🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
一、理论基础
生成对抗网络(Generative Adversarial Networks, GAN)是近年来深度学习领域的一个热点方向。GAN并不指代某一个具体的神经网络,而是指一类基于博弈思想而设计的神经网络。GAN由两个分别被称为生成器(Generator)和判别器(Discriminator)的神经网络组成。其中,生成器从某种噪声分布中随机采样作为输入,输出与训练集中真实样本非常相似的人工样本;判别器的输入则为真实样本或人工样本,其目的是将人工样本与真实样本尽可能地区分出来。生成器和判别器交替运行,相互博弈,各自的能力都得到升。理想情况下,经过足够次数的博弈之后,判别器无法判断给定样本的真实性,即对于所有样本都输出50%真,50%假的判断。此时,生成器输出的人工样本已经逼真到使判别器无法分辨真假,停止博弈。这样就可以得到一个具有“伪造”真实样本能力的生成器。
1. 生成器
GANs中,生成器 G 选取随机噪声 z 作为输入,通过生成器的不断拟合,最终输出一个和真实样本尺寸相同,分布相似的伪造样本G(z)。生成器的本质是一个使用生成式方法的模型,它对数据的分布假设和分布参数进行学习,然后根据学习到的模型重新采样出新的样本。
从数学上来说,生成式方法对于给定的真实数据,首先需要对数据的显式变量或隐含变量做分布假设;然后再将真实数据输入到模型中对变量、参数进行训练;最后得到一个学习后的近似分布,这个分布可以用来生成新的数据。从机器学习的角度来说,模型不会去做分布假设,而是通过不断地学习真实数据,对模型进行修正,最后也可以得到一个学习后的模型来做样本生成任务。这种方法不同于数学方法,学习的过程对人类理解较不直观。
2. 判别器
GANs中,判别器 D 对于输入的样本 x,输出一个[0,1]之间的概率数值D(x)。x 可能是来自于原始数据集中的真实样本 x,也可能是来自于生成器 G 的人工样本G(z)。通常约定,概率值D(x)越接近于1就代表此样本为真实样本的可能性更大;反之概率值越小则此样本为伪造样本的可能性越大。也就是说,这里的判别器是一个二分类的神经网络分类器,目的不是判定输入数据的原始类别,而是区分输入样本的真伪。可以注意到,不管在生成器还是判别器中,样本的类别信息都没有用到,也表明 GAN 是一个无监督的学习过程。
3. 基本原理
GAN是博弈论和机器学习相结合的产物,于2014年Ian Goodfellow的论文中问世,一经问世即火爆足以看出人们对于这种算法的认可和狂热的研究热忱。想要更详细的了解GAN,就要知道它是怎么来的,以及这种算法出现的意义是什么。研究者最初想要通过计算机完成自动生成数据的功能,例如通过训练某种算法模型,让某模型学习过一些苹果的图片后能自动生成苹果的图片,具备些功能的算法即认为具有生成功能。但是GAN不是第一个生成算法,而是以往的生成算法在衡量生成图片和真实图片的差距时采用均方误差作为损失函数,但是研究者发现有时均方误差一样的两张生成图片效果却截然不同,鉴于此不足Ian Goodfellow提出了GAN。
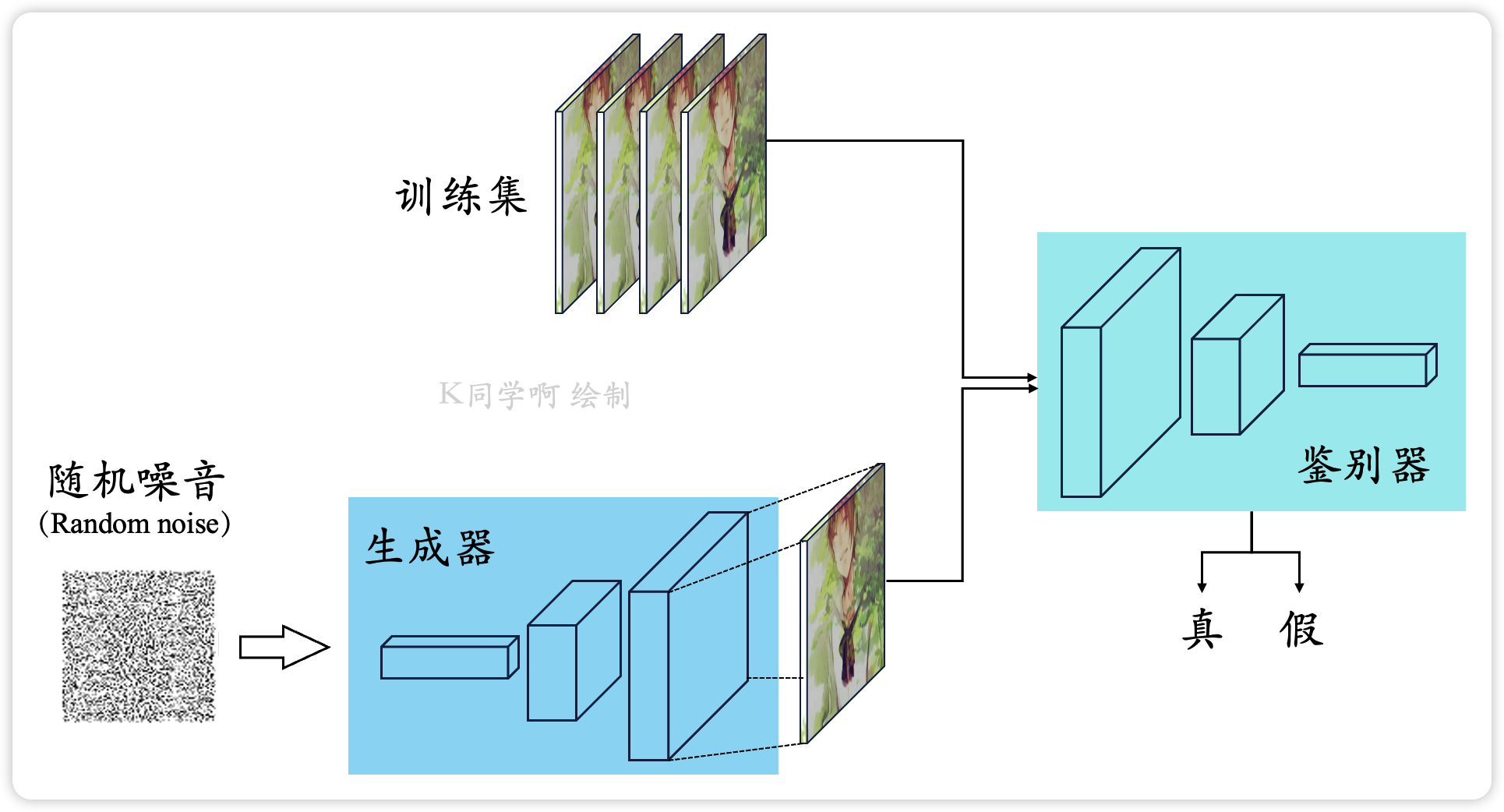
那么GAN是如何完成生成图片这项功能的呢,如图1所示,GAN是由两个模型组成的:生成模型G和判别模型D。首先第一代生成模型1G的输入是随机噪声z,然后生成模型会生成一张初级照片,训练一代判别模型1D另其进行二分类操作,将生成的图片判别为0,而真实图片判别为1;为了欺瞒一代鉴别器,于是一代生成模型开始优化,然后它进阶成了二代,当它生成的数据成功欺瞒1D时,鉴别模型也会优化更新,进而升级为2D,按照同样的过程也会不断更新出N代的G和D。
二、前期准备工作
1. 定义超参数
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch## 创建文件夹
os.makedirs("./images/", exist_ok=True) ## 记录训练过程的图片效果
os.makedirs("./save/", exist_ok=True) ## 训练完成时模型保存的位置
os.makedirs("./datasets/mnist", exist_ok=True) ## 下载数据集存放的位置## 超参数配置
n_epochs=50
batch_size=512
lr=0.0002
b1=0.5
b2=0.999
n_cpu=2
latent_dim=100
img_size=28
channels=1
sample_interval=500## 图像的尺寸:(1, 28, 28), 和图像的像素面积:(784)
img_shape = (channels, img_size, img_size)
img_area = np.prod(img_shape)## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
print(cuda)
## mnist数据集下载
mnist = datasets.MNIST(root='./datasets/', train=True, download=True, transform=transforms.Compose([transforms.Resize(img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),
)
## 配置数据到加载器
dataloader = DataLoader(mnist,batch_size=batch_size,shuffle=True,
)
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(img_area, 512), # 输入特征数为784,输出为512nn.LeakyReLU(0.2, inplace=True), # 进行非线性映射nn.Linear(512, 256), # 输入特征数为512,输出为256nn.LeakyReLU(0.2, inplace=True), # 进行非线性映射nn.Linear(256, 1), # 输入特征数为256,输出为1nn.Sigmoid(), # sigmoid是一个激活函数,二分类问题中可将实数映射到[0, 1],作为概率值, 多分类用softmax函数)def forward(self, img):img_flat = img.view(img.size(0), -1) # 鉴别器输入是一个被view展开的(784)的一维图像:(64, 784)validity = self.model(img_flat) # 通过鉴别器网络return validity # 鉴别器返回的是一个[0, 1]间的概率
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()## 模型中间块儿def block(in_feat, out_feat, normalize=True): # block(in, out )layers = [nn.Linear(in_feat, out_feat)] # 线性变换将输入映射到out维if normalize:layers.append(nn.BatchNorm1d(out_feat, 0.8)) # 正则化layers.append(nn.LeakyReLU(0.2, inplace=True)) # 非线性激活函数return layers## prod():返回给定轴上的数组元素的乘积:1*28*28=784self.model = nn.Sequential(*block(latent_dim, 128, normalize=False), # 线性变化将输入映射 100 to 128, 正则化, LeakyReLU*block(128, 256), # 线性变化将输入映射 128 to 256, 正则化, LeakyReLU*block(256, 512), # 线性变化将输入映射 256 to 512, 正则化, LeakyReLU*block(512, 1024), # 线性变化将输入映射 512 to 1024, 正则化, LeakyReLUnn.Linear(1024, img_area), # 线性变化将输入映射 1024 to 784nn.Tanh() # 将(784)的数据每一个都映射到[-1, 1]之间)## view():相当于numpy中的reshape,重新定义矩阵的形状:这里是reshape(64, 1, 28, 28)def forward(self, z): # 输入的是(64, 100)的噪声数据imgs = self.model(z) # 噪声数据通过生成器模型imgs = imgs.view(imgs.size(0), *img_shape) # reshape成(64, 1, 28, 28)return imgs # 输出为64张大小为(1, 28, 28)的图像
## 创建生成器,判别器对象
generator = Generator()
discriminator = Discriminator()## 首先需要定义loss的度量方式 (二分类的交叉熵)
criterion = torch.nn.BCELoss()## 其次定义 优化函数,优化函数的学习率为0.0003
## betas:用于计算梯度以及梯度平方的运行平均值的系数
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))## 如果有显卡,都在cuda模式中运行
if torch.cuda.is_available():generator = generator.cuda()discriminator = discriminator.cuda()criterion = criterion.cuda()
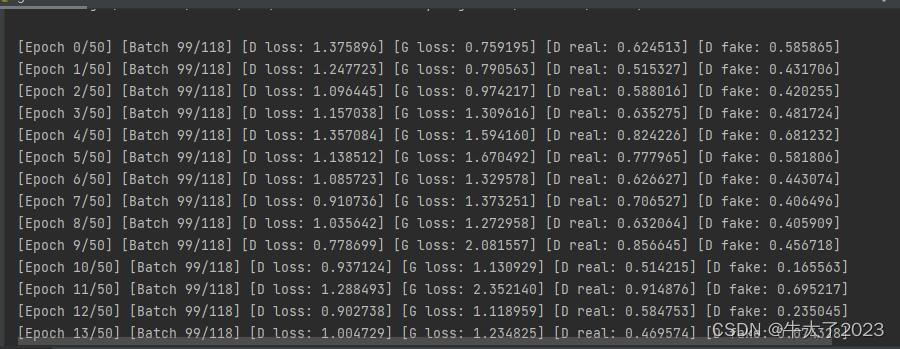
for epoch in range(n_epochs): # epoch:50for i, (imgs, _) in enumerate(dataloader): # imgs:(64, 1, 28, 28) _:label(64)imgs = imgs.view(imgs.size(0), -1) # 将图片展开为28*28=784 imgs:(64, 784)real_img = Variable(imgs).cuda() # 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度real_label = Variable(torch.ones(imgs.size(0), 1)).cuda() ## 定义真实的图片label为1fake_label = Variable(torch.zeros(imgs.size(0), 1)).cuda() ## 定义假的图片的label为0real_out = discriminator(real_img) # 将真实图片放入判别器中loss_real_D = criterion(real_out, real_label) # 得到真实图片的lossreal_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好## 计算假的图片的损失## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新z = Variable(torch.randn(imgs.size(0), latent_dim)).cuda() ## 随机生成一些噪声, 大小为(128, 100)fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。fake_out = discriminator(fake_img) ## 判别器判断假的图片loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的lossfake_scores = fake_out## 损失函数和优化loss_D = loss_real_D + loss_fake_D # 损失包括判真损失和判假损失optimizer_D.zero_grad() # 在反向传播之前,先将梯度归0loss_D.backward() # 将误差反向传播optimizer_D.step() # 更新参数z = Variable(torch.randn(imgs.size(0), latent_dim)).cuda() ## 得到随机噪声fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片output = discriminator(fake_img) ## 经过判别器得到的结果## 损失函数和优化loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的lossoptimizer_G.zero_grad() ## 梯度归0loss_G.backward() ## 进行反向传播optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数## 打印训练过程中的日志## item():取出单元素张量的元素值并返回该值,保持原元素类型不变if ( i + 1 ) % 100 == 0:print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"% (epoch, n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(), fake_scores.data.mean()))## 保存训练过程中的图像batches_done = epoch * len(dataloader) + iif batches_done % sample_interval == 0:save_image(fake_img.data[:25], "./images/%d.png" % batches_done, nrow=5, normalize=True)
torch.save(generator.state_dict(), './generator.pth')
torch.save(discriminator.state_dict(), './discriminator.pth')
部分运行截图: