本文介绍了 PingCAP 是如何用 Generative AI 构建一个使用企业专属知识库的用户助手机器人。除了使用业界常用的基于知识库的回答方法外,还尝试使用模型在 few shot 方法下判断毒性。 最终,该机器人在用户使用后,点踩的比例低于 5%,已经应用到了 TiDB 面向全球客户的各种渠道中。
Generative Al 的魔力已经展现
从 22 年开始,Generative AI (后文称 GenAI)在全球席卷了浪潮。 自 MidJourney ( https://www.midjourney.com/ ), DALL-E ( https://openai.com/dall-e-2 ) 带来了文字生成图片的火热,再到 ChatGPT ( https://openai.com/chatgpt ) 以自然、流利的对话彻底引爆人们的视线,GenAI 成为再也无法绕过的话题。 AI 是否能够在更通用的场景下支持人类更好的生活、工作,成为了 23 年的核心话题之一。
其中,LangChain ( https://www.langchain.com/ ) 等开发工具的崛起,代表着工程师开始批量的创建基于 GenAI 的应用。PingCAP 也做了一些实验,并且陆续完成了一些工作,比如:
● Ossingisht 的 Data Explorer ( https://ossinsight.io/explore/ ):一个用自然语言生成 SQL 来探索 Github 开源软件的项目
● TiDB Cloud 的 Chat2Query ( https://docs.pingcap.com/tidbcloud/explore-data-with-chat2query ):一个利用 Cloud 内数据库通过自然语言生成 SQL 的项目在构建了这些应用后,笔者开始思考是否可以用 GenAI 的能力构建更通用的应用,带给用户更大的价值。
需求思考
在全球 TiDB 和 TiDB Cloud 逐步成长下,面向全球用户的支持成为越来越重要的事情。 而随着用户量的几何增长,面向用户的支持人员数量并不会快速增长,因此,如何承接海量用户就成为急需考虑的事情。
根据实际支持用户的体验,对用户在全球社区的提问以及内部工单系统的调研,用户有 50% 以上的问题其实是可以在官方文档中找到答案,只是因为文档内容太多,难以找到。因此,如果可以提供一个具有 TiDB 所有官方文档的知识的机器人,也许可以帮助用户更好的使用 TiDB。
Generative Al 与需求实现的差距
发掘出需求后,也需要了解 GenAI 的特性和限制,以确认是否 Gen AI 能够用在此需求中。 根据已经完成的工作,笔者可以总结出一些 Gen AI 的特性。 在这里,Gen AI 主要指 GPT (Generative Pre-trained Transformer )类模型,以文本对话为主,本文后续都以 GPT 来描述。
1 GPT 的能力
● 理解语义的能力 。GPT 具有极强的语义理解能力,基本上可以无障碍理解任何文本。无论是何种语言(人类语言或计算机语言),何种表达水平的文本,就算是多语言混杂,或者是语法、用词错误,都可以理解用户的提问。
● 逻辑推理的能力 。GPT 具体一定的逻辑推理能力,在不额外增加任何特殊提示词情况下,GPT 可以做出简单的推理,并且挖掘出问题深层的内容。在补充了一定的提示词下,GPT 可以做出更强的推理能力,这些提示词的方法包括:Few-shot,Chain-of-Thought(COT),Self-Consistency,Tree of thought(TOT) 等等。
● 尝试回答所有问题的能力 。GPT,特别是 Chat 类型的 GPT,如 GPT 3.5,GPT 4,一定会尝试用对话形式,在满足设定价值观的情况下,回答用户的所有问题,就算是回答“我不能回答这个信息”。
● 通用知识的能力 。GPT 自身拥有海量的通用知识,这些通用知识有较高的准确度,并且覆盖范围很大。
● 多轮对话的能力 。GPT 可以根据设定好的角色,理解不同角色之间的多次对话的含义,这意味着可以在对话中采用追问形式,而不是每一次对话都要把历史所有的关键信息都重复一遍。这种行为非常符合人类的思考和对话逻辑。
2 GPT 的限制
● 被动触发 。GPT 必须是用户给出一段内容,才会回复内容。这意味着 GPT 本身不会主动发起交互。
● 知识过期 。这里特指 GPT 3.5 和 GPT 4,二者的训练数据都截止于 2021 年 9 月,意味着之后的知识,GPT 是不知道的。不能期待 GPT 本身给你提供一个新的知识。
● 细分领域的幻觉 。虽然 GPT 在通用知识部分有优秀的能力,但是在一个特定的知识领域,比如笔者所在的数据库行业,GPT 的大部分回答都存在着或多或少的错误,无法直接采信。
● 对话长度 。GPT 每轮对话有着字符长度的限制,因而如果提供给 GPT 超过字符长度的内容,此次对话会失败。
3 需求实现的差距
笔者期望用 GPT 实现一个“企业专属的用户助手机器人”,这意味着以下需求:
● 需求一:多轮对话形式,理解用户的提问,并且给出回答。
● 需求二:回答的内容中关于 TiDB 和 TiDB Cloud 的内容需要正确无误。
● 需求三:不能回答和 TiDB、TiDB Cloud 无关的内容。
对这些需求进行分析:
● 需求一:基本上可以满足,根据 GPT 的“理解语义的能力”、“逻辑推理的能力”、“尝试回答问题的能力”、“上下文理解的能力”。
● 需求二:无法满足。因为 GPT 的“知识过期”、“细分领域的幻觉”限制。
● 需求三:无法满足。因为 GPT 的 “尝试回答所有问题的能力”,任何问题都会回答,并且 GPT 本身并不会限制回答非 TiDB 的问题。
因此,在这个助手机器人构建中,主要就是在解决需求二和需求三的问题。
正确回答细分领域知识
这里要解决需求二的问题。
如何让 GPT 根据特定领域知识回答用户的问题并不是新鲜的领域,笔者之前的优化的 Ossinsight - Data Explorer 就使用特定领域知识,帮助自然语言生成 SQL 的可执行率(即生成的 SQL 可以成功的在 TiDB 中运行出结果)提升了 25% 以上 。
这里需要运用到的是向量数据库的空间相似度搜索能力。一般分为三个步骤:
1 领域知识存储到向量数据库中
第一步是将 TiDB ( https://docs.pingcap.com/tidb/stable ) 和 TiDB Cloud ( https://docs.pingcap.com/tidbcloud ) 的官方文档放入到向量数据库中。
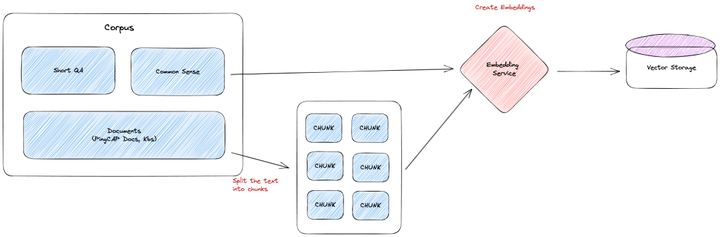
获取到文档后,将文字内容其放入 Embedding 模型中,产出文字内容对应的向量,并将这些向量放入到特定的向量数据库中。
在这一步中,需要检查两点:
● 如果文档的质量较差,或者文档的格式不满足预期,会事先对文档进行一轮预处理,将文档转化为相对干净,容易被 LLM 理解的文本格式。
● 如果文档较长,超过 GPT 单次的对话长度,就必须对文档进行裁剪,以满足长度需要。裁剪方法有很多种,比如,按特定字符(如,逗号,句号,分号)裁剪,按文本长度裁剪,等等。
2 从向量数据库中搜索相关内容
第二步是在用户提出问题的时候,从向量数据库中,根据用户问题搜索相关的文本内容。
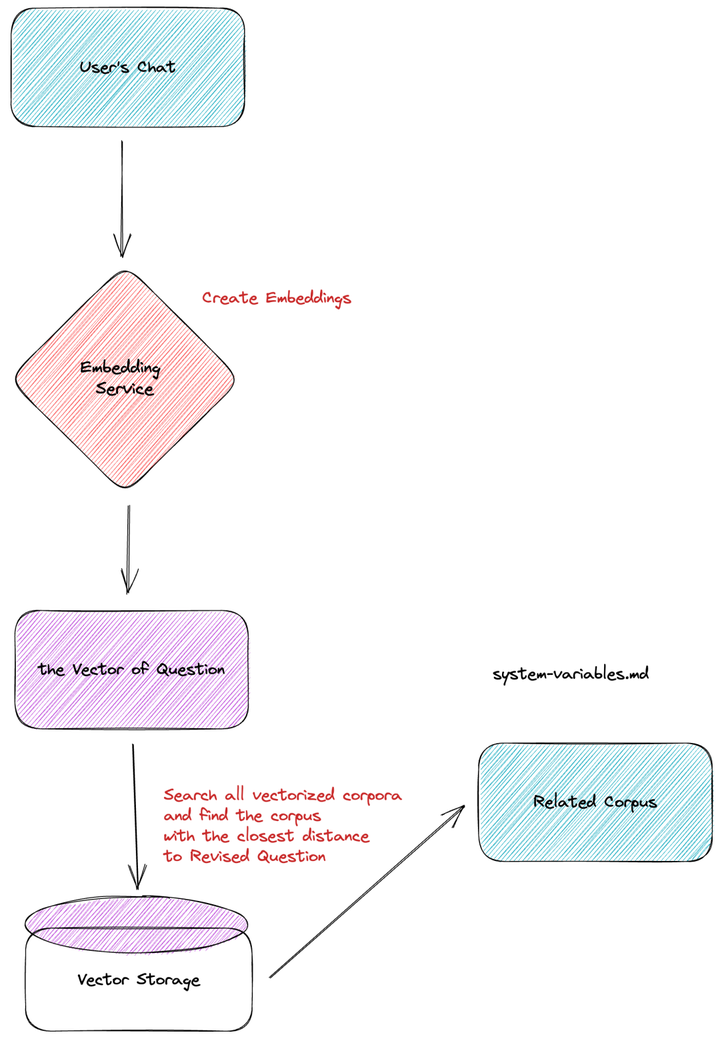
当用户发起一次对话时,系统会将用户的对话也通过 Embedding 模型转化成向量,再将这个向量放到向量数据库中和原有的预料进行查询。查询过程中,利用相似度算法(比如,cosine similarity,dot-product,等等),计算最相似的领域知识向量,并且提取出对应向量的文本内容。
用户的特定问题可能需要多篇文档才能回答,所以在搜索过程中,会取相似度最高的 Top N(目前 N 是 5)。这些 Top N 可以满足跨越多个文档的需要,并且都会成为下一步提供给 GPT 的内容。
3 相关内容和用户提问一起提供给 GPT
第三步是组装所有的相关信息,将其提供给 GPT。
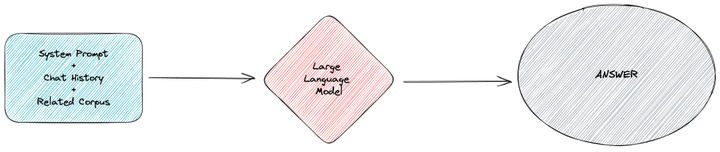
将任务目标和相关的领域知识包含在系统提示词中,并且根据历史对话组装好聊天历史。将所有内容一起提供给 GPT,就可以得到基于这部分领域知识的特定回答。
在完成以上步骤,我们就基本上可以满足需求二,可以根据特定的领域知识回答问题,回答正确性相比直接提问 GPT 有极大提升。
限定回答领域
这里要解决需求三的问题。
该机器人是作为企业支持能力提供给用户,因此期望机器人只回答和企业相关的内容,比如,TiDB、TiDB Cloud 本身,SQL 问题,应用构建问题,等等。如果超过这些范围,就期望机器人拒绝回答,比如,天气、城市、艺术,等等。
因为之前提到 GPT 的“尝试回答所有问题的能力”,对于 GPT 本身的设定,任何问题都应该要做出符合人类价值观的回复。所以,这一层限制无法依赖 GPT 帮我们构建,只能在应用侧尝试做限制。
只有做到了这个需求,一个业务才可能真正的上线对用户服务。遗憾的是目前工业界没有对此比较好的实现,大部分的应用设计中并不涉及这一部分内容。
1 概念:毒性
刚刚提到,GPT 其实会尝试让回答符合人类的价值观,这步工作在模型训练中叫做“对齐”(Align),让 GPT 拒绝回答仇恨、暴力相关的问题。如果 GPT 未按照设定回答了仇恨、暴力相关问题,就称之为检测出了毒性(Toxicity)。
因此,对于笔者即将创造的机器人,其毒性的范围实际上增加了,即,所有回答了非公司业务的内容都可以称之为存在毒性。在此定义下,我们就可以参考前人在去毒(Detoxifying)方面的工作。DeepMind 的 Johannes Welbl ( https://aclanthology.org/2021.findings-emnlp.210.pdf ) (2021)等人介绍了可以采用语言模型来做为毒性检测的方式,目前,GPT 的能力得到了足够的加强,用 GPT 来直接判断用户的提问是否属于公司业务范围,成为了可能。
要做到“限定回答领域”,需要有两个步骤。
2 限定领域的判断
第一步,需要对用户的原始提问进行判断。
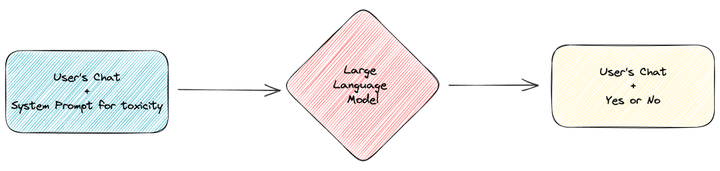
这里需要使用 few shot 的方法去构建毒性检测的提示词,让 GPT 在拥有多个示例的情况下,判断用户的提问是否符合企业服务的范围。
比如一些示例:
<< EXAMPLES >>
instruction: who is Lady Gaga?
question: is the instruction out of scope (not related with TiDB)?
answer: YES
instruction: how to deploy a TiDB cluster?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
instruction: how to use TiDB Cloud?
question: is the instruction out of scope (not related with TiDB)?
answer: NO在判断完成后,GPT 会输入 Yes 或 No 的文字,供后续流程处理。注意,这里 Yes 意味着有毒(和业务不相关),No 意味着无毒(和业务有关)。
第二步,得到了是否有毒的结果后,我们将有毒和无毒的流程分支,进行异常流程和正常流程的处理。
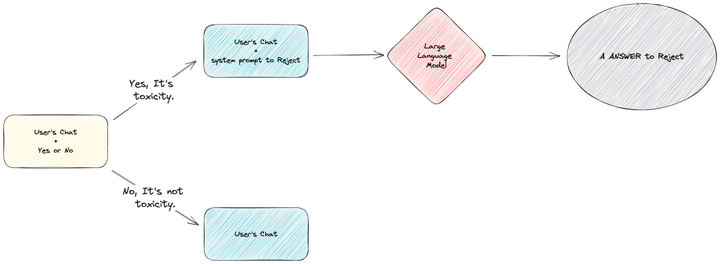
正常流程就是上文中的 正确回答细分领域知识相关内容,此处主要说明异常内容的流程。
当系统发现产出的内容是 “Yes” 时,会引导流程进入毒性内容回复流程。此时,会将一个拒绝回答用户问题的系统提示词和用户对应的问题提交给 GPT,最终用户会得到一个拒绝回答的回复。
当完成这两步后,需求三基本完成。
整体逻辑架构
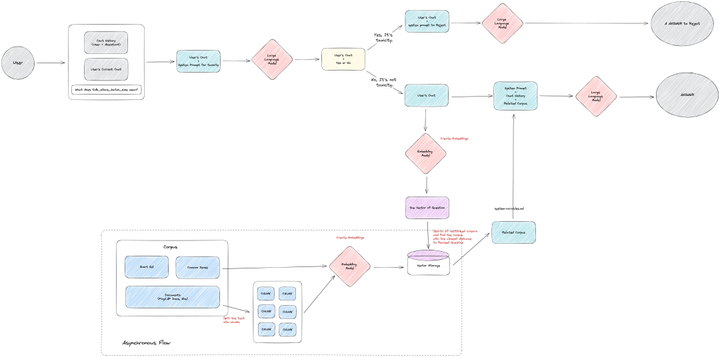
至此,我们得到了一个基本可以提供给用户的,具有特定企业领域知识的助手机器人。这机器人我们称之为 TiDB Bot。
TiDB Bot 上线后效果
从 3 月 30 日起,TiDB Bot 就开始进行内部测试,直到 7 月 11 日正式对 Cloud 的用户开放。
在 TiDB Bot 孵化的 103 天来,感谢无数的社区、开发者对测试产品提出的反馈,让 TiDB Bot 逐步变得可用。在测试阶段,一共 249 名用户使用,发送了 4570 条信息。到测试阶段完成为止,共有 83 名用户给出了 266 条反馈,其中点踩的反馈占总信息数的 3.4%,点赞的反馈占总信息数的 2.1%。
除了直接使用的社区用户,还有提出建议和思路的用户,给出更多解决方案的社区用户。感谢所有的社区和开发者,没有你们,就没有 TiDB Bot 产品发布。
后续
随着用户量逐渐增加,无论是召回内容的准确性、毒性判断的成功,都依然有不小的挑战,因此,笔者在实际提供服务中,对 TiDB Bot 的准确度进行优化,稳步提升回答效果。 这些内容将在后续的文章中介绍。