一、正则表达式概述
什么是正则表达式?
正则表达式是一种描述字符串匹配规则的重要工具
1、正则表达式定义:
正则表达式,又称正规表达式、常规表达式
使用字符串描述、匹配一系列符合某个规则的字符串
正则表达式
普通字符:
大小写字母、数字、标点符号及一些其它符号
元字符:
在正则表达式中具有特殊意义的专用字符
正则表达式的层次分类
基础正则表达式
扩展正则表达式
Linux三剑客(grep、sed、awk)支持的正则表达式
shell是不支持正则表达式的(shell支持的是通配符)。shell中的正则表达式只有个别命令支持的,一般常用的是Linux三剑客
| 支持正则的shell命令 | 正则类型 |
|---|---|
| grep | 默认使用基本正则表达式(BRE)(要使用扩展正则需要加转义字符) |
| egrep 或grep -E | 使用扩展的正则表达式(ERE) |
| sed | 默认使用基本正则表达式(BRE) |
| awk | 使用扩展正则表达式(ERE) |
2 基础正则表达式的元字符
基础正则表达式是常用的正则表达式部分
2.1 匹配字符
\ : 表示转义字符,去掉特殊符号的特殊含义
\n : 匹配换行符
\t : 匹配制表符
\w : 匹配单词字符(单词字符:a-z,A-Z,0-9,_ )
\W : 匹配非单词字符
\S : 匹配非空白字符
\s : 匹配空白字符
\d : 匹配数字
\D : 匹配非数字
. : 表示匹配任意单个字符(默认情况下,. 无法匹配换行符)
2.2 中括号表达式
字符组: 普通中括号包围的字符组,表示某个单个字符匹配中括号内的任意字符即匹配成功
x[abc]z :
可以匹配包含“xaz”、“xbz”、“xcz”的字符串
取反表示法:
中括号内开头使用 ^ ,表示只要不是中括号内的字符就匹配
x[ ^abc]z :
可以匹配包含 “xdz”、“xez” 等字符串,但不能匹配包含“xaz”、“xbz”、“xcz”的字符串
范围表示法
[a-z]:
表示任意单个小写字母
[ ^a-z] :
匹配非小写字母的其它任意字符串
[A-Z] :
表示任意单个大写字符
[0-9] :
表示任意单个数字
注意:[0-59],表示匹配0、1、2、3、4、5、9,而不是0-59中间的数值
[a-z0-9A-Z] : 表示任意字母或数字
[a-z0-9A-Z_] : 表示任意字符、数字或下划线,也就是匹配单个字符
特殊的元字符在中括号中匹配
想要在中括号中匹配: ^ ,需要将其放在 中括号非开头的位置 ,如:[a^]
想要在中括号中匹配: - ,需要将其放在 开头位置或结尾位置 ,如:[abc-]、[-abc]
想要在中括号中匹配: ] ,需要将其放在 开头位置 ,如:[]abc]
2.3 位置匹配(锚定)
只匹配位置,不匹配字符,所以不会消耗字符数量,也称为零宽断言
^ : 匹配行首
$ : 匹配行尾
2.4 量词(重复匹配次数)
\{m\} : 表示匹配前一个字符或前一个子表达式m次
\{m,n\} : (m<n)表示匹配前一个字符或前一个字表达式最少m次,最多n次
\{m,\} : 表示匹配前一个字符或前一个子表达式至少m次
\{,n\} : 表示匹配前一个字符或前一个字表达式最多n次(匹配0次也算是成功)
*: 表示前一个字符或前一个子表达式匹配0次或多次,等价于:{0,}
.* : 匹配任意长度的任意字符
**注意:这些量词均为贪婪匹配模式,就是尽可能的去匹配符合条件的字符,例如:ab. *c 去匹配字符串:abbcdecfc,其中. * 部分匹配的将是bcdecf **
2 扩展正则表达式的元字符
2.1 扩展常用的量词
? : 表示匹配前一个字符或前一个子表达式0或1次,等价于:{0,1}或者{,1}
+: 表示匹配前一个字符或前一个子表达式1次或多次,就是最少一次,等价于:{1,}
2.2 二选一表达式
竖线 | 分隔左右两个正则子表达式,表示匹配任何一个即可,即a|b表示:a或者b,在结果上等价[ab];但是:[0-5] |\sa 表示0、1、2、3、4、5 或者 “ a”,这种转化不了为[]的形式。
使用二选一子表达式需要注意:
二选一元字符优先级很低,所以abc|def 表示的是abc或者def,等价于:(abc)|(def),而不是ab(c|d)ef。
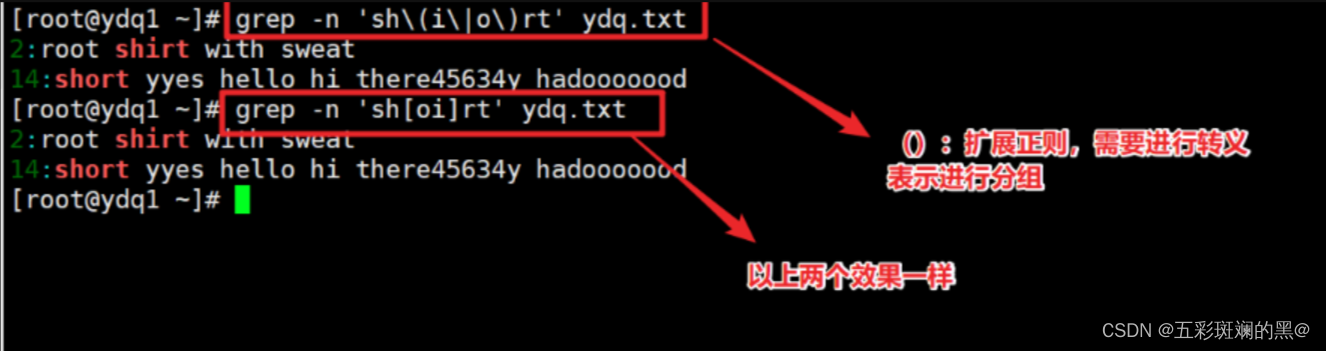
2.3 分组捕获和反向引用
使用小括号()包围一部分正则表达式,这部分正则表达式即成为一个分组整体,也称为一个子表达式。
根据左括号的位置决定第几个分组
例如:(abc)def 、([a-d]){3}、 ([0-9]abc(def){2}(hgi))。
分组后可以使用\N 来反向引用对应的分组匹配结果,N是1-9的正整数,\1表示第一个分组表达式的匹配结果,\2表达第二个分组表达式的匹配结果。
注意:反向引用引用的是分组匹配后的结果,不是分组表达式
例如:正则表达式:(abc|def) and \1xyz 可以匹配字符串“abc and abcxyz ” 或“def and defxyz”,但是不能匹配“abc and defxyz” 或 “def and abcxyz”
二、grep命令的使用
1、grep命令简介
grep是一种强大的文本搜索工具,它能使用正则表达式,并把匹配的行打印出来。
格式
grep [options] pattern [file]options表示:选项; pattern 表示:匹配的的表达式 ; file 表示:文件名例如:grep -i "root" /etc/passwd
2、常用选项
| 常用选项 | 功能 |
|---|---|
| -n | 列出所匹配的文本行,并显示行号 |
| -i | 匹配时忽略字符大小写 |
| -v | 反向匹配,匹配的字符串与搜索的不相符 |
| -w | 精确匹配。匹配整个单词 |
| -o | 只显示匹配的部分 |
| -c | 显示匹配内容的行数 |
3、grep 的选项使用案例
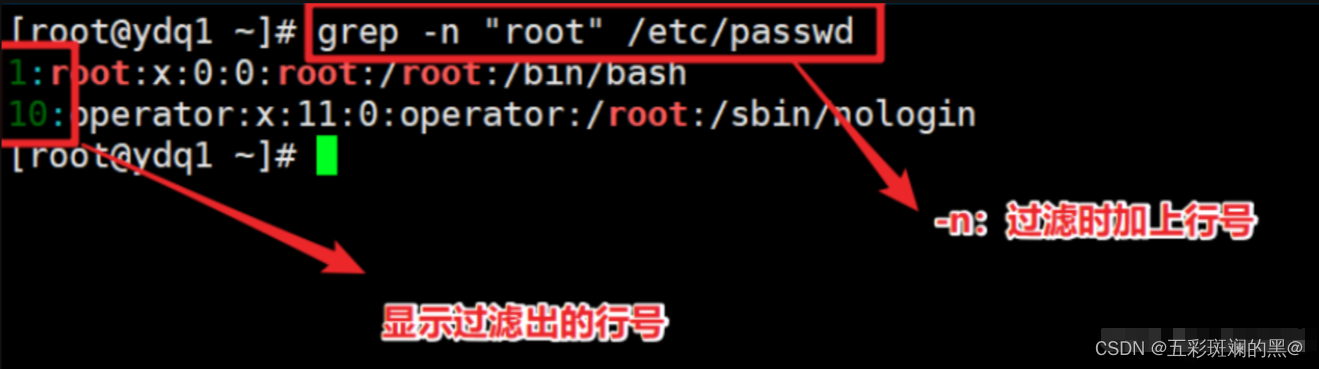
案例:过滤出/etc/passwd中的root,并添加行号(-n)
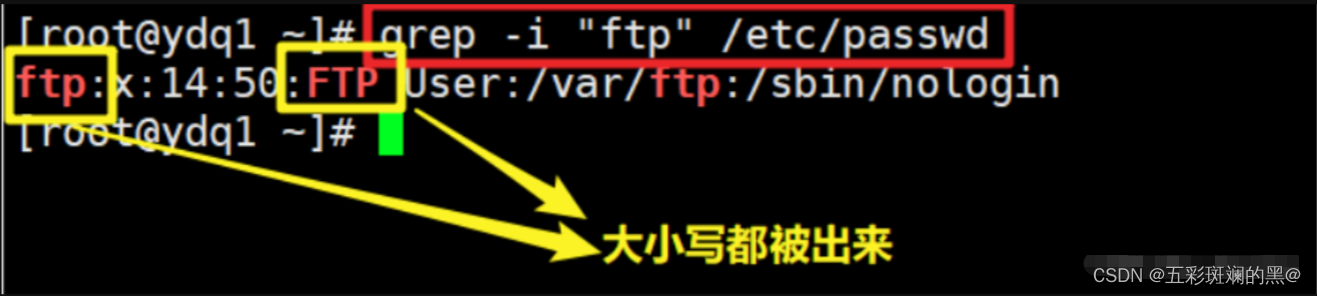
案例:过滤出/etc/passwd 中的FTP,不区分大小写(-i)
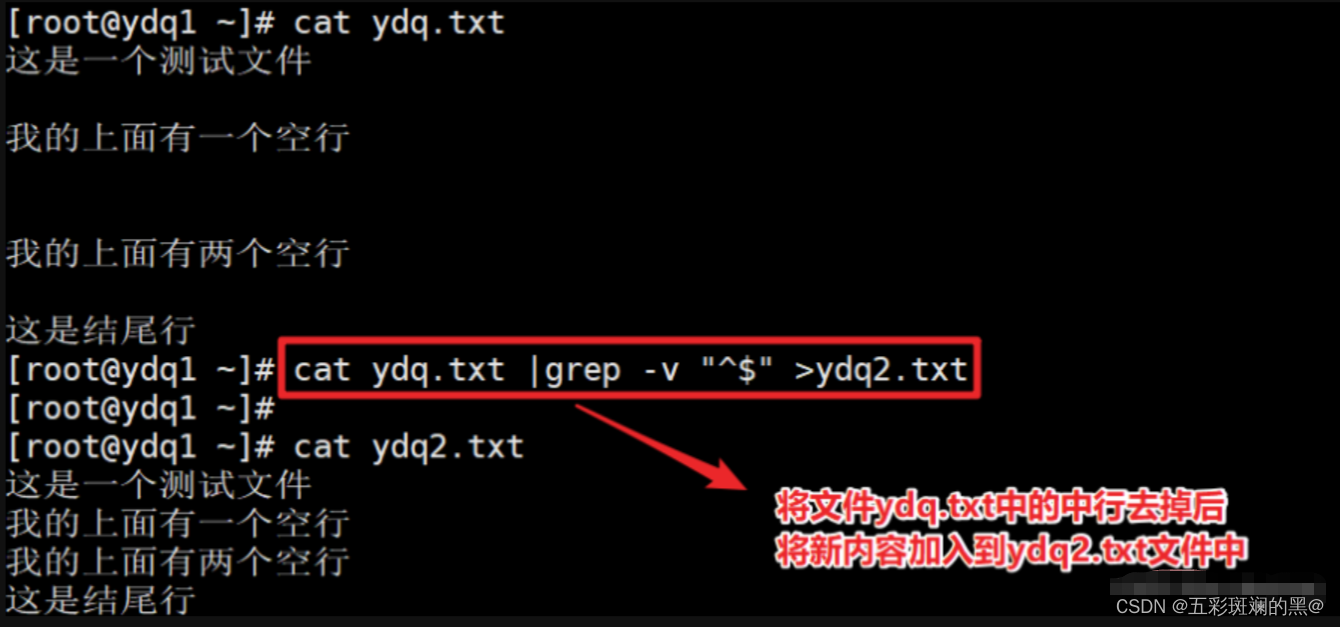
案例:过滤/etc/passwd 中的不包含root的行,并且显示行号(-v)

案例:精准搜索单词,只匹配到单词所在的行(-w)

案例:将匹配到的单词罗列出来(-o)
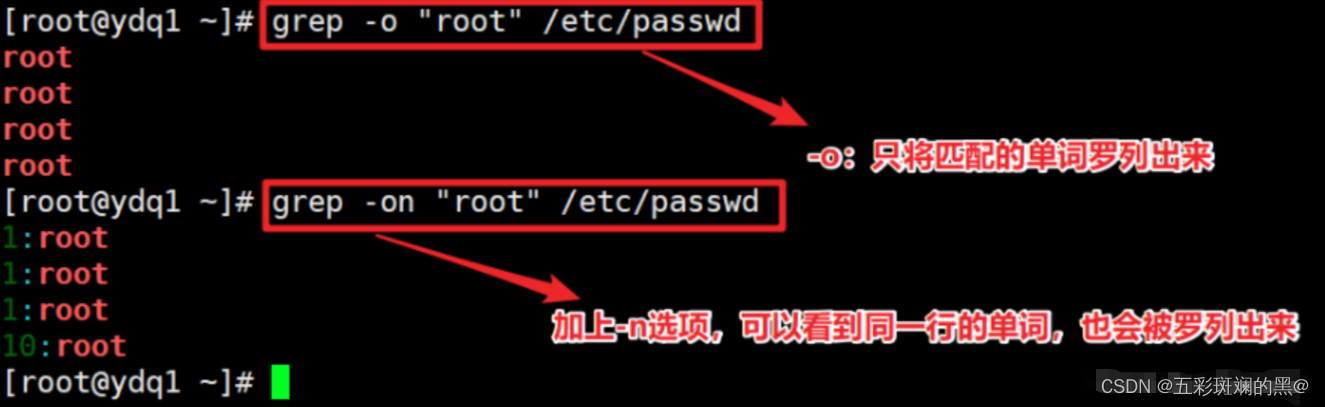
案例:显示匹配的内容的行数(-c)

三、grep加上正则使用案例
1、中括号表达式案例
案例1:搜索既可以查找shirt也可以查找short的单词所在行

案例2:搜索oo前面不是大小写字母开头的行

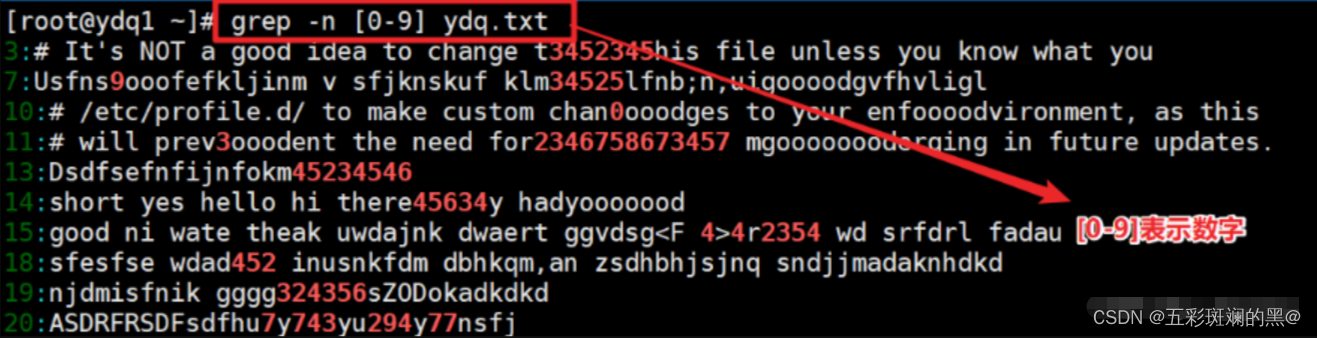
案例3:查找包含数字的行
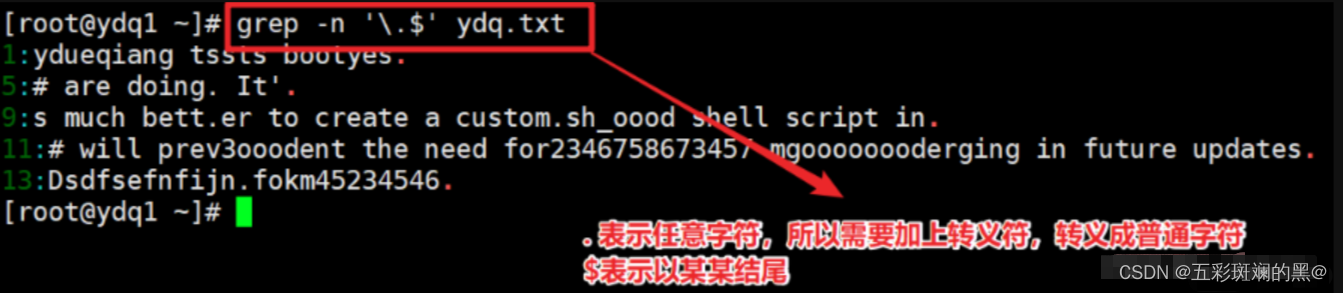
2、位置锚定案例
案例1:搜索以.结尾的行
案例2:搜索以y开头的行

3、量词案例
案例1:搜索2个oo的行 
为了匹配了6个o,但是要求搜索的是2个o?答:因为正则表达式是一行一行的检索的,表达式是2个o,搜索的内容时一个很长的字符串。
先拿表达式中的第一个字符与字符串匹配,匹配不到,进行下一个匹配,最后匹配到了mgoooooood中的o
匹配成功,然后匹配第二个o,也匹配成功,然后就会将匹配的两个字符消耗掉,再继续重新匹配到下一个字符
最后消耗掉三次,也就是6个o,第7个o虽然匹配成功,但是第8个字符不是o,所以不会匹配成功。
案例2:查看o这个字符,最少出现3次,最大出现6次

案例3:查找o这个字符,最少出现5次的行

案例:特殊的量词案例

4、二选一表达式和分组案例
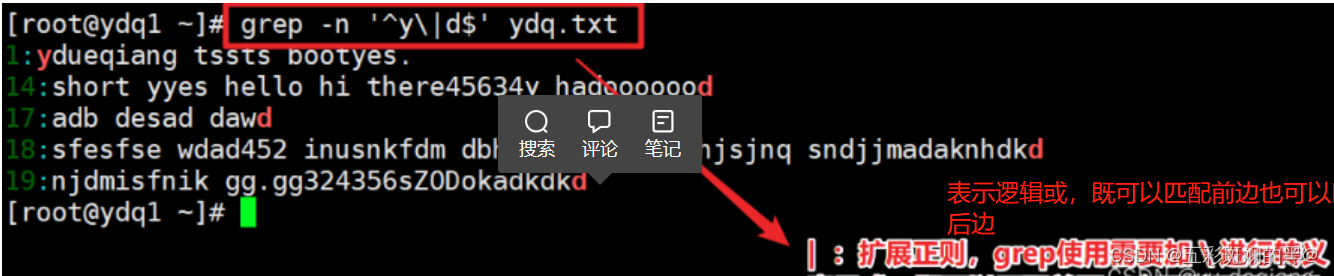
案例1:搜索以y开头或者以d结尾的行
案例2:搜索shirt和short所在的行
四、总结
| 正则元字符 | 描述 | grep | egrep | sed | awk |
|---|---|---|---|---|---|
| \ | 转义符,将特殊字符进行转义,忽略其特殊意义 | 支持 | 支持 | 支持 | 支持 |
| ^ | 匹配行首 | 支持 | 支持 | 支持 | 支持 |
| $ | 匹配行尾 | 支持 | 支持 | 支持 | 支持 |
| . | 匹配除换行符\n 之外的任意单个字符 | 支持 | 支持 | 支持 | 支持 |
| [] | 匹配包含在[字符]之中的任意一个字符 | 支持 | 支持 | 支持 | 支持 |
| [^] | 匹配[ ^z字符]之外的任意一个字符 | 支持 | 支持 | 支持 | 支持 |
| [-] | 匹配 []中指定范围的任意一个字符,要写成递增 | 支持 | 支持 | 支持 | 支持 |
| * | 匹配前导字符或子表达式0次或多次 | 支持 | 支持 | 支持 | 支持 |
| ? | 匹配前导字符或子表达式0次或1次 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| + | 匹配前导字符或子表达式1次或多次 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| () | 匹配表达式,创建一个用于匹配的字串 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| {n} | 匹配前导字符或子表达式n次,可以为0 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| {n,} | 匹配前导字符或子表达式至少n次 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| {n,m} | 匹配前导字符或子表达式,最少匹配n次,最低匹配m次,n<=m | 不支持(加\) | 支持 | 不支持(加\) | 支持 |
| | | 交替匹配| 两边的任意一项 | 不支持(加\) | 支持 | 不支持(加\) | 支持 |




![BUUCTF [MRCTF2020]Ezpop解题思路](https://img-blog.csdnimg.cn/83bddd922dbf405d9e25d7d1e280c529.png)