高并发内存池
分层处理
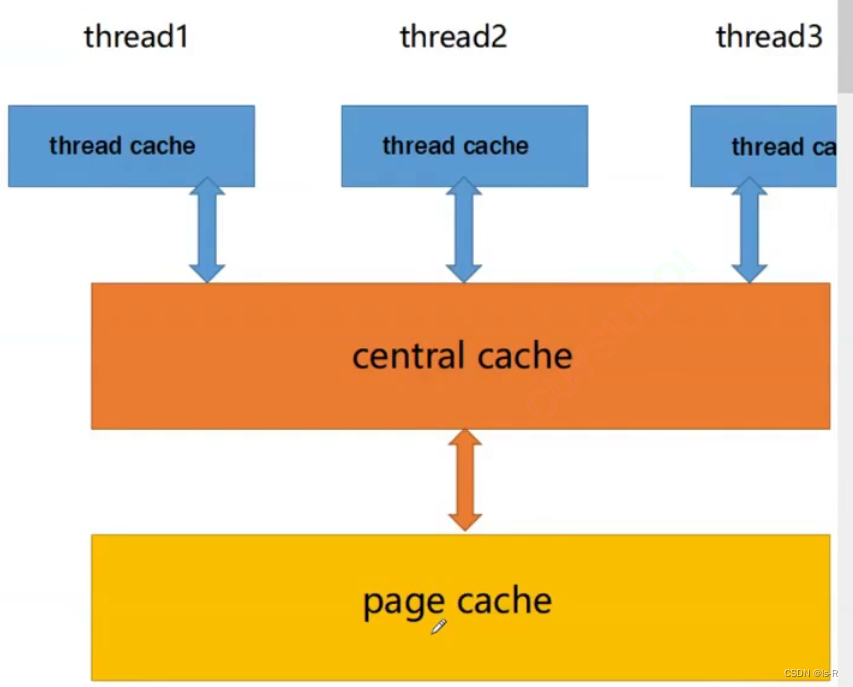

thread cache
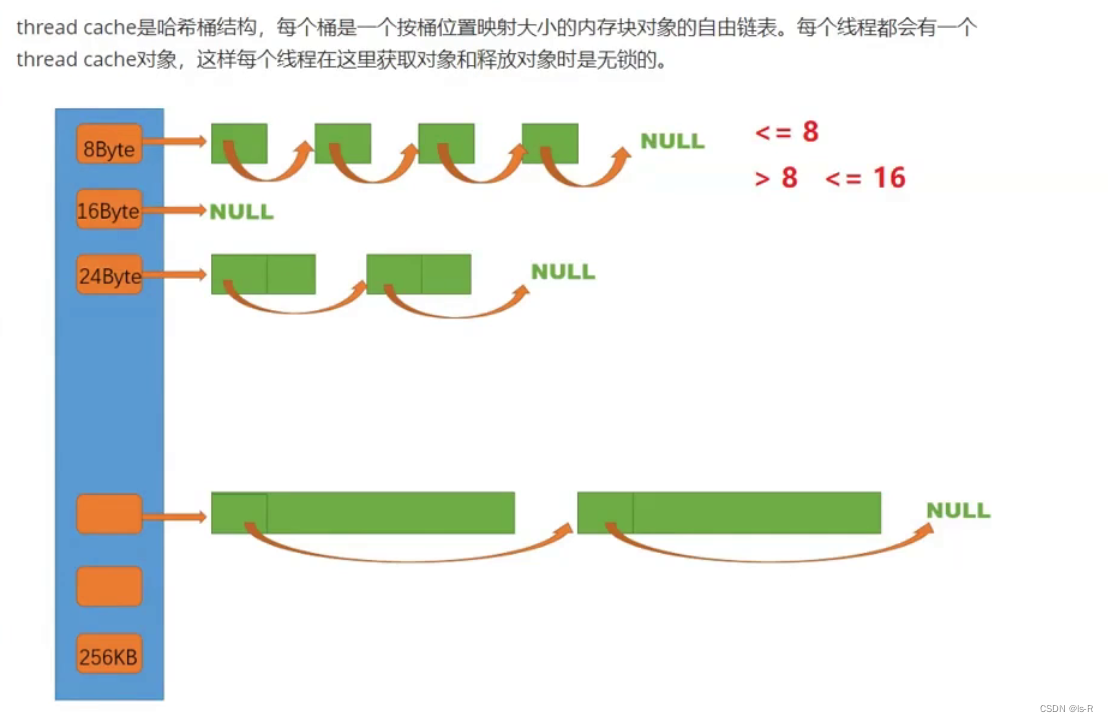
定义一个公共的FreeList管理切分的小空间
static void*& NextObj(void* obj)
{return *(void**)obj;
}//管理切分好的小对象的自由链表
class FreeList
{
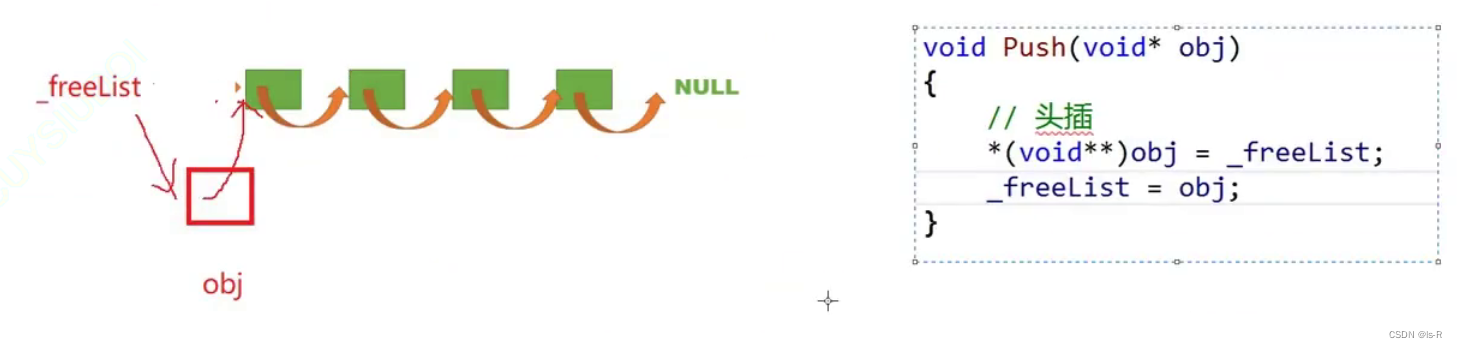
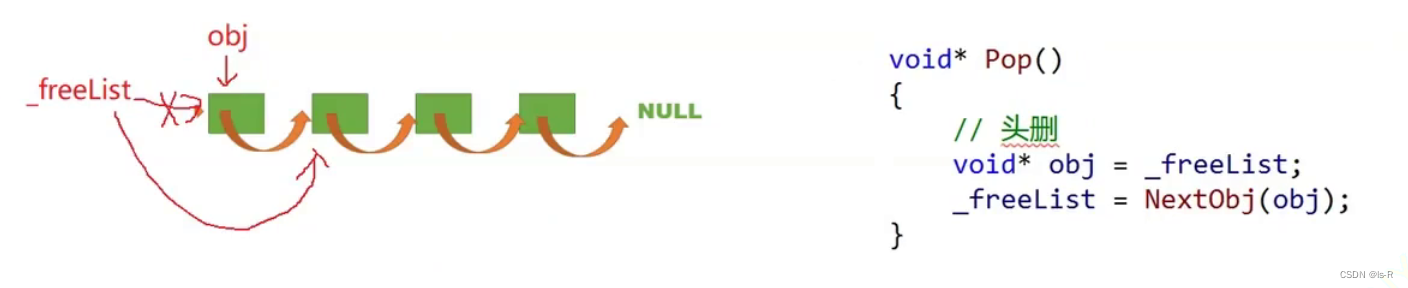
public:void Push(void* obj){assert(obj);//头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;}void* Pop(){assert(_freeList);//头删void* obj = _freeList;_freeList = NextObj(obj);}
private:void* _freeList = nullptr;
};
用FreeList做哈希桶的映射
class ThreadCache
{
public://申请和释放对象void* Allocate(size_t size);void* Deallocate(void* ptr, size_t size);
private:FreeList _freeLists[];
};
对齐找桶
对齐映射
对象中没有成员,使用静态的函数可以不通过对象就能调用,,用位运算的效率更高
先算在哪个对齐规则中,再计算在哪个桶中
static const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREE_LIST = 208;void*& NextObj(void* obj)
{return *(void**)obj;
}//管理切分好的小对象的自由链表
class FreeList
{
public:void Push(void* obj){assert(obj);//头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;}void* Pop(){assert(_freeList);//头删void* obj = _freeList;_freeList = NextObj(obj);}bool Empty(){return _freeList == nullptr;}
private:void* _freeList;
};
//计算对象大小的对齐映射规则
class SizeClass
{// 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16)// [128+1,1024] 16byte对齐 freelist[16,72)// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
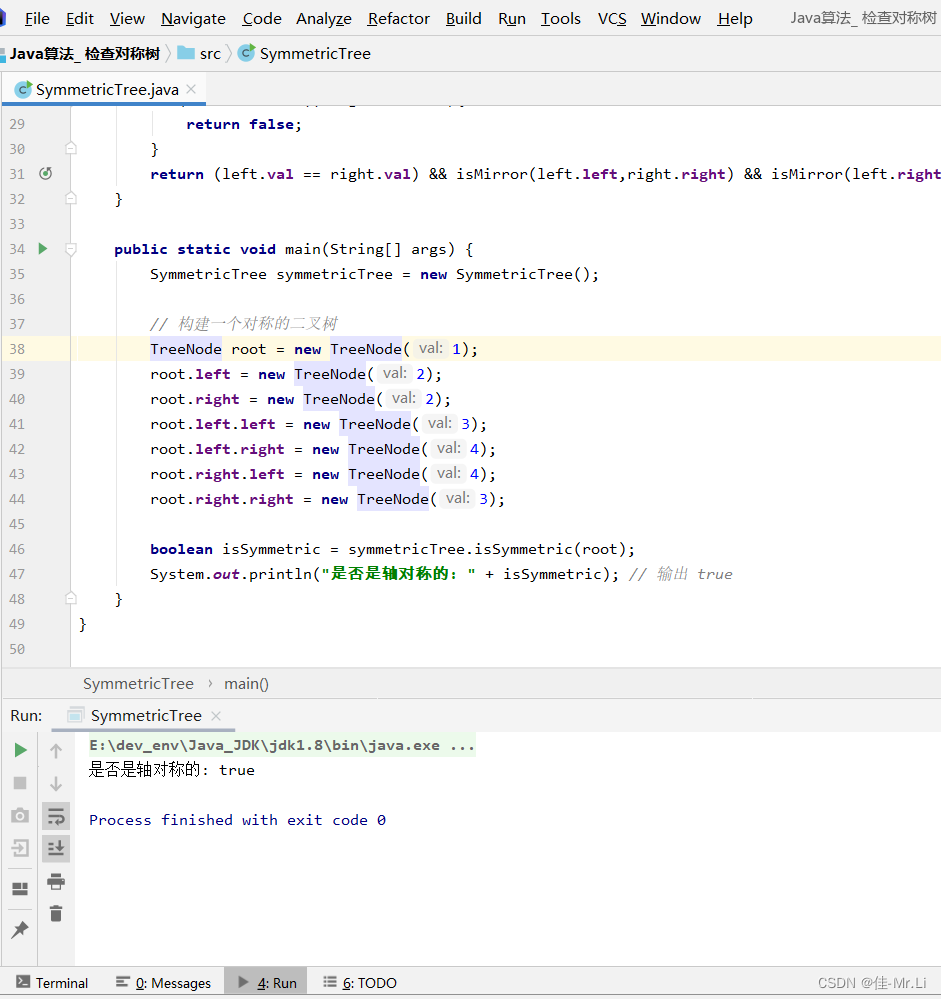
public://size_t _RoundUP(size_t size, size_t alignNum)//{// size_t alignSize;// if (size % 8 != 0)// {// alignSize = (size / alignNum + 1) * alignNum;// }// else// {// alignSize = size;// }// return alignSize;//}static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8*1024);}else{assert(false);return -1;}}/*size_t _Index(size_t bytes, size_t alignNum){if (bytes % alignNum == 0){return bytes / alignNum - 1;}else{return bytes / alignNum;}}*/// 1 + 7 8// 2 9// ...// 8 15// 9 + 7 16// 10// ...// 16 23static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}完善ThreadCache类
class ThreadCache
{
public://申请和释放对象void* Allocate(size_t size);void* Deallocate(void* ptr, size_t size);//从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);private:FreeList _freeLists[NFREE_LIST];
};
申请对象:先判断申请大小是否在规定范围-----得出在哪个映射规则—在哪个桶—判断桶不为空时头删桶,否则从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size)
{}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index,alignSize);}
}void* ThreadCache::Deallocate(void* ptr, size_t size)
{}
线程局部存储(TLS)

每个线程都定义一个这样的指针
_declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
每个线程无锁的获取自己的ThreadCache对象
static void* ConcurrentAlloc(size_t size)
{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}static void ConcurrentFree(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}