桶用两表关联字段,MapJoin时需要将小表填入内存,这时候,分桶就起到了作用
一个stage阶段代表一个mr执行,好几个MR,会吧每一个MR的结果都压缩
Mysql 慢查询
如果sql语句执行超过指定时间,定义该sql为慢查询,存储日志,
查问题: SQL日志,模拟慢SQL 然后查询执行计划
分组聚合
就是在Map后直接对他进行聚合,而不是在reduce时聚合

默认开启map端聚合
前提条件:
抽样校验 看样品聚合率是否达到要求,将数据会拿到内存聚合,
如果达不到要求,就不继续聚合,然后最后的比例,聚合
最后这个参数有疑问
给聚合留的内存的百分比
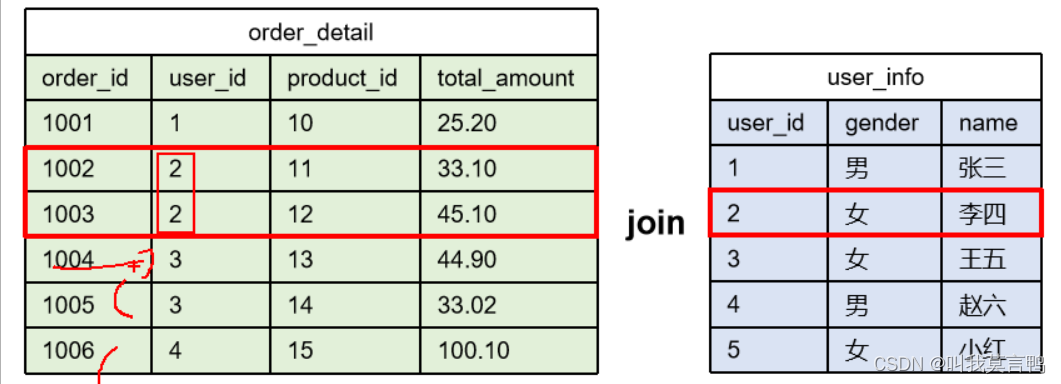
Join优化
Reduce Join
优点:使用范围广
缺点:性能慢
最稳定的,但是性能是最慢的
注意. 读表的时候也不一定是一个maptask完成,多个一起,加快速度
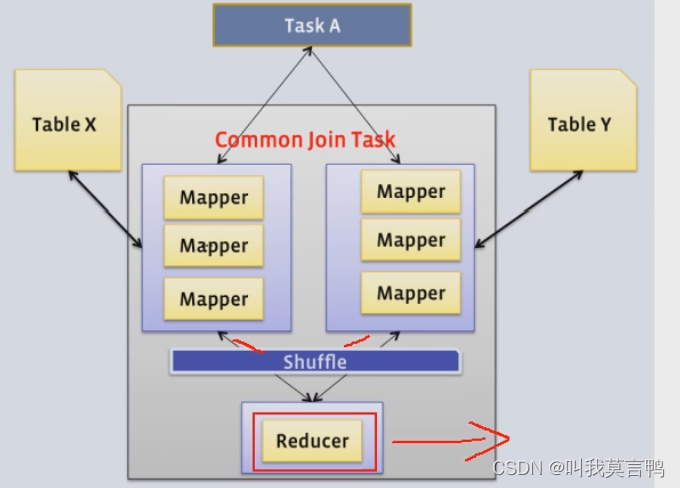
map 负责读数据 资源整合 key关联字段 v Bean
根据数据来源区分,
如果关联字段相同, Bean添加即可 1个
因为是按Key分组
所以不是一个JOIN语句必须对应一个Common Join
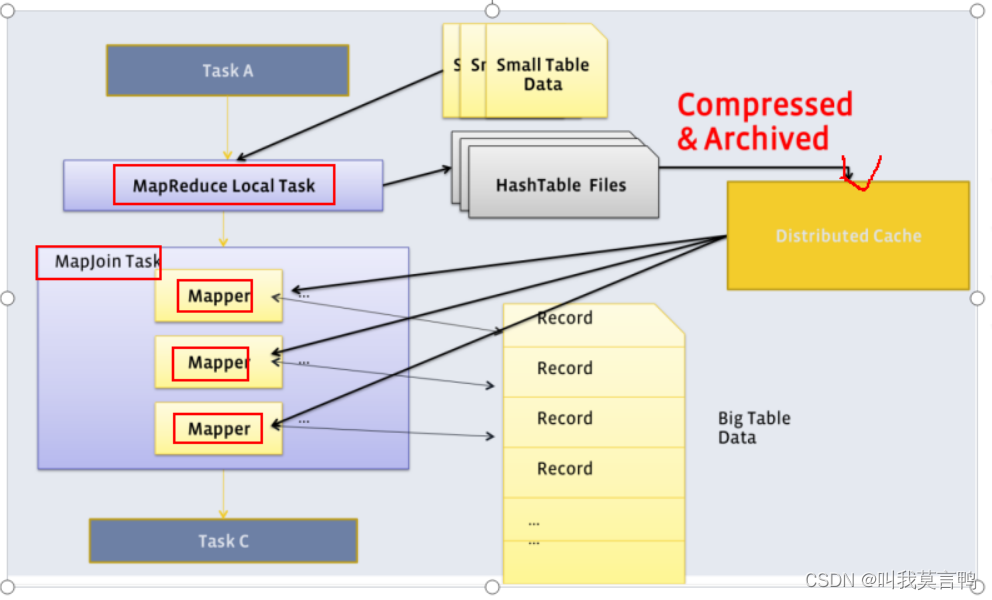
Map Join
特点:针对Common join的优化
使用前提:一张大表与一张小表
概况: job1:小表制作为hash table 上传分布式缓存.(因为分布式,都在内存中找数据)
job2:从缓存中读取小表数据,缓存在Map Task中,扫描大表.
思考:为什么需要大表对小表? 小表缓存快, 其实大表可以分成小表,分部加载即可
优点:
缺点:

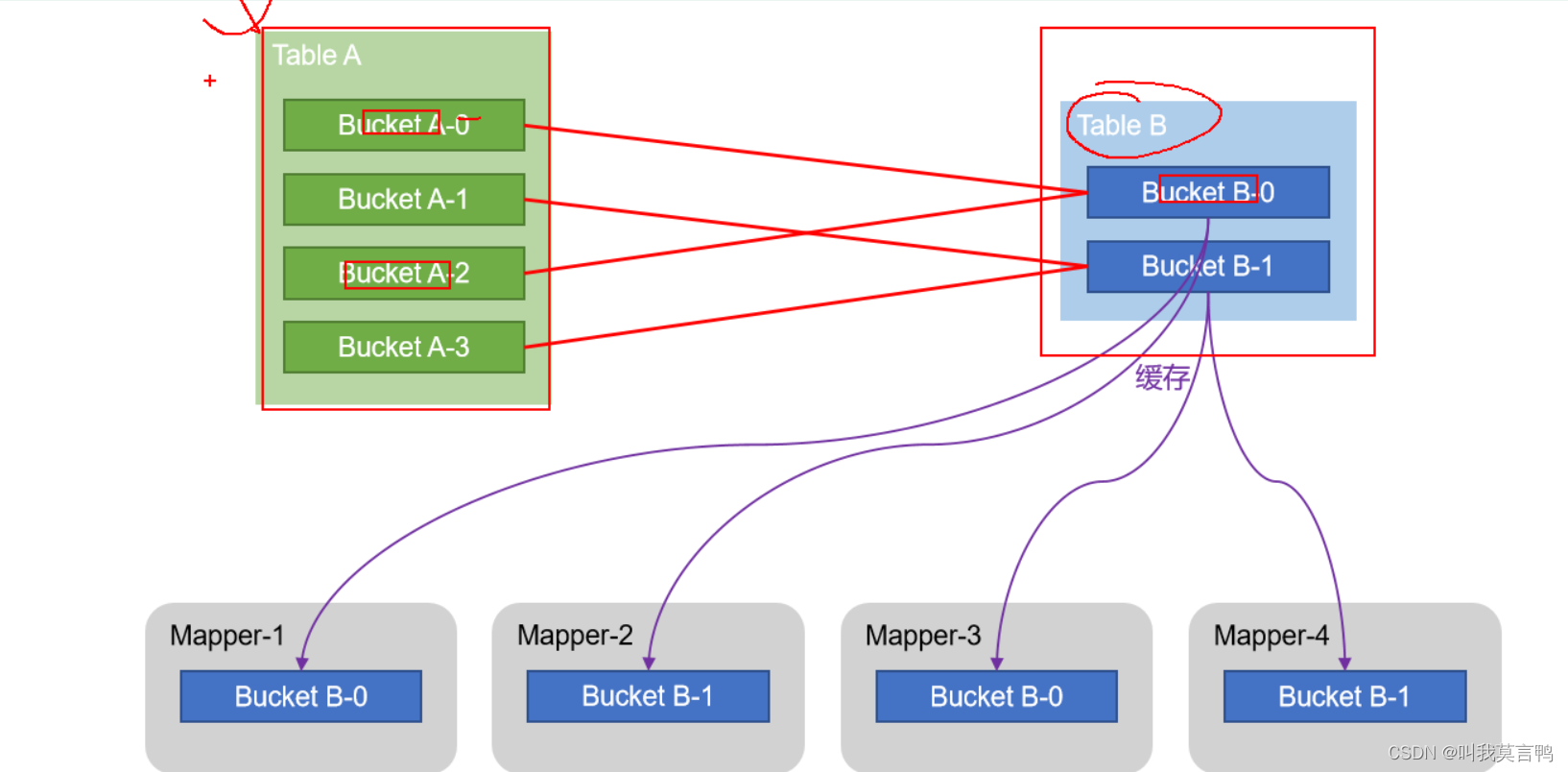
Bucket Map join
将大表进行分割成小表
注意:如果2个都是分桶表,且关联是分桶字段,一张的分桶数量是另一张的整数倍。就能保证join的分桶有明确的关联

因为都是哈希,所以相等或者倍数关系对应是比较符合的
这时候缓存的是桶比较少的表
mapper个数对应桶的最多数。
为什么这么对应?
这样mapper多,快 ,而且占用内存小
Sort Merge Bucket Map Join

比桶Map join多一个排序
HASH join 是什么?
排序后的表为什么快
不排序的话,join时每次比对都需要整表比对

这个数据不需要进入内存加载,直接在磁盘进行操作了,因为他是顺序读取,效率也很高,不需要加入内存读取来提高效率.
节省内存
1.什么时候不知道表大小 子查询
2.对未知大小的表如何map join选择存储的表

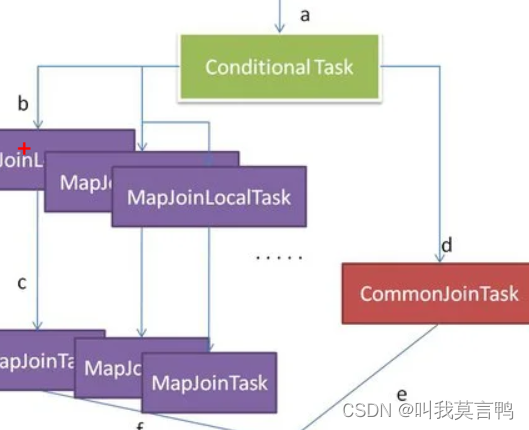
为什么3个?按理说不是2个么
全连接需要全扫描
left right 都只需要大表扫描 , 这里也 是问题 为什么 部分不用全表扫描
都未知走全部,其实就是搜索
大表候选人大小均已知,
最优map join 计划
多表(结合)
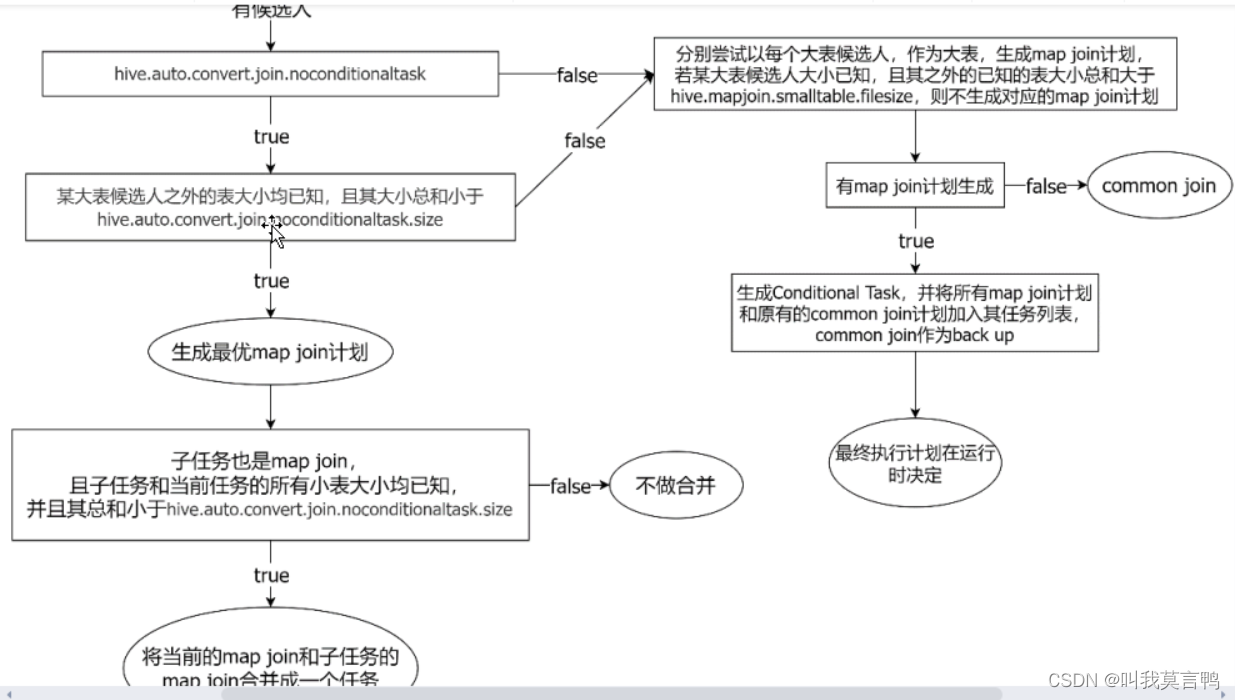
第一次判断,是判断大小第一次
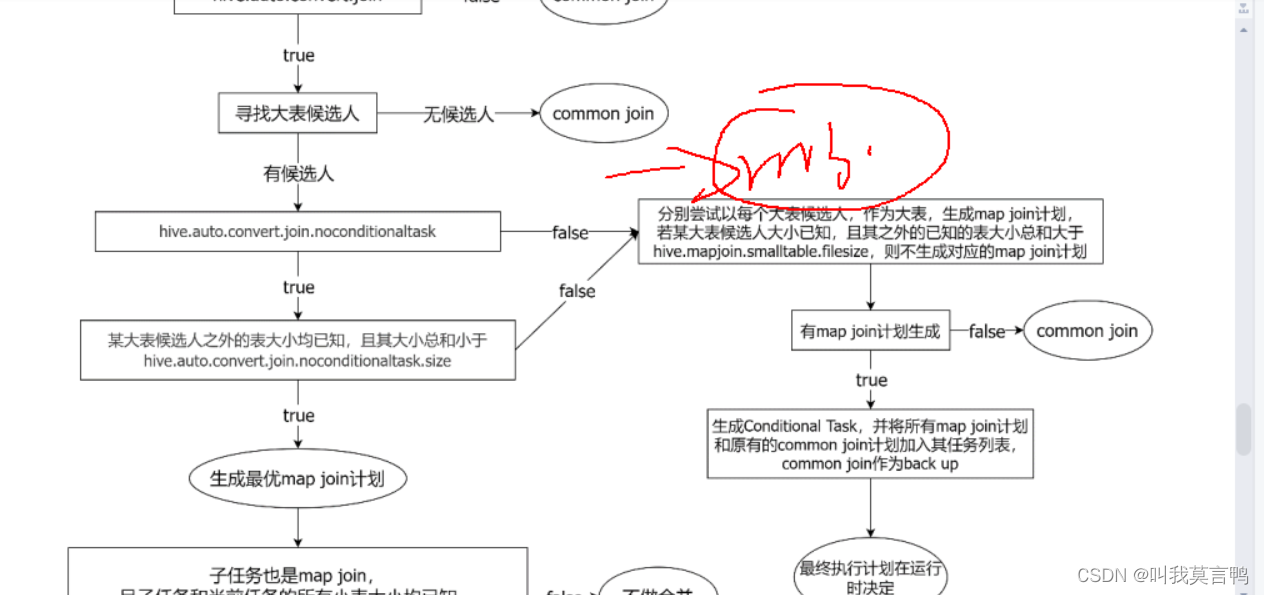
不理解
哪来2个job
CBO 代价优化 忽略mapjoin
Sort Merge Bucket Map join
问题:分桶表的插入等会看一下
只跑了一个job
为什么?
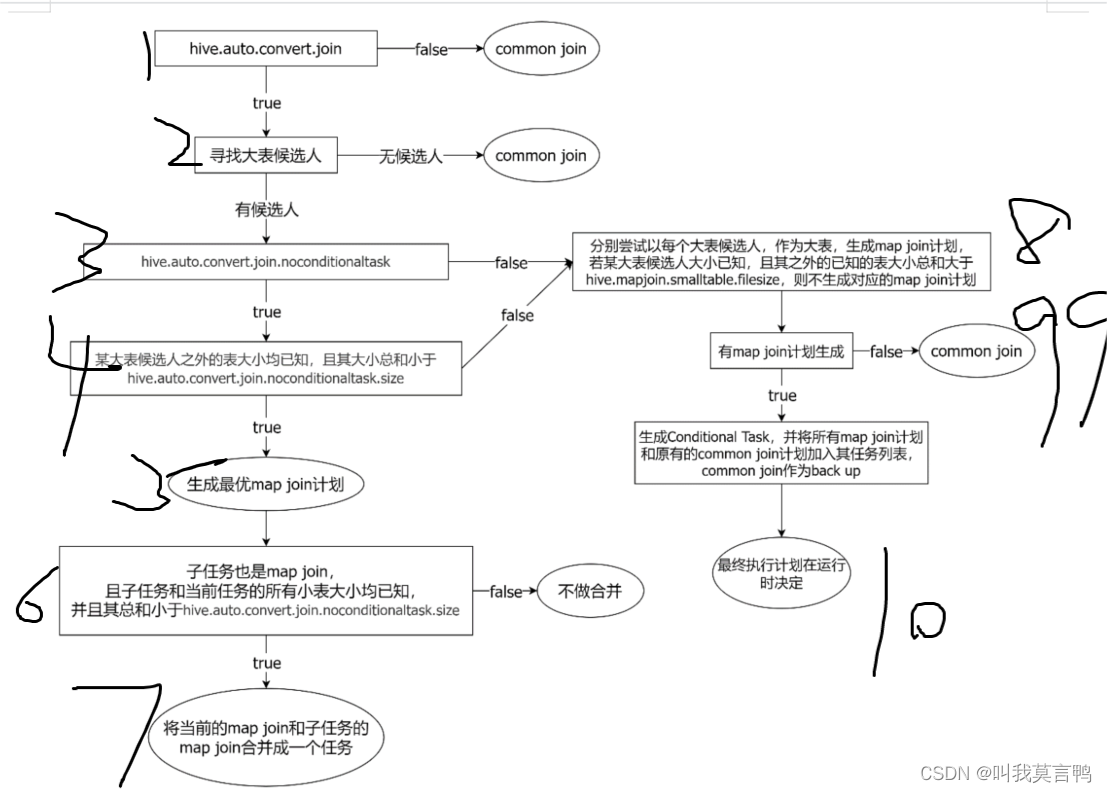
假设abc 三个表
a为主表 b c 为小表
m c 就是子任务 ,那么,子任务是map join么? c小于size
然后b+c 小于size 就说明 6成立 所以就是一个子任务 那么 map join 和子任务map join合并一个任务
就是一直重复
4->a+ n(子表的其中一个)->5 /8
其实就是
主表和小表,一个一个去结合判断,走流程