标题:MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
作者:Zizhang Wu , Guilian Chen , Yuanzhu Gan , Lei Wang , Jian Pu
来源:2023 IEEE International Conference on Robotics and Automation (ICRA 2023)
这是佳佳怪分享的第2篇文章
摘要
多视角雷达-摄像头融合三维物体检测为自动驾驶提供了更远的检测范围和更多有用的功能,尤其是在恶劣天气下。目前的雷达-相机融合方法提供了多种将雷达信息与相机数据融合的设计。然而,这些融合方法通常采用多模态特征之间的直接串联操作,忽略了雷达特征的语义一致性和模态之间的充分相关性。在本文中,我们提出了一种新颖的多视图雷达-摄像机融合方法 MVFusion,以实现雷达特征的语义对齐并增强跨模态信息交互。为此,我们通过语义对齐雷达编码器(SARE)将语义对齐注入雷达特征,生成图像引导的雷达特征。然后,我们提出了雷达引导融合变换器(RGFT)来融合雷达和图像特征,通过交叉注意机制从全局范围加强两种模态的相关性。大量实验表明 MVFusion 在 nuScenes 数据集上实现了最先进的性能(51.7% NDS 和 45.3% mAP)。我们将在论文发表后公布我们的代码和训练有素的网络。

图 1. 基于摄像头的方法 [13] 和我们的 MVFusion 的探测对比。(a) 图像和雷达输入,雷达点的颜色表示与雷达的距离。(b) 3D 检测地面实况。© 基于摄像头的方法 [13] 的结果,该方法未能检测到远处的汽车和近处的行人。(d) 我们的方法利用语义对齐的雷达信息进行了充分的雷达-摄像机融合,成功检测到了丢失的汽车和行人。
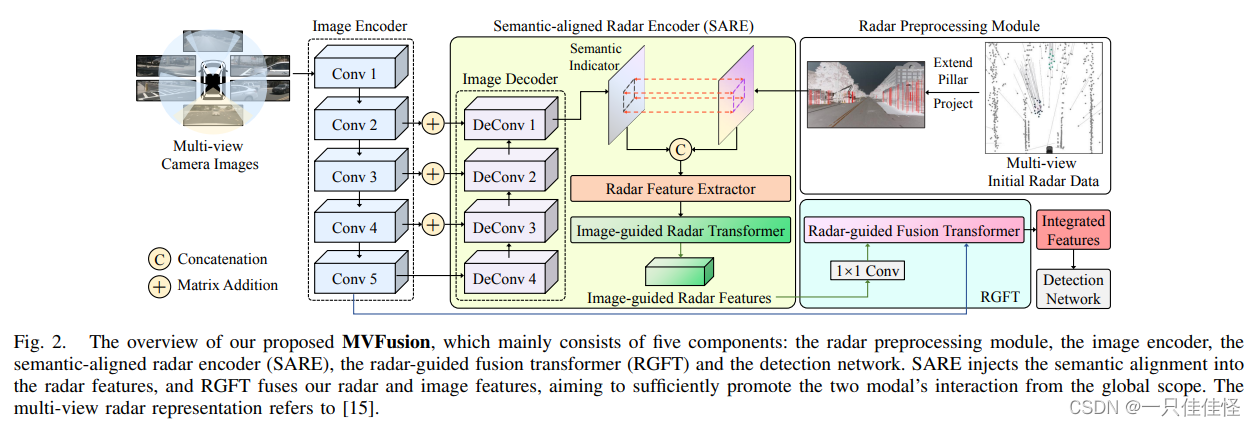
图 2. 我们提出的 MVFusion 概览,主要由五个部分组成:雷达预处理模块、图像编码器、语义对齐雷达编码器(SARE)、雷达引导融合变换器(RGFT)和检测网络。SARE 将语义配准注入雷达特征,而 RGFT 则 RGFT 融合雷达和图像特征,旨在从全局范围充分促进两种模态的互动。多视角雷达表示法参考了文献[15]。
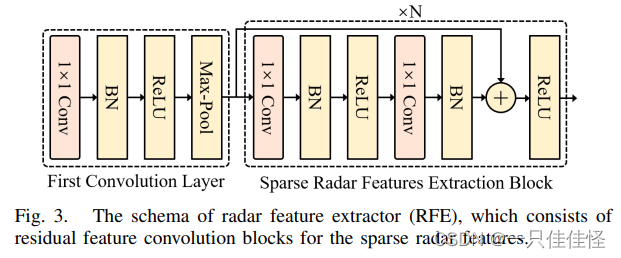
图 3. 雷达特征提取器(RFE)的结构图,其中包括 用于稀疏雷达特征的残差特征卷积块。
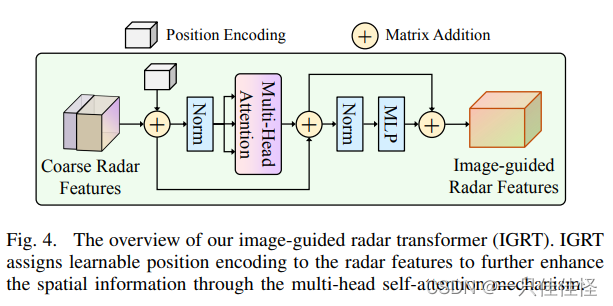
图 4. 图像制导雷达变换器(IGRT)概览。IGRT 为雷达特征分配可学习的位置编码,以通过多头自注意机制进一步增强 空间信息。
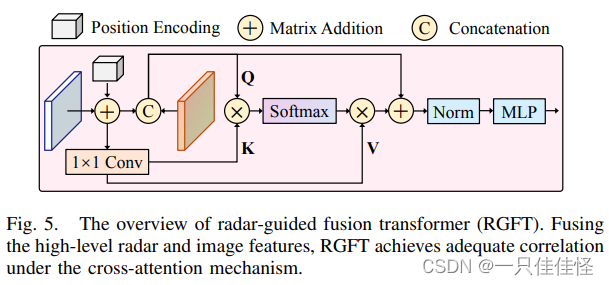
图 5. 雷达引导融合变换器(RGFT)概述。RGFT 融合了高级雷达和图像特征,在交叉注意机制下实现了充分的相关性。

图 6. 我们的方法与之前的方法 [13] 的环视检测结果对比。我们用 黄色圆圈表示我们的方法,蓝色圆圈表示 [13] 的方法。我们的方法在不同视角下都能实现正确的目标检测,而我们的方法在不同视角下都能实现充分的目标检测。在不同视角下,我们的方法都能正确检测到物体,其中语义对齐的雷达特征与视觉特征之间充分的雷达-相机互动为三维检测提供了更多有用的线索。
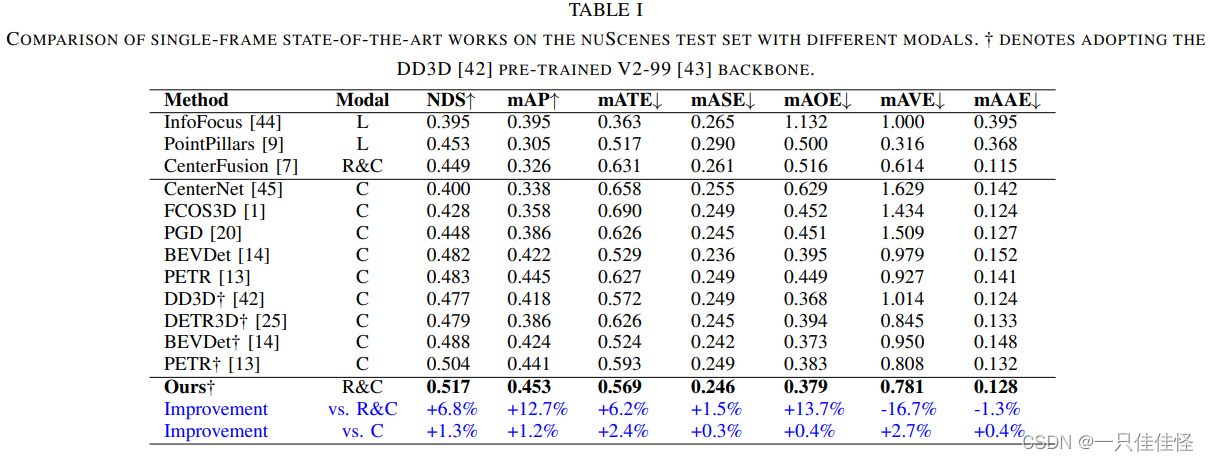
表1. 在 nuscenes 测试集上使用不同模态的单帧最先进作品比较。表示采用 dd3d [42] 预训练 v2-99 [43] 主干网
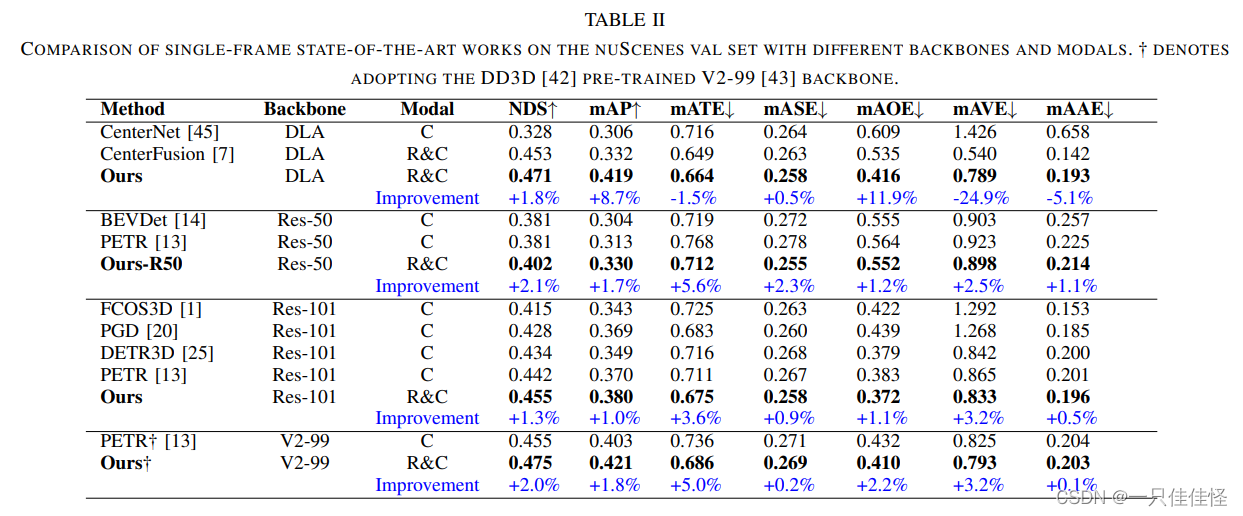
表2. 采用不同骨干网和模态对 nuscenes val 集进行的单帧最新研究成果比较。† 表示采用 dd3d [42] 预先训练的 v2-99 [43] 骨架。
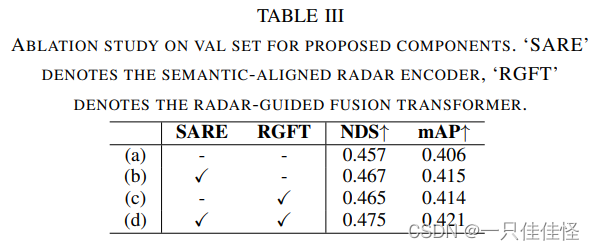
表3. 对拟议组件的值集进行消融研究。sare "表示语义对齐雷达编码器,"rgft "表示雷达制导融合变换器。
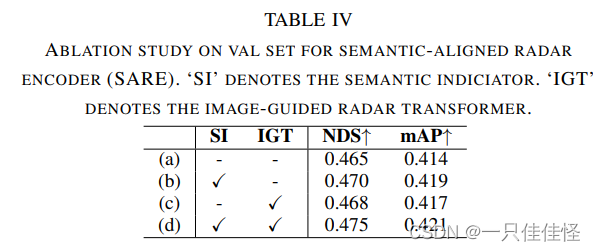
表4. 语义对齐雷达编码器(SARE)阀值集消融实验。si "表示语义指示器。igt "表示图像制导雷达变换器。

表5. 雷达制导融合变压器(RGFT)阀组烧蚀研究 变压器(RGFT)。w "表示 “有”,"w/o "表示 “无”。表示 “无”。q’、‘k’、‘v’表示查询、键、值。IMG. 表示图像。concat.’ 表示 “连接”。
结论
本文提供了一种用于三维物体检测的新型多视图雷达-摄像机融合方法 MVFusion,该方法实现了语义对齐雷达特征和鲁棒跨模态信息交互。具体来说,我们提出了语义对齐雷达编码器(SARE)来提取图像引导的雷达特征。在提取雷达特征后,我们提出了雷达引导融合变换器(RGFT),将增强的雷达特征与高级图像特征进行融合。在 nuScenes 数据集上进行的大量实验验证了我们的模型达到了单帧雷达-摄像机融合的最先进性能。未来,我们将汇集多视角相机的时空信息,进一步促进雷达-相机融合。