目录
- 版本介绍
- 背景介绍
- 优势说明
- 集成过程
- 1.引入依赖
- 2.添加配置文件
- 3.初始化
- 示例说明
- 代码
- 结果
- 总结提升
版本介绍
Spring boot的版本是: 2.3.12
ElasticSearch的版本是:7.6.2
背景介绍
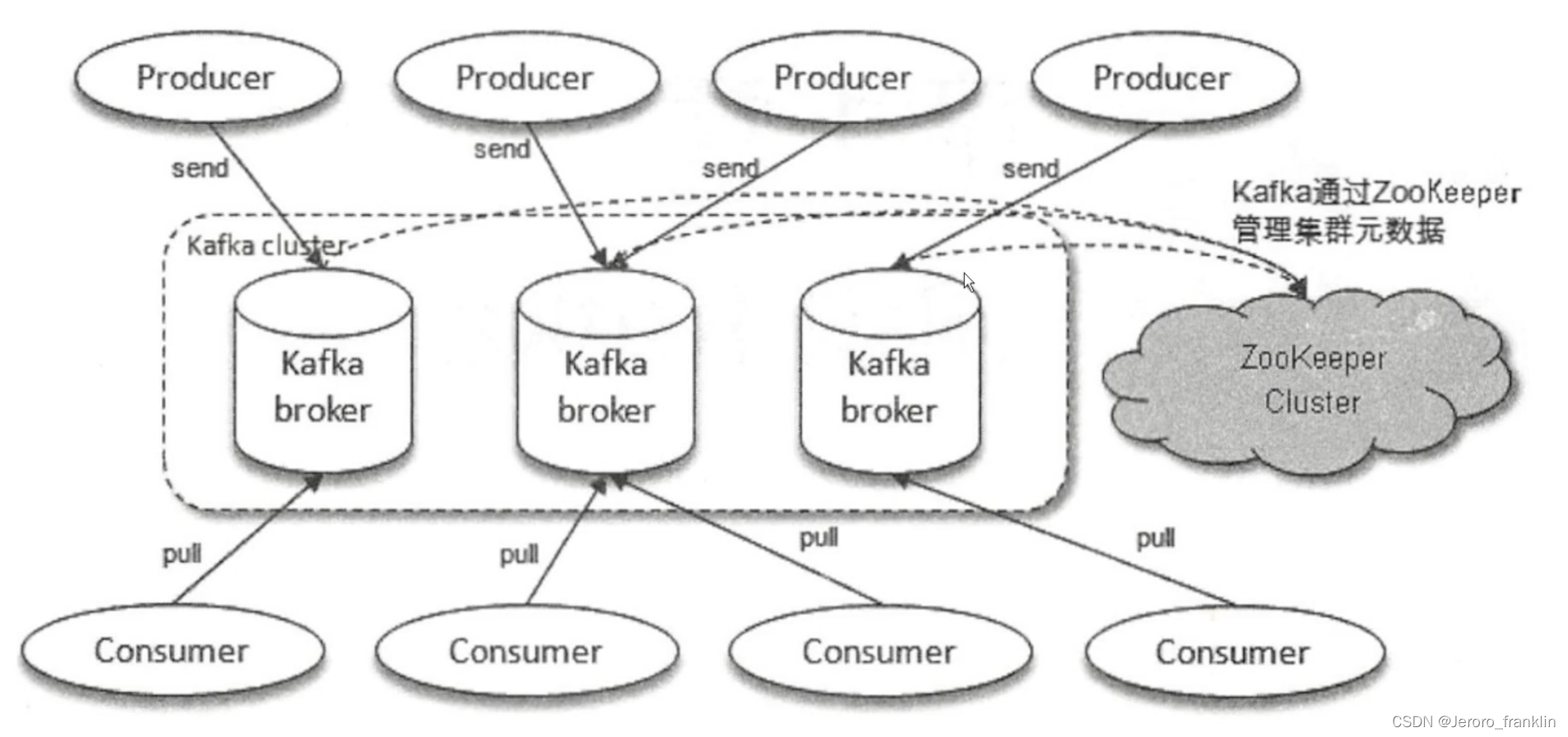
在我们的项目中经常会遇到对于字符串的一些操作,例如对于字符串的分词,通过一个词去查找对应的原文(全文搜索)。那可能有人就会问了,使用mysql的模糊查询也可以根据一个词去查找对应的原文呀?是的没有问题,Elasticsearch和 MySQL 是两种不同类型的数据库,各自有不同的特点和适用场景。MySQL 适用于关系型数据存储和复杂的关系查询,适合事务性操作和数据一致性要求较高的场景。Elasticsearch 适用于大规模数据的全文搜索和分析,适合实时性要求较高的场景。下面我们来说一说项目中是如何使用和集成Elasticsearch服务的。
优势说明
Elasticsearch(简称 ES)是一种开源的分布式搜索和分析引擎,具有以下几个主要的好处:
- 「 高性能和可扩展性 」:Elasticsearch 是分布式的,可以通过添加节点来扩展数据存储和查询能力。它使用倒排索引来加速搜索和聚合操作,具有快速的响应时间和高吞吐量。
- 「 全文搜索和复杂查询 」:Elasticsearch 支持全文搜索和复杂的查询功能,包括模糊搜索、多字段搜索、聚合查询、地理位置查询等。它使用自己的查询语言(DSL)来构建查询,并提供了强大的查询语法和过滤器。
- 「实时性和实时分析 」:Elasticsearch 支持实时索引和搜索,可以在数据写入后立即进行搜索和分析。它适用于实时监控、日志分析、实时搜索和实时报表等场景。
- 「多种数据类型支持」:Elasticsearch 支持多种数据类型的存储和查询,包括文本、数字、日期、地理位置等。它可以根据不同的数据类型进行索引和分析,并提供相应的查询和聚合功能。
- 「分布式架构和高可用性」:Elasticsearch 使用分布式架构,可以在多个节点上存储和处理数据,具有较好的水平扩展性和高可用性。它支持数据的自动分片和复制,可以在节点故障时自动恢复数据。
集成过程
1.引入依赖
<!--Elasticsearch服务--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version></dependency>
根据安装的Elasticsearch的版本来填写version标签中的内容
2.添加配置文件
elasticsearch:host: localhost 填写es服务的ip地址port: 9200 es服务的端口号client:type: http 请求es的类型:通过http或者内部的javaAPI通信username: xxxx 登录es的账号password: xxxx 登录es的密码
如果es服务没有设置账号和密码可以不进行账号密码配置的填写(为了安全建议添加上账号面密码)
3.初始化
一个RestHighLevelClient实例需要一个REST底层客户端构建器
@Value("${elasticsearch.host}")private String host;@Value("${elasticsearch.port}")private int port;@Value("${elasticsearch.client.type}")private String clientType;@Autowiredprivate RestHighLevelClient client;@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost(host, port, clientType)));return client;}
示例说明
代码
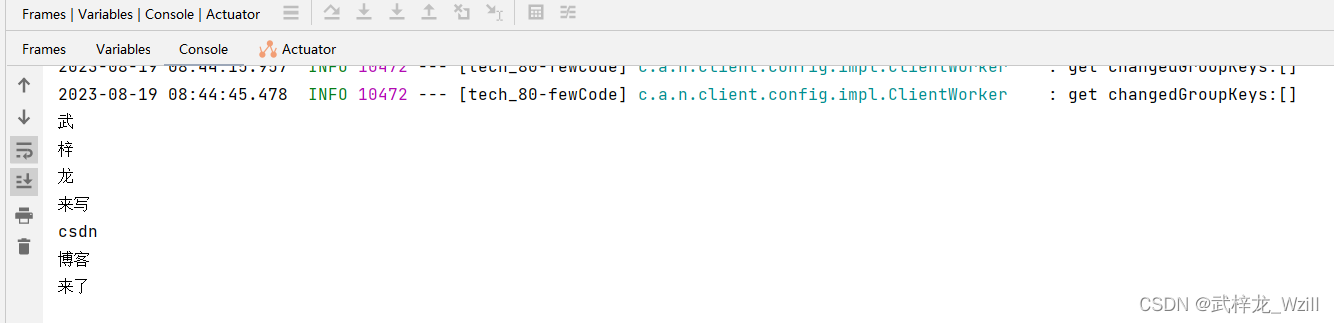
@Autowiredprivate RestHighLevelClient client;public void test() throws IOException {AnalyzeRequest analyzeRequest = AnalyzeRequest.withGlobalAnalyzer("ik_smart", "武梓龙来写CSDN博客来了");AnalyzeResponse analyze = client.indices().analyze(analyzeRequest, RequestOptions.DEFAULT);for (AnalyzeResponse.AnalyzeToken token : analyze.getTokens()) {System.out.println(token.getTerm());}}示例是将一段话进行分词操作,其中withGlobalAnalyzer方法的第一个参数是指定分词器ik_smart分词器(当然也可以使用其他分词器,根据业务的需求进行调整) 是es服务中安装了IK的插件实现的,如果不安装IK分词器的插件ik_smart分词器是无法使用的。第二个参数就是我们分词的内容了。
结果
总结提升
项目集成并使用ES服务可以提供强大的搜索和分析功能,帮助项目实现实时搜索、复杂查询和聚合分析等需求。ES具有分布式架构和高可用性,可以处理大规模数据并保证系统的可用性。同时,ES还拥有丰富的生态系统和工具支持,可以更好地集成和使用。因此,在项目中使用ES可以提升搜索和分析的效率和能力,满足项目的需求。