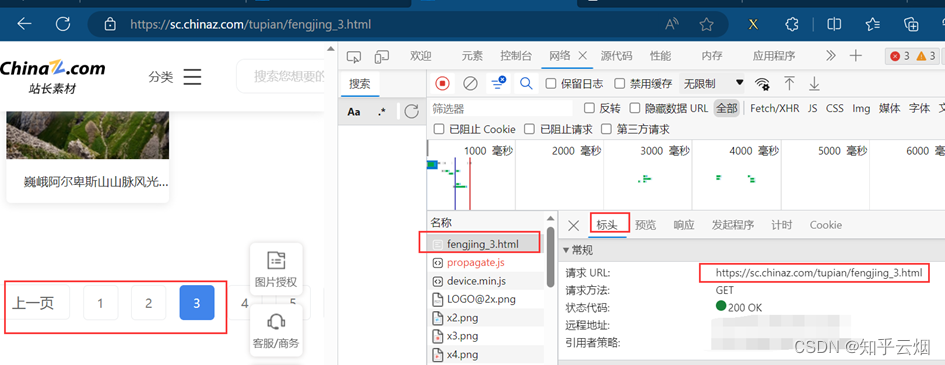

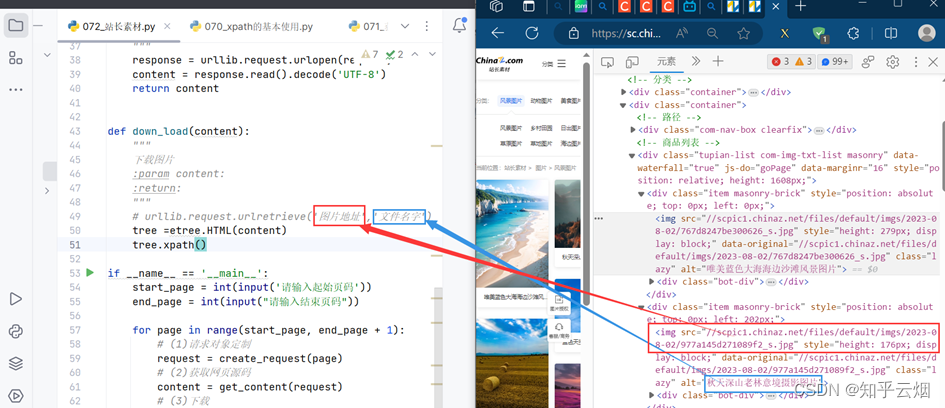
接着去编程,其中有一步代码需要参考下图进行理解。然后需要使用xpath插件去寻找图片地址与文件名字。
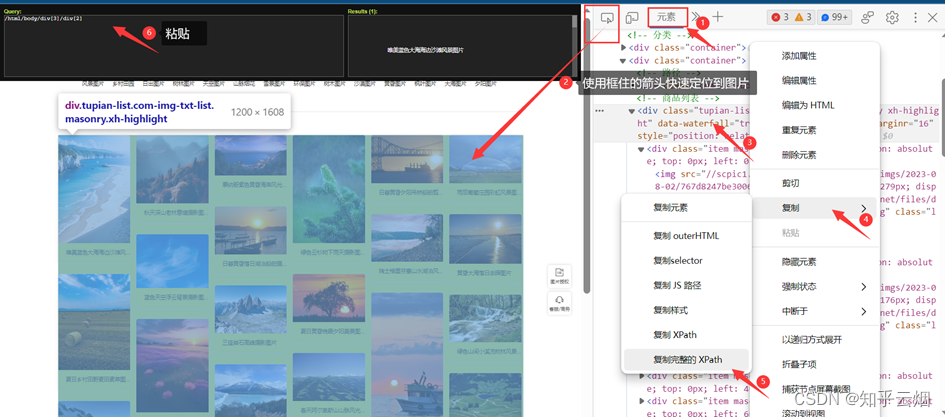
如下图,使用快捷键Ctr+Alt+X打开xpath,然后寻找到图片的路径,将路径复制到PyCharm中。
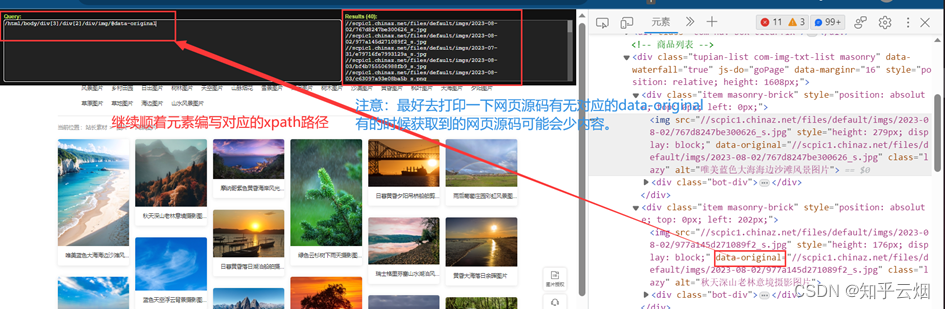
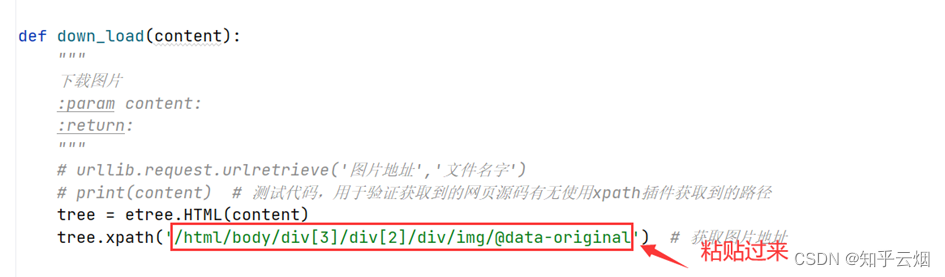
同理,可获取图片名。
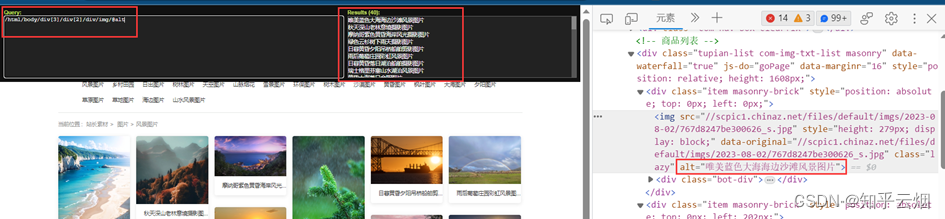
代码编写到此,可以验证有没有成功获取到对应路径。另外,如果想要下载高清图可以删掉地址里的“_s”。
"""
需求:下载前十页图片
"""# 第一页
# https://sc.chinaz.com/tupian/fengjing.html
# 第二页
# https://sc.chinaz.com/tupian/fengjing_2.html
# 第三页
# https://sc.chinaz.com/tupian/fengjing_3.htmlimport urllib.request
from lxml import etreedef create_request(page: int):"""请求对象定制:param page:页码:return:请求对象定制的结果"""# 访问地址if page == 1:url = 'https://sc.chinaz.com/tupian/fengjing.html'else:url = f"https://sc.chinaz.com/tupian/fengjing_{page}.html"# 请求头headers = {'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'}return urllib.request.Request(url=url, headers=headers)def get_content(request):"""获取网页源码:param request: 请求对象定制的结果:return: 获取的网页源码"""response = urllib.request.urlopen(request)content = response.read().decode('UTF-8')return contentdef down_load(content):"""下载图片:param content::return:"""# urllib.request.urlretrieve('图片地址','文件名字')# print(content) # 测试代码,用于验证获取到的网页源码有无使用xpath插件获取到的路径tree = etree.HTML(content)src_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@data-original') # 获取图片地址name_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@alt') # 获取图片名# 一般图片图片的网站可能会进行懒加载 下面打印的值可能为 0 40 解决办法:填写最初的元素对应的路径,不要填写加载后的路径# print(len(src_list), len(name_list)) # 本人使用1页打印为 40 40 不存在这个问题for i in range(len(name_list)):name = name_list[i]src = src_list[i]# print(name, src) # 测试代码,用于验证图片的名字与地址是否获取正确# 注意,src少了“https:”,需加上url = 'https:' + srcprint(name, url) # 测试代码,用于验证图片的名字与地址是否获取正确# urllib.request.urlretrieve(url=url, filename=name + '.jpg')if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input("请输入结束页码"))for page in range(start_page, end_page + 1):# (1)请求对象定制request = create_request(page)# (2)获取网页源码content = get_content(request)# (3)下载down_load(content)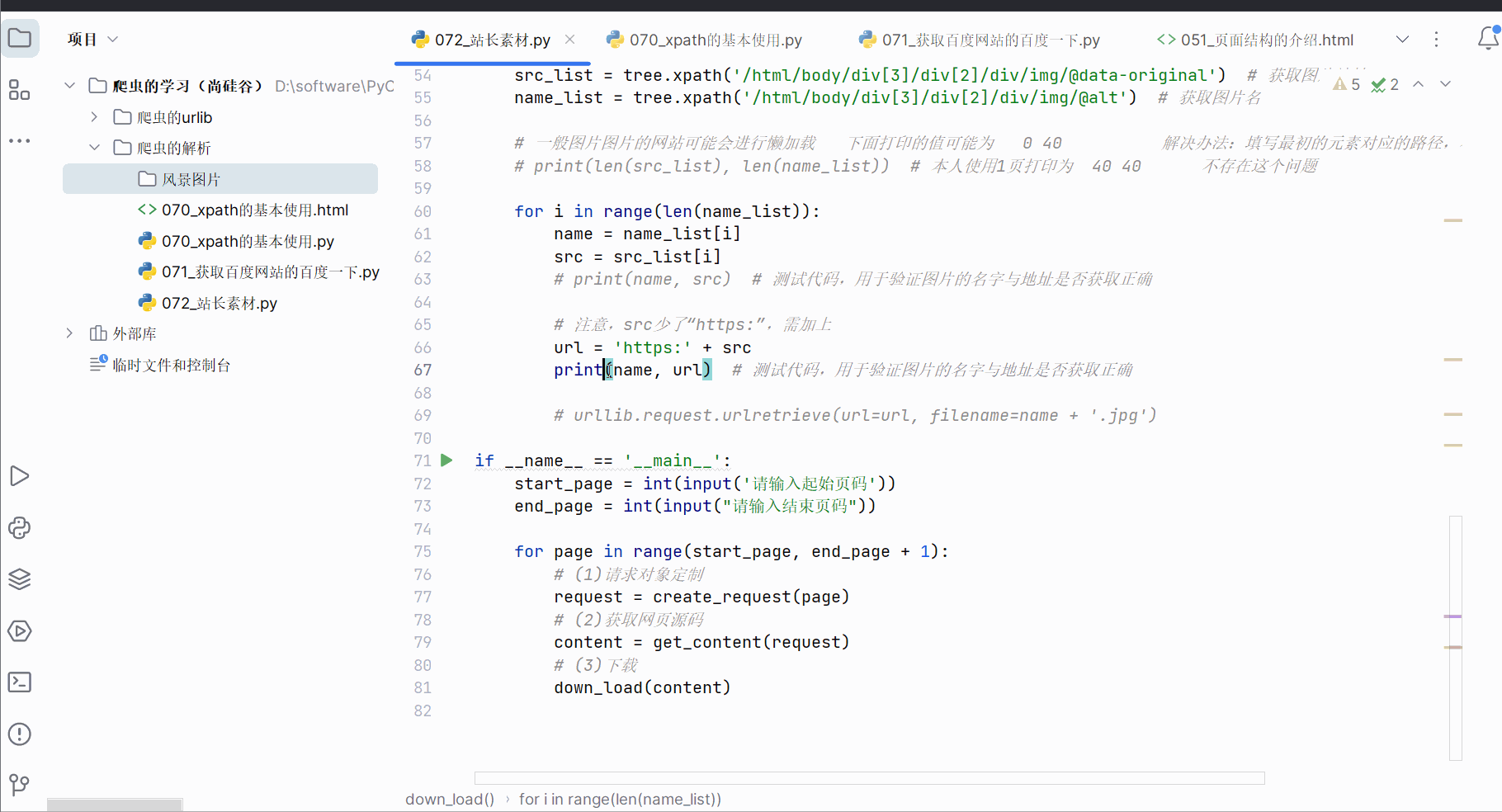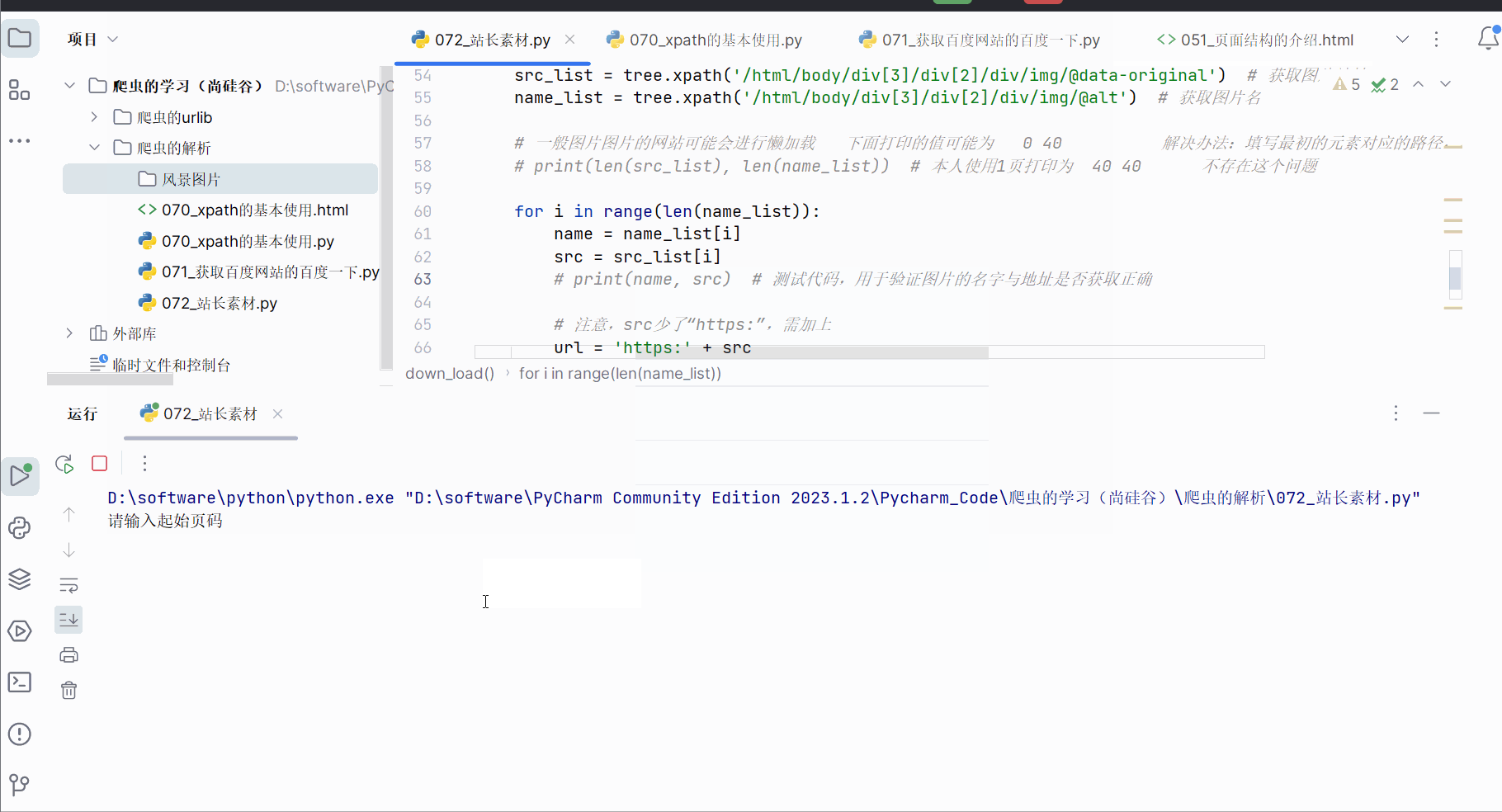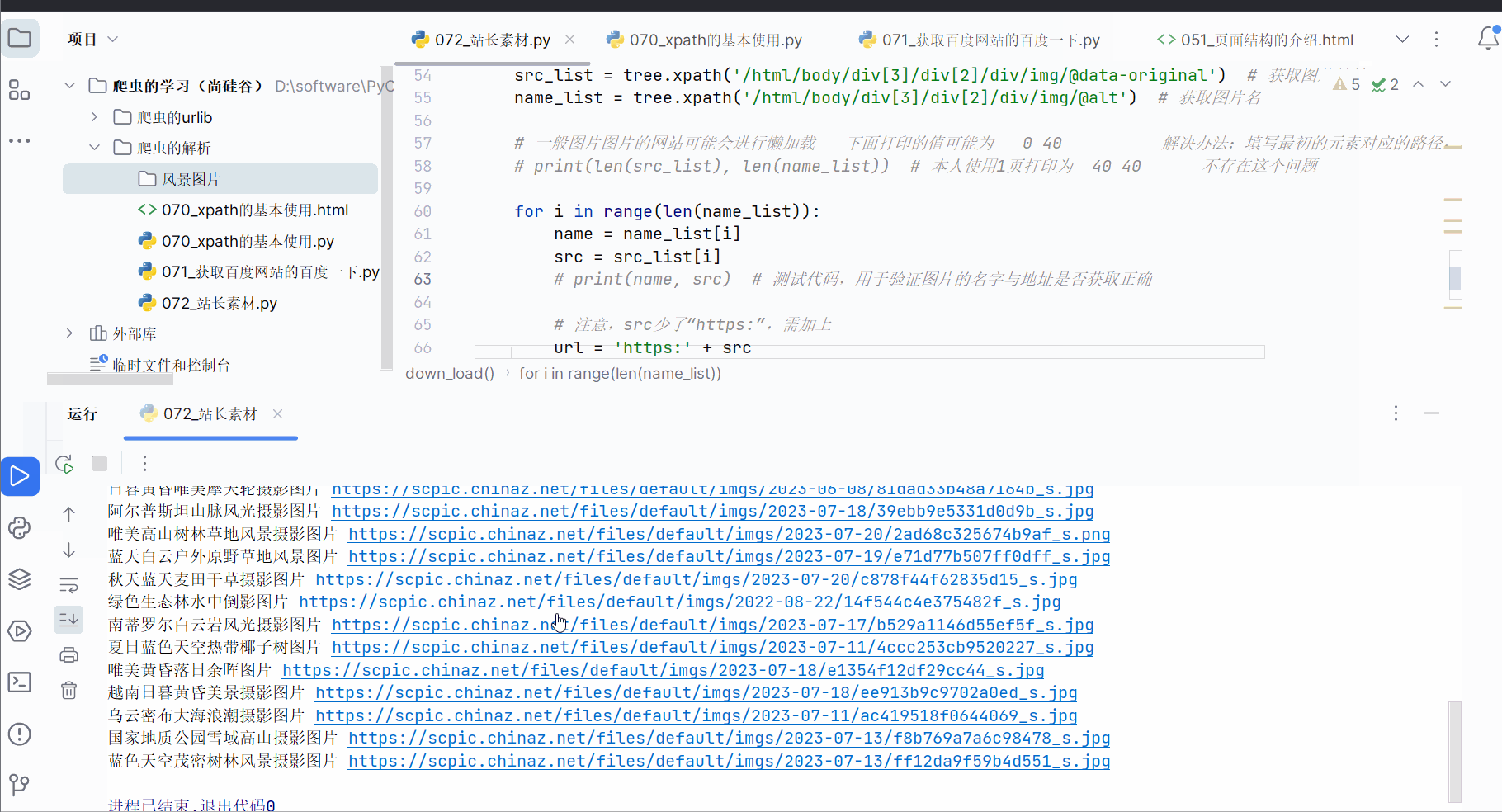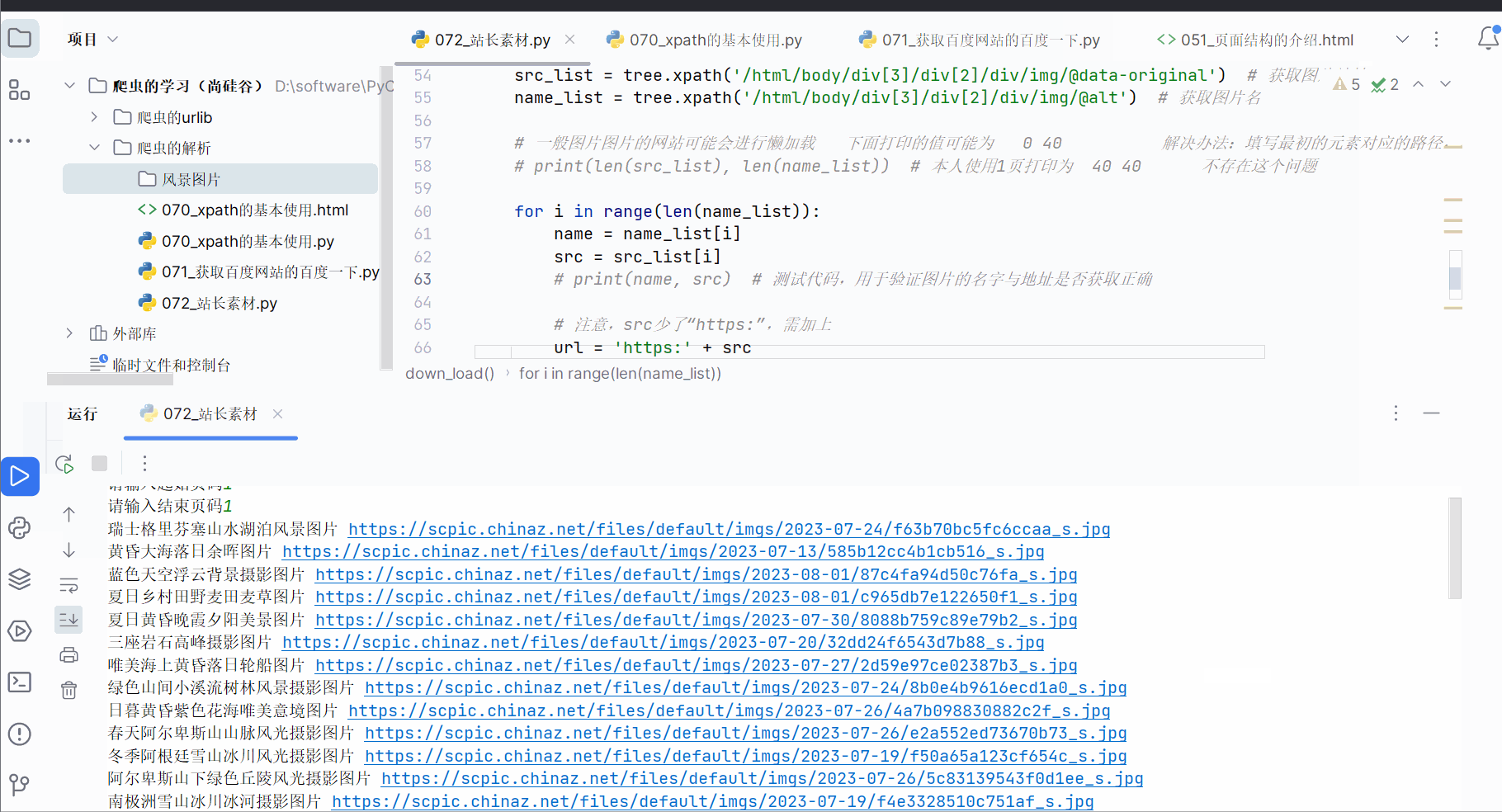
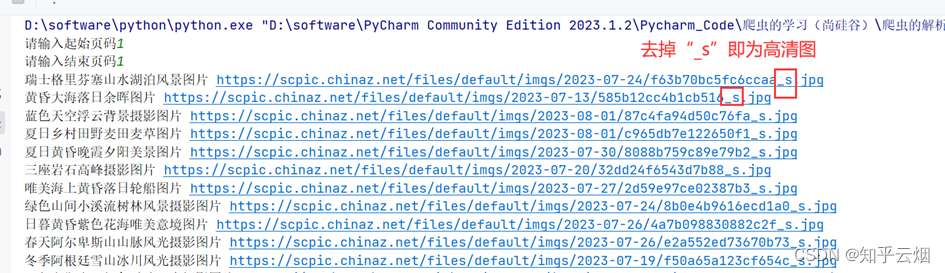
为了将下载的图片放到一个文件夹中,如下图所示,创建一个名为“风景图片”的文件夹。
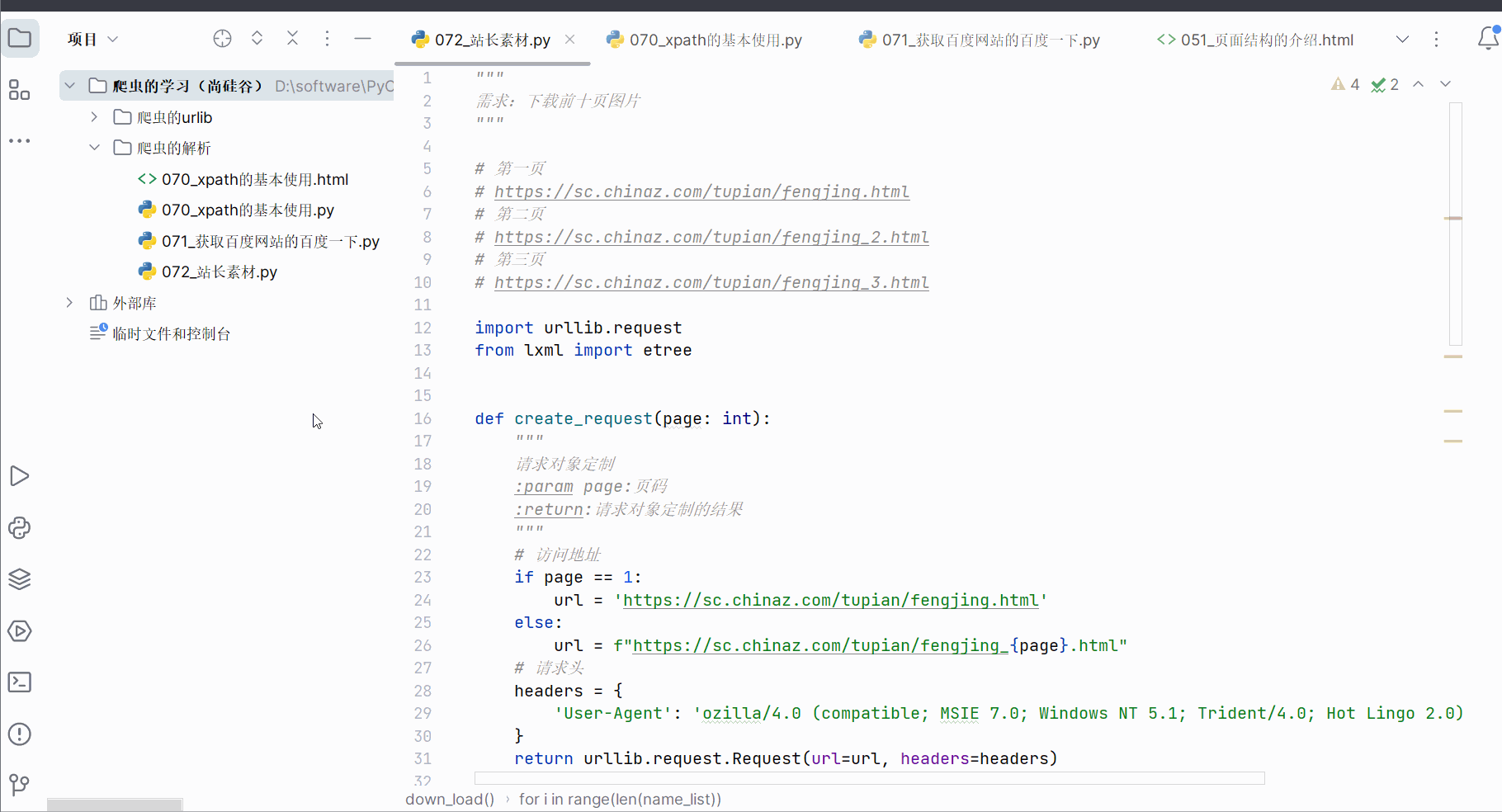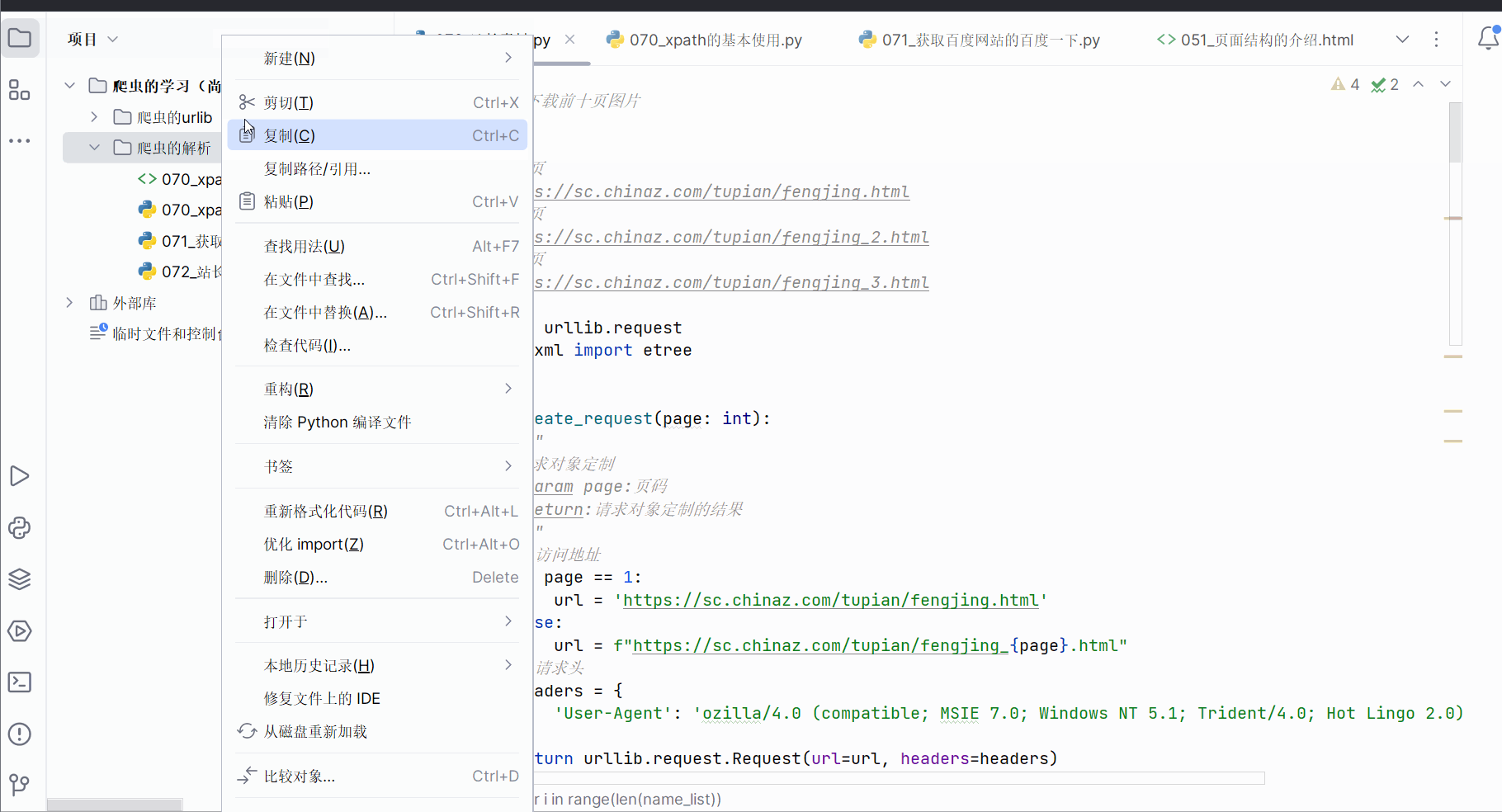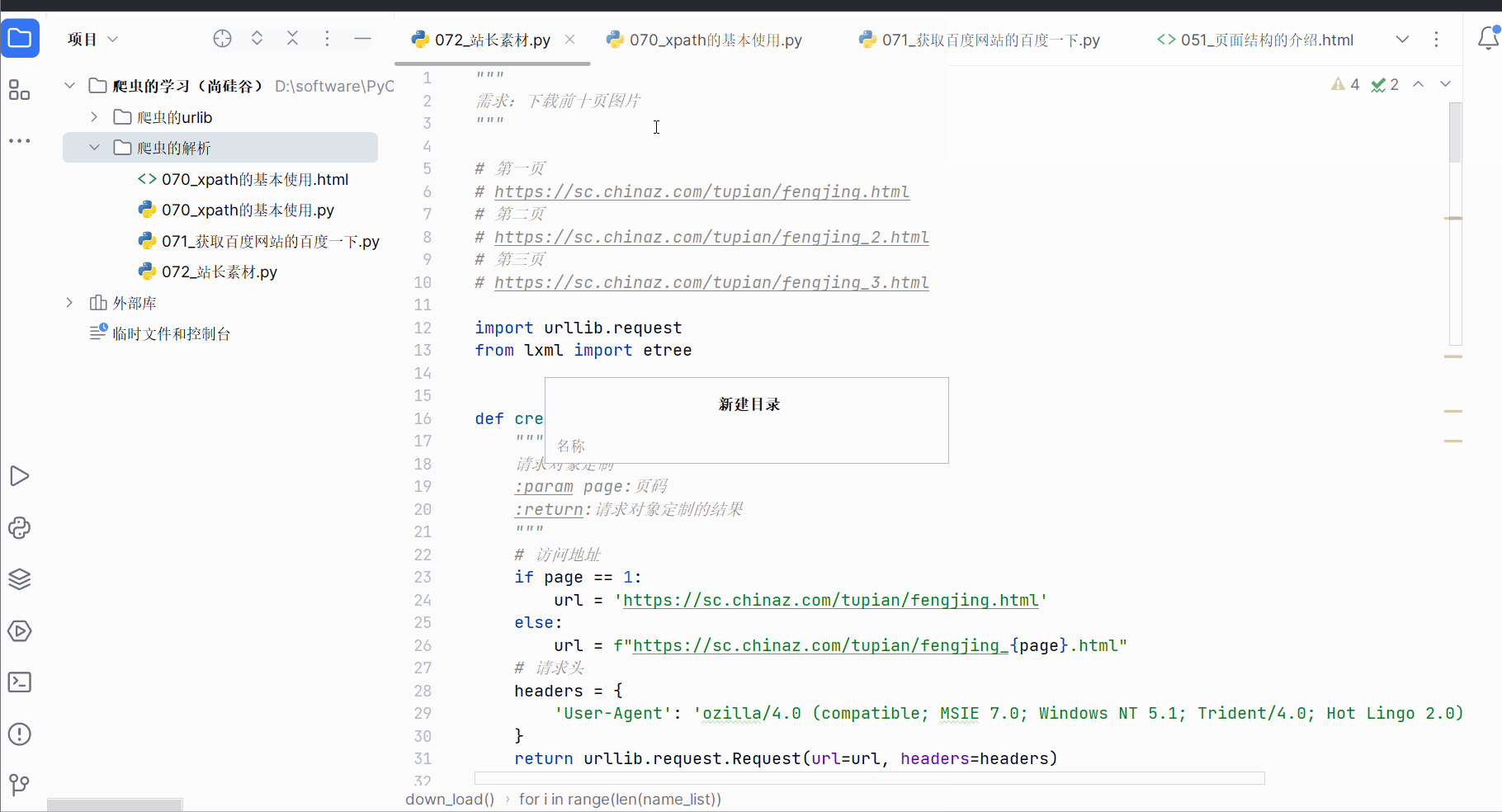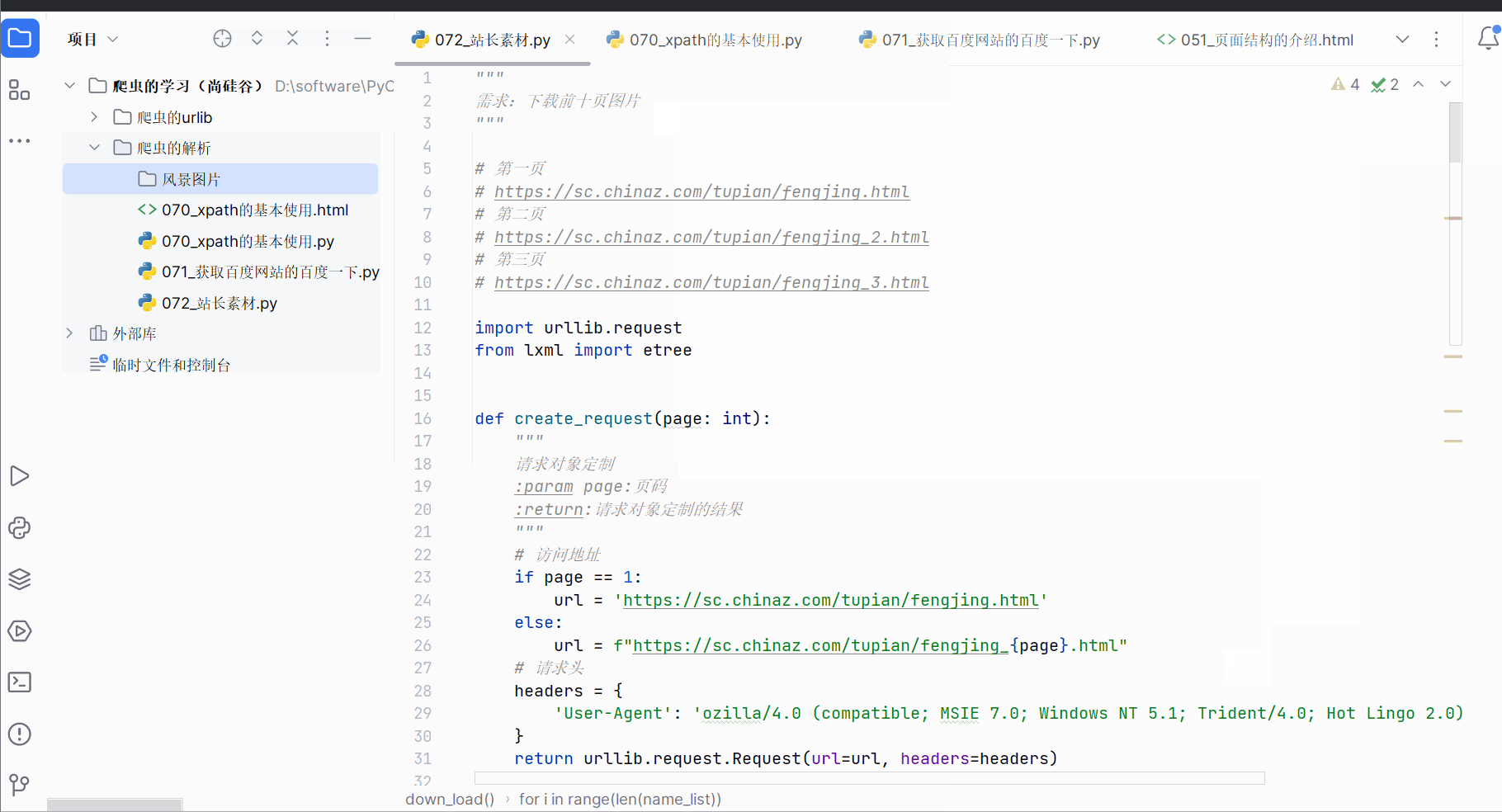
如下进行编程,即可获取前10页图片。
"""
需求:下载前十页图片
"""# 第一页
# https://sc.chinaz.com/tupian/fengjing.html
# 第二页
# https://sc.chinaz.com/tupian/fengjing_2.html
# 第三页
# https://sc.chinaz.com/tupian/fengjing_3.htmlimport urllib.request
from lxml import etreedef create_request(page: int):"""请求对象定制:param page:页码:return:请求对象定制的结果"""# 访问地址if page == 1:url = 'https://sc.chinaz.com/tupian/fengjing.html'else:url = f"https://sc.chinaz.com/tupian/fengjing_{page}.html"# 请求头headers = {'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'}return urllib.request.Request(url=url, headers=headers)def get_content(request):"""获取网页源码:param request: 请求对象定制的结果:return: 获取的网页源码"""response = urllib.request.urlopen(request)content = response.read().decode('UTF-8')return contentdef down_load(content):"""下载图片:param content::return:"""# urllib.request.urlretrieve('图片地址','文件名字')# print(content) # 测试代码,用于验证获取到的网页源码有无使用xpath插件获取到的路径tree = etree.HTML(content)src_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@data-original') # 获取图片地址name_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@alt') # 获取图片名# 一般图片图片的网站可能会进行懒加载 下面打印的值可能为 0 40 解决办法:填写最初的元素对应的路径,不要填写加载后的路径# print(len(src_list), len(name_list)) # 本人使用1页打印为 40 40 不存在这个问题for i in range(len(name_list)):name = name_list[i]src = src_list[i]# print(name, src) # 测试代码,用于验证图片的名字与地址是否获取正确# 注意,src少了“https:”,需加上url = 'https:' + src# print(name, url) # 测试代码,用于验证图片的名字与地址是否获取正确urllib.request.urlretrieve(url=url, filename='./风景图片/' + name + '.jpg')if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input("请输入结束页码"))for page in range(start_page, end_page + 1):# (1)请求对象定制request = create_request(page)# (2)获取网页源码content = get_content(request)# (3)下载down_load(content)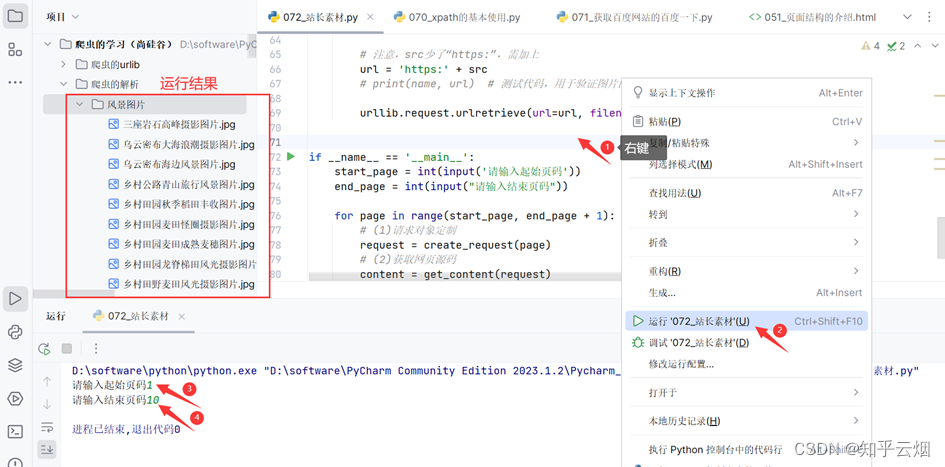
二、JsonPath
1.JsonPath的基本介绍
(1)引
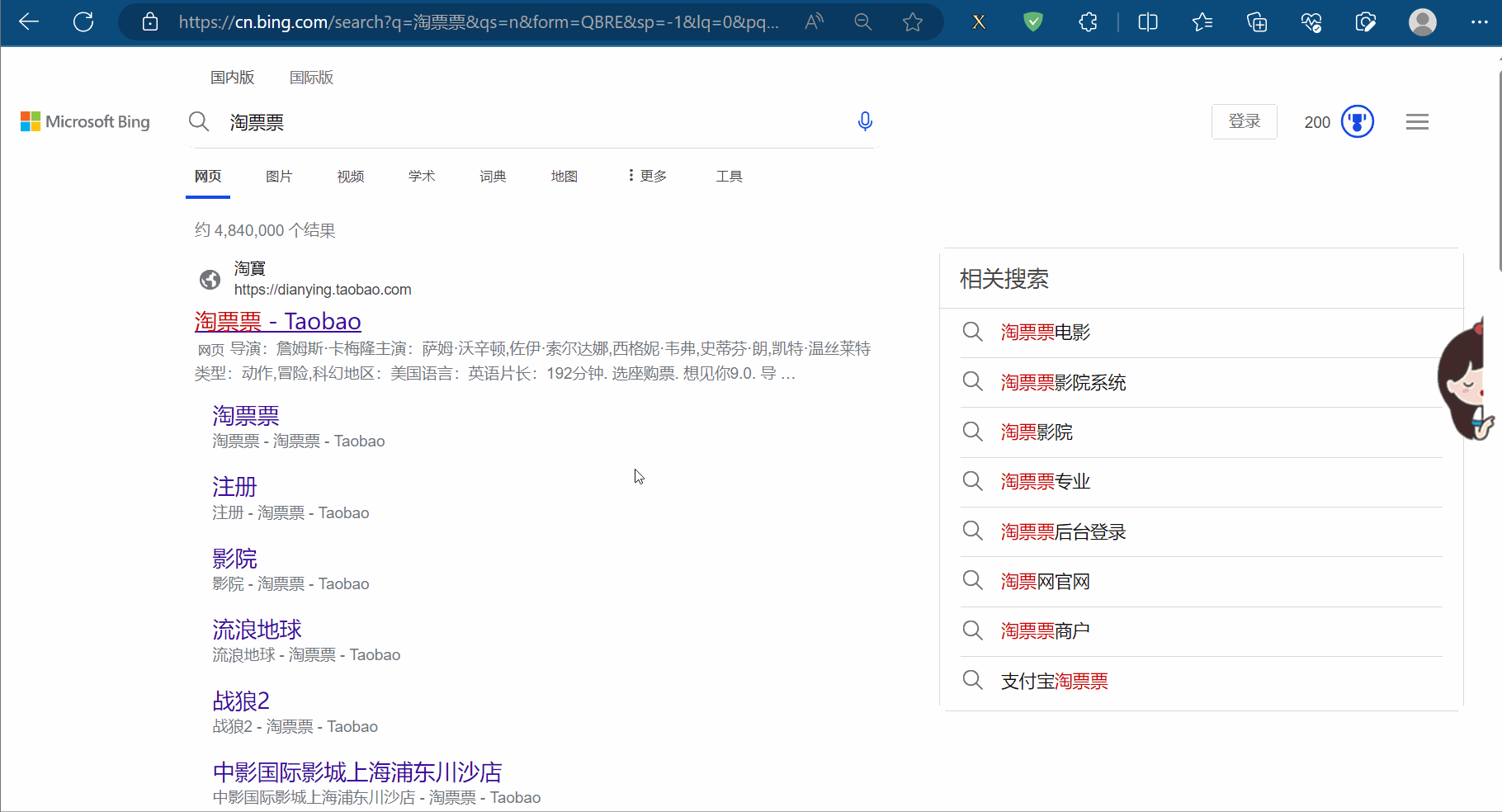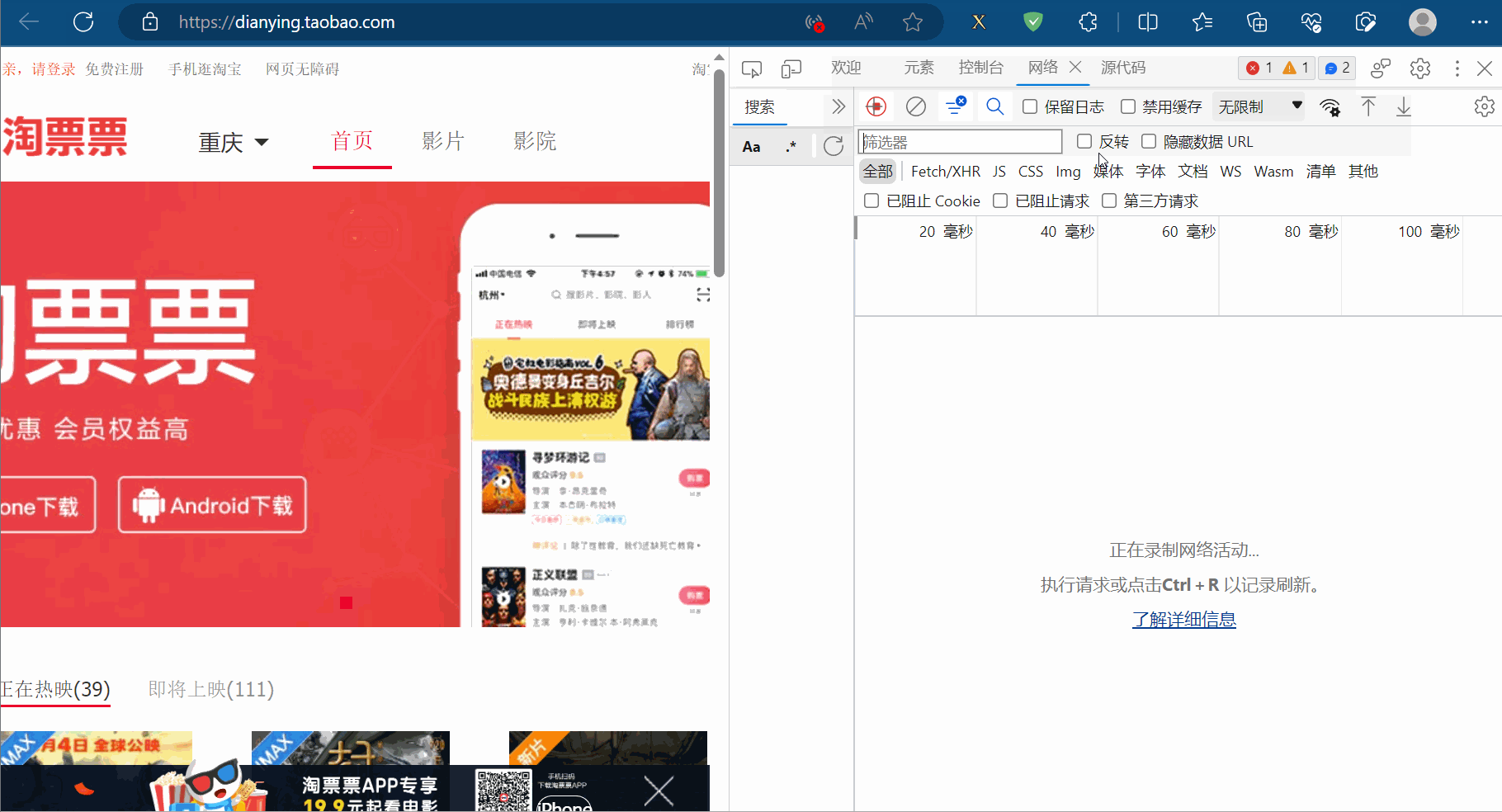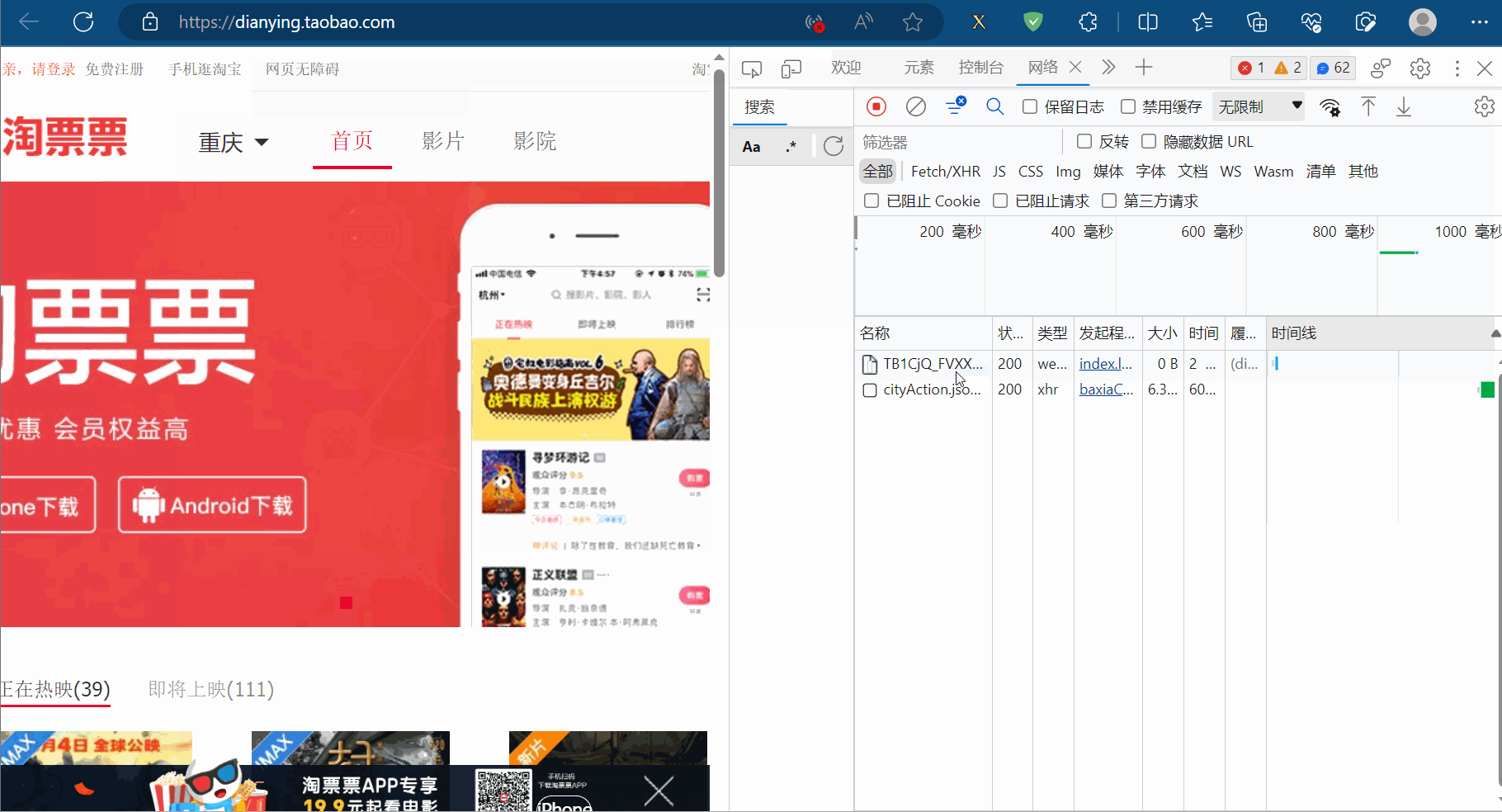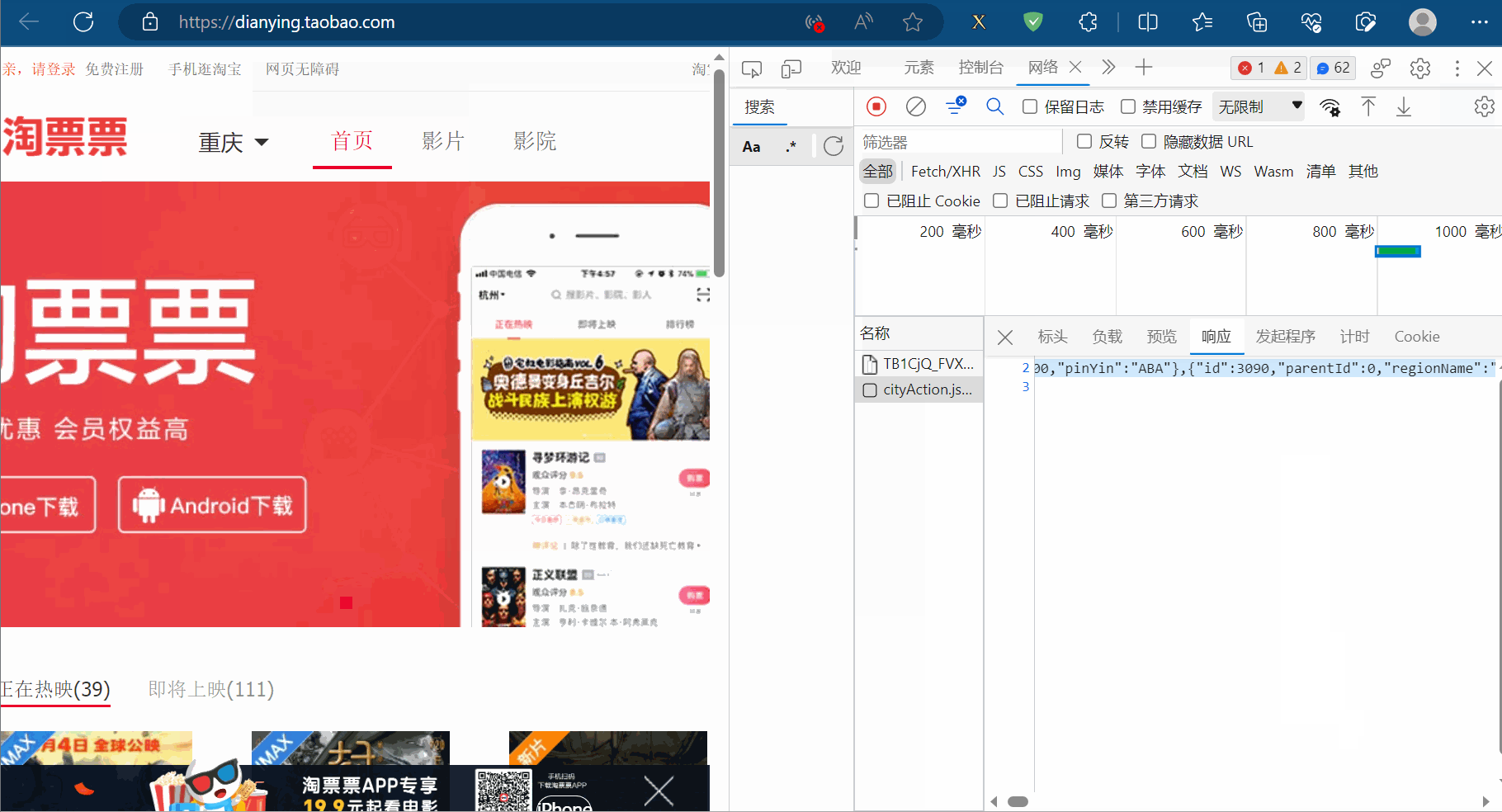
JsonPath用于解析网页源码的返回值为Json数据的网站。比如打开“淘票票”(网址为“https://dianying.taobao.com/”),按F12打开检查,点到网络。然后点击“淘票票”中的城市,会得到一个网络包,发现它是一个Json数据。下一小节将爬取该数据包存储的淘票票支持的城市。
(2)jsonpath的安装及使用方式

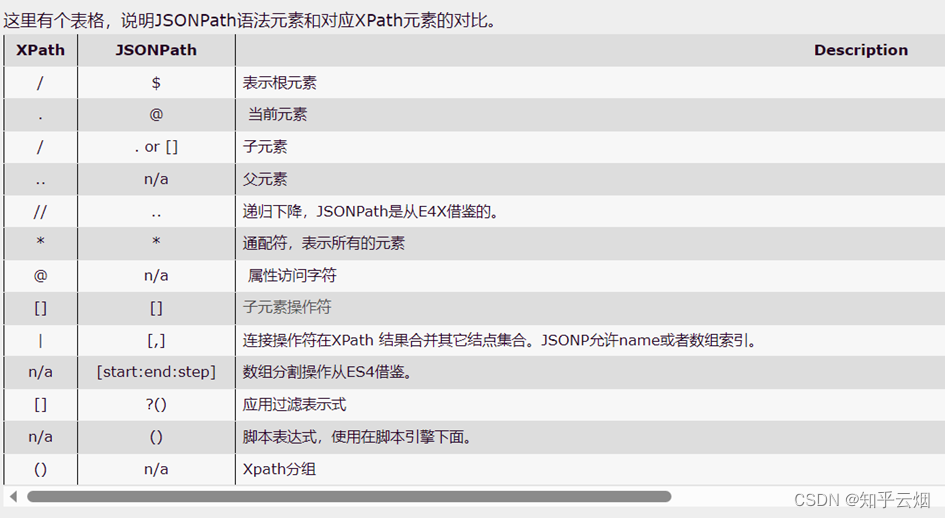
下图来源于“https://blog.csdn.net/luxideyao/article/details/77802389”,里面介绍了xpath和JsonPath路径在语法上的区别。
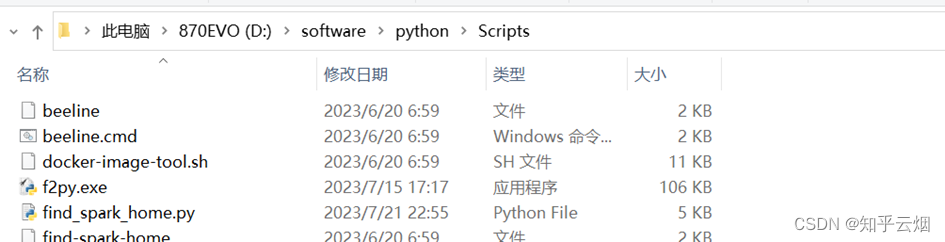
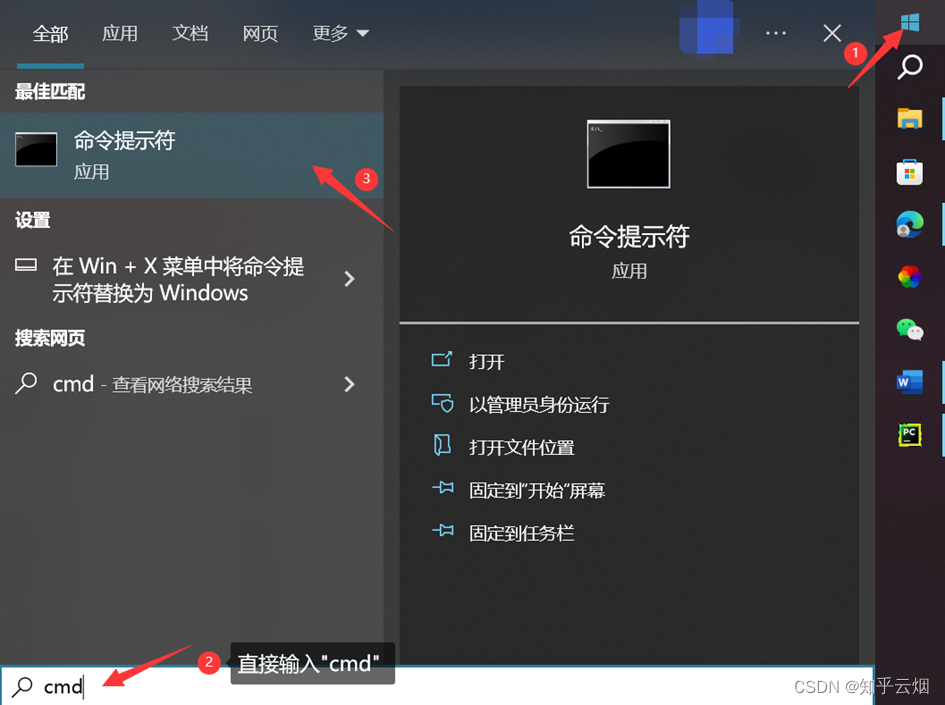
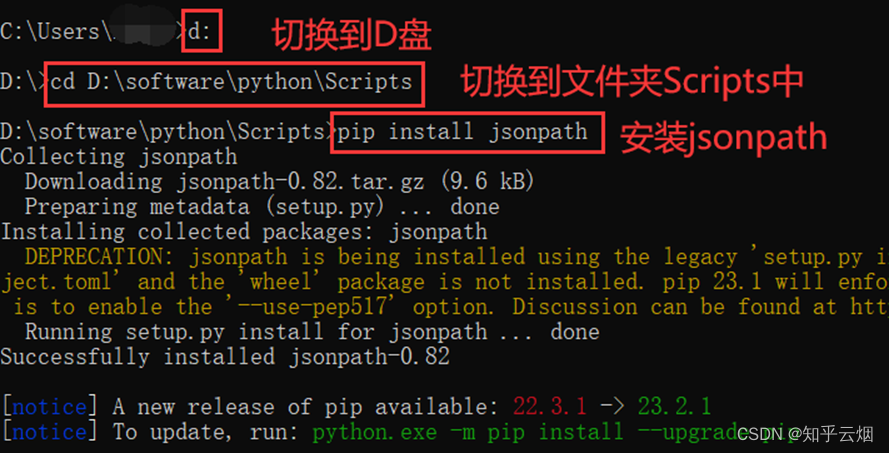
Jsonpath的安装方法如下几张图所示,首先找到python安装路径里的文件夹Scripts,里面专门用于存放python包。然后打开命令提示符,将命令行控制到文件夹Scripts中,并输入命令“pip install jsonpath”。
(3)代码演示
首先,创建文件“073_jsonpath.json”,输入以下内容。
{"store": {"book": [{"category": "修真","author": "六道","title": "环蛋是怎样练成的","price": 8.95},{"category": "修真","author": "天蚕土豆","title": "斗破苍穹","price": 12.99},{"category": "修真","author": "唐家三少","title": "斗罗大陆","isbn": "0-553-21311-3","price": 8.99},{"category": "修真","author": "南派三叔","title": "星辰变","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "黑色","price": 19.95}}
}
本次需要爬取下图圈出来的书名,类似地,获取书的作者等等来熟悉JsonPath的语法。

创建文件“073_jsonpath.py”。
编写代码,运行程序,学会jsonpath的基本使用。
"""
jsonpath使用的演示
"""
import json
import jsonpath# 加载json数据
obj = json.load(open('073_jsonpath.json', 'r', encoding='UTF-8'))
'''
json.load:从文件中加载 JSON 数据
json.loads:将 JSON 字符串转换为 Python 对象
'''# 书店所有书的作者 jsonpath.jsonpath(json数据,'json路径')
author_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
print(f"书店所有书的作者:{author_list}")# 书店第一本书的作者 jsonpath.jsonpath(json数据,'json路径')
author_first = jsonpath.jsonpath(obj, '$.store.book[0].author')
print(f"书店第一本书的作者:{author_first}")# 所有的作者
author_list = jsonpath.jsonpath(obj, '$..author')
print(f"所有的作者:{author_list}")# store下面的所有元素
tag_list = jsonpath.jsonpath(obj, '$.store.*')
print(f"store下面的所有元素:{tag_list}")# store里面所有东西的price
price_list = jsonpath.jsonpath(obj, '$.store..price')
print(f"store里面所有东西的price:{price_list}")# 第三本书
book = jsonpath.jsonpath(obj, '$..book[2]')
print(f"第三本书:{book}")# 最后一本书
book = jsonpath.jsonpath(obj, '$..book[(@.length-1)]')
print(f"最后一本书:{book}")# 前面的两本书
book_list = jsonpath.jsonpath(obj, '$..book[0,1]')
print(f"前面的两本书:{book_list}")book_list = jsonpath.jsonpath(obj, '$..book[:2]') # 切片的方式
print(f"前面的两本书:{book_list}")# 过滤出所有的包含版本号isbn的书 条件过滤需要在()前添加一个“?”
book_list=jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
print(f"过滤出所有的包含版本号isbn的书:{book_list}")# 超过10块钱的书
book_list=jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(f"超过10块钱的书:{book_list}")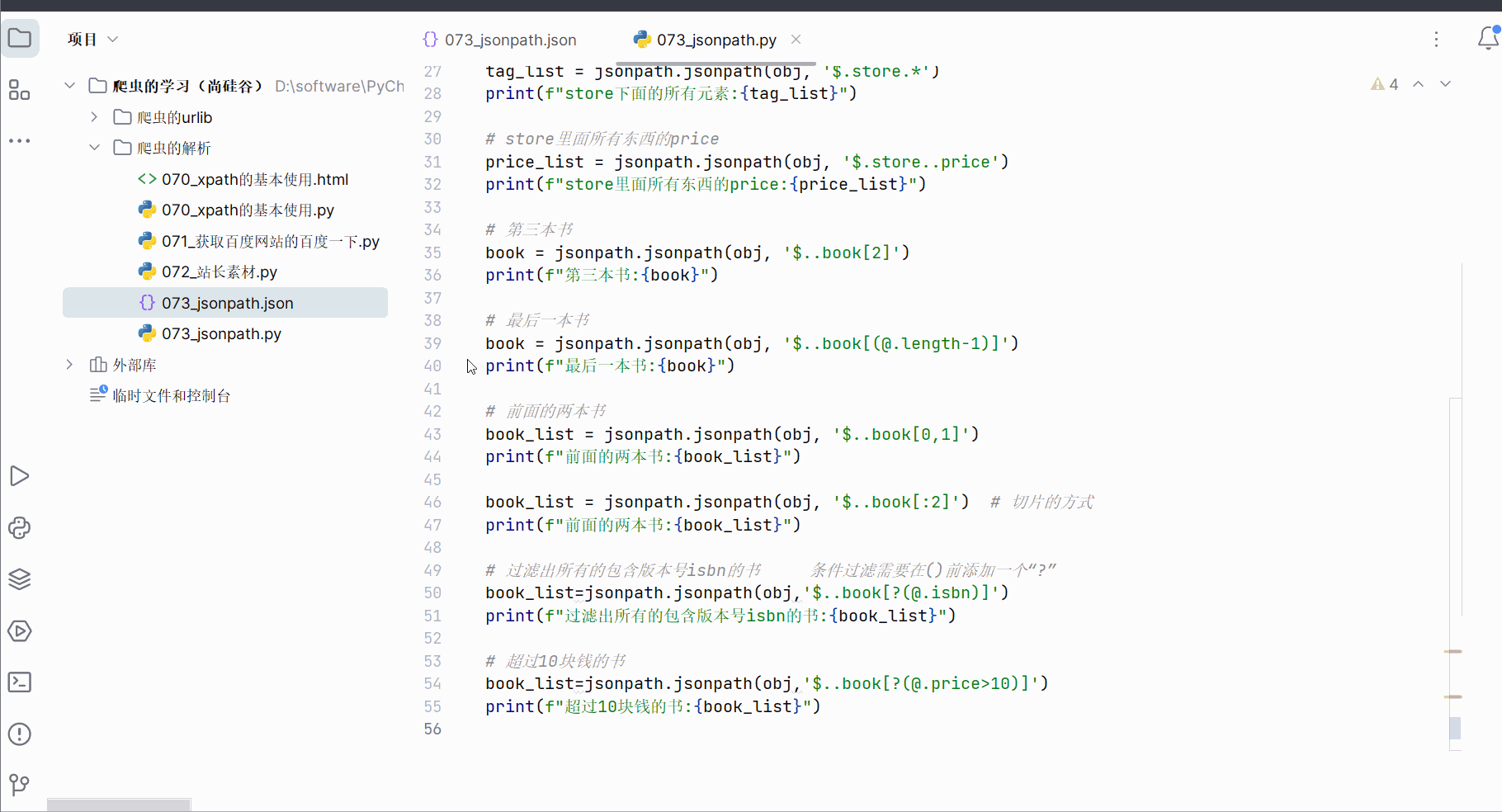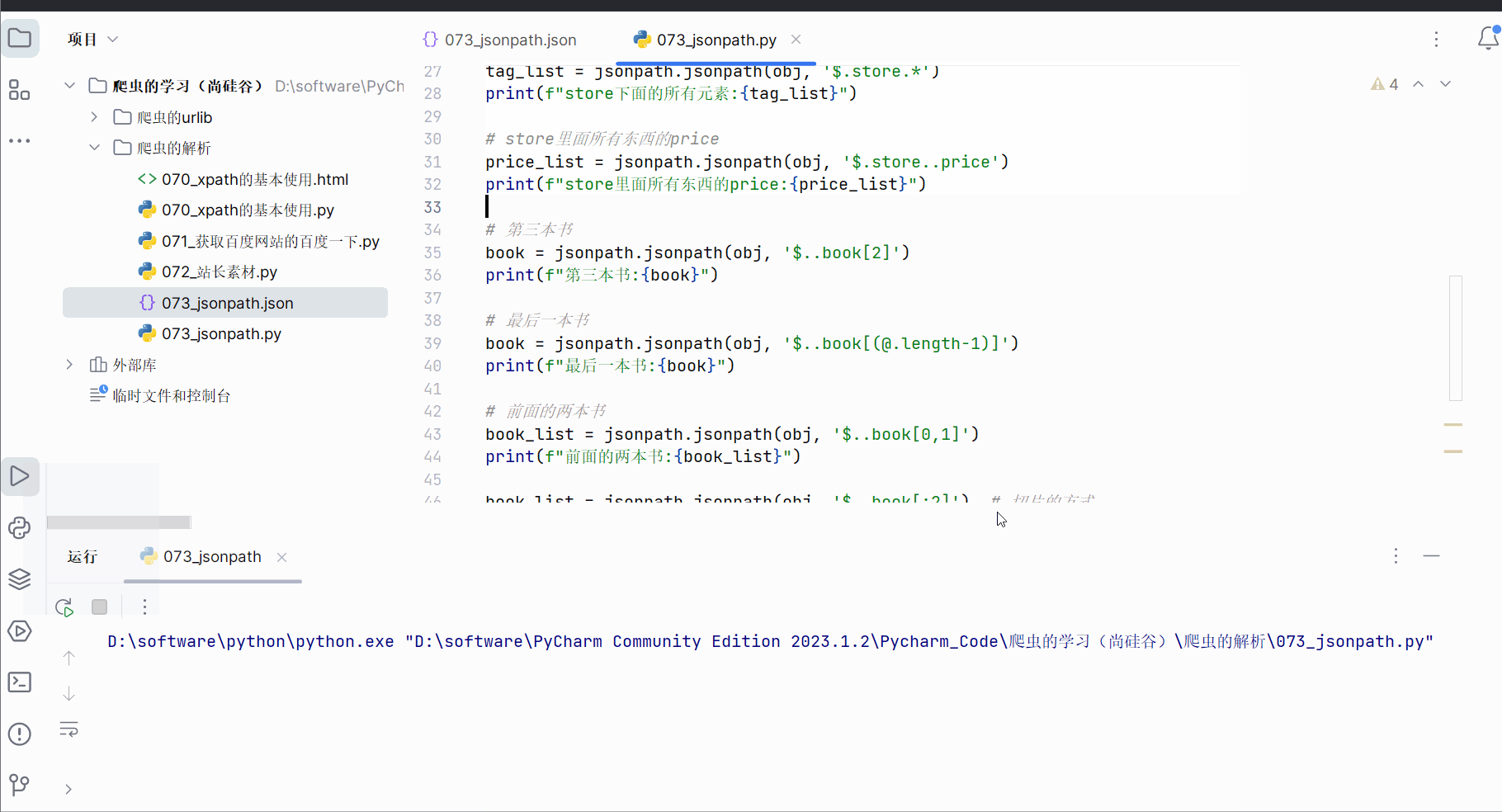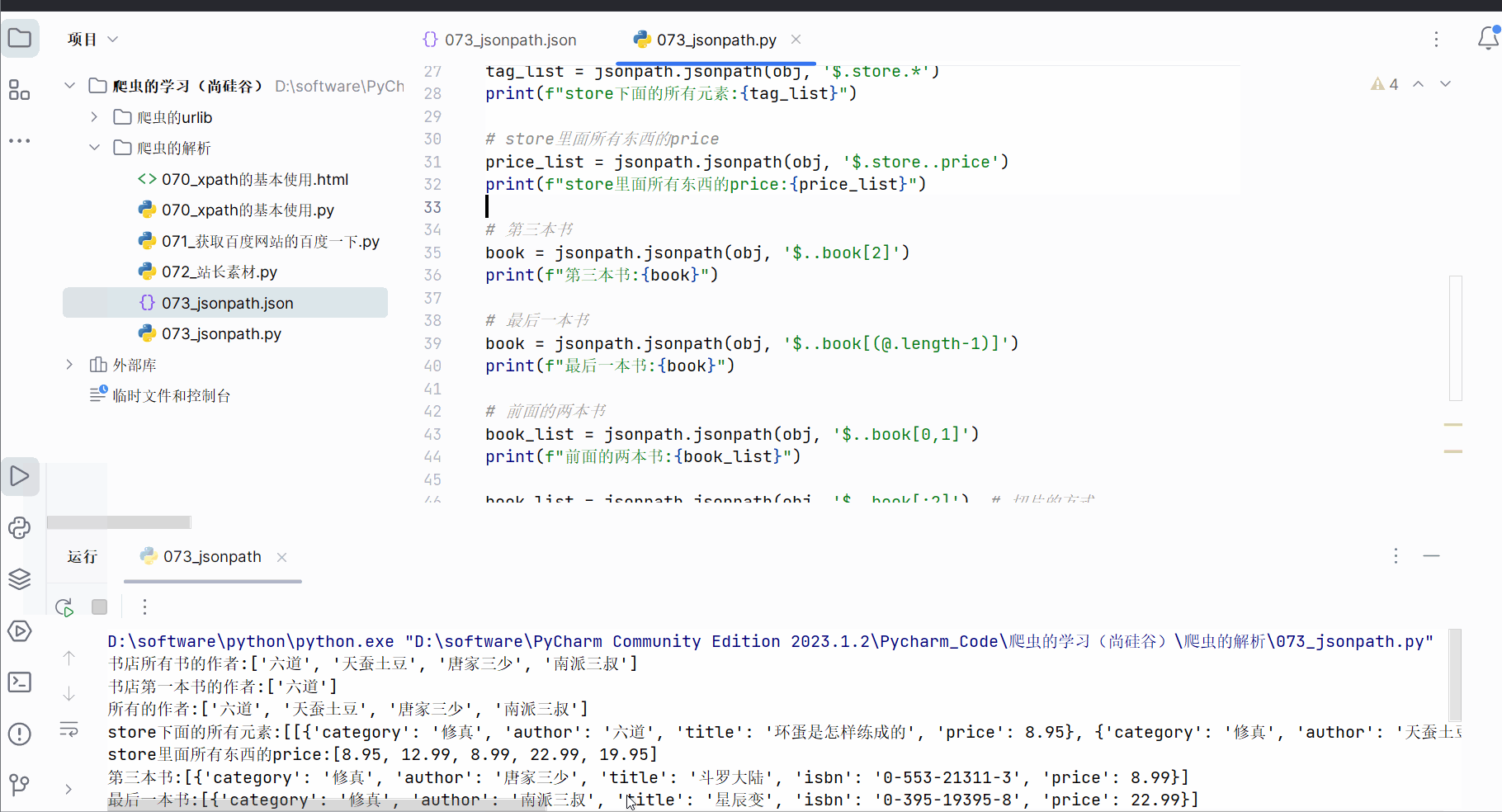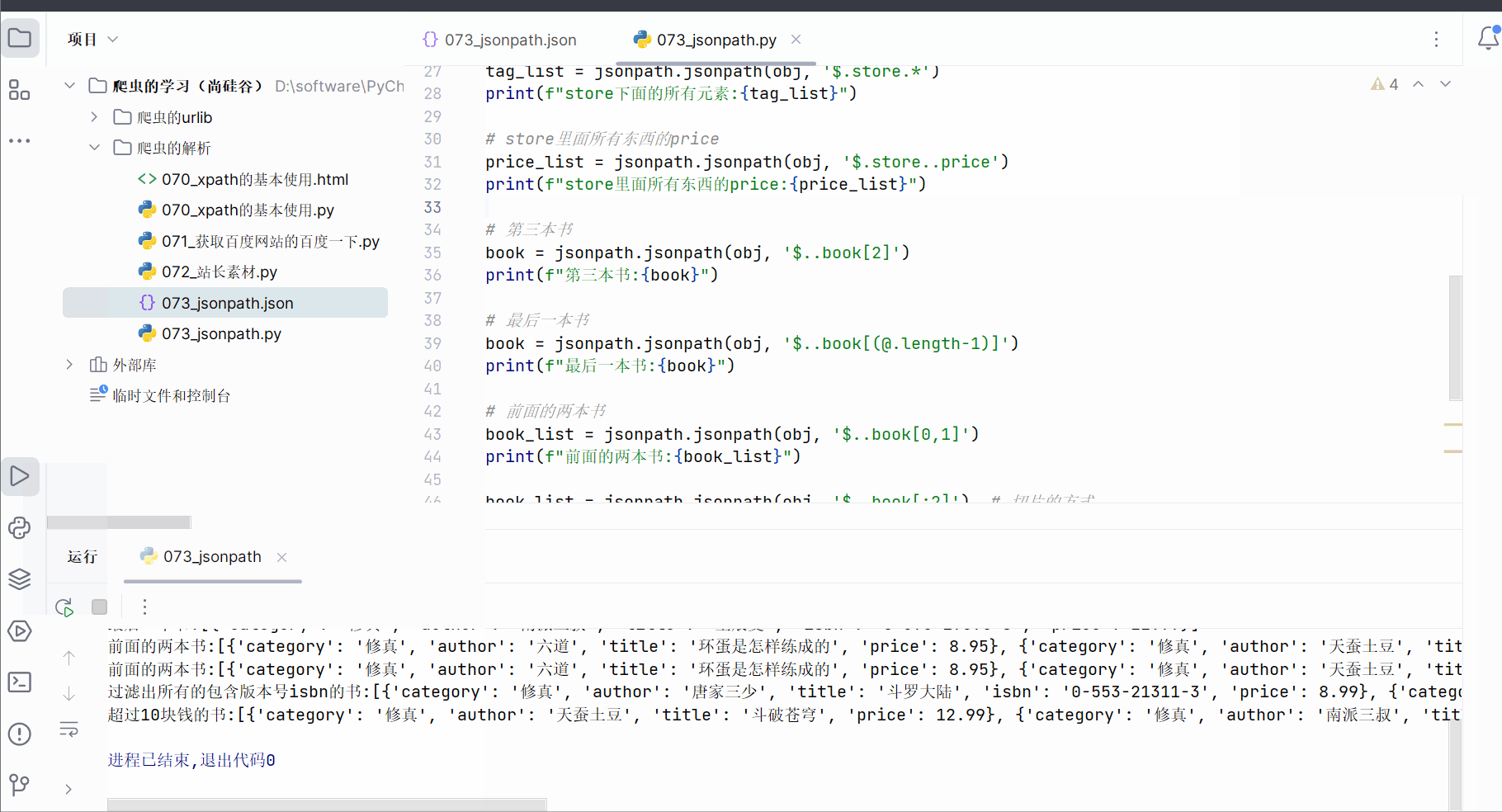
2.jsonpath解析淘票票
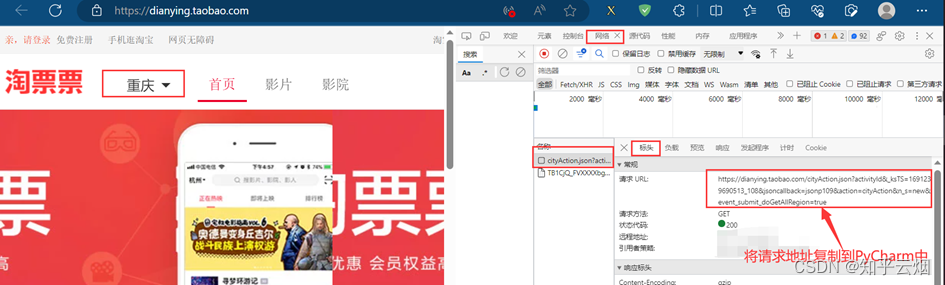
如下图,打开“淘票票”(网址为“https://dianying.taobao.com/”),按F12打开检查,点到网络。然后点击“淘票票”中的城市,会得到一个网络包,发现它是一个Json数据。本节将爬取该数据包存储的淘票票支持的城市。
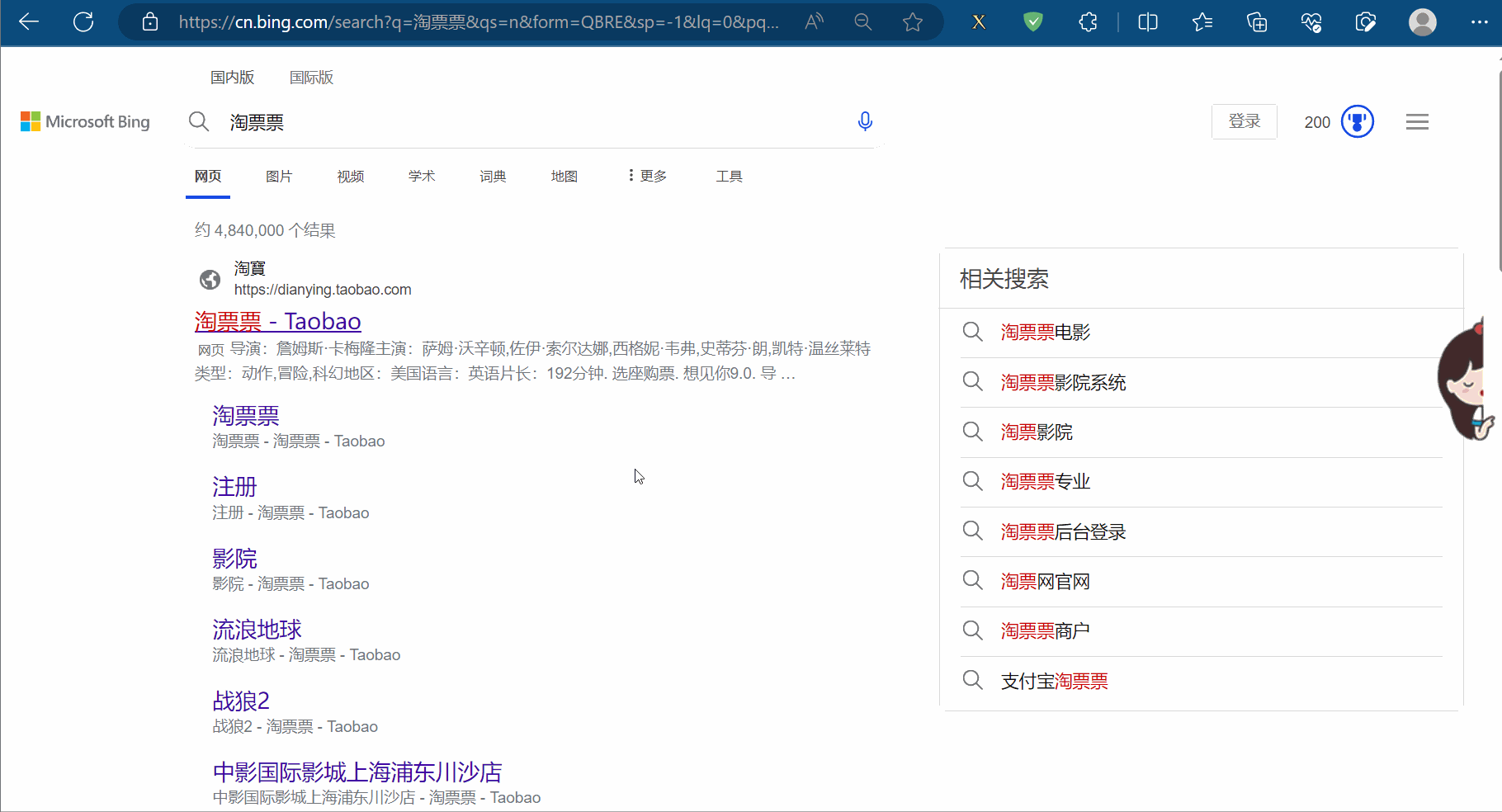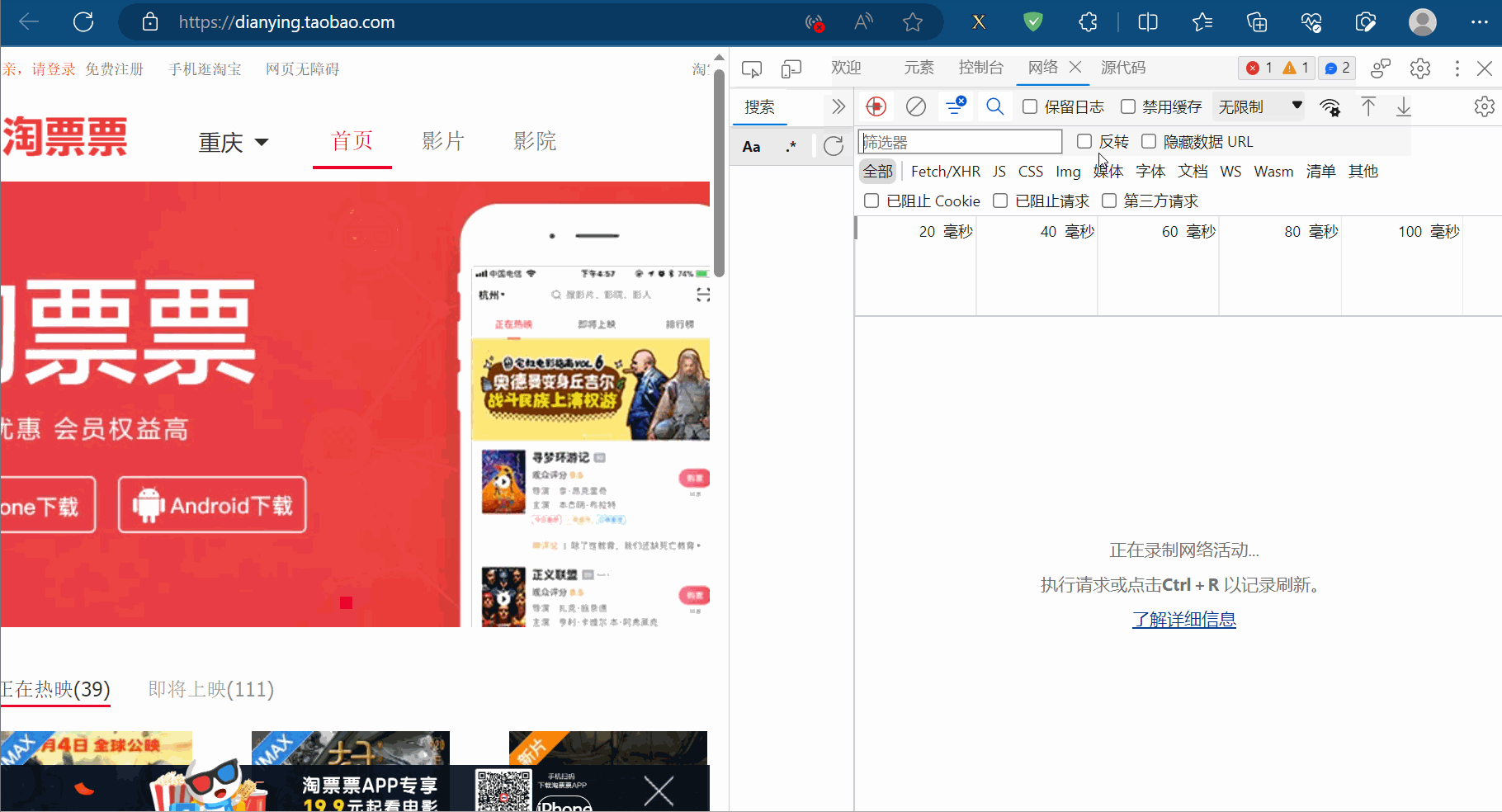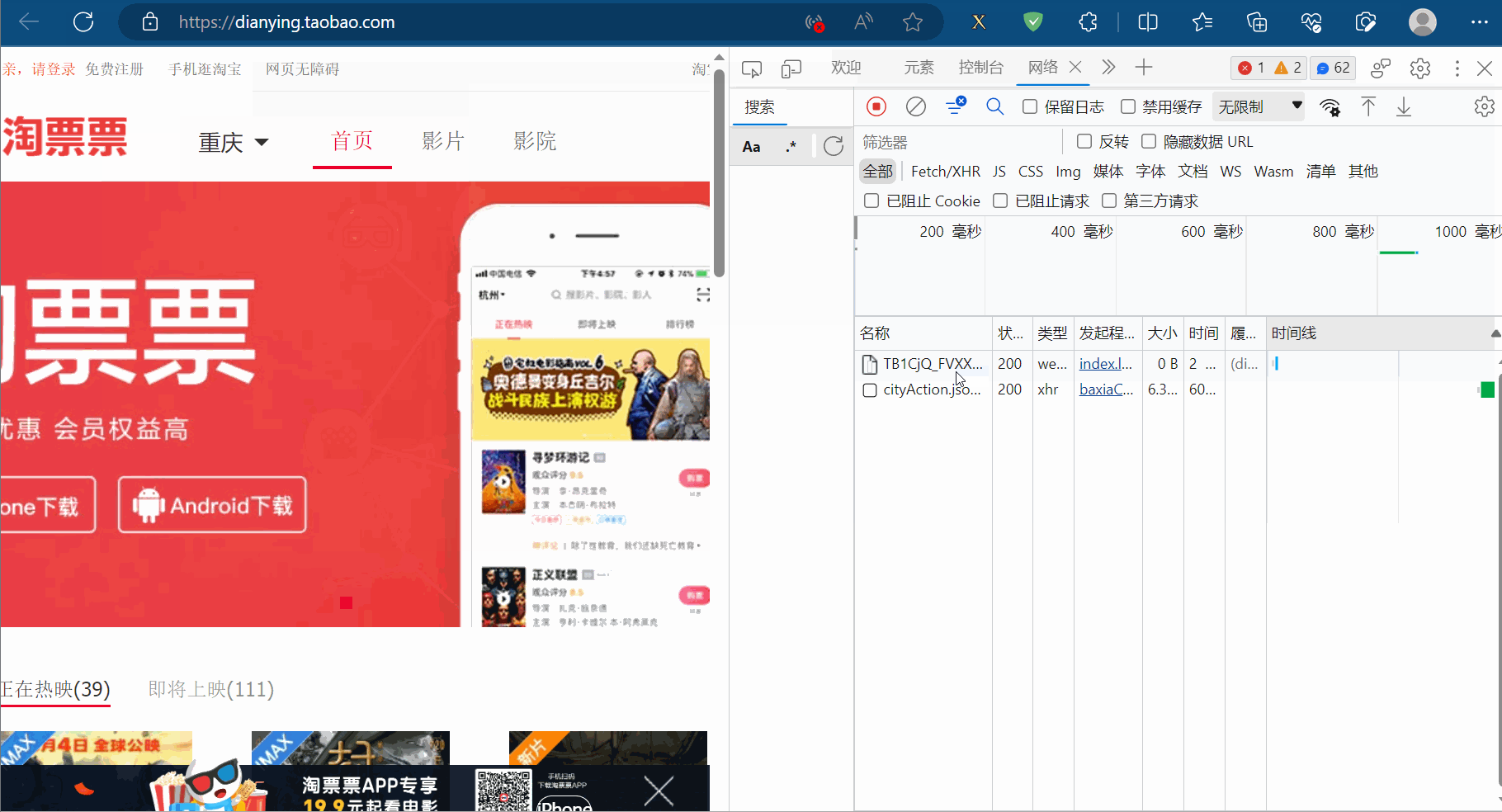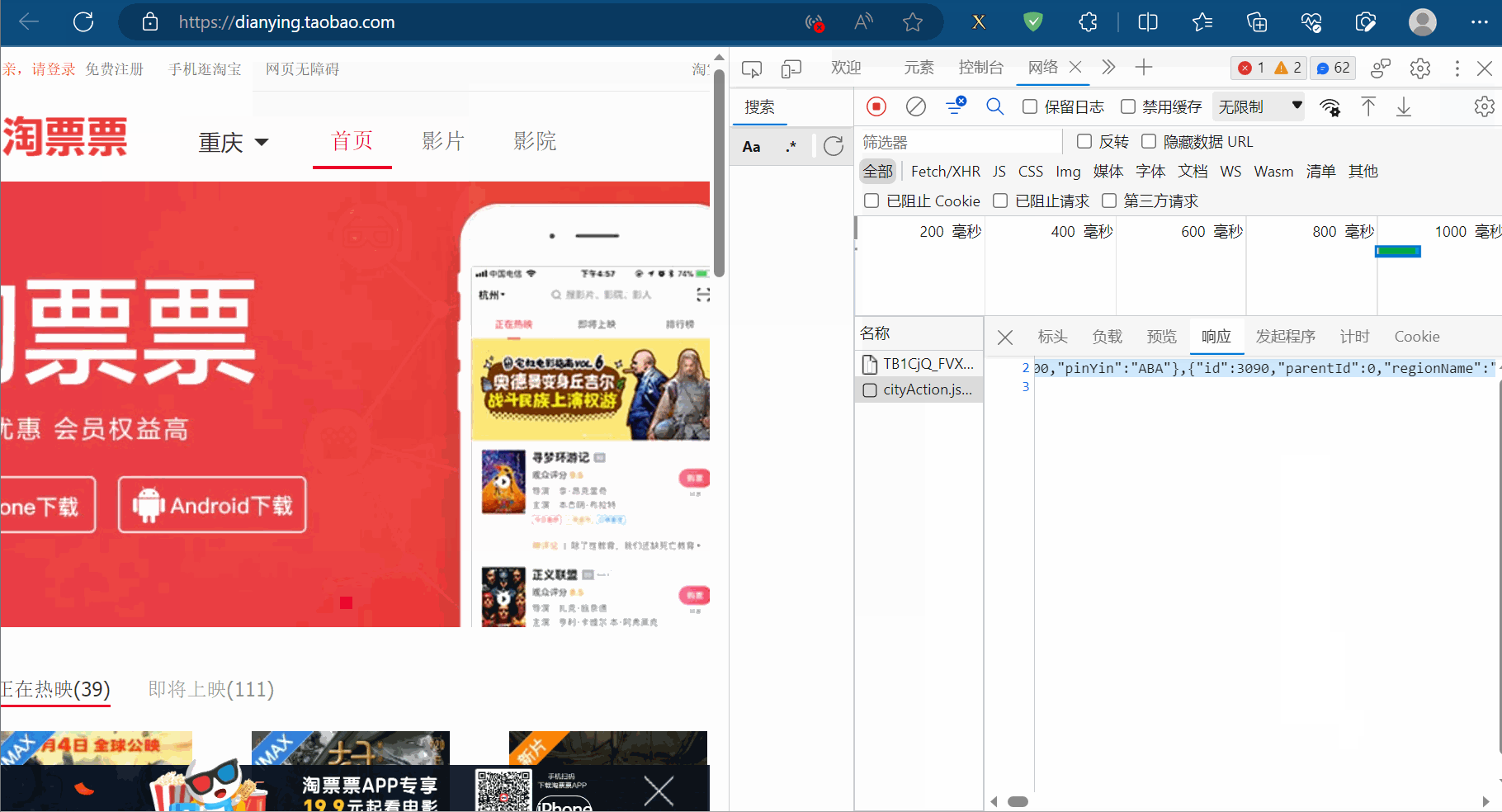
创建文件“074_jsonpath解析淘票票.py”。
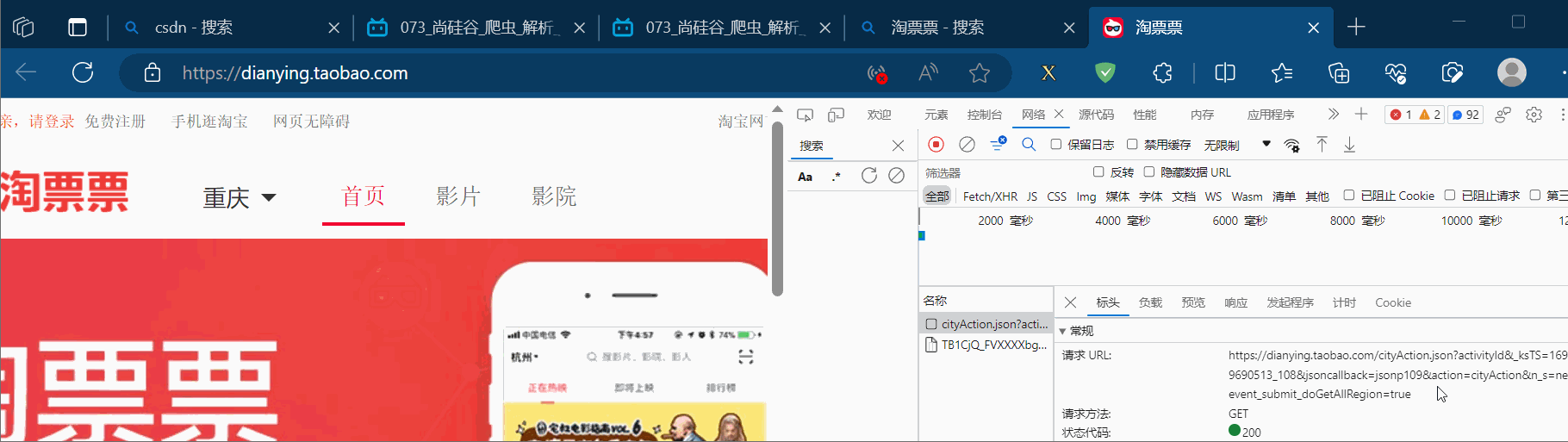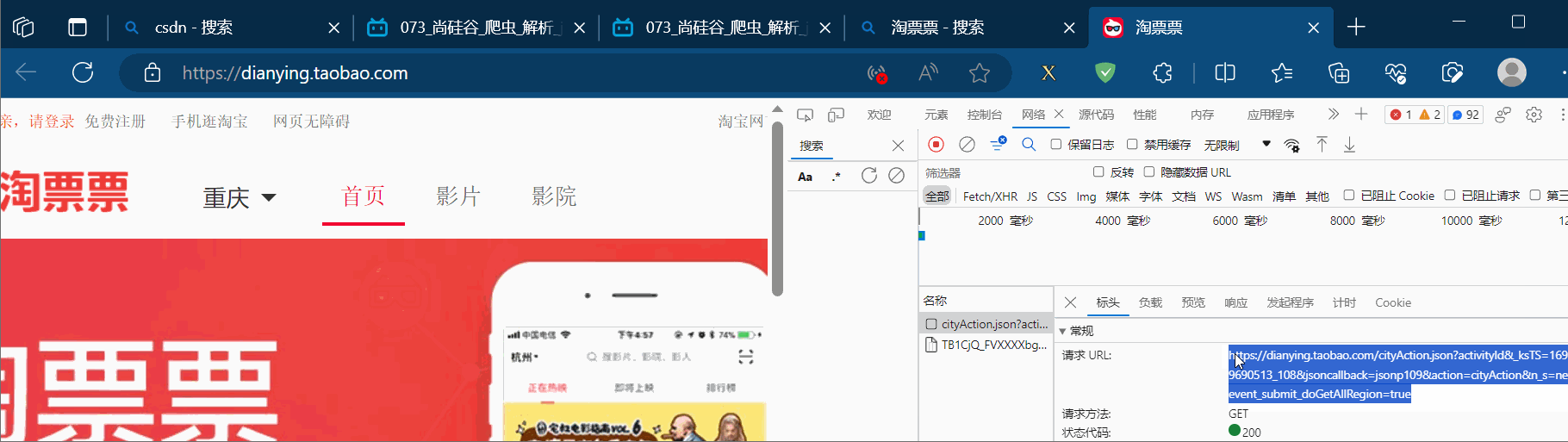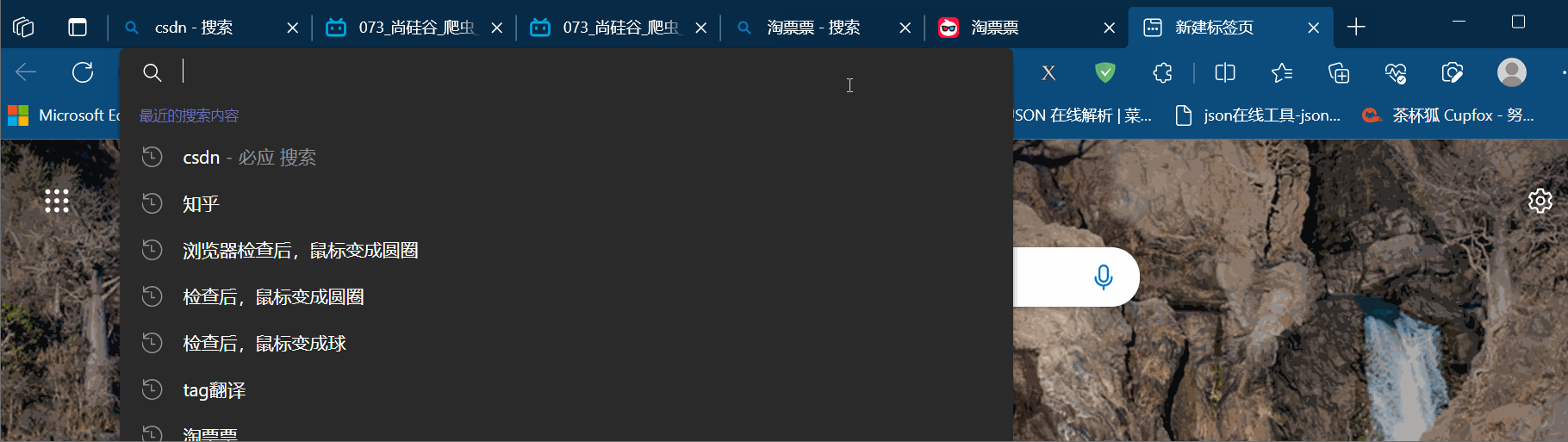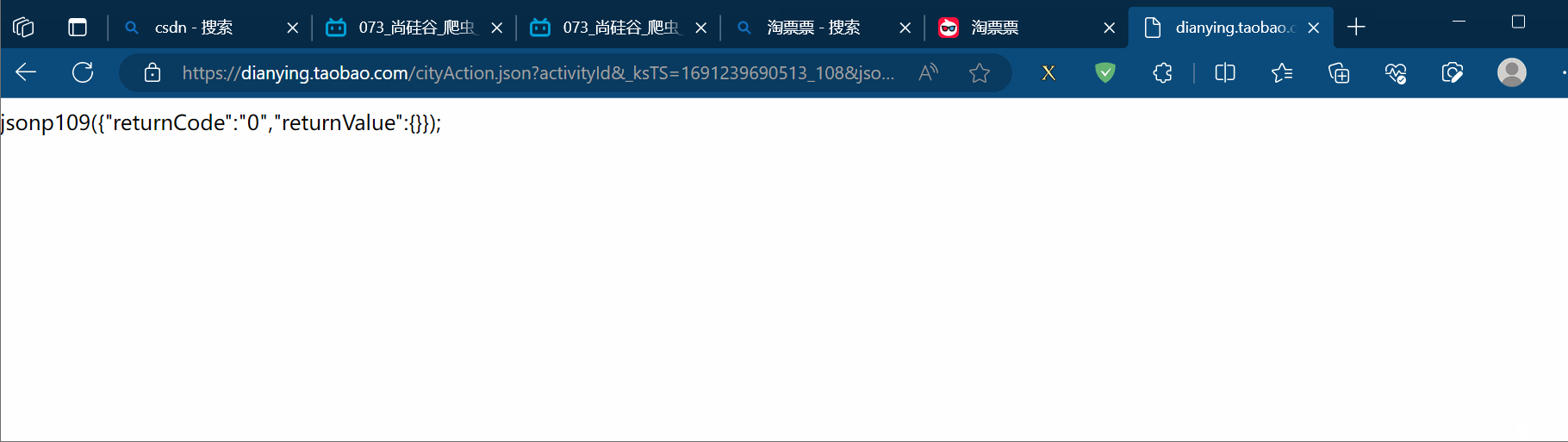
将请求地址复制到PyCharm中,另外将该地址使用浏览器打开,发现没有数据返回,说明有反爬机制。故将请求标头放到PyCharm中,删除开头带“:”的项(这些项没用,还会导致报错),再注释掉“Accept-Encoding”那一项,然后不断尝试,尝试获取源码,发现仅需“Referer”项即可获取到相应的数据。
"""
jsonpath解析淘票票
"""
import urllib.requesturl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1691239690513_108&json-callback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
# 请求头
headers = {'Referer': 'https://dianying.taobao.com/',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
print(content)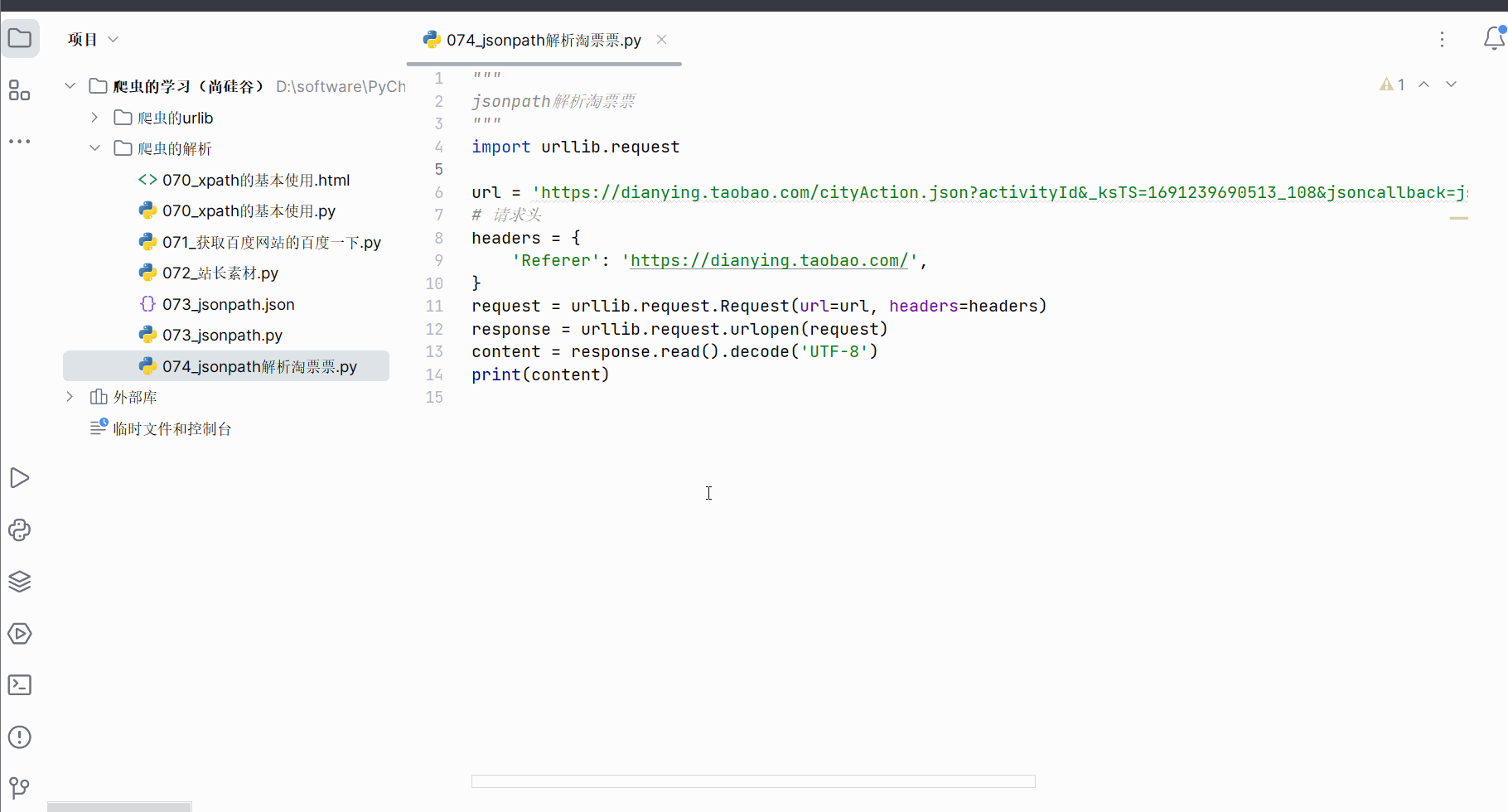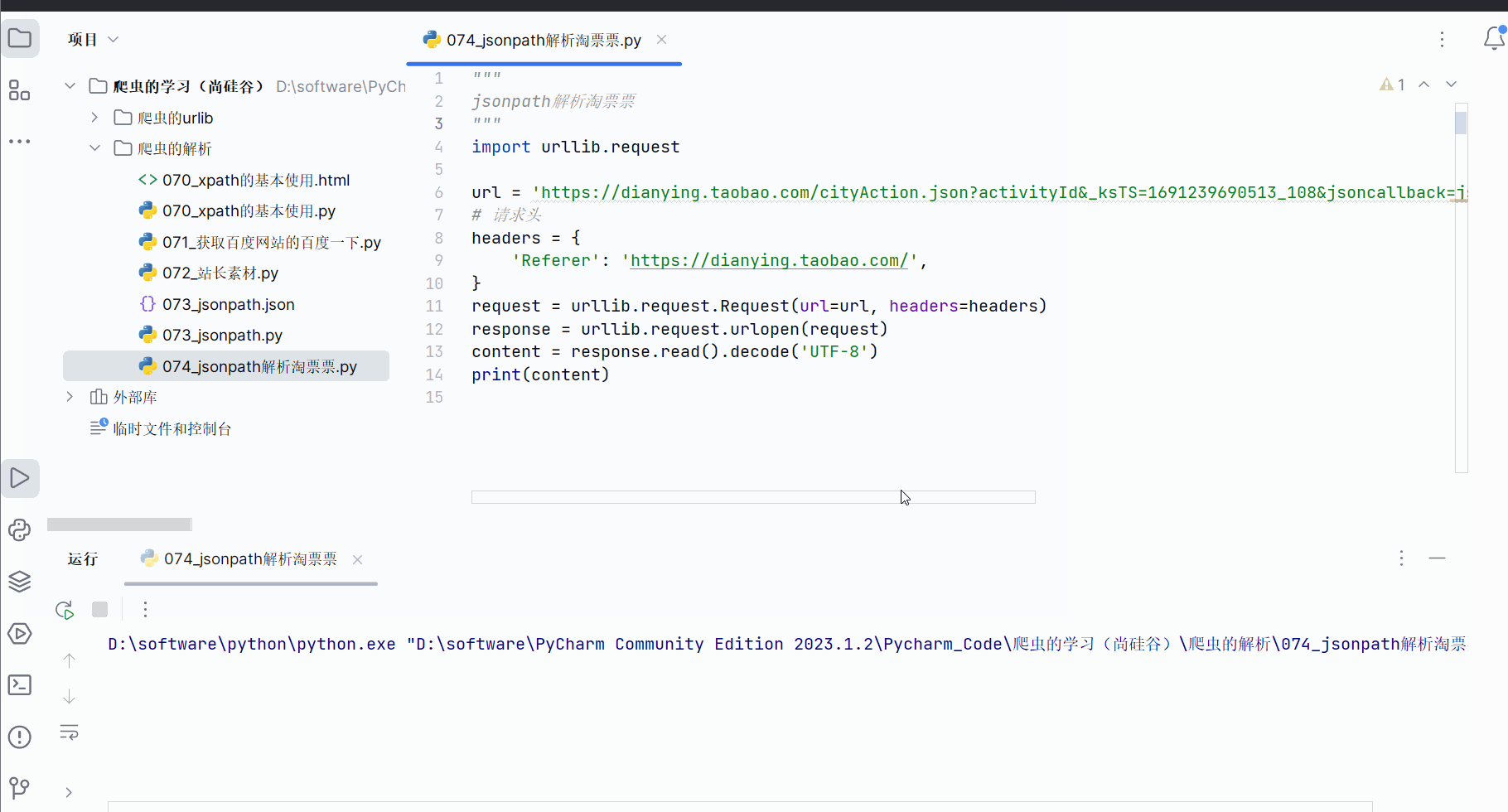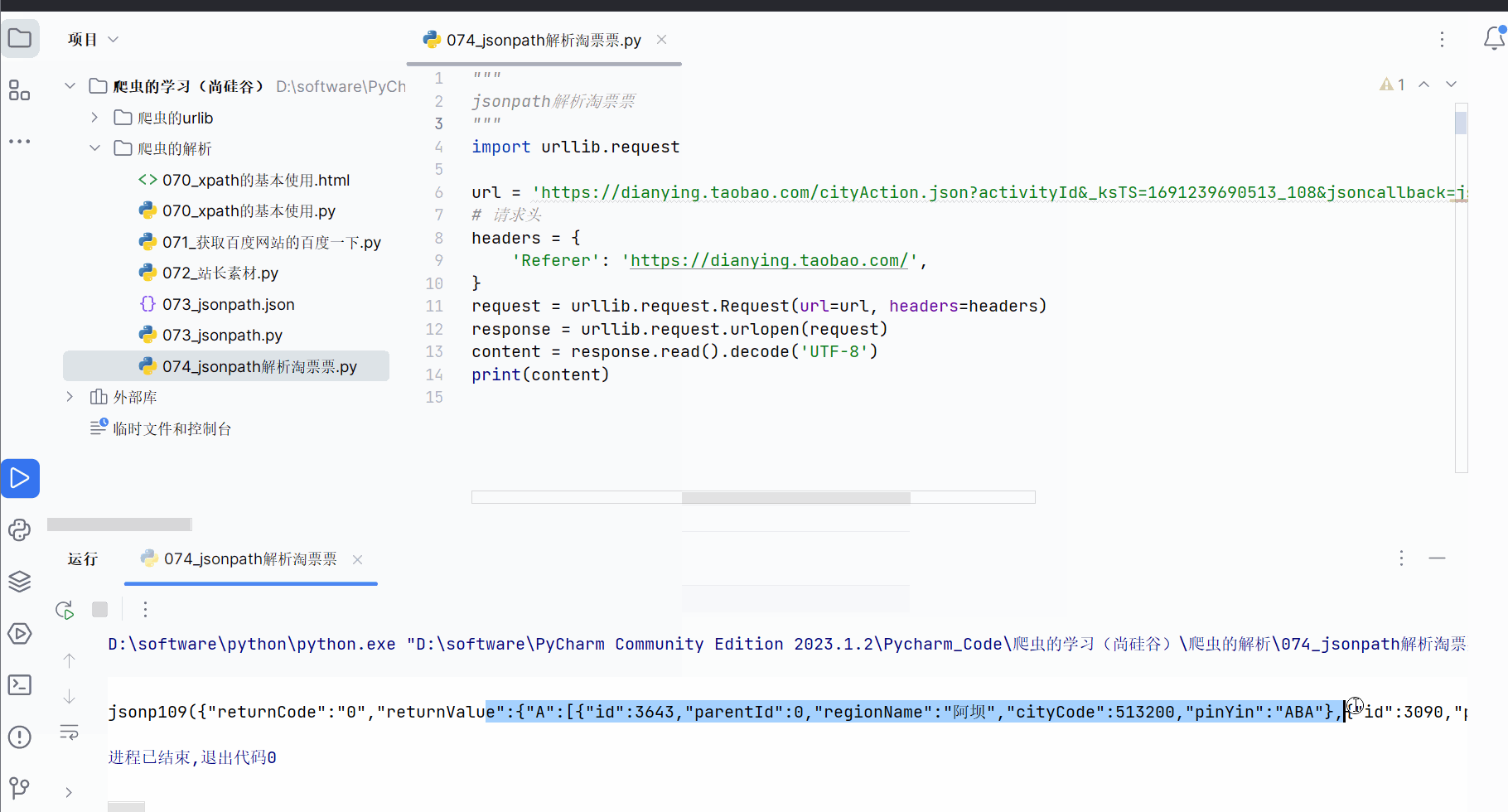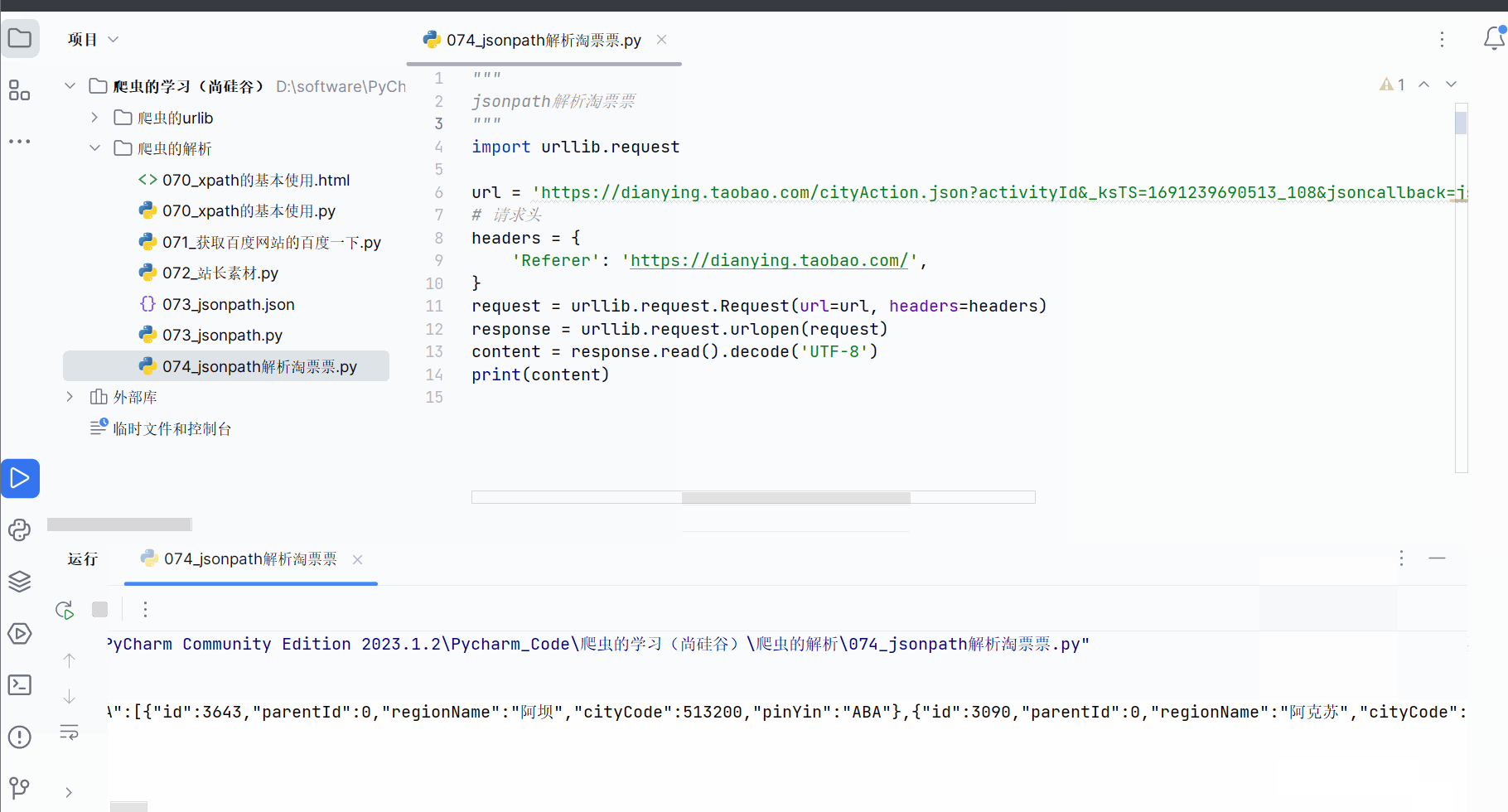
但是获取到的数据并不完全符合json格式,开头多了“jsonp109(”,结尾多了“);”,需要进一步处理才能转变成json数据。
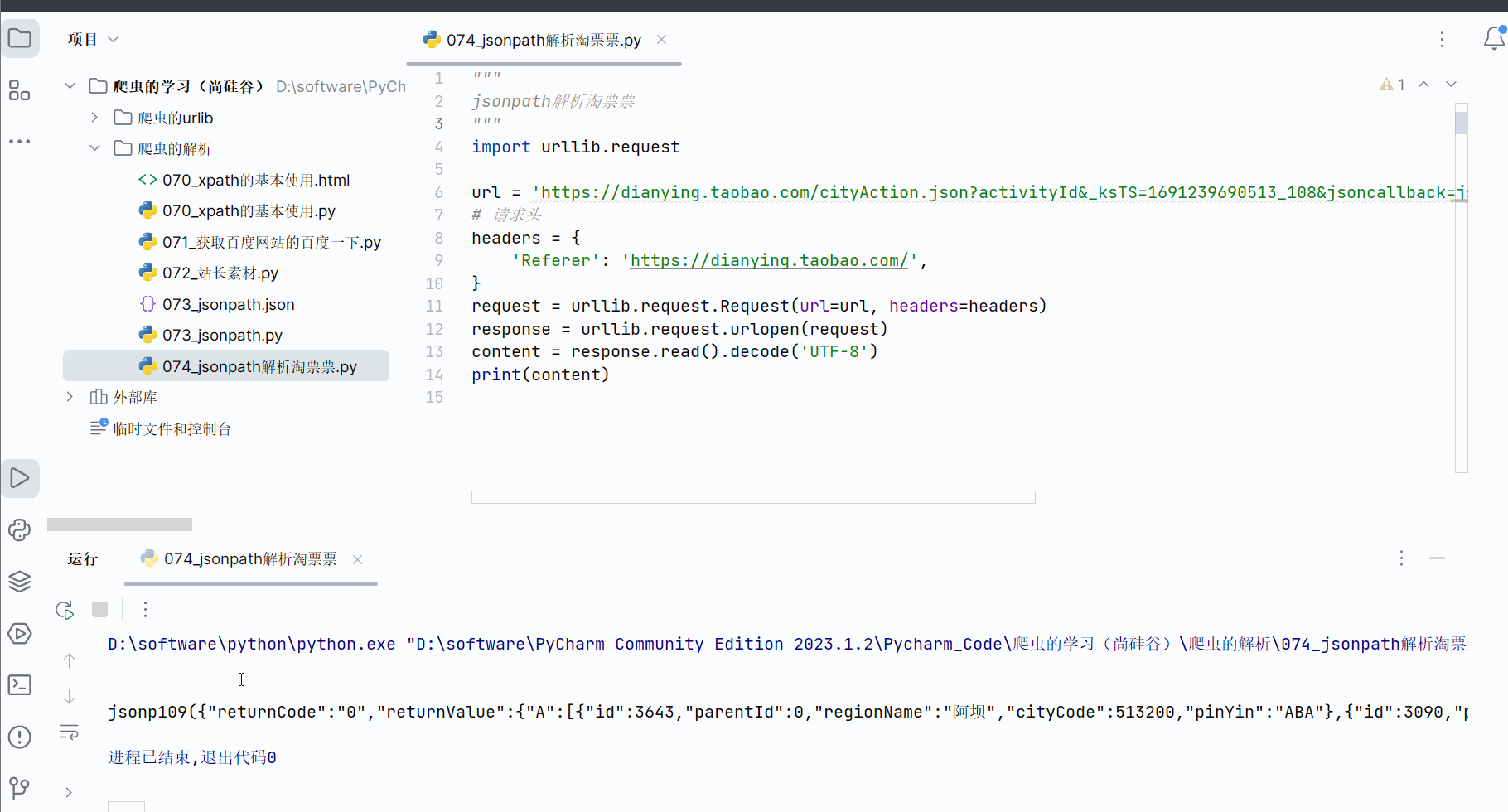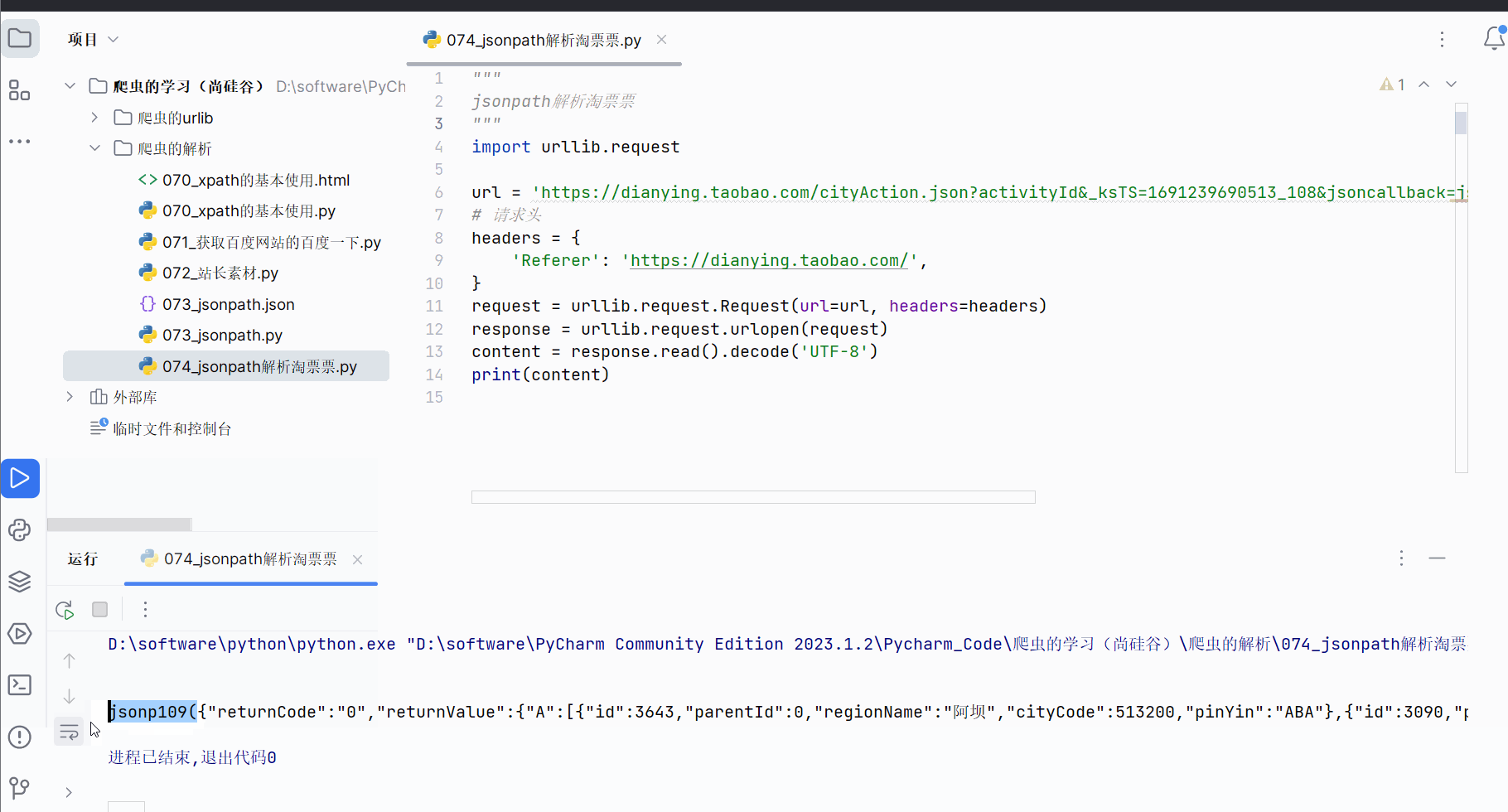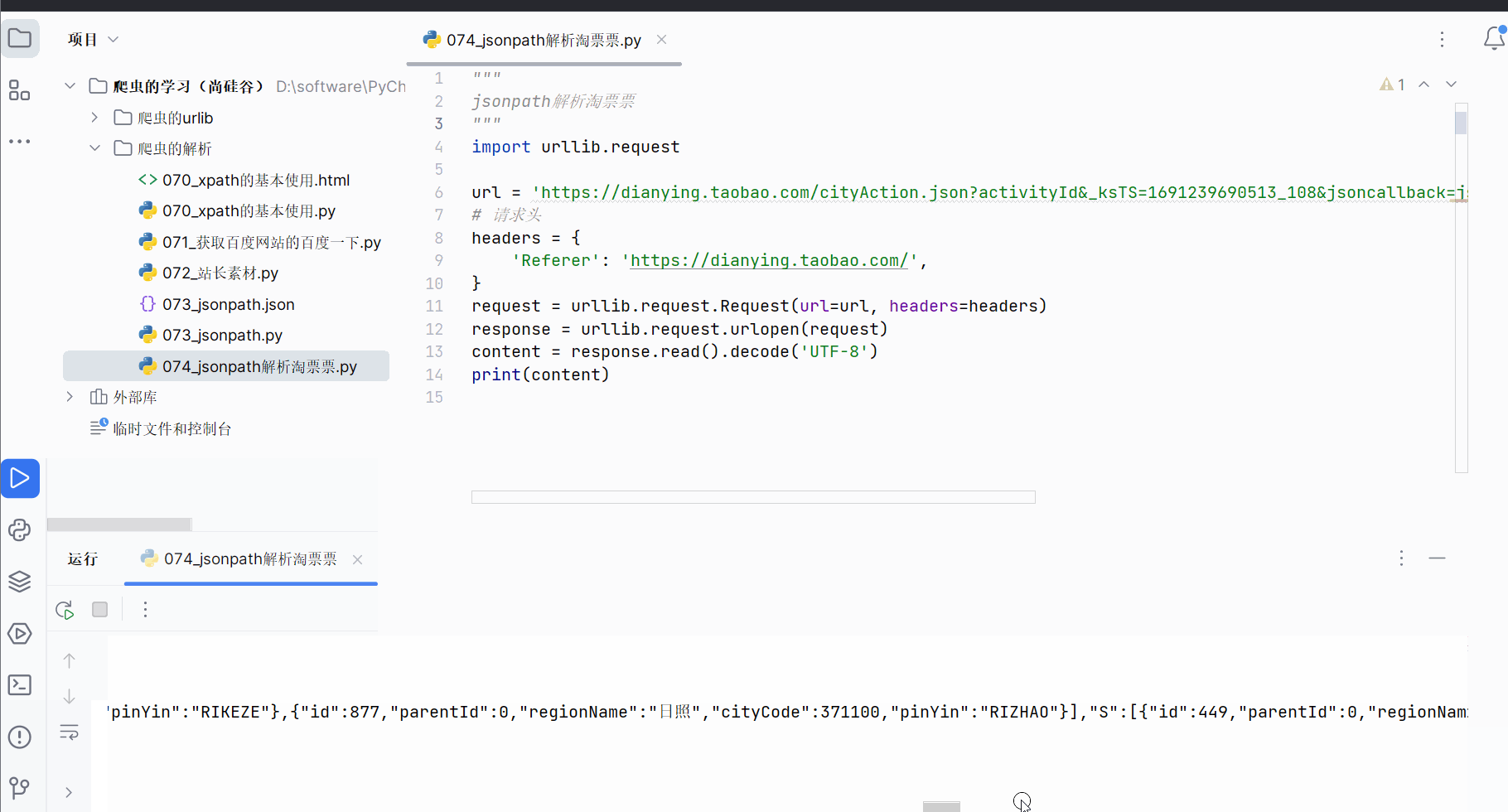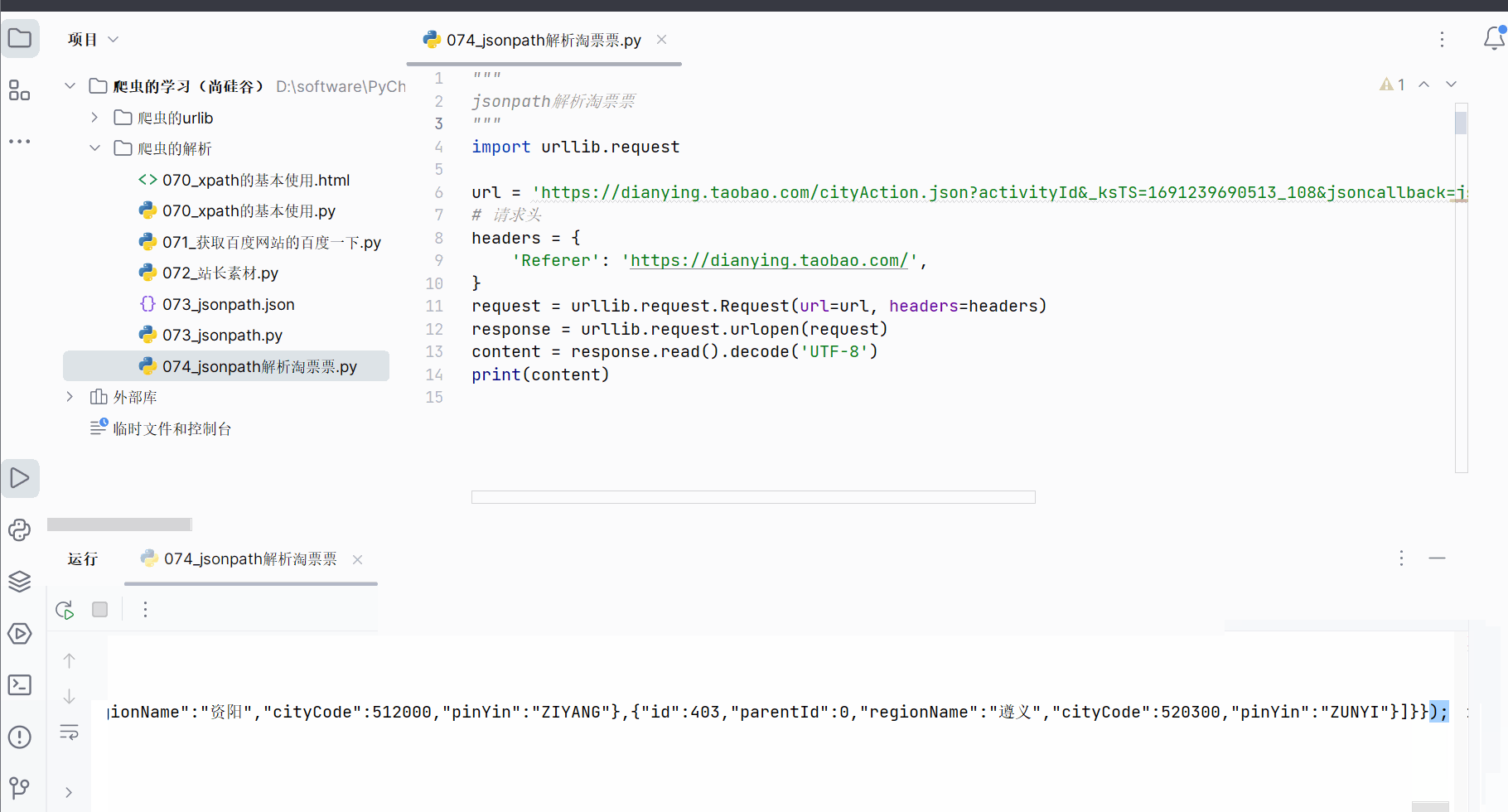
如下编程,获取到json数据并保存到文件中,然后点开产生的json文件,使用快捷键Ctr+Alt+L重新设置json数据的缩进,便能直观看到json数据。
"""
jsonpath解析淘票票
"""
import urllib.requesturl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1691239690513_108&json-callback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
# 请求头
headers = {'Referer': 'https://dianying.taobao.com/',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
# print(content) # 测试代码,判断是否获取到相应的数据
content = content.split('(')[1].split(')')[0] # 变成json数据 删去开头的“jsonp109(”,结尾的“);”
# print(content) # 测试代码,验证是否转为json数据
with open('074_jsonpath解析淘票票.json','w',encoding='UTF-8') as fp:fp.write(content)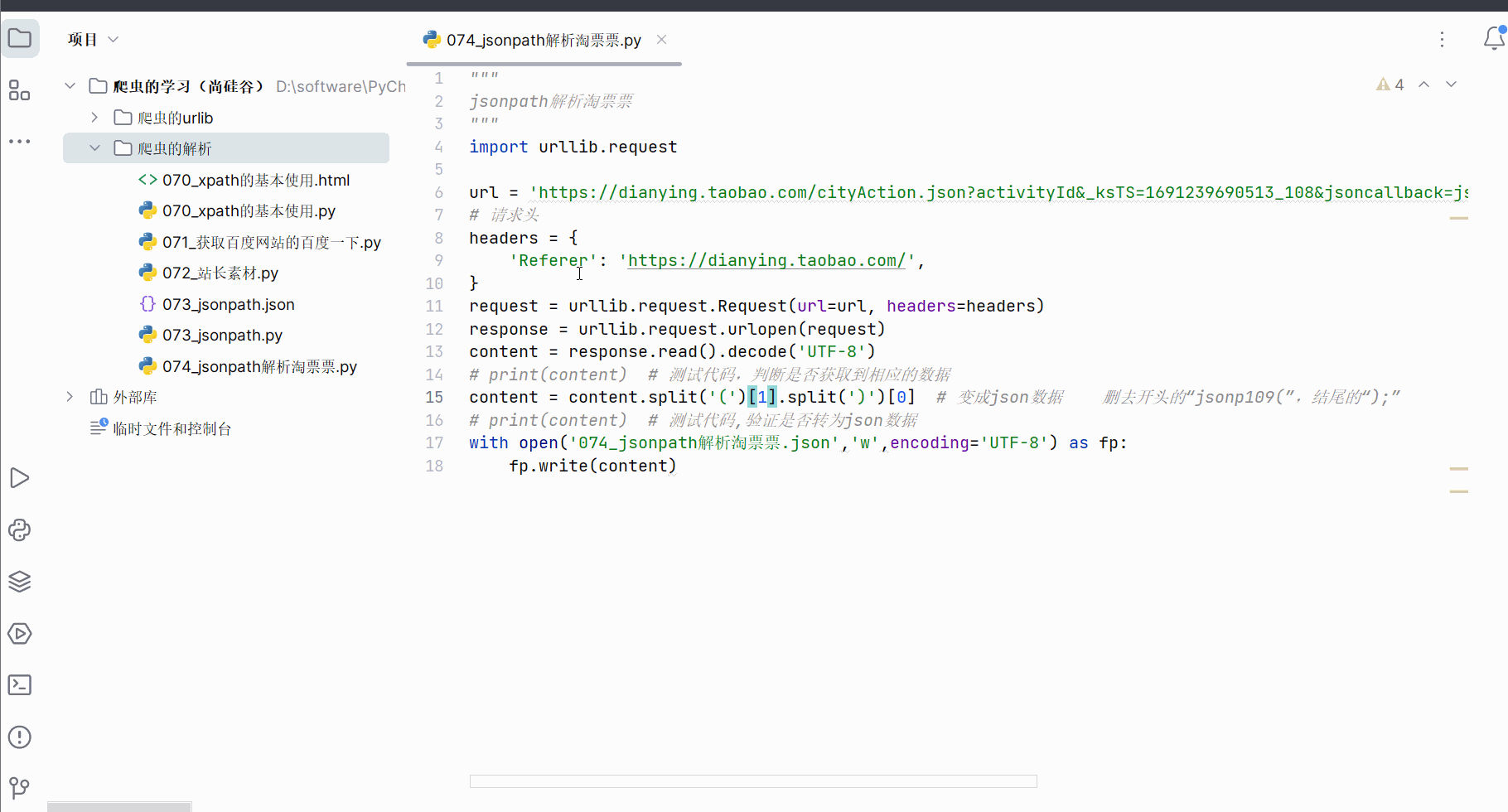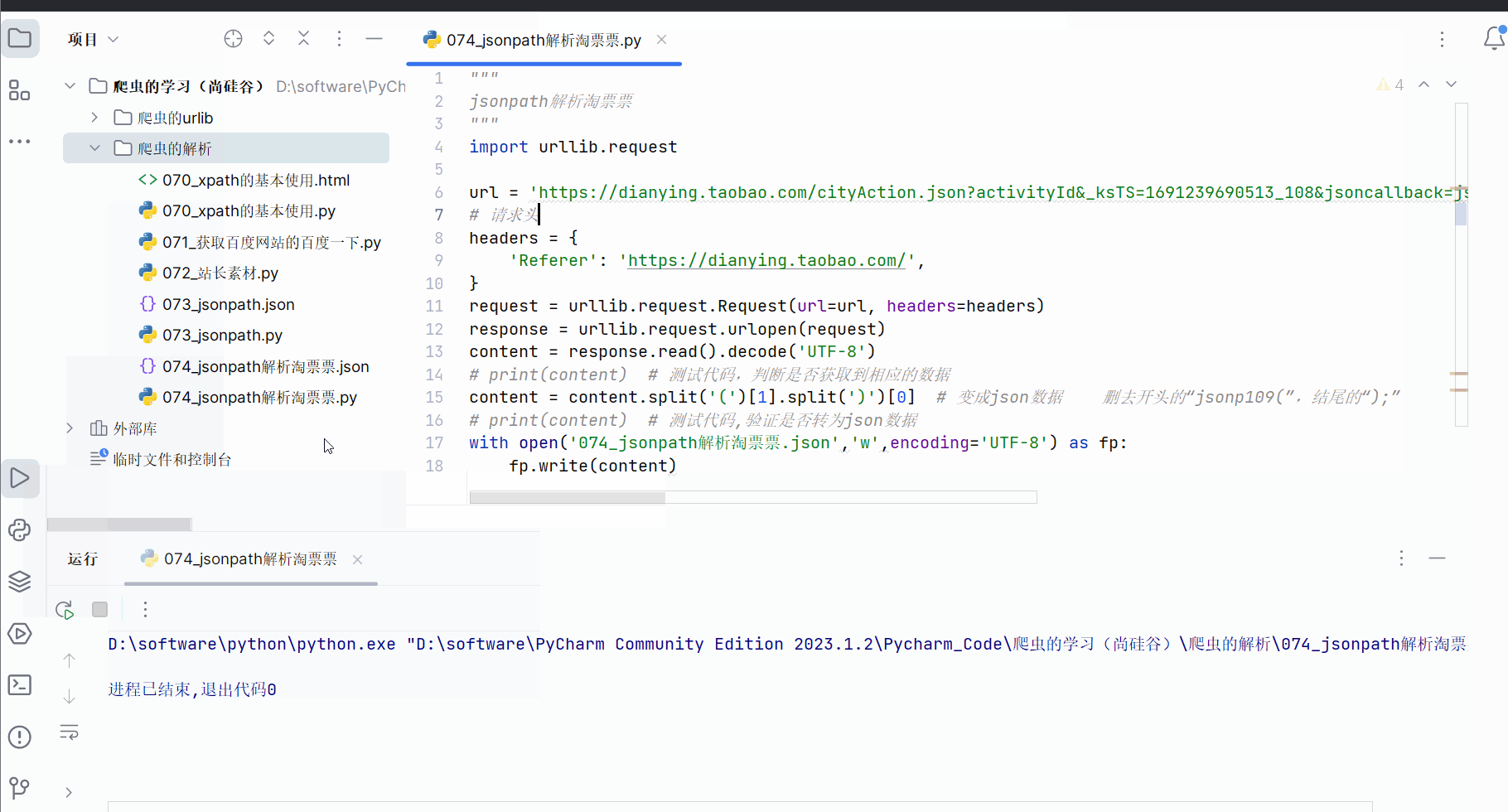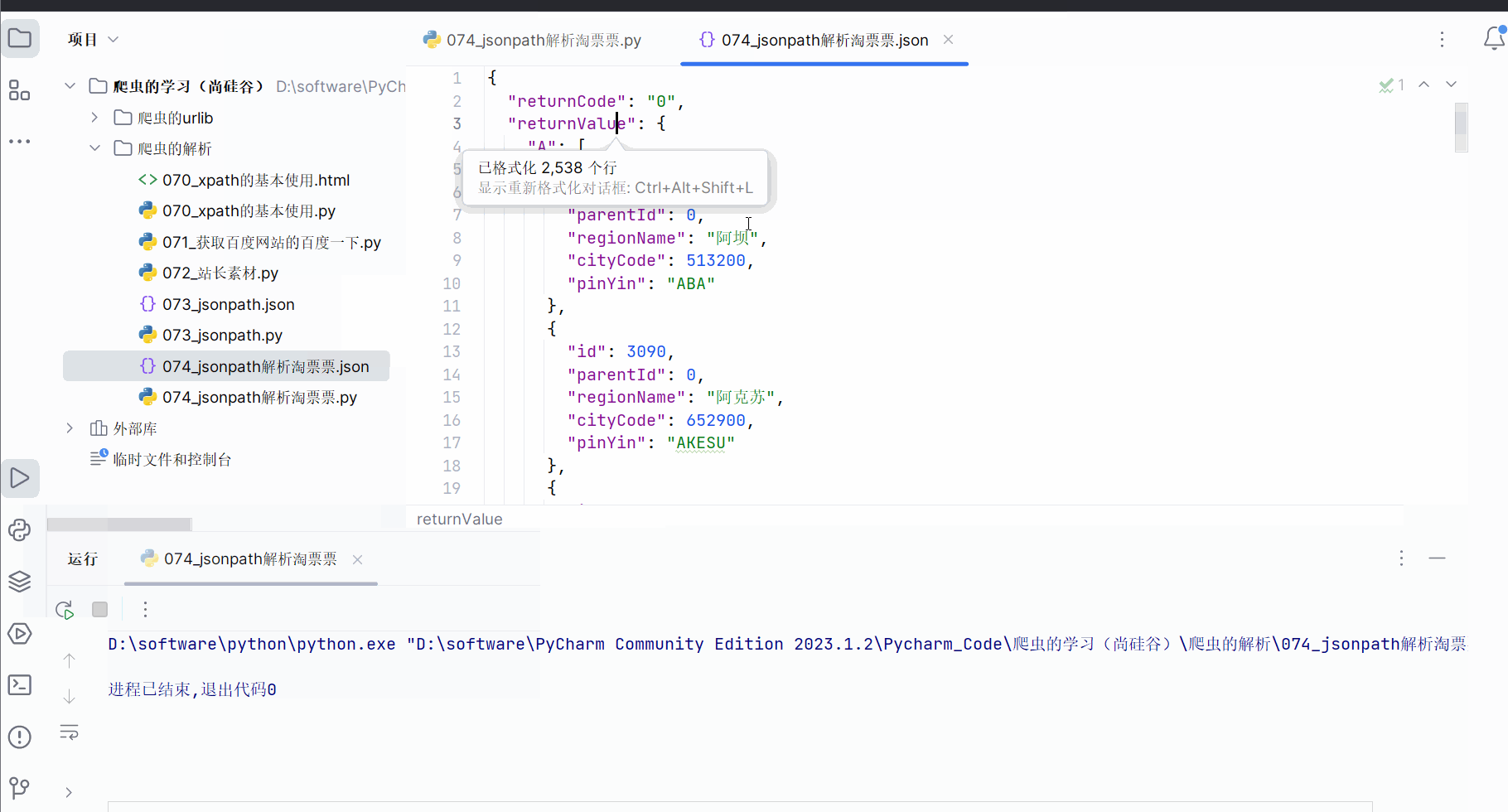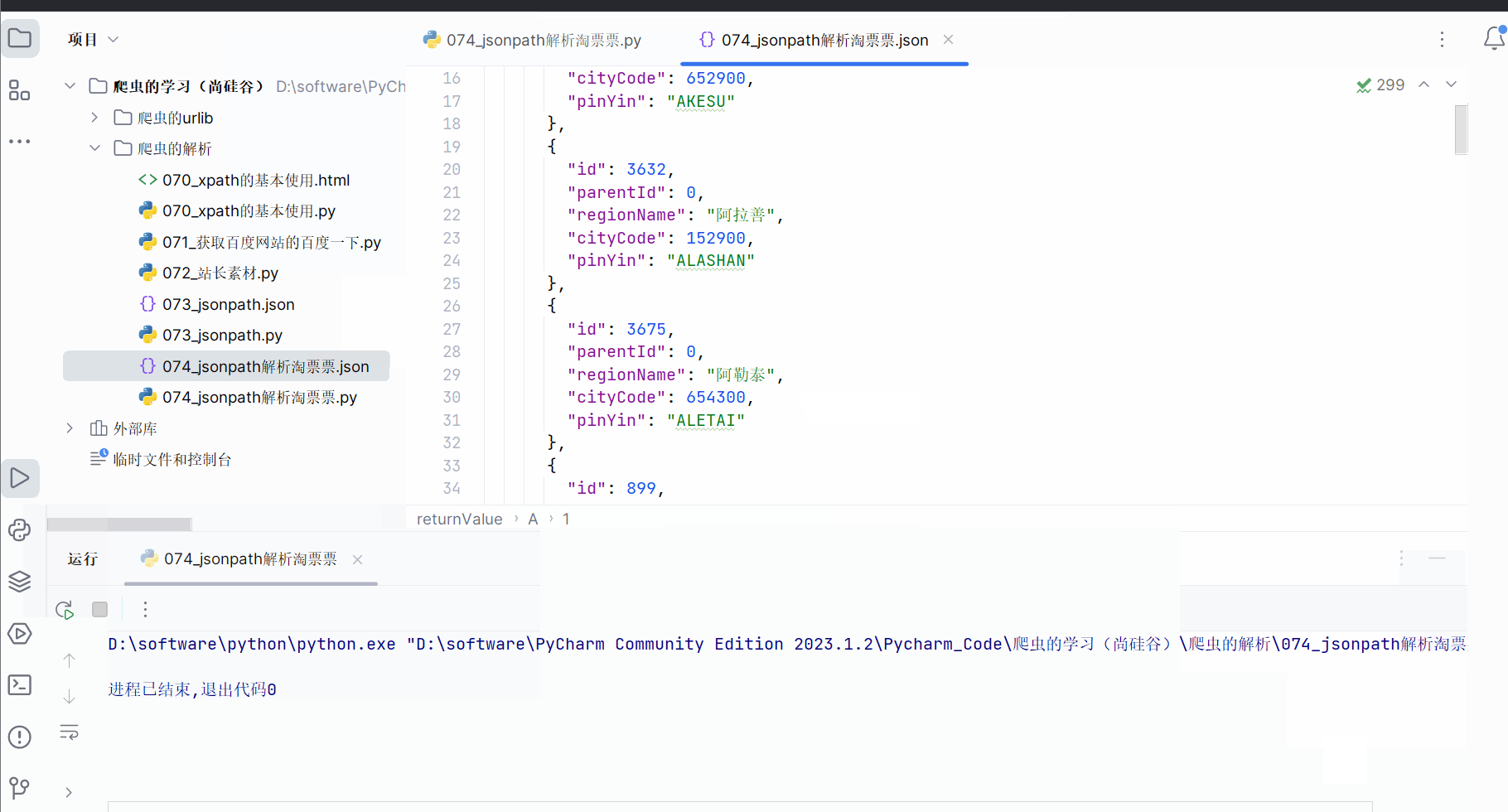
如下编程,即可获得城市。
"""
jsonpath解析淘票票
"""
import urllib.request
import json
import jsonpathurl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1691239690513_108&json-callback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
# 请求头
headers = {'Referer': 'https://dianying.taobao.com/',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
# print(content) # 测试代码,判断是否获取到相应的数据
content = content.split('(')[1].split(')')[0] # 变成json数据 删去开头的“jsonp109(”,结尾的“);”
# print(content) # 测试代码,验证是否转为json数据obj = json.loads(content)
city_list = jsonpath.jsonpath(obj, '$..regionName')
print(city_list)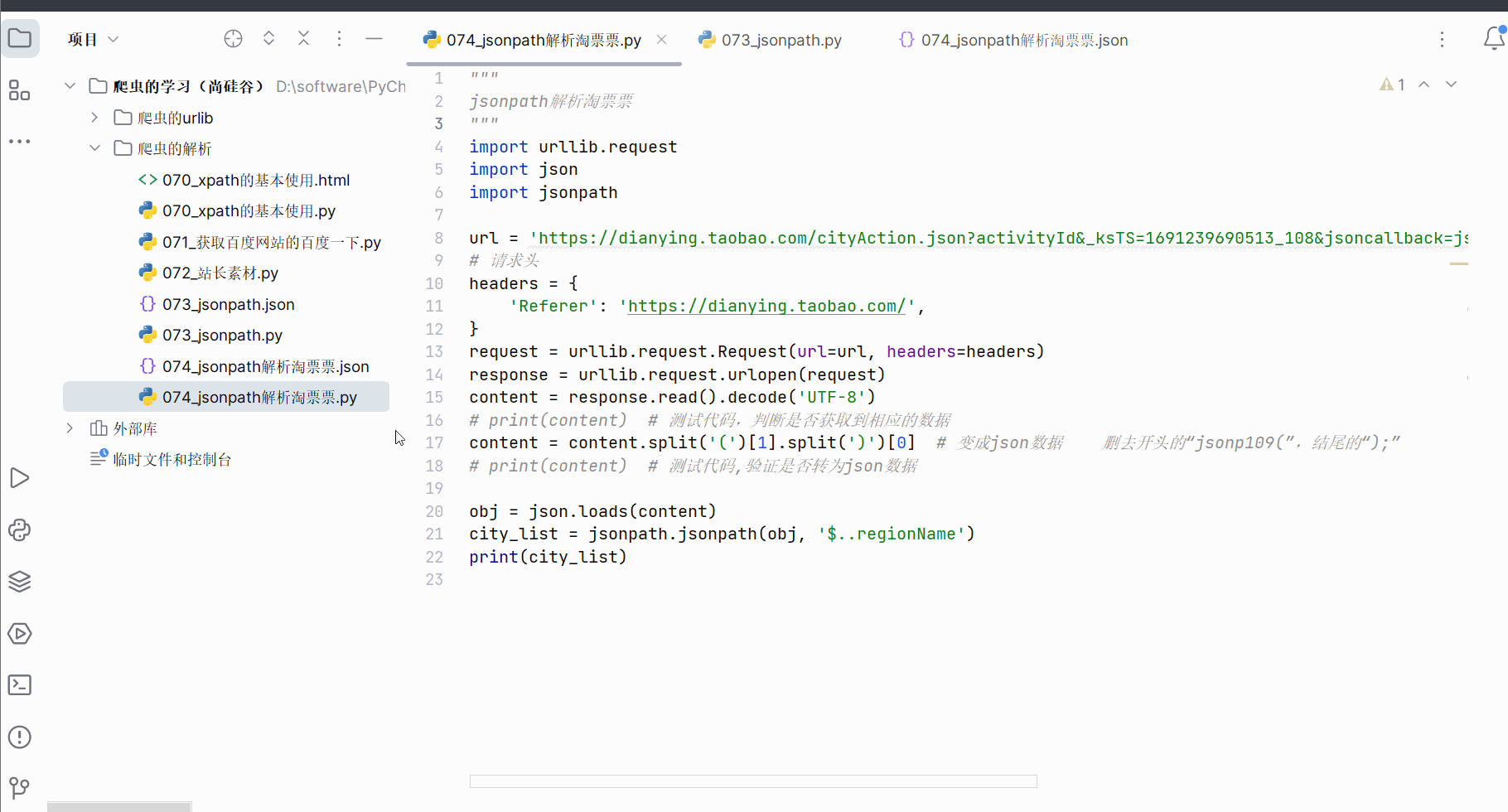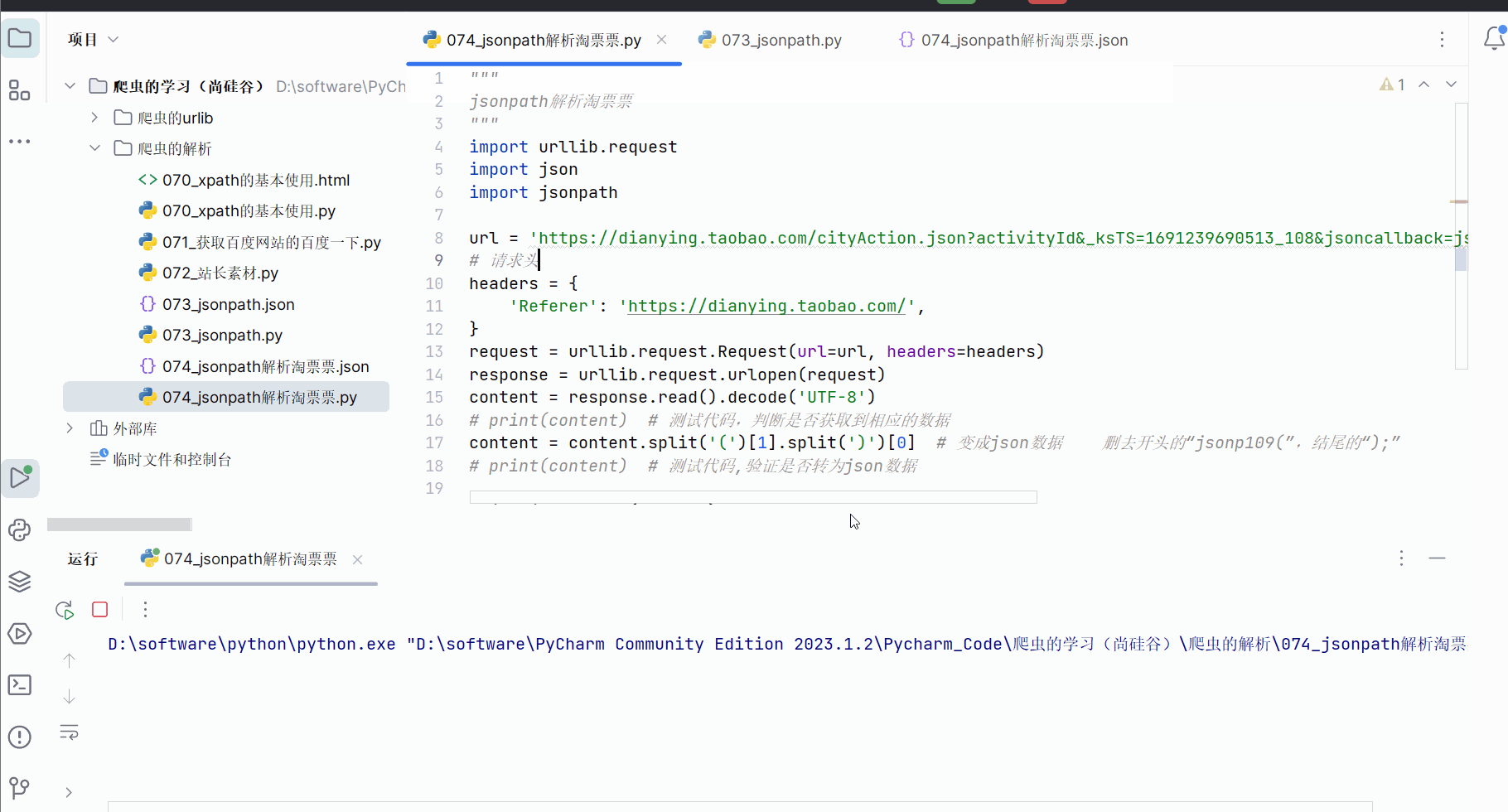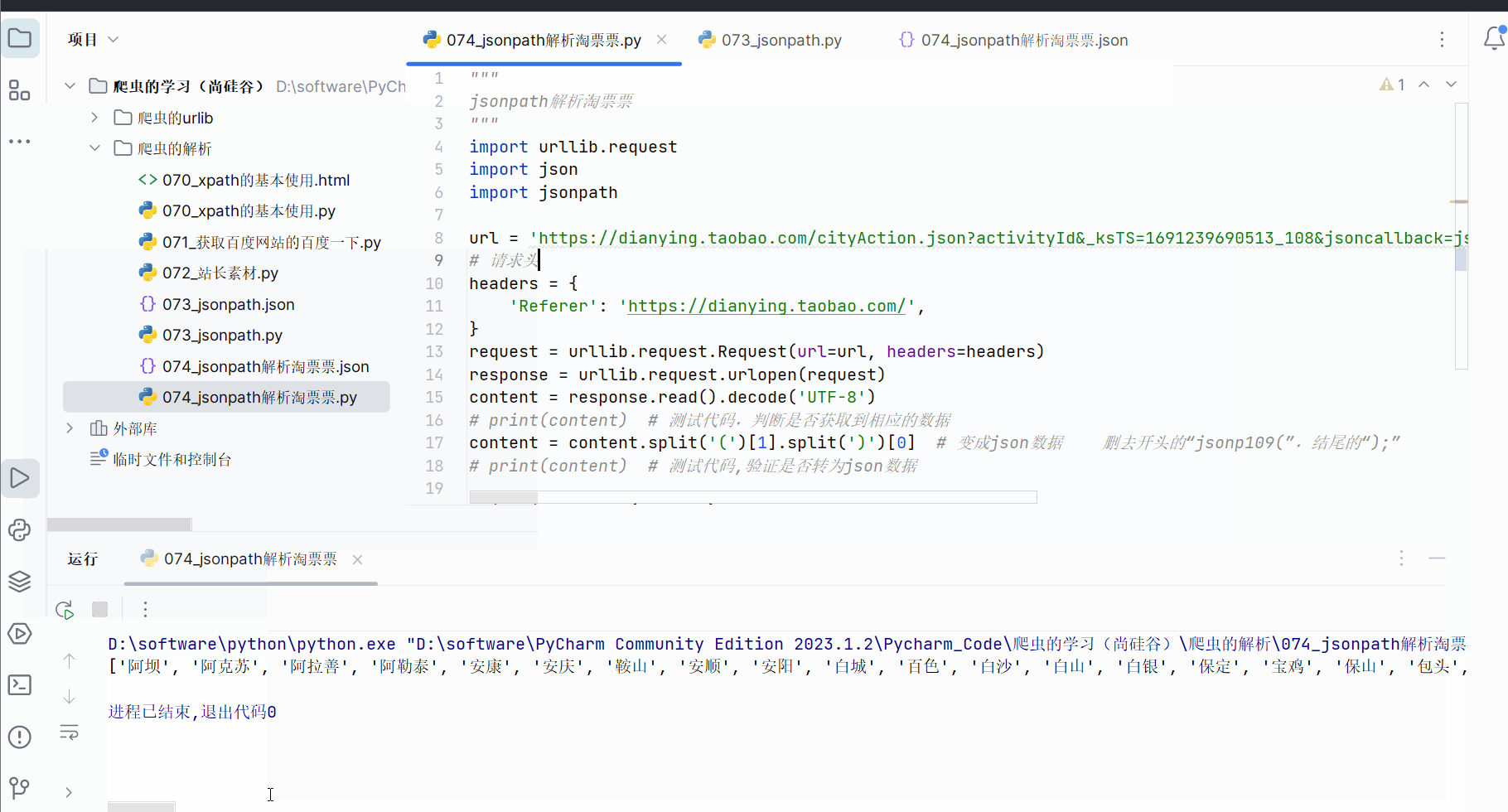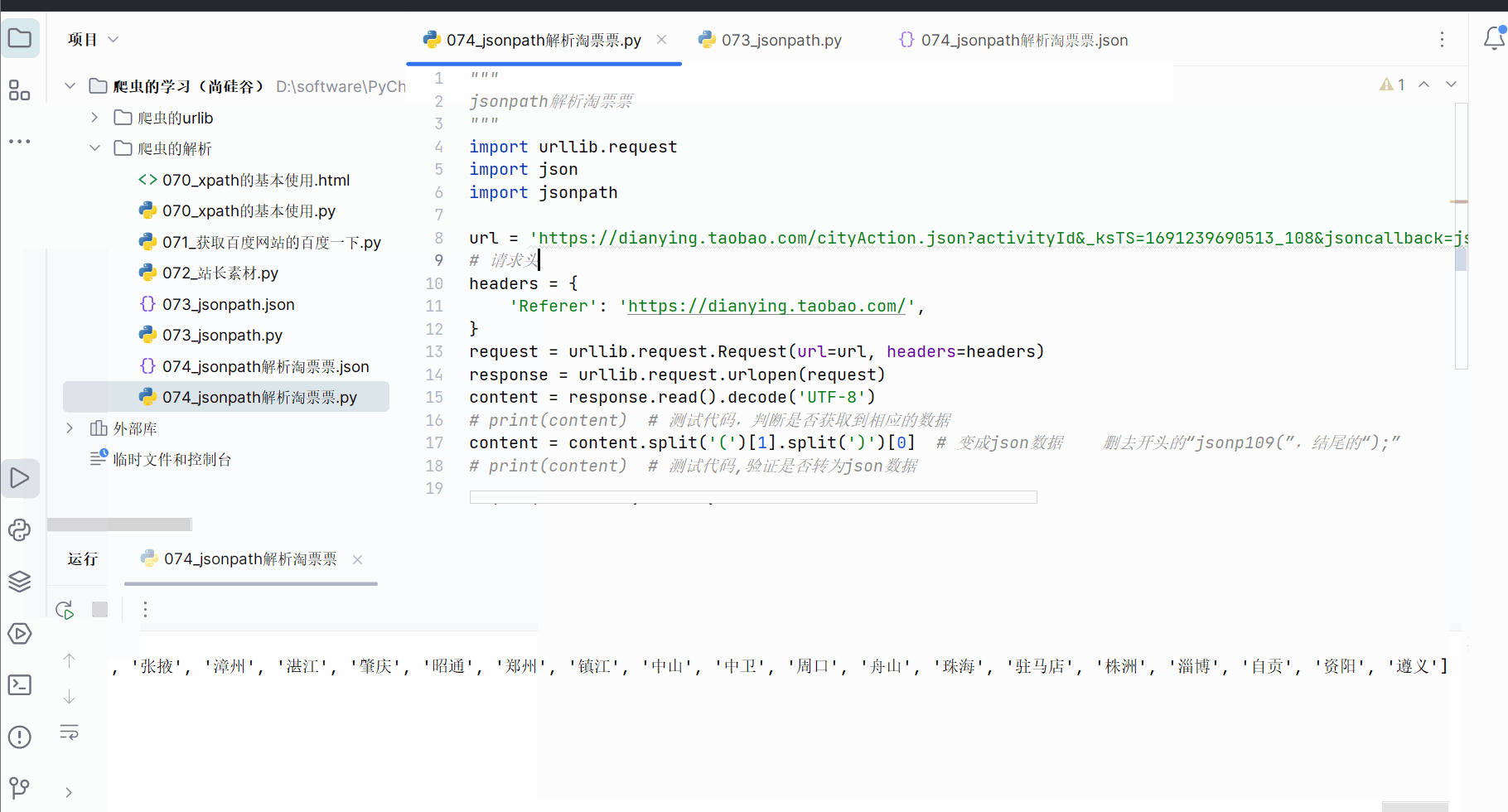
三、BeautifulSoup(即bs4)
1.bs4的基本使用
(1)基本简介(作用与优缺点)

(2)安装以及创建

具体安装步骤如下:首先找到python安装路径里的文件夹Scripts,里面专门用于存放python包。然后打开命令提示符,将命令行控制到文件夹Scripts中,并输入命令“pip install bs4 -i https://pypi.mirrors.ustc.edu.cn/simple/”。


(3)节点定位


具体如何使用请阅读代码演示。
(4)节点信息

具体如何使用请阅读代码演示。
(5)代码演示(详细语法请看代码,含注释,比如函数find、find_all、select、按属性class寻找标签时需要使用“class_”)
创建文件“075_bs4的基本使用.py”。
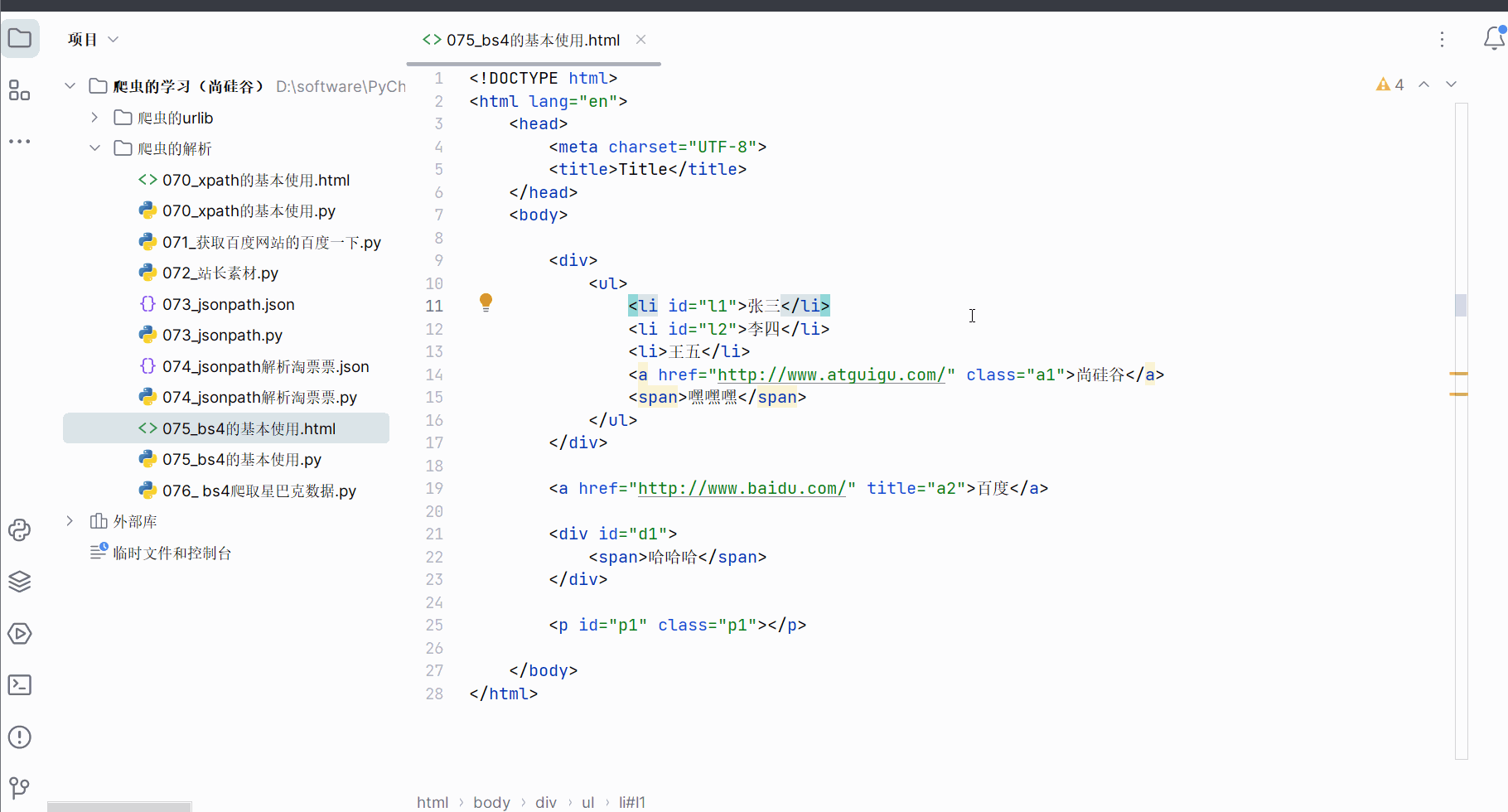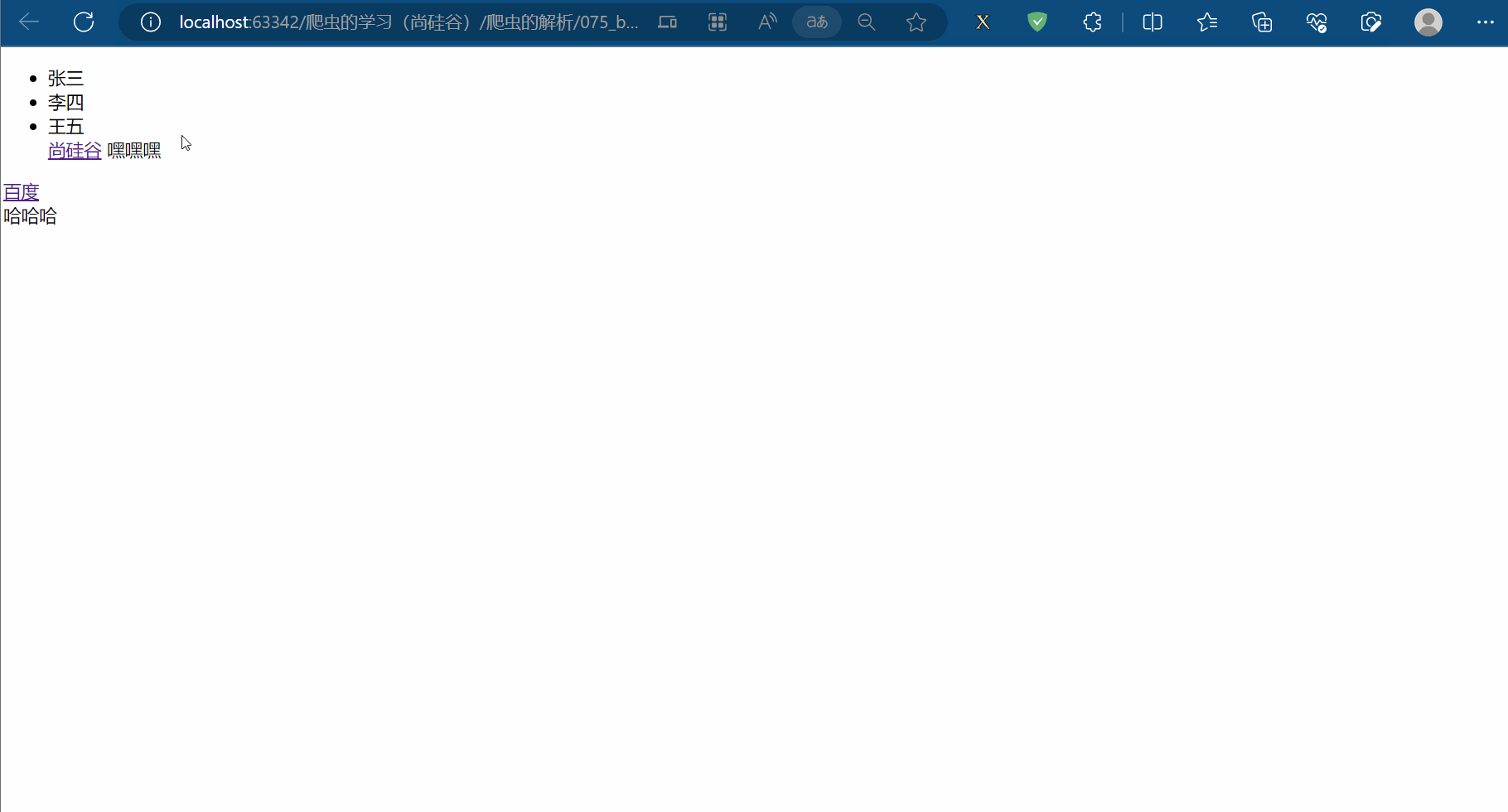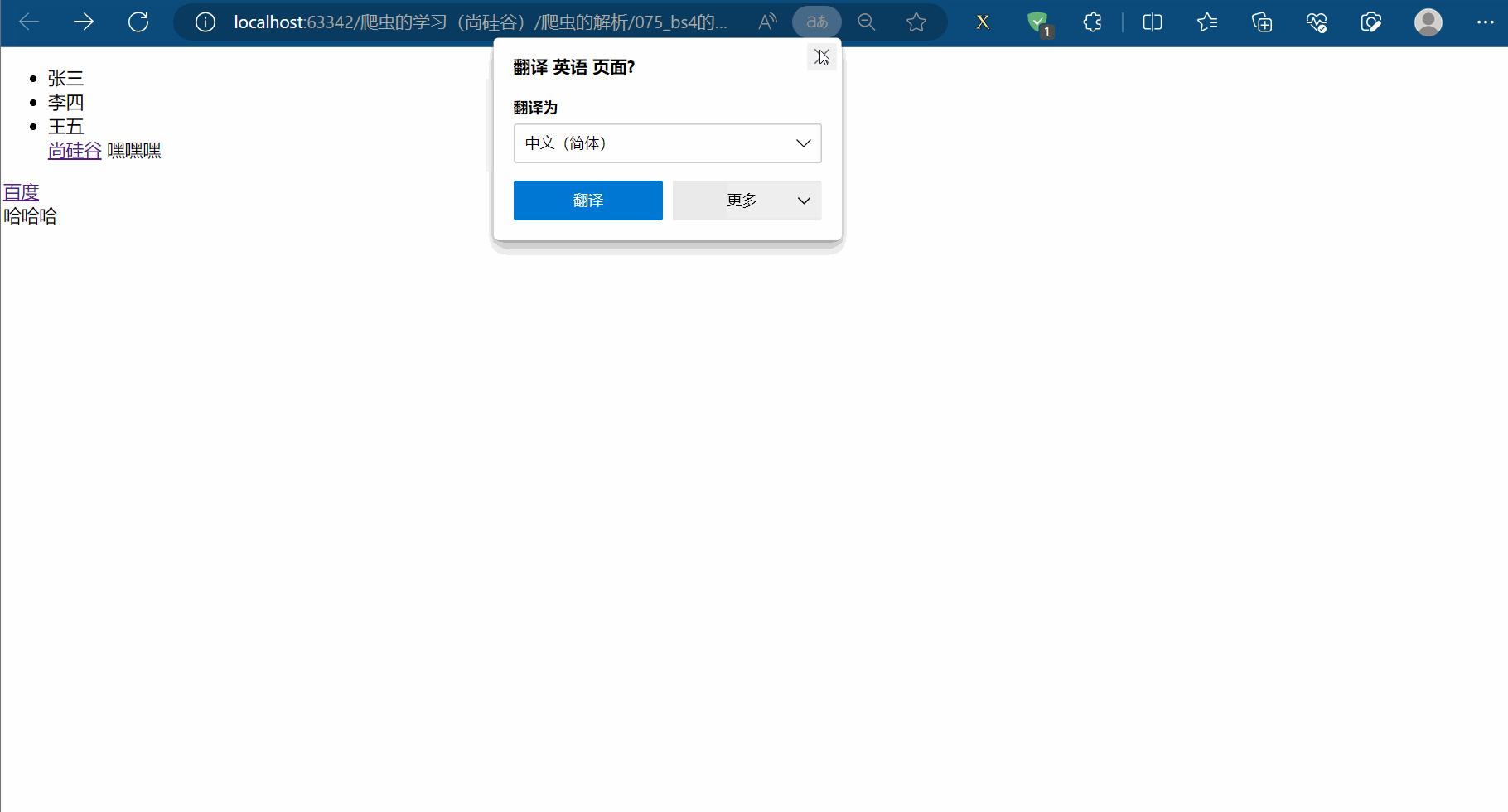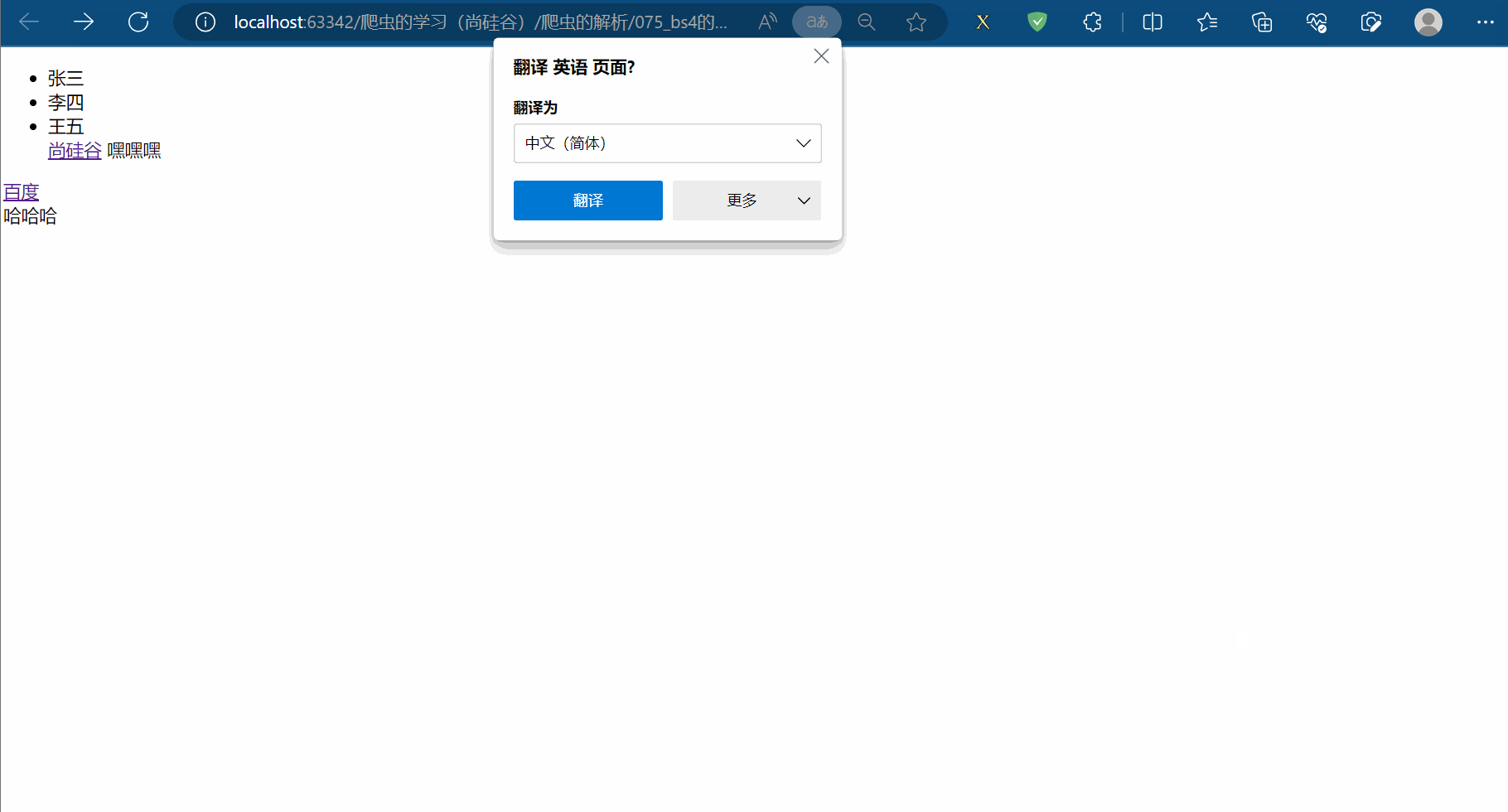
如下图所示,创建文件“075_bs4的基本使用.html”,然后编写html文件的代码并查看效果。
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><title>Title</title></head><body><div><ul><li id="l1">张三</li><li id="l2">李四</li><li>王五</li><a href="http://www.atguigu.com/" class="a1">尚硅谷</a><span>嘿嘿嘿</span></ul></div><a href="http://www.baidu.com/" title="a2">百度</a><div id="d1"><span>哈哈哈</span></div><p id="p1" class="p1"></p></body>
</html>
继续编写代码,熟悉语法并运行,查看结果。
"""bs4的基本使用
-本次将通过解析本地文件将bs4的基础语法进行讲解
"""
from bs4 import BeautifulSoup# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup = BeautifulSoup(open('075_bs4的基本使用.html', encoding='UTF-8'), 'lxml')
# print(soup) # 测试代码,判断能否读取本地的html文件# 根据标签名查找节点
# 找到的是第一个符合条件的数据 soup.a --> 在soup中找到第一个a标签
print(f"soup.a的内容:{soup.a}")# .attrs 将属性作为字典返回
print(f"soup.a.attrs的内容:{soup.a.attrs}")# bs4的一些函数 find、find_all、select
# (1)find 返回第一个符合条件的标签
print(f"soup.find('a')的内容:{soup.find('a')}")
print(f"soup.find('a',title='a2')的内容:{soup.find('a', title='a2')}")# 根据class的值来找到对应的标签对象 class需要添加下划线
print(f"soup.find('a',class_='a1')的内容:{soup.find('a', class_='a1')}")# (2)find_all 返回的是一个列表
# 返回所有的a标签
print(f"soup.find_all('a')的内容:{soup.find_all('a')}")# 加果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
print(f"soup.find_all(['a','span'])的内容:{soup.find_all(['a', 'span'])}")# 返回所有的li标签
print(f"soup.find_all('li')的内容:{soup.find_all('li')}")# 获取前两个li limit的作用: 查找前几个数据
print(f"soup.find_all('li',limit=2){soup.find_all('li', limit=2)}")# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
print(f"soup.select('a')的内容:{soup.select('a')}")# 根据类选择器class进行筛选 通过.代表class,称为类选择器
print(f"soup.select('.a1')的内容:{soup.select('.a1')}") # 找到class为“a1”的标签# #代表id
print(f"soup.select('#l1')的内容:{soup.select('#l1')}") # 找到id为“l1”的标签# 属性选择器 [attribute] ----- 通过属性来寻找对应的标签
# 查找到li标签中有id的标签
print(f"soup.select('li[id]')的内容:{soup.select('li[id]')}")# 查找到li标签中id为l2的标签
print(f'soup.select(\'li[id]\')的内容:{soup.select("li[id=l2]")}')# 层级选择器 后代(即子孙)、子代(即儿子)、子代 后代用空格表示;子代用“>”表示;
# 找到div下的li 后代选择器(即子孙)
print(f"soup.select('div li')的内容:{soup.select('div li')}")# 找到div下的li 子代选择器(即儿子)
# 注意:很多的计算机编程语言中,如果不加空格不会输出内容 但是在bs4中不会报错,也会显示内容
print(f"soup.select('div > ul > li')的内容:{soup.select('div > ul > li')}")# 找到a标签和li标签的所有对象
print(f"soup.select('a,li')的内容:{soup.select('a,li')}")# 节点信息
# (1)获取节点内容
obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
print(f"obj.string的内容:{obj.string}")
print(f"obj.get_text()的内容:{obj.get_text()}")# (2)节点的属性
obj = soup.select('#p1')[0]
# name用于获取标签的名字
print(f"obj.name的内容:{obj.name}") # obj对应标签的名字# .attrs 将属性作为字典返回
print(f"obj.attrs的内容:{obj.attrs}")# (3)获取节点的具体某个属性
obj = soup.select('#p1')[0] # select返回的是列表,需使用切片 “[0]” 获取到列表里的内容
print(f"obj.attrs.get('class')的内容:{obj.attrs.get('class')}") # 推荐
print(f"obj.get('class')的内容:{obj.get('class')}") # 不推荐
print(f"obj['class']的内容:{obj['class']}") # 不推荐
print(f"obj.attrs['class']的内容:{obj.attrs['class']}") # 使用切片
2.bs4爬取星巴克数据
打开星巴克官网(“https://www.starbucks.com.cn/”),然后点击菜单,本次需要爬取此页面的图片以及对应的产品名字,并保存到本地。
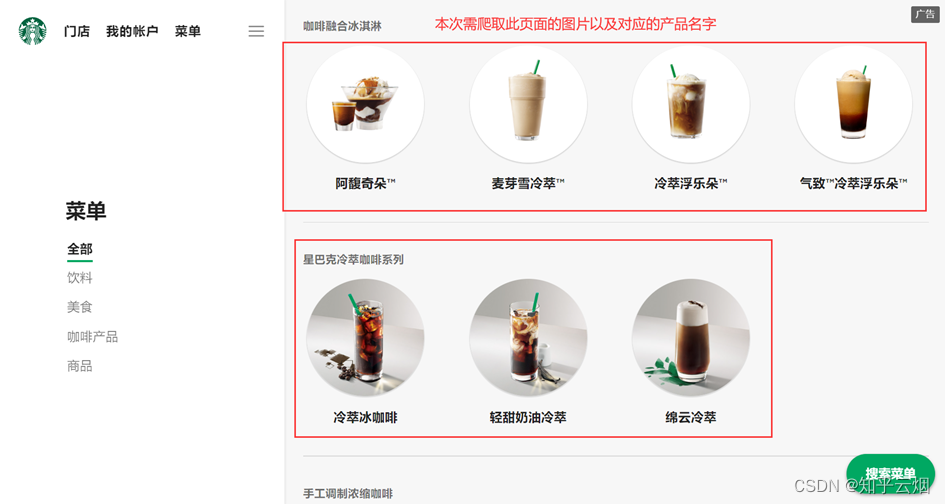
创建文件“076_bs4爬取星巴克数据.py”。

回到浏览器中,按F12打开检查,点到网络,刷新页面,慢慢寻找对应的接口(在响应中使用搜索快捷键Ctr+F,搜索对应的关键字)。然后,点击标头,将请求地址复制到PyCharm中。
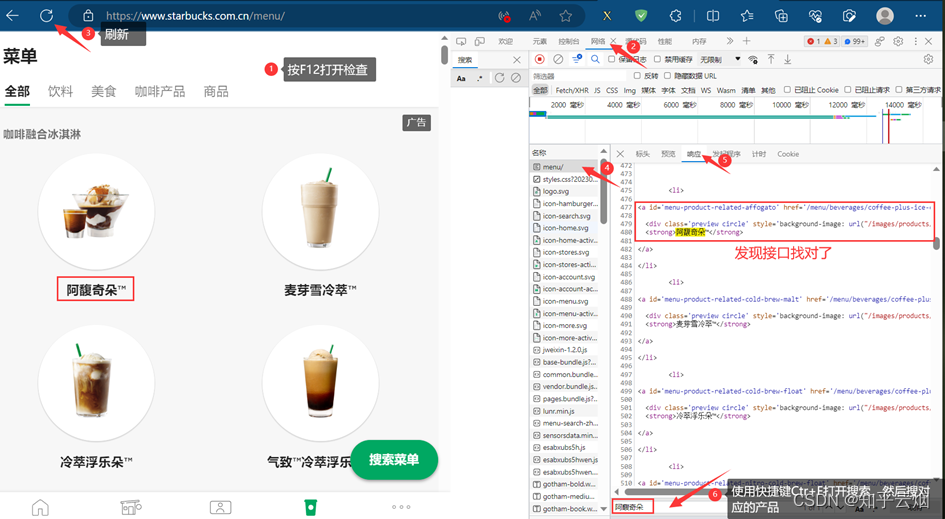

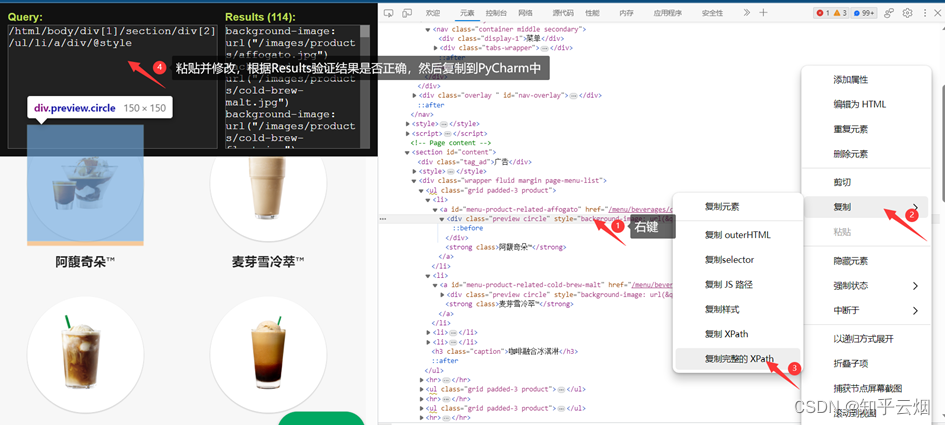
在寻找图片的名字的路径时,一般是先找的xpath路径,然后改成bs4路径的,具体如下图(注:使用快捷键Ctr+Alt+X即可打开插件xpath)。第一张图展示了如何获取到图片的名字的xpath路径,至于如何改成select下的路径参考后面的代码(具体如何理解请结合上一节的笔记。另外,根据xpath写的路径可能获取不到结果,可以根据元素进行适当修改,路径不止一种写法。)。
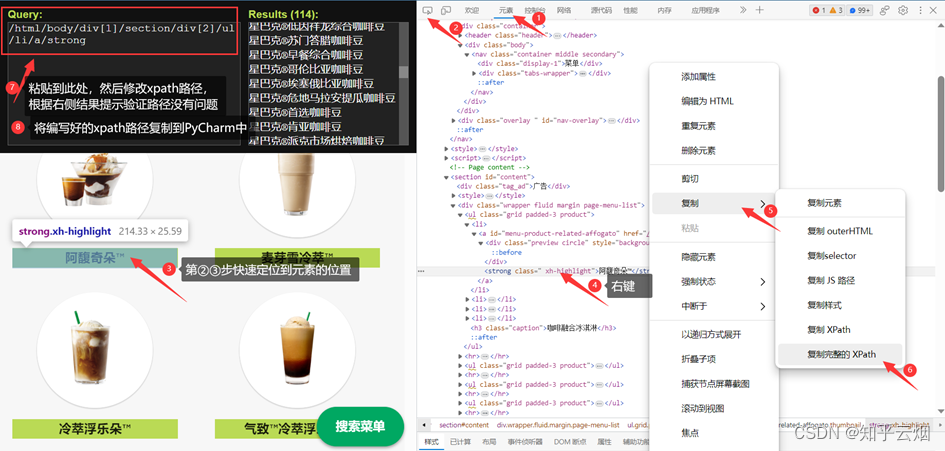
至于图片的请求地址,经过网络和元素两个地方观察发现,它的url是由“https://www.starbucks.com.cn”和元素里的一部分参数组成,具体如图所示。将“https://www.starbucks.com.cn”复制到PyCharm中。
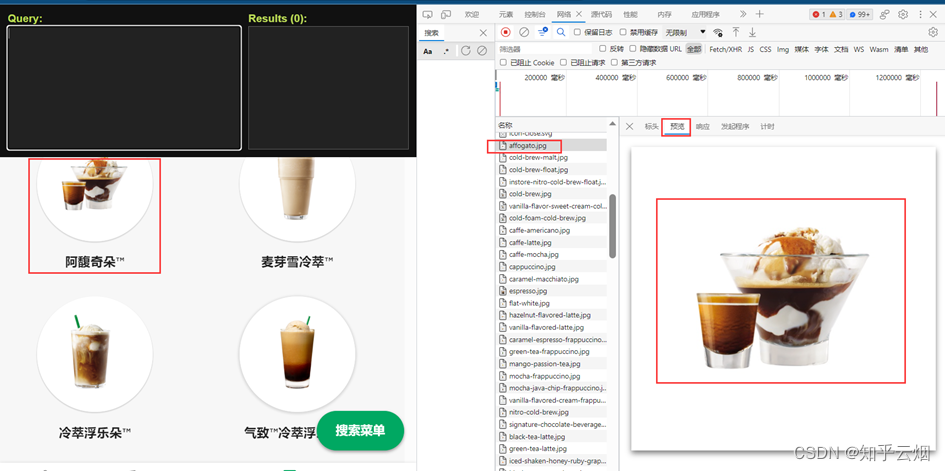
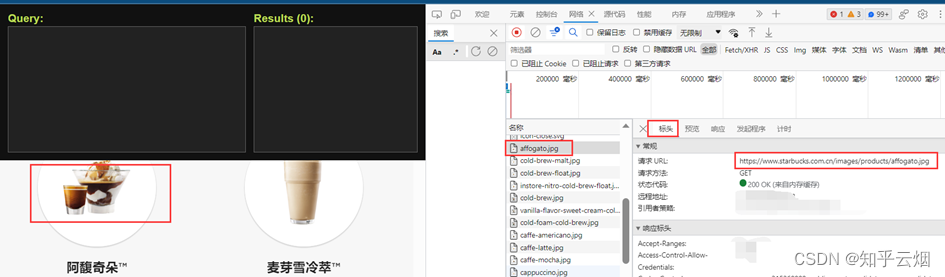
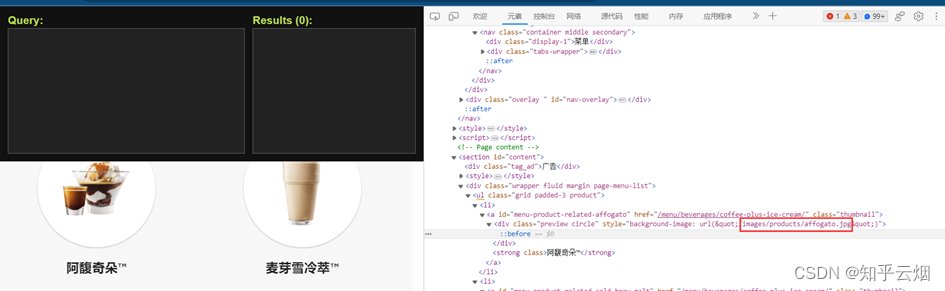
如下图所示,找到图片地址对应的参数的xpath路径,复制到PyCharm中。
创建名为“076_bs4爬取星巴克数据”的文件夹。
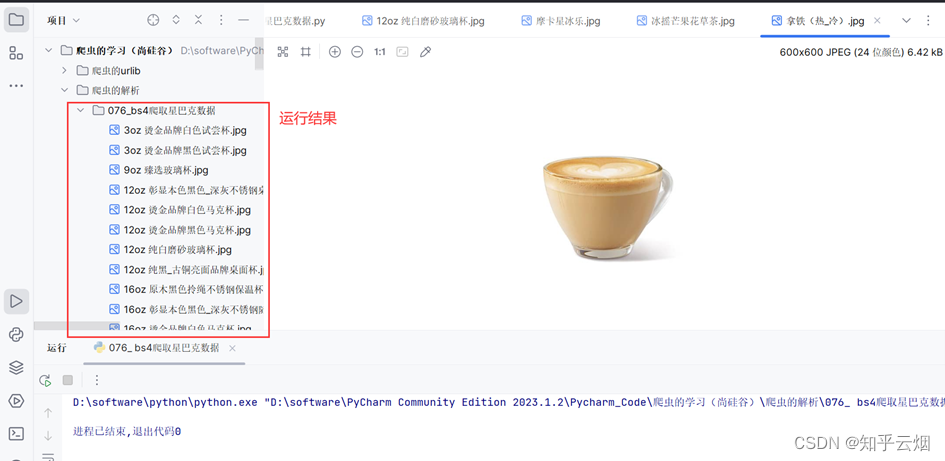
继续编写代码并运行,图片可能有点多,本次程序运行时间较长。
"""
bs4爬取星巴克数据的演示
"""
import urllib.request
from bs4 import BeautifulSoupurl = "https://www.starbucks.com.cn/menu/"
response = urllib.request.urlopen(url)
content = response.read().decode('UTF-8')
# print(content) # 测试代码,验证是否获取到网页源码soup = BeautifulSoup(content, 'lxml')
# 名字的xpath路径 /html/body/div[1]/section/div[2]/ul/li/a/strong
name_list = soup.select('ul[class="grid padded-3 product"] > li > a > strong')# 图片地址 图片参数的xpath路径:/html/body/div[1]/section/div[2]/ul/li/a/div/@style
pic_base_url = 'https://www.starbucks.com.cn'
pic_url_element_list = soup.select('ul[class="grid padded-3 product"] > li > a > div')
pic_url = [] # 用于存放图片地址
pic_name = [] # 用于存放图片名字
for i in range(len(name_list)):pic_name.append(name_list[i].get_text().replace('/', '_')) # 替换斜杠,避免文件命名问题# print(pic_name[i]) # 用于验证是否成功获取到名字# print(pic_url_element_list[i].attrs.get('style')) # 用于验证是否成功获取到图片地址的参数pic_url.append(pic_base_url + pic_url_element_list[i].attrs.get('style').split('"')[1])# 图片名和图片地址有了后,即可下载图片
for i in range(len(name_list)):urllib.request.urlretrieve(url=pic_url[i], filename='./076_bs4爬取星巴克数据/' + pic_name[i] + '.jpg')
好了,本章的笔记到此结束,谢谢大家阅读。