目录
特征预处理
1、简述
2、内容
3、归一化
3.1、鲁棒性
3.2、存在的问题
4、标准化
⭐所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你😊
特征预处理
1、简述

什么是特征预处理:scikit-learn的解释:
provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
翻译过来:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
详述:
特征预处理是机器学习和数据分析中的一个重要步骤,它旨在将原始数据转换为适合机器学习算法的形式,以提高模型的性能和稳定性。特征预处理涵盖了一系列数据转换和处理操作,用于清洗、归一化、缩放、编码等,以确保输入特征的质量和一致性。以下是特征预处理的一些常见操作和方法:
- 数据清洗和处理:处理缺失值、异常值和噪声,确保数据的完整性和准确性。常见的方法包括填充缺失值、平滑噪声、剔除异常值等。
- 特征缩放:将不同尺度的特征缩放到相似的范围,以避免某些特征对模型的影响过大。常见的特征缩放方法有标准化(Z-score标准化)和归一化(Min-Max缩放)。
- 特征选择:选择对目标变量有重要影响的特征,减少维度和噪声,提高模型的泛化能力。常见的特征选择方法有基于统计指标的方法(如方差选择、卡方检验)、基于模型的方法(如递归特征消除)、以及基于嵌入式方法(如L1正则化)。
- 特征转换:将原始特征转换为更适合模型的形式,如多项式特征、交叉特征、主成分分析(PCA)等。这可以帮助模型更好地捕捉数据的模式和结构。
- 特征编码:将非数值型的特征转换为数值型的形式,以便机器学习算法处理。常见的编码方法有独热编码(One-Hot Encoding)和标签编码(Label Encoding)。
- 文本特征提取:将文本数据转换为数值特征表示,如词袋模型、TF-IDF特征提取等,以便用于文本分析和机器学习。
- 特征组合和交叉:将多个特征进行组合或交叉,创建新的特征以捕捉更多的信息。这有助于挖掘特征之间的相互作用。
- 数据平衡处理:在处理不平衡数据集时,可以使用欠采样、过采样等方法来平衡正负样本的数量,以避免模型偏向于多数类。
特征预处理的目标是使数据更适合机器学习模型,提高模型的性能和稳定性,并且能够更好地捕捉数据的特征和模式。正确的特征预处理可以显著影响机器学习模型的结果和效果。不同的数据类型和问题可能需要不同的特征预处理方法,因此在进行特征预处理时需要根据具体情况进行选择和调整。
2、内容
包含内容:数值型数据的无量纲化:归一化、标准化 (二者放在后面详述)
什么是无量纲化:
无量纲化(Dimensionality Reduction)是特征工程的一部分,指的是将数据特征转换为合适的尺度或形式,以便更好地适应机器学习算法的要求。无量纲化的目的是减少特征的维度,同时保留数据中的重要信息,从而降低计算成本、避免维度灾难,并提高模型的性能和泛化能力。
无量纲化可以分为两种常见的方法:
①特征缩放(Feature Scaling):特征缩放是将特征的数值范围调整到相似的尺度,以便机器学习算法更好地工作。特征缩放的常见方法包括归一化和标准化。
归一化(Min-Max Scaling):将特征缩放到一个特定的范围,通常是[0, 1]。
标准化(Z-score Scaling):将特征缩放为均值为0,标准差为1的分布。
②降维(Dimensionality Reduction):降维是将高维特征空间映射到低维空间,以减少特征数量并去除冗余信息,从而提高计算效率和模型性能。常见的降维方法包括主成分分析(PCA)和线性判别分析(LDA)等。
主成分分析(PCA):通过线性变换将原始特征投影到新的坐标轴上,使得投影后的数据具有最大的方差。这些新坐标轴称为主成分,可以按照方差的大小选择保留的主成分数量,从而降低数据的维度。
线性判别分析(LDA):在降维的同时,尽可能地保留类别之间的区分性信息,适用于分类问题。
无量纲化可以帮助解决特征维度不一致、尺度不同等问题,使得机器学习算法能够更准确地学习数据的模式和结构。选择适当的无量纲化方法取决于数据的特点、问题的要求以及模型的性能。
特征预处理使用的API:sklearn.preprocessing
为什么我们要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
3、归一化
定义:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:
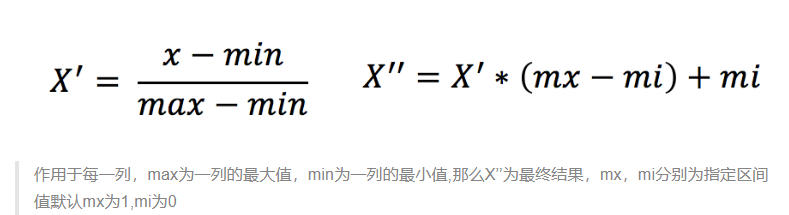
API:
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
下面分析会用到一组数据,名为dating.txt。展现如下:


实现:
关键代码解读:
transfer = MinMaxScaler(feature_range=(2, 3)):
实例化一个MinMaxScaler转换器对象,其中feature_range=(2, 3)表示将数据缩放到范围为[2, 3]之间。
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]):
使用fit_transform方法将选定的特征('milage', 'Liters', 'Consumtime')进行最小-最大归一化处理。
fit_transform方法首先计算出特征的最小值和最大值,然后将数据进行线性缩放,使其在指定的范围内。
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/8/15 21:52
import pandas as pd
from sklearn.preprocessing import MinMaxScaler # 最大最小值归一化转换器'''
归一化处理。
关键代码解读:transfer = MinMaxScaler(feature_range=(2, 3)):实例化一个MinMaxScaler转换器对象,其中feature_range=(2, 3)表示将数据缩放到范围为[2, 3]之间。data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]):使用fit_transform方法将选定的特征('milage', 'Liters', 'Consumtime')进行最小-最大归一化处理。fit_transform方法首先计算出特征的最小值和最大值,然后将数据进行线性缩放,使其在指定的范围内。
'''
def min_max_demo():"""归一化演示"""data = pd.read_csv("data/dating.txt",delimiter="\t")print(data)# 1、实例化一个转换器类transfer = MinMaxScaler(feature_range=(2, 3))# 2、调用fit_transformdata = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])print("最小值最大值归一化处理的结果:\n", data)if __name__ == '__main__':min_max_demo()打印结果:

手动计算(取前9行数据):

计算坐标为(0,0)的元素,总的计算流程为:[(40920-14488)/(75136-14488)] * (3-2)+2 = 2.435826408≈2.43582641
该结果与程序吻合!!
3.1、鲁棒性
鲁棒性(Robustness)是指在面对异常值、噪声和其他不完美情况时,系统能够继续正常工作并保持良好性能的能力。在数据分析、统计学和机器学习中,鲁棒性是一个重要的概念,指的是算法或方法对异常值和数据扰动的敏感程度。一个鲁棒性强的方法在存在异常值或数据变动时能够保持稳定的性能,而鲁棒性较差的方法可能会对异常值产生过度敏感的响应。
在数据处理和分析中,鲁棒性的重要性体现在以下几个方面:
- 异常值处理:鲁棒性的方法能够有效地识别和处理异常值,而不会因为异常值的存在导致结果的严重偏差。
- 模型训练:在机器学习中,使用鲁棒性的算法可以减少异常值对模型训练的影响,防止过拟合,并提高模型的泛化能力。
- 特征工程:在特征工程过程中,选择鲁棒性的特征提取方法可以确保提取的特征对异常值不敏感。
- 统计分析:鲁棒性的统计方法能够减少异常值对统计分析结果的影响,使得分析结果更可靠。
一些常见的鲁棒性方法包括:
- 中位数(Median):在数据中,中位数对异常值的影响较小,相对于平均值具有更强的鲁棒性。
- 百分位数(Percentiles):百分位数可以帮助识别数据分布的位置和离散程度,对异常值的影响较小。
- Z-score标准化:Z-score标准化将数据转化为均值为0、标准差为1的分布,能够对抗异常值的影响。
- IQR(四分位距)方法:使用四分位距来定义异常值的界限,对极端值具有一定的容忍度。
- 鲁棒性回归:使用鲁棒性回归方法可以减少异常值对回归模型的影响。
总之,鲁棒性是数据分析和机器学习中一个重要的考虑因素,能够保证在现实世界中面对多样性和不确定性时,方法和模型仍能保持有效性和稳定性。
3.2、存在的问题
使用归一化处理,如果数据中异常点较多,会有什么影响?
在数据中存在较多异常点的情况下,使用归一化处理可能会受到一些影响。归一化是将数据缩放到特定范围内的操作,但异常点的存在可能会导致以下影响:
- 异常点的放大:归一化可能会导致异常点在缩放后的范围内被放大。如果异常点的值较大,归一化后它们可能会被映射到特定范围的边缘,从而导致数据在正常值范围内分布不均匀。
- 降低数据的区分性:异常点可能导致归一化后的数据失去一部分原始数据的分布特征。数据特征的差异性可能被模糊化,从而降低模型的区分能力和准确性。
- 对模型的影响:在机器学习中,模型通常会受到输入数据的影响。异常点可能会干扰模型的训练,使其难以捕捉正常数据的模式,导致模型的性能下降。
- 过拟合的风险:如果异常点被放大或影响了数据的分布,模型可能会过拟合异常点,而忽略了正常数据的重要特征。
为了应对异常点对归一化处理的影响,可以考虑以下策略:
- 异常点检测和处理:在进行归一化之前,首先要进行异常点检测,并根据异常点的性质和数量采取适当的处理措施。可以选择删除异常点、使用异常点修正方法或将异常点映射到更合理的范围。
- 使用鲁棒性方法:某些归一化方法对异常点的影响较小,例如中心化和缩放(例如Z-score标准化),它们对异常值的影响较小,因为它们基于数据的分布特性。
- 尝试其他特征预处理方法:如果异常点较多且归一化效果不好,可以尝试其他特征预处理方法,如对数变换、截断、缩尾等。
总之,处理异常点是特征预处理的重要步骤,需要根据数据的特点和问题的需求来选择适当的策略。
这里使用标准化解决这个问题
4、标准化
定义:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
公式:

标准差:

所以实际上标准化的公式为:


参数如下:
x为当前值
mean为平均值
N 表示数据的总个数
xi 表示第 i 个数据点
μ 表示数据的均值
归一化的异常点:

标准化的异常点:

对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
API:
sklearn.preprocessing.StandardScaler( )
处理之后每列来说所有数据都聚集在均值0附近标准差差为1
StandardScaler.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
import pandas as pd
from sklearn.preprocessing import StandardScaler # 标准化'''
sklearn.preprocessing.StandardScaler( ) 处理之后每列来说所有数据都聚集在均值0附近标准差差为1StandardScaler.fit_transform(X)X:numpy array格式的数据[n_samples,n_features]返回值:转换后的形状相同的array
'''
def stand_demo():"""标准化演示:return: None"""data = pd.read_csv("data/dating.txt", delimiter="\t")print(data)# 1、实例化一个转换器类transfer = StandardScaler()# 2、调用fit_transformdata = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])print("标准化的结果:\n", data)print("每一列特征的平均值:\n", transfer.mean_)print("每一列特征的方差:\n", transfer.var_)if __name__ == '__main__':stand_demo()输出结果:

手动计算验证(取前8行数据),公式回顾如下:
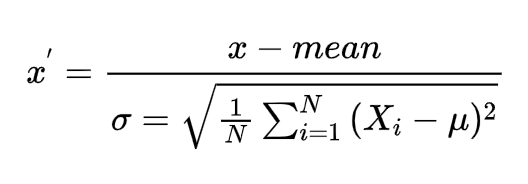
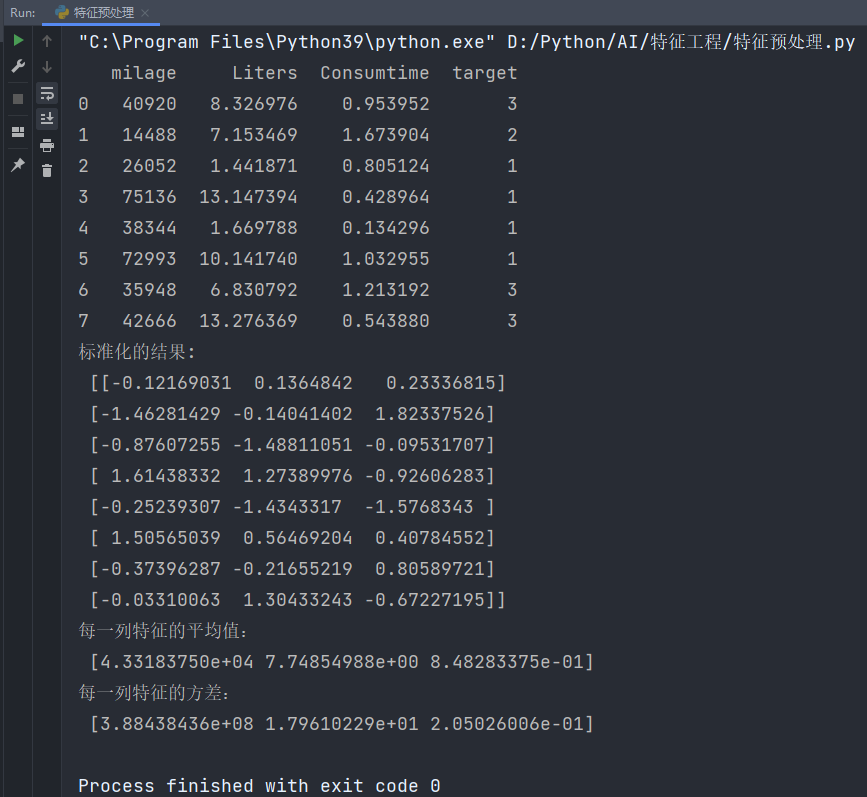
手动计算坐标为(0,0)的数据的标准化数据:
40920-43318.375=-2398.375
N=8,μ=43318.375 -> (40920-43318.375)^2+(14488-43318.375)^2+(26052-43318.375)^2+(75136-43318.375)^2+(38344-43318.375)^2+(72993-43318.375)^2+(35948-43318.375)^2+(42666-43318.375)^2=3107507487.875
3107507487.875 / 8 = 388438435.984375
根号下388438435.984375 = 19708.84156880802
最终:
x-mean=-2398.375
标准差=19708.84156880802
最后标准化后的数据结果为:-2398.375 / 19708.84156880802 = 0.121690307957813291 ≈ 0.12169031
与程序结果完全吻合!
标准化总结:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。