本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
链接:[1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (arxiv.org)
摘要
近年来,卷积网络(CNNs)的监督学习在计算机视觉应用中得到了广泛的应用。相比之下,CNNs的无监督学习受到的关注较少。在这项工作中,我们希望弥补CNNs在监督学习和无监督学习之间的差距。我们引入了一类称为深度卷积生成对抗网络(DCGANs)的CNNs,它们具有某些架构约束,并证明它们是无监督学习的有力候选者。在各种图像数据集上的训练中,我们展示了有说服力的证据,证明我们的深度卷积对抗对从对象部分到场景在生成器和鉴别器中都学到了表示的层次结构。此外,我们使用学到的特征进行新的任务——展示它们作为通用图像表示的适用性。
1 引言
从大型未标记的数据集中学习可重用的特征表示一直是活跃研究的领域。在计算机视觉的背景下,人们可以利用实际上无限量的未标记的图像和视频来学习好的中间表示,然后可以用于各种监督学习任务,如图像分类。我们建议,构建良好的图像表示的一种方法是通过训练生成对抗网络(GANs)(Goodfellow等人,2014),然后重用生成器和鉴别器网络的部分作为监督任务的特征提取器。GANs为最大似然技术提供了一个有吸引力的替代方案。人们还可以争辩说,他们的学习过程以及没有启发式的代价函数(如像素独立的均方误差)对于表示学习来说都很有吸引力。众所周知,GANs不稳定,经常导致生成器产生无意义的输出。在试图理解和可视化GANs学到了什么,以及多层GANs的中间表示方面,发表的研究非常有限。
在本文中,我们做出以下贡献:
- 我们提出并评估了一套对卷积GANs的架构拓扑的约束,使它们在大多数设置中稳定地进行训练。我们将这类架构命名为深度卷积生成对抗网络(DCGAN)。
- 我们使用经过训练的鉴别器进行图像分类任务,与其他无监督算法展现了有竞争力的性能。
- 我们可视化了GANs学到的过滤器,并凭经验显示特定的过滤器已经学会绘制特定的对象。
- 我们展示了生成器具有有趣的向量算术属性,允许轻松操纵生成样本的许多语义质量。
2 相关工作
2.1 从未标记的数据学习表示
无监督表示学习在通用计算机视觉研究中是一个相当研究得很深入的问题,也是在图像背景下的问题。无监督表示学习的经典方法是对数据进行聚类(例如使用K均值),并利用这些聚类来提高分类分数。在图像的背景下,可以对图像块进行层次性的聚类(Coates & Ng, 2012)来学习强大的图像表示。另一个流行的方法是训练自动编码器(卷积、堆叠(Vincent等人,2010)、分离代码的什么和哪里组件(Zhao等人,2015)、梯形结构(Rasmus等人,2015)),将图像编码为一个紧凑的代码,并解码代码以尽可能准确地重建图像。这些方法也已被证明可以从图像像素中学习到好的特征表示。深度信念网络(Lee等人,2009)也被证明在学习分层表示方面表现良好。
2.2 生成自然图像
生成图像模型已经研究得很深入,分为两类:参数和非参数。非参数模型通常从现有图像的数据库中进行匹配,常常是匹配图像的块,并已被用于纹理合成(Efros等人,1999)、超分辨率(Freeman等人,2002)和图像修复(Hays & Efros, 2007)。生成图像的参数模型已经被广泛探索(例如在MNIST数字上或用于纹理合成(Portilla & Simoncelli, 2000))。但是,直到最近生成真实世界的自然图像都没有取得太大的成功。生成图像的变分采样方法(Kingma & Welling, 2013)已经取得了一些成功,但是样本常常因为模糊而受到影响。另一种方法使用迭代的正向扩散过程(Sohl-Dickstein等人,2015)来生成图像。生成对抗网络(Goodfellow等人,2014)生成的图像受到噪声和难以理解的影响。这种方法的拉普拉斯金字塔扩展(Denton等人,2015)显示了更高质量的图像,但它们仍然受到由于在链接多个模型时引入的噪声导致的对象看起来摇晃不定的影响。递归网络方法(Gregor等人,2015)和反卷积网络方法(Dosovitskiy等人,2014)最近也在生成自然图像方面取得了一些成功。然而,他们没有利用生成器来进行监督任务。
2.3 可视化CNNs的内部结构
使用神经网络的一个持续的批评是它们是黑盒方法,很少理解网络以简单的人类可消化的算法形式所做的事情。在CNNs的背景下,Zeiler等人(Zeiler & Fergus, 2014)表明,通过使用反卷积和过滤最大激活,可以找到网络中每个卷积滤波器的大致用途。同样,对输入进行梯度下降使我们能够检查激活某些子集滤波器的理想图像(Mordvintsev等人)。
3 方法与模型架构
使用CNNs对GANs进行扩展以模拟图像的历史尝试都没有成功。这促使LAPGAN的作者(Denton等,2015)开发了一种替代方法,迭代地放大可以更可靠地建模的低分辨率生成的图像。我们也在尝试使用在监督文献中常用的CNN架构来扩展GANs时遇到了困难。然而,在广泛的模型探索之后,我们确定了一系列的架构,这些架构在一系列的数据集上都能稳定地进行训练,并允许训练更高分辨率和更深的生成模型。
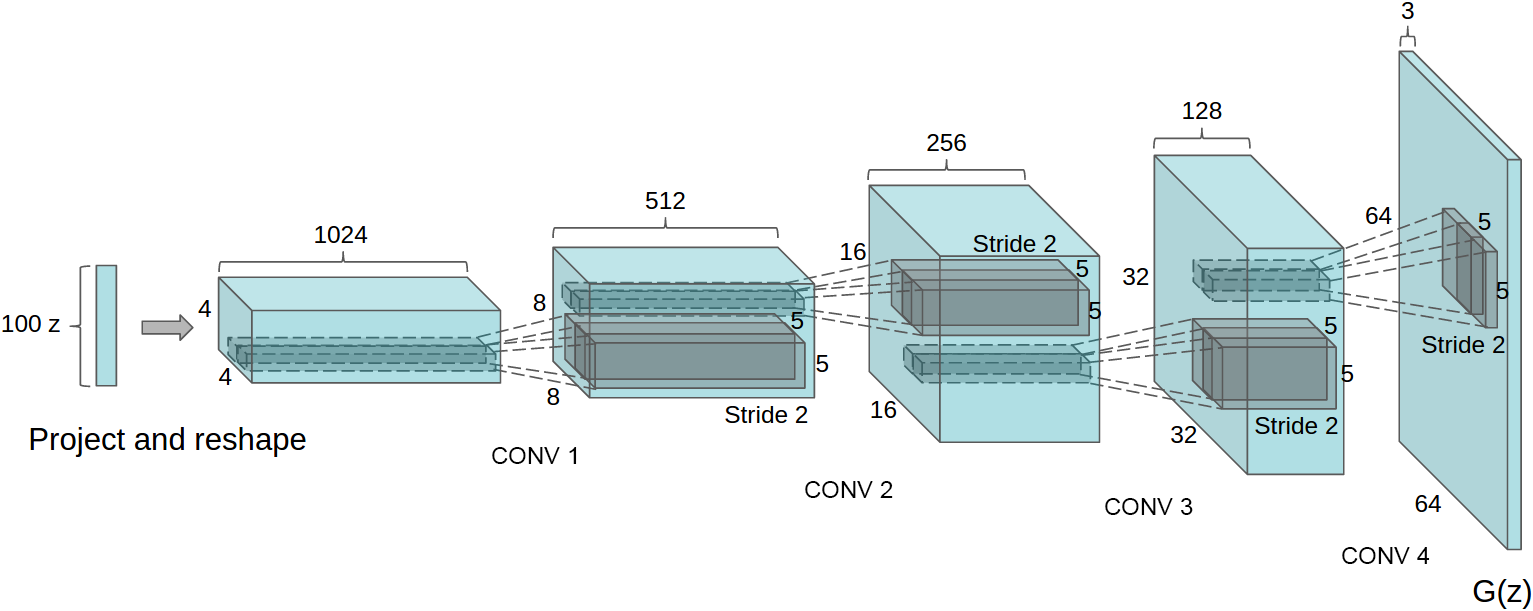
我们的方法的核心是采纳并修改了最近对CNN架构展示出的三个变化。第一个是全卷积网络(Springenberg等,2014),它用带步长的卷积替换了确定性的空间池化函数(如最大池化),使网络能够学习自己的空间下采样。我们在生成器中使用这种方法,让它学习自己的空间上采样,以及判别器。第二是消除卷积特征上面的全连接层的趋势。这方面最强烈的例子是全局平均池化,它已经被用于最先进的图像分类模型(Mordvintsev等)。我们发现全局平均池化增加了模型的稳定性,但降低了收敛速度。直接将最高的卷积特征连接到生成器和判别器的输入和输出,效果很好。GAN的第一层,将均匀噪声分布Z作为输入,可以被称为全连接,因为它只是一个矩阵乘法,但结果被重塑成一个4维张量,并用作卷积堆栈的开始。对于判别器,最后的卷积层被展平,然后送入一个单一的sigmoid输出。参见图1,查看一个示例模型架构的可视化。
图1:用于LSUN场景建模的DCGAN生成器。一个100维的均匀分布Z被映射到一个具有许多特征图的小空间范围的卷积表示。然后,四个分数步幅的卷积(在一些近期的论文中,这些被错误地称为反卷积)将这种高级表示转换为一个64×64像素的图像。值得注意的是,没有使用全连接或池化层。
第三是批量正则化(Ioffe & Szegedy, 2015),它通过将每个单元的输入标准化为均值为零和单位方差来稳定学习。这有助于处理由于不良初始化而产生的训练问题,并帮助在更深的模型中的梯度流动。这对于让深层的生成器开始学习至关重要,防止生成器将所有样本坍缩到一个点,这是在GANs中观察到的一个常见的失败模式。然而,直接将batchnorm应用到所有层上,会导致样本振荡和模型不稳定。通过不在生成器的输出层和判别器的输入层上应用batchnorm来避免这种情况。在生成器中使用ReLU激活函数(Nair & Hinton, 2010),除了输出层使用Tanh函数。我们观察到,使用有界激活允许模型更快地学习饱和和覆盖训练分布的颜色空间。在判别器内,我们发现泄漏修正激活(Maas等,2013)(Xu等,2015)工作得很好,特别是对于高分辨率建模。这与原始的GAN论文形成了对比,后者使用了maxout激活(Goodfellow等,2013)。
为稳定的深度卷积GANs的架构指南:
- 用带步长的卷积(判别器)和分数步长的卷积(生成器)替换任何池化层。
- 在生成器和判别器中都使用批量归一化(batchnorm)。
- 为了更深的架构,移除全连接的隐藏层。
- 在生成器中,除输出层外的所有层使用ReLU激活函数,输出层使用Tanh。
- 在判别器中的所有层使用LeakyReLU激活函数。
4 对抗训练的详细信息
我们在三个数据集上训练了DCGANs,即Large-scale Scene Understanding (LSUN) (Yu et al., 2015)、Imagenet-1k和一个新组装的人脸数据集。下面给出了这些数据集的使用细节。除了将训练图像缩放到tanh激活函数的范围[-1, 1]外,没有对训练图像进行任何预处理。所有模型都使用小批量随机梯度下降(SGD)进行训练,小批量的大小为128。所有权重都是从标准差为0.02的零中心正态分布初始化的。在LeakyReLU中,所有模型的泄漏斜率都设置为0.2。虽然之前的GAN工作已经使用动量来加速训练,但我们使用了Adam优化器(Kingma & Ba, 2014)并调整了超参数。我们发现建议的学习率0.001太高,改用0.0002。此外,我们发现将动量项β1保留在建议值0.9会导致训练震荡和不稳定,而将其减少到0.5有助于稳定训练。
4.1 LSUN
随着生成图像模型的样本视觉质量的提高,过拟合和训练样本的记忆问题引起了关注。为了展示我们的模型如何随更多的数据和更高分辨率的生成进行扩展,我们在LSUN卧室数据集上进行了训练,该数据集包含了略超过300万的训练样本。最近的分析显示,模型学习的速度与其泛化性能之间存在直接关联 (Hardt et al., 2015)。我们展示了一次训练周期的样本 (图2),模仿在线学习,以及收敛后的样本 (图3),以此为机会证明我们的模型不是通过简单的过拟合/记忆训练样本来产生高质量的样本。图片上没有应用任何数据增强。
图2:通过数据集进行一次训练后生成的卧室。从理论上讲,模型可以学会记忆训练样本,但由于我们使用小学习率和小批量SGD进行训练,这在实验上是不太可能的。我们不知道之前有任何实证证据显示使用SGD和小学习率的记忆效应。

图3:训练五次后生成的卧室。在多个样本中,通过重复的噪声纹理(例如一些床的底板)似乎有视觉上的欠拟合的证据。

4.1.1 去重
为了进一步降低生成器记忆输入样本 (图2) 的可能性,我们执行了一个简单的图像去重过程。我们在训练样本的32 × 32下采样中心裁剪上拟合了一个3072-128-3072的去噪dropout正则化ReLU自编码器。然后通过阈值化ReLU激活来二值化得到的代码层激活,这已被证明是一种有效的信息保持技术(Srivastava et al., 2014),并提供了一种方便的语义哈希形式,允许线性时间去重。哈希冲突的视觉检查显示了高精度,估计的误报率小于1/100。此外,这种技术检测并移除了约275,000个近似重复项,表明回忆率很高。
4.2 人脸
我们从随机的网络图片查询中爬取了包含人脸的图片。这些人的名字是从dbpedia获取的,标准是他们出生在现代时代。这个数据集有300万图片,来自10000个人。我们在这些图片上运行了一个OpenCV面部检测器,保留了足够高分辨率的检测结果,这给我们提供了约350,000个脸部框。我们使用这些脸部框进行训练。图片上没有应用任何数据增强。
4.3 IMAGENET-1K
我们使用Imagenet-1k (Deng et al., 2009) 作为无监督训练的自然图像来源。我们在32 × 32的中心裁剪上进行最小尺寸的训练。图片上没有应用任何数据增强。
5 DCGANs的实证验证
5.1 使用GAN作为特征提取器对CIFAR-10进行分类
对于评估无监督表示学习算法的质量的常见技术是将其作为一个特征提取器应用于监督数据集,并评估基于这些特征的线性模型的性能。
在CIFAR-10数据集上,使用K-means作为特征学习算法的单层特征提取流程已经展示了非常强的基线性能。当使用大量的特征图(4800)时,此技术达到80.6%的准确率。该基础算法的无监督多层扩展达到了82.0%的准确率 (Coates & Ng, 2011)。为了评估DCGANs对于监督任务学到的表示的质量,我们在Imagenet-1k上进行训练,然后使用鉴别器的所有层的卷积特征,对每一层的表示进行最大池化,产生一个4 × 4的空间网格。然后这些特征被展平并连接形成一个28672维的向量,之后在其上面训练一个正则化的线性L2-SVM分类器。这达到了82.8%的准确率,超过了所有基于K-means的方法。值得注意的是,与基于K-means的技术相比,鉴别器具有更少的特征图(在最高层有512),但由于4 × 4的空间位置的多层,结果在总特征向量大小上有所增加。DCGANs的性能仍然低于示例CNNs(Dosovitskiy et al., 2015),这是一种在无监督的方式下训练正常的区分性CNNs,以区分来自源数据集的特定选择的、大幅增强的、示例样本。通过微调鉴别器的表示可以进行进一步的改进,但我们将其留给未来的工作。此外,由于我们的DCGAN从未在CIFAR-10上进行过训练,此实验还展示了学到的特征的领域鲁棒性。
表1:使用我们的预训练模型对CIFAR-10的分类结果。我们的DCGAN并未在CIFAR-10上进行预训练,而是在Imagenet-1k上进行的,然后使用这些特征来对CIFAR-10的图像进行分类。

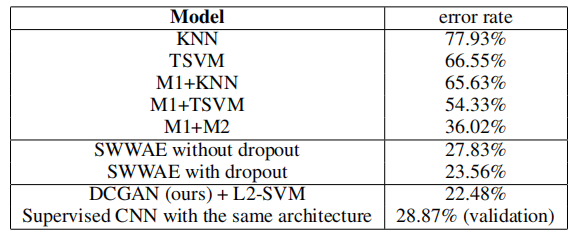
5.2 使用GAN作为特征提取器对SVHN数字进行分类
在街景房屋号码数据集(SVHN)(Netzer et al., 2011)上,当标记数据稀缺时,我们使用DCGAN的鉴别器的特征进行监督目的。按照CIFAR-10实验中的类似数据集准备规则,我们从非额外集合中分离出一个包含10,000个样本的验证集,并用它进行所有超参数和模型选择。随机选择1000个均匀分布的类别训练样本,并在CIFAR-10上使用的同样的特征提取流程上训练一个正则化的线性L2-SVM分类器。这达到了22.48%的测试误差,改进了另一种旨在利用未标记数据的CNNs的修改方法(Zhao et al., 2015)。此外,我们验证了在DCGAN中使用的CNN架构不是模型性能的主要贡献因素,通过在同样的数据上训练一个纯粹的监督CNN,并使用相同的架构,通过对64个超参数试验进行随机搜索优化这个模型(Bergstra & Bengio, 2012)。它达到了更高的28.87%的验证误差。
6 研究和可视化网络的内部结构
我们通过多种方式研究已经训练好的生成器和判别器。我们没有在训练集上进行任何类型的最近邻搜索。像素或特征空间的最近邻容易被小图像变换轻易欺骗(Theis等人,2015年)。我们也没有使用对数似然度量来定量地评估模型,因为它是一个不佳的评估标准(Theis等人,2015年)。
表2:使用1000个标签对SVHN进行分类
6.1 在潜在空间中行走
我们进行的第一个实验是为了理解潜在空间的结构。行走在已学习的流形上通常可以告诉我们关于记忆化的迹象(如果存在突然的转变),以及空间是如何层次化崩溃的。如果在这个潜在空间中的行走导致图像生成的语义改变(例如对象的添加和删除),我们可以推理出模型已经学到了相关且有趣的表示。结果展示在图4中。
图4:最上面几行:在Z中9个随机点之间的插值显示学到的空间具有平滑的过渡,空间中的每个图像都像一个卧室。在第6行,你可以看到一个没有窗户的房间慢慢变成了一个有巨大窗户的房间。在第10行,你可以看到一个似乎是电视的东西慢慢变成了一个窗户。

6.2 可视化判别器特征
以前的工作已经证明,对大型图像数据集进行CNN的监督训练可以产生非常强大的学习特征(Zeiler & Fergus, 2014年)。此外,进行场景分类的有监督的CNN可以学习物体探测器(Oquab等人,2014年)。我们证明,一个在大型图像数据集上无监督训练的DCGAN也可以学习到一系列有趣的特征。使用(Springenberg等人,2014年)提出的指导反向传播,我们在图5中展示了判别器所学的特征在卧室的典型部分(如床和窗户)上的激活。为了对比,我们在同一图中给出了随机初始化特征的基线,这些特征没有激活任何语义相关或有趣的内容。
图5:右侧显示的是鉴别器最后一个卷积层中前6个学习到的卷积特征对最大轴向响应的引导反向传播可视化。请注意,相当一部分特征对床产生响应——这是LSUN卧室数据集中的中心对象。左侧是一个随机滤波器的基线。与前面的响应相比,这里几乎没有区分度和随机结构。

6.3 操纵生成器表示
6.3.1 忘记绘制某些物体
除了判别器学到的表示外,还有生成器学到的表示问题。样本的质量表明生成器学到了主要场景组件的特定对象表示,如床、窗户、灯、门和杂项家具。为了探索这些表示的形式,我们进行了一个实验,试图完全从生成器中移除窗户。
在150个样本上,手工绘制了52个窗户边界框。在第二高的卷积层特征上,通过使用在绘制的边界框内的激活为正和来自同一图像的随机样本为负的标准,对逻辑回归进行了拟合,以预测特征激活是否在一个窗户上(或不在)。使用这个简单的模型,所有权重大于零的特征图(共200个)都从所有空间位置中删除。然后,生成了带有和不带特征图移除的随机新样本。
带有和不带窗户丢失的生成图像显示在图6中,有趣的是,网络大部分忘记在卧室中绘制窗户,用其他物体替换它们。
图6:顶行:来自模型的未修改样本。底行:在去除“窗户”滤镜后生成的相同样本。一些窗户被去除,其他的则被转化为视觉上相似的对象,如门和镜子。尽管视觉质量下降,但整体场景组合保持相似,这暗示生成器在从对象表示中分离场景表示方面做得很好。可以进行扩展的实验,从图像中去除其他对象,并修改生成器绘制的对象。

6.3.2 面部样本的向量算术
在评估学习到的单词表示的上下文中,Mikolov等人(2013)展示了简单的算术操作在表示空间中揭示了丰富的线性结构。一个经典的例子展示了vector(”King”) - vector(”Man”) + vector(”Woman”)的结果是一个与Queen向量最近邻的向量。我们研究了我们的生成器的Z表示中是否也有类似的结构。我们对视觉概念的一组典型样本的Z向量进行了类似的算术操作。只基于每个概念的单个样本的实验是不稳定的,但对三个样例的Z向量取平均后,产生了一致和稳定的生成结果,这些生成结果在语义上遵循了算术。除了在(图7)中显示的对象操作外,我们还展示了面部姿势也在Z空间中被线性地建模(图8)。
图7:视觉概念的向量算术。对于每一列,对样本的Z向量进行平均。然后对平均向量进行算术操作,创建一个新的向量Y。右侧中间的样本是通过将Y作为输入送入生成器而产生的。为了展示生成器的插值能力,均匀噪声采样(尺度为±0.25)被加到Y上,产生了其他8个样本。在输入空间(下面两个示例)应用算术会由于错位而导致噪声重叠。

图8:一个"转向"向量是由平均了四个样本所创建的,这些样本是面部向左看和向右看。通过在这个轴上添加插值到随机样本,我们能够可靠地转变它们的姿势。

这些演示表明,可以使用我们的模型学习到的Z表示来开发有趣的应用。已经有之前的证明,条件生成模型可以学习说服力地模拟对象属性,如尺度、旋转和位置 (Dosovitskiy et al., 2014)。据我们所知,这是首次在纯无监督模型中出现的演示。进一步探索和开发上述向量算术可能会大大减少条件生成建模复杂图像分布所需的数据量。
7 结论与未来工作
我们提出了一套更稳定的用于训练生成对抗网络的架构,并提供证据显示对抗网络学习了图像的好的表示,用于有监督的学习和生成建模。还有一些形式的模型不稳定性存在——我们注意到,随着模型训练时间的增长,它们有时会将一部分滤波器折叠到一个单一的振荡模式。需要进一步的工作来解决这种不稳定性。我们认为,将这个框架扩展到其他领域,如视频(用于帧预测)和音频(预训练的用于语音合成的特征)会非常有趣。对所学习的潜在空间的属性进行进一步的研究也会很有趣。
致谢
在这项工作中,我们非常幸运并感谢收到的所有建议和指导,特别是Ian Goodfellow、Tobias Springenberg、Arthur Szlam和Durk Kingma的建议。此外,我们还要感谢indico的所有同事提供的支持、资源和交流,特别是indico研究团队的另外两名成员,Dan Kuster和Nathan Lintz。最后,我们要感谢Nvidia捐赠的在这项工作中使用的Titan-X GPU。
参考文献
- Bergstra, James & Bengio, Yoshua. (2012). 随机搜索用于超参数优化。JMLR。
- Coates, Adam & Ng, Andrew. (2011). 在深度网络中选择感受野。NIPS。
- Coates, Adam & Ng, Andrew Y. (2012). 使用 k-means 学习特征表示。在 神经网络:行业诀窍 (第561–580页)。Springer。
- Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, & Fei-Fei, Li. (2009). ImageNet:一个大规模的分层图像数据库。在 计算机视觉和模式识别,2009年。IEEE计算机学会 (第248–255页)。IEEE。
- Denton, Emily, Chintala, Soumith, Szlam, Arthur, & Fergus, Rob. (2015). 使用拉普拉斯金字塔对抗网络的深度生成图像模型。arXiv 预印本 arXiv:1506.05751。
- Dosovitskiy, Alexey, Springenberg, Jost Tobias, & Brox, Thomas. (2014). 使用卷积神经网络生成椅子。arXiv 预印本 arXiv:1411.5928。
- Dosovitskiy, Alexey 等。 (2015). 利用样本卷积神经网络进行判别式无监督特征学习。模式分析与机器智能,IEEE 交易,卷99。IEEE。
- Efros, Alexei 等。 (1999). 非参数采样进行纹理合成。在 计算机视觉,第七届 IEEE 国际会议论文集,卷2,第1033–1038页。IEEE。
- Freeman, William T. 等。 (2002). 基于示例的超分辨率。计算机图形学与应用,IEEE,22(2):56–65。
- Goodfellow, Ian J. 等。 (2013). Maxout 网络。arXiv 预印本 arXiv:1302.4389。
- Goodfellow, Ian J. 等。 (2014). 生成对抗网络。NIPS。
- Gregor, Karol 等。 (2015). Draw:一种用于图像生成的递归神经网络。arXiv 预印本 arXiv:1502.04623。
- Hardt, Moritz 等。 (2015). 更快地训练,更好地推广:随机梯度下降的稳定性。arXiv 预印本 arXiv:1509.01240。
- Hauberg, Sren 等。 (2015). 梦境更多数据:面向学习数据增强的类相关微分流形分布。arXiv 预印本 arXiv:1510.02795。
- Hays, James & Efros, Alexei A. (2007). 使用数百万张照片进行场景补全。ACM 图形学交易 (TOG),26(3):4。
- Ioffe, Sergey & Szegedy, Christian. (2015). 批标准化:通过减少内部协变量转移加速深度网络训练。arXiv 预印本 arXiv:1502.03167。
- Kingma, Diederik P. & Ba, Jimmy Lei. (2014). Adam:一种随机优化方法。arXiv 预印本 arXiv:1412.6980。
- Kingma, Diederik P. & Welling, Max. (2013). 自编码变分贝叶斯。arXiv 预印本 arXiv:1312.6114。
- Lee, Honglak 等。 (2009). 用于可扩展无监督学习分层表示的卷积深度置信网络。在 第26届国际机器学习年会论文集,第609–616页。ACM。
- Loosli, Gaëlle 等。 (2007). 使用选择性采样训练不变支持向量机。在 大规模核机器,第301–320页。MIT出版社,剑桥,马萨诸塞州。
- Maas, Andrew L. 等。 (2013). 整流器非线性改善神经网络声学模型。ICML 会议论文集,卷30。
- Mikolov, Tomas 等。 (2013). 单词和短语的分布表示及其组合性。在 神经信息处理系统的进展,第3111–3119页。
- Mordvintsev, Alexander 等。 内省主义:更深入地探索神经网络。谷歌研究博客。[在线]. 访问日期:2015年06月17日。
- Nair, Vinod & Hinton, Geoffrey E. (2010). 整流线性单元改善受限玻尔兹曼机。第27届国际机器学习年会论文集 (ICML-10),第807–814页。
- Netzer, Yuval 等。 (2011). 使用无监督特征学习在自然图像中读取数字。在 NIPS 深度学习和无监督特征学习研讨会,卷2011,第5页。格拉纳达,西班牙。
- Oquab, M. 等。 (2014). 使用卷积神经网络学习和传递中层图像表示。在 CVPR。
- Portilla, Javier & Simoncelli, Eero P. (2000). 基于复杂小波系数联合统计的参数纹理模型。国际计算机视觉杂志,40(1):49–70。
- Rasmus, Antti 等。 (2015). 使用梯度爬梯子网络的半监督学习。arXiv 预印本 arXiv:1507.02672。
- Sohl-Dickstein, Jascha 等。 (2015). 使用非平衡热力学进行深度无监督学习。arXiv 预印本 arXiv:1503.03585。
- Springenberg, Jost Tobias 等。 (2014). 追求简单:全卷积网络。arXiv 预印本 arXiv:1412.6806。
- Srivastava, Rupesh Kumar 等。 (2014). 理解局部竞争网络。arXiv 预印本 arXiv:1410.1165。
- Theis, L. 等。 (2015). 有关生成模型评估的注释。arXiv:1511.01844。
- Vincent, Pascal 等。 (2010). 堆叠去噪自动编码器:在具有局部去噪标准的深度网络中学习有用的表示。机器学习研究杂志,11:3371–3408。
- Xu, Bing 等。 (2015). 在卷积网络中实证评估整流激活。arXiv 预印本 arXiv:1505.00853。
- Yu, Fisher 等。 (2015). 利用人在循环中的深度学习构建大规模图像数据集。arXiv 预印本 arXiv:1506.03365。
- Zeiler, Matthew D & Fergus, Rob. (2014). 可视化和理解卷积网络。在 计算机视觉–ECCV 2014,第818–833页。Springer。
- Zhao, Junbo 等。 (2015). 堆叠 what-where 自动编码器。arXiv 预印本 arXiv:1506.02351。
REFERENCES
- Bergstra, James & Bengio, Yoshua. (2012). Random search for hyper-parameter optimization. JMLR.
- Coates, Adam & Ng, Andrew. (2011). Selecting receptive fields in deep networks. NIPS.
- Coates, Adam & Ng, Andrew Y. (2012). Learning feature representations with k-means. In Neural Networks: Tricks of the Trade (pp. 561–580). Springer.
- Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, & Fei-Fei, Li. (2009). Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (pp. 248–255). IEEE.
- Denton, Emily, Chintala, Soumith, Szlam, Arthur, & Fergus, Rob. (2015). Deep generative image models using a laplacian pyramid of adversarial networks. arXiv preprint arXiv:1506.05751.
- Dosovitskiy, Alexey, Springenberg, Jost Tobias, & Brox, Thomas. (2014). Learning to generate chairs with convolutional neural networks. arXiv preprint arXiv:1411.5928.
- Dosovitskiy, Alexey et al. (2015). Discriminative unsupervised feature learning with exemplar convolutional neural networks. Pattern Analysis and Machine Intelligence, IEEE Transactions on, volume 99. IEEE.
- Efros, Alexei et al. (1999). Texture synthesis by non-parametric sampling. In Computer Vision, The Proceedings of the Seventh IEEE International Conference on, volume 2, pp. 1033–1038. IEEE.
- Freeman, William T. et al. (2002). Example-based super-resolution. Computer Graphics and Applications, IEEE, 22(2):56–65.
- Goodfellow, Ian J. et al. (2013). Maxout networks. arXiv preprint arXiv:1302.4389.
- Goodfellow, Ian J. et al. (2014). Generative adversarial nets. NIPS.
- Gregor, Karol et al. (2015). Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623.
- Hardt, Moritz et al. (2015). Train faster, generalize better: Stability of stochastic gradient descent. arXiv preprint arXiv:1509.01240.
- Hauberg, Sren et al. (2015). Dreaming more data: Class-dependent distributions over diffeomorphisms for learned data augmentation. arXiv preprint arXiv:1510.02795.
- Hays, James & Efros, Alexei A. (2007). Scene completion using millions of photographs. ACM Transactions on Graphics (TOG), 26(3):4.
- Ioffe, Sergey & Szegedy, Christian. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
- Kingma, Diederik P. & Ba, Jimmy Lei. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kingma, Diederik P. & Welling, Max. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Lee, Honglak et al. (2009). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 609–616. ACM.
- Loosli, Gaëlle et al. (2007). Training invariant support vector machines using selective sampling. In Large Scale Kernel Machines, pp. 301–320. MIT Press, Cambridge, MA.
- Maas, Andrew L. et al. (2013). Rectifier nonlinearities improve neural network acoustic models. Proc. ICML, volume 30.
- Mikolov, Tomas et al. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119.
- Mordvintsev, Alexander et al. Inceptionism: Going deeper into neural networks. Google Research Blog. [Online]. Accessed: 2015-06-17.
- Nair, Vinod & Hinton, Geoffrey E. (2010). Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp. 807–814.
- Netzer, Yuval et al. (2011). Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp. 5. Granada, Spain.
- Oquab, M. et al. (2014). Learning and transferring mid-level image representations using convolutional neural networks. In CVPR.
- Portilla, Javier & Simoncelli, Eero P. (2000). A parametric texture model based on joint statistics of complex wavelet coefficients. International Journal of Computer Vision, 40(1):49–70.
- Rasmus, Antti et al. (2015). Semi-supervised learning with ladder network. arXiv preprint arXiv:1507.02672.
- Sohl-Dickstein, Jascha et al. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. arXiv preprint arXiv:1503.03585.
- Springenberg, Jost Tobias et al. (2014). Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806.
- Srivastava, Rupesh Kumar et al. (2014). Understanding locally competitive networks. arXiv preprint arXiv:1410.1165.
- Theis, L. et al. (2015). A note on the evaluation of generative models. arXiv:1511.01844.
- Vincent, Pascal et al. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 11:3371–3408.
- Xu, Bing et al. (2015). Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853.
- Yu, Fisher et al. (2015). Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365.
- Zeiler, Matthew D & Fergus, Rob. (2014). Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014, pp. 818–833. Springer.
- Zhao, Junbo et al. (2015). Stacked what-where auto-encoders. arXiv preprint arXiv:1506.02351.
8 附加材料
8.1 评估 DCGAN 对捕捉数据分布的能力
我们提出在我们模型的条件版本上应用标准分类指标,评估所学的条件分布。我们在 MNIST 数据集上训练了一个 DCGAN(将其中的 1 万个样本用作验证集),同时还训练了一个置换不变的 GAN 基线,并使用最近邻分类器评估了这些模型,将真实数据与一组生成的条件样本进行比较。我们发现,从批归一化中移除尺度和偏置参数可以为这两个模型带来更好的结果。我们推测,批归一化引入的噪声有助于生成模型更好地探索底层数据分布并从中生成样本。结果在表 3 中展示了出来,该表将我们的模型与其他技术进行了比较。DCGAN 模型在测试误差方面达到了与在训练数据集上拟合的最近邻分类器相同的水平,这表明 DCGAN 模型在建模该数据集的条件分布方面表现出色。在每个类别一百万个样本的情况下,DCGAN 模型的性能超过了 InfiMNIST(Loosli 等,2007),这是一个手工开发的数据增强流程,它使用训练样本的平移和弹性变形。DCGAN 在与一种使用了学习的每类别变换的概率生成数据增强技术(Hauberg 等,2015)竞争时表现出色,同时更加通用,因为它直接对数据进行建模,而不是数据的变换。
表3:最近邻分类结果

图9:并排示例图(从左到右)显示了 MNIST 数据集、基线 GAN 生成以及我们的 DCGAN 生成结果。

图10:更多来自我们的人脸 DCGAN 的生成图像。

图11:在 Imagenet-1k 数据集上训练的 DCGAN 的生成图像。