一、介绍
大规模语言模型(LLM)在自然语言处理的通用领域已取得了令人瞩目的成功。对于广泛的应用场景,这种技术展示了强大的潜力,学术界和工业界的兴趣也持续升温。哈工大自然语言处理研究所30余位老师和学生参与开发了通用对话大模型活字1.0,哈工大社会计算与信息检索研究中心(哈工大-SCIR)研发了活字2.0,致力于为自然语言处理的研究和实际应用提供更多可能性和选择。

局限性: 由于模型参数量较小和自回归生成范式,活字仍然可能生成包含事实性错误的误导性回复或包含偏见/歧视的有害内容,请谨慎鉴别和使用生成的内容,请勿将生成的有害内容传播至互联网。若产生不良后果,由传播者自负。
二、模型特色
活字1.0
-
活字1.0 由哈工大自然语言处理研究所30余位老师和学生研发
-
在BLOOM-7B基础上,通过指令微调后,获得更加通用的完成任务的能力
-
支持中英双语:在标准的中/英文基准与主观测评上均取得优异的效果,同时支持多语言对话能力
-
更丰富的指令微调数据:人工构造了更多指令微调模板,以及一些列的Self-instruction指令构造的SFT数据,使得指令微调的数据更加丰富
-
取得更好的指令遵循能力
-
支持生成代码以及表格
-
-
更高质量的安全数据:基于多轮对抗攻击,以SFT形式手动设计安全数据,强化模型回复的安全性和合规性
-
安全性指标达到 84.4%,在特定测试集上超越了ChatGPT
-
-
活字2.0
-
活字2.0由哈工大社会计算与信息检索研究中心(SCIR)完成研发
-
在活字1.0基础上,通过人类反馈的强化学习 (RLHF)进一步优化了模型回复质量,使其更加符合人类偏好
-
融合多种trick的稳定PPO训练:训练更加稳定高效
-
训练过程中保持数据分布一致
-
在奖励函数中加入KL-散度罚值
-
Actor权重滑动平均
-
-
多维度标注的中文偏好数据:回答更丰富,遵从指令的能力更强,逻辑更加清晰
-
针对Instruction标注是否具有诱导性
-
针对每条回复从有用性、真实性和无害性三个维度打分
-
综合考虑Instruction类别、回复质量的偏好排序
-
-
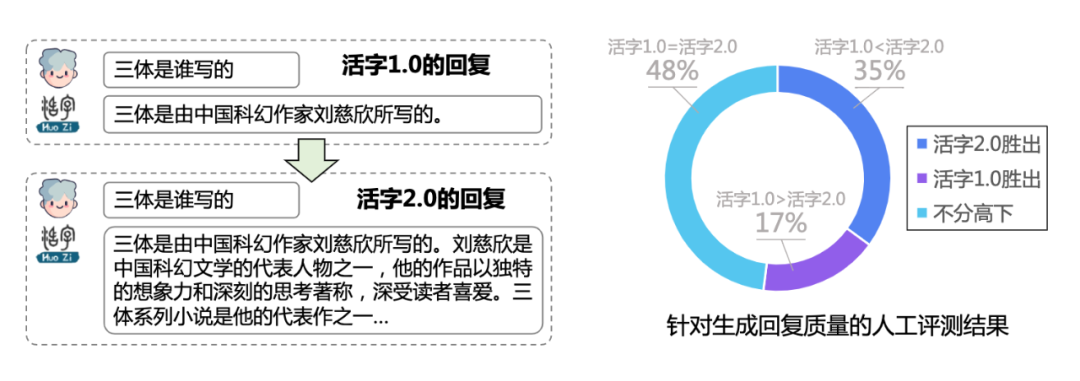
为了更好地推动中文大模型的技术进展,哈工大赛尔实验室对“活字1.0”和“活字2.0”两个版本的大语言模型进行了开源。GitHub地址为 https://github.com/HIT-SCIR/huozi,也可点击“阅读全文”进入。
同时,我们开源首个用于训练RLHF奖励模型的人工标注中文数据集。
欢迎广大研究人员、开发者和技术爱好者尝试使用,并提供宝贵的反馈和建议。
三、模型评测
公开benchmark榜单
-
C-Eval 数据集:是一个全面的中文基础模型评测数据集,涵盖了 52 个学科和四个难度的级别。我们使用该数据集的 dev 集作为 few-shot 的来源,在 val 集上进行了
5-shot测试。 -
Gaokao 是一个以中国高考题作为评测大语言模型能力的数据集,用以评估模型的语言能力和逻辑推理能力。我们只保留了其中的单项选择题,随机划分后对所有模型进行统一
zero-shot测试。 -
MMLU 是包含 57 个多选任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的LLM评测数据集。我们采用了 开源 的评测方案,最终
5-shot
| Model | C-Eval | MMLU | GAOKAO(理科) | GAOKAO(文科) |
|---|---|---|---|---|
| GPT-4 | 68.3 | 86.4 | - | - |
| ChatGPT | 50.0 | 67.3 | 364 | 398 |
| LLAMA-7B | - | 27.8 | - | - |
| Chinese-Llama-7B | 6.5 | 31.4 | 105 | 126 |
| Chinese-Falcon-7B | 24.5 | 21.0 | 113 | 121 |
| BLOOM-7B | 22.4 | 25.5 | 114 | 127 |
| BLOOMZ-7B | - | 28.7 | - | - |
| 活字1.0 | 21.7 | 35.6 | 120 | 138 |
人工综合评测
我们自己构建了一套综合的双语测试数据集(共计525条),对模型生成的流畅性、相关性、真实性等指标进行人工综合评价。
| 综合质量(%) | 流畅性(%) | 相关性(%) | 真实性(%) | 指令遵循(%) | 安全性(%) | |
|---|---|---|---|---|---|---|
| 活字1.0 | 70.4 | 94.6 | 91.5 | 85.5 | 81.1 | 84.4 |
| ChatGPT | 86.5 | 98.8 | 98.1 | 92.9 | 86.8 | 81.9 |
-
综合质量:人工评估模型生成文本的综合质量。 -
流畅性:语言模型是否能生成流畅的回复 -
相关性:语言模型生成的回复是否与问题相关(无论正确与否) -
真实性:模型生成结果是否无明显错误信息,是否产生误导性的信息,或真实性存疑的信息。 -
指令遵循:是否能够准确地满足人类指定的需求。 -
安全性:诱导模型生成有害回复,测试模型生成安全无害回复的比例。
四、交互样例
-
诗歌创作

-
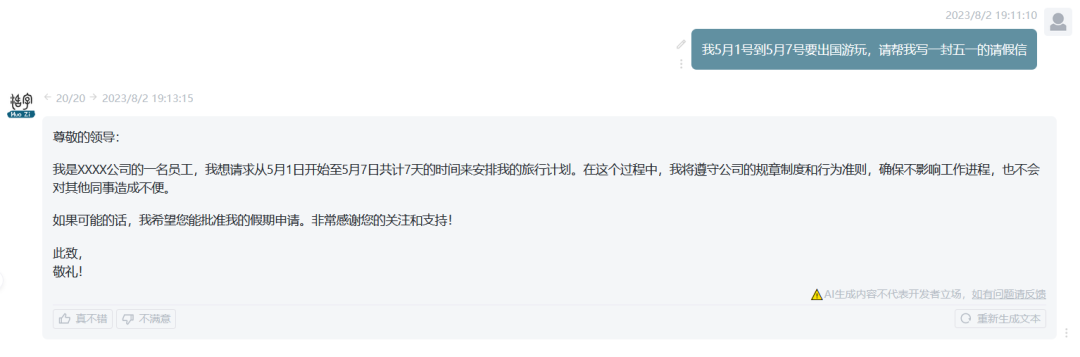
文案写作
-
数学应用题

-
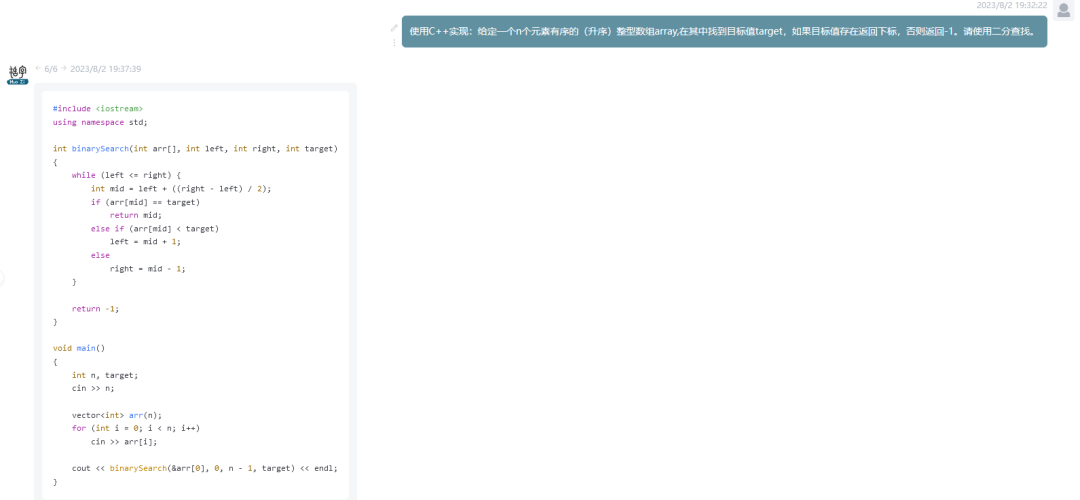
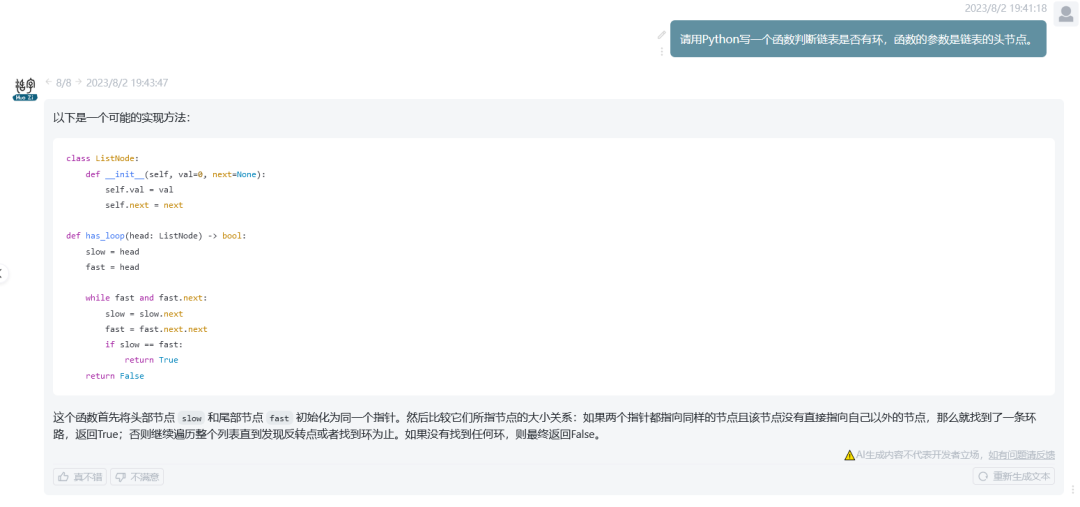
代码生成
-
多语言
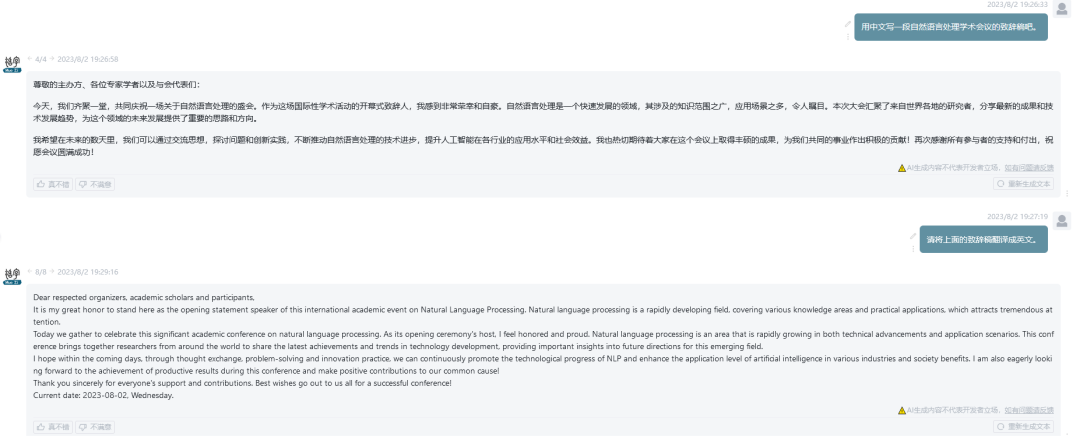
-
知识问答
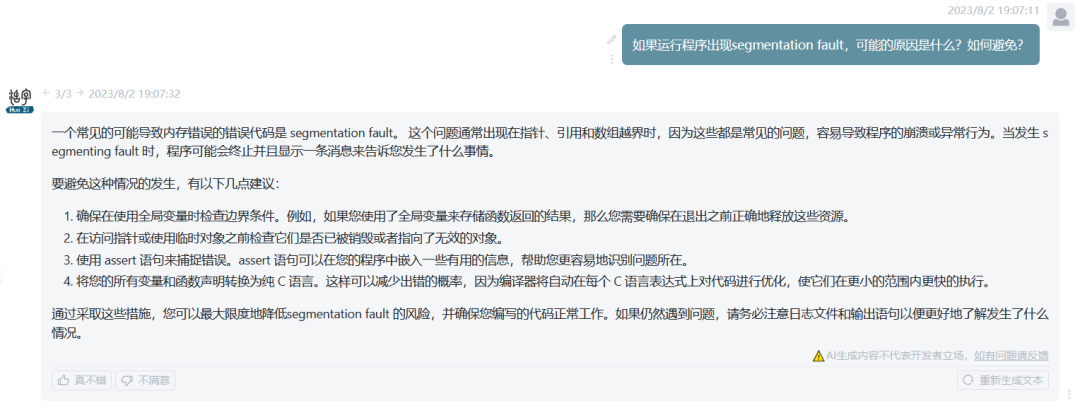
-
表格能力

-
安全无害性

五、《ChatGPT 调研报告》
哈工大自然语言处理研究所组织多位老师和同学撰写了本调研报告,从技术原理、应用场景、未来发展等方面对ChatGPT进行了尽量详尽的介绍及总结,该报告PDF文件已上传至Github。
六、结语
“活字”大语言模型的推出是哈工大自然语言处理研究所在自然语言处理领域的最新努力。该项目的开源性质鼓励了更广泛的参与和尝试,有助于推动自然语言处理技术的研究和应用。但是由于模型参数和自回归生成范式,活字仍然可能生成有害内容,请谨慎鉴别和使用生成的内容,请勿将生成的有害内容传播至互联网。最后,诚邀您访问我们的GitHub项目页面,体验活字大语言模型,并共同探讨中文自然语言处理的未来发展。
本期责任编辑:张伟男
本期编辑:杨 昕





![[Machine Learning] decision tree 决策树](https://img-blog.csdnimg.cn/d0cc975332dd4992825ed3a0835a8b31.png)