爬取的基本步骤
很简单,主要是两大步
向url发起请求
这里注意找准对应资源的url,如果对应资源不让程序代码访问,这里可以伪装成浏览器发起请求。
解析上一步返回的源代码,从中提取想要的资源
这里解析看具体情况,一般是筛选标签之中的信息或者资源,有很多筛选的第三方包和方法
贴吧图片下载
导入 requests 和 lxml两个第三方包,没有需要下载
找到我们需要图片资源的==url ==, 比如我这里是 贴吧图片测试 http://c.tieba.baidu.com/p/5857827920
然后就是发起请求,拿到源代码,解析资源获得下载的url,下载资源到本地
import requests
from lxml import etree# 发起请求拿到网页源代码
index_url = 'http://c.tieba.baidu.com/p/5857827920'
response = requests.get(index_url).text# 解析源代码,筛选数据
selector = etree.HTML(response)
image_urls = selector.xpath('//img[@class="BDE_Image"]/@src')offset = 0
# 拿到url下载对应文件
for image_url in image_urls:image_content = requests.get(image_url).contentoffset += 1# 将数据写入本地with open("D:/桌面/image_test/{}.jpg".format(offset), 'wb') as f:f.write(image_content)酷狗音乐歌曲下载
步骤是差不多的,但是这里找 url 变化了一点,找到你想要下载的歌曲,并打开对应的播放页,如下:
按下F12或者是右键点击检查,我这里用的是 谷歌浏览器,打开网页的源代码
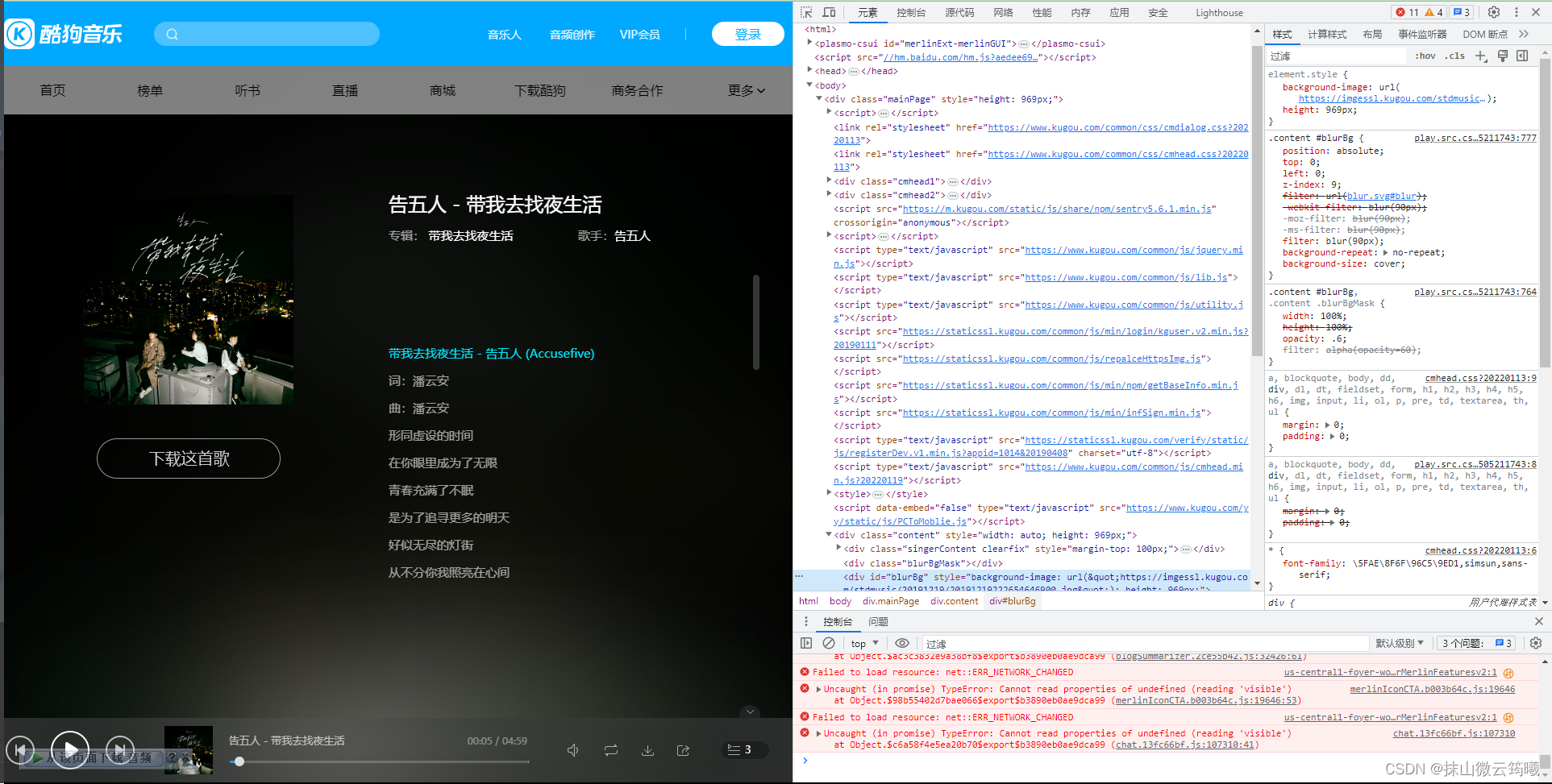
选择上面的网络或者network,点击打开
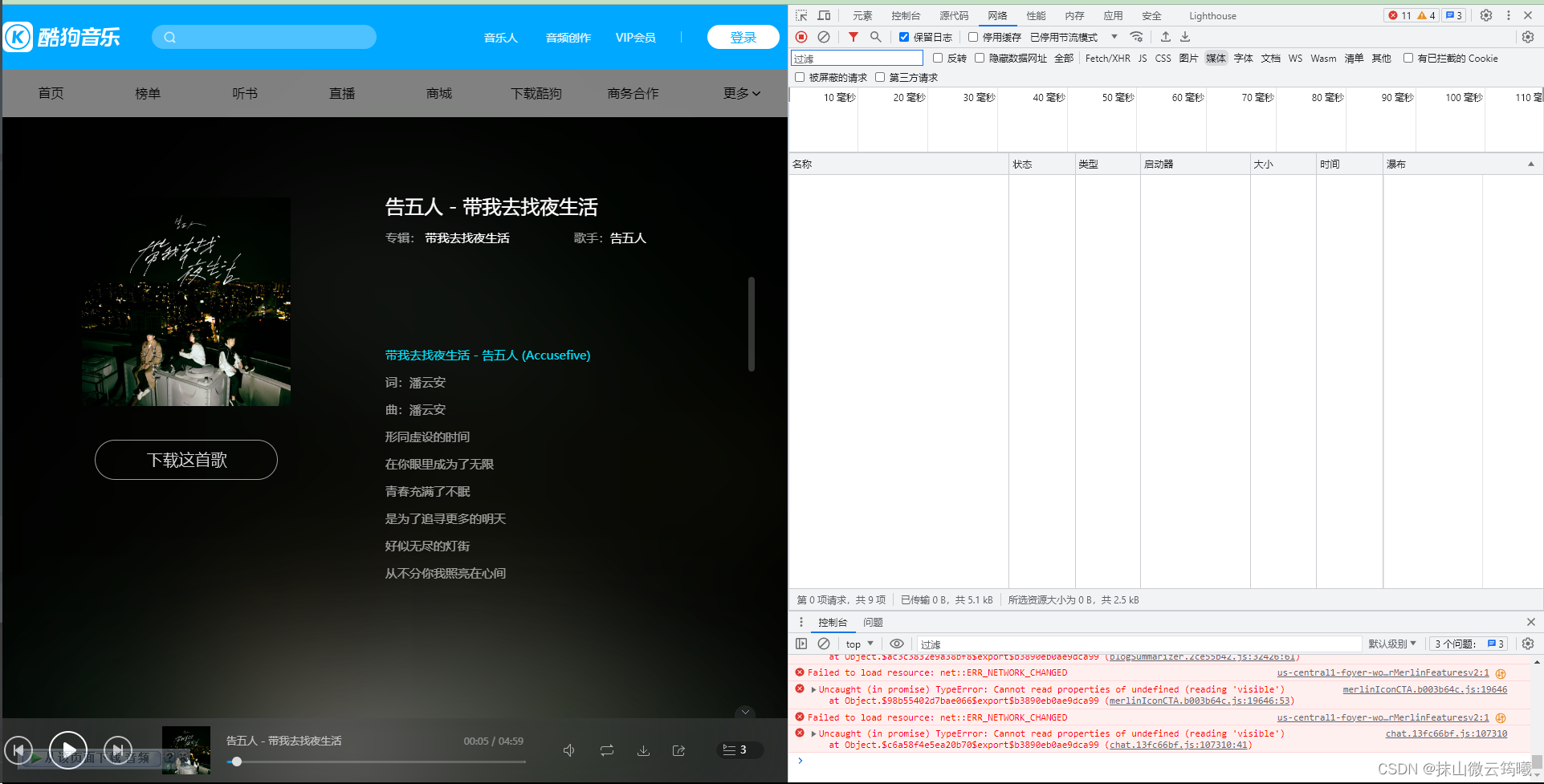
然后刷新一下网页,发起的网络请求就可以在这个界面看到,然后筛选媒体或者media,看到后缀为MP3的文件打开,多图示例:
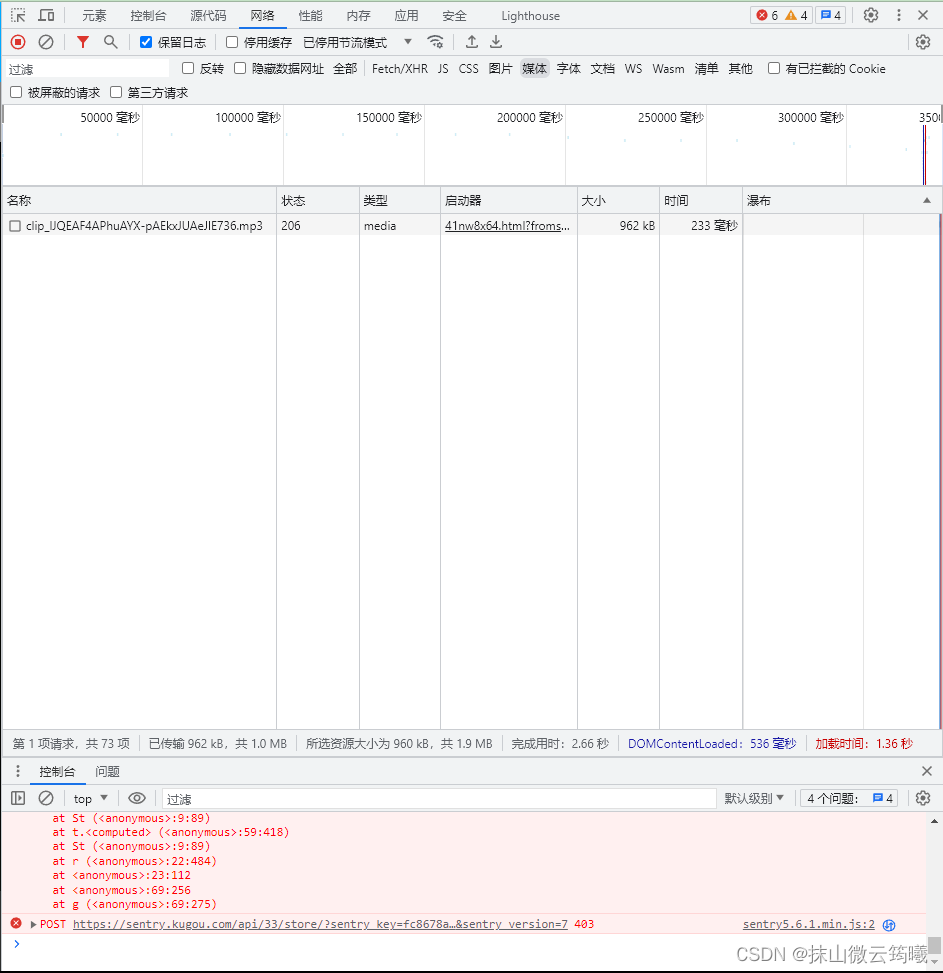
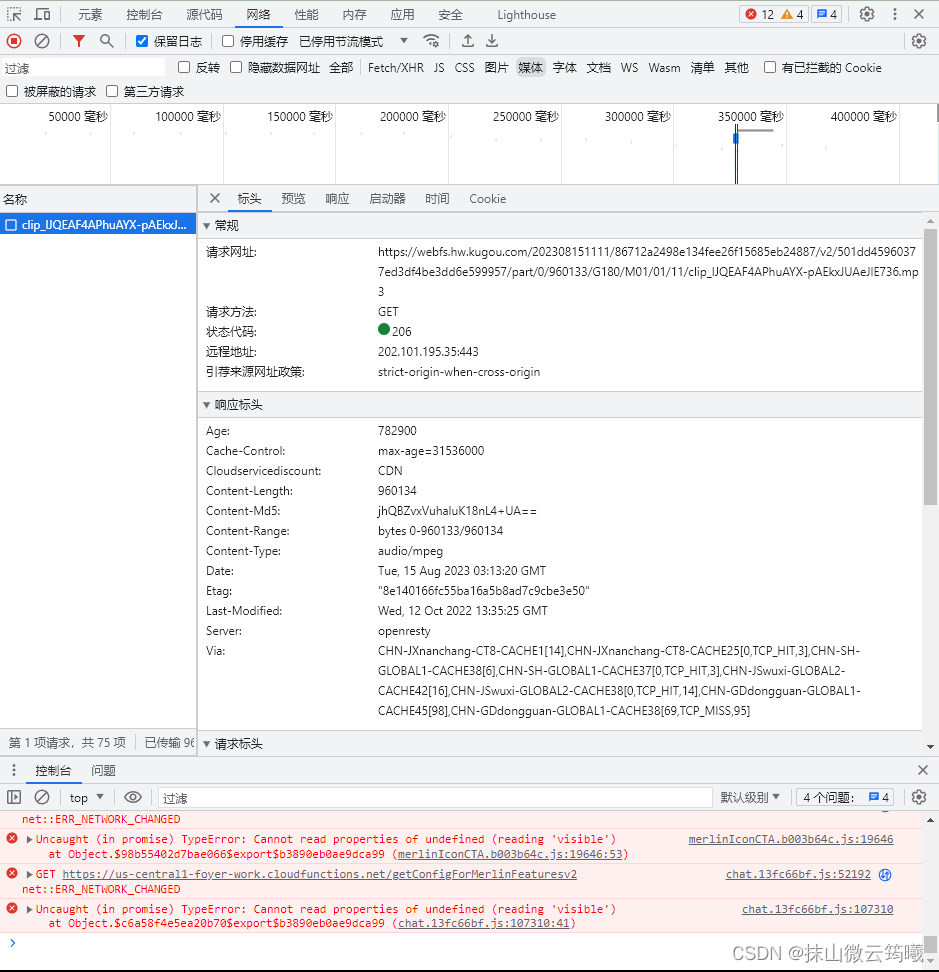
看到请求网址,复制它,到一个新页面打开试一下能不能播放,如果可以,那么我们要下载的资源的url就找到了。这个也就是代码中发起请求的那个资源url
直接上代码
import requests# url
m_url = 'https://webfs.hw.kugou.com/202308142239/c9d5212c77dac7daf7e3a144b167e5ef/KGTX/CLTX001/d632d77fc37a7f5fee87baf23a0944cb.mp3'# 获取源代码headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36m_resp = requests.get(m_url)'}# 这个headers就是请求标头,可以区别请求来源,会指明来源的操作系统浏览器这些信息,程序代码请求的话我们可以伪装成浏览器,加上这个标头。m_resp = requests.get(m_url, headers=headers)# 保存数据
with open("D:/桌面/test/geini.mp3", 'wb') as f:f.write(m_resp.content)请求标头这里可以找到
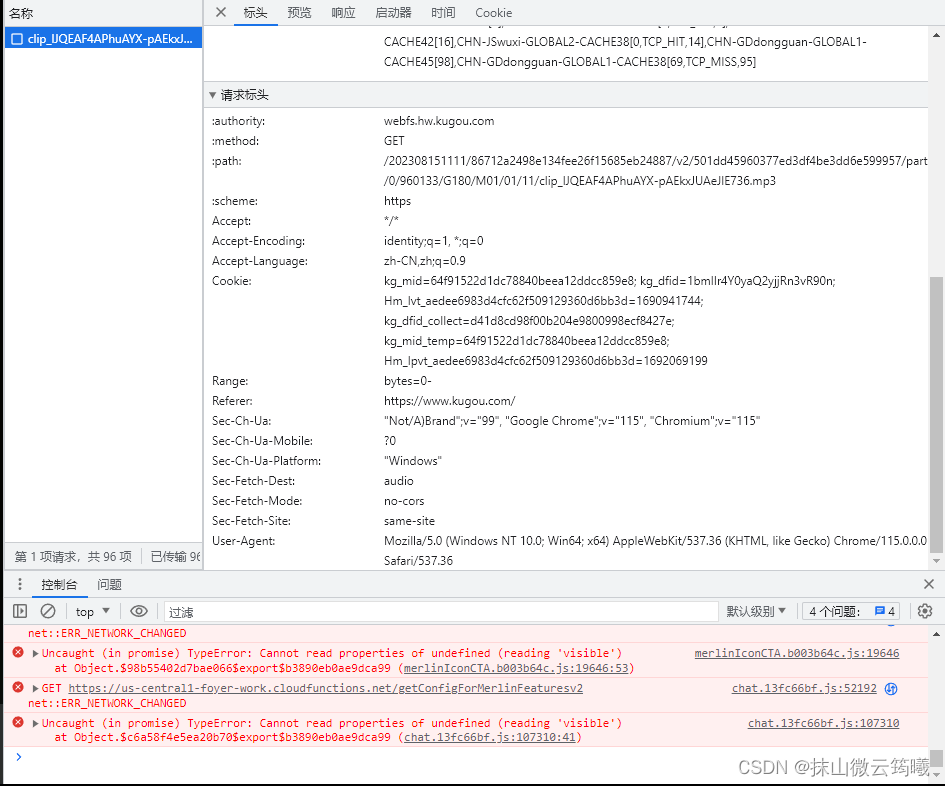
最下面的一个。