随着chatGPT的出现,通用大模型已经成为了研究的热点,由于众所周知的原因,亚太地区调用经常会被禁,在国内,讯飞星火大模型是一个非常优秀的中文预训练模型。本文将介绍如何使用Python调用讯飞星火大模型接口,实现文本生成等功能。
1. 安装API库
需要安装库,在命令行中输入以下命令进行安装:
pip3 install websocket
pip3 install websocket-client
2. 获取讯飞星火大模型API密钥
在使用讯飞星火大模型API之前,需要先获取一个API密钥。请访问讯飞开放平台官网(https://www.xfyun.cn/),注册账号并登录后,进入“我的应用”页面,创建一个新的应用
在工单中申请API密钥:
3. 调用讯飞星火大模型API进行文本生成
参考官方api:https://www.xfyun.cn/doc/spark/Web.html
下面演示如何使用Python调用讯飞星火大模型接口进行文本生成。需要导入所需的库,并设置API密钥: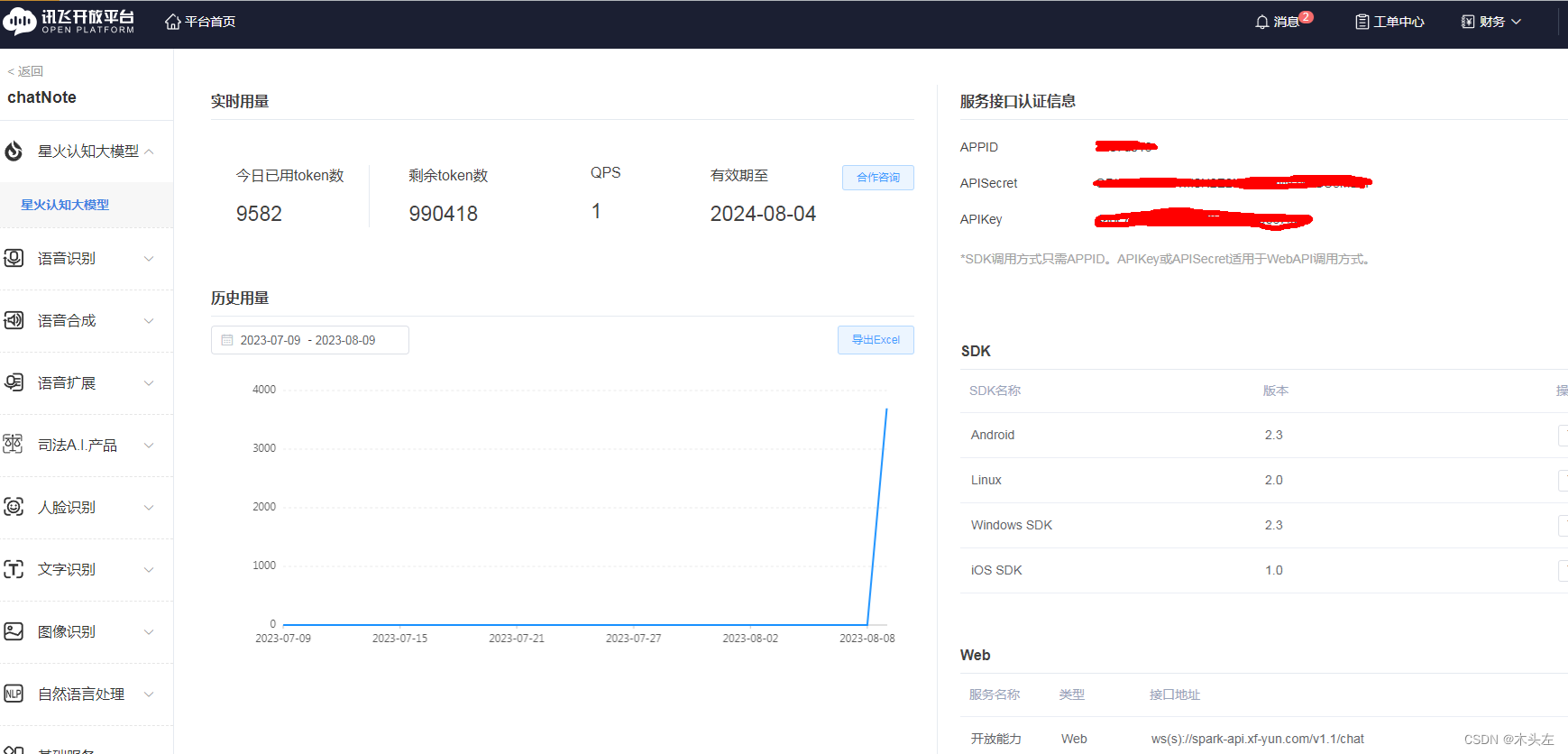
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_timeimport websocket
global result
import osclass Ws_Param(object):# 初始化def __init__(self, APPID, APIKey, APISecret, gpt_url):self.APPID = APPIDself.APIKey = APIKeyself.APISecret = APISecretself.host = urlparse(gpt_url).netlocself.path = urlparse(gpt_url).pathself.gpt_url = gpt_url# 生成urldef create_url(self):# 生成RFC1123格式的时间戳now = datetime.now()date = format_date_time(mktime(now.timetuple()))# 拼接字符串signature_origin = "host: " + self.host + "\n"signature_origin += "date: " + date + "\n"signature_origin += "GET " + self.path + " HTTP/1.1"# 进行hmac-sha256进行加密signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),digestmod=hashlib.sha256).digest()signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')# 将请求的鉴权参数组合为字典v = {"authorization": authorization,"date": date,"host": self.host}# 拼接鉴权参数,生成urlurl = self.gpt_url + '?' + urlencode(v)# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致return url# 收到websocket错误的处理def on_error(ws, error):print("### error:", error)# 收到websocket关闭的处理def on_close(ws):print("### closed ###")# 收到websocket连接建立的处理def on_open(ws):thread.start_new_thread(run, (ws,))def run(ws, *args):data = json.dumps(gen_params(appid=ws.appid, question=ws.question))ws.send(data)# 收到websocket消息的处理def on_message(ws, message):global result # print(message)data = json.loads(message)code = data['header']['code']if code != 0:print(f'请求错误: {code}, {data}')ws.close()else:choices = data["payload"]["choices"]status = choices["status"]content = choices["text"][0]["content"]result += contentprint(content, end='')if status == 2:ws.close()")
4. 代码解释
这段代码定义了一个名为Ws_Param的类,用于处理WebSocket请求。以下是代码中各个方法的解释:
-
__init__(self, APPID, APIKey, APISecret, gpt_url):初始化方法,用于设置类的实例变量。其中,APPID、APIKey、APISecret分别表示讯飞开放平台的应用ID、API Key和API Secret;gpt_url表示讯飞语音合成服务的URL。 -
create_url(self):生成请求的URL。根据当前时间生成RFC1123格式的时间戳;然后,拼接签名字符串,包括host、date和GET请求行;接着,使用hmac-sha256算法对签名字符串进行加密;将加密后的签名字符串进行Base64编码,并将其添加到鉴权参数中,生成完整的URL。 -
on_error(ws, error):收到WebSocket错误的处理方法。当WebSocket连接发生错误时,会调用此方法。 -
on_close(ws):收到WebSocket关闭的处理方法。当WebSocket连接关闭时,会调用此方法。 -
on_open(ws):收到WebSocket连接建立的处理方法。当WebSocket连接建立时,会调用此方法。在此处,会启动一个新的线程来运行run函数。 -
run(ws, *args):运行函数,用于向讯飞语音合成服务发送请求。根据WebSocket实例的appid和question属性生成请求参数;然后,将请求参数转换为JSON字符串并通过WebSocket发送。 -
on_message(ws, message):收到WebSocket消息的处理方法。当从讯飞语音合成服务接收到消息时,会调用此方法。解析接收到的消息;然后,根据消息中的code判断请求是否成功;如果成功,则将返回的内容累加到全局变量result中,并打印出来;如果code不为0,表示请求失败,此时关闭WebSocket连接。
5.自动保存
最好把每次调用接口保存下来,并总结一些常用的话术,如起名,指定markdown格式等:
# -*- coding: utf-8 -*-
import sys
import os
sys.path.append(os.path.abspath(os.path.dirname(os.path.dirname(__file__))))
import requests, json,time
from ai import SparkApi
from util import file_util
def write(prefix, titile):result = SparkApi.api(prefix + titile) result = result.replace('我们','').replace('首先,','').replace('其次,','').replace('最后,','')file_util.write(os.path.join(r'./data', titile + '.md'), result)
def article(titile): prefix = '假如你是一个公众号博主,请以markdown格式写一篇1500字的文章并起10个吸引人的标题,从第二级标题开始,' write(prefix, titile)
def replace(titile):result = file_util.read(os.path.join(r'./data', titile + '.md'))result = result.replace('我们','').replace('首先,','').replace('其次,','').replace('最后,','')file_util.write(os.path.join(r'./data', titile + '.md'), result)
def code(titile, code_str):prefix = '假如你是一个公众号博主,请以markdown格式写一篇1500字的文章,解释如下代码:' write(prefix + code_str, titile)
if __name__ == '__main__':startTime=time.time() article("python调用讯飞星火大模型接口")endTime=time.time()print(str(endTime-startTime))''')