目录
编辑
栈:
栈的概念及结构:
栈的实现:
队列:
队列的概念及结构:
队列的实现:
扩展知识:
以上就是个人学习线性表的个人见解和学习的解析,欢迎各位大佬在评论区探讨!
感谢大佬们的一键三连! 感谢大佬们的一键三连! 感谢大佬们的一键三连!
栈:
栈的概念及结构:
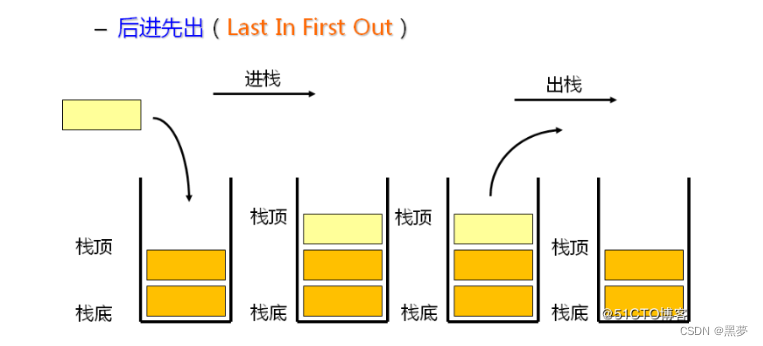
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。一般用在1.公平性排队(抽号机);2.BFS(广度优先遍历)。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
栈的实现:
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。链的尾插需要调动更多的数据,过程中有更多的消耗。
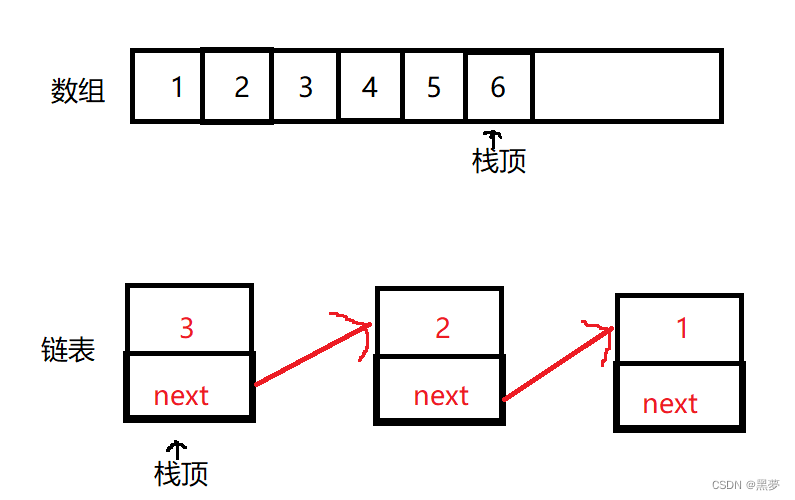
// 支持动态增长的栈typedef int STDataType ;typedef struct Stack{STDataType * _a ;int _top ; // 栈顶int _capacity ; // 容量} Stack ;// 初始化栈void StackInit ( Stack * ps );// 入栈void StackPush ( Stack * ps , STDataType data );// 出栈void StackPop ( Stack * ps );// 获取栈顶元素STDataType StackTop ( Stack * ps );// 获取栈中有效元素个数int StackSize ( Stack * ps );// 检测栈是否为空,如果为空返回非零结果,如果不为空返回 0int StackEmpty ( Stack * ps );// 销毁栈void StackDestroy ( Stack * ps );
//初始化栈
//初始化
void SLInit(SL* ps)
{assert(ps);ps->a = NULL;ps->capacity = ps->top = 0;
}//入栈
//入栈
void SLPush(SL* ps, STDataType x)
{assert(ps);//栈顶=容量说明需要扩容if (ps->capacity == ps->top){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;STDataType* tmp = (STDataType*)realloc(ps->a,sizeof(STDataType) * newcapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}ps->capacity = newcapacity;ps->a = tmp;}ps->a[ps->top] = x;//后缀++方便下一次入栈和打印栈顶ps->top++;
}//出栈
//出栈
void SLPop(SL* ps)
{assert(ps);//为空情况“0”assert(ps->top > 0);//--ps->top;
}//获得栈顶元素
//获得栈顶元素
STDataType SLTTop(SL* ps)
{assert(ps);//为空情况“0”assert(ps->top > 0);int n = (ps->top) - 1;return ps->a[n];
}//获取栈中有效元素个数
//获取栈中有效元素个数
int SLSize(SL* ps)
{assert(ps);return ps->top;
}
//销毁栈
//销毁栈
void SLDestroy(SL* ps)
{assert(ps);//开辟数组优势:一次全部释放free(ps->a);ps->a = NULL;ps->capacity = ps->top = 0;
}// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool SLEmpty(SL* ps)
{assert(ps);//为“0”说明为NULLif (ps->top == 0){return true;}return false;
}队列:
队列的概念及结构:

队列的实现:
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数 组头上出数据,效率会比较低。
// 链式结构:表示队列typedef struct QListNode{struct QListNode * _pNext ;QDataType _data ;} QNode ;// 队列的结构typedef struct Queue{QNode * _front ;QNode * _rear ;} Queue ;// 初始化队列void QueueInit ( Queue * q );// 队尾入队列void QueuePush ( Queue * q , QDataType data );// 队头出队列void QueuePop ( Queue * q );// 获取队列头部元素QDataType QueueFront ( Queue * q );// 获取队列队尾元素QDataType QueueBack ( Queue * q );// 获取队列中有效元素个数int QueueSize ( Queue * q );// 检测队列是否为空,如果为空返回非零结果,如果非空返回 0int QueueEmpty ( Queue * q );// 销毁队列void QueueDestroy ( Queue * q );
//初始化
//初始化
void QueueInit(Que* pq)
{assert(pq);pq->head = pq->tail = NULL;pq->size = 0;
}//入列
//入列
void QueuePush(Que* pq, Qdatatype x)
{assert(pq);//开辟队列结构动态内存Qnode* newnode = (Qnode*)malloc(sizeof(Qnode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->data = x;newnode->next = NULL;//第一次或N+1次if (pq->tail == NULL){pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = newnode;}pq->size++;
}//出列
//出列
void QueuePop(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));if (pq->head->next == NULL){//就剩下一个free(pq->head);pq->head = pq->tail = NULL;}else{//剩下两个及以上Que * del = pq->head;pq->head = pq->head->next;free(del);}pq->size--;
}// 获取队列头部元素
// 获取队列头部元素
Qdatatype QueueFront(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->data;
}// 获取队列队尾元素
// 获取队列队尾元素
Qdatatype QueueBack(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->data;
}// 获取队列中有效元素个数
// 获取队列中有效元素个数
int QueueSize(Que* pq)
{assert(pq);return pq->size;
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Que* pq)
{assert(pq);return pq->head == NULL;
}//销毁
//销毁
void QueueDestroy(Que* pq)
{assert(pq);while (pq->head){Que* del = pq->head->next;free(pq->head);pq->head = del;pq->size--;}pq->head = pq->tail = NULL;
}扩展知识:
队列适合使用链表实现,使用顺序结构(即固定的连续空间)实现时会出现假溢出的问题,因此大佬们设计出了循环队列,循环队列就是为了解决顺序结构实现队列假溢出问题的
循环队列:实际中我们有时还会使用一种队列叫循环队列。如操作系统课程讲解生产者消费者模型时可以就会使用循环队列。环形队列可以使用数组实现,也可以使用循环链表实现。
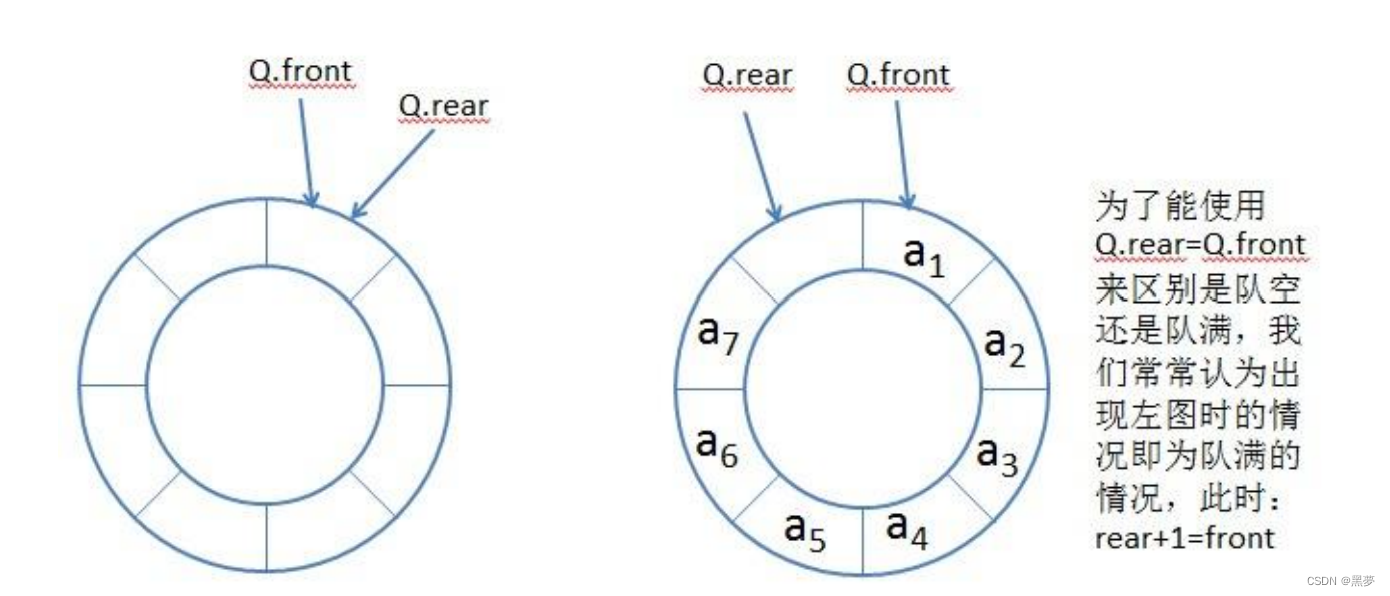
同时指向一个位置为空,rear(尾)的下一个位置为front(头)时说明已经填满,此处是多开辟了一个空间来做判断是否为满 !!!
以上就是个人学习线性表的个人见解和学习的解析,欢迎各位大佬在评论区探讨!
感谢大佬们的一键三连! 感谢大佬们的一键三连! 感谢大佬们的一键三连!