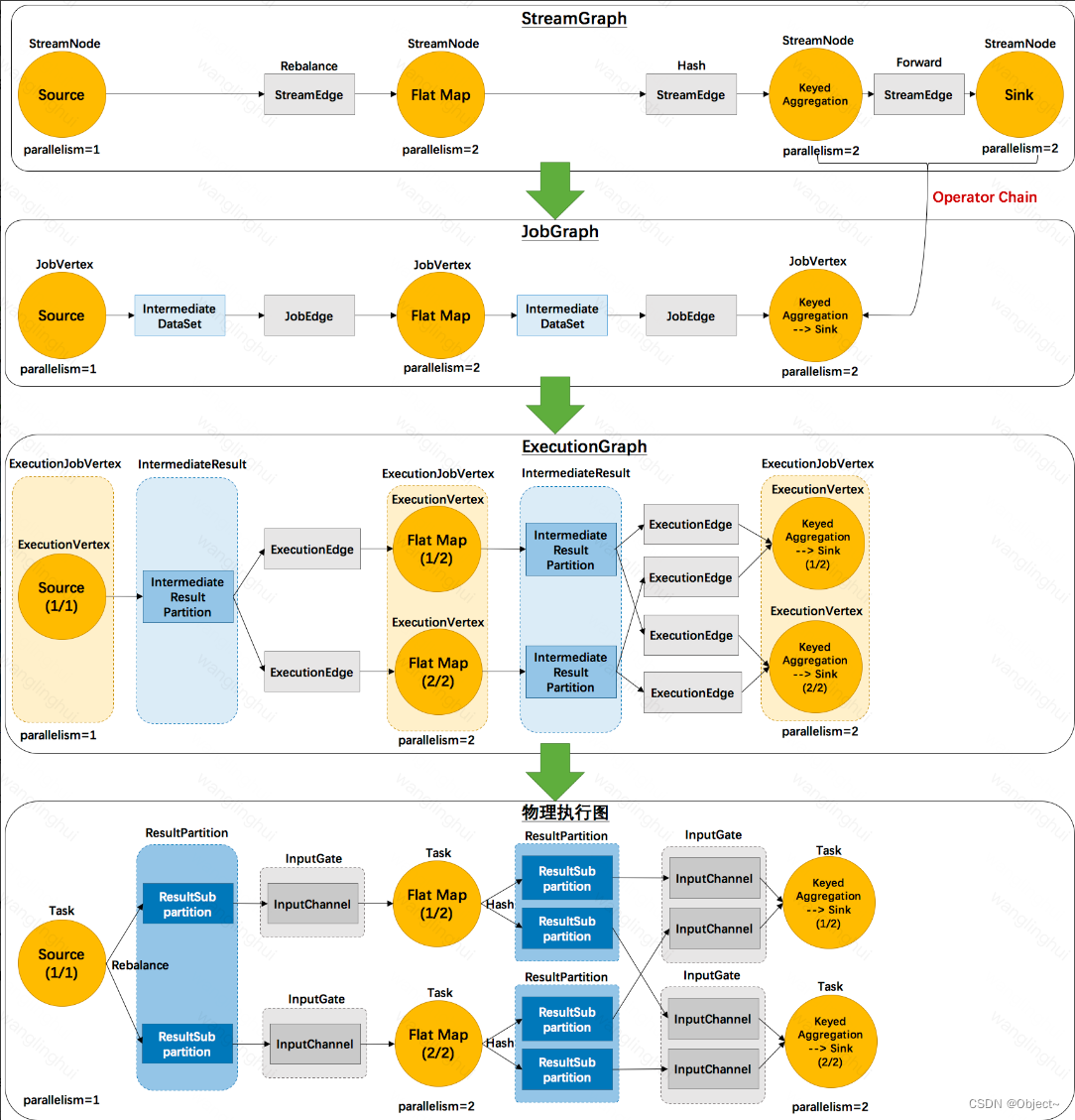
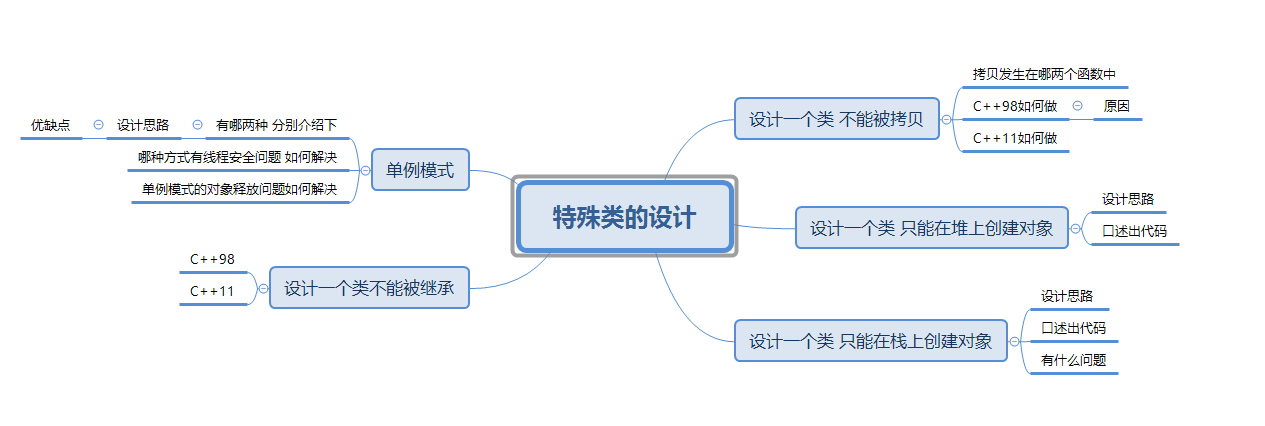
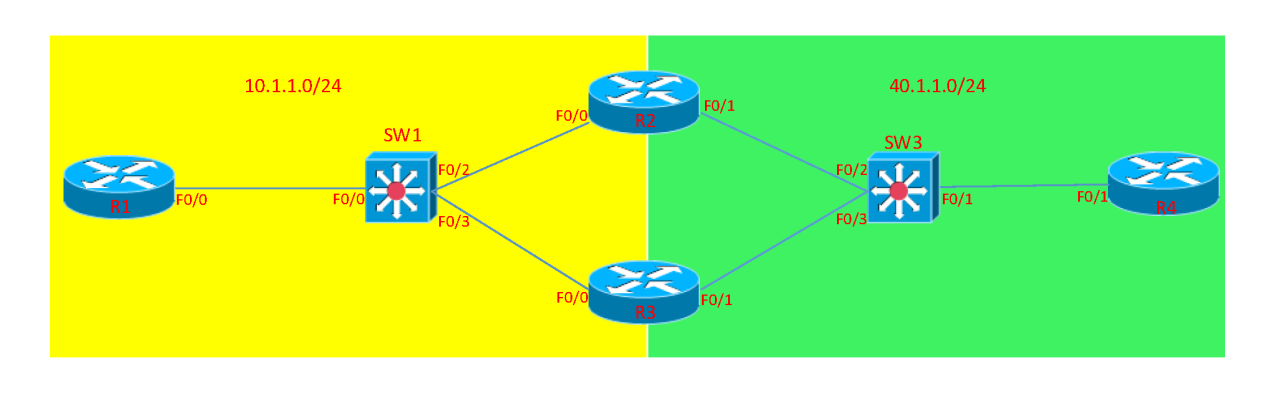
x.view()就是对tensor进行reshape:
我们在创建一个网络的时候,会在Foward函数内看到view的使用。
首先这里是一个简单的网络,有卷积和全连接组成。它的foward函数如下:
class NET(nn.Module):def __init__(self,batch_size):super(NET,self).__init__()self.conv = nn.Conv2d(outchannels=3,in_channels=64,kernel_size=3,stride=1)self.fc = nn.Linear(64*batch_size,10)def forward(self,x):x = self.conv(x)x = x.view(x.size(0), -1) out = self.fc(x)在CNN中卷积或者池化之后需要连接全连接层,所以需要把多维度的tensor展平成一维,x.view(x.size(0), -1)就实现的这个功能。
卷积或者池化之后的tensor的维度为(batchsize,channels,x,y),其中x.size(0)指batchsize的值,x = x.view(x.size(0), -1)简化x = x.view(batchsize, -1)。( 通过x.view(x.size(0), -1)将tensor的结构转换为了(batchsize, channelsxy),即将(channels,x,y)拉直,然后就可以和fc层连接了。)
示例:
x变量的本质就是一个4维向量,而在conv1层的输入的x为一个10 ∗ * ∗ 3 ∗ * ∗ 100 ∗ * ∗ 100的向量,参数分别表示batchsize,RGB,100 ∗ * ∗ 100图片大小,x经过一层层的卷积,最后10 ∗ * ∗ 256 ∗ * ∗ 4 ∗ * ∗ 4向量作为第四层卷积输出。
最后使用x.view(x.shape(0),-1)将x转化成一个10行的矩阵,矩阵的每一行就是这个批量(批量大小为10)中每张图片的各个参数(即256 ∗ * ∗ 4 ∗ * ∗ 4),即矩阵中一行对应一张图片。
view()函数的功能根reshape类似,用来转换size大小。
x = x.view(batchsize, -1)中batchsize指转换后有几行,而-1指在不告诉函数有多少列的情况下,根据原tensor数据和batchsize自动分配列数。

x.view(a,b)解析
引用自:Python函数.view(1,-1)和 .view(-1,1)有什么区别
引用自:pytorch中的X.view[-1],X.view[-1,参数],X.view[参数,-1]
x.view[-1,参数a]以及x.view[参数a,-1]语句的作用就是根据参数来调整维度
- x.view[参数,-1]:就是根据参数来自动调整列数
- x.view[-1,参数]:就是根据参数来自动调整行数
- x.view[-1]:-1本意是根据另外一个数来自动调整维度,但因为行数,列数参数都未知,最后就将所有维度数据调整为一维tensor。
x.view(1, -1):这种形式的 .view() 操作将张量重新塑造为一个行数为 1,列数自动推断的二维张量。在推断列数时,会根据张量的总元素数量和行数来确定。如果张量原来的形状是 (a, b, c),则 .view(1, -1) 将其转换为 (1, a * b * c) 的形状。这种操作通常用于在保持张量元素总数不变的情况下,将多维张量展平为一维张量或行向量。
x.view(-1, 1):这种形式的 .view() 操作将张量重新塑造为一个列数为 1,行数自动推断的二维张量。在推断行数时,会根据张量的总元素数量和列数来确定。如果张量原来的形状是 (a, b, c),则 .view(-1, 1) 将其转换为 (a * b * c, 1) 的形状。这种操作通常用于在保持张量元素总数不变的情况下,将多维张量展平为一维张量或列向量。
x.view(-1)中的-1本意是根据另外一个数来自动调整维度,但是这里只有一个维度,因此就会将x里面的所有维度数据转化成一维的,并且按先后顺序排列。
因此,.view(1, -1) 和 .view(-1, 1) 的区别在于最终张量的形状,前者得到一个行向量或一维张量,后者得到一个列向量或一维张量。