Redis中的数据结构
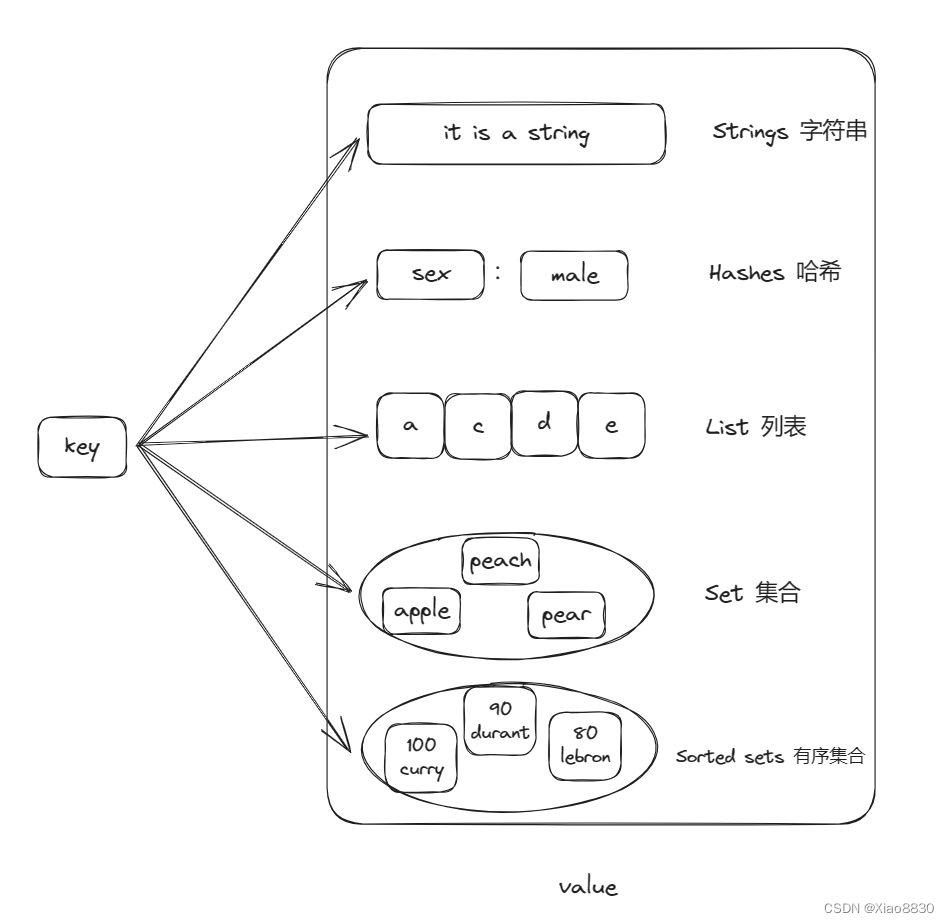
Redis中所有的数据都是基于key,value实现的,这里的数据结构指的是value有不同的类型。
当前版本Redis支持10种数据类型,下面介绍常用的五种数据类型
底层编码
Redis在实现上述数据结构时,会在源码有特定的优化,保证用户进行增删查改的操作时的时间复杂度为O(1)
| 数据类型 | 内部编码 |
|---|---|
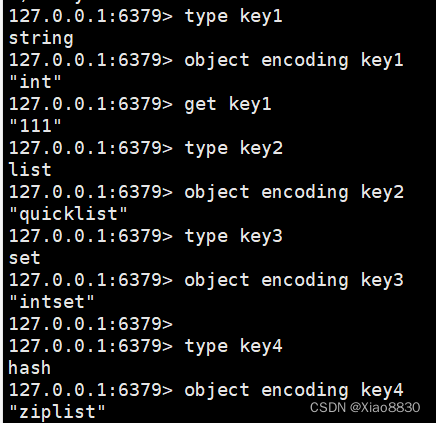
| string | raw, int, embstr |
| hash | hashtable, ziplist |
| list | linkedlist, ziplist |
| set | hashtable, intset |
| zset | skiplist, ziplist |
string
raw:底层是字节数组或者字符数组
int:用来计数,当value是整数时,可以直接用int保存
embstr:针对于短字符串的特殊优化,可以占据更小的空间,一般来说,如果字符串小于39字节,使用embstr,超过则用raw
hash
hashtable:基本的哈希表
ziplist:压缩列表,当哈希表中的数据比较少时,优化为ziplist节省空间
list
linkedlist:链表
ziplist:压缩列表
事实上,从3.2版本后,Redis引入了quicklist,代替了linkedllist和ziplist,quicklist整体上是一个链表,链表中的每个节点是ziplist
set
hashtable:基本的哈希表
intset:如果集合中存放的都是整数就会优化为intset
zset
skiplist:本质上还是一个链表,但每个节点中有多个指针域,通过不同的指针域可以实现快速的检索元素,时间复杂度为O(logN)
ziplist:压缩列表
object encoding key
通过上面这个命令,可以查看key对应的实际编码方式
单线程模型
Redis只使用一个线程处理所有的命令,而其他的线程处理网络io
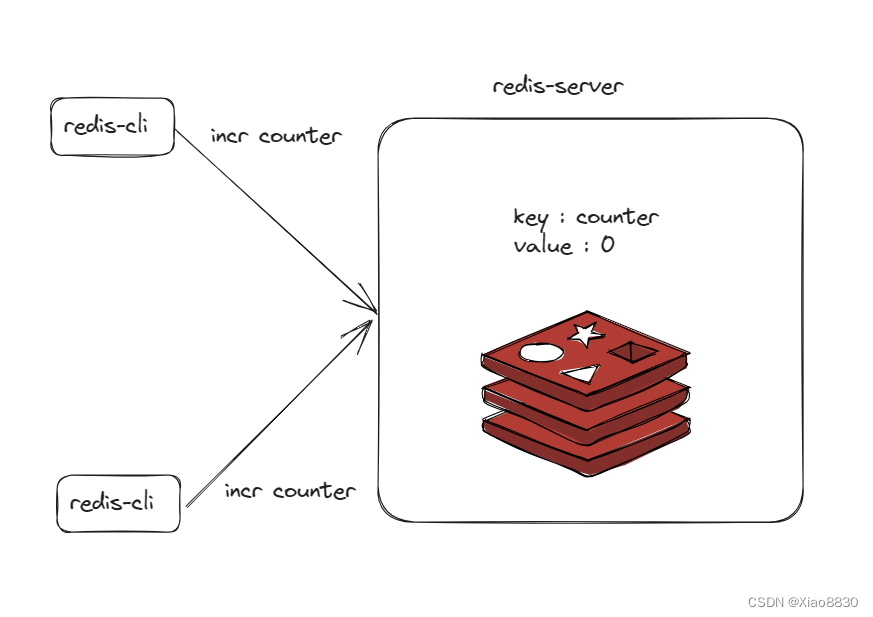
当redis服务器同时收到两个客户端对同一个变量的自增请求,但是由于Redis是单线程模型,因此多个请求要先在队列中排队,最终Redis还是串行的执行多个命令。
Redis之所以能够使用单线程工作,是因为Redis中的业务都是短小精悍的,每条指令都效率很高,并不会消耗过多的cpu资源。我们使用Redis时也需要保证没有请求占用时间特别长的操作,这样就会阻塞其他的命令
Redis中指令效率高的原因
- redis是访问内存,而数据库访问的是硬盘
- redis核心功能比数据库中的核心功能更加简单(例如数据库中的各种约束都会导致额外的开销)
- 单线程模型中避免了线程竞争的开销,减少了cpu的开销
- 处理网络io使用了epoll多路复用机制(一个线程管理多个socket)