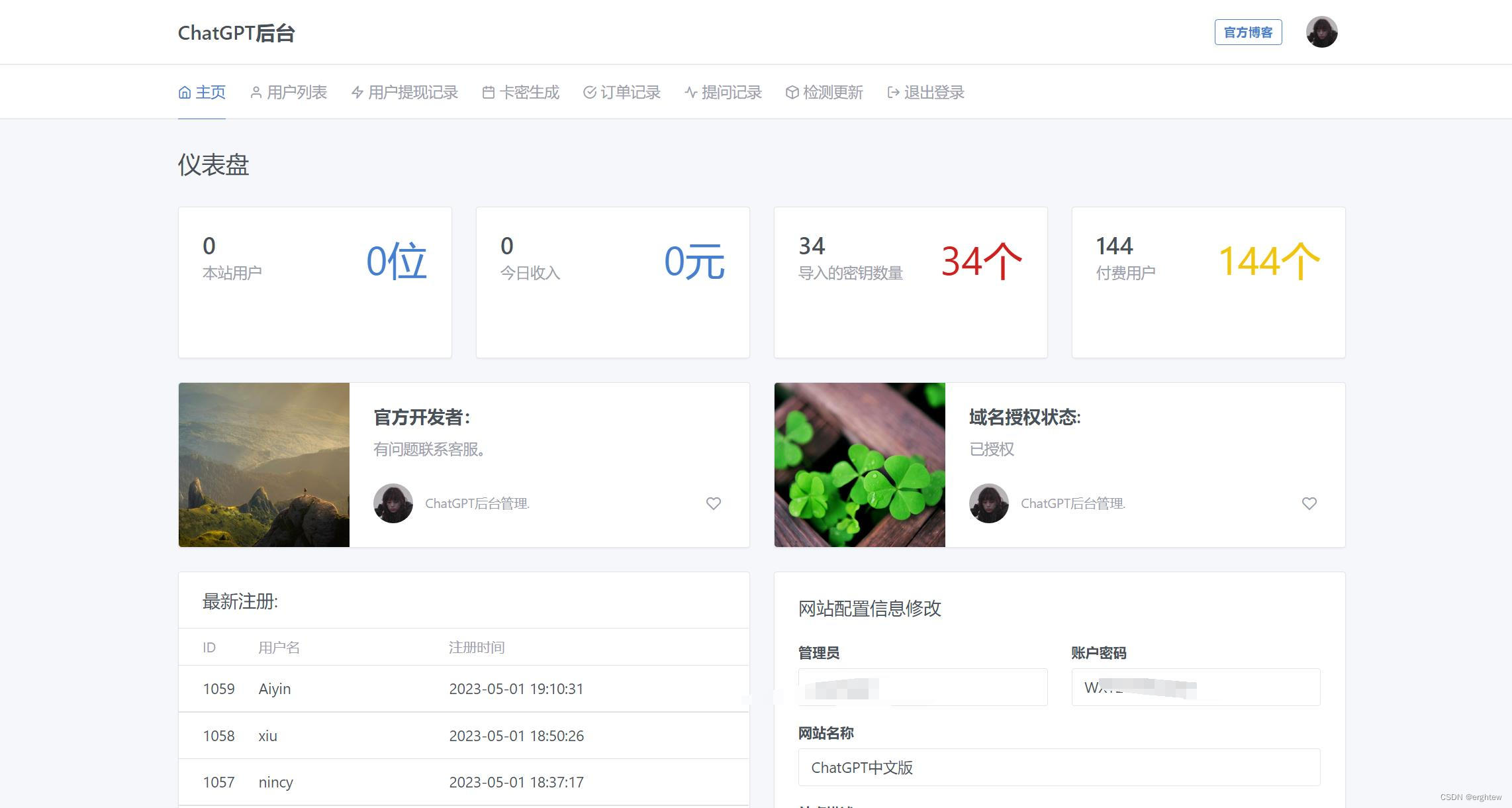
1. temperature 的作用机制
GPT 中的 temperature 参数调整模型输出的随机性。随机性大可以理解为多次询问的回答多样性、回答更有创意、回答更有可能没有事实依据。随机性小可以理解为多次询问更有可能遇到重复的回答、回答更接近事实(更接近训练数据)。
Temperature 参数通常用于调整 softmax 函数的输出,用于增加或减少模型对不同类别的置信度。具体来说,softmax 函数将模型对每个类别的预测转换为概率分布。Temperature 参数可以看作是一个缩放因子,它可以增加或减少 softmax 函数输出中每个类别的置信度。
下面从模型的计算逻辑上来看 temperature 的作用机制。
当模型在根据上文计算下一个 token 时,他会先得到一组候选 token 及每一个 token 的概率 (原始概率,原始概率取决于训练方法、训练采用的数据和 prompt)。然后使用数学方法 softmax调整候选项的概率分布。这时 temperature 就会起作用。
忽略 softmax 的内部算法,直接看影响。
假设我们有这几个单词和他们出现在下一个位置的概率:
the: 0.5
a: 0.25
an: 0.15
some: 0.08
this: 0.02
当应用 temperature 时,他们的概率会被改变。下图表示在不同 temperature 下 softmax 对概率的影响
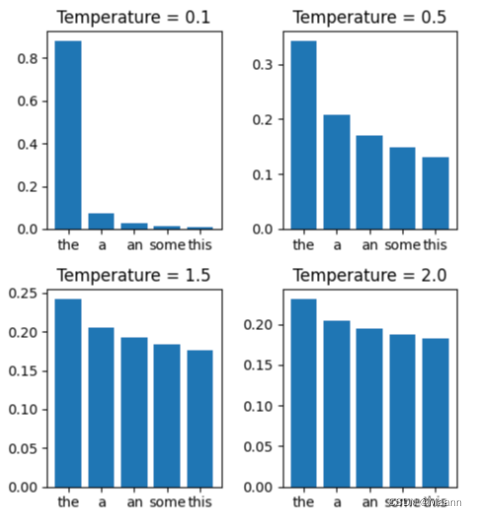
可以看到,当 temperature 更大时,模型的选择更加随机(每个 token 的概率更加接近), 给予原本低概率的 token 更大的选择机会,从而产生更多样化和创意的输出。大的更大,小的更小。
相反, temperature 更小使模型的选择更加确定,给予原本高概率的 token 更大的选择机 会,从而产生更集中和一致的输出。大的更小,小的更大。
当 temperature = 0 =0 =0 时,模型在每次选择 token时只选择概率最大的那一个,于是我们每次询 问 (同样的prompt) 都会得到完全相同的回答。
2. top_p 的作用机制
Top P 参数是指在生成文本等任务中,选择可能性最高的前 P 个词的概率累加和。这个参数被称为 Top P,也称为 Nucleus Sampling。
top_ p 对回答的影响时机,是在 temperature 调整完 token 概率之后。但是官方建议不要同 时使用这两个参数。
top_p 弃数接受的是一个累积概率, top_p 的大小影响到候选 token 的数量。
我们还是假设有这几个单词可供选择
the: 0.5
a: 0.25
an: 0.15
some: 0.08
this: 0.02
假设我们设定 top_p = 0.7 =0.7 =0.7 ,模型使用以下逻辑选择部分单词加入备选集合
1、对所有单词按照概率从大到小进行排序
2、将富选集合中的概率逐个相加,当超过 0.7 时停止处理后面的单词
考虑 the,将它加入备选集合。他的概率(前面的概率之和是 0 ) 小于 0.7 ,于是继续考虑下一 个羊词。
考虑 a$,他的概率是 0.25 ,加上前面的所有概率得到 0.75 。这时已经超过了 0.7 的阈值。a 会被加入家选集合,但是不再处理后面的单词。
现在集合中有 the 和 a 两个单词,模型会根据概率进行选择(the 还是更容易选中)
为什么不建议同时使用
这一部分暂时还没想明白,也欢迎知道细节的小伙伴一起讨论。
从资料上看,如果同时使用top_p 和 temperature 会导致模型的输出更不可控,可能导致意 外的输出。
如何选择
使用 temperature 比 top_p 更容易控制创造性的回答。当需要获得更有创意、更多样性 的回答时,可以把 temperature 设置为2。当需要多次询问且获得一致性的回答时,可以 把 temperature 设置为 0 。
top_p 比 temperature 更容易控制输出的质量。top_p 可以把较低概率的单词滤掉,避免得到低质量的回答, 也避免得到不常见的单词。
有些研究中表明,top_p 越高,输出的内容会越长。但是这种现象在 ChatGPT 中并不明 显, 可能是因为 ChatGPT 的训练数据集已经有比较高的质量,避免了低概率单词的输出。
在之前 Hugging Face 上的 prompt 比赛中,为了保证所有选手的 prompt 能够有统一 的评价标准,也为了保证每次询问 prompt 都得到完全一样的回答,评判系统会同时设置 temperature =0, top_ p=0 。