1.什么是状态
官方定义:当前计算流程需要依赖到之前计算的结果,那么之前计算的结果就是状态。
这句话还是挺好理解的,状态不只存在于Flink,也存在生活的方方面面,比如看到一个认识的人,如何识别认识呢?就是眼睛看到这个人的样子,再和大脑记忆中的人做对比,就知道认识这个人,其中大脑记忆中的人就是存储在状态中。
状态又分为无状态和有状态。
- 无状态:例如消费延迟计算,单条输入包含所有的信息,不依赖于历史消息。在这种模式的计算中,无论这条输入进来多少次,输出的结果都是一样的,因为单条输入中已经包含了所需的所有信息。消费落后等于生产者减去消费者。生产者的消费在单条数据中可以得到,消费者的数据也可以在单条数据中得到,所以相同输入可以得到相同输出,这就是一个无状态的计算。
- 有状态:例如访问量统计,单条输入仅包含部分信息,依赖历史消息。这种模式是将数据输入算子中,用来进行各种复杂的计算并输出数据。这个过程中算子会去访问之前存储在里面的状态。另外一方面,它还会把现在的数据对状态的影响实时更新,如果输入100 条数据,最后输出就是 100 条结果。
2.状态应用场景
通常以下4种场景会用到状态:
- 去重:比如上游的系统数据可能会有重复,落到下游系统时希望把重复的数据都去掉。去重需要先了解哪些数据来过,哪些数据还没有来,也就是把所有的主键都记录下来,当一条数据到来后,能够看到在主键当中是否存在。
- 窗口计算:比如统计每分钟 Nginx 日志 API 被访问了多少次。窗口是一分钟计算一次,在窗口触发前,如 08:00 ~ 08:01 这个窗口,前59秒的数据来了需要先放入内存,即需要把这个窗口之内的数据先保留下来,等到 8:01 时一分钟后,再将整个窗口内触发的数据输出。未触发的窗口数据也是一种状态。
- 机器学习/深度学习:如训练的模型以及当前模型的参数也是一种状态,机器学习可能每次都用有一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
- 访问历史数据:比如与昨天的数据进行对比,需要访问一些历史数据。如果每次从外部去读,对资源的消耗可能比较大,所以也希望把这些历史数据也放入状态中做对比。
3.状态管理
实时计算中的状态的功能主要体现在任务可以做到失败重启后没有数据质量、时效问题。
- 数据质量问题:当实时任务挂掉后,从消息失败offset位置开始消费,数据就错误。
- 数据时效问题:实时任务要求有时效性,当从源offset开始位置运行时,需要好几个小时才能追上当前offset。时效性就很差。
针对以上问题,就引出了状态管理。
当我们把数据定期(例如每隔10min)的给存储到 HDFS 上面时,任务挂了、恢复之后。我们的任务还可以从 HDFS 上面把这个数据给读回来,接着从最新的一个 Kafka Offset 继续计算就可以,这样既没没有数据质量问题,也没有数据时效性问题。
因此,实时计算中提到的状态的概念重点不止在于状态本身,更重要的在于强调 "管理" 状态。
基于上述,状态管理对流式作业的要求总结如下:
- 7*24小时运行,高可靠;
- 数据不丢不重,恰好计算一次;
- 数据实时产出,不延迟;
但是基于以上要求,内存的管理就会出现一些问题。由于内存的容量是有限制的。如果要做 24 小时的窗口计算,将 24 小时的数据都放到内存,可能会出现内存不足;另外,作业是 7*24,需要保障高可用,机器若出现故障或者宕机,需要考虑如何备份及从备份中去恢复,保证运行的作业不受影响;此外,考虑横向扩展,假如网站的访问量不高,统计每个 API 访问次数的程序可以用单线程去运行,但如果网站访问量突然增加,单节点无法处理全部访问数据,此时需要增加几个节点进行横向扩展,这时数据的状态如何平均分配到新增加的节点也问题之一。因此,将数据都放到内存中,并不是最合适的一种状态管理方式。
最理想的状态管理需要满足易用、高效、可靠三点需求:
- 易用,Flink 提供了丰富的数据结构、多样的状态组织形式以及简洁的扩展接口,让状态管理更加易用;
- 高效,实时作业一般需要更低的延迟,一旦出现故障,恢复速度也需要更快;当处理能力不够时,可以横向扩展,同时在处理备份时,不影响作业本身处理性能;
- 可靠,Flink 提供了状态持久化,包括不丢不重的语义以及具备自动的容错能力,比如 HA,当节点挂掉后会自动拉起,不需要人工介入。
4.状态后端
做状态数据(持久化,restore)的工具就叫做状态后端。比如在 Flink 中见到的 RocksDB、FileSystem 的概念就是指状态后端。这些状态后端就是实际存储上面的状态数据的。比如配置了 RocksDB 作为状态后端,MapState 的数据就会存储在 RocksDB 中。
总的来说可以这么理解:应用中有一份状态数据,把这份状态数据存储到 MySQL 中,这个 MySQL 就能叫做状态后端。
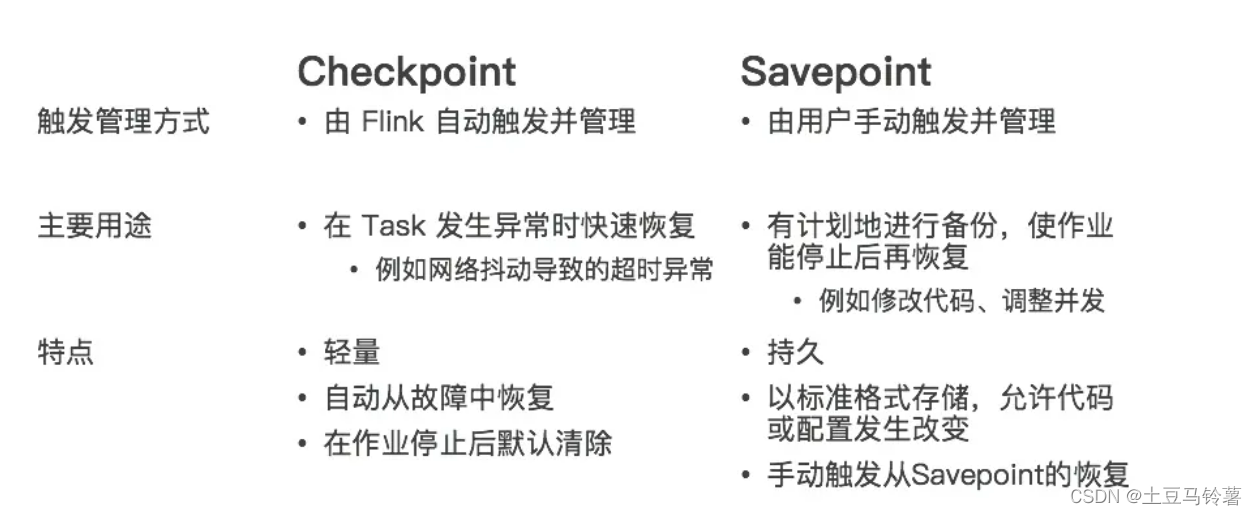
5.Checkpoint和Savepoint
概念:协调整个任务 when,how 去将 Flink 任务本地机器中存储在状态后端的状态去同步到远程文件存储系统(比如 HDFS)的过程就叫 Checkpoint、Savepoint。
Flink 状态保存主要依靠 Checkpoint 机制,Checkpoint 会定时制作分布式快照,对程序中的状态进行备份。分布式快照 Checkpoint 完成后,当作业发生故障了如何去恢复?假如作业分布跑在 3 台机器上,其中一台挂了。这个时候需要把进程或者线程移到 active 的 2 台机器上,此时还需要将整个作业的所有 Task 都回滚到最后一次成功 Checkpoint 中的状态,然后从该点开始继续处理。
Checkpoint流程如下:
- JM 定时调度 Checkpoint 的触发:JM CheckpointCoorinator 定时触发,CheckpointCoordinator 会去通过 RPC 接口调用 Source 算子的 TM 的 StreamTask 告诉 TM 可以开始执行 Checkpoint 了。
- Source 算子:接受到 JM 做 Checkpoint 的请求后,开始做本地 Checkpoint,本地执行完成之后,发 barrier 给下游算子。barrier 发送策略是随着 partition 策略走,将 barrier 发往连接到的所有下游算子(举例:keyby 就是广播,forward 就是直接送)。
- 剩余的算子:接收到上游所有 barrier 之后进行触发 Checkpoint。当一个算子接收到上游一个 channel 的 barrier 之后,就停止处理这个 input channel 来的数据(本质上就是不会再去影响状态了)
Savepoint 与 Checkpoint 类似,同样是把状态存储到外部介质。当作业失败时,可以从外部恢复。主要区别如下: