K8s+Docker+KubeSphere+DevOps
- 前言
- 一、阿里云服务器开通
- 二、docker基本概念
- 1.一次构建、到处运行
- 2、docker基础命令操作
- 3、docker进阶操作
- 1.部署redis中间件
- 2.打包docker镜像
- 三、kubernetes 大规模容器编排系统
- 1、基础概念:
- 1、服务发现和负载均衡
- 2、存储编排
- 3、自动部署和回滚
- 4、自动完成装箱计算
- 5、自我修复
- 6、密钥与配置管理
- 2、架构
- 1、工作方式
- 2、组件架构
- a、kube-apiserver
- b、etcd
- c、kube-scheduler
- d、kube-controller-manager
- e、cloud-controller-manager
- f、Node 组件
- g、kubelet
- h、kube-proxy
- 3、集群搭建
- 1、基础环境、所有服务器执行
- a、安装docker环境
- b、服务器基础设置
- 2、k8s初始化master节点:
- a、kubeadm reset 初始化错误重置
- b、kubeadm init 初始化成功
- c、工作节点h5和h9
- d、网络配置
- 1、kubectl get nodes
- 2、主节点运行
- 3、令牌失效,生成新令牌
- 4、安装k8s可视化界面,dashboard
- 1、安装
- 2、查看容器启动状态
- 3、修改集群的web访问界面端口暴露出来等同于docker -p端口映射选项
- 4、找到映射端口
- 5、访问
- 四、k8s核心实战
- 1、命令行
- 2、NameSpace
- 3、pod 需要图片
- 4、Deployment:自愈、扩缩容
- 5、service:pod的服务发现与负载均衡
- 6、 ingress:svc的统一网关入口
前言
提示:这里可以添加本文要记录的大概内容:
提示:以下是本篇文章正文内容,下面案例可供参考
一、阿里云服务器开通
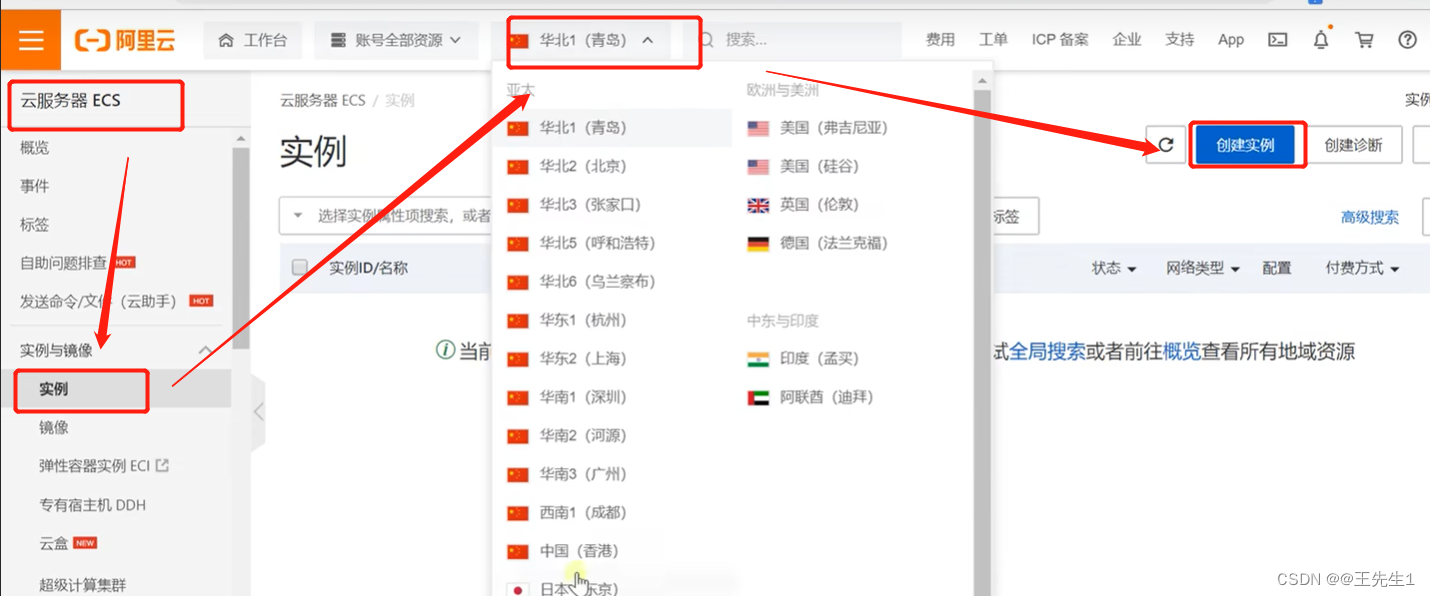
云服务器ECS–实例–选区–创建–付费模式(按量付费)–服务器架构选择(包含服务器内存及数量)–镜像(操作系统)–选择实例基础存储–确认购买–选择网络(默认或选择自建的vpc)–网络安全组、分配公网ip(远程访问:固定带宽或者流量、访问部分端口须安全组开放端口)–系统配置(密码、服务器名称)–创建实例
集群网络规划:
专有网络VPC创建:私有网络、专有网络(划分网段)
专有网络–创建–名称–ipv4网段–创建交换机(子网–名称–可用区–)–
连接工具electerm: https://electerm.github.io/electerm
二、docker基本概念
1.一次构建、到处运行
https://baijiahao.baidu.com/s?id=1651403959832263386&wfr=spider&for=pc
三要素:镜像、容器、仓库
2、docker基础命令操作
#容器运行命令
docker run --name=zidingyi -d(后台) --restart=always(开机自启) -p(映射) 88(主机):80(容器) images#挂载数据到外部修改(主机目录为空,容器内同为空)
docker run --name=zidingyi -d(后台) \
--restart=always(开机自启) -p(映射) 88(主机):80(容器)\
-v 主机目录:容器目录:ro(容器内只读、rw) images#查看正在运行中的
docker ps
#查看所有
docker ps -a
#删除停止/强制删除运行的容器
docker rmi/rm -f images/id
#停止/启动容器
docker stop/start iamges
#更新配置
docker update images --restart=always
#交互式容器命令
docker exec -it id /bin/bash或/bin/sh
#容器提交改变(修改好)可生成一个新镜像
docker commit -a (作者) -m "变化标签" image_id image_new_name:ver
#镜像保存传输加载(离线操作)
docker save -o name.tar images:ver
docker load -i name.tar docker export images_id > name.tar
cat name.tar | docker import - 仓库/image_name:version#镜像推送到远程仓库tag 修改镜像标签,仓库/镜像:版本都可改
docker tag local-image:tagname wangjch/images:tagnamedocker login #登录docker hub
docker push wangjch/images:tagname #提交推送
docker logout
#公有镜像下载
docker pull wangjch/images:tag
#查看日志排错
docker logs image/id
#镜像的net、image、volunm 等内部细节
docker inspect image/id
#复制容器内文件到本机
docker cp id:容器目录 本机目录
docker cp 本机目录 id:容器目录
#/docker构建镜像
docker build -t java-daemon:v1.0 -f ./DockerFile
#/docker network不同服务器之间容器的互联通信以及端口映射
容器ip变动时可以通过服务名直接网络通信不受影响
docker network create net_name
docker network connect net_name container1
#同服务器下,network链接
docker run -it --network net_name image
##虚悬镜像查看删除。
docker image ls -f dangling=true
docker image prune
##docker compose
https://docs.docker.com/compose/compose-file/
docker compose up/down 直接创建删除
##
docker swarm
3、docker进阶操作
https://start.spring.io/
1.部署redis中间件
docker pull redis#docker run 使用自定义配置文件启动命令 (--privileged=true -v挂载权限不够时)(继承--volumes-from 父类name)
#创建redis.conf配置文件
docker run -v /data/redis/redis.conf:/etc/redis/redis.conf \
-v /data/myredis/data:/data/redis/data
-d --name myredis \
-p 6379:6379 \
redis:latest redis-server /etc/redis/redis.conf #(自定义启动命令\指定容器内配置文件)
2.打包docker镜像
FROM 基础镜像
RUN 容器构建是需要的命令
WORKDIR 指定创建容器后,登陆时的工作目录。
USER 指定用户
ENV 用于构建过程中设置环境变量
ADD 将宿主机的文件拷贝进镜像且自动处理url和解压tar压缩包
COPY 拷贝文件和目录到镜像中。
VOLUME 容器卷 -v
EXPOSE 端口暴露 -p
CMD 指令会被docker run后面的指令所取代。
ENTRYPOINT 容器启动时运行的命令但不会被docker run后面的命令取代,并作为参数
微服务
#dockerfile
FROM openjdk:8-jdk-slim ##环境
LABEL maintainer=wangjch#复制本地jar包到容器内
COPY target/*.jar /app.jar
COPY target/*.yml /app.yml
##ADD app.jar docker.jar
#镜像启动命令
ENTRYPOINT ["java" ,"-jar","app.jar"]
# docker构建镜像
docker build -t java-daemon:v1.0 -f ./DockerFile
#运行容器
docker run -d -p 8080:8080 \
-v /data/app-java/app.yml:/app.yml--name myjava java-daemon:v1.0
#推送到远程仓库
docker tag java-daemon:v1.0 wangjch/java-daemon:v1.0
docker push wangjch/java-daemon:v1.0
#拉取镜像
docker pull wangjch/java-daemon:v1.0
三、kubernetes 大规模容器编排系统
1、基础概念:
1、服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
2、存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
3、自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
4、自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。
5、自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
6、密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
2、架构
1、工作方式
k8s cluster = N Master Node + N Worker Node : N >=1
2、组件架构
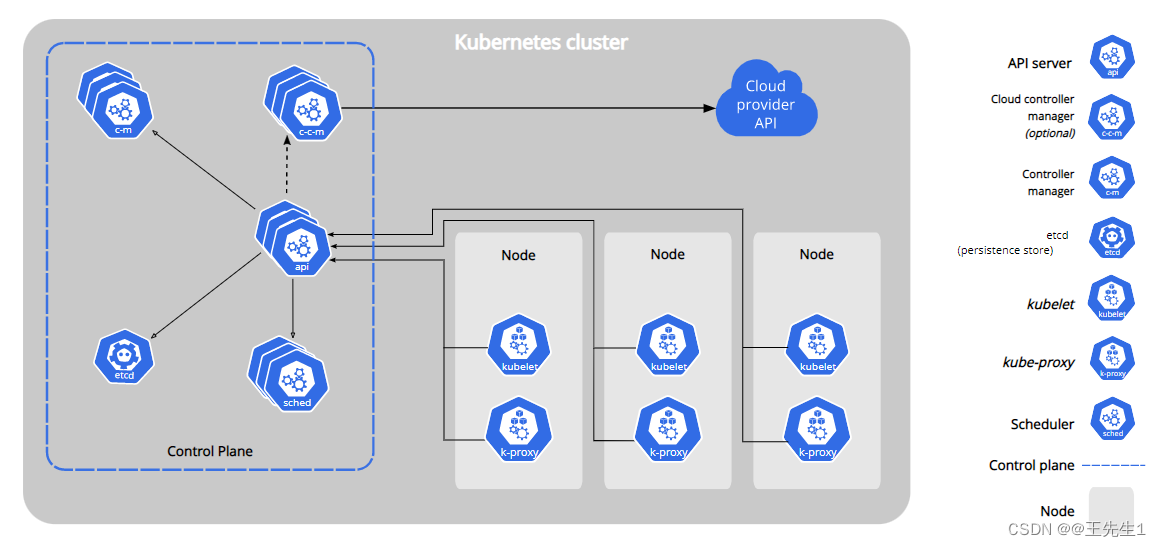
控制组件controller manager、对接组件apiserver(控制节点的交互唯一入口、通知记录存储)、调度组件scheduler监视选择优先Node运行pod、存储组件etcd、代理组件proxy之间互相同步(访问所有项目的入口)、cloud provider api 与外部云链接控制(cloud controller manager)
a、kube-apiserver
API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平扩缩,也就是说,它可通过部署多个实例来进行扩缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
b、etcd
一致且高度可用的键值存储,用作 Kubernetes 的所有集群数据的后台数据库。
如果你的 Kubernetes 集群使用 etcd 作为其后台数据库, 请确保你针对这些数据有一份 备份计划。
你可以在官方文档中找到有关 etcd 的深入知识。
c、kube-scheduler
kube-scheduler 是控制平面的组件, 负责监视新创建的、未指定运行节点(node)的 Pods, 并选择节点来让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 及 Pods 集合的资源需求、软硬件及策略约束、 亲和性及反亲和性规范、数据位置、工作负载间的干扰及最后时限。
d、kube-controller-manager
kube-controller-manager 是控制平面的组件, 负责运行控制器进程。
从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在同一个进程中运行。
这些控制器包括:
节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
端点分片控制器(EndpointSlice controller):填充端点分片(EndpointSlice)对象(以提供 Service 和 Pod 之间的链接)。
服务账号控制器(ServiceAccount controller):为新的命名空间创建默认的服务账号(ServiceAccount)。
e、cloud-controller-manager
一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager)允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
cloud-controller-manager 仅运行特定于云平台的控制器。 因此如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的集群不需要有云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的控制回路组合到同一个可执行文件中, 供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
节点控制器(Node Controller):用于在节点终止响应后检查云提供商以确定节点是否已被删除
路由控制器(Route Controller):用于在底层云基础架构中设置路由
服务控制器(Service Controller):用于创建、更新和删除云提供商负载均衡器
f、Node 组件
节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
g、kubelet
kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs, 确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
h、kube-proxy
kube-proxy 是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
3、集群搭建
1、基础环境、所有服务器执行
a、安装docker环境
#下载镜像
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo#安装docker
yum -y install docker-ce docker-ce-cli containerd.io (ver20.10.7、1.4.6)#docker镜像国内加速
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"],"log-driver": "json-file","log-opts": {"max-size": "100m"},"storage-driver": "overlay2"
}
EOFsystemctl daemon-reload
#立即启用docker并开机自启
systemctl enable docker --now
b、服务器基础设置
#各个机器设置自己的域名
hostnamectl set-hostname xxxx# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/configsed -i 's/^SELINUX=disabled$/SELINUX=permissive/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstabsystemctl disable firewalld.service --now
systemctl disable NetworkManager --now
ntp时间同步rpm -ivh http://mirrors.wlnmp.com/centos/wlnmp-release-centos.noarch.rpmntpdate time2.aliyun.com
crontab -e
*/5 * * * * ntpdate time2.aliyun.com/etc/rc.local
ntpdate time2.aliyun.comulimit -SHn 65535#允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
vm.swappiness = 0 # 禁止使用 swap 空间,只有当系统 0OM 时才允许使用它vm.overcommit memory=1 # 不检查物理内存是否够用
fs.inotify.max_user_instances = 8192
fs.inotify.max_user_watches = 1048576
fs.file-max = 52706963
fs.nr_open = 52706963
net.ipv6.conf.all.disable_ipv6 = 1
net.netfilter.nf_conntrack_max = 2310720
net.ipv4.ip_forward = 1
EOFsysctl --systemsysctl -p /etc/sysctl.d/k8s.conftimedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0systemctl restart rsyslog crond
systemctl stop postfix && systemctl disable postfixmkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5mRateLimitInterval=30sRateLimitBurst=1000
# 最大占用空间 19G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到
syslogForwardToSyslog=no
EOF
systemctl restart systemd-journald
yum install wget jg pamisc vim net-tools telnet yum-utils device-mapper-persistent-data lvm2 -yyum install ipvsadm ipset sysstat contrack libseccomp -y
#安装命令补全
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
2、永久生效
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrcmodprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4 / nf_conntrack
cat << EOF > /etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ng_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
systemctl enable systemd-modules-load --now
lsmod | grep -e ip_vs -e nf_conntrack
#导入签名key,这是elrepo仓库公共秘钥,(3.0以上内核引入签名机制)以及仓库源,
#文档地址http://elrepo.org/tiki/HomePage
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install http://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm#查看可安装版本
yum --enablerepo="elrepo-kernel" list --showduplicates | sort -r | grep kernel-ml.x86_64#选择ml或者lt版本安装
# 安装 ML 最新版本
yum --enablerepo=elrepo-kernel install kernel-ml-devel kernel-ml -y
# 安装 LT长期支持版本
yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y#查看现有内核启动顺序
awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg#修改默认启动项
grub2-set-default 0 从0计数,grub2-set-default 0和/etc/default/grub文件里的GRUB_DEFAULT=0意思一样看新版本为那个序号一般为0
#关闭 NUMA
cp /etc/default/grub{,.bak}vim /etc/default/grub # 在 GRUB_CMDLINE_LINUX 一行添加numa=off’参数,如下所示:diff /etc/default/grub.bak /etc/default/grub<GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet"
GRUB CMDLINE LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet numa=off"cp /boot/grub2/grub.cfg[,.bak}#重新生成grub配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#重启检查版本即可
https://baijiahao.baidu.com/s?id=1750085573442213926&wfr=spider&for=pc
haproxy + keepalived
haproxy 配置
grep -E -v "^*#|^$" /etc/haproxy/haproxy.cfg
globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemonstats socket /var/lib/haproxy/stats
defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption forwardfor except 127.0.0.0/8option redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000
frontend main *:16443acl url_static path_beg -i /static /images /javascript /stylesheetsacl url_static path_end -i .jpg .gif .png .css .jsuse_backend k8s-master if url_staticdefault_backend k8s-master
listen stats bind *:8006mode httpstats enablestats hide-versionstats uri /statsstats refresh 30s stats realm Haproxy\ statisticsstats auth admin:P@ssword
backend k8s-masterbalance roundrobinserver k8s-master-01 192.168.220.128:6443 checkserver k8s-master-02 192.168.220.129:6443 checkserver k8s-master-03 192.168.220.130:6443 check
keepalived 配置
[root@h1 k8s]# grep -E -v "^*#|^$" /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {router_id k8s-master-01 ##主备不同vrrp_skip_check_adv_addrvrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0
}
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 51 ##主备相同priority 100 ##权重逐级减小advert_int 1authentication {auth_type PASSauth_pass 10086}virtual_ipaddress { 192.168.200.100 ##vip}
}
2、k8s初始化master节点:
kube-proxy开启ipvs的前置条件
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash/etc/sysconfig/modules/ipvs,modules && lsmod grep -e ip_vs -e nf_conntrack _ipv4
k8s服务对应默认端口
Kubernetes API server: Port 6443 (secure) or 8080 (insecure).
kubelet API: Port 10250 (default).
Kubernetes DNS service (CoreDNS): Port 53 (TCP and UDP).
etcd: Ports 2379 (client communication) and 2380 (server-to-server communication).
kube-proxy: Port 10256 (default).
kube-scheduler: Port 10251 (default).
kube-controller-manager: Port 10252 (default).
Container runtime (e.g. Docker): Typically uses port 2375 (insecure) or 2376 (secure).
Prometheus monitoring: Port 9090 (default).
Grafana dashboard: Port 3000 (default).
##镜像下载:
##无魔法上网下载镜像
cat << EOF > image_download.sh
#!/bin/bash
images_list='
daocloud.io/daocloud/kube-apiserver:v1.26.0
daocloud.io/daocloud/kube-controller-manager:v1.26.0
daocloud.io/daocloud/kube-scheduler:v1.26.0
daocloud.io/daocloud/kube-proxy:v1.26.0
daocloud.io/daocloud/conformance:v1.26.0
daocloud.io/daocloud/pause:3.7
daocloud.io/daocloud/etcd:3.5.3-0
daocloud.io/daocloud/coredns/coredns:v1.8.6'for i in $images_list
dodocker pull $i
done
EOF
##镜像上传
## 上传到自己的docker hub
[root@h1 k8s]# cat << EOF > images_push.sh
#!/bin/bash
images_list='
daocloud.io/daocloud/kube-apiserver:v1.26.0
daocloud.io/daocloud/kube-controller-manager:v1.26.0
daocloud.io/daocloud/kube-scheduler:v1.26.0
daocloud.io/daocloud/kube-proxy:v1.26.0
daocloud.io/daocloud/conformance:v1.26.0
daocloud.io/daocloud/pause:3.7
daocloud.io/daocloud/etcd:3.5.3-0
daocloud.io/daocloud/coredns/coredns:v1.8.6'
images_target='
wangjch/kube-apiserver:v1.26.0
wangjch/kube-controller-manager:v1.26.0
wangjch/kube-scheduler:v1.26.0
wangjch/kube-proxy:v1.26.0
wangjch/conformance:v1.26.0
wangjch/pause:3.7
wangjch/etcd:3.5.3-0
wangjch/coredns/coredns:v1.8.6'
for i in $images_list
dofor im in $images_target dodocker tag $i $imdocker push $imdone
done
EOF
a、kubeadm reset 初始化错误重置
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOFyum install -y kubelet kubeadm kubectlcat /etc/profile
#export DOCKER_CGROUP=$(docker info | grep "Cgroup D" | cut -d ' ' -f4)
export DOCKER_CGROUP=systemdsystemctl enable kubelet && systemctl start kubeletkubeadm config print init-defaults >> kubeadm-config.yaml
kubeadm config migrate --old-config kubeadm-config.yaml --nwe-config new.yaml
kubeadm config images list
kubeadm config images pull --config new.yaml
kubeadm init \
--apiserver-advertise-address=192.168.174.44 \
--control-plane-endpoint=h4 \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v版本号\
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=172.168.0.0/16
--xri-socket unix:///var/run/containerd/containerd.sock
##解释:apiserver-advertise-address=(master节点所在的ip)
control-plane-endpoint=cluster-endpoint (/etc/hosts中master主机名)
image-repository registry.aliyuncs.com/google_containers (镜像仓库地址,此为官方)
##service-cidr、pod-network-cidr所有网络与主机ip范围不重叠。
#生成kubeadm-config文件
kubeadm config print init-defaults > kubeadm-config.yaml
vim kubeadm-config.yamlapiVersion: kubeadm.k8s.io/v1beta2 #使用的API版本
bootstrapTokens: #引导令牌的设置
- groups: #组设置- system:bootstrappers:kubeadm:default-node-token #指定默认节点令牌token: 7t2weq.bjbawausm0jaxury #节点令牌的值ttl: 24h0m0s #节点令牌的过期时间usages: #用途设置- signing #签名- authentication #身份验证
kind: InitConfiguration #初始化配置
localAPIEndpoint: #本地Kubernetes API的端点设置advertiseAddress: 192.168.220.128 #广告地址,即API服务器将用于在此地址上公开它自己bindPort: 6443 #绑定端口,即API服务器将用于此端口公开它自己
nodeRegistration: #节点注册信息criSocket: /run/containerd/containerd.sock #容器运行时的socketname: k8s-master01 #节点名称taints: #节点容忍设置- effect: NoSchedule #不允许在该节点上调度新的Podkey: node-role.kubernetes.io/master #键是节点角色的标签,这里是标记为master的节点
---
apiServer: #API服务器的设置certSANs: #证书的主体名称设置- 192.168.220.128 #证书的主体名称timeoutForControlPlane: 4m0s #控制平面操作的超时时间
apiVersion: kubeadm.k8s.io/v1beta2 #使用的API版本
certificatesDir: /etc/kubernetes/pki #证书目录
clusterName: kubernetes #集群名称
controlPlaneEndpoint: ”192.168.200.100:16443“ #控制平面的地址,这里是通过VIP来实现高可用
controllerManager: {} #控制器管理器的配置
dns: #DNS设置type: CoreDNS #使用的DNS插件
etcd: #etcd存储配置local: #本地etcd的配置dataDir: /var/lib/etcd #数据目录
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #容器镜像仓库地址
kind: ClusterConfiguration #集群配置
kubernetesVersion: v1.23.1 #使用的Kubernetes版本
networking: #网络配置dnsDomain: cluster.local #DNS域名podSubnet: 172.16.0.0/12 #Pod的IP地址段serviceSubnet: 192.168.0.0/16 #Service的IP地址段
scheduler: {} #调度器的配置常见错误:
一、Oct 08 20:31:27 k8s-master01 kubelet[3189]: E1008 20:31:27.600468 3189 run.go:74] “command failed” err=“failed to load kubelet config file, error: failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file “/var/lib/kubelet/config.yaml”, error: open /var/lib/kubelet/config.yaml: no such file or directory, path: /var/lib/kubelet/config.yaml”
解决办法:执行kubeadm init就会生成相应的配置文件二、Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the ‘criSocket’ field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
To see the stack trace of this error execute with --v=5 or higher
解决办法:加选项指定使用的CRI三、Error getting node" err=“node “k8s-master01” not found”
解决办法:这种情况是apiserver-advertise-address地址有误
kubeadm config print init-defaults > kubenetes-init-config
vim kubenetes-init-config四、failed pulling image "registry.k8s.io/pause:3.6
cri-docker会去拉pause镜像,因为镜像库原因可能拉不成功,我们需要在cri-docker.service文件中配置相应的镜像地址
注意:–network-plugin=留空,不要和网上傻不拉几的去填cni。网络的等集群创建好在配置
sed -ie ‘s#ExecStart=.*#ExecStart=/usr/bin/cri-dockerd --network-plugin= --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.8#g’ /usr/lib/systemd/system/cri-docker.servicegithub提供的镜像加速,下载github东西用这个前缀可以
https://ghproxy.com/cat /etc/kubernetes/kubelet.conf apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
kubelet --config=/etc/kubernetes/kubelet.conf
E0328 09:18:25.463707 83231 run.go:74] “command failed” err=“failed to validate kubelet flags: the container runtime endpoint address was not specified or empty, use --container-runtime-endpoint to set”
kubelet --config=/etc/kubernetes/kubelet.conf --container-runtime=remote --container-runtime-endpoint=unix:///var/run/docker.sock
apiVersion: kubelet.config.k8s.io/v1beta1 # 指定Kubelet配置文件的API版本
kind: KubeletConfiguration # 指定Kubelet的类型为KubeletConfiguration
cgroupDriver: systemd # 指定容器运行时使用的cgroup驱动为systemd
clusterDNS: # 指定集群DNS的地址
- 10.96.0.10
clusterDomain: cluster.local # 指定集群的域名
featureGates: # 定义功能开关,控制特定功能是否启用RotateKubeletServerCertificate: true # 开启自动轮换Kubelet证书的功能
authentication: # 配置Kubelet的认证方式anonymous: # 配置匿名认证enabled: false # 禁用匿名认证webhook: # 配置Webhook认证enabled: true # 启用Webhook认证x509: # 配置x509证书认证clientCAFile: /etc/kubernetes/pki/ca.crt # 客户端CA证书文件路径
authorization: # 配置Kubelet的授权方式mode: Webhook # 使用Webhook模式授权
serverTLSBootstrap: true # 启用自动为Kubelet生成证书的功能
tlsCertFile: /etc/kubernetes/pki/kubelet.crt # Kubelet证书文件路径
tlsPrivateKeyFile: /etc/kubernetes/pki/kubelet.key # Kubelet私钥文件路径
containerRuntime: remote # 指定容器运行时为远程的容器运行时
--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock # 指定容器运行时的终端点,这里使用了containerd运行时
b、kubeadm init 初始化成功
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:
##创建mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:
##root用户export KUBECONFIG=/etc/kubernetes/admin.confYou can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
### 加入主节点kubeadm join h4:6443 --token n6xtqm.79qrkwskxnzaypp5 \--discovery-token-ca-cert-hash sha256:ce62bcec7deeb91822685bc78a87699906b8a6681b0d51e31427603bfe63a42f \--control-plane Then you can join any number of worker nodes by running the following on each as root:
### 加入工作节点,
kubeadm join h4:6443 --token n6xtqm.79qrkwskxnzaypp5 \--discovery-token-ca-cert-hash sha256:ce62bcec7deeb91822685bc78a87699906b8a6681b0d51e31427603bfe63a42f
c、工作节点h5和h9
kubeadm join h4:6443 --token n6xtqm.79qrkwskxnzaypp5
–discovery-token-ca-cert-hash sha256:ce62bcec7deeb91822685bc78a87699906b8a6681b0d51e31427603bfe63a42f
d、网络配置
1、kubectl get nodes

2、主节点运行
修改文件calico.yaml
–pod-network-cidr=172.168.0.0/16
初始化master节点时,该范围ip与calico.yaml文件中须一致,下载完成后修改,再apply。
CALICO_IPV4POOL_CIDR

curl https://docs.projectcalico.org/manifests/calico.yaml -Okubectl apply -f calico.yaml
如遇以下报错:说明版本不对
error: unable to recognize "calico.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1"
在calico.yaml文件里面找到PodDisruptionBudgt前面的apiVersion:v1后面加上beta1改为apiVersion:v1beta1
错误原因是k8s不支持当前calico版本,如果你使用的是1.20版本的k8s,可安装v3.21版本的Calico,具体版本对应关系见系统要求
#下载其他版本
curl https://docs.projectcalico.org/v3.18/manifests/calico.yaml -O
curl https://docs.projectcalico.org/archive/v3.21/manifests/calico.yaml -O
kubectl apply -f calico.yaml
3、令牌失效,生成新令牌
kubeadm token create --print-join-command

4、安装k8s可视化界面,dashboard
1、安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
2、查看容器启动状态
kubectl get pod -A
3、修改集群的web访问界面端口暴露出来等同于docker -p端口映射选项
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboardtype: ClusterIP 改为 type: NodePort
4、找到映射端口
kubectl get svc -A |grep kubernetes-dashboard

5、访问
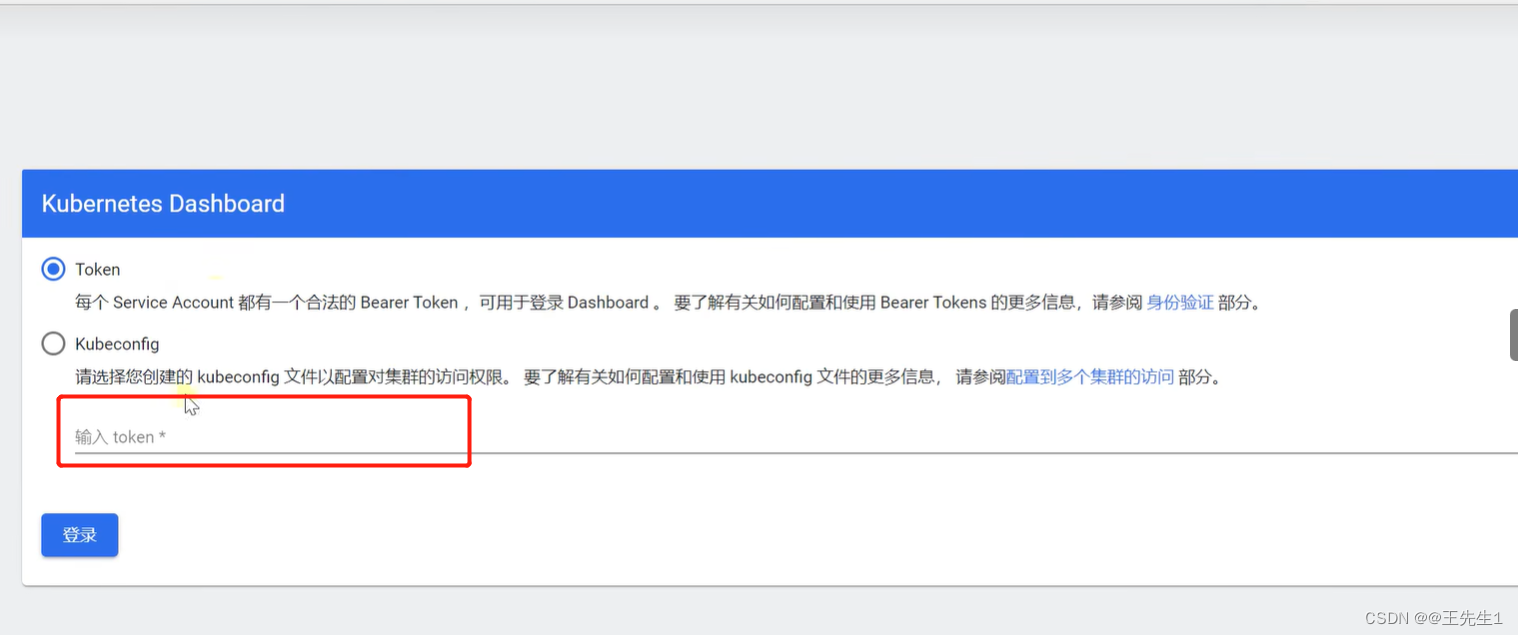
https://集群任意IP:30753
创建用户
kubectl apply -f dash.yaml
#创建访问账号,准备一个yaml文件; vim dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: admin-usernamespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: admin-user
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: cluster-admin
subjects:
- kind: ServiceAccountname: admin-usernamespace: kubernetes-dashboard
#获取访问令牌token
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
四、k8s核心实战
1、命令行
kubectl apply -f yaml文件
2、NameSpace
名称空间,对集群资源进行隔离划分。默认只隔离资源,不隔离网络。
#获取所有名称空间
kubectl get ns
#列出某命名空间下所有pod
kubectl get pod -n namepasce_name
#创建/删除名称空间
kubectl create/delete ns hello
##创建
vim hello.yaml && kubectl apply -f hello.yaml
apiVersion: v1
kind: Namespace
metadata:name: hello
##删除
kubectl delete -f hello.yaml
3、pod 需要图片
#启动pod
kubectl run mynginx --image=nginx
#查看默认命名空间中pod运行状况
kubectl get pod (-n deafult )
#查看pod具体运行日志
kubectl describe mynginx
#删除pod
kubectl delete pod mynginx
# 查看Pod的运行日志
kubectl logs Pod名字
# 每个Pod - k8s都会分配一个ip
kubectl get pod -owide
# 使用Pod的ip+pod里面运行容器的端口
curl 192.168.169.136
apiVersion: v1
kind: Pod
metadata:labels:run: myappname: myappnamespace: default
spec:containers:- image: nginxname: mynginx- image: redisname: myredis
kubectl logs Pod名称
4、Deployment:自愈、扩缩容
控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
# 自愈能力、故障转移
kubectl create deployment mytomcat --image=tomcat:8.5.68 --replicas=3(副本数)
#获取
kubectl get deploy
#删除
kubectl delete deploy tomcat
#扩、缩容
kubectl scale deploy/my-dep --replicas=
kubectl edit deploy my-dep
##滚动更新
#升级
kubectl set image deployment/my-dep nginx=nginx:1.16.1 --record
#查看历史记录
kubectl rollout status deployment/my-dep
kubectl rollout history deployment/my-dep
#回退
kubectl rollout undo deployment/my-dep --to-revision=1
5、service:pod的服务发现与负载均衡
#获取svc
kubectl get pod --show-labels 查看pod标签
kubectl get service

#删除svc
kubectl delete service my-dep
#端口暴露提供负载均衡。
kubectl expose deploy my-dep --port=8000 (svc端口) --target-port=80(pod端口) --type=ClusterIP(集群内部的访问) / --type=NodePort (集群外也可以访问)
域名规则:服务名.所在名称空间.svc
my-dep.default.svc
6、 ingress:svc的统一网关入口
ingress是一种通过http协议暴露kubernetes内部服务的api对象,即充当Edge Router边界路由器的角色对外基于七层的负载均衡调度机制,能够提供以下几个功能:
负载均衡,将请求自动负载均衡到后端的Pod上;
SSL加密,客户端到Ingress Controller为https加密,到后端Pod为明文的http;
基于名称的虚拟主机,提供基于域名或URI更灵活的路由方式
kubectl get
kubectl discribe pod name
nfs
pv 持久卷
pvc 动态、静态创建持久卷声明
创建配置集configmap
kubectl create cm redis-conf --from-file=redis.conf
kubesphere
默认存储类型动态供用。nfs
https://registry.hub.docker.com/_/mysql
应用仓库:
helm.sh
https://charts.bitnami.com/bitnami
ruoyi-cloud
https://gitee.com/zhangmrit/ruoyi-cloud/blob/nacos/doc/ruoyi-cloud.png
ideal.exe
https://gitee.com/leifengyang/RuoYi-Cloud
nacos 系统部署配置
https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html
部署应用
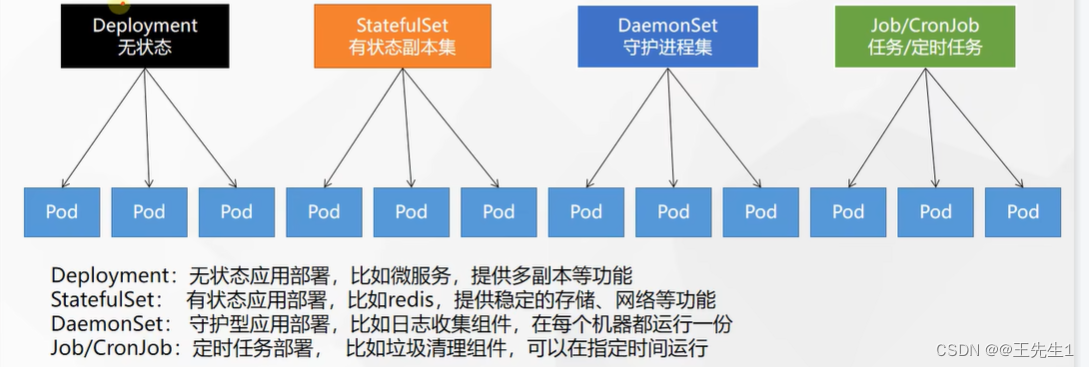
1、应用的部署方式(无状态、有状态、守护进程集)
2、应用的数据挂载(存储:数据、配置文件)
3、应用的可访问性(svc:nodeport、clusterport)
微服务上云,
中间件:mysql库迁移,redis部署。
nacos集群部署(有状态服务部署stateful)
ping 域名 域名规则:服务名.所在名称空间.svc 集群
dockerfile:
FROM 镜像
LABEL 标签VOLUME 卷挂载目录
COPY target/*.jar /home/appname.jar
ENV 参数(动态指定配置文件中的值)key="value"
#ENV ARAMS="--server.port=8080 --spring.profiles.active=prod --spring.cloud.nacos.discovery.server-addr=his-nacos.his:8848 --spring.cloud.nacos.config.server-addr=his-nacos.his:8848 --spring.cloud.nacos.config.namespace=prod --spring.cloud.nacos.config.file-extension=yml"EXPOSE 暴露端口
RUN ["" , "", "容器启动命令"]
微服务模块制作镜像
打包:maven打成可执行jar,上传到服务器
制作镜像:根据Dockerfile生成指定镜像
docker build -t name:version -f Dockerfile .
推送镜像:将镜像推送给docker hub
docker logindocker tag docker pushdocker pull
应用部署:
nginx配置文件 : server_host _;
● npm install --registry=https://registry.npm.taobao.org 安装项目依赖
● npm run build 对项目打包,
● 打包完成后把 .nuxt ,static, nuxt.config.js, package.json 这四个关键文件复制到 node 环境。先npm install再使用npm run start 即可运行
存活检查:健康检查器–添加容器就绪检查–存活检查(探针:请求命令)
网络访问:
生产环境与开发环境配置分离。
java打包编译:
mvn clean package -Dmaven.test.skip=true ##清除old包,跳过测试。
mvn -o -Dmaven.test.skip=true -gs pwd/configuration/settings.xml clean package
构建镜像:

openssl x509 -in api.crt -text -noout
go 中文社区下载,解压,配置环境变量
git clone https://github.com/kubernetes/kubernetes.gits
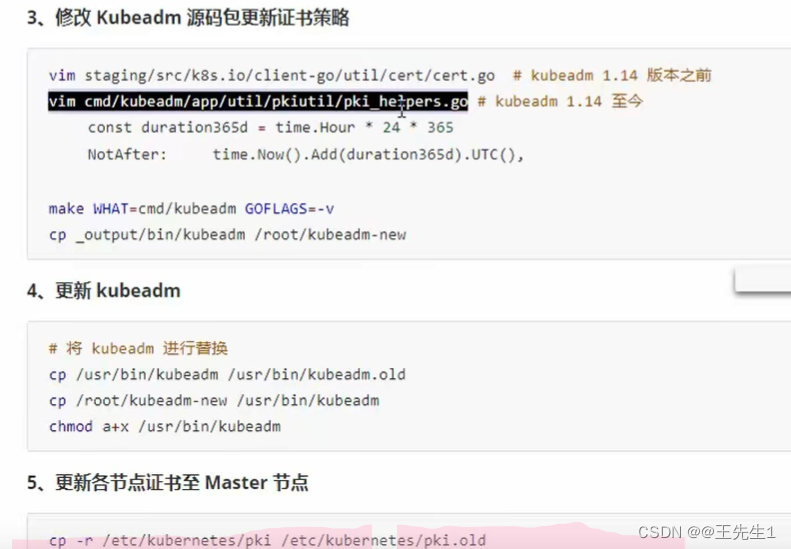
kubeadm version
切换版本
git checkout -b remotes/origin/release-1.15.1 v1.15.1


![[保研/考研机试] KY11 二叉树遍历 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/7caeb35fef9748e088f020f524d4b9f4.png)