概述
Redis 是一个开源的高性能键值数据库,它支持多种数据类型,可以满足不同的业务需求。本文将介绍 Redis 的10种数据类型,分别是
-
string(字符串)
-
hash(哈希)
-
list(列表)
-
set(集合)
-
zset(有序集合)
-
stream(流)
-
geospatial(地理)
-
bitmap(位图)
-
bitfield(位域)
-
hyperloglog(基数统计)
String
概述
string 是 Redis 最基本的数据类型,它可以存储任意类型的数据,比如文本、数字、图片或者序列化的对象。一个 string 类型的键最大可以存储 512 MB 的数据。
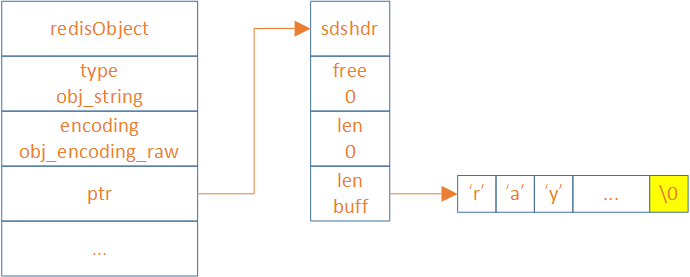
string 类型的底层实现是 SDS(simple dynamic string),它是一个动态字符串结构,由长度、空闲空间和字节数组三部分组成。SDS有3种编码类型:
-
embstr:占用64Bytes的空间,存储44Bytes的数据
-
raw:存储大于44Bytes的数据
-
int:存储整数类型
embstr和raw存储字符串数据,int存储整型数据
应用场景
string 类型的应用场景非常广泛,比如:
-
缓存数据,提高访问速度和降低数据库压力。
-
计数器,利用 incr 和 decr 命令实现原子性的加减操作。
-
分布式锁,利用 setnx 命令实现互斥访问。
-
限流,利用 expire 命令实现时间窗口内的访问控制。
底层原理
embstr结构
embstr 结构存储小于等于44个字节的字符串,embstr 每次开辟64个byte的空间
-
前19个byte用于存储embstr 结构
-
中间的44个byte存储数据
-
最后为
\0符号
raw结构
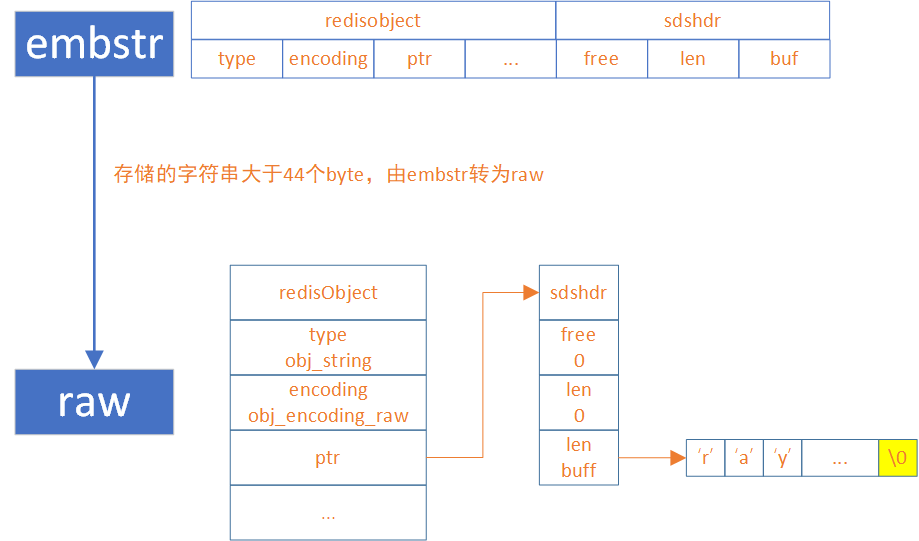
embstr和raw的转换
在存储字符串的时候,redis会根据数据的长度判断使用哪种结构
-
如果长度小于等于44个字节,就会选择embstr 结构
-
如果长度大于44个byte,就会选择raw结构
127.0.0.1:6379> object encoding str
"embstr"
# str赋值44个字节的字符串
127.0.0.1:6379> set str 1234567890123456789012345678901234567890abcd
OK
127.0.0.1:6379> object encoding str
"embstr"
# str2赋值45个字节的字符串
127.0.0.1:6379> set str2 1234567890123456789012345678901234567890abcde
OK
127.0.0.1:6379> object encoding str2
"raw"
127.0.0.1:6379> set num 123
OK
127.0.0.1:6379> object encoding num
"int"
Hash
概述
hash 是一个键值对集合,它可以存储多个字段和值,类似于编程语言中的 map 对象。一个 hash 类型的键最多可以存储 2^32 - 1 个字段。
Hash类型的底层实现有三种:
-
ziplist:压缩列表,当hash达到一定的阈值时,会自动转换为hashtable结构 -
listpack:紧凑列表,在Redis7.0之后,listpack正式取代ziplist。同样的,当hash达到一定的阈值时,会自动转换为hashtable结构 -
hashtable:哈希表,类似map
应用场景
hash 类型的应用场景主要是存储对象,比如:
-
用户信息,利用 hset 和 hget 命令实现对象属性的增删改查。
-
购物车,利用 hincrby 命令实现商品数量的增减。
-
配置信息,利用 hmset 和 hmget 命令实现批量设置和获取配置项。
底层原理
Redis在存储hash结构的数据,为了达到内存和性能的平衡,也针对少量存储和大量存储分别设计了两种结构,分别为:
-
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)
-
hashTable
从ziplist/listpack编码转换为hashTable编码是通过判断元素数量或单个元素Key或Value的长度决定的:
-
hash-max-ziplist-entries:表示当hash中的元素数量小于或等于该值时,使用ziplist编码,否则使用hashtable编码。ziplist是一种压缩列表,它可以节省内存空间,但是访问速度较慢。hashtable是一种哈希表,它可以提高访问速度,但是占用内存空间较多。默认值为512。 -
hash-max-ziplist-value:表示当 hash中的每个元素的key和value的长度都小于或等于该值时,使用 ziplist编码,否则使用 hashtable编码。默认值为 64。
ziplist与listpack
ziplist/listpack都是hash结构用来存储少量数据的结构。从Redis7.0后,hash默认使用ziplist结构。因为 ziplist有一个致命的缺陷,就是连锁更新,当一个节点的长度发生变化时,可能会导致后续所有节点的长度字段都要重新编码,这会造成极差的性能
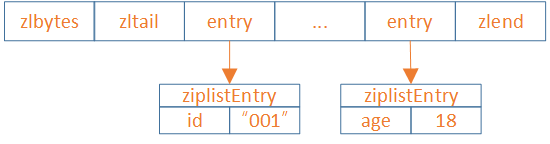
ziplist结构
ziplist是一种紧凑的链表结构,它将所有的字段和值顺序地存储在一块连续的内存中。
Redis中ziplist源码
typedef struct {/* 当使用字符串时,slen表示为字符串长度 */unsigned char *sval;unsigned int slen;/* 当使用整形时,sval为NULL,lval为ziplistEntry的value */long long lval;
} ziplistEntry;
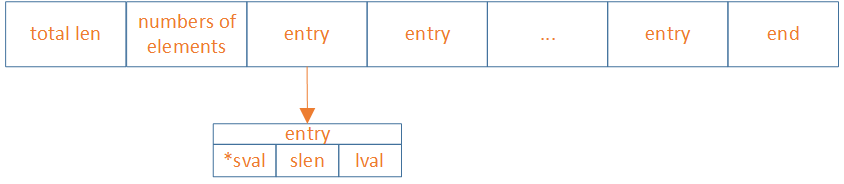
listpack结构
zipList的连锁更新问题
ziplist的每个entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个byte:
-
如果前一节点的长度小于254个byte,则采用1个byte来保存这个长度值
-
如果前一节点的长度大于等于254个byte,则采用5个byte来保存这个长度值,第一个byte为0xfe,后四个byte才是真实长度数据
假设,现有有N个连续、长度为250~253个byte的entry,因此entry的previous_entry_length属性占用1个btye
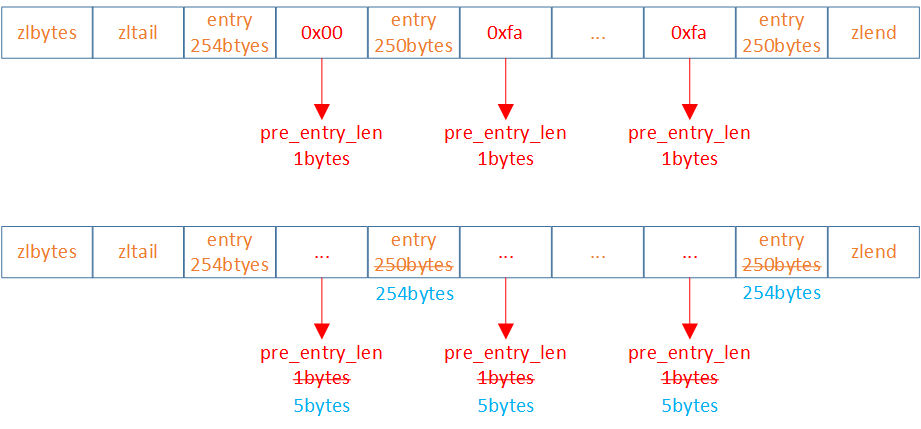
当第一节长度大于等于254个bytes,导致第二节previous_entry_length变为5个bytes,第二节的长度由250变为254。而第二节长度的增加必然会影响第三节的previous_entry_length。ziplist这种特殊套娃的情况下产生的连续多次空间扩展操作成为连锁更新。新增、删除都可能导致连锁更新的产生。
listpack是如何解决的
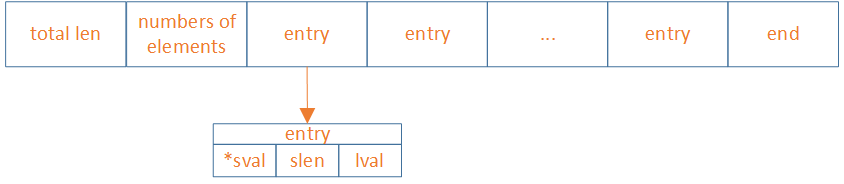
-
由于ziplist需要倒着遍历,所以需要用previous_entry_length记录前一个entry的长度。而listpack可以通过total_bytes和end计算出来。所以previous_entry_length不需要了。
-
listpack 的设计彻底消灭了 ziplist 存在的级联更新行为,元素与元素之间完全独立,不会因为一个元素的长度变长就导致后续的元素内容会受到影响。
-
与ziplist做对比的话,牺牲了内存使用率,避免了连锁更新的情况。从代码复杂度上看,listpack相对ziplist简单很多,再把增删改统一做处理,从listpack的代码实现上看,极简且高效。
hashTable
hashTable是一种散列表结构,它将字段和值分别存储在两个数组中,并通过哈希函数计算字段在数组中的索引
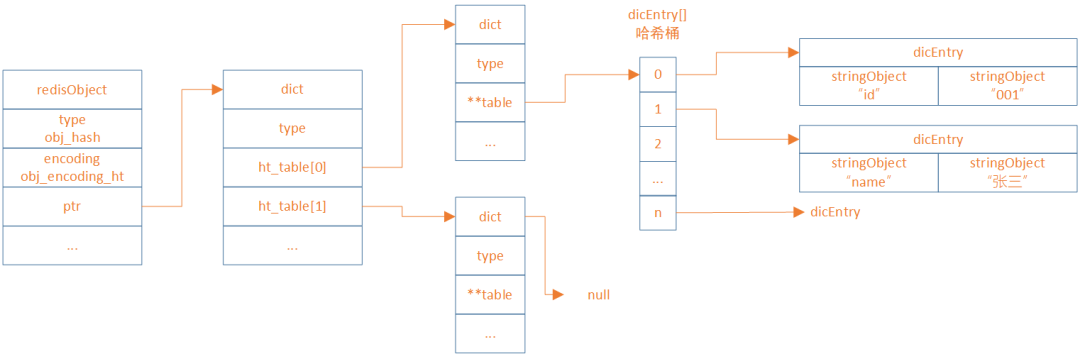
Redis中hashTable源码
struct dict {dictType *type;dictEntry **ht_table[2];unsigned long ht_used[2];long rehashidx; /* 当进行rehash时,rehashidx为-1 */int16_t pauserehash; /* 如果rehash暂停,pauserehash则大于0,(小于0表示代码错误)*/signed char ht_size_exp[2]; /* 哈希桶的个数(size = 1<<exp) */
};typedef struct dict {dictEntry **table;dictType *type;unsigned long size;unsigned long sizemask;unsigned long used;void *privdata;
} dict;typedef struct dictEntry {void *key;void *val;struct dictEntry *next;
} dictEntry;
ziplist和hashTable的转换
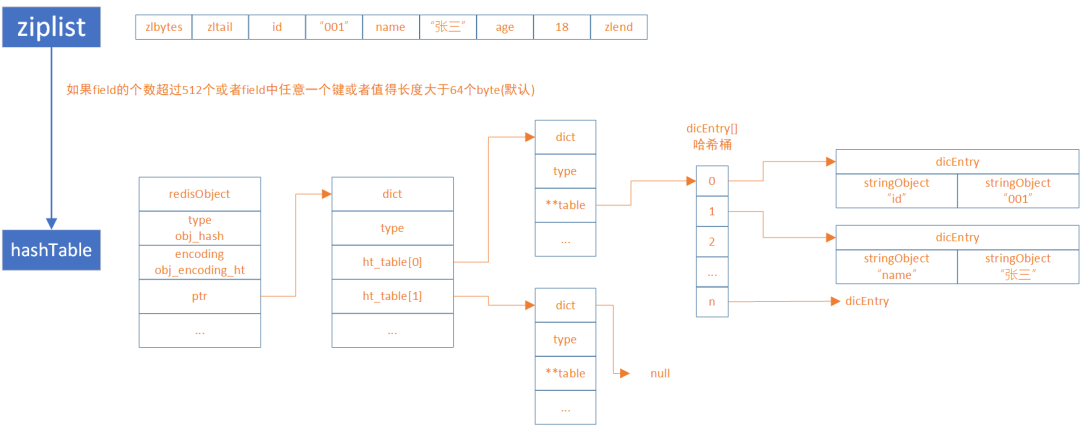
127.0.0.1:6379> hset h1 id 123456789012345678901234567890123456789012345678901234567890abcd
(integer) 1
127.0.0.1:6379> object encoding h1
"ziplist"
127.0.0.1:6379> hset h2 id 123456789012345678901234567890123456789012345678901234567890abcde
(integer) 1
127.0.0.1:6379> object encoding h2
"hashtable"ziplist的废弃
显然是ziplist在field个数太大、key太长、value太长三者有其一的时候会有以下问题:
-
ziplist每次插入都有开辟空间,连续的
-
查询的时候,需要从头开始计算,查询速度变慢
hashTable变得越来越长怎么办
扩容,hashTabel是怎么扩容的?使用的是渐进式扩容rehash。rehash会重新计算哈希值,且将哈希桶的容量扩大。
rehash 步骤
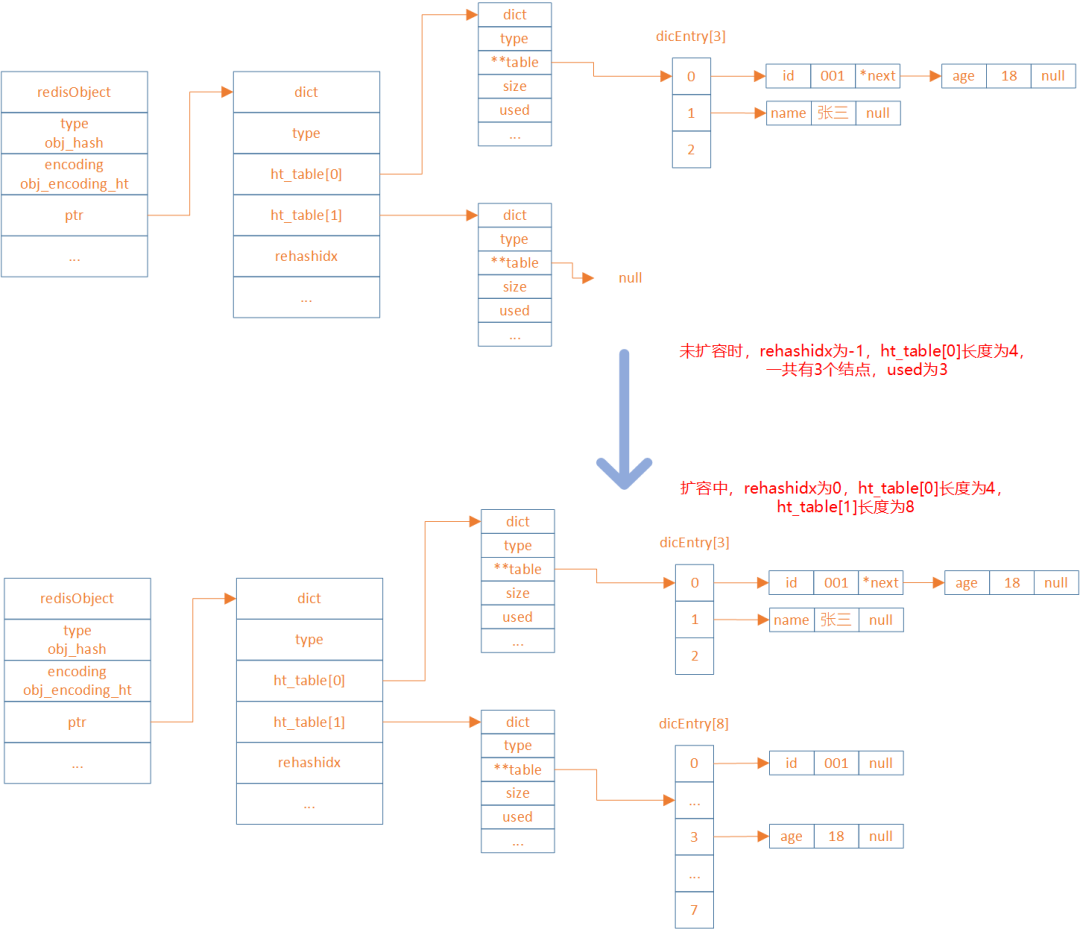
扩展哈希和收缩哈希都是通过执行rehash来完成,这其中就涉及到了空间的分配和释放,主要经过以下五步:
-
为字典dict的ht[1]哈希表分配空间,其大小取决于当前哈希表已保存节点数(即:
ht[0].used):-
如果是扩展操作则ht[1]的大小为2的n次方中第一个大于等于
ht[0].used * 2属性的值(比如used=3,此时ht[0].used * 2=6,故2的3次方为8就是第一个大于used * 2的值(2 的 2 次方 6))。 -
如果是收缩操作则ht[1]大小为 2 的 n 次方中第一个大于等于
ht[0].used的值
-
-
将字典中的属性
rehashidx的值设置为0,表示正在执行rehash操作 -
将ht[0]中所有的键值对依次重新计算哈希值,并放到ht[1]数组对应位置,每完成一个键值对的
rehash之后rehashidx的值需要自增1 -
当ht[0]中所有的键值对都迁移到ht[1]之后,释放ht[0],并将ht[1]修改为ht[0],然后再创建一个新的ht[1]数组,为下一次rehash做准备
-
将字典中的属性
rehashidx设置为-1,表示此次rehash操作结束,等待下一次rehash
渐进式 rehash
Redis中的这种重新哈希的操作因为不是一次性全部rehash,而是分多次来慢慢的将ht[0]中的键值对rehash到ht[1],故而这种操作也称之为渐进式rehash。渐进式rehash可以避免集中式rehash带来的庞大计算量,是一种分而治之的思想。
在渐进式rehash过程中,因为还可能会有新的键值对存进来,此时Redis的做法是新添加的键值对统一放入ht[1]中,这样就确保了ht[0]键值对的数量只会减少。
当正在执行rehash操作时,如果服务器收到来自客户端的命令请求操作,则会先查询ht[0],查找不到结果再到ht[1]中查询
List
概述
list 是一个有序的字符串列表,它按照插入顺序排序,并且支持在两端插入或删除元素。一个 list 类型的键最多可以存储 2^32 - 1 个元素。
redis3.2以后,list 类型的底层实现只有一种结构,就是quicklist。版本不同时,底层实现是不同的,下面会讲解。
应用场景
list 类型的应用场景主要是实现队列和栈,比如:
-
消息队列,利用 lpush 和 rpop 命令实现生产者消费者模式。
-
最新消息,利用 lpush 和 ltrim 命令实现固定长度的时间线。
-
历史记录,利用 lpush 和 lrange 命令实现浏览记录或者搜索记录。
底层原理
在讲解list结构之前,需要先说明一下list结构编码的更替,如下
-
在
Redis3.2之前,list使用的是linkedlist和ziplist -
在
Redis3.2~Redis7.0之间,list使用的是quickList,是linkedlist和ziplist的结合 -
在
Redis7.0之后,list使用的也是quickList,只不过将ziplist转为listpack,它是listpack、linkedlist结合版
linkedlist与ziplist
在Redis3.2之前,linkedlist和ziplist两种编码可以选择切换,它们之间的转换关系如图
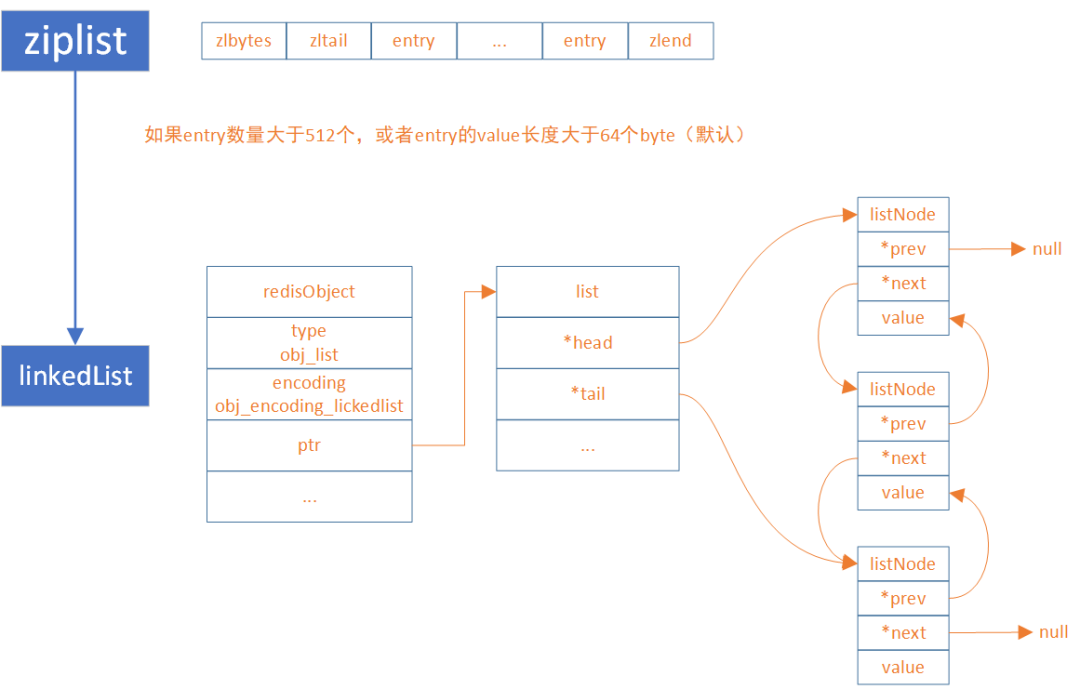
同样地,ziplist转为linkedlist的条件可在redis.conf配置
list-max-ziplist-entries 512
list-max-ziplist-value 64
quickList(ziplist、linkedlist结合版)
quicklist存储了一个双向列表,每个列表的节点是一个ziplist,所以实际上quicklist并不是一个新的数据结构,它就是linkedlist和ziplist的结合,然后被命名为快速列表。
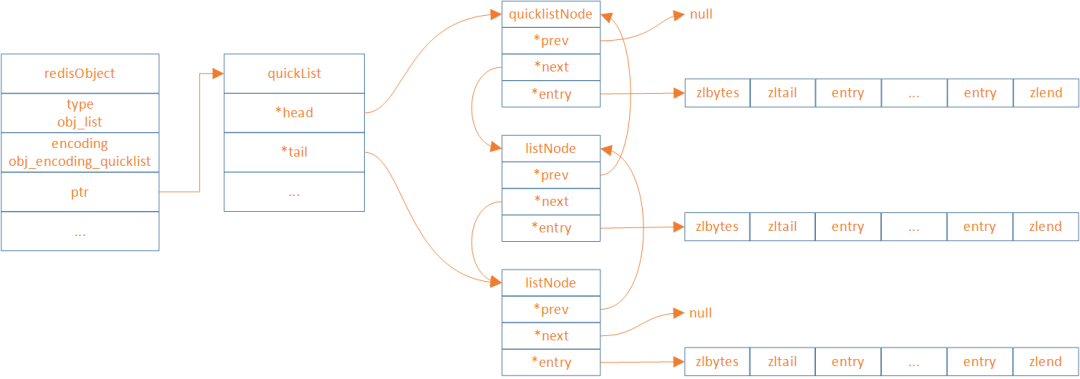
ziplist内部entry个数可在redis.conf配置
list-max-ziplist-size -2
# -5: 每个ziplist最多为 64 kb <-- 影响正常负载,不推荐
# -4: 每个ziplist最多为 32 Kb <-- 不推荐
# -3: 每个ziplist最多为 16 Kb <-- 最好不要使用
# -2: 每个ziplist最多为 8 Kb <-- 好
# -1: 每个ziplist最多为 4 Kb <-- 好
# 正数为ziplist内部entry个数ziplist通过特定的LZF压缩算法来将节点进行压缩存储,从而更进一步的节省空间,而很多场景都是两端元素访问率最高,我们可以通过配置list-compress-depth来排除首尾两端不压缩的entry个数。
list-compress-depth 0
# - 0:不压缩(默认值)
# - 1:首尾第 1 个元素不压缩
# - 2:首位前 2 个元素不压缩
# - 3:首尾前 3 个元素不压缩
# - 以此类推
quickList(listpack、linkedlist结合版)
和Hash结构一样,因为ziplist有连锁更新问题,redis7.0将ziplist替换为listpack,下面是新quickList的结构图
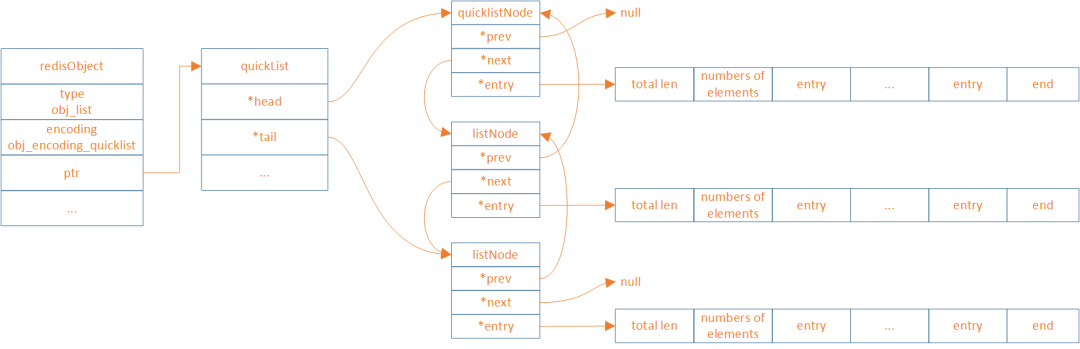
Redis中listpack源码
typedef struct quicklist {quicklistNode *head;quicklistNode *tail;unsigned long count; /* 所有列表包中所有条目的总数,占用16 bits,最大65536 */unsigned long len; /* quicklistNode 的数量 */signed int fill : QL_FILL_BITS; /* 单个节点的填充因子 */unsigned int compress : QL_COMP_BITS; /* 不压缩的端节点深度;0=off */unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *entry;size_t sz; /* 当前entry占用字节 */unsigned int count : 16; /* listpack元素个数,最大65535 */unsigned int encoding : 2; /* RAW==1 or LZF==2 */unsigned int container : 2; /* PLAIN==1 or PACKED==2 */unsigned int recompress : 1; /* 当前listpack是否需要再次压缩 */unsigned int attempted_compress : 1; /* 测试用 */unsigned int extra : 10; /* 备用 */
} quicklistNode;
listpack内部entry个数可在redis.conf配置
List-Max-listpack-size -2
# -5: 每个listpack最多为 64 kb <-- 影响正常负载,不推荐
# -4: 每个listpack最多为 32 Kb <-- 不推荐
# -3: 每个listpack最多为 16 Kb <-- 最好不要使用
# -2: 每个listpack最多为 8 Kb <-- 好
# -1: 每个listpack最多为 4 Kb <-- 好
# 正数为listpack内部entry个数
Set
概述
set 是一个无序的字符串集合,它不允许重复的元素。一个 set 类型的键最多可以存储 2^32 - 1 个元素。
set 类型的底层实现有两种:
-
intset,整数集合 -
hashtable(哈希表)。哈希表和 hash 类型的哈希表相同,它将元素存储在一个数组中,并通过哈希函数计算元素在数组中的索引
Redis 会根据 set 中元素的数量和类型来选择合适的编码方式,当 set 达到一定的阈值时,会自动转换编码方式。
typedef struct intset {uint32_t encoding;uint32_t length;int8_t contents[];
} intset;应用场景
set 类型的应用场景主要是利用集合的特性,比如:
-
去重,利用 sadd 和 scard 命令实现元素的添加和计数。
-
交集,并集,差集,利用 sinter,sunion 和 sdiff 命令实现集合间的运算。
-
随机抽取,利用 srandmember 命令实现随机抽奖或者抽样。
底层原理
在讲解set结构之前,需要先说明一下set结构编码的更替,如下
-
在
Redis7.2之前,set使用的是intset和hashtable -
在
Redis7.2之后,set使用的是intset、listpack、hashtable
intset
intset是一种紧凑的数组结构,它只保存int类型的数据,它将所有的元素按照从小到大的顺序存储在一块连续的内存中。intset会根据传入的数据大小,encoding分为int16_t、int32_t、int64_t
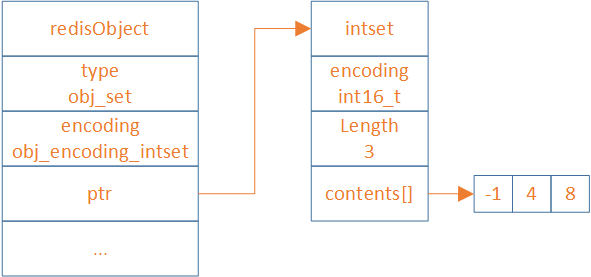
127.0.0.1:6379> sadd set 123
(integer) 1
127.0.0.1:6379> object encoding set
"intset"
127.0.0.1:6379> sadd set abcd
(integer) 1
127.0.0.1:6379> object encoding set
"hashtable"
intset 和 hashtable 的转换
在Redis7.2之前,当一个集合满足以下两个条件时,Redis 会选择使用intset编码:
-
集合对象保存的所有元素都是整数值
-
集合对象保存的元素数量小于等于
512个(默认)
intset最大元素数量可在redis.conf配置
set-max-intset-entries 512
为什么加入了listpack
在redis7.2之前,sds类型的数据会直接放入到编码结构式为hashtable的set中。其中,sds其实就是redis中的string类型。
而在redis7.2之后,sds类型的数据,首先会使用listpack结构当 set 达到一定的阈值时,才会自动转换为hashtable。
添加listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比较高。
hashtable 的空间开销高
hashtable 的空间开销高是因为它需要预先分配一个固定大小的数组来存储键值对,而这个数组的大小通常要大于实际存储的元素个数,以保证较低的装载因子。装载因子是指 hashtable 中已经存储的元素个数和数组大小的比值,它反映了 hashtable 的空间利用率
-
如果装载因子过高,那么 hashtable 的性能会下降,因为碰撞的概率会增加
-
如果装载因子过低,那么 hashtable 的空间利用率会下降,因为数组中会有很多空闲的位置
因此,hashtable 需要在装载因子和空间利用率之间做一个平衡,通常装载因子的推荐值是 0.75
hashtable 的碰撞概率高
hashtable 的碰撞概率高是因为它使用了一个散列函数来将任意长度的键映射到一个有限范围内的整数,作为数组的索引
散列函数的设计很重要,它应该尽可能地保证不同的键能够均匀地分布在数组中,避免出现某些位置过于拥挤,而其他位置过于稀疏的情况。然而,由于散列函数的输出范围是有限的,而键的取值范围是无限的,所以不可能完全避免两个不同的键被散列到同一个位置上,这就产生了碰撞。碰撞会影响 hashtable 的性能,因为它需要额外的处理方式来解决冲突,比如开放寻址法或者链地址法
举例说明,假设有一个大小为8的hashtable,使用取模运算作为散列函数,即h(k) = k mod 8。现在有四个键:5,13,21,29,它们都被散列到索引1处
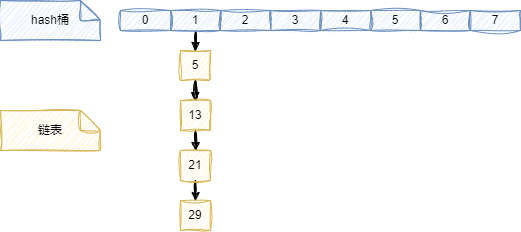
这就是一个碰撞的例子,因为四个键都映射到了同一个索引。这种情况可能是由于以下原因造成的:
-
散列函数的选择不合适,没有充分利用hashtable的空间。
-
键的分布不均匀,有些区间的键出现的频率更高。
-
hashtable的大小太小,不能容纳所有的键。
为了解决碰撞,redis采用了链地址法。就是在每个索引处维护一个链表,存储所有散列到该索引的键。但是,如果链表过长,查找效率会降低。因此,一般建议保持hashtable的负载因子(即键的数量除以hashtable的大小)在一定范围内,比如0.5到0.75之间。如果负载因子过高或过低,可以通过扩容或缩容来调整hashtable的大小
intset 、listpack和hashtable的转换
intset 、listpack和hashtable这三者的转换时根据要添加的数据、当前set的编码和阈值决定的。
-
如果要添加的数据是整型,且当前
set的编码为intset,如果超过阈值由intset直接转为hashtable阈值条件为:
set-max-intset-entries,intset最大元素个数,默认512 -
如果要添加的数据是字符串,分为三种情况
阈值条件为:
set-max-listpack-entries:最大元素个数,默认128set_max_listpack_value:最大元素大小,默认64
以上两个条件需要同时满足才能进行编码转换-
当前
set的编码为intset:如果没有超过阈值,转换为listpack;否则,直接转换为hashtable -
当前
set的编码为listpack:如果超过阈值,就转换为hashtable -
当前
set的编码为hashtable:直接插入,编码不会进行转换
-
ZSet
概述
Redis 中的 zset 是一种有序集合类型,它可以存储不重复的字符串元素,并且给每个元素赋予一个排序权重值(score)。Redis 通过权重值来为集合中的元素进行从小到大的排序。zset 的成员是唯一的,但权重值可以重复。一个 zset 类型的键最多可以存储 2^32 - 1 个元素。
Redis中zset源码
typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
应用场景
zset 类型的应用场景主要是利用分数和排序的特性,比如:
-
排行榜,利用 zadd 和 zrange 命令实现分数的更新和排名的查询
-
延时队列,利用 zadd 和 zpopmin 命令实现任务的添加和执行,并且可以定期地获取已经到期的任务
-
访问统计,可以使用 zset 来存储网站或者文章的访问次数,并且可以按照访问量进行排序和筛选。
底层原理
Redis在存储zset结构的数据,为了达到内存和性能的平衡,针对少量存储和大量存储分别设计了两种结构,分别为:
-
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用) -
skiplist
当 zset 中的元素个数和元素值的长度比较小的时候,Redis 使用ziplist/listpack来节省内存空间。当 zset 中的元素个数和元素值的长度达到一定阈值时,Redis 会自动将ziplist/listpack转换为skiplist,以提高操作效率
具体来说,当 zset 同时满足以下两个条件时,会使用 listpack作为底层结构:
-
元素个数小于
zset_max_listpack_entries,默认值为 128 -
元素值的长度小于
zset_max_listpack_value,默认值为 64
当 zset 中不满足以上两个条件时,会使用 skiplist 作为底层结构。
skiplist
跳跃表是一种随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳跃表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳跃表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
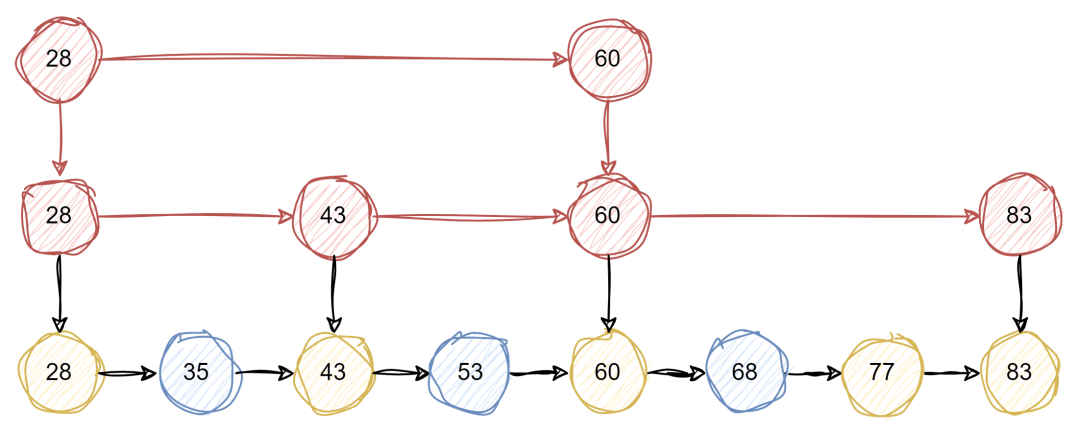
跳跃表相比于其他平衡树结构,有以下几个优点和缺点:
优点:
-
实现简单,易于理解和调试
-
插入和删除操作只需要修改局部节点的指针,不需要像平衡树那样进行全局调整
-
可以利用空间换时间,通过增加索引层来提高查找效率
-
支持快速的范围查询,可以方便地返回指定区间内的所有元素
缺点:
-
空间复杂度较高,需要额外存储多级索引
-
随机性太强,性能不稳定,最坏情况下可能退化成链表
-
不支持快速的倒序遍历,需要额外的指针来实现
redis的skiplist
skiplist有一个层数上的问题,当层数过多,会影响查询效率。而Redis 使用了一个随机函数来决定每个节点的层数,这个随机函数的期望值是 1/(1-p) ,其中 p 是一个概率常数,Redis 中默认为 0.25。这样可以保证跳跃表的平均高度为 log (1/p) n ,其中 n 是节点数。Redis 还限制了跳跃表的最大层数为 32 ,这样可以避免过高的索引层造成空间浪费
Stream
概述
stream 是一个类似于日志的数据结构,它可以记录一系列的键值对,每个键值对都有一个唯一的 ID。一个 stream 类型的键最多可以存储 2^64 - 1 个键值对。
stream 类型的底层实现是 rax(基数树),它是一种压缩的前缀树结构,它将所有的键值对按照 ID 的字典序存储在一个树形结构中。rax 可以快速地定位、插入、删除任意位置的键值对
应用场景
stream 类型的应用场景主要是实现事件驱动的架构,比如:
-
消息队列,利用 xadd 和 xread 命令实现生产者消费者模式。
-
操作日志,利用 xadd 和 xrange 命令实现操作记录和回放。
-
数据同步,利用 xadd 和 xreadgroup 命令实现多个消费者组之间的数据同步。
底层原理
Rax Tree
rax tree是一种基于基数树(radix tree)的变体,也叫做压缩前缀树(compressed prefix tree),它被应用于redis stream中,用来存储streamID,其数据结构为
typedef struct raxNode {uint32_t iskey:1; /* Does this node contain a key? */uint32_t isnull:1; /* Associated value is NULL (don't store it). */uint32_t iscompr:1; /* 前缀是否压缩 */uint32_t size:29; /* Number of children, or compressed string len. */unsigned char data[];
} raxNode;
-
iskey:是否包含key -
isnull:是否存储value值 -
iscompr:前缀是否压缩。决定了size存储的是什么和data的数据结构 -
size:-
iscompr=0:节点为非压缩节点,size是孩子节点的数量 -
iscompr=1:节点为压缩节点,size是已压缩的字符串长度
-
-
data:-
iscompr=0:节点为非压缩节点,数据格式为[header strlen=0][abc][a-ptr][b-ptr][c-ptr](value-ptr?)。其有size个字符, -
iscompr=1:节点为压缩节点,数据格式为[header strlen=3][xyz][z-ptr](value-ptr?)。
-
为了便于理解,设定一些场景举例说明
场景一:只插入foot
数据结构为:
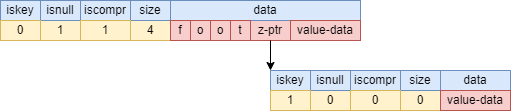
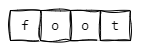
其中,z-ptr指向的叶子节点的iskey=1,标识foot这个key。下图为使用树状图的形式来展现其数据结构
场景二:插入foot后,插入footer
数据结构为:

其插入过程为:
-
与foot节点中每个字符进行比较,获得最大公共前缀
foot -
将er作为foot的子节点,其
iskey=1,标识foot这个key -
将er的子节点的
iskey=1,标识footer这个key
下图为使用树状图的形式来展现其数据结构
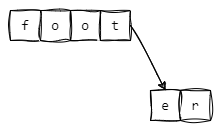
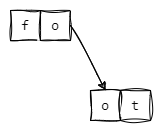
场景三:插入foot后,插入fo
数据结构为:
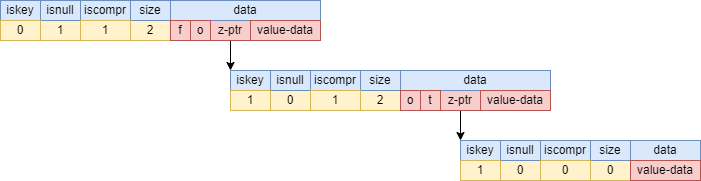
其插入过程为:
-
与foot节点中每个字符进行比较,获得最大公共前缀
fo -
将foot拆成fo和ot
-
将ot作为fo的子节点,其
iskey=1,标识fo这个key -
设置ot的子节点的
iskey=1,标识foot这个key
下图为使用树状图的形式来展现其数据结构
场景四:插入foot后,插入foobar
数据结构为:
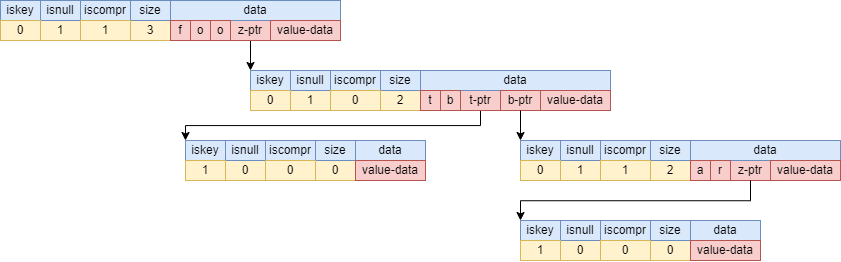
其插入过程为:
-
与foot节点中每个字符进行比较,获得最大公共前缀
foo -
将foot拆成foo和t
-
将footbar拆成foo、b、ar
-
将t、b作为foo的子节点
-
设置ot的子节点的
iskey=1,标识foot这个key -
将ar作为b的子节点
-
设置ar的子节点的
iskey=1,标识footbar这个key
下图为使用树状图的形式来展现其数据结构
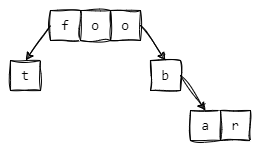
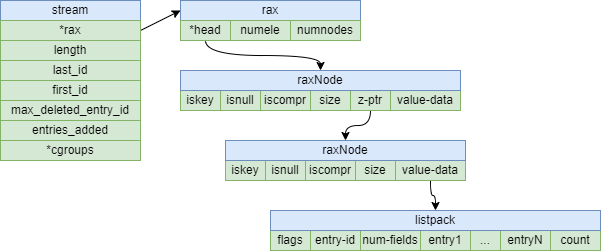
Stream
stream的底层使用了rax tree和listpack两种结构,rax tree用来存储streamID,而listpack用来存储对应的值,结构图如下:
Hyperloglog
概述
HyperLogLog 是一种概率数据结构,用于在恒定的内存大小下估计集合的基数(不同元素的个数)。它不是一个独立的数据类型,而是一种特殊的 string 类型,它可以使用极小的空间来统计一个集合中不同元素的数量,也就是基数。一个 hyperloglog 类型的键最多可以存储 12 KB 的数据
hyperloglog 类型的底层实现是 SDS(simple dynamic string),它和 string 类型相同,只是在操作时会使用一种概率算法来计算基数。hyperloglog 的误差率为 0.81%,也就是说如果真实基数为 1000,那么 hyperloglog 计算出来的基数可能在 981 到 1019 之间
应用场景
hyperloglog 类型的应用场景主要是利用空间换时间和精度,比如:
-
统计网站的独立访客数(UV)
-
统计在线游戏的活跃用户数(DAU)
-
统计电商平台的商品浏览量
-
统计社交网络的用户关注数
-
统计日志分析中的不同事件数
假如需要统计某商品的用户关注数,可以通过以下方式:
> PFADD goodA "1"
1
> PFADD goodA "2"
1
> PFADD goodA "3"
1
> PFCOUNT goodA
3GEO
概述
geospatial 是一种用于存储和查询地理空间位置的数据类型,它基于 sorted set 数据结构实现,利用 geohash 算法将经纬度编码为二进制字符串,并作为 sorted set 的 score 值。Redis geospatial 提供了一系列的命令来添加、删除、搜索和计算地理空间位置,例如:
-
GEOADD key longitude latitude member [longitude latitude member …]:将一个或多个地理空间位置(经度、纬度、名称)添加到指定的 key 中 -
GEOPOS key member [member …]:返回一个或多个地理空间位置的经纬度 -
GEODIST key member1 member2 [unit]:返回两个地理空间位置之间的距离,可以指定单位(m, km, mi, ft) -
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:返回指定圆心和半径内的地理空间位置,可以指定返回坐标、距离、哈希值、数量、排序方式等,也可以将结果存储到另一个 key 中 -
GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]: 返回以指定成员为圆心的指定半径内的地理空间位置,其他参数同GEORADIUS
应用场景
geospatial 的应用是地理位置搜索、分析和展示,例如地图应用、导航应用、位置服务应用等。例如,可以使用 geospatial 来实现以下功能:
-
统计某个区域内的商家或用户数量
-
查询某个位置附近的餐馆或酒店
-
计算两个位置之间的距离或行驶时间
-
显示某个位置周围的景点或活动
Bitmap
概述
bitmap 不是一个独立的数据类型,而是一种特殊的 string 类型,它可以将一个 string 类型的值看作是一个由二进制位组成的数组,并提供了一系列操作二进制位的命令。一个 bitmap 类型的键最多可以存储 2^32 - 1 个二进制位。
bitmap 类型的底层实现是 SDS(simple dynamic string),它和 string 类型相同,只是在操作时会将每个字节拆分成 8 个二进制位。
应用场景
bitmap 类型的应用场景主要是利用二进制位的特性,比如:
-
统计用户活跃度,利用 setbit 和 bitcount 命令实现每天或每月用户登录次数的统计。
-
实现布隆过滤器,利用 setbit 和 getbit 命令实现快速判断一个元素是否存在于一个集合中。
-
实现位图索引,利用 bitop 和 bitpos 命令实现对多个条件进行位运算和定位
假如需要统计每个用户的当天登录次数统计。
首先,需要规定bitmap的格式,假设为{userid}:{年份}:{第几天} {秒数} {是否登录}
将
userid为100的用户,记录他在2024年第100天中第1秒,是否登录
SETBIT 1000:2024:100 1 1
0将
userid为100的用户,记录他在2024年第100天中第10240 秒,是否登录
SETBIT 1000:2024:100 10240 1
0
将
userid为100的用户,记录他在2024年第100天中第86400 秒,是否登录
SETBIT 1000:2024:100 86400 1
0
统计
userid为100的用户,在2024年第100天的登录次数
BITCOUNT 1000:2024:100
3
Bitfield
概述
bitfield结构是基于字符串类型的一种扩展,可以让你对一个字符串中的任意位进行设置,增加和获取操作,就像一个位数组一样
可以操作任意位长度的整数,从无符号的1位整数到有符号的63位整数。这些值是使用二进制编码的Redis字符串来存储的
bitfield结构支持原子的读,写和增加操作,使它们成为管理计数器和类似数值的好选择
使用场景
Bitfield的使用场景与bitmap 类似,主要是一些需要用不同位长度的整数来表示状态或属性的场合,例如:
-
用一个32位的无符号整数来表示用户的金币数量,用一个32位的无符号整数来表示用户杀死的怪物数量,可以方便地对这些数值进行设置,增加和获取
-
用一个16位的有符号整数来表示用户的等级,用一个16位的有符号整数来表示用户的经验值,可以方便地对这些数值进行设置,增加和获取
-
用一个8位的无符号整数来表示用户的性别,用一个8位的无符号整数来表示用户的年龄,可以方便地对这些数值进行设置,增加和获取
bitfield和bitmap都是基于string类型的位操作,但是有一些区别:
-
bitmap只能操作1位的无符号整数,而bitfield可以操作任意位长度的有符号或无符号整数 -
bitmap只能设置或获取指定偏移量上的位,而bitfield可以对指定偏移量上的位进行增加或减少操作 -
bitmap可以对多个字符串进行位运算,而bitfield只能对单个字符串进行位操作 -
bitmap的偏移量是从0开始的,而bitfield的偏移量是从最高有效位开始的
例如,使用bitfield存储用户的个人信息,
-
用一个8位的无符号整数来表示用户的性别,0表示男,1表示女
-
用一个8位的无符号整数来表示用户的年龄,范围是0-255
-
用一个16位的无符号整数来表示用户的身高,单位是厘米,范围是0-65535
-
用一个16位的无符号整数来表示用户的体重,单位是克,范围是0-65535
假设有一个用户,性别是女,年龄是25,身高是165厘米,体重是50千克,可以用以下命令来存储和获取这些信息:
> BITFIELD user:1:info SET u8 #0 1 SET u8 #1 25 SET u16 #2 165 SET u16 #3 50000
0
0
0
0
然后,获取这个用户的信息,性别、年龄、身高、体重
> BITFIELD user:1:info GET u8 #0 GET u8 #1 GET u16 #2 GET u16 #3
1
25
165
50000![[Java优选系列第2弹]SpringMVC入门教程:从零开始搭建一个Web应用程序](https://img-blog.csdnimg.cn/5cb1ae10caa44fd4bccb1e3e7237861c.webp)



![[bug] 记录version `GLIBCXX_3.4.29‘ not found 解决方法](https://img-blog.csdnimg.cn/340321d324154ed5a7991073959c0df8.png)