手把手推导扩散模型:Diffusion Models(DDPM)
- DDPM理论回顾
- 前置知识
- 过程详解
- Forward Process
- Reverse Process
- DDPM算法伪代码
- 训练部分
- 采样部分
- 总结一下
- 参考链接
在这篇博客文章中,我们将深入研究 去噪扩散概率模型(也称为 DDPM,扩散模型,基于分数的生成模型或简单的 自动编码器) ,因为研究人员已经能够用它们在(非)条件图像/音频/视频生成方面取得显著成果。最受欢迎的例子(在写这篇文章的时候)包括由 OpenAI 设计的 GLIDE 和 DALL-E 2,由海德堡大学设计的 潜扩散,以及由谷歌大脑设计的 ImageGen。
DDPM理论回顾
生成扩散模型DDPM如下图所示分为前向、逆向两个过程,它首先通过不断往原始清晰数据中添加噪声使其变成标准高斯噪声(前向过程),而后期望从标准高斯噪声中还原原始数据(逆向过程)。若能实现,那便可从已知的标准高斯分布中采样一个噪声数据,而后利用DDPM模型生成符合原始数据分布的新数据。
Diffusion模型包含两个过程:
- 逆向过程(Reverse Process):也称为去噪过程(denoising diffusion)。如果知道逆向过程的每一步的真实分布 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt),那么从一个随机噪声 x T ∼ N ( x ; 0 , I ) x_T\sim \mathcal{N}\left(x ; \mathbf{0}, \mathrm{I}\right) xT∼N(x;0,I)开始,逐渐去噪就能生成一个真实的样本,所以逆向过程也就是生成数据的过程。
- 正向过程(Forward Process):也就是加噪过程、扩散(diffusion)过程。对于给定的现实世界中存在的真实图像 x 0 \mathbf{x}_0 x0,我们对其一步步加噪声,得到 x 1 \mathbf{x}_1 x1, x 2 \mathbf{x}_2 x2,…,最后得到完全的高斯噪声 x T \mathbf{x}_T xT。前向过程的存在意义是帮助神经网络去学习逆向过程,也就是训练用的。
更仔细想想的话,前向过程里得到的噪声其实就是"生成标签"的过程,因为在这一过程中,已经有了真实的图像,并且生成了真实图像加噪后的结果;那么自然就可能让网络学习这样一个映射,即从有噪声的图像中恢复原始图像。
前置知识
数学符号: y ∝ x y\propto x y∝x:y正比于x,即y随着x增大而线性增大。
条件概率:
- p ( A ∣ B ) p(A|B) p(A∣B)表示事件B已经发生的情况下,事件A发生的可能性。也就是说变量B已知的情况下,变量A的取值分布。
- p ( A ∣ B , C ) p(A|B,C) p(A∣B,C)表示在B、C同时发生的情况下,事件A发生的概率。也就是说变量B、C已知确定的情况下,变量A的取值分布。
贝叶斯公式: p ( A ∣ B ) = p ( B ∣ A ) × p ( A ) p ( B ) p(A|B)=\frac{p(B|A)\times p(A)}{p(B)} p(A∣B)=p(B)p(B∣A)×p(A)
高斯分布的概率密度函数:给定均值为 μ \mu μ,标准差为 σ \sigma σ,方差为 σ 2 \sigma^2 σ2的高斯分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2),其概率密度函数(PDF)为: p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 p(x)=\frac{1}{\sqrt{2\pi}\sigma }e^{-\frac{(x-\mu)^2}{2\sigma^2}} p(x)=2πσ1e−2σ2(x−μ)2。很多时候为了方便也会写成 p ( x ) ∝ e − ( x − μ ) 2 2 σ 2 p(x)\propto e^{-\frac{(x-\mu)^2}{2\sigma^2}} p(x)∝e−2σ2(x−μ)2,也就是把前面乘的常数 1 2 π \frac{1}{\sqrt{2\pi}} 2π1去掉。进一步地,为了方便推导,把 e − ( x − μ ) 2 2 σ 2 e^{-\frac{(x-\mu)^2}{2\sigma^2}} e−2σ2(x−μ)2展开,因此有 p ( x ) ∝ e x p ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) p(x)\propto exp(-\frac{1}{2}(\frac{1}{\sigma ^2}x^2-\frac{2\mu }{\sigma ^2}x+\frac{\mu^2}{\sigma^2})) p(x)∝exp(−21(σ21x2−σ22μx+σ2μ2))
概率分布中分号的理解,对形如 q ( x t ∣ x t − 1 ) = N ( X t ; 1 − β t x t − 1 , β t I ) q(x_t|x_{t-1})=N(X_t;\sqrt{1-\beta _t}x_{t-1},\beta _t\mathrm{I}) q(xt∣xt−1)=N(Xt;1−βtxt−1,βtI)的式子的理解如下:
f ( x ) f(x) f(x)其实就是一个函数,输入变量值 x x x,在经过规则 f f f 处理后,最终拿到一个结果。另一种常见的情况,比如概率分布 P ( x ) P(x) P(x),其本质上也是一个以 x x x 为自变量的函数,在变量 X X X的值为 x x x的情况下,拿到一个结果,这个结果的意义为变量 X X X取到 x x x的概率。而 f ( x ; θ ) f(x;\theta) f(x;θ),其实意思就是 f ( x ) f(x) f(x),只不过强调函数的参数为 θ \theta θ。这个 θ \theta θ可以是某个确定的常量,也可以是多个确定常量的总体(比如深度神经网络中的全体可训练参数)。例如: θ 2 x + 2 θ + 1 \theta^2x + 2\theta + 1 θ2x+2θ+1, θ = 3 \theta = 3 θ=3,这个函数自变量是 x x x,自然可以写成 f ( x ) f(x) f(x);又因为 x x x的系数(参数)是 θ \theta θ(某个已知或未知的确定值),因此可以表达为 f ( x ; θ ) f(x;\theta) f(x;θ)。
根据上述内容,现在讨论一个比较复杂的情况。比如, N ( x ; 0 , I ) \mathcal{N}\left(x ; \mathbf{0}, \mathrm{I}\right) N(x;0,I)的意思是什么?我们知道, N ( 0 , I ) \mathcal{N}\left(\mathbf{0}, \mathrm{I}\right) N(0,I)表示标准高斯分布,均值为0,方差为1,其本质上也是一个概率密度函数: f ( x ) = 1 2 π e − x 2 2 f(x)=\frac{1}{\sqrt{2 \pi}} e^{-\frac{x^2}{2}} f(x)=2π1e−2x2。从这里可以发现,一般的函数我们都是强调自变量本身(比如 x x x),而在概率论里面有时候强调的是函数参数本身(比如高斯分布的均值和方差),而淡化了输入变量(默认为 x x x,省略)。因此 N ( x ; 0 , I ) \mathcal{N}\left(x ; \mathbf{0}, \mathrm{I}\right) N(x;0,I)相比与 N ( 0 , I ) \mathcal{N}\left(\mathbf{0}, \mathrm{I}\right) N(0,I)的区别就在于显式强调了函数的输入为 x x x。
最后再来讲一个更复杂的东西: q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)=\mathcal{N}\left(\mathbf{x}_t ; \sqrt{1-\beta_t} \mathbf{x}_{t-1}, \beta_t \mathrm{I}\right) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)。这个公式要分多步来看。首先,函数本身是个条件概率分布, q ( x t ∣ x t − 1 ) q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right) q(xt∣xt−1)表示 x t − 1 \mathbf{x}_{t-1} xt−1已知的情况下, x t \mathbf{x}_{t} xt的分布( x t \mathbf{x}_{t} xt取各种值的概率)。而后面的这个高斯分布则强调了其输入自变量为 x t \mathbf{x}_{t} xt(因为是 x t \mathbf{x}_{t} xt的概率密度函数,所以自变量当然是 x t \mathbf{x}_{t} xt,而高斯分布的均值和方差则分别为 1 − β t x t − 1 \sqrt{1-\beta_t} \mathbf{x}_{t-1} 1−βtxt−1和 β t I \beta_t \mathrm{I} βtI,与条件分布的条件 x t − 1 \mathbf{x}_{t-1} xt−1有关。
也就是说,如果概率分布密度函数中的自变量不是默认的 x x x而是其他,那么应该在分布记号中显式地用分号表示实际的自变量,比如实际的自变量是 x 1 x_1 x1而不是 x x x,那么高斯分布应该记作 N ( x 1 ; μ , σ 2 ) \mathcal{N}(x_1; \mu, \sigma^2) N(x1;μ,σ2)。默认不写分号的话, N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2)等价于 N ( x ; μ , σ 2 ) \mathcal{N}(x; \mu, \sigma^2) N(x;μ,σ2)。
高斯分布的乘法与加法:
- 对标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1)做乘法,乘以 σ \sigma σ,得到一个新的高斯分布, N ( 0 , σ 2 ) \mathcal{N}(0, \sigma^2) N(0,σ2)N。
- 对标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1)做加法,加上 μ \mu μ,得到一个新的高斯分布, N ( μ , 1 ) \mathcal{N}(\mu, 1) N(μ,1)。
- 两个高斯分布 N ( 0 , σ 1 2 ) \mathcal{N}(0, \sigma_1^2) N(0,σ12), N ( 0 , σ 2 2 ) \mathcal{N}(0, \sigma_2^2) N(0,σ22)相加,得到一个新的高斯分布, N ( 0 , σ 1 2 + σ 2 2 ) \mathcal{N}(0, \sigma_1^2 + \sigma_2^2) N(0,σ12+σ22)。
重参数化技巧:对高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2)进行采样一个噪声 ϵ \epsilon ϵ,等价于先从标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1)中采样得到一个噪声 z \mathbf{z} z,乘以标准差 σ \sigma σ,加上均值 μ \mu μ,即: ϵ = μ + z ⋅ σ \epsilon = \mu + \mathbf{z} \cdot \sigma ϵ=μ+z⋅σ,进行这一转化是为了方便网络训练。举个例子,上面我们已经得到了 x t \mathbf{x}_t xt是从高斯分布 N ( 1 − β t x t − 1 , β t I ) \mathcal{N}(\sqrt{1-\beta_{t}}\mathbf{x}_{t-1},\beta_{t}\mathbf{I}) N(1−βtxt−1,βtI)采样出来的噪声,该高斯分布的均值为 1 − β t x t − 1 \sqrt{1-\beta_{t}}\mathbf{x}_{t-1} 1−βtxt−1 ,标准差为 β t \sqrt{\beta_{t}} βt ,所以 x t = 1 − β t x t − 1 + β t z \mathbf{x}_t=\sqrt{1-\beta_{t}}\mathbf{x}_{t-1}+\sqrt{\beta_{t}}\mathbf{z} xt=1−βtxt−1+βtz。
过程详解
Forward Process
前向过程也称为扩散过程,将真实数据逐步变成噪声。比方说,给定一张原始图像 x 0 \mathbf{x}_0 x0,对其加一次「标准」高斯噪声 z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(0, \mathbf{I}) z∼N(0,I),得到 x 1 \mathbf{x}_1 x1。记 x i \mathbf{x}_i xi为对原始图像加 i i i 次噪声后的结果,可以发现,当 i i i 足够大的时候,数据会被高斯噪声淹没,变成纯正的高斯噪声。
第一个问题,加多少次噪声?在文中,其由一个超参数 T T T控制,即步数。原文 T = 1000 T=1000 T=1000,即对原始图像加1000次噪声后,其会变成完全的高斯噪声。
第二个问题,噪声怎么加?因为加噪过程本质是加权和,比如 0.8 × I m a g e + 0.1 × N o i s e 0.8×Image + 0.1×Noise 0.8×Image+0.1×Noise,会涉及到一个权重的问题(注意,我们后面会看到,图像的权重与噪声的权重相加并不需要为1)。在文章中,噪声的这个权重有个专有的名词,叫做扩散率,记为 β \beta β,比如可以从0.0001逐步插值到0.02。从这里可以看到,加噪是一个逐步的过程,对图像原有的信息是慢慢破坏的(扩散率很低)。这样主要是为了方便网络在逆扩散过程中学习去噪,如果对信息一次破坏太多那么网络可能就无法学会怎么去复原了。
为什么扩散率是逐渐增大的呢?可以反过来理解,在加噪声的过程中,扩散率逐渐增大,对应着在去噪声的过程中,扩散率逐渐减小——也就是说,去噪的过程是先把"明显"的噪声给去除,对应着较大的扩散率;当去到一定程度,逐渐逼近真实真实图像的时候,去噪速率逐渐减慢,开始微调,也就是对应着较小的扩散率。
现在来看扩散过程的初步数学定义 。给定当前具有一定噪声的图像 x t − 1 \mathrm{x}_{t-1} xt−1,加入标准高斯噪声 z t − 1 ∼ N ( 0 , I ) \mathbf{z}_{t-1}\sim \mathcal{N}(0,\mathbf{I}) zt−1∼N(0,I),得到进一步加噪的图像 x t \mathbf{x}_t xt,有: x t = 1 − β t x t − 1 + β t z t − 1 \mathbf{x}_t=\sqrt{1-\beta _t}\mathbf{x}_{t-1}+\sqrt{\beta_t}\mathbf{z}_{t-1} xt=1−βtxt−1+βtzt−1这个公式其实就是上面提到的 a × Image + b × Noise a\times \text{Image}+b\times \text{Noise} a×Image+b×Noise,其中 Image \text{Image} Image为 x t − 1 \mathbf{x}_{t-1} xt−1, Noise \text{Noise} Noise为 z t − 1 \mathbf{z}_{t-1} zt−1。
但是,论文中提到了下面的式子,也就是概率分布的形式: q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1})=\mathcal{N}(\mathbf{x}_t;\sqrt{1-\beta _t}\mathbf{x}_{t-1},\beta_t\mathbf{I}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)需要注意的是 x t = 1 − β t x t − 1 + β t z t − 1 \mathbf{x}_t=\sqrt{1-\beta _t}\mathbf{x}_{t-1}+\sqrt{\beta_t}\mathbf{z}_{t-1} xt=1−βtxt−1+βtzt−1与 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1})=\mathcal{N}(\mathbf{x}_t;\sqrt{1-\beta _t}\mathbf{x}_{t-1},\beta_t\mathbf{I}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)是等价的。这可以从前面介绍的重参数化技巧中可知, ϵ = μ + z ⋅ σ \epsilon = \mu + \mathbf{z}\cdot \sigma ϵ=μ+z⋅σ表示的就是从 ϵ ∼ N ( μ , σ 2 ) \epsilon \sim \mathcal{N}(\mu, \sigma^2) ϵ∼N(μ,σ2)中采样的过程。据此,同样就可以将 x t \mathbf{x}_t xt改写为从 q ( x t ∣ x t − 1 ) q(\mathbf{x}_t|\mathbf{x}_{t-1}) q(xt∣xt−1)中采样的形式。
进一步地,用人话来说,有:
- 因为加噪声是一个带有随机性的过程(噪声是随机的),所以 x t \mathbf{x}_t xt是可以写成概率分布形式的,即 q ( x t ) q(\mathbf{x}_t) q(xt),并且该分布是一个高斯分布 N \mathcal{N} N(加入的是高斯噪声);
- 又因为是给定了 x t − 1 \mathbf{x}_{t-1} xt−1,才能知道 x t \mathbf{x}_t xt,所以这个分布还是一个条件分布,即 q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) q(xt∣xt−1)。
- 此外,这个高斯分布是有关于当前变量 x t \mathbf{x}_t xt的条件分布,因此会记作 N ( x t ; a , b ) \mathcal{N}(\mathbf{x}_t; a, b) N(xt;a,b)而非 N ( a , b ) \mathcal{N}(a,b) N(a,b)。
- 关于 β t \beta_t βt,之前提到的扩散率 β \beta β是插值得到的,会不断变化,因此落实到加噪第 t t t步过程的 β \beta β则记为 β t \beta_t βt。
现在解决第三个问题:给定原始图像 x 0 \mathbf{x}_0 x0,能不能一步到位计算得到加噪 t t t次后的 x t \mathbf{x}_t xt?答案是可以的。首先看结论: x t = α ˉ t x 0 + 1 − α ˉ t z ~ t \mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\tilde {\mathbf{z}}_t xt=αˉtx0+1−αˉtz~t其中 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, α t ˉ = α 1 × . . . × α t = ∏ i = 1 t α i \bar{\alpha_t} = \alpha_1 × ... × \alpha_t = \prod \limits_{i=1}^t \alpha_i αtˉ=α1×...×αt=i=1∏tαi, z ~ t ∼ N ( 0 , I ) \tilde{\mathbf{z}}_t \sim \mathcal{N}(0, \mathbf{I}) z~t∼N(0,I)。这样,当想求一个 t t t很大的 x t \mathbf{x_t} xt时,就省去了逐步模拟的步骤。
可以发现,当 t t t很大时, α ˉ t \sqrt{\bar{\alpha}_t} αˉt会很接近0,最终的结果 x t \mathbf{x}_t xt几乎完全由噪声 z ~ t \tilde{\mathbf{z}}_t z~t所取代,但仍然保留了十分微弱的原始图像 x 0 \mathbf{x}_0 x0。也就是说,只要方法巧妙,理论上还是可以通过逐步去噪的方式得到 x t \mathbf{x}_t xt中隐藏的 x 0 \mathbf{x}_0 x0。
推导过程: x t = α t x t − 1 + 1 − α t z t − 1 = α t α t − 1 x t − 2 + α t ( 1 − α t − 1 ) z t − 2 + 1 − α t z t − 1 = α t α t − 1 x t − 2 + 1 − α t α t − 1 z ˉ t − 2 = . . . = α ˉ t x 0 + 1 − α ˉ t z ~ t \begin{equation*} \begin{split} \mathbf{x}_t & =\sqrt{\alpha _t}\mathbf{x}_{t-1}+\sqrt{1-\alpha_t}\mathbf{z}_{t-1} \\ & = \sqrt{\alpha _t\alpha _{t-1}}\mathbf{x}_{t-2}+\sqrt{\alpha_t(1-\alpha _{t-1})}\mathbf{z}_{t-2}+\sqrt{1-\alpha _t}\mathbf{z}_{t-1}\\ & = \sqrt{\alpha_t\alpha _{t-1}}\mathbf{x}_{t-2}+\sqrt{1-\alpha _t\alpha _{t-1}}\bar{\mathbf{z}}_{t-2} \\ & = ... \\ & = \sqrt{\bar{\alpha }_t}\mathbf{x}_0 +\sqrt{1-\bar{\alpha }_t}\tilde {\mathbf{z}}_t \end{split} \end{equation*} xt=αtxt−1+1−αtzt−1=αtαt−1xt−2+αt(1−αt−1)zt−2+1−αtzt−1=αtαt−1xt−2+1−αtαt−1zˉt−2=...=αˉtx0+1−αˉtz~t上面式子中各种 z \mathbf{z} z的变体都满足标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1)。第一行到第二行是把 x t − 1 = α t − 1 x t − 2 + 1 − α t − 1 z t − 2 \mathbf{x}_{t-1} =\sqrt{\alpha_{t-1}} \mathbf{x}_{t-2}+\sqrt{1-\alpha_{t-1}} \mathbf{z}_{t-2} xt−1=αt−1xt−2+1−αt−1zt−2给换进去。主要比较难理解的地方在于第二行到第三行, α t ( 1 − α t − 1 ) z t − 2 + 1 − α t z t − 1 \sqrt{\alpha_t\left(1-\alpha_{t-1}\right)} \mathbf{z}_{t-2}+\sqrt{1-\alpha_t} \mathbf{z}_{t-1} αt(1−αt−1)zt−2+1−αtzt−1是怎么变成 1 − α t α t − 1 z ˉ t − 2 \sqrt{1-\alpha_t \alpha_{t-1}}\bar{\mathbf{z}}_{t-2} 1−αtαt−1zˉt−2 的,解释如下:
对于任意两个正态分布 x ∼ N ( μ 1 , σ 1 2 ) \mathbf{x}\sim \mathcal{N}(\mu_1, \sigma_1^2) x∼N(μ1,σ12)和 y ∼ N ( μ 2 , σ 2 2 ) \mathbf{y}\sim \mathcal{N}(\mu_2, \sigma_2^2) y∼N(μ2,σ22),根据前面介绍的公式,它们的和的分布为 x + y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) \mathbf{x}+\mathbf{y} \sim \mathcal{N}(\mu_1+\mu_2, \sigma_1^2+\sigma_2^2) x+y∼N(μ1+μ2,σ12+σ22),因此,对于两个标准正态分布 z t − 2 \mathbf{z}_{t-2} zt−2和 z t − 1 \mathbf{z}_{t-1} zt−1,将其前面乘上一个系数得到: α t − α t α t − 1 z t − 2 ∼ N ( 0 , α t − α t α t − 1 ) , 1 − α t z t − 1 ∼ N ( 0 , 1 − α t ) \sqrt{\alpha _t-\alpha _t\alpha _{t-1}}\mathbf{z}_{t-2}\sim \mathcal{N}(0, \alpha_t-\alpha_t\alpha_{t-1}), \sqrt{1-\alpha_t}\mathbf{z}_{t-1}\sim \mathcal{N}(0,1-\alpha_t) αt−αtαt−1zt−2∼N(0,αt−αtαt−1),1−αtzt−1∼N(0,1−αt),因此 α t − α t α t − 1 z t − 2 + 1 − α t z t − 1 ∼ N ( 0 , 1 − α t α t − 1 ) \sqrt{\alpha _t-\alpha _t\alpha _{t-1}}\mathbf{z}_{t-2}+ \sqrt{1-\alpha_t}\mathbf{z}_{t-1}\sim \mathcal{N}(0,1-\alpha_t\alpha_{t-1}) αt−αtαt−1zt−2+1−αtzt−1∼N(0,1−αtαt−1),也即 1 − α t α t − 1 z ˉ t − 2 \sqrt{1-\alpha_{t}\alpha_{t-1}}\bar{\mathbf{z}}_{t-2} 1−αtαt−1zˉt−2。这里不同形式的 z \mathbf{z} z单纯起区分作用,本质上都属于标准正态分布 N ( 0 , I ) \mathcal{N}(0,\mathrm{I}) N(0,I)的不同采样。
以上就是前向过程大概内容,从前向过程得到的 x t \mathbf{x}_t xt将会作为标签,帮助网络学习如何从 x T \mathbf{x}_T xT中一步步去噪,最终得到 x 0 \mathbf{x}_0 x0。
Reverse Process
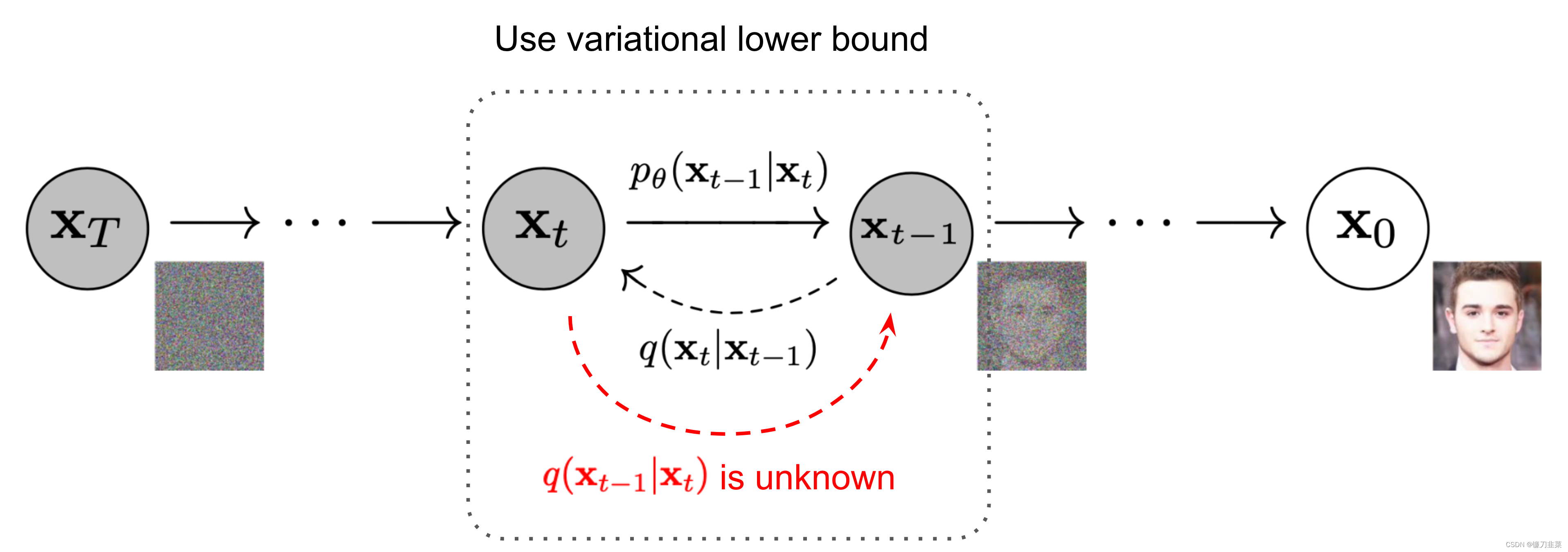
后向过程又称逆扩散过程。我们希望能够从一个噪声分布 x T \mathbf{x}_T xT中逐步去预测出来目标分布 x 0 \mathbf{x}_0 x0。后向过程仍然是一个马尔科夫链过程。根据我们输入的 x t \mathbf{x}_{t} xt去求 x t − 1 \mathbf{x}_{t-1} xt−1的分布,即求 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{t}) q(xt−1∣xt),直接对该公式求解比较困难,可以使用贝叶斯公式将其转化为我们已知的量,因为加噪过程 q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) q(xt∣xt−1)是已知的,因此有 q ( x t − 1 ∣ x t ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ) q ( x t ) q(\mathbf{x}_{t-1}|\mathbf{x}_{t})=\frac{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})\times q(\mathbf{x}_{t-1})}{q(\mathbf{x}_{t})} q(xt−1∣xt)=q(xt)q(xt∣xt−1)×q(xt−1)
现在就出现了一个问题,虽然 q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1}}) q(xt∣xt−1)我们是知道了,但是 q ( x t ) q(\mathbf{x}_{t}) q(xt)和 q ( x t − 1 ) q(\mathbf{x}_{t-1}) q(xt−1)我们不知道。需要特别注意的是,当 T T T足够大的时候,可以认为 q ( x T ) q(\mathbf{x}_T) q(xT)就是标准高斯噪声,这个是可以知道的;而由于 t t t并不知道是多少,可能是个很小的值,这种情况下 q ( x t ) q(\mathbf{x}_t) q(xt)中包含了大量的原始图像信息,因此 q ( x t ) q(\mathbf{x}_t) q(xt)是不知道的。
要想知道加了一定噪声的图像 q ( x t ) q(\mathbf{x}_t) q(xt)和 q ( x t − 1 ) q(\mathbf{x}_{t-1}) q(xt−1),自然就依赖于一个先决条件,没加噪声的图像 q ( x 0 ) q(\mathbf{x_0}) q(x0)。换句话说, q ( x t ∣ x 0 ) q(\mathbf{x}_t \mid \mathbf{x_0}) q(xt∣x0)和 q ( x t − 1 ∣ x 0 ) q(\mathbf{x}_{t-1} \mid \mathbf{x_0}) q(xt−1∣x0)是知道的,因此对式子 q ( x t − 1 ∣ x t ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ) q ( x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}}) = \frac{q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1}})×q(\mathbf{x}_{t-1})}{q({\mathbf{x}_t})} q(xt−1∣xt)=q(xt)q(xt∣xt−1)×q(xt−1)再加上一个条件 x 0 \mathbf{x_0} x0,得到一个多元条件分布,即: q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) × q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) = \frac{q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1} , \mathbf{x}_0})×q(\mathbf{x}_{t-1} \mid \mathbf{x}_0)}{q({\mathbf{x}_t} \mid \mathbf{x}_0)} q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)×q(xt−1∣x0)
其实上面这个式子还可以继续变一下。由于扩散过程是一个马尔可夫过程,因此 x t \mathbf{x}_t xt只和 x t − 1 \mathbf{x}_{t-1} xt−1有关,和 x 0 \mathbf{x}_0 x0无关,即 q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1} , \mathbf{x}_0}) = q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1}}) q(xt∣xt−1,x0)=q(xt∣xt−1),有:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) = \frac{q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1} })×q(\mathbf{x}_{t-1} \mid \mathbf{x}_0)}{q({\mathbf{x}_t} \mid \mathbf{x}_0)} q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1)×q(xt−1∣x0)
可以发现一个问题,在测试阶段, x 0 \mathbf{x}_0 x0本身是我们要求的东西,是未知的;因此上面这个式子只有在训练阶段 x 0 \mathrm{x}_0 x0已知的情况下才能运转起来。为了让测试阶段也能用,对上面式子进一步分析,也就是看一下能否将 x 0 \mathbf{x}_0 x0消除掉。如果可以消除,就不用陷入到这种要算 x 0 \mathbf{x}_0 x0还要必须知道 x 0 \mathbf{x}_0 x0的窘境。
由于正态分布 N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma^2) N(μ,σ2)的概率密度函数 p ( x ) = 1 2 π σ e − 1 2 ( x − μ σ ) 2 ∝ e x p ( − 1 2 ( x − μ σ ) 2 ) = e x p ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2}\propto exp({-\frac{1}{2}(\frac{x-\mu}{\sigma})^2})=exp(-\frac{1}{2}(\frac{1}{\sigma^2}x^2-\frac{2\mu}{\sigma^2}x+\frac{\mu^2}{\sigma^2})) p(x)=2πσ1e−21(σx−μ)2∝exp(−21(σx−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2)),故
- q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}\mid\mathbf{x}_{t-1}) q(xt∣xt−1)等价于 x t = α t x t − 1 + 1 − α t z t − 1 \mathbf{x}_t=\sqrt{\alpha_t}\mathbf{x}_{t-1}+\sqrt{1-\alpha_t}\mathbf{z}_{t-1} xt=αtxt−1+1−αtzt−1。写成概率分布的形式为 N ( x t ; α t x t − 1 , ( 1 − α t ) I ) \mathcal{N}(\mathbf{x}_{t};\sqrt{\alpha_{t}}\mathbf{x}_{t-1},(1-\alpha_{t})\mathbf{I}) N(xt;αtxt−1,(1−αt)I),进一步写成概率密度函数的形式,得到 q ( x t ∣ x t − 1 ) ∝ e x p ( − 1 2 ( x t − α t x t − 1 ) 2 1 − α t ) q(\mathbf{x}_{t}\mid\mathbf{x}_{t-1})\propto exp(-\frac{1}{2}\frac{(\mathbf{x}_{t}-\sqrt{\alpha_{t}}\mathbf{x}_{t-1})^2}{1-\alpha_{t}}) q(xt∣xt−1)∝exp(−211−αt(xt−αtxt−1)2)
- q ( x t − 1 ∣ x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_0) q(xt−1∣x0)等价于 x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 z ~ t − 1 \mathbf{x}_{t-1}=\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_{t-1}}\tilde{\mathbf{z}}_{t-1} xt−1=αˉt−1x0+1−αˉt−1z~t−1,利用重参数技巧,则 q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) ∝ e x p ( − 1 2 ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{0})=\mathcal{N}(\mathbf{x}_{t-1};\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0,(1-\bar{\alpha}_{t-1})\mathbf{I})\propto exp(-\frac{1}{2}\frac{(\mathbf{x}_{t-1}-\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}}) q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)∝exp(−211−αˉt−1(xt−1−αˉt−1x0)2)
- q ( x t ∣ x 0 ) q(\mathbf{x}_{t}\mid\mathbf{x}_0) q(xt∣x0)等价于 x t = α ˉ t x 0 + 1 − α ˉ t z ~ t \mathbf{x}_{t}=\sqrt{\bar{\alpha}_{t}}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_{t}}\tilde{\mathbf{z}}_{t} xt=αˉtx0+1−αˉtz~t,同样利用重参数技巧,则 q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) ∝ e x p ( − 1 2 ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) q(\mathbf{x}_{t}\mid\mathbf{x}_{0})=\mathcal{N}(\mathbf{x}_{t};\sqrt{\bar{\alpha}_{t}}\mathbf{x}_0,(1-\bar{\alpha}_{t})\mathbf{I})\propto exp(-\frac{1}{2}\frac{(\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}}\mathbf{x}_0)^2}{1-\bar{\alpha}_{t}}) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)∝exp(−211−αˉt(xt−αˉtx0)2)
这样一来对概率分布的运算就可以转化为指数运算。由于对指数进行乘除运算相当于对其系数的加减运算,也就是说,两个分布相乘,可以认为就是对其密度函数相加;两个分布相除,可以认为就是对其密度函数相减。因此, q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ∣ x 0 ) / q ( x t ∣ x 0 ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) = q(\mathbf{x}_{t} \mid {\mathbf{x}_{t-1} })×q(\mathbf{x}_{t-1} \mid \mathbf{x}_0) / q({\mathbf{x}_t} \mid \mathbf{x}_0) q(xt−1∣xt,x0)=q(xt∣xt−1)×q(xt−1∣x0)/q(xt∣x0),写成密度函数的形式,有:
q ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 [ ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ] ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) \propto \exp(-\frac{1}{2} [\frac{(\mathbf{x}_t - \sqrt{{\alpha}_{t}}\mathbf{x}_{t-1})^2}{{\beta}_{t}} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0)^2}{1 - \bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_{t} - \sqrt{\bar{\alpha}_t}\mathbf{x}_0)^2}{1 - \bar{\alpha}_t}]) q(xt−1∣xt,x0)∝exp(−21[βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2])
现在,要对上面这个式子进行进一步的整理,看看能不能得到什么有用的东西来。首先把括号里的平方展开来试一试:
q ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 [ x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − x t 2 − 2 α ˉ t x 0 x t + α ˉ t x 0 2 1 − α ˉ t ] ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) \propto \exp(-\frac{1}{2} [\frac{\mathbf{x}_t^2 - 2\sqrt{{\alpha}_{t}}\mathbf{x}_t\mathbf{x}_{t-1} +{{\alpha}_{t}}\mathbf{x}_{t-1}^2}{{\beta}_{t}} + \frac{\mathbf{x}_{t-1}^2 - 2\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0\mathbf{x}_{t-1} + \bar{\alpha}_{t-1}\mathbf{x}_0^2}{1 - \bar{\alpha}_{t-1}} - \frac{\mathbf{x}_{t}^2 -2\sqrt{\bar{\alpha}_t}\mathbf{x}_0\mathbf{x}_{t} + \bar{\alpha}_t\mathbf{x}_0^2}{1 - \bar{\alpha}_t}]) q(xt−1∣xt,x0)∝exp(−21[βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉtxt2−2αˉtx0xt+αˉtx02])
接下来的操作就是比较有技巧性的了。回到最初的问题,由于我们的目标是为了求于 x t − 1 \mathbf{x}_{t-1} xt−1有关的条件分布 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) q(xt−1∣xt,x0)。基于这一直觉,把上式的 x t − 1 \mathbf{x}_{t-1} xt−1给提取整理出来,得到:
q ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 [ ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 a ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ] ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) \propto \exp (-\frac{1}{2}[(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}) \mathbf{x}_{t-1}^2-(\frac{2 \sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t+\frac{2 \sqrt{\bar{a}_{t-1}}}{1-\bar{\alpha}_{t-1}} \mathbf{x}_0) \mathbf{x}_{t-1}+C(\mathbf{x}_t, \mathbf{x}_0)]) q(xt−1∣xt,x0)∝exp(−21[(βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12aˉt−1x0)xt−1+C(xt,x0)])
注意 C ( x t , x 0 ) C(\mathbf{x}_t, \mathbf{x}_0) C(xt,x0)是一个和 x t − 1 \mathbf{x}_{t-1} xt−1无关的部分,所以省略。由于 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{t},\mathbf{x}_0) q(xt−1∣xt,x0)服从于正态分布,所以只需要找到其均值和方差就能求出其分布。怎么求?根据高斯分布的概率密度函数定义和上述结果(配平方),我们可以得到分布 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{t},\mathbf{x}_0) q(xt−1∣xt,x0)的均值和方差。
现在,尝试将 x t − 1 \mathbf{x}_{t-1} xt−1的均值和方差给求出来。根据 N ( x ; μ , σ 2 ) ∝ exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \mathcal{N}(x; \mu, \sigma^2) \propto \exp(-\frac{1}{2}\left(\frac{1}{\sigma^2} x^2-\frac{2 \mu}{\sigma^2} x+\frac{\mu^2}{\sigma^2}\right)) N(x;μ,σ2)∝exp(−21(σ21x2−σ22μx+σ2μ2)),发现,方差 σ 2 \sigma^2 σ2就是 x 2 x^2 x2系数的倒数;而 x t − 1 2 \mathbf{x}^2_{t-1} xt−12的系数为 α t β t + 1 1 − α ˉ t − 1 \frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}} βtαt+1−αˉt−11,可以发现,其完全只由人工确定的超参数 α \alpha α和 β \beta β所确定,因此方差是已知的,即
β ~ t = 1 ( α t β t + 1 1 − α ˉ t − 1 ) = 1 ( α t − α t α ˉ t − 1 + β t ) β t ( 1 − α ˉ t − 1 ) \tilde {\beta }_t=\frac{1}{(\frac{\alpha _t}{\beta _t}+\frac{1}{1-\bar{\alpha }_{t-1}})}=\frac{1}{\frac{(\alpha _t-\alpha _t\bar{\alpha }_{t-1}+\beta _t)}{\beta_t(1-\bar{\alpha}_{t-1})}} β~t=(βtαt+1−αˉt−11)1=βt(1−αˉt−1)(αt−αtαˉt−1+βt)1根据前文的定义 α t ˉ = α 1 × . . . × α t \bar{\alpha_t} = \alpha_1 × ... × \alpha_t αtˉ=α1×...×αt ,可知 α t α ˉ t − 1 = α t ˉ \alpha _t\bar{\alpha }_{t-1}=\bar{\alpha_t} αtαˉt−1=αtˉ,而且 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, 所以有: β ~ t = 1 ( α t − α ˉ t + β t ) β t ( 1 − α ˉ t − 1 ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \tilde {\beta }_t=\frac{1}{\frac{(\alpha _t-\bar{\alpha }_{t}+\beta _t)}{\beta_t(1-\bar{\alpha}_{t-1})}}=\frac{1-\bar{\alpha }_{t-1}}{1-\bar{\alpha }_t}\cdot \beta _t β~t=βt(1−αˉt−1)(αt−αˉt+βt)1=1−αˉt1−αˉt−1⋅βt
而对于均值,其值与 x t − 1 \mathbf{x}_{t-1} xt−1的系数 2 α t β t x t + 2 a ˉ t − 1 1 − α ˉ t − 1 x 0 \frac{2 \sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t+\frac{2 \sqrt{\bar{a}_{t-1}}}{1-\bar{\alpha}_{t-1}} \mathbf{x}_0 βt2αtxt+1−αˉt−12aˉt−1x0 有关。可以发现,除了已知量 α \alpha α, β \beta β, x t \mathbf{x}_t xt,依然包含着我们想要消除的项 x 0 \mathbf{x}_0 x0。
但是对于 x 0 \mathbf{x}_0 x0,由于现在是处于后向过程, x 0 \mathbf{x}_0 x0是未知的,现在要想办法将 x 0 \mathbf{x}_0 x0用已知量进行替换。现在,将均值 μ \mu μ写成一个关于 x t \mathbf{x}_t xt与 x 0 \mathbf{x}_0 x0的函数,记做 μ ~ t ( x t , x 0 ) \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right) μ~t(xt,x0) 。将 1 σ 2 = ( α t β t + 1 1 − α ˉ t − 1 ) \frac{1}{\sigma^2}=(\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\bar{\alpha}_{t-1}}) σ21=(βtαt+1−αˉt−11) 代入 2 μ σ 2 = ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) \frac{2\mu}{\sigma^2}=(\frac{2\sqrt{\alpha_{t}}}{\beta_t}\mathbf{x}_t+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}\mathbf{x}_0) σ22μ=(βt2αtxt+1−αˉt−12αˉt−1x0)求解得到:
μ ~ t ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)=\frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_t} \mathbf{x}_t+\frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} \mathbf{x}_0 μ~t(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0做到这一步,我们已经把求解
q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}, \mathbf{x}_0}) q(xt−1∣xt,x0)这一复杂的问题,转化为怎么去求解该分布的均值 μ \mu μ的问题。而要求 μ \mu μ,就得想办法把复杂的 x 0 \mathbf{x}_0 x0给消掉或简化,有没有办法把 x 0 \mathbf{x}_0 x0化简成一个更容易看懂的形式呢?
回想一下,在前向过程中已经得到了 x 0 \mathbf{x}_0 x0和 x t \mathbf{x}_t xt的关系 x t = α ˉ t x 0 + 1 − α ˉ t z ~ t \mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\tilde {\mathbf{z}}_t xt=αˉtx0+1−αˉtz~t我们直接把 x 0 \mathbf{x}_0 x0给移动到等式左边,得到:
x 0 = 1 α ˉ t ( x t − 1 − α ˉ t z ~ t ) \mathbf{x}_0=\frac{1}{\sqrt{\bar{\alpha}_t}}\left(\mathbf{x}_t-\sqrt{1-\bar{\alpha}_t} \tilde{\mathbf{z}}_t\right) x0=αˉt1(xt−1−αˉtz~t)然后把 x 0 \mathbf{x}_0 x0带入到 μ ~ t ( x t , x 0 ) \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right) μ~t(xt,x0)中,最终得到 μ ~ t ( x t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t z ~ t ) \tilde{\mu}_t(\mathbf{x}_t)=\frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\tilde{\mathbf{z}}_t) μ~t(xt)=αt1(xt−1−αˉt1−αtz~t)这样我们就把 x 0 \mathbf{x}_0 x0消掉了,现在我们只要知道了 z ~ t \tilde{\mathbf{z}}_t z~t,就能将 μ ~ t \tilde{\mu}_t μ~t表示出来,进而得到 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{t},\mathbf{x}_0) q(xt−1∣xt,x0)的分布,将 x t − 1 \mathbf{x}_{t-1} xt−1采样出来,完成一次去噪过程。那么 z ~ t \tilde{\mathbf{z}}_t z~t怎么求呢?
问题是, z ~ t \tilde{\mathbf{z}}_t z~t 本身也是训练阶段,加噪过程中涉及到的东西。在测试阶段,对于一个全新采样的噪声,并不知道其是由一张图像与具体哪个高斯噪声给合成出来的(采样有无数种可能)。而且,从数学推导的角度, z ~ t \tilde{\mathbf{z}}_t z~t作为一个噪声,已经非常原子了,没法将其转换成更易获得的形式。
因此,这时就需要深度学习来解决了,神经网络擅长的就是这种人力解不出但是可以通过算法去逼近的东西。也就是说,设计一个网络 ϵ ( x t , t ) \boldsymbol{\epsilon}(\mathbf{x}_t, t) ϵ(xt,t),希望其能够预测 z ~ t \tilde{\mathbf{z}}_t z~t。
- 网络的输入为当前图像 x t \mathbf{x}_t xt与加噪步数 t t t。这里需要 t t t,可以理解为只有在知道 t t t的情况下才存在 x t \mathbf{x}_t xt的说法。
- 有了这个噪声 z ~ t \tilde{\mathbf{z}}_t z~t,就能求出高斯分布 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}}) q(xt−1∣xt)的均值 μ \mu μ与方差 σ \sigma σ(方差可以直接由超参数计算得到)。
- 有了分布 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_{t}}) q(xt−1∣xt),就可以在知道当前阶段图像 x t \mathbf{x}_{t} xt的情况下,采样得到去噪图像 x t − 1 \mathbf{x}_{t-1} xt−1了。
总结逆向过程:已知当前图像 x t \mathbf{x}_t xt,获得去噪一步后的图像 x t − 1 \mathbf{x}_{t-1} xt−1的过程,用概率的形式写作 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_t}) q(xt−1∣xt)。用贝叶斯公式对其处理后,发现,必须在知道 x 0 \mathbf{x}_0 x0的情况下才能求解 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_t}) q(xt−1∣xt),而 x 0 \mathbf{x}_0 x0本身是去噪的最终目的,因此看起来陷入了死循环。所以,尝试将 x 0 \mathbf{x}_0 x0进行变形消除,最后发现只要能够求到一个噪声 z ~ t \tilde{\mathbf{z}}_t z~t,就能够对 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid {\mathbf{x}_t}) q(xt−1∣xt)进行模拟,完成逆扩散过程。其实最后网络要预测的是一个噪声,这一结论也非常符合我们对扩散模型的直觉。因为 x t \mathbf{x}_{t} xt本身是加噪声得到的,那么如果知道加的噪声是什么,自然就能把这一过程反过来。
至此,前向过程和后向过程已经推导结束了,如果想了解论文中交叉熵Loss的推导,可参考文章的解释,公式较复杂,如果不感兴趣,直接跳过即可。
DDPM算法伪代码

训练部分
对于每次迭代:
- 第二行:随机选择一张图像。从数学的角度讲,叫做从真实图像分布 q ( x 0 ) q(\mathbf{x_0}) q(x0)中采样得到一个样本 x 0 \mathbf{x_0} x0。
- 第三行:随机选择一个前向步数(加噪声次数) t t t。这个 t t t是从最小步数 1 1 1和最大步数 T T T中随机抽出来的。从数学的角度讲,叫从均匀分布 1 ∼ T 1 \sim T 1∼T中采样。
- 第四行:随机生成一个标准高斯噪声 ϵ \epsilon ϵ。从数学的角度讲,叫做从标准高斯分布 N ( 0 , I ) \mathcal{N}(0, \mathbf{I}) N(0,I)中采样。
- 第五行: 计算训练时损失(也就是"进行梯度下降步骤")。 ∣ ∣ a − b ∣ ∣ 2 ||a - b||^2 ∣∣a−b∣∣2的形式其实就是最常见的均方误差损失函数(Mean Square Loss)。既然是损失函数,肯定就有一个真值和一个网络的预测值。这里的真值就是实时生成的随机噪声 ϵ \epsilon ϵ,而网络预测值则是:
ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) \boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right) ϵθ(αˉtx0+1−αˉtϵ,t)其中的
α ˉ t x 0 + 1 − α ˉ t ϵ \sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon} αˉtx0+1−αˉtϵ是什么含义呢?回顾上文中提到的公式:
x t = α ˉ t x 0 + 1 − α ˉ t z ~ t \mathbf{x_t} = \sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \tilde{\mathbf{z}}_t xt=αˉtx0+1−αˉtz~t而这个 z ~ t \tilde{\mathbf{z}}_t z~t和 ϵ \epsilon ϵ同样都是标准高斯噪声。也就是说, α ˉ t x 0 + 1 − α ˉ t ϵ \sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon} αˉtx0+1−αˉtϵ其实就是 x t \mathbf{x_t} xt。至此,损失函数变成了这样:
∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 ||\epsilon - \boldsymbol{\epsilon}_\theta\left(\mathbf{x_t}, t\right)||^2 ∣∣ϵ−ϵθ(xt,t)∣∣2
再次对第五行的理解就是,对于第二行,第三行拿到的原始图像 x 0 \mathbf{x_0} x0和加噪次数 t t t,利用前向过程能够直接推出加噪结果 x t \mathbf{x_t} xt出来。现在有一个网络 ϵ θ \epsilon_\theta ϵθ,我们希望其在输入加噪结果 x t \mathbf{x_t} xt和加噪次数 t t t后,能够预测到一个「合适的」标准高斯噪声,也就是未知的 z ~ t \tilde{\mathbf{z}}_t z~t。
总结一下训练过程就是给定 x 0 \mathbf{x}_0 x0和随机噪声 ϵ \epsilon ϵ,然后生成一个扩散(加噪)次数 t t t,进行 t t t次扩散过程得到 x t \mathbf{x}_t xt,然后通过一个网络 ϵ θ \epsilon_{\theta} ϵθ来预测一个合适的噪声,也就是 z ~ t \tilde{\mathbf{z}}_t z~t。
但是问题来了,网络为什么要去预测一个标准高斯噪声呢?直观来讲,这种东西直接从标准高斯分布中直接采样就可以了,为什么还要单独设计一个网络去学。要想理解这一点,将损失函数的表达式重新展开来,把 ϵ \epsilon ϵ替换成熟悉的 z ~ t \tilde{\mathbf{z}}_t z~t;此外,由于训练阶段的 x t \mathbf{x}_t xt是由 x 0 \mathbf{x}_0 x0和 t t t直接求出来的,因此也进行相应的替换,最终把:
∣ ∣ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∣ ∣ 2 ||\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)||^2 ∣∣ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∣∣2重新改写为:
∣ ∣ z ~ t − ϵ θ ( x 0 , t , z ~ t ) ∣ ∣ 2 ||\tilde{\mathbf{z}}_t - \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_0, t, \tilde{\mathbf{z}}_t\right)||^2 ∣∣z~t−ϵθ(x0,t,z~t)∣∣2这么写有什么好处呢?可以发现一个有趣的事实,在训练阶段,网络去猜测这个 z ~ t \tilde{\mathbf{z}}_t z~t并不是凭空的,而是事实上已经将 z ~ t \tilde{\mathbf{z}}_t z~t和 x 0 \mathbf{x}_0 x0给混在了一起,得到了一个混沌,然后让网络去从混沌中把 z ~ t \tilde{\mathbf{z}}_t z~t给重新"捞出来"。
举个形象的比喻就是,与其说 ϵ θ \boldsymbol{\epsilon}_\theta ϵθ是一个所谓的什么去噪网络,不如说是「沙里淘金」:
图像是金,噪声是沙子。在训练阶段,把金和沙子混在一起(加噪),让网络学习怎么去把沙子从混合物中给重新分离出来(预测噪声)。至于为什么不是直接把金给拿出来…这是前面的推导决定的,求噪声要比求图像远远更容易;换句话说,如果是直接淘金,那么网络可能淘个成百上千次,准确率仍然是0,因此很难训练,所以才是淘沙。
从这里发现,网络学到的如何淘沙子的知识,是来源于沙子和金的混合物的,受原有的金(图像)的影响。这就导致,网络在猫图像上训练的去噪网络,对于一个新噪声而言去噪也只能得到各种猫,因为在训练阶段真实分布的信息被嵌入了网络中。
而在测试阶段,相当于仍是有一堆混在一起的金和沙子,这个时候没有标准答案,网络是凭借着自己的训练阶段学到的知识把沙子给淘出来,进而「间接」完成淘金的过程。
采样部分
- 第一行:从标准高斯分布中采样得到一个噪声。由于原始图像 x 0 \mathbf{x}_0 x0在加 t t t次噪声后得到的东西也是一个标准高斯噪声,因此这里采样的得到的结果记为 x T \mathbf{x}_T xT。
- 第二行:进行 T T T次逆扩散过程,将图像从高斯噪声 x T \mathbf{x}_T xT中恢复出来。对于每次逆扩散过程:
- 第三行:随机采样一个标准高斯噪声 z \mathbf{z} z。注意在最后一步的时候就不采样了, z = 0 \mathbf{z} = 0 z=0,这算是一个trick…不管这一技巧并不影响对整体的理解。
- 第四行:通过公式计算得到去噪一次的结果: x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z \mathbf{x}_{t-1}=\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t, t\right)\right)+\sigma_t \mathbf{z} xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz这个式子的理解依旧是参考前置知识中的「重参数化技巧」。从分布的角度,比方说,从 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2)中采样得到一个 ϵ \epsilon ϵ,写成数学表达式就是:
ϵ = μ + z ⋅ σ \epsilon= \mu + \mathbf{z} \cdot \sigma ϵ=μ+z⋅σ其中 z \mathbf{z} z为标准高斯噪声。根据上文中的结论,我们知道高斯分布 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid \mathbf{x}_t) q(xt−1∣xt)的均值 μ t \mu_{t} μt为 1 α t ( x t − 1 − α t 1 − α ˉ t z ~ t ) \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1 - \alpha_t}{\sqrt{1-\bar{\alpha}_t}} \tilde{\mathbf{z}}_t\right) αt1(xt−1−αˉt1−αtz~t),再加上方差 σ t 2 \sigma_t^2 σt2 (可以由超参数 α \alpha α和 β \beta β直接求得),有:
q ( x t − 1 ∣ x t ) ∼ N ( 1 α t ( x t − 1 − α t 1 − α ˉ t z ~ t , σ t 2 ) q(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}) \sim \mathcal{N}(\frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \tilde{\mathbf{z}}_t, \sigma_t^2) q(xt−1∣xt)∼N(αt1(xt−1−αˉt1−αtz~t,σt2)而 z ~ t \tilde{\mathbf{z}}_t z~t,其实就是网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) ϵθ(xt,t)能够预测的东西,直接替换掉就行。
从分布 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}) q(xt−1∣xt)中采样得到 x t − 1 \mathbf{x}_{t-1} xt−1,有:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z \mathbf{x}_{t-1}=\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t, t\right)\right)+\sigma_t \mathbf{z} xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz
总结一下
DDPM对Deep Unsupervised Learning using Nonequilibrium Thermodynamics文中提出的模型(下文称扩散模型)改进了两点
- 第一点,扩散模型在后向过程中,是由 x t \mathbf{x}_t xt预测 x t − 1 \mathbf{x}_{t-1} xt−1,也即直接预测图像,而DDPM是预测在前向过程中,我们从 x t − 1 \mathbf{x}_{t-1} xt−1扩散到 x t \mathbf{x}_t xt所加的噪声,有点类似Resnet,即如何将噪声从噪声-图像混合物中分离出来,从而将问题简化。
- 第二点,如果要预测一个正态分布,只需要学它的均值和方差即可,而DDPM将方差视作常数,只需学习均值就能得到分布,最后的效果也不错,并且降低了模型优化的难度
简单来说,一张图像哪怕加很多很多次标准高斯噪声,最后得到的纯标准高斯噪声中也包含少许的原始图像信息。也就是说,哪怕随便拿一个并非由图像加噪得到的真实高斯噪声出来,也可以视其为从某张真实世界并不存在的逼真图像加噪而来。如果能想办法推导出加的噪声是什么样的,那么自然就能完成去噪过程。但是这个"推导"目前无法由数学实现,只能通过训练网络来进行近似预测这个噪声。而且由于一步到位的去噪难度极高,因此要拆成很多步以便网络训练。需要注意的是,网络进行噪声预测并不是完全无依据的,而是去学会如何把噪声从噪声-图像混合物中给分离出来。
参考链接
- The Annotated Diffusion Model
- 带你深入理解扩散模型DDPM
- 扩散模型全新课程:扩散模型从0到1实现!
- Denoising Diffusion Probabilitistic Models
- 《Diffusion Models Beat GANs on Image Synthesis》阅读笔记
- How Diffusion Models Work
- DDPM交叉熵损失函数推导
- DDPM(Denoising Diffusion Probabilistic Models)扩散模型简述
- What are Diffusion Models?
- 由浅入深了解Diffusion Model
- 什么是Diffusion模型?
- Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读
- Denoising Diffusion Probabilistic Model, in Pytorch