前言
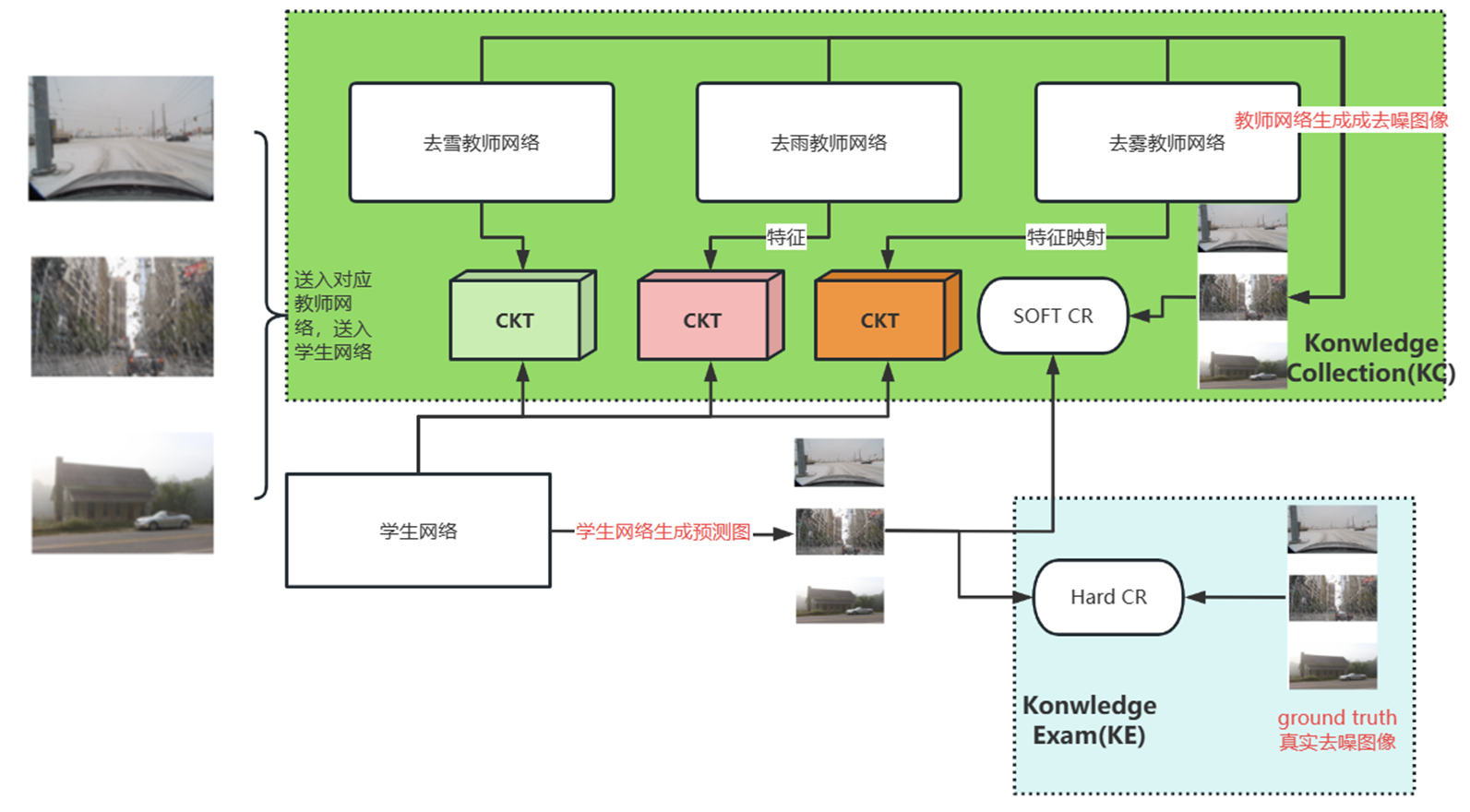
该项目的介绍可以参考博主这篇博文:基于知识蒸馏的去雪、去雾、去雨算法
调试过程
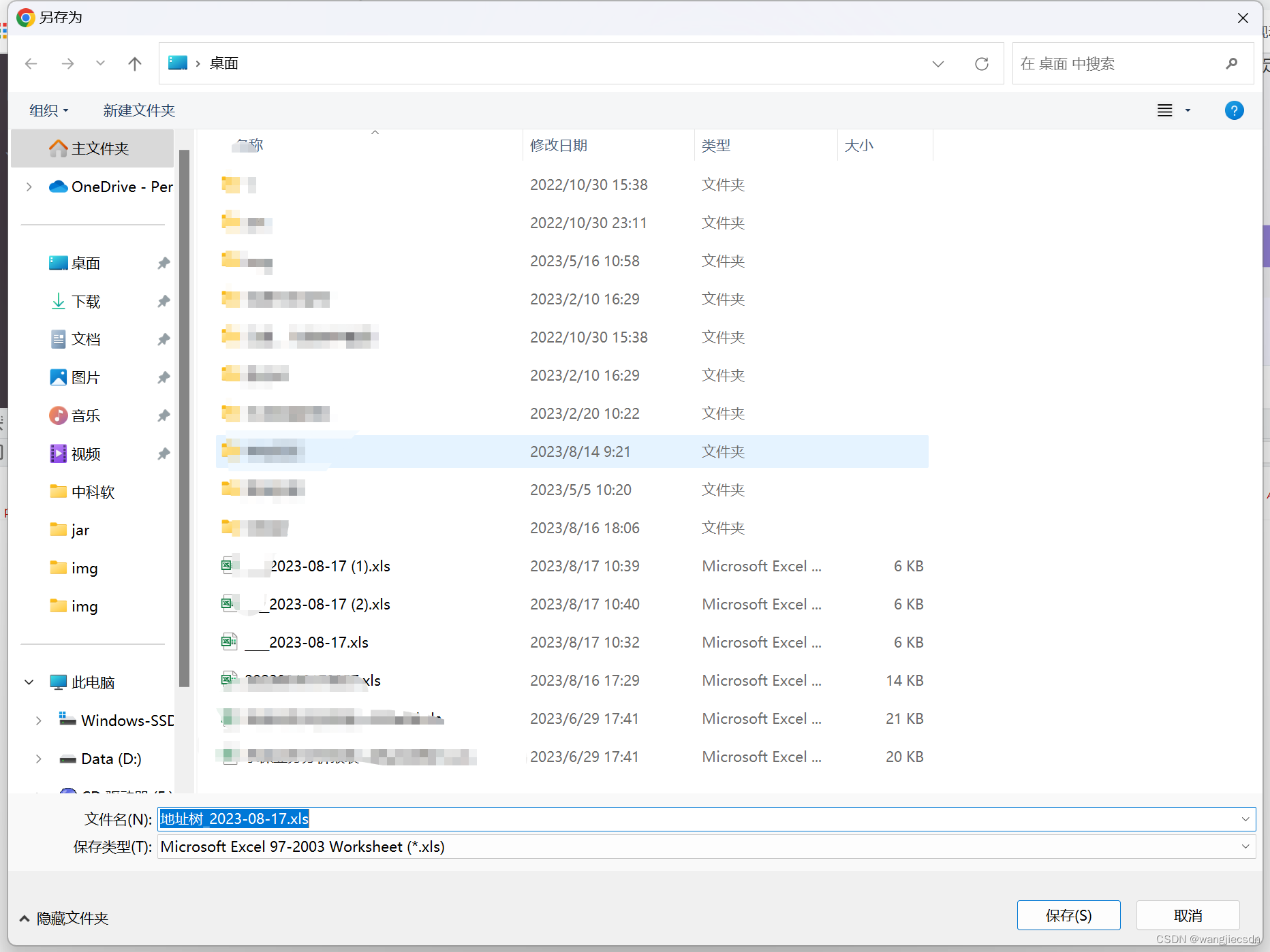
该项目中inference.py可以直接使用,只要将student的权重文件放入即可,博主实验过其去噪后的结果,貌似是变清晰了一点。但train时的meta里的json文件没有找到,作者指出meta文件是需要自己构建。
按照其要求,结构如下:
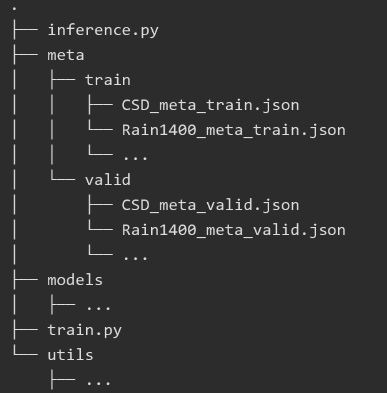
json文件结构如下:
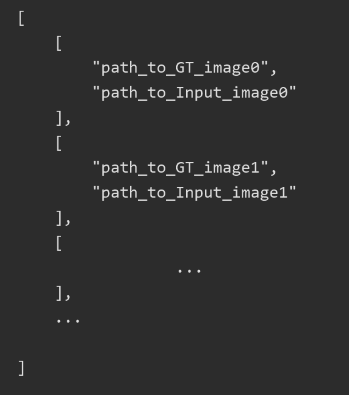
最终我们按照指定格式生成了对应的json地址文件
生成代码很简单,因为文件命名是有顺序的,所以不需要读取目录生成。
gt_path="D:/CSD/Test/Gt/"
input_path="D:/CSD/Test/Snow/"for i in range(1,20):path1=gt_path+str(i)+".tif"path2=input_path+str(i)+".tif"path='"'+path1+'",\n'+'"'+path2+'"'with open('test.json', 'a') as f:f.write("["+path+"],\n")
随后配置train.py的相关参数即可,值得注意的是,readme中给出的运行方式如下:
python train.py --teacher TEACHER_CHECKPOINT_PATH_0 TEACHER_CHECKPOINT_PATH_1 TEACHER_CHECKPOINT_PATH_2 --save-dir RESULTS_WILL_BE_SAVED_HERE
其中–teacher参数指的是已经训练好的教师网络的权重文件,但如果我们不使用命令运行,而是想直接运行python文件的话却会报错,经过定位可知,这是由于权重文件读取失败导致的,只需要修改一下参数,将权重文件之间加一个逗号。
parser.add_argument('--teachers', default="weights/CSD-teacher.pth,weights/Rain1400-teacher,weights/ITS-OTS-teacher",type=str, nargs='+')
随后在读取权重文件之前加上如下代码就OK了。
teachers=args.teachers.split(",")
完整代码如下:
teachers=args.teachers.split(",")
for checkpoint_path in teachers:checkpoint = torch.load(checkpoint_path)teacher = net_func().cuda()teacher.load_state_dict(checkpoint['state_dict'], strict=True)teacher_networks.append(teacher)print(Fore.MAGENTA + "Loading teacher model from '{}' ...".format(checkpoint_path) + Style.RESET_ALL)
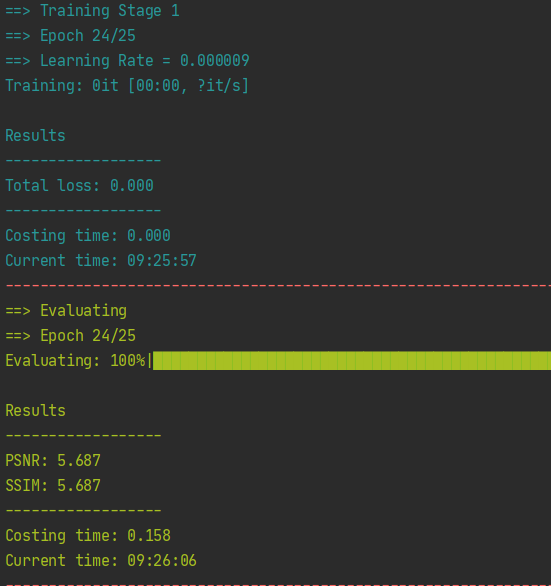
运行结果: