目录
- 前言
- 阅读准备
- 阅读指引
- 阅读建议
- 课程内容
- 一、依赖注入方式(前置知识)
- 1.1 手动注入
- 1.2 自动注入
- 1.2.1 XML的autowire自动注入
- 1.2.1.1 byType:按照类型进行注入
- 1.2.1.2 byName:按照名称进行注入
- 1.2.1.3 constructor:按照构造方法进行注入
- 1.2.1.4 其他
- 1.2.1.5 XML的autowire自动注入方式总结
- 1.2.2 @Autowired注解的自动注入
- 1.2.3 自动注入总结
- 二、依赖注入过程
- 2.1 简单回顾
- 2.2 概念回顾
- 2.3 核心方法讲解
- 三、【寻找注入点】方法讲解
- 3.1 AbstractAutowireCapableBeanFactory#applyMergedBeanDefinitionPostProcessors:寻找注入点代码入口
- 3.2 AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition
- 3.3 AutowiredAnnotationBeanPostProcessor#findAutowiringMetadata:寻找注入点
- *3.4 AutowiredAnnotationBeanPostProcessor#buildAutowiringMetadata:构建注入点
- 3.5 ReflectionUtils#doWithLocalFields:利用反射遍历类上的【字段】
- 3.6 AutowiredAnnotationBeanPostProcessor#findAutowiredAnnotation:寻找字段上的自动装配注解
- 3.7 Modifier.isStatic
- 3.8 剩余步骤
- 四、【寻找注入点】逻辑流程图
- 学习总结
前言
阅读准备
由于Spring源码分析是一个前后联系比较强的过程,而且这边分析,也是按照代码顺序讲解的,所以不了解前置知识的情况下,大概率没办法看懂当前的内容。所以,特别推荐看看我前面的文章(自上而下次序):
- Spring底层核心原理解析【学习难度:★★☆☆☆】
- 手写简易Spring容器过程分析【学习难度:★★☆☆☆】
- Spring之底层架构核心概念解析【学习难度:★★★☆☆,重要程度:★★★★★】
- Bean的生命周期流程图【学习难度:☆☆☆☆☆,重要程度:★★★★★】
- Spring之Bean的生命周期源码解析——阶段一(扫描生成BeanDefinition)【学习难度:★★☆☆☆,重要程度:★★★☆☆】
- Spring之Bean的生命周期源码解析——阶段二(IOC之实例化)【学习难度:★★★★★,重要程度:★★★☆☆】
(PS:特别是《Bean的生命周期流程图》,帮大家【开天眼】,先了解下流程。毕竟【通过业务了解代码,远比通过代码了解业务简单的多】!!!!)
(PS:特别是《Bean的生命周期流程图》,帮大家【开天眼】,先了解下流程。毕竟【通过业务了解代码,远比通过代码了解业务简单的多】!!!!)
(PS:特别是《Bean的生命周期流程图》,帮大家【开天眼】,先了解下流程。毕竟【通过业务了解代码,远比通过代码了解业务简单的多】!!!!)
阅读指引
我们在上一节课已经说到过了,本次Spring源码剖析的总入口是new AnnotationConfigApplicationContext("org.tuling.spring");,这里就不再重复解释了。本节课要说的内容,是SpringIOC的属性填充/依赖注入,我们这里直接给到入口吧,调用链如下:(调用链比较深,不要纠结细枝末节)
- AbstractApplicationContext#refresh:刷新方法,不用在意
- AbstractApplicationContext#finishBeanFactoryInitialization:在这里实例化所有剩余的(非lazy-init)单例
- DefaultListableBeanFactory#preInstantiateSingletons:在这里实例化所有剩余的(非lazy-init)单例(上面的方法,核心干活的方法就是这里)
- DefaultListableBeanFactory#getBean:获取Bean的方法
- AbstractBeanFactory#doGetBean:返回指定bean的一个实例,它可以是共享的,也可以是独立的
- 上面这个
AbstractBeanFactory#doGetBean里面的一段局部代码写的回调方法,如下:
// 如果是单例创建bean实例if (mbd.isSingleton()) {sharedInstance = getSingleton(beanName, () -> {try {return createBean(beanName, mbd, args);}catch (BeansException ex) {// Explicitly remove instance from singleton cache: It might have been put there// eagerly by the creation process, to allow for circular reference resolution.// Also remove any beans that received a temporary reference to the bean.destroySingleton(beanName);throw ex;}});beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);}
- AbstractAutowireCapableBeanFactory#createBean:这个类的中心方法:创建一个bean实例,填充bean实例,应用后处理器,等等。
- AbstractAutowireCapableBeanFactory#doCreateBean:【实例化】及后面声明周期调用地方。
- 【入口一】:AbstractAutowireCapableBeanFactory#applyMergedBeanDefinitionPostProcessors:应用合并BeanDefinition后置处理器给给定的BeanDefinition。
- 【入口二】AbstractAutowireCapableBeanFactory#populateBean:使用来自bean定义的属性值在给定的BeanWrapper中填充bean实例。
如上面的调用链所示,最后两个方法,才是我们本次要研究的核心方法。为什么这里会说有两个入口呢?主要是,本章的【属性填充/依赖注入】将分为两个部分来解析。【入口一】对应的是【第一部分:寻找注入点】;【入口二】对应的是【第二部分:属性填充及填充后】
阅读建议
- 看源码,切记纠结细枝末节,不然很容易陷进去。正常来说,看主要流程就好了
- 遇到不懂的,多看看类注释或者方法注释。Spring这种优秀源码,注释真的非常到位
- 如果你是idea用户,多用F11的书签功能。
- Ctrl + F11 选中文件 / 文件夹,使用助记符设定 / 取消书签 (必备)
- Shift + F11 弹出书签显示层 (必备)
- Ctrl +1,2,3…9 定位到对应数值的书签位置 (必备)
课程内容
一、依赖注入方式(前置知识)
在Spring中,属性注入的方式分为两种,分别是:【手动注入】和【自动注入】。
1.1 手动注入
在XML中定义Bean时,就是手动注入,因为是程序员手动给某个属性指定了值。如下:
<bean name="userService" class="com.luban.service.UserService"><property name="orderService" ref="orderService"/>
</bean>
有经验的同学应该知道,上面这种底层是通过setXxx方法进行注入的。另外,还有一种方式,是通过构造方法进行注入的,如下:
<bean name="userService" class="com.luban.service.UserService"><constructor-arg index="0" ref="orderService"/>
</bean>
所以手动注入的底层也就是分为两种:【set方法注入】和【构造方法注入】。
1.2 自动注入
自动注入又分为两种:【XML的autowire自动注入】和【@Autowired注解的自动注入】。
1.2.1 XML的autowire自动注入
在XML中,我们可以在定义一个Bean时去指定这个Bean的自动注入模式,它有如下几种方式:
1.2.1.1 byType:按照类型进行注入
byType注入方式,底层是基于setXxx方法实现的,所以setter方法不能少。这里说的类型是【入参】的类型。
Spring在通过byType的自动填充属性时流程是:
- 获取到set方法中的唯一参数的参数类型,并且根据该类型去容器中获取bean
- 如果找到多个,会报错
使用示例如下:
<bean id="userService" class="com.luban.service.UserService" autowire="byType"/>
public void setOrderService(OrderService orderService) {this.orderService = orderService;}
如上示例的类型,就是指入参orderService的类型OrderService
1.2.1.2 byName:按照名称进行注入
byType注入方式,底层是基于setXxx方法实现的,所以setter方法不能少。这里说的【名称】,是指setXxx后面的Xxx部分。
所以,Spring在通过byName的自动填充属性时流程是:
- 找到所有set方法所对应的Xxx部分的名字
- 根据Xxx部分的名字去获取bean
使用示例如下:
<bean id="userXmlBean" class="org.tuling.spring.xml.bean.UserXmlBean" autowire="byName"/><bean id="walletXmlBean" class="org.tuling.spring.xml.bean.WalletXmlBean"/>
如上,我们定义了userXmlBean的自动注入类型是byName,并且定义了一个名字叫walletXmlBean的bean。
public class UserXmlBean {private WalletXmlBean wallet;public void printProperty() {System.out.println(wallet);}public void setWalletXmlBean(WalletXmlBean param) {this.wallet = param;}
}
如上,我们定义了一个UserXmlBean ,他有成员变量WalletXmlBean wallet。同时给他声明了一个成员方法printProperty()用来打印它的成员属性的地址。
测试代码:
public class MyXmlApplicationContextTest {public static void main(String[] args) {ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");UserXmlBean userXmlBean = (UserXmlBean)context.getBean("userXmlBean");userXmlBean.printProperty();}// 系统输出:// org.tuling.spring.xml.bean.WalletXmlBean@1d16f93d
}
如上,UserXmlBean的WalletXmlBean类型的属性出现了2个名称,一个是成员变量wallet,另一个是setter方法入参中的param,但是一点都不妨碍我们byName注入。因为,根据byName的规则,寻找的是setXxx后面的Xxx部分。还不够信服是吗?我们改一下UserXmlBean里面的setter方法,如下:
public void setWalletXmlBean123(WalletXmlBean param) {this.wallet = param;}
这个时候再去调用,输出null。
1.2.1.3 constructor:按照构造方法进行注入
constructor表示通过构造方法注入,其实这种情况就比较简单了,没有byType和byName那么复杂。
如果是constructor,那么就可以不写set方法了,当某个bean是通过构造方法来注入时,spring利用构造方法的参数信息从Spring容器中去找bean,找到bean之后作为参数传给构造方法,从而实例化得到一个bean对象,并完成属性赋值(属性赋值的代码得程序员来写)。
(PS:我们这里先不考虑一个类有多个构造方法的情况,后面单独讲推断构造方法。我们这里只考虑只有一个有参构造方法。)
其实构造方法注入相当于byType+byName。Spring在通过byName的自动填充属性时流程是:
- 通过构造方法中的参数类型去找bean,如果对应的类型只有一个bean,那就是它了;
- 如果找到多个会根据参数名确定
- 如果最后根据参数名都无法确定,则报错
使用示例如下:
<bean id="userXmlBean" class="org.tuling.spring.xml.bean.UserXmlBean" autowire="constructor"/><bean id="walletXmlBean123" class="org.tuling.spring.xml.bean.WalletXmlBean"/><bean id="walletXmlBean" class="org.tuling.spring.xml.bean.WalletXmlBean"/>
bean示例:
public class UserXmlBean {private WalletXmlBean wallet;public void printProperty() {System.out.println(wallet);}public UserXmlBean(WalletXmlBean walletXmlBean) {this.wallet = walletXmlBean;}
}
具体的调用跟错误方式这边就不介绍了,大家回头自己试试吧
1.2.1.4 其他
其他,诸如:
- default:表示默认值,我们一直演示的某个bean的autowire,而也可以直接在<beans>标签中设置autowire,如果设置了,那么<bean>标签中设置的autowire如果为default,那么则会用<beans>标签中设置的autowire
- no:表示关闭autowire,不自动注入
1.2.1.5 XML的autowire自动注入方式总结
那么XML的自动注入底层其实也就是:
- set方法注入
- 构造方法注入
1.2.2 @Autowired注解的自动注入
@Autowired注解,本质上也是byType和byName的结合。它是先byType,如果找到多个则byName。这个跟xml构造方式注入原理如出一辙。就是:
- 先根据类型去找bean,如果对应的类型只有一个bean,那就是它了;
- 如果找到多个会根据属性名确定
- 如果最后根据属性名都无法确定,则报错
@Autowired注解可以写在:
- 属性上:先根据属性类型去找Bean,如果找到多个再根据属性名确定一个(属性注入)
- 构造方法上:先根据方法参数类型去找Bean,如果找到多个再根据参数名确定一个(构造方法注入)
- set方法上:先根据方法参数类型去找Bean,如果找到多个再根据参数名确定一个(set方法注入)
1.2.3 自动注入总结
可以发现XML中的自动注入是挺强大的,那么问题来了,为什么我们平时都是用的@Autowired注解呢?而没有用上文说的这种自动注入方式呢?
其实啊,@Autowired注解相当于XML中的autowire属性的注解方式的替代。从本质上讲,@Autowired注解提供了与autowire相同的功能,但是拥有更细粒度的控制和更广泛的适用性。
XML中的autowire控制的是整个bean的所有属性,而@Autowired注解是直接写在某个属性、某个set方法、某个构造方法上的。
再举个例子,如果一个类有多个构造方法,那么如果用XML的autowire=constructor,你无法控制到底用哪个构造方法,而你可以用@Autowired注解来直接指定你想用哪个构造方法。
同时,用@Autowired注解,还可以控制,哪些属性想被自动注入,哪些属性不想,这也是细粒度的控制。
二、依赖注入过程
2.1 简单回顾
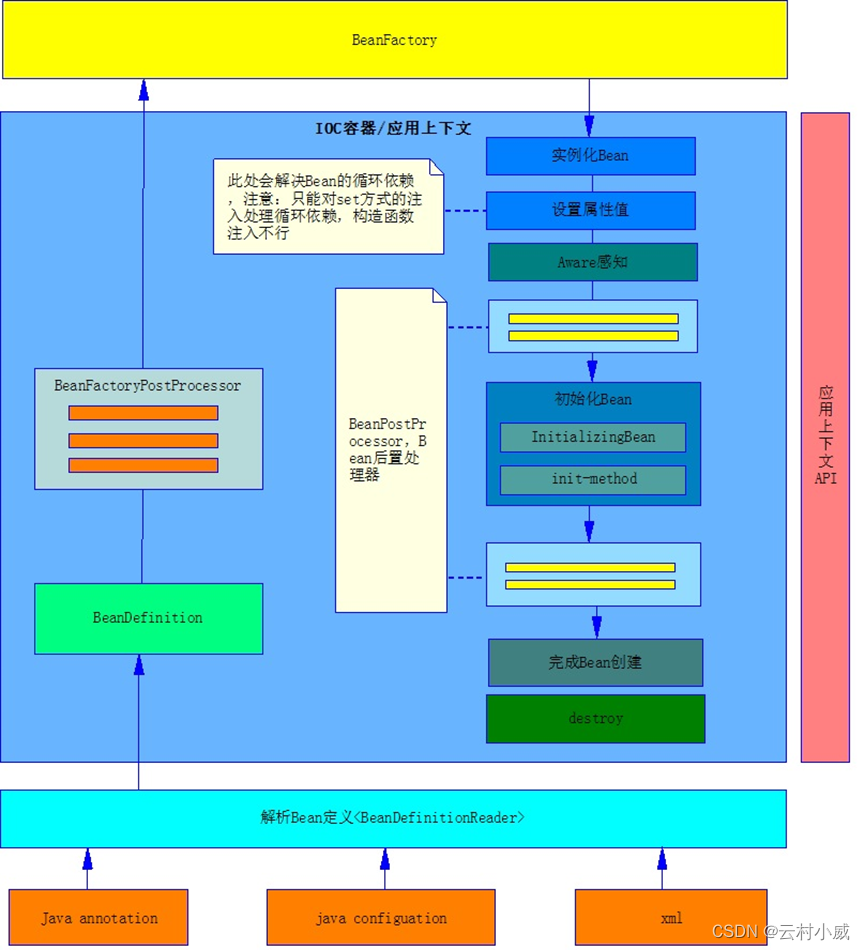
依赖注入的过程,大体上其实能分为以下三步的:【寻找注入点】、【填充属性】、【填充属性后】。但其实,【寻找注入点】这个过程,会在两个地方被调用。第一个就是箭头所向,【实例化】阶段【BeanDefinition后置处理】那个地方。怎么理解呢?因为,【寻找注入点】的实现类就是【BeanDefinition后置处理】中的一个。
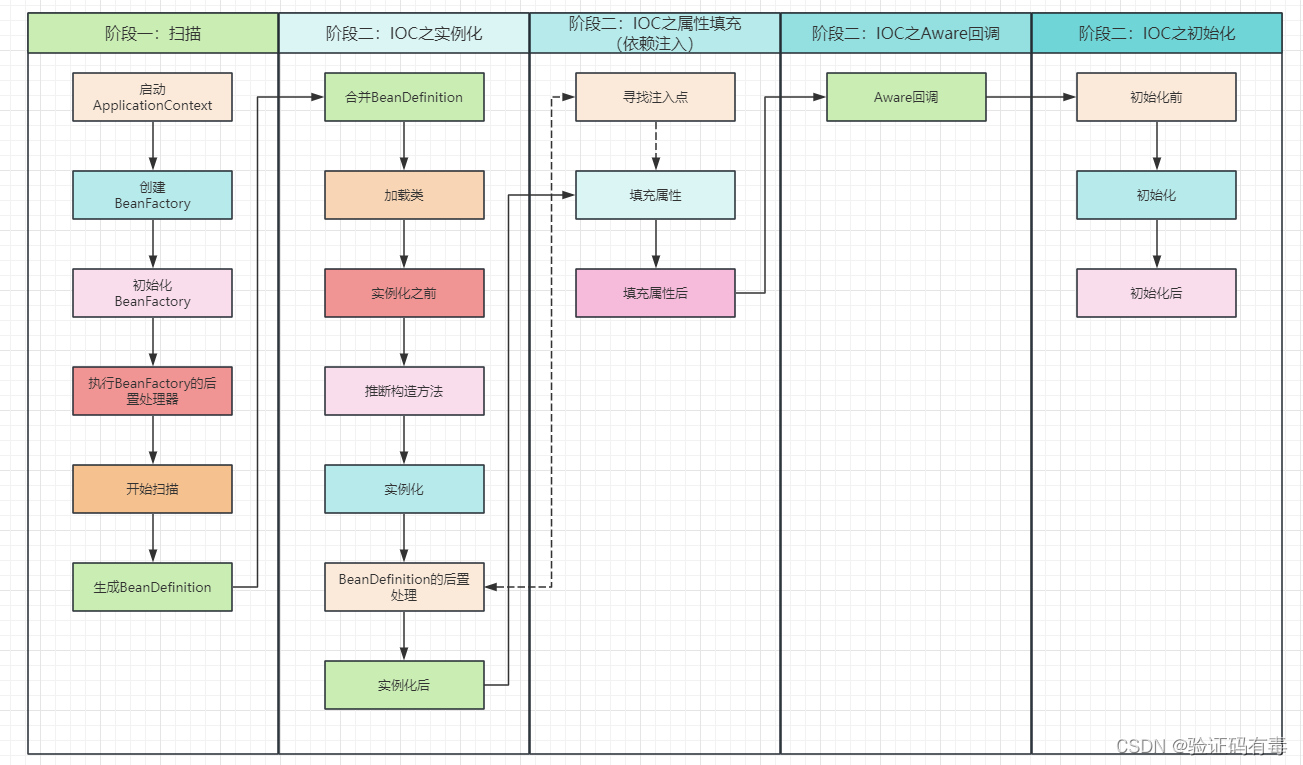
上面说的概念多少有点绕。简单来说,【寻找注入点】就是寻找被@Autowird、@Value、@Inject、@Resource注解修饰的属性、方法等等;然后,【属性填充】的时候再来处理这些找到的注入点,将他们设置到对应Bean属性中。
2.2 概念回顾
在这个【实例化】过程中,涉及到了一些Spring底层设计的概念,我在上一个笔记里面有大概介绍过Spring底层概念的一些讲解,不记得的同学记得回去翻一翻。
主要涉及的概念有:
- BeanDefinition(设计图纸):BeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特征
- MergedBeanDefinitionPostProcessor:合并BeanDefinition后置处理器。但这里其实主要说的是
AutowiredAnnotationBeanPostProcessor跟CommonAnnotationBeanPostProcessor。他俩有什么作用呢?前者是处理Spring内部定义的@Autowired跟@Value自动注入注解;后者是处理jdk定义的@Resource注解。既然都说到这了,那你们回忆一下用到的是这个后置处理器的什么方法?嘿,不就是MergedBeanDefinitionPostProcessor里面定义的方法嘛,赶紧去翻翻看。
CommonAnnotationBeanPostProcessor接口定义如下:
/*** 这个后置处理器通过继承InitDestroyAnnotationBeanPostProcessor和InstantiationAwareBeanPostProcessor注解,* 获得了对@PostConstruct和@PreDestroy的支持。* 另外,这个类的核心处理元素是@Resource注解*/
public class CommonAnnotationBeanPostProcessor extends InitDestroyAnnotationBeanPostProcessorimplements InstantiationAwareBeanPostProcessor, BeanFactoryAware, Serializable {// 具体代码就不贴了。学到这里大家应该知道如何通过【接口】继承、实现来猜测类能力了吧
}
AutowiredAnnotationBeanPostProcessor接口定义如下:
// 继承类跟CommonAnnotationBeanPostProcessor 如出一辙,唯一不同的是,继承了功能更强大的
// SmartInstantiationAwareBeanPostProcessor(InstantiationAwareBeanPostProcessor子类)
// 实现这个类,是为了实现里面的推断构造方法
public class AutowiredAnnotationBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor,MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware {
2.3 核心方法讲解
本节【属性注入】,将会分两个部分来讲。第一部分是:【寻找注入点】;剩下的是第二部分。
先说第一部分,第一部分主要涉及【3个类,7个核心方法】。
第二部分,待定…
三、【寻找注入点】方法讲解
我在上面说过,【寻找注入点】其实是有两个地方会调用到的。一个是在【属性填充populateBean()】之前的【合并BeanDefinitionapplyMergedBeanDefinitionPostProcessors()】,另一个就是在【属性填充】里面了。(【寻找注入点】源码以AutowiredAnnotationBeanPostProcessor举例)
3.1 AbstractAutowireCapableBeanFactory#applyMergedBeanDefinitionPostProcessors:寻找注入点代码入口
全路径:org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#applyMergedBeanDefinitionPostProcessors
将MergedBeanDefinitionPostProcessors应用于指定的bean定义,调用它们的postProcessMergedBeanDefinition方法。
源码如下:
protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName) {for (MergedBeanDefinitionPostProcessor processor : getBeanPostProcessorCache().mergedDefinition) {processor.postProcessMergedBeanDefinition(mbd, beanType, beanName);}
}
我们点开这个循环的类对象,找到他们的两个实现类:AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor。为了方便,我们这里就只举例AutowiredAnnotationBeanPostProcessor,因为他俩实现方式基本雷同,只不过前者处理的Spring的注解,由Spring本家写的;后者处理的JDK的注解。
3.2 AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition
方法调用链:由3.2的applyMergedBeanDefinitionPostProcessors()调用进来
全路径:org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition
方法注释:对指定bean的给定合并bean定义进行后处理。
源码如下:
@Overridepublic void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);metadata.checkConfigMembers(beanDefinition);}
方法解读:代码很简单,整个过程真正干活的其实是里面的findAutowiringMetadata()方法
3.3 AutowiredAnnotationBeanPostProcessor#findAutowiringMetadata:寻找注入点
方法调用链:由3.2的applyMergedBeanDefinitionPostProcessors()调用进来
全路径:org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor#findAutowiringMetadata
方法注释:寻找注入点
** private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {// 设置缓存keyString cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());// 先看缓存里面有没有InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);if (InjectionMetadata.needsRefresh(metadata, clazz)) {synchronized (this.injectionMetadataCache) {metadata = this.injectionMetadataCache.get(cacheKey);if (InjectionMetadata.needsRefresh(metadata, clazz)) {if (metadata != null) {metadata.clear(pvs);}metadata = buildAutowiringMetadata(clazz);this.injectionMetadataCache.put(cacheKey, metadata);}}}return metadata;}**
方法解读:在这里,用到了一个缓存,说白了就是一个map,来判断是否已经【寻找过注入点】了,也是为了方便后续做注入。在这里,最核心的操作还是通过调用buildAutowiringMetadata,构建了当前类的注入点信息,并且包装成了InjectionMetadata。
*3.4 AutowiredAnnotationBeanPostProcessor#buildAutowiringMetadata:构建注入点
方法调用链:由3.3的findAutowiringMetadata()调用进来
全路径:org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor#buildAutowiringMetadata
方法注释:构建注入点
源码如下:
private InjectionMetadata buildAutowiringMetadata(Class<?> clazz) {// 第一步:判断当前类是否候选类(是否需要【寻找注入点】)if (!AnnotationUtils.isCandidateClass(clazz, this.autowiredAnnotationTypes)) {return InjectionMetadata.EMPTY;}List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();Class<?> targetClass = clazz;do {final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();// 第二步:利用反射,寻找【字段】上是否有【自动注入】的注解ReflectionUtils.doWithLocalFields(targetClass, field -> {MergedAnnotation<?> ann = findAutowiredAnnotation(field);if (ann != null) {if (Modifier.isStatic(field.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static fields: " + field);}return;}boolean required = determineRequiredStatus(ann);currElements.add(new AutowiredFieldElement(field, required));}});// 第三步:利用反射,寻找【方法】上是否有【自动注入】的注解ReflectionUtils.doWithLocalMethods(targetClass, method -> {Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {return;}MergedAnnotation<?> ann = findAutowiredAnnotation(bridgedMethod);if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {if (Modifier.isStatic(method.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static methods: " + method);}return;}if (method.getParameterCount() == 0) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation should only be used on methods with parameters: " +method);}}boolean required = determineRequiredStatus(ann);PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);currElements.add(new AutowiredMethodElement(method, required, pd));}});elements.addAll(0, currElements);targetClass = targetClass.getSuperclass();}while (targetClass != null && targetClass != Object.class);return InjectionMetadata.forElements(elements, clazz);
}
方法解读:上面的方法看似很长,但整体上就分为三个步骤而已,没什么特别难理解的地方。特别是,如果你如果看过我前面的【手写Spring-引导篇】的话。
第一个步骤,判断当前类是否候选类(是否需要【寻找注入点】)。说实在这里暂时不确定啥意思,看代码就是过滤java.开头的类跟注解(百度了下,java.开头的一般是JDK开放的API,其中元注解就在里面声明,如:@Retention、@Target等)。所以我的理解是,这里的判断逻辑是让Spring的类,或者说我们自定义的类,可以使用JDK的【自动装配】注解,比如@Resource;但是JDK只能用JDK自己的【自动装配】注解。
第二个步骤:我们都知道,@Autowired注解,可以修饰在字段和方法上的,第二个步骤就是处理【字段】类型的注解。
第三个步骤:处理【方法】类型的注解。
关于第二、三步的源码实现其实都一样,只不过处理对象不一样而已,所以这里就只拿处理【字段】的逻辑来讲讲了。即如下:
ReflectionUtils.doWithLocalFields(targetClass, field -> {MergedAnnotation<?> ann = findAutowiredAnnotation(field);if (ann != null) {if (Modifier.isStatic(field.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static fields: " + field);}return;}boolean required = determineRequiredStatus(ann);currElements.add(new AutowiredFieldElement(field, required));}});
不过还是要先说一点。大家可能注意到了,这整个处理是在一个do-while循环体里面完成的,为什么呢?其实这里的do-while循环就是为了处理存在【继承关系的Bean】的注入而已。
3.5 ReflectionUtils#doWithLocalFields:利用反射遍历类上的【字段】
方法调用链:由3.4的buildAutowiringMetadata()调用进来
全路径:org.springframework.util.ReflectionUtils#doWithLocalFields
方法注释:对给定类中所有局部声明的字段调用给定的回调。
反射工具方法实现如下:
public static void doWithLocalFields(Class<?> clazz, FieldCallback fc) {for (Field field : getDeclaredFields(clazz)) {try {fc.doWith(field);}catch (IllegalAccessException ex) {throw new IllegalStateException("Not allowed to access field '" + field.getName() + "': " + ex);}}}
(PS:这上边的代码,如果对函数式接口,或者说lambda表达式使用不清楚的可能看不懂,得赶紧去复习下了)
3.6 AutowiredAnnotationBeanPostProcessor#findAutowiredAnnotation:寻找字段上的自动装配注解
方法调用链:由3.5的doWithLocalFields()调用进来
全路径:org.springframework.util.ReflectionUtils#doWithLocalFields
方法注释:对给定类中所有局部声明的字段调用给定的回调。
再然后,就是在反射【回调函数】里面,调用findAutowiredAnnotation判断当前字段、方法是否有【自动装配】的注解。如下:
@Nullableprivate MergedAnnotation<?> findAutowiredAnnotation(AccessibleObject ao) {MergedAnnotations annotations = MergedAnnotations.from(ao);for (Class<? extends Annotation> type : this.autowiredAnnotationTypes) {MergedAnnotation<?> annotation = annotations.get(type);if (annotation.isPresent()) {return annotation;}}return null;}
细心的朋友可能会问了, this.autowiredAnnotationTypes的值是啥?是的,我知道是@Autowired和@Value注解,但是在哪里赋值呢?啊,这个目前不会讲到,这是在Spring容器启动的章节才会给大家讲。但是可以先告诉大家,这个是在AutowiredAnnotationBeanPostProcessor的构造方法中初始化的。如下:
public AutowiredAnnotationBeanPostProcessor() {this.autowiredAnnotationTypes.add(Autowired.class);this.autowiredAnnotationTypes.add(Value.class);try {this.autowiredAnnotationTypes.add((Class<? extends Annotation>)ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));logger.trace("JSR-330 'javax.inject.Inject' annotation found and supported for autowiring");}catch (ClassNotFoundException ex) {// JSR-330 API not available - simply skip.}}
3.7 Modifier.isStatic
方法调用链:由3.5的doWithLocalFields()调用进来
全路径:java.lang.reflect.Modifier#isStatic
方法注释:对给定类中所有局部声明的字段调用给定的回调。
然后,如果找到有被@Autowired和@Value注解的字段或者方法,还会判断该字段或者方法是否被static修饰,即静态的。静态的就不处理了。源码如下:
if (Modifier.isStatic(field.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static fields: " + field);}return;}if (Modifier.isStatic(method.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static methods: " + method);}return;}
点解啊?道理很简单的,你从原型Bean考虑一下就知道了。我们知道静态的是属于类的,不是属于对象的,那如果你每次注入的时候还要处理静态,那不就重复覆盖了吗?举例:
@Component
@Scope("prototype")
public class OrderService {
}@Component
@Scope("prototype")
public class UserService {@Autowiredprivate static OrderService orderService;public void test() {System.out.println("test123");}}
看上面代码,UserService和OrderService都是原型Bean,假设Spring支持static字段进行自动注入,那么现在调用两次
UserService userService1 = context.getBean("userService")
UserService userService2 = context.getBean("userService")
问此时,userService1的orderService值是什么?还是它自己注入的值吗?答案是不是,一旦userService2 创建好了之后,static orderService字段的值就发生了修改了,从而出现bug。
3.8 剩余步骤
剩余步骤,干了三件事,如下:
- 设置
@Autowired(required = false)这个属性 - 将得到构建点包装成
InjectionMetadata.InjectedElement - 将得到的所有注入点,封装成
InjectionMetadata,接着缓存起来
四、【寻找注入点】逻辑流程图
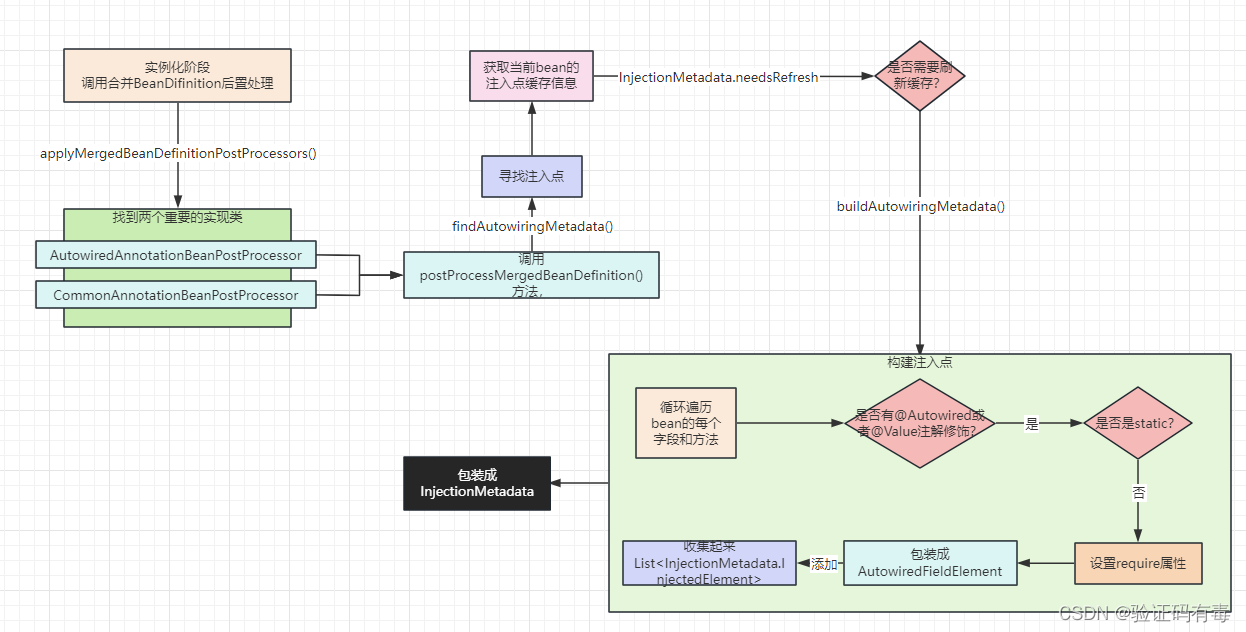
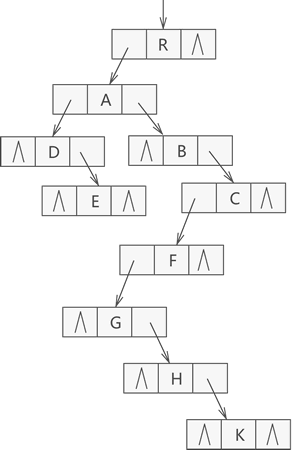
流程描述:
- 遍历当前类的所有的属性字段Field
- 查看字段上是否存在@Autowired、@Value、@Inject中的其中任意一个,存在则认为该字段是一个注入点
- 如果字段是static的,则不进行注入
- 获取@Autowired中的required属性的值
- 将字段信息构造成一个AutowiredFieldElement对象,作为一个注入点对象添加到currElements集合中。
- 遍历当前类的所有方法Method
- 判断当前Method是否是桥接方法,如果是找到原方法
- 查看方法上是否存在@Autowired、@Value、@Inject中的其中任意一个,存在则认为该方法是一个注入点
- 如果方法是static的,则不进行注入
- 获取@Autowired中的required属性的值
- 将方法信息构造成一个AutowiredMethodElement对象,作为一个注入点对象添加到currElements集合中。
- 遍历完当前类的字段和方法后,将遍历父类的,直到没有父类。
- 最后将currElements集合封装成一个InjectionMetadata对象,作为当前Bean对于的注入点集合对象,并缓存。



![[MySQL] — 数据类型和表的约束](https://img-blog.csdnimg.cn/0574370828b24d1ba8a12ac9eec4e1ab.png)