300万字!全网最全大数据学习面试社区等你来!
上个周五的时候,Doris官宣了2.0版本,除了在性能上的大幅提升,还有一些特性需要大家特别关注。
根据官网的描述,Doris在下面领域都有了长足进步:
日志分析
数据湖联邦分析场景
数据更新效率和写入
资源弹性和存算分离
其他面向企业用户的易用性特性
在Doris出现这些能力之前,大家是没有机会免费用到这些能力的。数据库的这些能力集中在云平台上的一些付费数据库,不花钱根本体验不到。
这里面有一些特别重要的更新,大家在深度使用Doris的时候可能需要特别注意一下,这些内容也是很多面试官喜欢问的,我结合我的一些实践,挑一些重要的说。
点查并发能力的支持
在数据开发领域,「点查询」或者叫KV查询,在过去此类需求往往需要引入 Apache HBase等KV系统来应对点查询、或者Redis作为缓存层来分担高并发带来的系统压力。例如我们在订单属性查询的场景中,我们需要根据订单号关联订单的一些属性信息,很多OLAP在这个场景有很严重的性能问题,所以我们在之前提到各种OLAP库并不擅长像后端开发用Mysql数据库一样应付 Data Serving查询,但是在2.0版本后,如果我们的业务规模不大,我们可以不引入类似Hbase这样额外的组件,可以小范围的支持某些点查询需求,减少复杂技术栈带来的维护成本以及数据的冗余存储。
这里面原理涉及到:缓存优化、行式存储格式、点查询短路径优化、语句预处理、Row Cache等,需要大家自行了解。假如你在规模较大的生产环境用到了这样的能力,需要了解基本的原理,以及有哪些最佳生产实践。
日志分析类场景
Doris 2.0版本中引入了一些特性例如「倒排索引」「半结构数据类型」等,大家如果对ES不陌生的话,应该理解上面的这两些词语。
在此之前我们大规模使用ELK全家桶支持日志系统:FileBeat、Logstash、Kafka、Kibana,或者还需要了解ES DSL,如果我们的系统规模不大,要引入上述组件带来的使用和运维成本复杂度非常高昂,另外还需要解决ES的读写稳定性问题等等。
在Doris 2.0版本之后,我们可以基于Doris尝试在某些场景直接打造一个低成本、高易用的简版ELK系统,加之Doris对标准 SQL的支持和高度兼容 MySQL协议和语法,我们可以非常简单的进行日志分析。
冷热分离
2.0版本的一个重要功能是冷热分离。冷热分离是大数据领域的一个很重要的概念,其实在Doris之前,很多大数据领域的组件都支持冷热分离存储,例如大家熟知的Elasticsearch,利用ES的分片分配策略和给定节点路由,可以实现数据的冷热分离存储,使得热数据节点处理所有新输入的数据,并且存储速度也较快,以便确保快速地采集和检索数据。冷节点的存储密度则较大,可以在较长保留期限内保留数据,从而大大降低成本。
Doris同样也可以利用动态分区功能,对表分区进行生命周期管理,通过设置热数据转冷时间以及存储介质标识,后台任务将热数据从SSD自动冷却到 HDD,以帮助用户较大程度地降低存储成本。
这个在业务和数据规模较大的场景几乎是必做的操作,毕竟,谁会跟省钱过不去呢?
湖仓一体领域
Doris在很早的版本就已经支持了多种异构数据源的映射,例如Hive、ES等,在2.0版本这个范围扩展了湖表领域,增加了对Hudi、Iceberg、Paimon的支持。这将是一个巨大的改变,我们现在可以很轻松的将湖表映射到Doris来加速查询,在数据联邦查询分析场景得到了长足的进步。
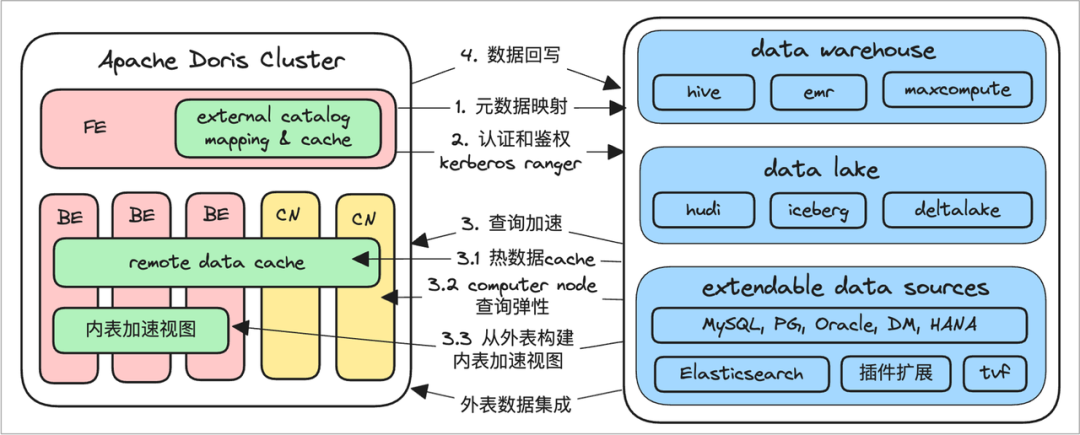
未来,我们可以在特定业务场景中轻松实现湖仓一体化架构。届时,基于Flink、Doris、Hudi等的湖仓一体架构会频繁出现在大家眼前。当然这里面需要进行大量的最佳化实践,不过这一天很快会到来。
其他
此外,Doris还对某些功能进行了增强,例如多个数据模型下的列更新能力,高频写入Compaction内存优化等,在这些优化之前,我们都需要对任务进行很多优化,而现在不需要了,需要大家在使用过程中自行体会一下。
总之,2.0版本之后,Doris在开源OLAP领域的领先优势会逐步扩大,可以媲美很多云平台上的成熟的产品。
大家可以看到,数据开发领域过去的这几年发展有多快,是所有IT开发方向里几乎仅有的技术栈一直在快速迭代升级的方向,大家的技术栈也要跟上时代啊!不要等到被时代抛弃了才醒悟过来!
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」