目录
🐳今日良言:不悲伤 不彷徨 有风听风 有雨看雨
🐇一、简介
🐇二、相关代码
🐼1.线程池代码
🐼2.自定义实现线程池
🐇三、ThreadPoolExecutor类
🐳今日良言:不悲伤 不彷徨 有风听风 有雨看雨

🐇一、简介
首先来介绍一下什么是线程池,线程池是一种利用池化技术思想来实现的线程管理技术,主要是为了复用线程、便利地管理线程和任务并将线程的创建和任务的执行解耦开来。我们可以创建线程池来复用已经创建的线程来降低频繁创建和销毁线程所带来的资源消耗。在JAVA中主要是通过java.util.concurrent包中的ThreadPoolExecutor类来实现线程池 。
🐇二、相关代码
🐼1.线程池代码
这里就是创造出一个10个线程的线程池,然后就可以随机安排这些线程完成任务了。
线程池提供了一个重要的方法 submit 可以给线程池提交若干个任务。

submit的参数是一个Runnable,用来描述这些线程要执行的任务是什么。
线程池中的线程都是前台线程,前台线程会阻止进程结束,也就是说,运行程序之后,main线程结束了,但是整个进程没有结束。

当前是往线程池里放了 1000 个任务,1000 个任务就是由这 10 个线程来平均分配一下,差不多是一人执行 100个,但是这里并非是严格的平均,可能有的多一个有的少一个都正常。(每个线程都执行完一个任务之后,再立即取下一个任务...由于每个任务执行时间都差不多,因此每个线程做的任务数量就差不多)
上述代码涉及到变量捕获

这里的 i 是主线程里的局部变量(在主线程的栈上),随着主线程的代码执行结束就销毁了,但是,很可能这里的 for 循环已经执行完了,当前 run 的任务在线程池里还没有排到,此时 i 就已经要销毁了。这里的 run 方法属于 Runnable ,这个方法的执行时机并不是立刻执行,而是在未来的某个时间点(后续在线程池的队列中排到了) 才会执行,为了避免作用域的差异,导致执行 run 方法的时候,i 已经销毁了,于是就有了变量捕获,也就是让 run 方法把主线程的 i 往当前 run 方法的栈上拷贝一份(在定义 run 方法的时候了,把当前 i 的值记住,后续执行 run 的时候,就创建一个也叫做 i 的局部变量,并且把这个值给赋值过去)。
在Java 中,对于变量捕获,做了一些额外的要求,在JDK 1.8之前,要求变量捕获只能捕获 final 修饰的变量,后来发现,这样太麻烦了,于是,在 JDK 1.8 开始,发送了一点标准,要求不一定非得待 final 关键字,只要代码中没有修改过这个变量,也可以捕获。
在上述代码中,i 是被修改的,因此不能捕获,但是 n 没有被修改,所以可以被捕获。
接下来,介绍一下几种不同的线程池:
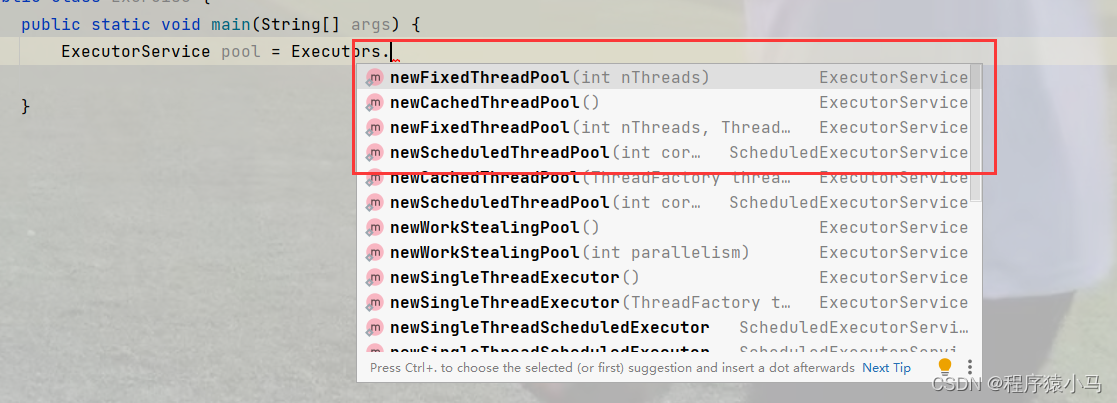
new FixedThreadPool 创建固定线程数的线程池。
newCachedThreadPool 线程数量是动态变化的,任务多了就多创建几个线程,任务少了
就少创建几个。
newScheduledThreadPool 类似于定时器,让任务延时执行。
newSingleThreadExecutor 线程池里只有一个线程。
上述这些线程池,本质上都是通过包装 ThreadPoolExecutor 来实现的,这个线程池用起来比较麻烦,所以提供了工厂类,让我们使用更方便,ThreadPoolExecutor 提供的功能更为强大,后面会详细介绍。
🐼2.自定义实现线程池
自定义实现线程池代码如下:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;class MyThreadPool {// 阻塞队列private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();// 若干个工作线程// n表示线程的数量public MyThreadPool(int n) {for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {while (true) {try {// 从阻塞队列中取出然后执行Runnable runnable = queue.take();runnable.run();} catch (InterruptedException e) {throw new RuntimeException(e);}}});t.start();}}// 注册任务给线程池public void submit(Runnable runnable) {try {queue.put(runnable);} catch (InterruptedException e) {throw new RuntimeException(e);}}
}
public class Exercise{public static void main(String[] args) {MyThreadPool myThreadPool = new MyThreadPool(10);for (int i = 0; i < 1000; i++) {int n = i;myThreadPool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello:"+n);}});}}
}🐇三、ThreadPoolExecutor类
最后,介绍一下ThreadPoolExecutor 里面的参数,如下图:
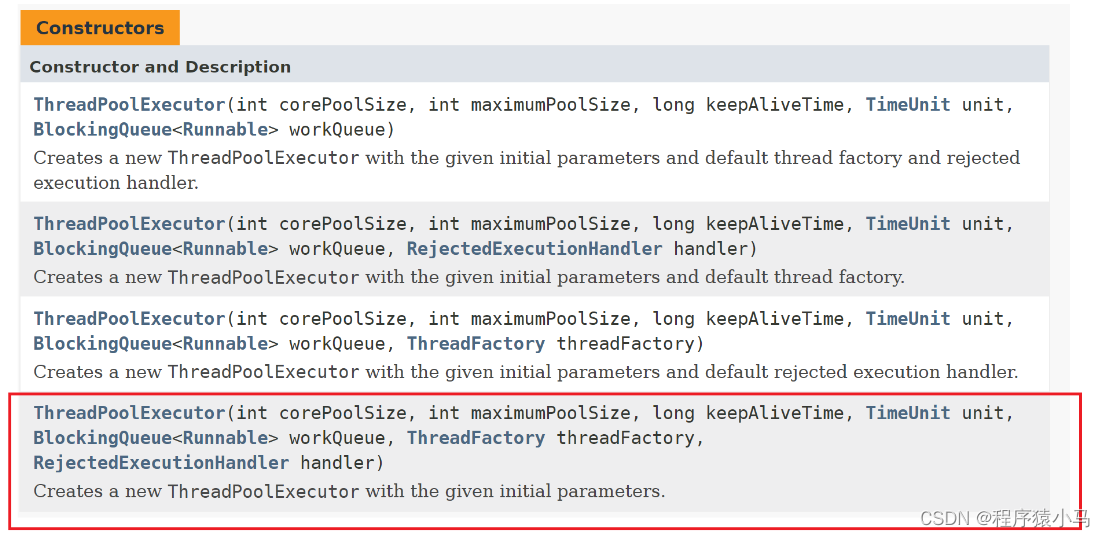
1)int corePoolSize
核心线程数
2)int maximumPoolSize
最大线程数
ThreadPoolExecutor 相当于是把里面的线程分成了两类,一类是核心线程,一类是临时线程,核心线程相当于是正式工,临时线程相当于是临时工,这二者之和就是最大线程数。
如果任务多,需要创建更多的线程,但是,一个程序的任务不一定始终都有很多,有时候多,有时候少,如果现在任务少了,线程还那么多,就非常不合适了,因此,就需要对现有的线程进行一定的淘汰,整体的淘汰策略是:核心线程保底,临时线程动态调节。
在实际开发的时候,线程池的线程数设置成多少比较合适呢?
实际上,这里不应该回答出具体的数字,在实际开发中,线程池的线程数设置需要根据具体情况进行调整,一般来说,应该设置为CPU核心数的两倍到四倍之间,如果线程数过少,则导致任务等待时间过长,而如果线程数过多,会导致系统资源浪费。如果任务是IO密集型的,那么可以适当的增加线程数,如果任务是CPU密集型的,则可以适当的减少线程数。
3)long keepAliveTime
临时线程的最大空闲时间,超出这个时间,临时线程就会被销毁了。
也就是临时工的最大摸鱼时间。
4)TimeUnit unit
时间单位(s,ms,分钟...)
5)BlockingQueue<Runnable> workQueue
线程池的任务队列
此处使用的是阻塞队列,每个线程都是在不停的尝试take,如果有任务,就take成功,没有就阻塞。
6)ThreadFactory threadFactory
用于创建线程,线程池是需要创建线程的
7)RejectedExecutionHandler handler
描述了线程池的“拒绝策略”,也是一个特殊的对象,描述了当线程池任务队列满了,如果继续添加任务会有什么样的行为。
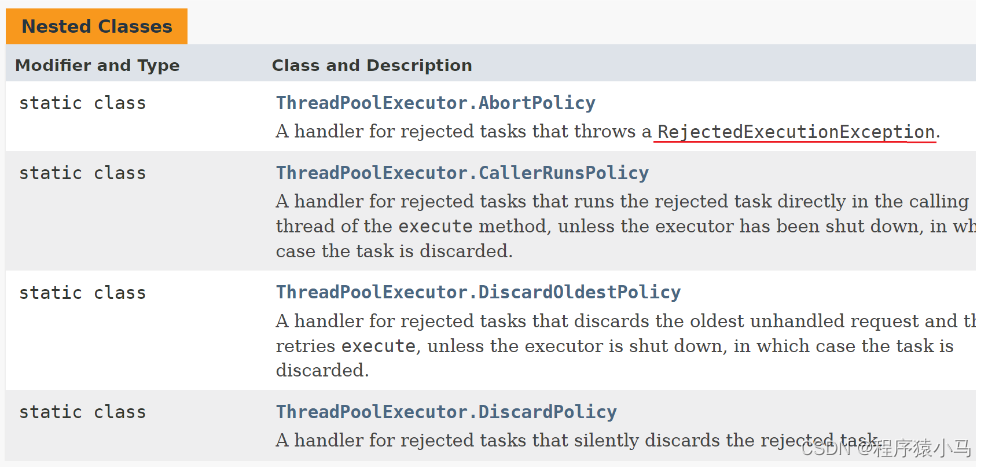
标准库提供了四个拒绝策略,如下图:
第一个拒绝策略
如果任务太多,任务队列满了,就直接抛出异常。
第二个拒绝策略
如果任务太多,任务队列满了,多出来的任务,谁加的谁负责执行。
第三个拒绝策略
如果任务太多,任务队列满了,丢弃最早的任务。
第四个拒绝策略
如果任务太多,任务队列满了,丢弃最新的任务。
以上就是本篇博客的所有内容了,望有所帮助~





![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://img-blog.csdnimg.cn/7282dce02ace4c1bbffedde6c6a817e3.png)