简介
作为新入门的新手,通常安装完Stable Diffusion之后,一打开界面,在文生图输入girl或者dog,结果出来的画面比较糟糕,看起来像素很低,画面不清晰,人物也不怎么美,等等其他问题,总之就觉得自己生成的图片怎么跟别人差距那么大?是不是大家也曾经这样过来过?

今天就来教会大家,如何正确使用Stable Diffusion,掌握基础知识,能正确做出优秀的作品来,首先,先来个基本公式
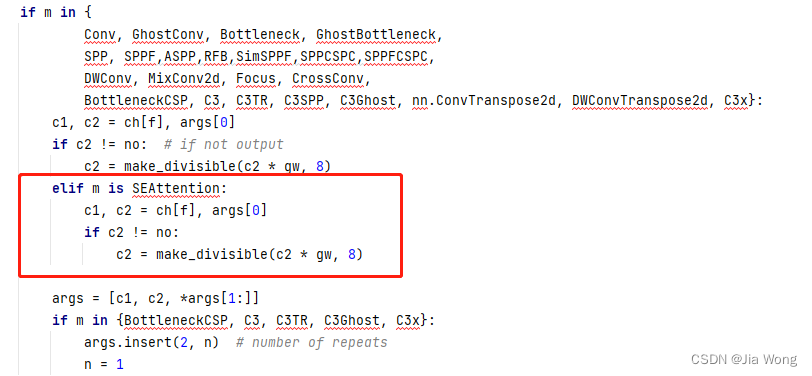
- 一个优秀的作品=CheckPoint大模型+vae+优秀的prompt+embeding+Lora
- 一个4k优秀的作品=CheckPoint大模型+vae+优秀的prompt+embeding+Lora+Controlnet(Tile)增加细节+放大算法


主要角色

1、checkpoint(大模型)
这是我们常说的模型,也可以说是底模,必须指定一个才能作画,它是用来控制大整个画面的风格走势的。比如:写实风格,漫画风格等等,文件名后缀一般为.ckpt和.safetensors,模型大小为2G到8G不等。
checkpoint文件放置路径:\models\Stable-diffusion
2、Lora模型
它也是模型之一,它可以使用也可以不使用,它的出现只为了解决大模型能够微调的一种技术,它的作用主要用于雕刻人物、动漫角色、物品的特征、控制画风、固定特征动作等等。文件名后缀一般为.safetensors,大小在20mb到300mb不等,部分Lora会需要触发词来使用,否则效果不明显。
Lora放置路径:\models\lora
3、embedding
这是我们说的prompt集合,它可以用一个特殊表达式词语来代表一连串的关键词,让填写prompt更简单。举个例子,如果我们想要生成一个皮卡丘,通常需要输入很多描述词,如黄毛、老鼠、长耳朵、腮红等等。但是,如果在我们的embedding库中,已经引入皮卡丘的embedding,我们只需要输入皮卡丘。皮卡丘的embedding打包了所有皮卡丘的特征描述,这样我们就不用每次输入很多单词来控制生成的画面了。
embedding文件放置路径:\models\embedding
4、VAE
Vae也是模型之一,但它的作用只是给画面加载一个滤镜的效果,为了就是修正最终输出的图片色彩,如果不加载VAE可能会出现图片特别灰的情况。一般我们直接选用自动模型就可以了,它会自动帮我们解决这类问题。当然也有些特殊情况需要用到VAE来对色彩进行调节。文件后缀一般为.downloading、.safetensors、.ckpt、.pt
VAE文件的放置路径:\models\vae
prompt的使用
prompt的好坏会决定出图的质量,所以为什么有咒语这一说,因为需要很长的prompt来告诉AI具体要的是什么。于是咒语的优化和书写尤为重要,不过不用担心,市场上现在网站上已经出了很多优秀作品,他们的prompt是开源的,可以复制之后来学习,积累自己的prompt词。
- propmt:正向提示词,表示在画面中需要出现的元素
- negative propmt:负面提示词,表示在画面中不想要出现的元素
1、增加权重
增加权重会让Stable Diffusion出图的时候,会优先考虑画当前的关键词,当权重超过2.0之后,会让图片重复出现当前关键词,导致Stable Diffusion发挥失常
- (tag):1.1倍
- ((tag)):1.1x1.1=1.21倍,每套一层括号,额外x1.1倍
- {tag}:1.05倍
- {{tag}}:1.05x1.05=1.1025倍,每套一层大括号,额外x1.05倍
当然权重也不是越高越好的

2、减少权重
减少权重会让Stable Diffusion出图的时候,只是作为参考使用,当权重低于0.5的时候表示当前的关键词可有可无
- [tag]:0.9倍
- [[tag]]:0.9x0.9=0.81倍,每套一层括号,额外x0.9倍
3、精准权重
- (tag:1.2):1.2倍
- (tag:0.9):0.9倍
4、使用Lora
lora的使用是一个表达式,如下:
- lora:bg:1.2:使用bg的Lora模型,权重为1.2
- lora:bg:1.2,lora:bgV2:1.5:同样的多个Lora的使用也是可以的

市场上开源的Lora风格还是很多,像图上的盲盒风格(第一个),电影风格(最后一个)
5、使用embedding
embedding的使用非常简单,跟书写prompt一样,直接写到提示词上即可,前提是要下载好当前的embedding模型,不需要任何表达式。embedding最常用的例子就是生成的人物的时候,要求必须是完整的2个眼睛1个鼻子2个耳朵1个嘴巴5个手指,同样的也能在负面提示词中增加embedding,还是同样的人物,不能出现坏手,3个手指,4个手指等

很明显可以看出,在NP(negative prompt)中使用EasyNegative模型和没有使用NP的区别
- 没有EasyNegative:手部明显画的很粗糙,不太像是人的手
- 使用EasyNegative:手部比较正常,细节也是正常可观
prompt的进阶玩法
进阶玩法能更加精准控制prompt生成我们想要的图
1、混合
- 混合:强制将不同的主体的元素特征进行混合出图,用
AND把多种要素强制融合画进去 - 语法:关键词1 AND 关键词2 AND 关键词3
- 举例:1cat:2 AND 1dog AND 1tiger,想要生成一个狗、猫和老虎

2、渐变
- 渐变:指的是在作画中,将元素进行过渡的过程
- 语法:[from:to:when]
- when:表示的迭代步数或比例(数值在0-1范围表示比例,1- 表示步数)
- From:提示词,表示在 when 前的步数渲染 from 提示词
- to:提示词,表示在 when 后的步数渲染 to 提示词
- 举例:(1 girl ,[blue hair:red hair:5]):我们希望画一个女孩,能够有红色和蓝色的头发

3、交替渲染
- 交替渲染:交替渲染更像是在作画时每一笔交替使用不同的主体特征进行作画的方式
- 语法:[关键词1|关键词2]
- 举例:[1dog|1cat|1tiger],一个狗、猫和老虎进行交替渲染

界面介绍
1、模型选项
模型选项就是顶部的几个选择栏,用来选择大模型和Vae模型使用,常用的就是换大模型,其他保持默认即可

2、提示词面板
提示词面板分2块,propmt和negative propmt
- propmt:正向提示词,表示在画面中需要出现的元素
- negative propmt:负面提示词,表示在画面中不想要出现的元素

3、功能按钮
功能按钮指的是右边这几个功能按钮

第一按钮他有两个功能
- 当你关掉软件后,点击这个按钮,就会读取你上一次做图的所有参数信息复制进来。
- 当你在其他模型网站中
Copy Generation Data复制别人案例图片的所有配置信息,粘贴到提示词中,再点击这个按钮,就会自动读取配置信息的所有配置,并应用到自己的作画参数中

第二个按钮就是删除了,清空关键词

第三个按钮就是模型选择管理,可以选择现有的CheckPoint、Lora、embedding等模型仓库,点击模型即可应用


第四个按钮和第五个按钮是提示词模板功能
- 第四个是读取当前选定的模板风格所有提示词写入到提示词中
- 第五个是将当前的提示词,保存到新的模板中,方便下次使用

4、绘图参数面板
绘图参数面板的功能是比较多的,他可以通过拓展安装各种插件,来控制绘图的过程

1.采样步数
一般来说大部分时候采样部署只需要保持在20~30之间即可,更低的采样部署可能会导致图片没有计算完全,更高的采样步数的细节收益也并不高,只有非常微弱的证据表明高步数可以小概率修复肢体错误,所以只有想要出一张穷尽细节可能的图的时候才会使用更高的步数。(加大这个会导致出图变慢)

2.采样方法
采样方法即是Stable Diffusion中的去噪音过程,你可以理解为不同的算法,目前的采样方法较多,但是我们常用的就那几个,经过各方面的实验来说,带有++符号的采样方法是经过改进后的算法,建议找带有++符号的使用。

3.其他选项

- 面部修复:在做一些人物图片的时候,防止人脸出现崩坏的情况,可以勾选,但如果你的提示词足够强大,就可以不开启
- 高清修复:把基础生成的图片,按照你选择放大的倍率放大到指定分辨率之后再重新绘制图片
- 宽度、高度:图片的长和宽
- 生成批次和数量:生成几批图,一批几张图
- 提示词相关性:图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示词,如果提示词比较烂,那么图像质量会有降低
- 种子:生成图片的唯一标识,输入不同的种子,生成的图片不一样,seed值一样,那生成的图片也是一样
实操演示
这里实操一张4k的赛博朋克风格的手机壁纸,作为演示例子。手机屏幕4K分辨率=2160×3840 (9:16)
第一步:文生图
先通过简单的咒语,用写实风格的模型,固定的种子,生成1张540x960的图,作为现在的手机像素540勉强有点说不过去,所以增加高清修复功能,放大到2倍,也就是生成的图是1080x1920


第二步:增加Lora模型
在咒语中增加赛博朋克的Lora模型,让当前风格增加些赛博朋克元素,当前用的是超写实赛博朋克美女的Lora,记得提前下载


很明显图片更加的靠近游戏的赛博朋克风格
第三步:发送到图生图,启用Controlnet的Tile模型
将当前的图片发送到图生图

在图生图的Controlnet插件中,选择启用,选用tile模型,tile模型可以极大限度提升当前图片的细节,将重绘幅度调为0.9,点击生成


很明显图片的细节和色彩更加丰富
第四步:将图片发送到后期处理,进行放大算法处理
由于我们现在生成的是高清修复后的1080,距离4k像素还有2倍的距离,所以我们将当前图片放大2倍,选择R-ESRGAN 4x+放大算法


图片超过5m上传不了,这里只能截图展示啦
到这里我们就生成出一张像素为2160×3840赛博朋克风格的手机壁纸,到这里就掌握了Stable diffusion的入门操作啦