一、说明
一般来说,BERTopic 在开箱即用的模型中工作得很好。但是,当您有数百万个数据要处理时,使用基本模型处理数据可能需要一些时间。在这篇文章中,我将向您展示如何微调BERTopic中的一些参数并比较它们的结果。让我们潜入。
二、BERTopic 基本型号
我们首先检查类 BERTopic 中有哪些参数。有关详细检查,请查看此处的文件:BERTopic。在官方文档中,对每个参数及其默认值都有说明。在这里,我想挑一些参数来提及,因为这些参数在表示文档中的主题方面起着关键作用。
class BERTopic:def __init__(self,language: str = "english",top_n_words: int = 10,n_gram_range: Tuple[int, int] = (1, 1),min_topic_size: int = 10,nr_topics: Union[int, str] = None,low_memory: bool = False,calculate_probabilities: bool = False,seed_topic_list: List[List[str]] = None,embedding_model=None,umap_model: UMAP = None,hdbscan_model: hdbscan.HDBSCAN = None,vectorizer_model: CountVectorizer = None,ctfidf_model: TfidfTransformer = None,representation_model: BaseRepresentation = None,verbose: bool = False,)self.XXXself.XXX......- n_gram_range:默认为(1,1),即分别产生“新”和“约克”等主题词。如果要显示“纽约”,可以将此参数发送到 (1,2)。
- umap_model:UMAP(均匀流形近似和投影)是一种降维算法,通常用于高维数据的可视化。它的工作原理是查找保留原始高维空间结构的数据的低维表示形式。
- hdbscan_model:HDBSCAN(基于分层密度的带噪声应用程序空间聚类)是一种基于密度的聚类算法,可以识别数据集中任意形状和大小的聚类。它的工作原理是在数据中查找高密度区域并将其扩展为集群,同时还识别不属于任何集群的噪声点。
三、微调参数
我们已经了解了参数是什么以及它们的实际作用。现在,让我们对它们进行微调,并将结果与开箱即用的模型进行比较。同样,我们将使用我们之前准备的卡塔尔世界杯数据。如果您还没有下载 umap 和 hbdscan,请 pip 安装。
# Base Modelimport pandas as pd
import pickle
with open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)data = data.Tweet_processed.to_list()from bertopic import BERTopic
model_B = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics_B, probs_B = topic_model.fit_transform(data)# Fine-tuned Modelimport pandas as pd
import pickle
with open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)data = data.Tweet_processed.to_list()from umap import UMAP
from hdbscan import HDBSCANumap_model = UMAP(n_neighbors=3, n_components=3, min_dist=0.05)
hdbscan_model = HDBSCAN(min_cluster_size=80, min_samples=40,gen_min_span_tree=True,prediction_data=True)
from bertopic import BERTopicmodel_A = BERTopic(umap_model=umap_model,hdbscan_model=hdbscan_model,top_n_words=10,language='english',calculate_probabilities=True,verbose=True,n_gram_range=(1, 2)
)
topics_A, probs_A = model.fit_transform(data)UMAP:
- n_neighbors=3:此参数确定 UMAP 用于近似数据局部结构的最近邻数。在这种情况下,UMAP将在构造嵌入时查看每个数据点的三个最近邻。
- n_components=3:指定嵌入空间中的维数。默认情况下,UMAP 会将数据的维数减少到 2 维,但在这种情况下,它会将其减少到 3 维。
- min_dist=0.05:此参数控制嵌入空间中点之间的最小距离。较高的min_dist值将导致点之间的空间越大,这可以改善聚类的分离。
HDBSCAN:
- min_cluster_size=80:此参数指定形成聚类所需的最小点数。点少于此阈值的聚类将被标记为噪声。
- min_samples=40:此参数确定将点视为核心点所需的邻域样本数。核心点用于构建聚类,非核心点的点被归类为噪声。
- gen_min_span_tree=True:此参数告诉 HDBSCAN 在聚类之前构造输入数据的最小生成树。这有助于识别仅由几个点连接的聚类,其他聚类算法可能会遗漏这些点。
- prediction_data=True:此参数指示 HDBSCAN 存储有关数据的其他信息,例如每个群集中每个点的成员资格概率。此信息可用于下游分析和可视化。
四、比较结果
基本型号:
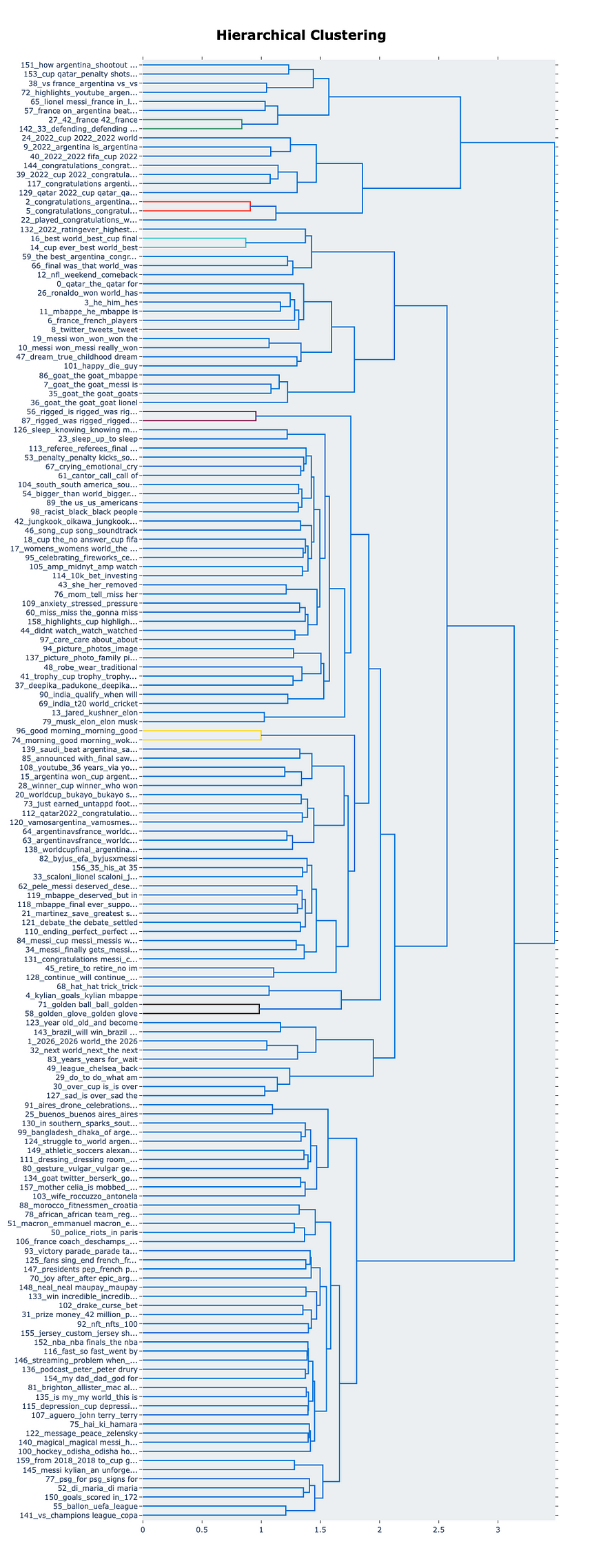
作者创建的基本模型
微调模型:
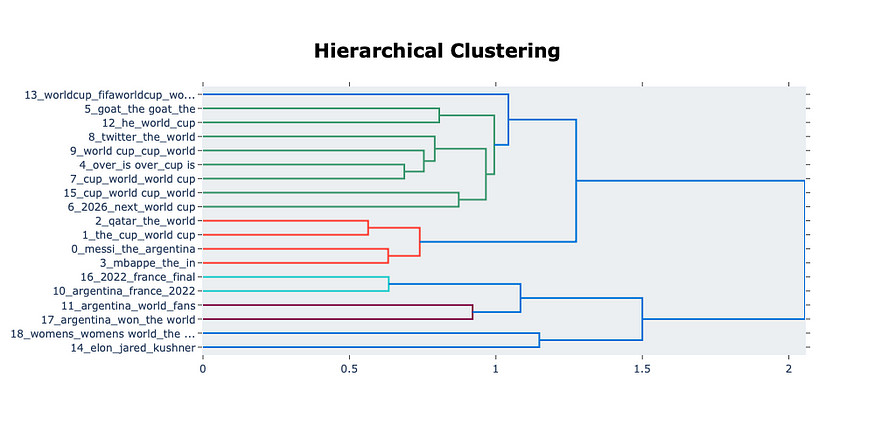
作者创建的微调模型
显然,在基本模型中生成了更多主题,这解释了处理大量文本需要很长时间的事实。同时,在微调模型中,根据参数中的设置创建的主题较少。
对于那些对结果如何随参数设置的不同组合而变化感兴趣的人。我将示例代码放在这里,您可以更改参数以检查不同的结果。
from bertopic import BERTopic
from umap import UMAP
from hdbscan import HDBSCAN# Define a list of parameters to try for UMAP
umap_params = [{'n_neighbors': 15, 'n_components': 2, 'min_dist': 0.1},{'n_neighbors': 10, 'n_components': 2, 'min_dist': 0.01},{'n_neighbors': 3, 'n_components': 2, 'min_dist': 0.001}
]# Define a list of parameters to try for HDBSCAN
hdbscan_params = [{'min_cluster_size': 100, 'min_samples': 100},{'min_cluster_size': 50, 'min_samples': 70},{'min_cluster_size': 5, 'min_samples': 50}
]# Loop over the parameter combinations and fit BERTopic models
for umap_param in umap_params:for hdbscan_param in hdbscan_params:# Create UMAP and HDBSCAN models with the current parameter combinationumap_model = UMAP(**umap_param)hdbscan_model = HDBSCAN(**hdbscan_param, gen_min_span_tree=True, prediction_data=True)# Fit a BERTopic model with the current parameter combinationmodel = BERTopic(umap_model=umap_model,hdbscan_model=hdbscan_model,top_n_words=10,language='english',calculate_probabilities=True,verbose=True,n_gram_range=(1, 2))topics, probs = model.fit_transform(data)# Visualize the hierarchy and save the figure to an HTML filefig = model.visualize_hierarchy()fig.write_html(f'model_umap_{umap_param}_hdbscan_{hdbscan_param}.html')
五、后记
关于BertTopic的应用知识点还很多,我们将在另外的文章中,逐步介绍之。谢谢阅读!
参考资料:
伯特
主题建模
深度学习
数据科学
蟒