摘要:本文整理自实时引擎研发工程师袁奎,在 Flink Forward Asia 2022 数据集成专场的分享。本篇内容主要分为四个部分:
- 小红书实时服务降本增效背景
- Flink 与在离线混部实践
- 实践过程中遇到的问题及解决方案
- 未来展望
点击查看原文视频 & 演讲PPT
一、小红书实时服务降本增效背景
1.1 小红书 Flink 使用场景特点

小红书的 Flink 特点包含以下三条:
-
第一,云原生,复杂的多云、海内外架构。小红书从成立之初就将所有的技术体系全部搭建在公有云上,是真正意义上云的原住民。
我们与多家云厂商都有合作,比如 AWS,腾讯云,华为云,阿里云等等。经过多年的发展,业务数据也分布到了不同的云厂商下。云原生本身就会带来天然的好处,比如资源隔离和扩展都非常容易。
-
第二,数据集成链路较长,作业存在高峰期资源互相抢占的现象。以数据集成为例,在多云体系架构下,数据要经常进行跨云的传输,所以数据集成任务是重要且不可或缺的。我们在过去搭建了 Flink 的数据集成的独占集群,但随着数据集成任务的增多,出现了越来越多资源抢占的现象。
因为 Flink 集成任务都是批任务,大部分会在凌晨同时集中运行,就会出现一部分任务因抢占不到资源而失败的情况。同时整个资源池的整体利用率也比较低,因为白天批任务运行的比较少,这个时候资源是空闲的。
-
第三,数据集成的高优、低优作业均以 Flink 流模式引擎运行。有一些历史原因,一个是因为早期 Flink 版本的批模式引擎还不成熟,另外一个是流模式比较简单,它速度快,且不用考虑中间数据落盘的问题。在资源比较宽裕的情况下,它是更优的选择。
1.2 小红书 Flink 数据集成服务

小红书典型的数据集成类型有很多种,比如 Hive to Clickhouse、Hive to Doris、Hive to MySQL、Mongo to Hive 等等。
上图右侧是是一张 Top 图,一个数据源进行了一次 Mongo 的 Lookup Join,分为两个流写入到下游,这就是一个典型的 Flink 数据集成任务。
1.3 降本增效的大环境要求

随着小红书的发展,基础设施越来越完善,资源的使用也更加规范化。过去那种资源野蛮申请的时代已经结束,现在逐渐重视集群的 CPU 利用率。
在这样的背景下,我们来看 Flink 的资源集群。一方面我们现在的 Flink 资源集群主要采用独占模式,部分小资源池任务比较少,容易产生资源碎片,存在资源浪费。另外一方面 Flink 集成任务的集群,在晚上存在资源抢占的现象,而在白天又因为资源空闲而利用不起来,会造成整体的资源利用率不高。

针对以上两个问题,有什么解决方法,来提升整体资源的利用率呢?可以分为如下两点:
- 第一,如何规避小规模集群。我们可以将小规模集群进行合并,然后配合 K8s 的 Resource Quota 进行资源隔离。除此之外,我们还有一个更好的解决方案,即使用容器团队提供的在离线混部集群。将小规模集群的任务迁移到在离线混部集群中,然后将小规模集群的资源释放掉。
- 第二,如何减少高峰时期的资源抢占。从平台的角度来考虑,我们可以优化资源的调度,细化任务的优先级。从 Flink 引擎的角度来考虑,我们可以推广 Flink 的批模式引擎,因为批模式引擎对资源的要求更低。但我们的切入点不太一样,我们是从资源角度来考虑的。
1.4 降本增效视角下的 Flink 流模式/批模式对比

接下来我们从资源角度对比一下 Flink 的流模式和批模式。
Flink 的流模式引擎运行的时候没有阶段的概念,数据以 pipeline 的方式进行流转。这就要求所有的算子和并发的资源都要实时准备就绪,程序才能正常运行。而对于批模式引擎来说,任务被划分到几个阶段,上一个阶段运行结束后才能运行下一个阶段,且只需要部分算子和并发获取到资源就可以运行了。
从另外一个角度来看,部分聚合类型的批任务,在流模式运行的时候,会不可避免地引入 State 和 Watermark,这就需要更多的CPU和内存资源。而在批模式引擎下不需要 State 和 Watermark,仅需要 Shuffle 中间数据,这对磁盘的要求也很高,但磁盘相对于 CPU 和内存来说更加便宜。
这就是资源视角下流模式和批模式的对比,也是我们将批任务从流模式切换到批模式来运行的一些考虑。
二、Flink 与在离线混部实践
2.1 在离线混部的 K8s 集群

首先来看看什么是在离线混部。一般公司都会有两种类型的服务。一种是在线服务,它的特点就是运行时间长,服务流量和资源利用率具有潮汐性。也就是在白天使用人数多的时候,资源利用率就会高,流量也会高,而到了晚上使用人群数量降下来之后,资源利用率也会降下去。另外一种是离线作业。它只会运行一段时间,运行期间资源利用率非常高,一般也是时延不敏感的,只要在一个时间点之前运行结束之后资源就会空闲下来。
所谓在离线混部就是指将在线服务空闲的资源匀给离线作业使用,提升资源的整体利用率。对离线业务来说,能极大降低这资源的使用成本。在离线任务混跑期间,需要保护在线服务,可能会对离线业务的运行进行资源压制等操作。
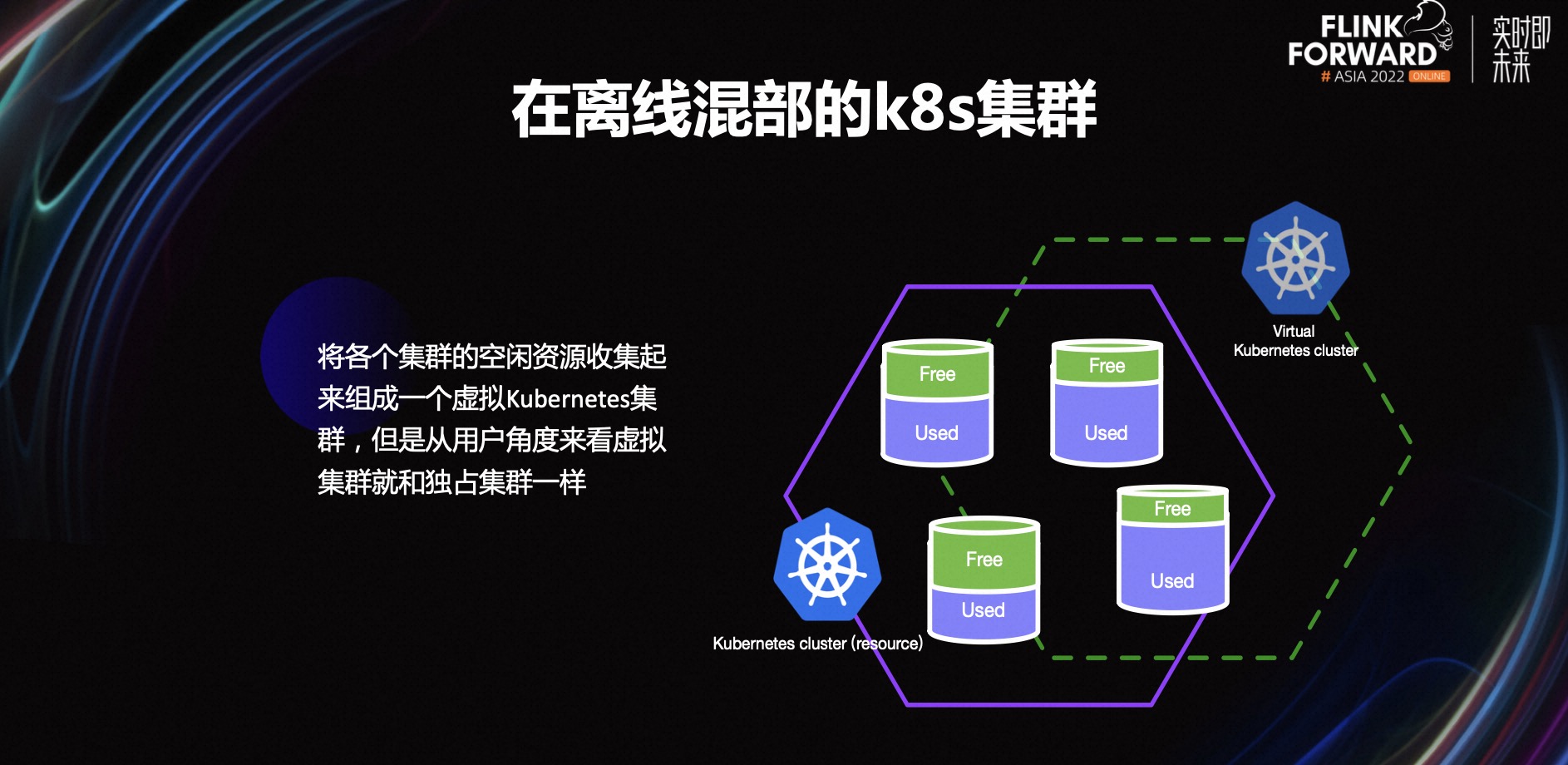
上图是在离线混部集群的示意图。容器团队将各个在线服务集群的空闲资源收集起来,组成一个资源集群。从用户角度,只能看到一些虚拟节点,但实际上每个虚拟节点背后都对应着一到多个真正的资源节点。对用户来说,虚拟集群的使用和真正独占集群是一样的,唯一不一样的是,虚拟节点的资源可能在不断变化。容器团队提供了在离线混部集群,而我们正好有离线任务,且有资源利用率的压力,算是一拍即合。
2.2 适合在离线混部的离线任务特点

哪些任务适合迁移过去,主要的考虑的特点有以下三个:
-
第一个是迁移过去的任务必须是非延时敏感的,因为在离线混部集群会压缩离线资源,离线任务运行的时间可能会更长。
-
第二个是任务要具有潮汐的特性,需要选择刚好在资源空闲时大量运行的离线任务迁移过去。一般来说,在线服务在晚上资源比较空闲,而离线任务都是集中在晚上运行比较多,这一点比较契合。
-
第三个是具有容错能力,因为在离线混部可能会压缩离线任务的资源,并对 Pod 进行驱逐,所以需要任务具有一定容错能力。
2.3 适合在离线混部的 Flink 任务

对批任务来说,由于 Pod 可能被驱逐掉,当被驱逐的时候,在其他节点上拉起就有可能重新消费数据,造成数据的重复,所以我们要选择 Sink 端支持幂等插入或不在意重复数据的批任务迁移。对批模式引擎,我们要尽可能让所有算子 chain 到一起,选择这一部分的任务迁移。因为算子如果不 chain 到一起,就会进行中间数据的落盘,这样就会对资源节点的要求更高。尽量选择在夜间大量运行的批任务迁移,因为在离线混部集群在晚上资源比较空闲。一般在离线混部集群不适合上流任务,但因为它在白天会有一些空闲资源能够支持一部分的流任务运行,所以我们也选择迁移一部分低优的流任务,且这部分流任务需要能够容忍 Fail Over,允许一段时间的延迟。
2.4 Flink 与在离线共建
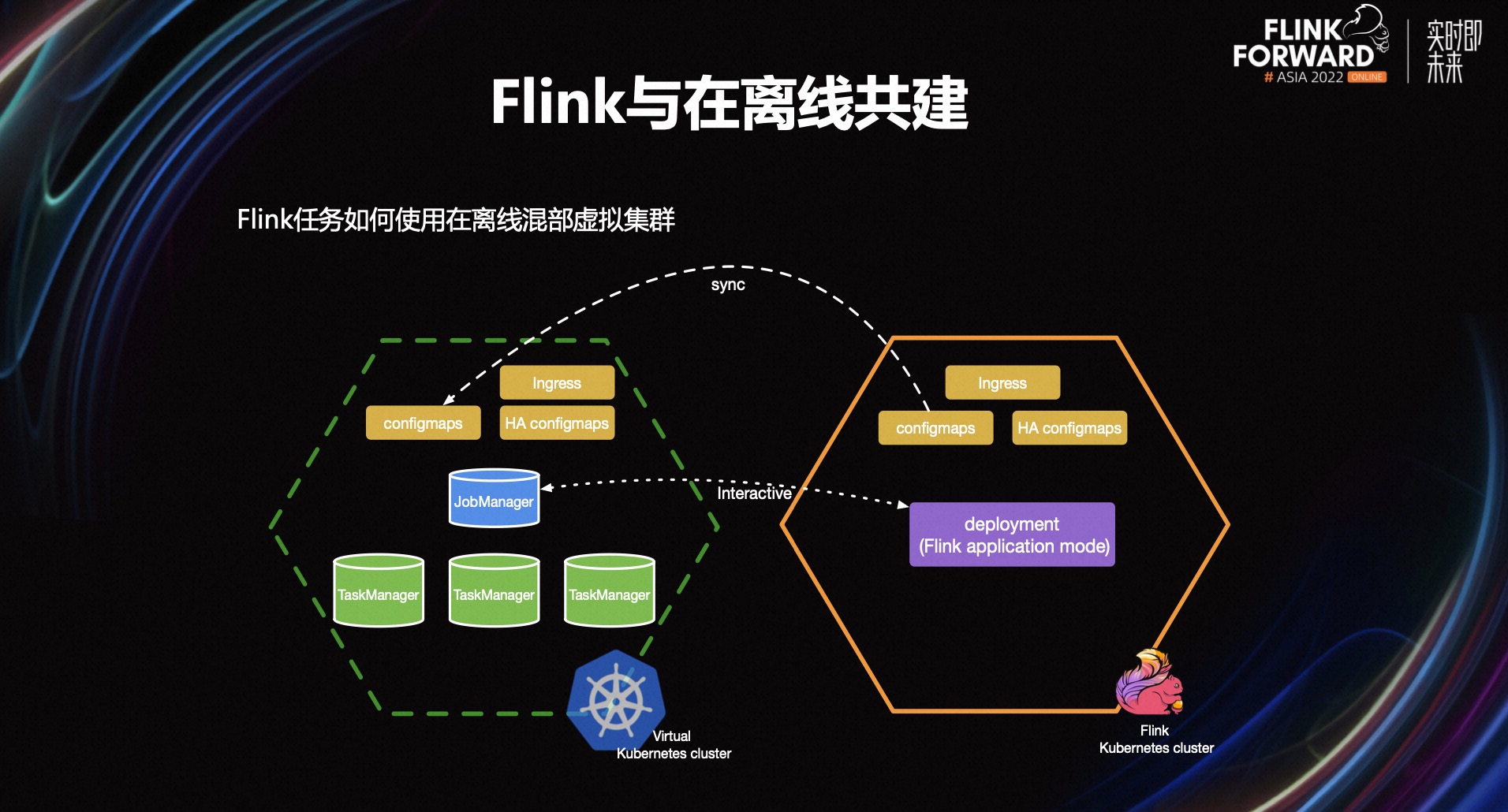
首先我们会部署一个 Flink 的独占集群,它上面没有独占的节点,然后容器团队将虚拟节点部署到我们的独占集群中。虚拟节点背后对应着一个 controller 和真正的资源节点,当我们提交任务时,只需要将任务提交给虚拟节点,deployment 就会在虚拟节点上拉起 JobManager 的 Pod。最后这个创建过程会被虚拟节点的 controller 下发到背后真正的资源节点上执行。
我们采用的是 Flink Native K8s 的方式,所以 TaskManager 由 JobManager 拉起。这个创建过程和 deployment 的创建过程一样,也会被虚拟节点下发到真正的资源节点去执行。也就是说最终 JobManager 和 TaskManager 的 Pod 都运行在背后的资源节点上,在虚拟节点上只有 Pod 的一份镜像。对于 Configmaps、Service、Ingress 等 K8s 资源,它的源数据都存在 ETCD 中,只需要同步一部分过去就可以了。
通过这种方式,我们可以在 Flink 独占集群正常提交任务,且能正常通过 kubectl 命令操作 Pod,对我们来说使用在离线的虚拟集群就和使用一个普通的 flink 独占集群是一样的。当然实现过程中有一些问题,比如 JobManager 和 TaskManager 分属于两个集群,他们之间如何进行通信,日志和监控指标如何采集等等,这些都是一些工程实现上的问题,这里就不再赘述了。
三、实践过程中遇到的问题及解决方案
最后一部分就是我们在实践过程中遇到的一些问题,作为云的原住民,这里问题也聚焦于我们在云原生上遇到的一些问题和解决方案。
3.1 避免宿主机上临时数据文件的残存
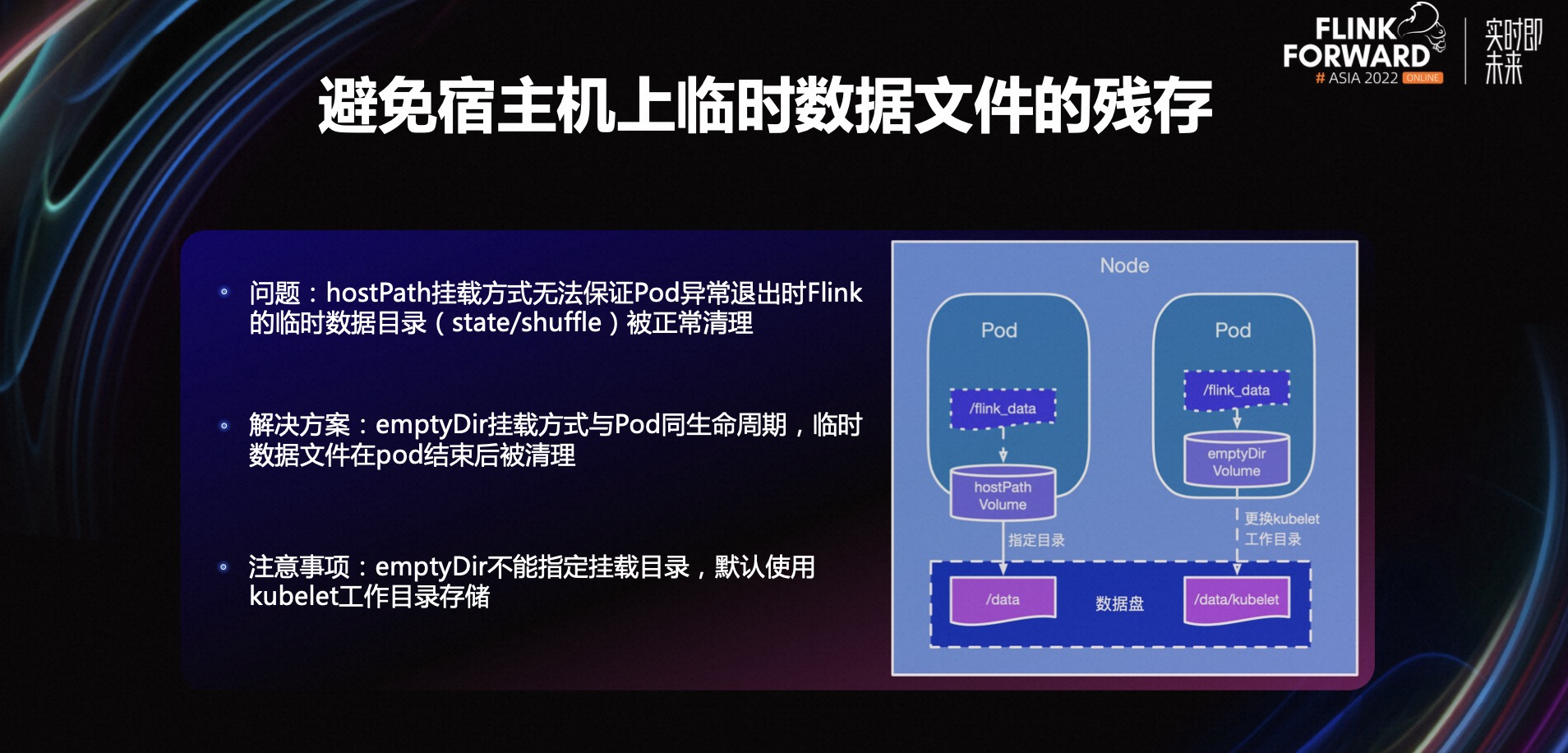
第一个问题,如何避免宿主机上临时数据文件的残存。使用过 K8s 容器技术的人都会遇到这样的问题,默认情况下启动一个容器,容器中的临时数据文件都存在 docker 盘中。如果临时数据文件过大就会影响 docker 的运行稳定性,这个时候我们可以在容器中挂载另外一块数据盘,让临时数据文件写到这块数据盘中,这样就不会影响 docker 的运行稳定性了。
在 K8s 里挂载数据盘一般都通过 hostPath volume 的挂载方式,这种方式的好处是可以指定一个宿主机的挂载目录,挂载方式简单,但 hostPath 挂载方式依赖程序本身临时文件的清理逻辑。如果 Pod 异常退出,比如遇到了 OOM 被 K8s Kill 掉了,此时临时数据文件的清理逻辑还没来得及执行 Pod 已经结束掉了,那么这个临时数据文件就会残存在宿主机上。当残存的文件越来越多,占满了整个数据盘,就会影响任务运行的稳定性。那么我们是如何解决的呢?
K8s 有一种挂载方式叫 emptyDir,它与 Pod 同生命周期。所以无论 Pod 是正常结束还是异常结束,只要结束之后 emptyDir 挂载目录中的临时数据文件都会被清理掉,这就降低了对程序清理逻辑的依赖。
这里有一点需要要注意,emptyDir 不能指定挂载目录,默认使用 kubelet 工作目录存储。一般这个目录在系统盘里,如果不做任何处理,临时文件写入系统盘就有可能会影响系统运行的稳定性,所以一般我们要在开机的时候,更换 kubelet 的工作目录到另外一块数据盘。
3.2 批模式在云原生场景下的 OOM 问题
第二个问题,批模式在云原生场景下的 OOM 问题。这个任务在流模式引擎运行的非常顺畅,但转换到批模式引擎运行之后就会频繁出现 OOM 问题。
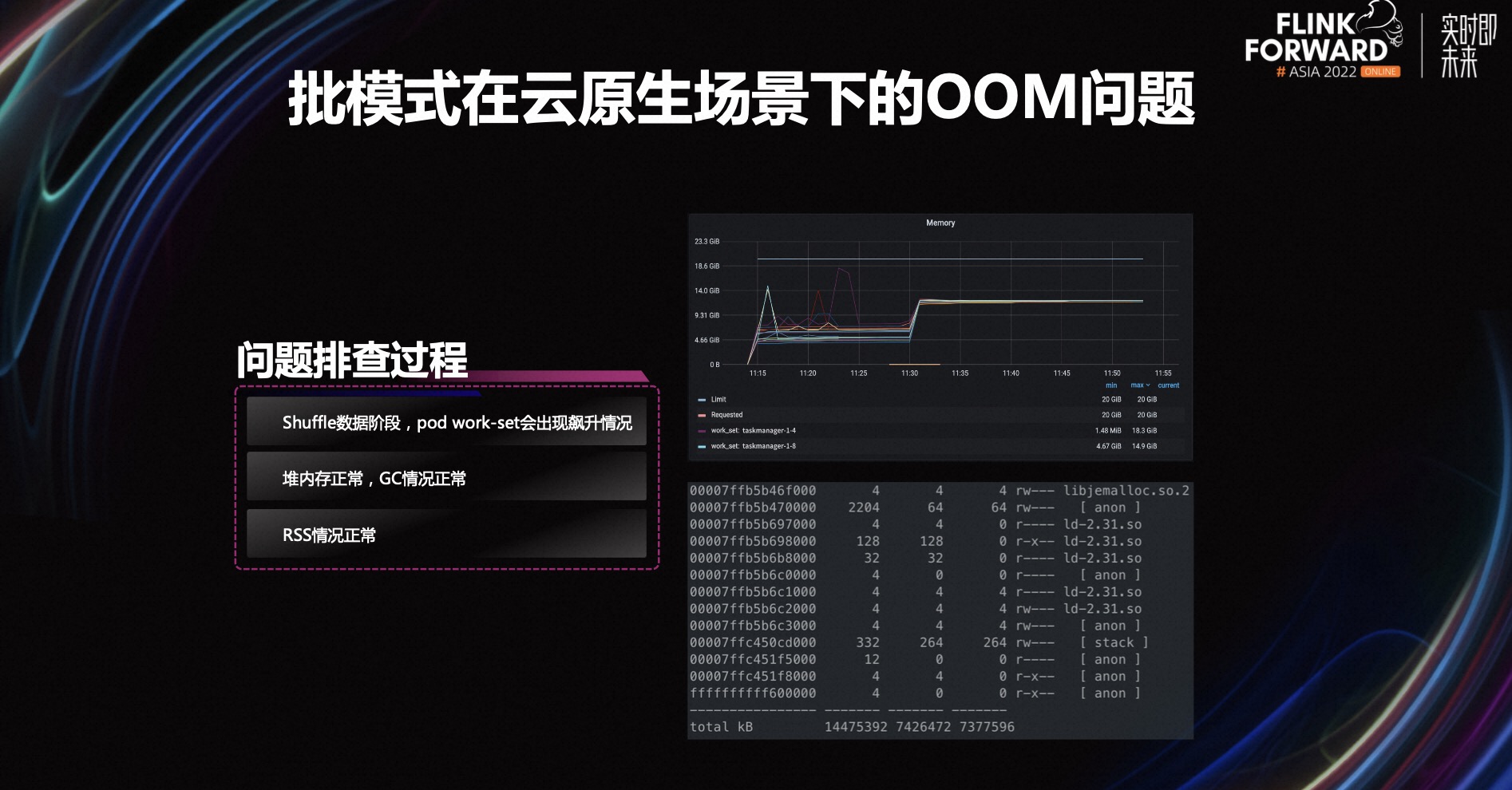
这个任务在 chain 之后依然有两个算子,也就是说中间会进行一次数据的 Shuffle,OOM 就发生在写 Shuffle 数据的这个阶段。从上图右上角的监控图,可以明显看到两个阶段,第一个阶段是写 Shuffle 数据的阶段,有一些 work-set 飙升的情况,一旦超过容器限制就会触发 OOM Kill。
出现这种情况,首先我们首先从 Flink 的 webui 上观察堆内存使用情况,目前看堆内存的使用是正常的,从 GC 监控界面也可以看到 GC 情况是正常的。那么我们怀疑可能是堆外内存出现了泄漏,于是我们进入 Pod 里面通过 pmap 命令查看 RSS 的使用情况。也就是右下角的这张图,可以看到 RSS 也是正常的,且 RSS 只有 7G 左右,没有达到 20G 的限制,也就可以说明不是堆外内存泄露导致的。
到这里答案其实已经呼之欲出了。work-set 指标可以简单理解为 RSS+Page Cache,RSS 是正常的,work-set 又出现飙升的情况,所以我们就可以怀疑是 Page Cache 造成的 OOM。

顺着这个思路,我们登录到机器节点上去查看机器日志。如上图所示,我们找到了一个调用栈,可以看到是由于申请 Page Cache 造成的 OOM。实际上就是云盘的性能不足,在 Shuffle 数据时瞬间大量写 Page Cache,不能及时将数据刷到磁盘,导致内存超用,触发 OOM Kill。
我们有一个临时的解决方案。增加 Pod 数量,减少单个 Pod 处理的数据量,然后尽量让 Pod 分布到不同的机器节点上,降低机器节点的压力。或者升级机器内核,通过调整内核参数进行限流。除此之外,我们还可以从 Flink 引擎本身着手,在 Shuffle 数据阶段直接进行限流。
四、未来展望

未来小红书将要探索的方向,主要包含以下三部分。
- 第一,批模式应用深入挖掘。我们希望能够深入用户,挖掘更多的批模式引擎的使用场景,真正推广 Flink 的流批一体。
- 第二,配合使用 K8s 的 Resource Quota 功能,将业务方的多个小集群进行合并,减少机器的资源碎片问题。
- 第三,Serverless 是批模式引擎在云原生环境下部署的一个重要目标,但是强行部署为 serverless 意味着如果 pod 被 Kill 掉中间数据就会被清理,会影响任务的故障恢复,这个时候 remote Shuffle Service 的价值就体现出来了,使用 Remote Shuffle Service 可以有效减少对本地磁盘的部分依赖,提升资源利用率,助力云原生架构。
点击查看原文视频 & 演讲PPT