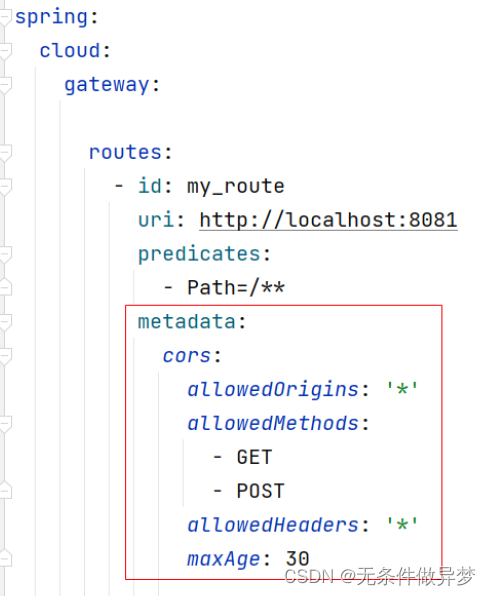
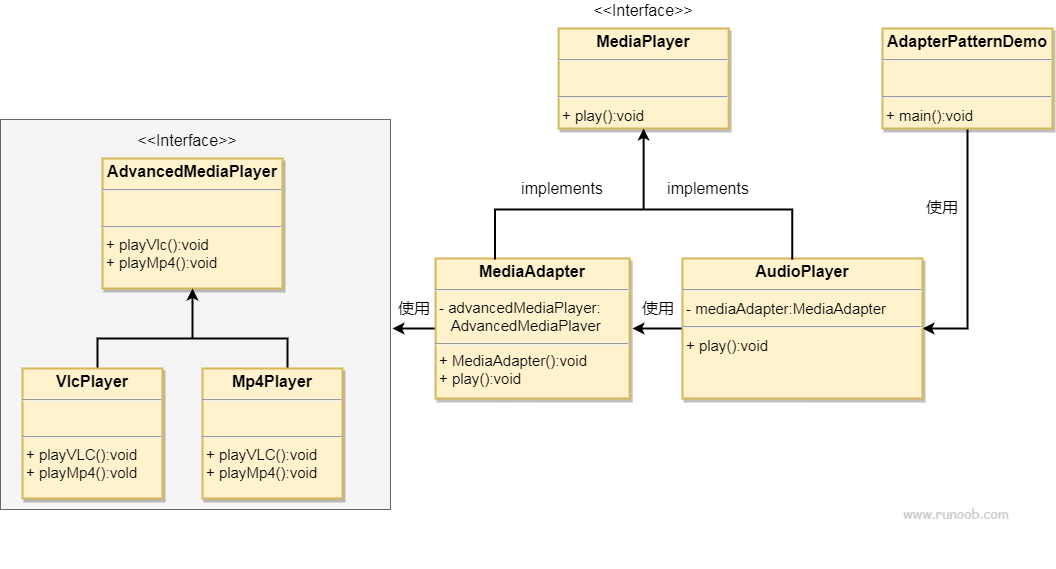
作为当前计算机视觉应用的首选,深度网络通常通过监督学习(一种需要标记数据集的方法)来实现其强大的性能。尽管人工智能多年来取得了许多成就和进步,但标记数据的关键任务仍然落在人类专家身上。他们很难满足那些数据饥渴的深度网络的需求。
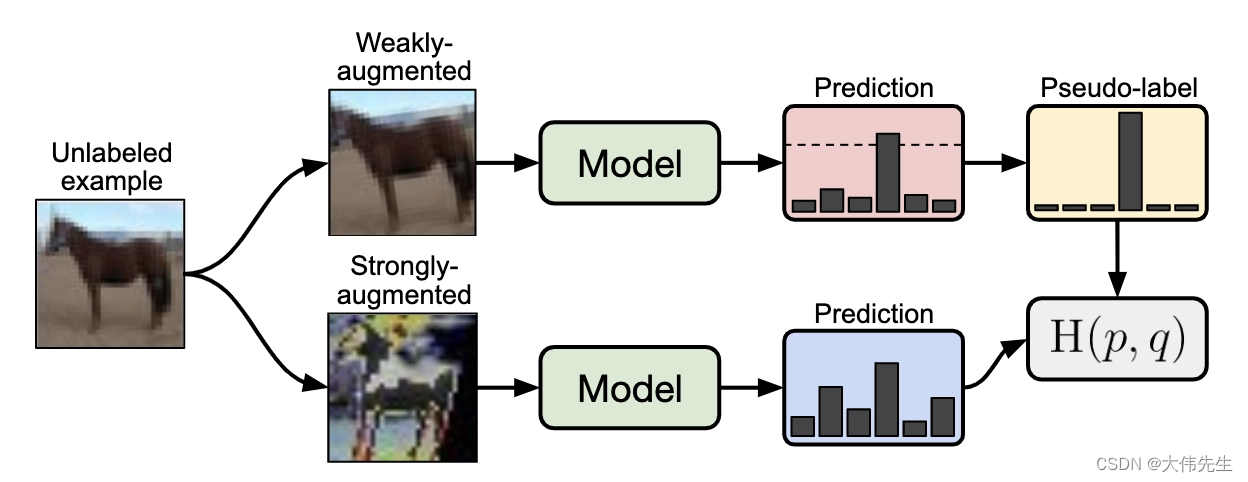
专家短缺的一个解决方案是减少模型对标记数据的依赖。半监督学习(SSL)旨在通过在模型训练期间提出使用未标记数据的方法来实现这一目标。而且由于未标记的数据通常可以用最少的人力获得,因此SSL的性能提升成本相对较低。
谷歌研究院的一个团队本周推出了FixMatch,这是一种结合了两种常见深度网络SSL方法的算法:伪标签(又名自我训练)和一致性正则化。伪标记有效地使用模型的类预测作为要训练的标签。同时,一致性正则化假设模型在馈送同一图像的扰动版本时应输出类似的预测。
虽然 FixMatch 看起来只是现有技术的简单组合,但它在各种标准的半监督学习基准测试中实现了 SOTA 性能,包括在 CIFAR-94 上具有 93 个标签的准确率为 10.250%,在 88 个标签(每个类只有四个标签)上达到 61.40% 的准确率。
FixMatch 首先使用模型对弱增强的未标记图像的预测生成伪标签。对于给定图像,仅当模型生成高置信度预测时,才会保留伪标签。然后训练模型以在馈送同一图像的强增强版本时预测伪标签。
“我们还展示了FixMatch如何开始弥合低标签半监督学习和少镜头学习甚至聚类之间的差距:我们在每个类只有一个标签的情况下获得了惊人的高准确性,”论文合著者解释说。
由于FixMatch的简单性,研究人员能够调查该算法的几乎所有方面,以探索它如何以及为什么如此有效。他们发现,为了获得良好的结果,特别是在有限标签设置中,某些以前被低估的设计选择——比如权重衰减或优化器的选择——实际上对提高模型性能非常有帮助。
论文FixMatch: Compplizing Semi-Supervised Learning with Consistency and Confidence发表在arXiv上。该代码可在项目 GitHub 上找到。





![[保研/考研机试] KY7 质因数的个数 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/img_convert/6f7891bab949c1a0aea5b10fa4afba08.png)