文章目录
- 1 说明
- 2 为什么要使用Stream API
- 3 什么是Stream
- Stream的操作三个步骤
- 创建Stream实例
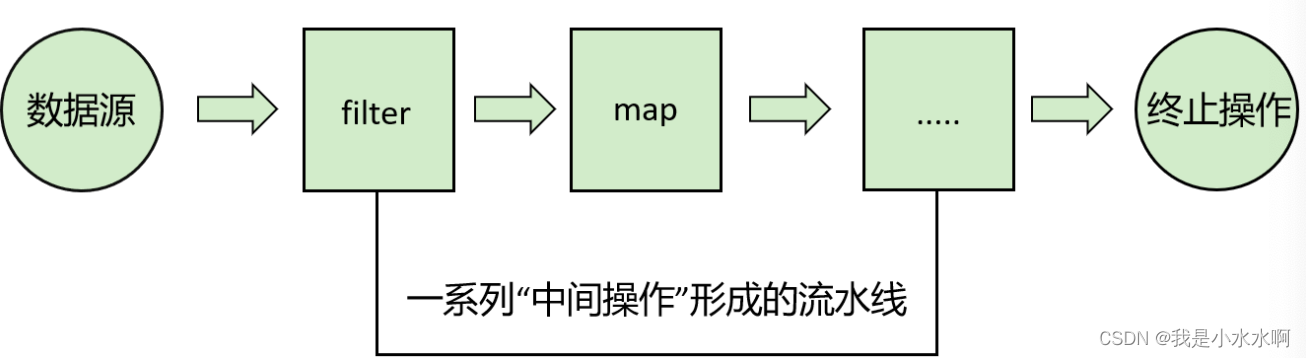
- 一系列中间操作
- 终止操作
1 说明
- Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一个则是 Stream API。
- Stream API ( java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库
最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。 - Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 **使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。**也可以使用 Stream API 来并行执行操作。简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
2 为什么要使用Stream API
实际开发中,项目中多数数据源都来自于MySQL、Oracle等。但现在数据源可以更多了,有MongDB,Radis等,而这些NoSQL的数据就需要Java层面去处理。
3 什么是Stream
Stream 是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
Stream 和 Collection 集合的区别:**Collection 是一种静态的内存数据结构,讲的是数据,而 Stream 是有关计算的,讲的是计算。**前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。即一旦执行终止操作,就执行中间操作链,并产生结果。
④ Stream一旦执行了终止操作,就不能再调用其它中间操作或终止操作了。
Stream的操作三个步骤
1- 创建 Stream
一个数据源(如:集合、数组),获取一个流
2- 中间操作
每次处理都会返回一个持有结果的新Stream,即中间操作的方法返回值仍然是Stream类型的对象。因此中间操作可以是个操作链,可对数据源的数据进行n次处理,但是在终结操作前,并不会真正执行。
3- 终止操作(终端操作)
终止操作的方法返回值类型就不再是Stream了,因此一旦执行终止操作,就结束整个Stream操作了。一旦执行终止操作,就执行中间操作链,最终产生结果并结束Stream。
创建Stream实例
方式一:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
-
default Stream stream() : 返回一个顺序流
-
default Stream parallelStream() : 返回一个并行流
@Test
public void test01(){List<Integer> list = Arrays.asList(1,2,3,4,5);//JDK1.8中,Collection系列集合增加了方法Stream<Integer> stream = list.stream();
}
方式二:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- static <T> Stream<T> stream(T[] array): 返回一个流
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
@Test
public void test02(){String[] arr = {"hello","world"};Stream<String> stream = Arrays.stream(arr);
}@Test
public void test03(){int[] arr = {1,2,3,4,5};IntStream stream = Arrays.stream(arr);
}
方式三:通过Stream的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数。
- public static<T> Stream<T> of(T... values) : 返回一个流
@Test
public void test04(){Stream<Integer> stream = Stream.of(1,2,3,4,5);stream.forEach(System.out::println);
}
方式四:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
- 迭代public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) - 生成public static<T> Stream<T> generate(Supplier<T> s)
// 方式四:创建无限流
@Test
public void test05() {// 迭代// public static<T> Stream<T> iterate(final T seed, final// UnaryOperator<T> f)Stream<Integer> stream = Stream.iterate(0, x -> x + 2);stream.limit(10).forEach(System.out::println);// 生成// public static<T> Stream<T> generate(Supplier<T> s)Stream<Double> stream1 = Stream.generate(Math::random);stream1.limit(10).forEach(System.out::println);
}一系列中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
1-筛选与切片
| 方 法 | 描 述 |
|---|---|
| filter(Predicatep) | 接收 Lambda , 从流中排除某些元素 |
| distinct() | 筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。 若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
2-映 射
| 方法 | 描述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
3-排序
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
代码举例:
import org.junit.Test;
import java.util.Arrays;
import java.util.stream.Stream;public class StreamMiddleOperate {@Testpublic void test01(){//1、创建StreamStream<Integer> stream = Stream.of(1,2,3,4,5,6);//2、加工处理//过滤:filter(Predicate p)//把里面的偶数拿出来/** filter(Predicate p)* Predicate是函数式接口,抽象方法:boolean test(T t)*/stream = stream.filter(t -> t%2==0);//3、终结操作:例如:遍历stream.forEach(System.out::println);}@Testpublic void test02(){Stream.of(1,2,3,4,5,6).filter(t -> t%2==0).forEach(System.out::println);}@Testpublic void test03(){Stream.of(1,2,3,4,5,6,2,2,3,3,4,4,5).distinct().forEach(System.out::println);}@Testpublic void test04(){Stream.of(1,2,3,4,5,6,2,2,3,3,4,4,5).limit(3).forEach(System.out::println);}@Testpublic void test05(){Stream.of(1,2,2,3,3,4,4,5,2,3,4,5,6,7).distinct() //(1,2,3,4,5,6,7).filter(t -> t%2!=0) //(1,3,5,7).limit(3).forEach(System.out::println);}@Testpublic void test06(){Stream.of(1,2,3,4,5,6,2,2,3,3,4,4,5).skip(5).forEach(System.out::println);}@Testpublic void test07(){Stream.of(1,2,3,4,5,6,2,2,3,3,4,4,5).skip(5).distinct().filter(t -> t%3==0).forEach(System.out::println);}@Testpublic void test08(){long count = Stream.of(1,2,3,4,5,6,2,2,3,3,4,4,5).distinct().peek(System.out::println) //Consumer接口的抽象方法 void accept(T t).count();System.out.println("count="+count);}@Testpublic void test09(){//希望能够找出前三个最大值,前三名最大的,不重复Stream.of(11,2,39,4,54,6,2,22,3,3,4,54,54).distinct().sorted((t1,t2) -> -Integer.compare(t1, t2))//Comparator接口 int compare(T t1, T t2).limit(3).forEach(System.out::println);}@Testpublic void test10(){Stream.of(1,2,3,4,5).map(t -> t+=1)//Function<T,R>接口抽象方法 R apply(T t).forEach(System.out::println);}@Testpublic void test11(){String[] arr = {"hello","world","java"};Arrays.stream(arr).map(t->t.toUpperCase()).forEach(System.out::println);}@Testpublic void test12(){String[] arr = {"hello","world","java"};Arrays.stream(arr).flatMap(t -> Stream.of(t.split("|")))//Function<T,R>接口抽象方法 R apply(T t) 现在的R是一个Stream.forEach(System.out::println);}
}终止操作
-
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。
-
流进行了终止操作后,不能再次使用。
1-匹配与查找
| 方法 | 描述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| **anyMatch(Predicate p) ** | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。 相反,Stream API 使用内部迭代——它帮你把迭代做了) |
2-归约
| 方法 | 描述 |
|---|---|
| reduce(T identity, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional |
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
3-收集
| 方 法 | 描 述 |
|---|---|
| collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的实现, 用于给Stream中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toList | Collector<T, ?, List> | 把流中元素收集到List |
List<Employee> emps= list.stream().collect(Collectors.toList());
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toSet | Collector<T, ?, Set> | 把流中元素收集到Set |
Set<Employee> emps= list.stream().collect(Collectors.toSet());
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toCollection | Collector<T, ?, C> | 把流中元素收集到创建的集合 |
Collection<Employee> emps =list.stream().collect(Collectors.toCollection(ArrayList::new));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| counting | Collector<T, ?, Long> | 计算流中元素的个数 |
long count = list.stream().collect(Collectors.counting());
| 方法 | 返回类型 | 作用 |
|---|---|---|
| summingInt | Collector<T, ?, Integer> | 对流中元素的整数属性求和 |
int total=list.stream().collect(Collectors.summingInt(Employee::getSalary));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| averagingInt | Collector<T, ?, Double> | 计算流中元素Integer属性的平均值 |
double avg = list.stream().collect(Collectors.averagingInt(Employee::getSalary));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| summarizingInt | Collector<T, ?, IntSummaryStatistics> | 收集流中Integer属性的统计值。如:平均值 |
int SummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| joining | Collector<CharSequence, ?, String> | 连接流中每个字符串 |
String str= list.stream().map(Employee::getName).collect(Collectors.joining());
| 方法 | 返回类型 | 作用 |
|---|---|---|
| maxBy | Collector<T, ?, Optional> | 根据比较器选择最大值 |
Optional<Emp>max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| minBy | Collector<T, ?, Optional> | 根据比较器选择最小值 |
Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| reducing | Collector<T, ?, Optional> | 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 |
int total=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| collectingAndThen | Collector<T,A,RR> | 包裹另一个收集器,对其结果转换函数 |
int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| groupingBy | Collector<T, ?, Map<K, List>> | 根据某属性值对流分组,属性为K,结果为V |
Map<Emp.Status, List<Emp>> map= list.stream().collect(Collectors.groupingBy(Employee::getStatus));
| 方法 | 返回类型 | 作用 |
|---|---|---|
| partitioningBy | Collector<T, ?, Map<Boolean, List>> | 根据true或false进行分区 |
Map<Boolean,List<Emp>> vd = list.stream().collect(Collectors.partitioningBy(Employee::getManage));
举例:
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;import org.junit.Test;public class StreamEndding {@Testpublic void test01(){Stream.of(1,2,3,4,5).forEach(System.out::println);}@Testpublic void test02(){long count = Stream.of(1,2,3,4,5).count();System.out.println("count = " + count);}@Testpublic void test03(){boolean result = Stream.of(1,3,5,7,9).allMatch(t -> t%2!=0);System.out.println(result);} // 是否全部都不是偶数@Testpublic void test04(){boolean result = Stream.of(1,3,5,7,9).anyMatch(t -> t%2==0);System.out.println(result);} // 其中有一个是偶数 ---》false@Testpublic void test05(){Optional<Integer> opt = Stream.of(1,3,5,7,9).findFirst();System.out.println(opt);}@Testpublic void test06(){Optional<Integer> opt = Stream.of(1,2,3,4,5,7,9).filter(t -> t%3==0).findFirst();System.out.println(opt);}@Testpublic void test07(){Optional<Integer> opt = Stream.of(1,2,4,5,7,8).filter(t -> t%3==0).findFirst();System.out.println(opt);}@Testpublic void test08(){Optional<Integer> max = Stream.of(1,2,4,5,7,8).max((t1,t2) -> Integer.compare(t1, t2));System.out.println(max);}@Testpublic void test09(){Integer reduce = Stream.of(1,2,4,5,7,8).reduce(0, (t1,t2) -> t1+t2);//BinaryOperator接口 T apply(T t1, T t2)System.out.println(reduce);}@Testpublic void test10(){Optional<Integer> max = Stream.of(1,2,4,5,7,8).reduce((t1,t2) -> t1>t2?t1:t2);//BinaryOperator接口 T apply(T t1, T t2)System.out.println(max);}@Testpublic void test11(){List<Integer> list = Stream.of(1,2,4,5,7,8).filter(t -> t%2==0).collect(Collectors.toList());System.out.println(list);}
}