传送门
分布式定时任务系列1:XXL-job安装
分布式定时任务系列2:XXL-job使用
分布式定时任务系列3:任务执行引擎设计
分布式定时任务系列4:任务执行引擎设计续
Java并发编程实战1:java中的阻塞队列
引子
这篇文章的主要目不是讨论XXL-job的使用,而是要通过它的任务线程实现机制来分析java中阻塞队列的应用!
而这一切要从上周某天,公司一个普通的下午说起。
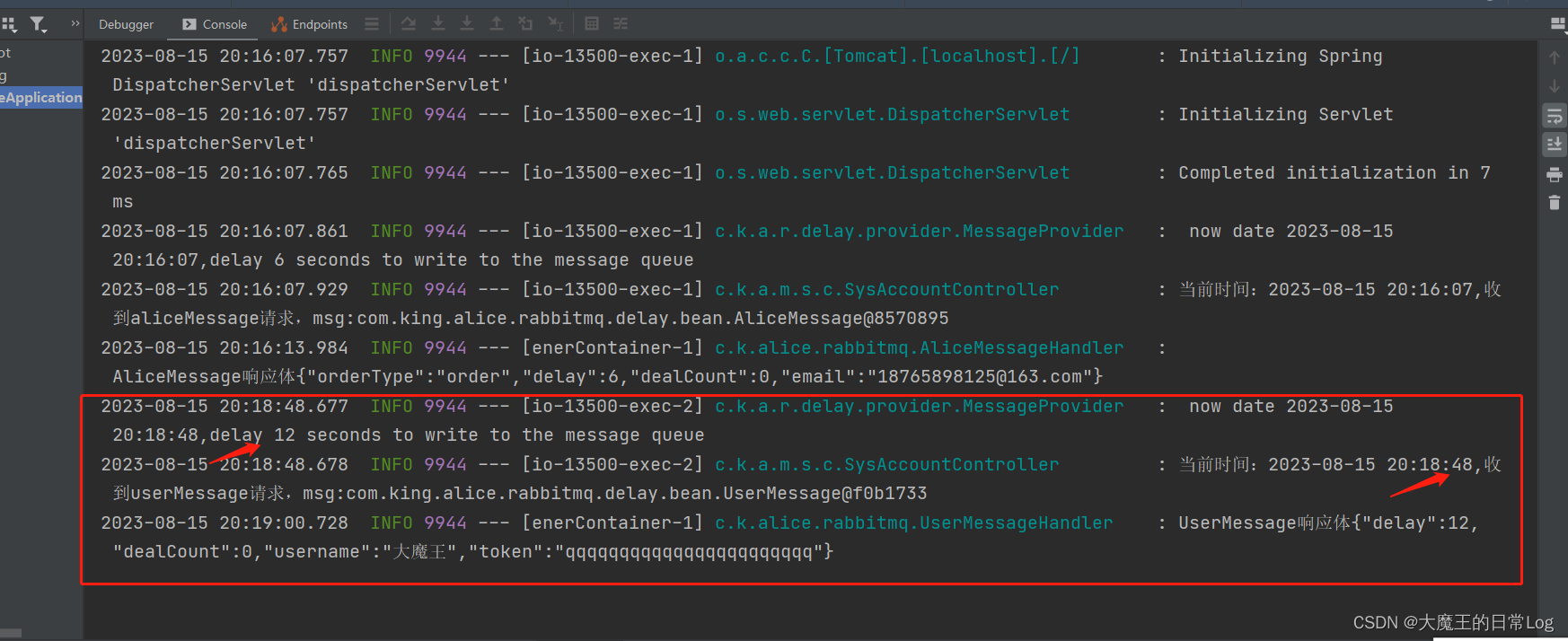
当时一个同事要添加任务,就随口问了一句:“阻塞处理策略选啥?”,我心里一惊,以前没注意过这个地方,每次都是默认的,也就是单机串行。
就是下图这个:
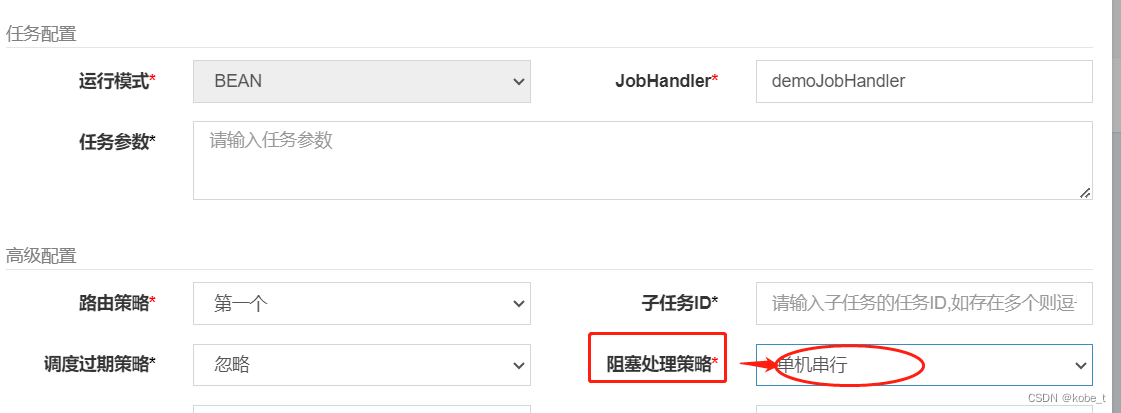
这里面有3个选项:
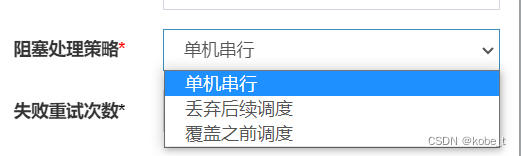
众人先是侃侃讨论了半天,后面再去翻了源码来查看,发现了下面的blockingQueue

阻塞队列
什么是阻塞队列
关于java阻塞队列,可以看看java中的阻塞队列。里面例子用到的是有界队列ArrayBlockingQueue,XXL-job里面用的是无界队列LinkedBlockingQueue。不论它们的相似及区别点,最重要的都是拥有阻塞特性。
要分析XXL-job是怎么使用阻塞队列的,就从XXL-job的调度触发机制入手!
什么是XXL-job任务
前面在分布式定时任务系列2:XXL-job使用里面介绍过XXL-job的使用,注册一个任务也很简单,只要在业务代码方法中打上@XxlJob注解即可!下面是官方提供的demo:
/*** 1、简单任务示例(Bean模式)*/@XxlJob("demoJobHandler")public void demoJobHandler() throws Exception {XxlJobHelper.log("XXL-JOB, Hello World.");for (int i = 0; i < 5; i++) {XxlJobHelper.log("beat at:" + i);TimeUnit.SECONDS.sleep(2);}// default success}开发步骤
1、任务开发:在Spring Bean实例中,开发Job方法;
2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
任务注册
对于XXL-job来说,是怎么注册并管理这些任务的呢?
在程序启动的时候,xxl-job-core包中的XxlJobSpringExecutor类由于实现了接口SmartInitializingSingleton,在Bean实例化完成时会调用afterSingletonsInstantiated()方法:
@Overridepublic void afterSingletonsInstantiated() {// init JobHandler Repository (for method)initJobHandlerMethodRepository(applicationContext);// refresh GlueFactoryGlueFactory.refreshInstance(1);// super starttry {super.start();} catch (Exception e) {throw new RuntimeException(e);}}在initJobHandlerMethodRepository(applicationContext)方法中,现在看一下这个方法的代码:该方法会提取所有SpringBean的实例中方法上添加了XxlJob注解的方法,并进行注册!
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {if (applicationContext == null) {return;}// init job handler from methodString[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false, true);for (String beanDefinitionName : beanDefinitionNames) {Object bean = applicationContext.getBean(beanDefinitionName);Map<Method, XxlJob> annotatedMethods = null; // referred to :org.springframework.context.event.EventListenerMethodProcessor.processBeantry {annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),new MethodIntrospector.MetadataLookup<XxlJob>() {@Overridepublic XxlJob inspect(Method method) {return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class);}});} catch (Throwable ex) {logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "].", ex);}if (annotatedMethods==null || annotatedMethods.isEmpty()) {continue;}for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {Method executeMethod = methodXxlJobEntry.getKey();XxlJob xxlJob = methodXxlJobEntry.getValue();// registregistJobHandler(xxlJob, bean, executeMethod);}}// ---------------------- job handler repository ----------------------private static ConcurrentMap<String, IJobHandler> jobHandlerRepository = new ConcurrentHashMap<String, IJobHandler>();public static IJobHandler loadJobHandler(String name){return jobHandlerRepository.get(name);}public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){logger.info(">>>>>>>>>>> xxl-job register jobhandler success, name:{}, jobHandler:{}", name, jobHandler);return jobHandlerRepository.put(name, jobHandler);}注册的方法就是registJobHandler(name, new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod)),会将XxlJob注解标记的方法,提取出对应的方法名,通过反射得到Method信息并实例为对应的MethodJobHandler,最后通过ConcurrentMap来管理,其中key是注任务名称,value为JobHandler实例。
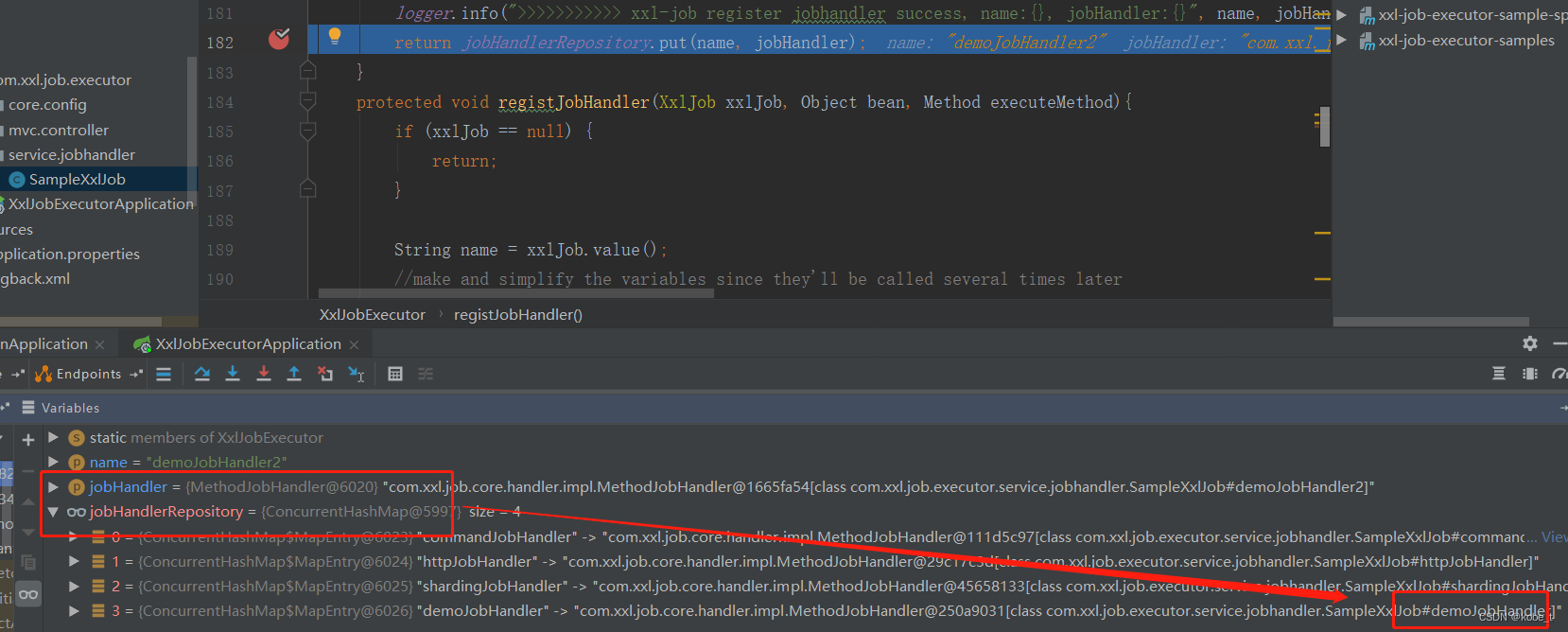
看到这里,不知你有没有一个疑问:这里的JobHandler里面并没有阻塞队列BlockingQueue,它们是怎么关联起来的呢?所以这里就要讨论一下XXL-job的任务执行!
XXL-job的任务执行
在后台管理手动触发一下测试任务,并把代码打上debug断点:
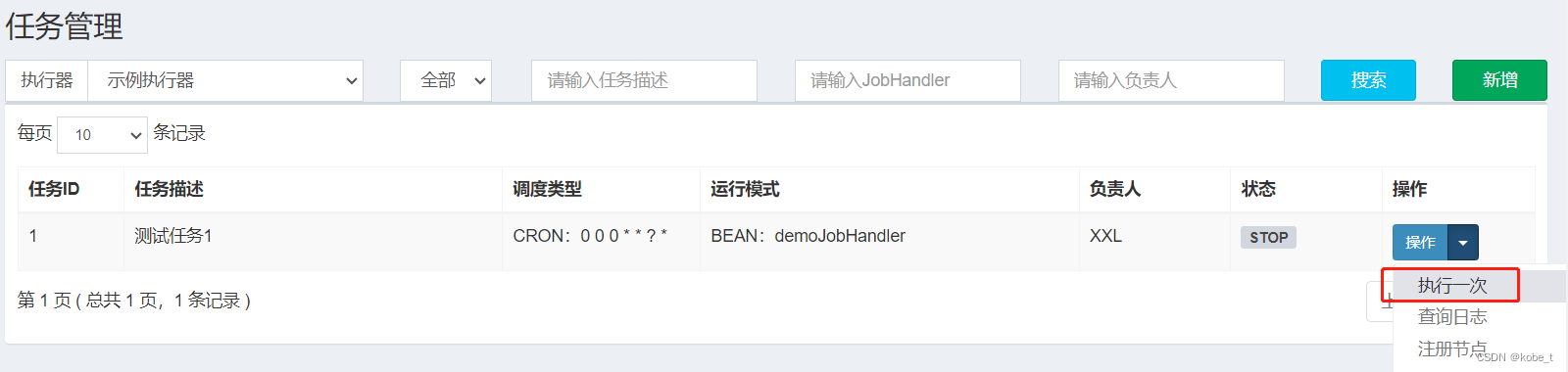
首先会发送后台请求:

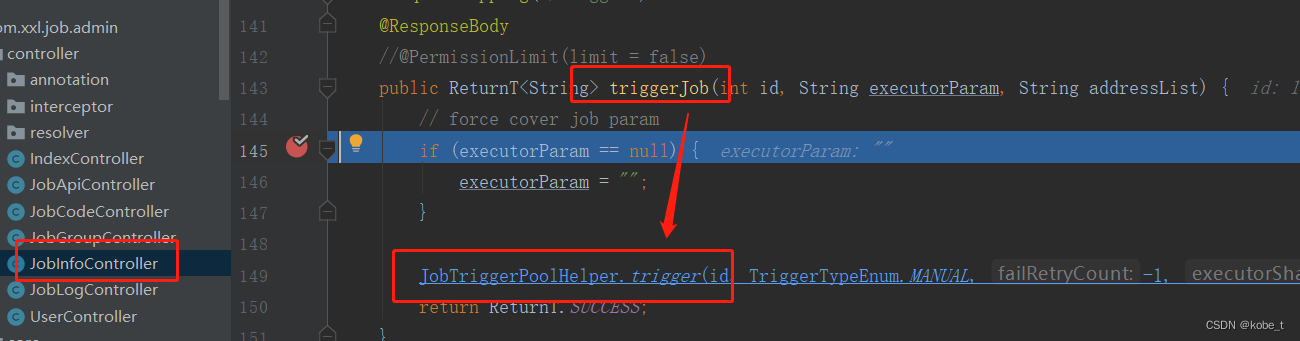 一路跟踪下去,会进入到XxlJobExecutor.runExecutor(TriggerParam triggerParam, String address)方法,最终是到ExecutorBizImpl.run(TriggerParam triggerParam)方法:
一路跟踪下去,会进入到XxlJobExecutor.runExecutor(TriggerParam triggerParam, String address)方法,最终是到ExecutorBizImpl.run(TriggerParam triggerParam)方法:
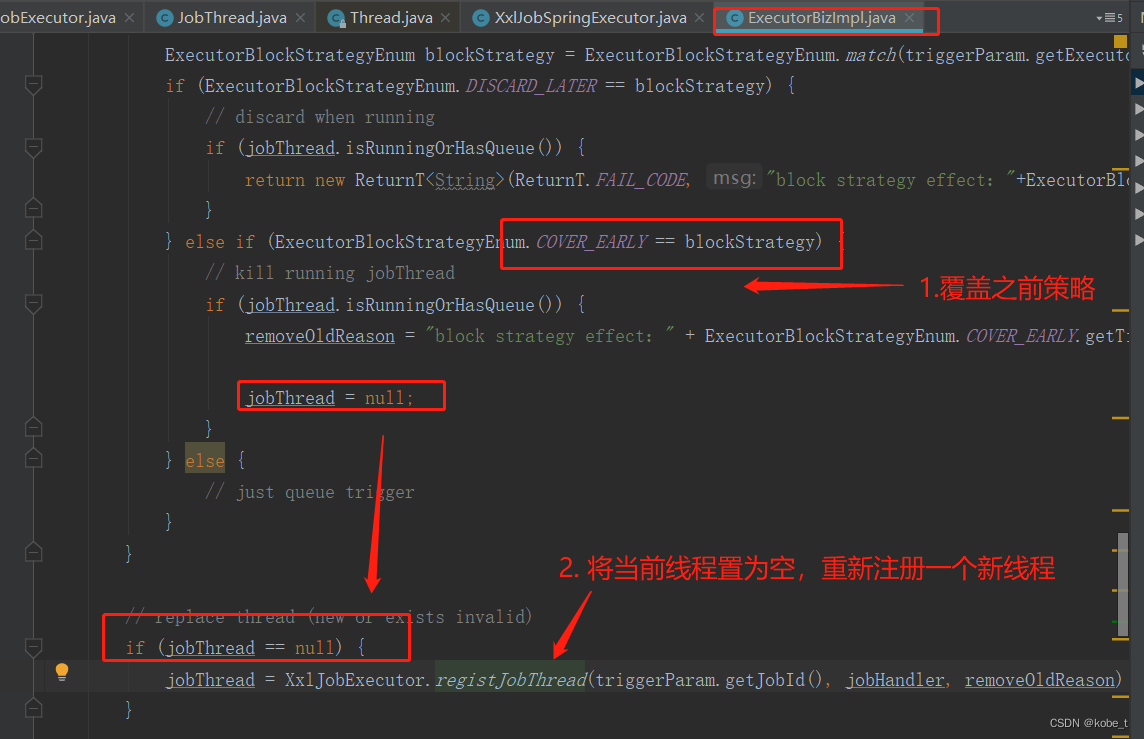
public ReturnT<String> run(TriggerParam triggerParam) {// load old:jobHandler + jobThreadJobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;String removeOldReason = null;// valid:jobHandler + jobThreadGlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());if (GlueTypeEnum.BEAN == glueTypeEnum) {// new jobhandlerIJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());// valid old jobThreadif (jobThread!=null && jobHandler != newJobHandler) {// change handler, need kill old threadremoveOldReason = "change jobhandler or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = newJobHandler;if (jobHandler == null) {return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");}}} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof GlueJobHandler&& ((GlueJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change handler or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {try {IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());jobHandler = new GlueJobHandler(originJobHandler, triggerParam.getGlueUpdatetime());} catch (Exception e) {logger.error(e.getMessage(), e);return new ReturnT<String>(ReturnT.FAIL_CODE, e.getMessage());}}} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof ScriptJobHandler&& ((ScriptJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change script or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = new ScriptJobHandler(triggerParam.getJobId(), triggerParam.getGlueUpdatetime(), triggerParam.getGlueSource(), GlueTypeEnum.match(triggerParam.getGlueType()));}} else {return new ReturnT<String>(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");}// executor block strategyif (jobThread != null) {ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// discard when runningif (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// kill running jobThreadif (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {// just queue trigger}}// replace thread (new or exists invalid)if (jobThread == null) {jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);}// push data to queueReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);return pushResult;}任务执行过程中,如果发现XXL-job对应的执行线程不存在,会创建一个新new Thread实例,并绑定前面的JobHandler实例,这样对于每一个任务都有一个单独的线程,也就将执行线程JobThread跟任务关联起来了:
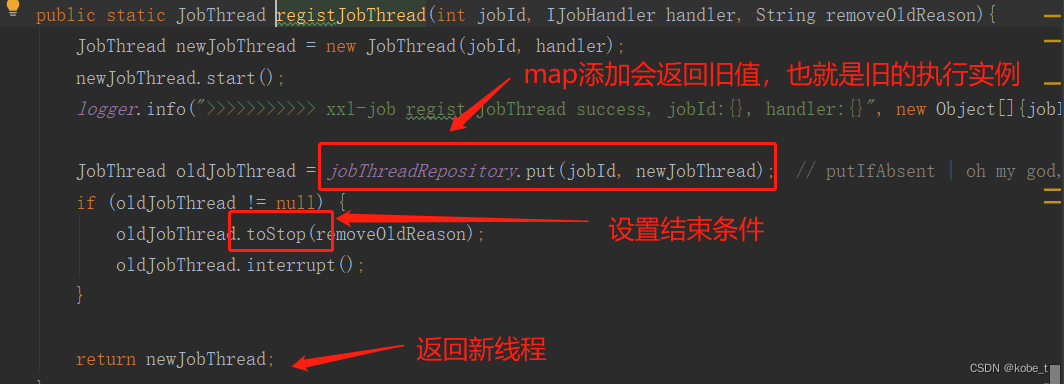
public static JobThread registJobThread(int jobId, IJobHandler handler, String removeOldReason){JobThread newJobThread = new JobThread(jobId, handler);newJobThread.start();logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}", new Object[]{jobId, handler});JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread); // putIfAbsent | oh my god, map's put method return the old value!!!if (oldJobThread != null) {oldJobThread.toStop(removeOldReason);oldJobThread.interrupt();}return newJobThread;}public JobThread(int jobId, IJobHandler handler) {this.jobId = jobId;this.handler = handler;// 初始化阻塞队列this.triggerQueue = new LinkedBlockingQueue<TriggerParam>();this.triggerLogIdSet = Collections.synchronizedSet(new HashSet<Long>());// assign job thread namethis.setName("xxl-job, JobThread-"+jobId+"-"+System.currentTimeMillis());}而执行任务的最后一步,就是将当前任务入队到刚才的执行线程的BlockingQueue中:
// push data to queueReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);而这也就跟文章最前面的代码关联起来了:
/*** new trigger to queue** @param triggerParam* @return*/public ReturnT<String> pushTriggerQueue(TriggerParam triggerParam) {// avoid repeatif (triggerLogIdSet.contains(triggerParam.getLogId())) {logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());return new ReturnT<String>(ReturnT.FAIL_CODE, "repeate trigger job, logId:" + triggerParam.getLogId());}triggerLogIdSet.add(triggerParam.getLogId());triggerQueue.add(triggerParam);return ReturnT.SUCCESS;}BlockingQueue的应用
消息入队
至此,就可以看出任务触发的大致逻辑了,用户在admin手工触发任务之后最终会放入到任务对应的队列之中:通过add方法将当前执行参数入队(FIFO),不阻塞队列,如果满了就抛出异常(这也是一个比较大的隐患,如果触了过于频繁,可能会导致OOM,而这也就是为什么要设计不同阻塞策略的原因)。
消息消费
而这些触发的任务怎么消费的呢?其实也是在上面的提到的执行线程JobThread:
- 当实例化一个线程的时候(com.xxl.job.core.executor.XxlJobExecutor类),会立即启动:调用线程的start()方法
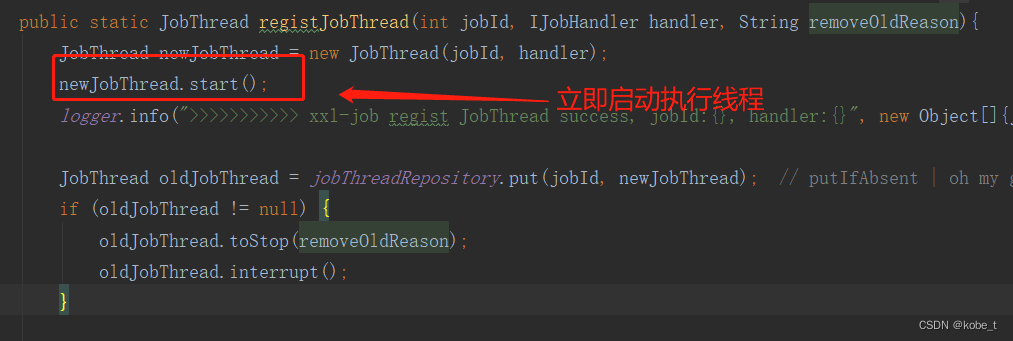
- 启动之后会调用线程的run()方法(com.xxl.job.core.thread.JobThread类)
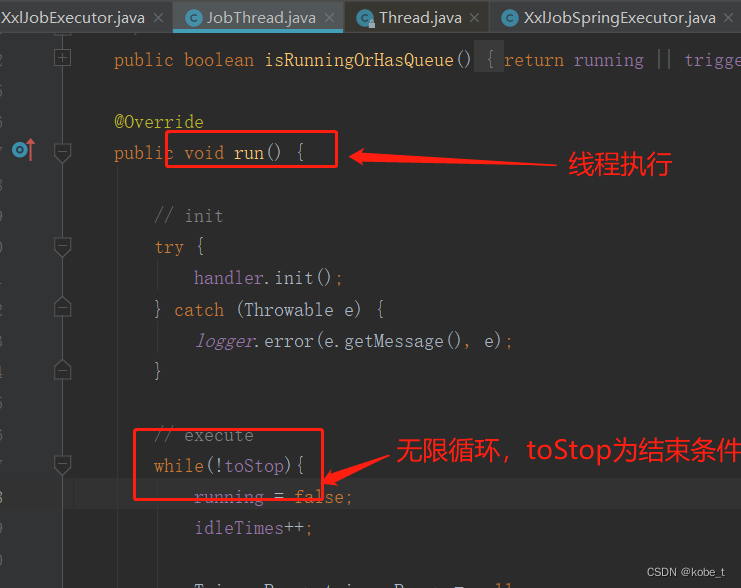
- 在执行线程中,会写一个while的无限循环来不停的从阻塞队列中取出任务

- 循环结束的条件就是上面的阻塞队列:如果是覆盖之前调度将会结束循环(com.xxl.job.core.biz.impl.ExecutorBizImpl类)