论文链接:https://papers.nips.cc/paper_files/paper/2022/file/4ec0b6648bdf487a2f1c815924339022-Paper-Conference.pdf
源码链接:https://github.com/chenyd7/PEFD
文章目录
- 前言
- 一、论文核心
- 二、论文摘要
- 三、论文内容
- 四、集成投影方法
- 五、源码环境安装
- 六、源码修改
- 1、源码问题
- 2、修改代码
- 3、代码执行效果
- 七、代码流程解读
- 八.projector代码解读
- 1、模型特征提取代码解读
- 2、projector代码解读
- 特征返回值
- projector结构
- 投影loss计算
前言
昨日看到蒸馏一篇蒸馏论文PEFD文章,论文提到特征蒸馏方法,本着好奇与疑问,于是我读了,有一些启示。为此,我将记录于此,改论文重点提出投影projector帮助学生模型特征空间转换,说是缓解overvit教师,我个人认为有点借助projector作为缓冲(像辅助教师)。既然读了,我将写下论文主要内容,并结合论文代码深入解读。
一、论文核心
论文背景:narrow the gap between the student and teacher’s feature spaces.various feature distillation methods have been developed by designing more powerful objective functions and determining more effective links between the layers of the
student and the teacher。缩小teacher与student特征空间gap,研究者更多聚焦目标函数(loss)或在teacher和student的layers中有效links。
解决问题:distillation model without a projector, the student network tends to overfit the teacher’s feature distributions despite having different architecture and weights initialization.缓解student模型过拟合teacher模型。
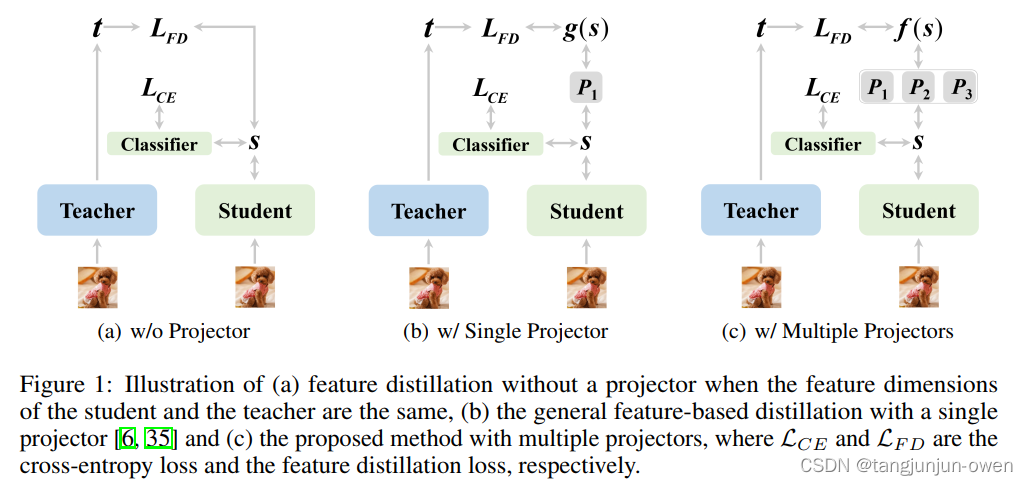
论文方法:通过特征投影projector解决,且在student模型上使用,从一个projector增加到三个projector,结构如下图。
注:projector可理解为投影projector-->代码使用nn.Linear方法。
二、论文摘要
先前特征蒸馏方法主要聚焦在loss函数设计和distilled layers的links,很少研究会使用projector。我们以往经验认为增加projector的特征蒸馏方法是有效的,然后我们提出投projector。我们发现即使学生和教师feature dimensions相同,基于学生with projector是有效的。我们也证明了without projector在不同学生网络架构和赋予不同初始化权重,学生网络tends to overfit教师网络,得到较差deep feature质量,影响分类结果。with projector能让学生网络更好聚焦特征extraction,能更好利用教师guidance。我们提出an ensenble of projectors进一步改善学生网络特征提取质量。实验表明,一系列teacher-student组合实验证明我们提出方法的有效性。
已有的知识蒸馏方法可以大致分为基于logit,基于特征和基于相似度的方法。根据之前研究,与其他两种算法相比,基于特征的方法通常可以提取出更好的学生网络。
三、论文内容
本文推测,模仿教师特征的过程为学生网络训练提供了更清晰的优化方向。尽管特征提取具有更好的性能,但缩小学生模型和教师模型特征空间之间差距仍然具有挑战性。为了提升学生模型特征学习能力,已经开发了各种通过设计更强大的目标函数并确定学生和教师模型层之间更有效的的连接的特征蒸馏方法。
本文发现,从学生模型到教师模型特征空间的特征投影过程在特征提取重起着关键作用,可以重新设计以提高性能。由于学生网络的特征维度并不总是有教师模型特征尺度相同,因此通常需要投影特征映射到公共空间重进行匹配。即使学生和教师网络特征维度相同,在学生网络上安装投影也能提高蒸馏性能。本文假设当最小化学生和教师模型特征差异是,添加投影进行蒸馏有助于缓解过拟合问题。此外受到添加投影进行特征提取有效性启发,提出了一个投影集合以进一步改进。直觉是具有不同初始化的投影会生成不同转换特征。因此根据集成学习理论,使用多个投影器有助于提高学生网络泛化能力。
为了匹配教师与学生模型维度,需要一个投影器projector转换学生或教师特征。本文实验中发现,将投影器强加于教师效果较差,因为来自教师原始且信息量更大的特征分布会被破坏。因此在提出蒸馏框架中,训练时投影器添加在学生模型,蒸馏训练后在被移除。
作为多任务学习的特征蒸馏,近期方法,SRRL和CID组合基于特征和基于logit损失提升性能。由于蒸馏方法对超参数和教师-学生组合敏感,额外的目标将增加系数调整的训练成本。为了缓解这个问题,本文特征蒸馏简单使用方向对齐(Direction Alignment, DA)损失:
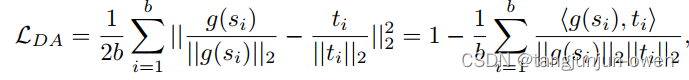
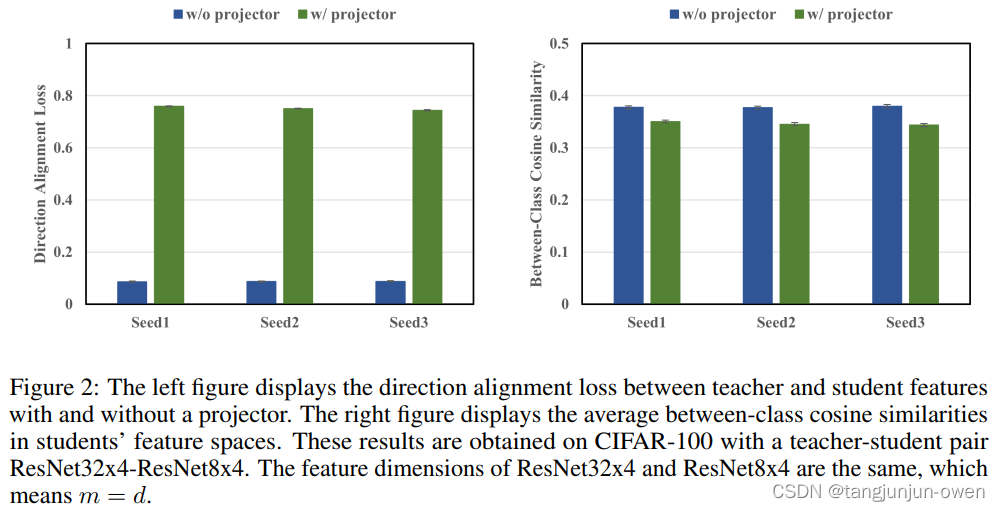
本文假设没有投影器的学生网络训练过程可以被视作为在相同特征空间的多任务学习(蒸馏和分类任务)。此时学生特征倾向于过拟合教师特征,从而降低分类判别力。这里用两种测量方法验证这一假设。一个是测量学生和教师特征的差异:
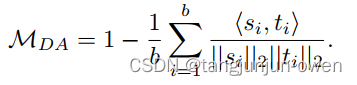
显然,由于学生特征会直接与教师特征交互,因此在不同种子中,没有投影器的学生MDA性能显著差于有投影器的学生模型。然而通过研究学生特征空间中类别间余弦相似度,发现在没有投影器的情况下提取学生特征判别力较小。类间余弦相似度:
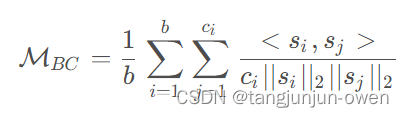
下图中可知,与没有投影器的学生网络相比,有投影器的学生网络产生了更多的判别特征。图中所示,在没有投影器情况下,学生模型往往会过度拟合在教师的特征空间。由于分类和蒸馏在同一个特征空间中执行。由于分类和蒸馏任务是在同一个特征空间中执行,因此生成的特征对于分类来说不太可区分。
四、集成投影方法
上述分析表明,投影器可以提高学生模型蒸馏性能。受此启发,提出了集成投影器进行进一步改进。使用多个投影器有两个动机。首先,具有不同初始化的投影器提供不同转换特征,这有利于学生的可推广性。其次,由于使用ReLU函数使投影器能够执行非线性特征提取时投影的学生特征可能包含0,而教师模型由于CNN中常用的平均池化层操作不太可能为0。也就是说,在单个投影层情况下,教师和学生模型之间特征分布差距很大,因此使用集成学习是训练误差和泛化能力之间实现良好平衡的自然方式。
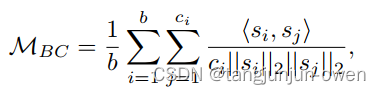
五、源码环境安装
github上下载源码,直接安装环境对应的torch版本。
我缺少tensorflow,直接使用:
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
我是windows10使用安装,环境即可完成。
六、源码修改
1、源码问题
我遇到问题是源码缺少self.train_data与self.train_labels,如下:
img, target = self.train_data[index], self.train_labels[index]
代码在cifar100.py第34行左右,其部分代码如下:
class CIFAR100Instance(datasets.CIFAR100):"""CIFAR100Instance Dataset."""def __getitem__(self, index):if self.train:img, target = self.train_data[index], self.train_labels[index]else:img, target = self.test_data[index], self.test_labels[index]# doing this so that it is consistent with all other datasets# to return a PIL Image
实际是cifar图片加载问题,或许是我缺少环境,若你们能跑通,请直接忽略,否则我们进行下一步修改。
2、修改代码
尽然是图片加载除了问题,我们将修改图片加载代码即可,我采用torchvision方法加载cifar数据,修改train_student.py第170含左右,
源代码如下:
if opt.dataset == 'cifar100':train_loader, val_loader, n_data = get_cifar100_dataloaders(batch_size=opt.batch_size,num_workers=opt.num_workers,is_instance=True)n_cls = 100
注释或删除上面数据加载代码,修改后代码如下:
if opt.dataset == 'cifar100':import torchvision.datasetsfrom torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR100(root="./data", train=True,transform=torchvision.transforms.ToTensor(),download=True)train_loader = DataLoader(train_data, batch_size=64)val_loader=train_loader# train_loader, val_loader, n_data = get_cifar100_dataloaders(batch_size=opt.batch_size,# num_workers=opt.num_workers,# is_instance=True)n_cls = 100
我们修改了数据加载部分,自然也得调整一下模型加载数据格式,位置在loops.py第90行:
源代码如下:
end = time.time()for idx, data in enumerate(train_loader):input, target, index = datadata_time.update(time.time() - end)
注释或删除上面数据加载代码,修改后代码如下:
end = time.time()for idx, data in enumerate(train_loader):input, target = data# input, target, index = datadata_time.update(time.time() - end)
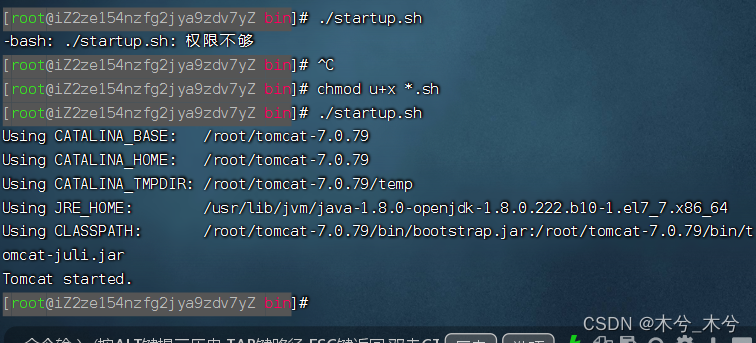
3、代码执行效果
记得修改如下参数:
parser.add_argument('--path_t', type=str, default='./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth', help='teacher model snapshot')# distillationparser.add_argument('--distill', type=str, default='ours', choices=['kd', 'ours'])parser.add_argument('--trial', type=str, default='1', help='trial id')parser.add_argument('-r', '--gamma', type=float, default=1, help='weight for classification')parser.add_argument('-a', '--alpha', type=float, default=0, help='weight balance for KD')parser.add_argument('-b', '--beta', type=float, default=25, help='weight balance for other losses')
按照以上方法,执行代码效果如下:
七、代码流程解读
代码流程解读,直接告知数据加载一块格式,若出现问题,只要将数据格式改成我给的格式,也可以是模型运行。
按照这样数据输入模型,即可运行。
八.projector代码解读
1、模型特征提取代码解读
我以源码resnet的backbone为列解读特征提取。
def forward(self, x, is_feat=False, preact=False):x = self.conv1(x)x = self.bn1(x)x = self.relu(x) # 32x32f0 = xx, f1_pre = self.layer1(x) # 32x32 x最后输出进行了relu而f1_pre没有进行reluf1 = xx, f2_pre = self.layer2(x) # 16x16f2 = xx, f3_pre = self.layer3(x) # 8x8f3 = xx = self.avgpool(x)x = x.view(x.size(0), -1)f4 = xx = self.fc(x)if is_feat:if preact:return [f0, f1_pre, f2_pre, f3_pre, f4], xelse:return [f0, f1, f2, f3, f4], xelse:return x
以上代码可知,特征提取一种是有激活函数后每层特征,返回值为return [f0, f1, f2, f3, f4], x,另一种为五激活函数前特征提取,返回值为return [f0, f1_pre, f2_pre, f3_pre, f4], x。
2、projector代码解读
我以源码resnet的backbone为列解读特征提取。
首先教师模型与学生模型特征返回值代码解读。
特征返回值
preact = Falsefeat_s, logit_s = model_s(input, is_feat=True, preact=preact)with torch.no_grad():feat_t, logit_t = model_t(input, is_feat=True, preact=preact)feat_t = [f.detach() for f in feat_t]
以上教师返回feat_s=[f0, f1_pre, f2_pre, f3_pre, f4], logit_s=x,学生网络与教师类似。
projector结构
projector实际是nn.linear结构,其代码如下:
class Reg(nn.Module):"""Linear regressor"""def __init__(self, dim_in=1024, dim_out=1024):super(Reg, self).__init__()self.linear = nn.Linear(dim_in, dim_out)def forward(self, x):x = self.linear(x)return x
投影loss计算
我们解释一下,以下loss计算公式,若为原来KD蒸馏方式为只需将opt.alpha赋权重值,opt.beta赋值为0可实现原有蒸馏方式;若使用本论文蒸馏方式,需将opt.alpha赋值为0,opt.beta赋值;
loss = opt.gamma * loss_cls + opt.alpha * loss_div + opt.beta * loss_kd
论文多个投影方法代码如下:
# cls + kl divloss_cls = criterion_cls(logit_s, target)loss_div = criterion_div(logit_s, logit_t)# other kd beyond KL divergenceif opt.distill == 'kd':loss_kd = 0 elif opt.distill == 'ours': # 1 - cos(theta_i): average different projections f_t = feat_t[-1]relu = torch.nn.ReLU() # linear Regressf_s1 = feat_s[-1] # 64 512f_s1 = module_list[1](f_s1) # 64 256f_s1 = relu(f_s1) # 64 256f_s2 = feat_s[-1] # 64 512f_s2 = module_list[2](f_s2) f_s2 = relu(f_s2) # 64 256f_s3 = feat_s[-1]f_s3 = module_list[3](f_s3) f_s3 = relu(f_s3)f_s = (f_s1 + f_s2 + f_s3) / 3 # 64 256bsz = f_s.shape[0]bdm = f_s.shape[1]# inner product (normalize first and inner product)normft = f_t.pow(2).sum(1, keepdim=True).pow(1. / 2)outft = f_t.div(normft) normfs = f_s.pow(2).sum(1, keepdim=True).pow(1. / 2)outfs = f_s.div(normfs)cos_theta = (outft * outfs).sum(1, keepdim=True)G_diff = 1 - cos_thetaloss_kd = (G_diff).sum() / bsz else:raise NotImplementedError(opt.distill)loss = opt.gamma * loss_cls + opt.alpha * loss_div + opt.beta * loss_kd
以上代码可知,投影实际将学生模型最后输出[batch,classs_n]通过projector结构转换,总共执行了三次,将其平均,将得到本论文提的集成投影的特征空间蒸馏。
值得注意是:论文方法没有使用loss_div = criterion_div(logit_s, logit_t)此loss。
三、四内容参考链接:https://blog.csdn.net/qgh1223/article/details/130724222