当JProfiler测量方法调用的执行时间及其调用堆栈时,我们称之为“CPU评测”。这些数据以多种方式呈现。根据你试图解决的问题,其中一个或另一个演示将是最有帮助的。默认情况下不会记录CPU数据,您必须打开CPU记录才能捕获有趣的用例。
一、调用树
跟踪所有方法调用及其调用堆栈将消耗大量内存,并且只能保持很短的时间,直到所有内存耗尽。此外,在繁忙的JVM中直观地掌握方法调用的数量并不容易。通常,这个数字太大了,无法定位和跟踪轨迹。
另一个方面是,许多性能问题只有在收集到的数据被聚合后才会变得清楚。通过这种方式,您可以判断方法调用在某个时间段内对整个活动的重要性。对于单个跟踪,您不知道所查看的数据的相对重要性。
这就是为什么JProfiler构建了一个所有观察到的调用堆栈的累积树,并用观察到的时间和调用计数进行注释。删除了按时间顺序排列的部分,只保留了总数。树中的每个节点表示一个调用堆栈,该堆栈至少被观察一次。节点具有代表在该调用堆栈中看到的所有传出调用的子级。

调用树是“CPU视图”部分中的第一个视图,当您开始CPU评测时,它是一个很好的起点,因为方法调用从起点到最细粒度的终点的自上而下的视图最容易理解。JProfiler根据子级的总时间对其进行排序,因此您可以首先打开树深度来分析树中对性能影响最大的部分。
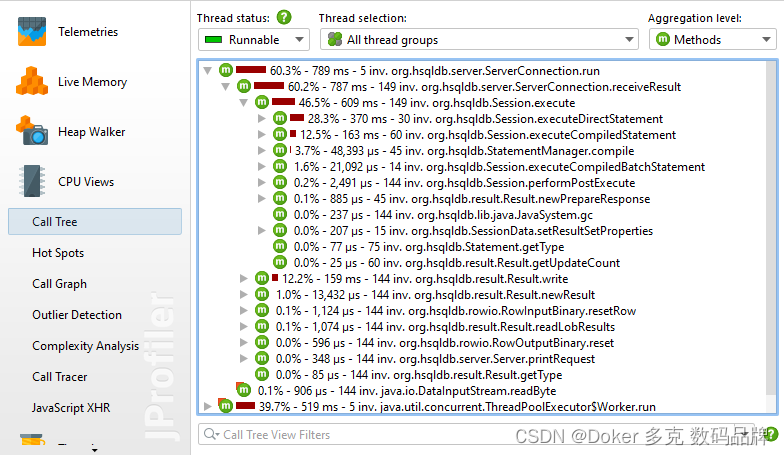
虽然所有的测量都是针对方法执行的,但JProfiler允许您通过在类或包级别聚合调用树来获得更广泛的视角。聚合级别选择器还包含一个“JEE/Spring组件”模式。如果您的应用程序使用JEE或Spring,则可以使用此模式在类级别上仅查看JEE和Spring组件。像URL这样的拆分节点保留在所有聚合级别中。

二、调用树筛选器
如果调用树中显示了所有类的方法,则该树通常太深而无法管理。如果你的应用程序是由一个框架调用的,那么调用树的顶部将由你不关心的框架类组成,你自己的类将被深深地掩埋。对库的调用将显示其内部结构,可能有数百个级别的方法调用,这些调用您不熟悉,也无法影响。
这个问题的解决方案是对调用树应用过滤器,这样只记录一些类。作为一个积极的副作用,需要收集的数据更少,需要检测的类也更少,因此减少了开销。
默认情况下,配置分析会话时会使用一个从常用框架和库中排除的包列表。
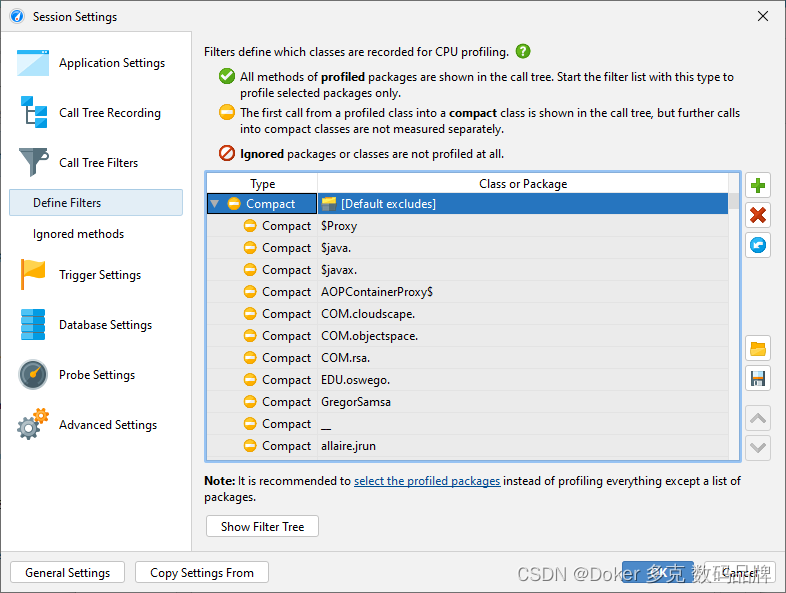
当然,这个列表是不完整的,所以最好删除它并自己定义感兴趣的包。事实上,插装和默认过滤器的组合是非常不可取的,因此JProfiler建议在会话启动对话框中进行更改。

过滤器表达式与完全限定的类名进行比较,因此com.mycorp.匹配所有嵌套包中的类,如com.mycorp.myapp.Application。有三种类型的过滤器,称为“profiled”、“compact”和“ignored”。“概要”类中的所有方法都是经过测量的。这是您自己的代码所需要的。
在“紧凑”过滤器所包含的类中,只测量对该类的第一次调用,但不显示进一步的内部调用。“Compact”是库(包括JRE)所需要的。例如,当调用hashMap.put(a,b)时,您可能希望在调用树中看到hashMap.put。
最后,“忽略”的方法根本没有被分析。由于开销方面的考虑,它们可能不适合使用,或者它们可能只是在调用树中分散注意力,例如插入动态调用之间的内部Groovy方法。
手动输入程序包容易出错,因此您可以使用程序包浏览器。在启动会话之前,包浏览器只能向您显示配置的类路径中的包,该路径通常不会覆盖实际加载的所有类。在运行时,包浏览器将显示所有加载的类。

为每个类从上到下评估配置的筛选器列表。在每个阶段,如果匹配,则当前过滤器类型可能会发生变化。什么样的过滤器从过滤器列表开始很重要。如果您从一个“profiled”过滤器开始,那么类的初始过滤器类型是“compact”,这意味着只对显式匹配进行分析。

如果您从一个“紧凑”过滤器开始,那么类的初始过滤器类型是“profiled”。在这种情况下,除了显式排除的类之外,所有类都将进行分析。

三、调用树时间
要正确解释调用树,了解调用树节点上显示的数字非常重要。任何节点都有两个有趣的时间,总时间和自身时间。自身时间是节点的总时间减去嵌套节点中的总时间。
通常,自时间很小,除了紧凑的过滤类。大多数情况下,紧凑过滤类是一个叶节点,总时间等于自身时间,因为没有子节点。有时,紧凑过滤类会调用一个配置文件类,例如通过回调,或者因为它是调用树的入口点,比如当前线程的run方法。在这种情况下,一些未编译的方法会消耗时间,但不会显示在调用树中。该时间冒泡到调用树中的第一个可用祖先节点,并为紧凑过滤类的自身时间做出贡献。

调用树中的百分比栏显示总时间,但自身时间部分显示为不同的颜色。除非重载了同一级别上的两个方法,否则方法显示时没有其签名。有多种方法可以自定义视图设置对话框中调用树节点的显示。例如,您可能希望将自身时间或平均时间显示为文本,始终显示方法签名或更改使用的时间刻度。此外,百分比计算可以基于父时间,而不是整个调用树的时间。

四、线程状态
在调用树的顶部,有几个视图参数可以更改所显示的分析数据的类型和范围。默认情况下,所有线程都是累积的。JProfiler在每个线程的基础上维护CPU数据,您可以显示单个线程或线程组。

在任何时候,每个线程都有一个关联的线程状态。如果线程已准备好处理字节码指令,或者当前正在CPU核心上执行这些指令,则线程状态称为“可运行”。在查找性能瓶颈时,该线程状态是感兴趣的,因此默认情况下会选择它。
或者,线程可能正在监视器上等待,例如通过调用Object.wait()或thread.sleep(),在这种情况下,线程状态被称为“等待”。在尝试获取监视器时被阻塞的线程(例如在同步代码块的边界处)处于“阻塞”状态。
最后,JProfiler添加了一个合成的“Net I/O”状态,用于跟踪线程等待网络数据的时间。这对于分析服务器和数据库驱动程序非常重要,因为这段时间可能与性能分析相关,例如用于调查慢速SQL查询。
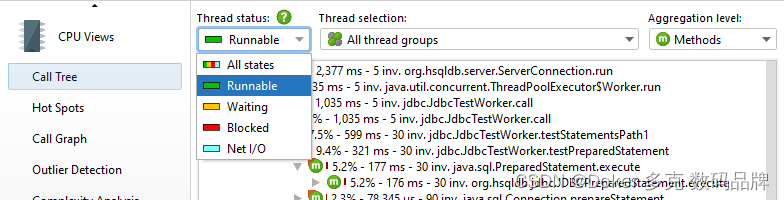
如果你对挂钟时间感兴趣,你必须选择线程状态“所有状态”,也可以选择一个线程。只有这样,您才能将时间与代码中调用System.currentTimeMillis()计算的持续时间进行比较。
如果您想将所选方法转移到不同的线程状态,可以使用方法触发器和“覆盖线程状态”触发器操作,或者使用嵌入或注入的探测API中的ThreadStatus类来实现。
五、在调用树中查找节点
有两种方法可以在调用树中搜索文本。首先,有一个快速搜索选项,它通过从菜单中调用View->Find或直接开始在调用树中键入来激活。按下PageDown后,匹配项将突出显示,搜索选项可用。使用“向上箭头”和“向下箭头”键,您可以在不同的匹配中循环。

搜索方法、类或包的另一种方法是使用调用树底部的视图过滤器。在这里,您可以输入一个逗号分隔的筛选器表达式列表。以“-”开头的筛选器表达式类似于被忽略的筛选器。以“!”开头的表达式类似于紧凑型过滤器。所有其他表达式都类似于配置文件过滤器。就像过滤器设置一样,初始过滤器类型决定了默认情况下是包括类还是排除类。
单击视图设置文本字段左侧的图标可显示视图过滤器选项。默认情况下,匹配模式为“包含”,但在搜索特定包时,“以开头”可能更合适。

六、火焰图
另一种查看调用树的方法是将其作为火焰图。通过调用关联的调用树分析,可以将整个调用树或其一部分显示为火焰图。

火焰图在一个图像中显示了调用树的全部内容。调用从火焰图的底部开始,并向顶部传播。每个节点的子节点排列在其正上方的行中。子节点按字母顺序排序,并以其父节点为中心。由于在每个节点中花费的自身时间,“火焰”向顶部逐渐变窄。有关节点的更多信息显示在工具提示中,您可以在其中标记文本以将其复制到剪贴板。

火焰图具有非常高的信息密度,因此可能有必要通过关注所选节点及其子节点层次来缩小显示的内容。虽然可以放大感兴趣的区域,但也可以通过双击或使用上下文菜单来设置新的根节点。当连续多次更改根时,可以在根的历史中再次向后移动。
分析火焰图的另一种方法是根据类名、包名或任意搜索项添加着色。着色可以从上下文菜单中添加,也可以在着色对话框中进行管理。第一个匹配的着色用于每个节点。除了着色之外,您还可以使用快速搜索功能来查找感兴趣的节点。使用光标键,可以在显示当前高亮显示的匹配的工具提示时循环显示匹配结果。