目录儿
- 1 C++是如何工作的
- 1.1 预处理语句
- 1.2 include
- 1.3 main()
- 1.4 编译
- 单独编译
- 项目编译
- 1.5 链接
- 2 定义和调用函数
- 3 编译器如何工作
- 3.1 编译
- 3.1.1 引入头文件
- 系统头文件
- 自定义头文件
- 3.1.2 自定义类型
- 3.1.3 条件判断
- 拓展: 汇编
- 3.2 链接
- 3.2.1 起始函数
- 3.2.2 被调用的函数
- 3.3 总结,编译和链接的区别
1 C++是如何工作的
工具:Visual Studio
1.1 预处理语句
在.cpp源文件中,所有#字符开头的语句为预处理语句
例如在下面的 Hello World 程序中
#include<iostream>int main() {std::cout <"Hello World!"<std::endl;std::cin.get();
}
#include<iostream>就是一个预处理语句(pre-process statement),编译器在加载源文件的时候,识别到#开头的语句,会优先处理这个语句,所以称为预处理语句。
注意:预处理语句是在 编译器加载源文件的时候处理的,那个时候还没有发生编译动作。
1.2 include
include关键字的含义就是找到<xxx>里面指定名称的文件,然后把文件里面的内容拷贝到当前文件,以供调用;
这个被导入的文件称为头文件;
1.3 main()
main()函数是程序的入口,计算机从main()函数开始运行程序,每个程序都要有一个main()函数;
main()函数的返回值是int类型,但是在 Hello World 程序中我们没有返回任何值,这是因为main()函数比较特殊,如果没有显式返回一个int值,他会默认返回0;
1.4 编译
单独编译
当写好了一个源文件,就可以对其进行编译操作,在Visual Studio上直接按快捷键ctrl + F7,或者点击编译按钮执行编译
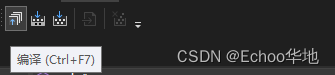
编译结果在输出窗口就能看到:
注意,此时我们是针对一个源文件进行单独编译,而不是编译整个项目。
每次编译需要指定规则和目标平台
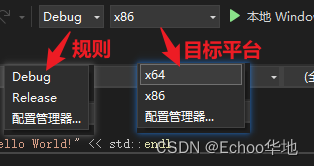
- 规则:
默认分为Debug和Release,代表着编译代码时按照设置选择的的规则设置进行编译,这些规则是可以自行设置的,但一般都用默认设置。比如在Debug规则的默认设置中,不会对程序进行优化
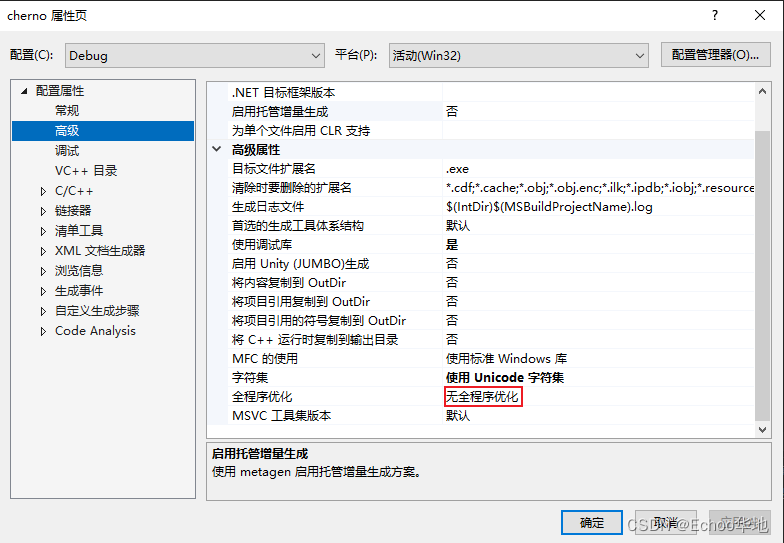
在Release规则的默认设置中,则会对程序进行链接优化
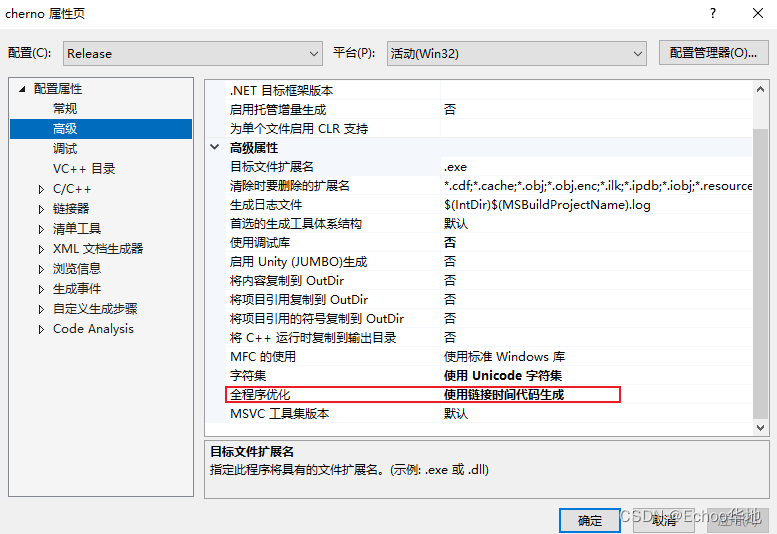
- 目标平台:
意思就是你这个代码编译后是用在哪个平台的,比如x86/windows64位、x64/windows32位或者是Android等移动平台(因为C++是不能跨平台运行的,所以不同的目标平台编译出来的二进制码不一样,不像Java)
打开项目目录可以看到,在不同的规则下编译生成的文件分别放在不同的目录下面:
在目录里面可以看到.cpp文件编译生成的.obj文件

打开看, 里面的内容都是二进制机器码
项目编译
在资源文件窗口中,项目名称→右键→生成,这也是一个编译操作,但此时是编译整个项目;
它会把项目中的每个.cpp文件编译成.obj文件,然后再把这些.obj文件链接成一个程序比如.exe程序;
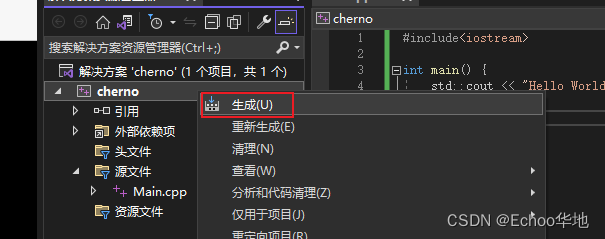
在输出窗口可以看到生成了一个.exe文件
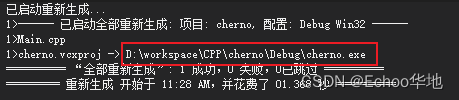
打开对应的目录就能看到

1.5 链接
链接比较复杂,大概就是一个C++项目通常都包含这很多个源文件,而编译后每一个源文件对应地都会生成一个.obj二进制码文件,然后链接的作用就是把这些二进制码文件链接起来构成一个完整的项目。
2 定义和调用函数
写在同一个文件中:
#include<iostream>void Log(const char* message) {std::cout << message << std::endl;
}int main() {Log("Hello World!");std::cin.get();
}
写在不同的文件中:

Log.cpp
#include<iostream>void Log(const char* message) {std::cout << message << std::endl;
}
Main.cpp
#include<iostream>void Log(const char* message);
//void Log(const char*); // 声明函数时可以忽略参数名int main() {Log("Hello World!");std::cin.get();
}
想要在Main.cpp文件中调用Log函数,必须先声明,声明函数和定义函数的区别就是一个有方法体,一个没有方法体;
这里注意的点是,编译器在编译单个
Main.cpp这个源代码文件的时候,并不会去检查这个声明的函数是否真实存在,而且编译单个文件的时候不会对编译文件进行链接;
但是当运行或者编译整个项目的时候,也就是进行文件链接的时候,如果声明的函数不存在,就会报错:

3 编译器如何工作
首先需要知道,编译分为两个阶段: 编译 + 链接
3.1 编译
不经过设置时, 执行编译默认会直接编译成.obj文件, 直接就是二进制码了
为了能够搞清楚从 源代码 → 二进制码 的过程中发生了什么, 我们接下来就先不直接编译成.obj文件
而是先把编译过程中预处理后产生的内容输出成文件, 看看预处理都处理了啥.
3.1.1 引入头文件
前面说过,编译器处理#include<xxx>这个语句就是把对应的xxx头文件里面的内容copy到当前文件中#include语句所在的地方
下面来证实一下
首先打开项目属性:
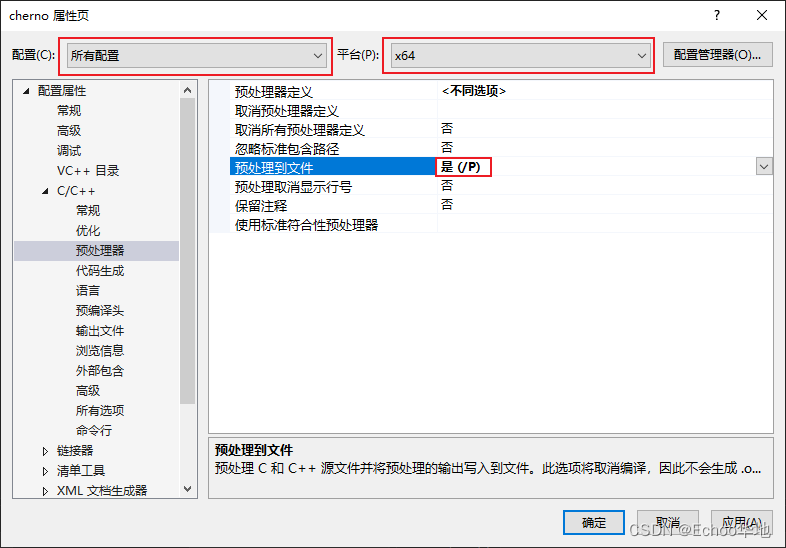
这一步是为了让编译器在预编译后把内容输出成一个文件, 这样我们就可以看到预编译的内容了, 注意这个设置也是精确到配合和平台的, 选择所有配置和自己的操作系统平台就行;
注意: 修改了输出预编译文件后, 编译器就不会输出
.obj文件, 所以做完实验就要把它改回去!!
系统头文件
在Main.cpp中, 我们引入了iostream头文件
#include<iostream>int main() {std::cout << "Hello World!" << std::endl;std::cin.get();
}
编译一下, 生成的.i文件就是预编译文件
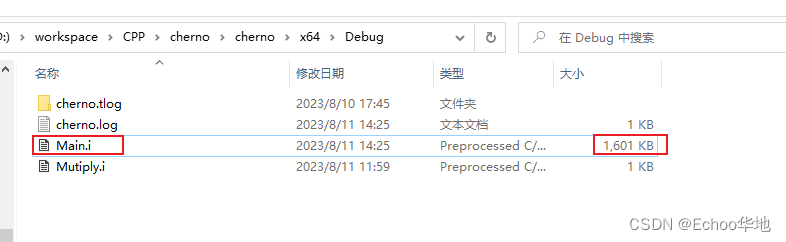
可以发现这个文件有1.6M大, 我只写了几行代码
直接打开看
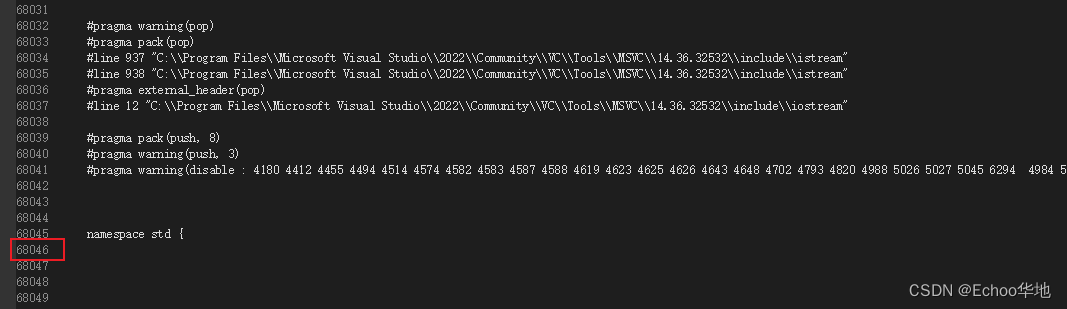
会发现这个文件有6万多行, 这些内容就是从iostream头文件中copy过来的, 所以整个文件很大
这就印证了#inclued引入语句的作用.
自定义头文件
下面我们要编译这个Mutiply.cpp
int Mutiply(int a, int b) {int result = a * b;return result;
可以看到这个函数是缺少了一个}的, 故意的
接下来创建一个头文件EndBrace.h
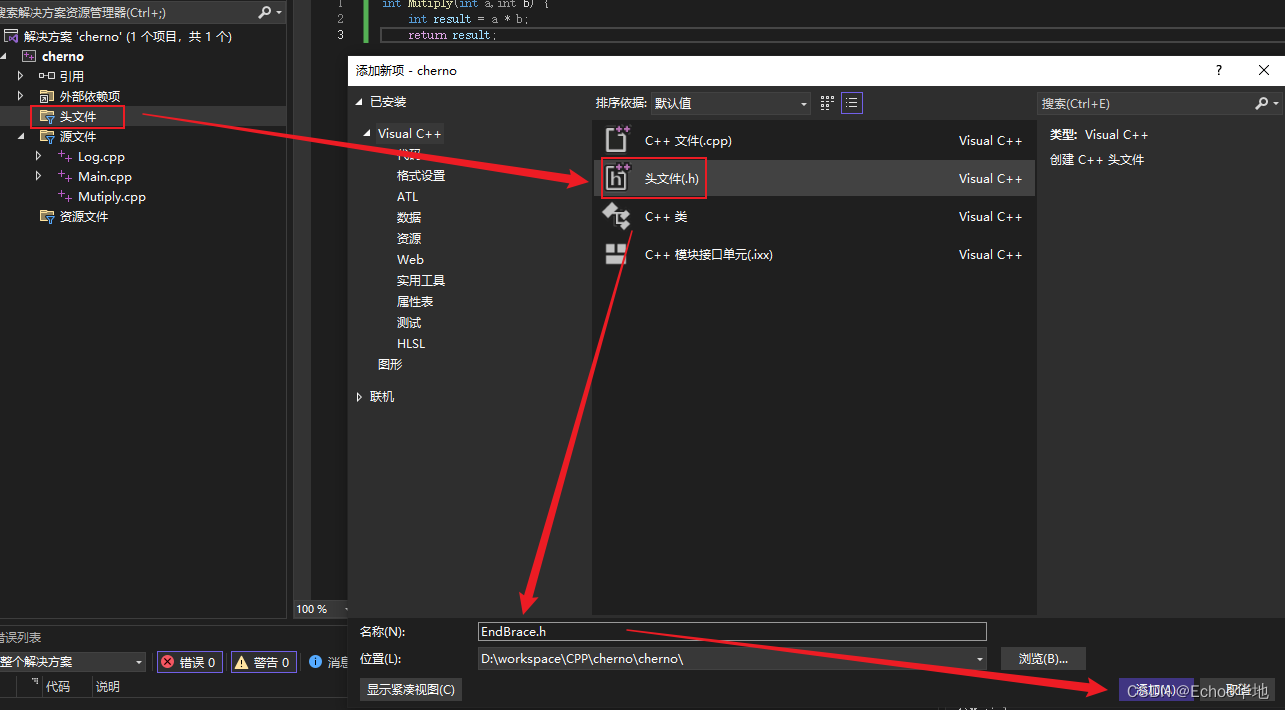
头文件里面的内容就是一个}
}
接下来在Mutiply.cpp中引入这个EndBrace.h头文件
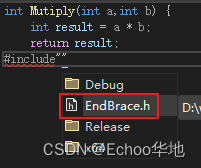
引入后Mutiply.cpp内容如下:
int Mutiply(int a,int b) {int result = a * b;return result;
#include"EndBrace.h"
好,接下来编译一下这个Mutiply.cpp源文件
在项目对应目录中可以看到生成了一个Mutiply.i文件, 这个就是预编译生成的文件
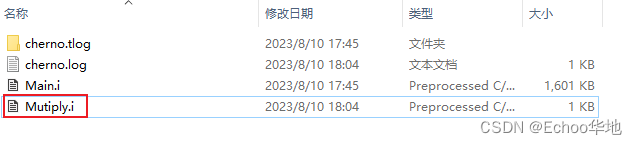
直接打开看内容
#line 1 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"int Mutiply(int a,int b) {int result = a * b;return result;#line 1 "D:\\workspace\\CPP\\cherno\\cherno\\EndBrace.h"
}
#line 5 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
忽略那些#line语句, 可以看到EndBrace.h头文件中的}被复制到了Mutiply.cpp中
注意,在c++中,引入头文件有两种方式:
#include<>这个语法用于引入系统头文件, 这种引入方式下预处理器会在标准系统目录中搜索这些文件。例如引入iostream头文件,可以使用#include <iostream>。#include ""语法用于引入用户定义的头文件, 这种引入方式下预处理器会首先在当前目录中搜索这些文件,如果没有找到,则在标准系统目录中搜索。例如,如果当前目录中有一个名为myheader.h的头文件,则可以使用#include "myheader.h"将其包含到程序中。
3.1.2 自定义类型
还是在Mutiply.cpp中做修改,
#define ECHOO intECHOO Mutiply(int a, int b) {ECHOO result = a * b;return result;
}
这里我自定义了一个ECHOO类型, 实际上是一个int类型
然后我在Mutiply定义中用了这个ECHOO类型代替原来的int
接下来编译看一下预编译生成的文件内容:
#line 1 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
int Mutiply(int a, int b) {int result = a * b;return result;
}
编译器自动把ECHOO替换成了它的实际类型int,
所以说#define实际上是自定义别名, 用一个别名代替实际的类型或者字符,符号
这也是C++灵活的地方,可以给各种类型, 符号自定义别名
再改一下, 用ECHOO代替Hello
#define ECHOO HelloECHOO Mutiply(int a, int b) {ECHOO result = a * b;return result;
}
预编译:
#line 1 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
Hello Mutiply(int a, int b) {Hello result = a * b;return result;
}
有点意思
3.1.3 条件判断
改一下Mutiply.cpp, 用#if语句来做条件判断
#if 0
int MutiplyOne(int a, int b) {int result = a * b;return result;//#include "EndBrace.h"
}
#endif // 0#if 1
int MutiplyTwo(int a, int b) {int result = a * b;return result;//#include "EndBrace.h"
}
#endif // 1
函数MutiplyOne用#if 0 和 #endif包起来了
函数MutiplyTwo用#if 1 和 #endif包起来了
预编译:
#line 1 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
#line 8 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
int MutiplyTwo(int a, int b) {int result = a * b;return result;
}
#line 17 "D:\\workspace\\CPP\\cherno\\cherno\\Mutiply.cpp"
函数MutiplyOne不能被预编译
函数MutiplyTwo能正常被预编译
非常明显, 是因为判断条件的原因
我们可以通过#if condition这个语句来动态地禁用 / 启用某一段代码, 非常灵活
有点儿意思
拓展: 汇编
通过Visual Studio可以输出汇编文件, 设置一下汇编程序输出
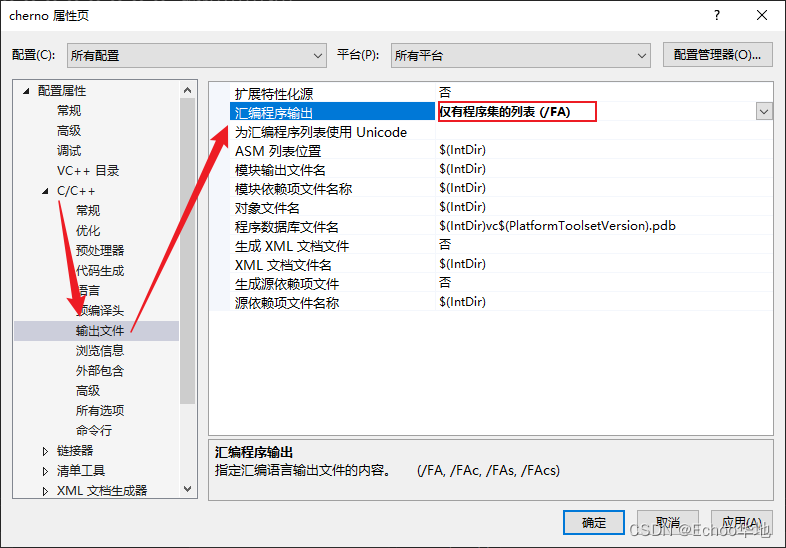
接下来编译Mutiply.cpp:
int MutiplyOne(int a, int b) {int result = a * b;return result;//#include "EndBrace.h"
}
在项目目录中生成的.asm文件就是生成的汇编程序文件

打开可以看到一条一条的汇编指令,
; Listing generated by Microsoft (R) Optimizing Compiler Version 19.36.32537.0 include listing.incINCLUDELIB MSVCRTD
INCLUDELIB OLDNAMESmsvcjmc SEGMENT
__B1702CDC_Mutiply@cpp DB 01H
msvcjmc ENDS
PUBLIC ?MutiplyOne@@YAHHH@Z ; MutiplyOne
PUBLIC __JustMyCode_Default
EXTRN _RTC_InitBase:PROC
EXTRN _RTC_Shutdown:PROC
EXTRN __CheckForDebuggerJustMyCode:PROC
; COMDAT pdata
pdata SEGMENT
$pdata$?MutiplyOne@@YAHHH@Z DD imagerel $LN3DD imagerel $LN3+63DD imagerel $unwind$?MutiplyOne@@YAHHH@Z
pdata ENDS
; COMDAT rtc$TMZ
rtc$TMZ SEGMENT
_RTC_Shutdown.rtc$TMZ DQ FLAT:_RTC_Shutdown
rtc$TMZ ENDS
; COMDAT rtc$IMZ
rtc$IMZ SEGMENT
_RTC_InitBase.rtc$IMZ DQ FLAT:_RTC_InitBase
rtc$IMZ ENDS
; COMDAT xdata
xdata SEGMENT
$unwind$?MutiplyOne@@YAHHH@Z DD 025051601HDD 01112316HDD 0700a0021HDD 05009H
xdata ENDS
; Function compile flags: /Odt
; COMDAT __JustMyCode_Default
_TEXT SEGMENT
__JustMyCode_Default PROC ; COMDATret 0
__JustMyCode_Default ENDP
_TEXT ENDS
; Function compile flags: /Odtp /RTCsu /ZI
; COMDAT ?MutiplyOne@@YAHHH@Z
_TEXT SEGMENT
result$ = 4
a$ = 256
b$ = 264
?MutiplyOne@@YAHHH@Z PROC ; MutiplyOne, COMDAT
; File D:\workspace\CPP\cherno\cherno\Mutiply.cpp
; Line 2
$LN3:mov DWORD PTR [rsp+16], edxmov DWORD PTR [rsp+8], ecxpush rbppush rdisub rsp, 264 ; 00000108Hlea rbp, QWORD PTR [rsp+32]lea rcx, OFFSET FLAT:__B1702CDC_Mutiply@cppcall __CheckForDebuggerJustMyCode
; Line 3mov eax, DWORD PTR a$[rbp]imul eax, DWORD PTR b$[rbp]mov DWORD PTR result$[rbp], eax
; Line 4mov eax, DWORD PTR result$[rbp]
; Line 6lea rsp, QWORD PTR [rbp+232]pop rdipop rbpret 0
?MutiplyOne@@YAHHH@Z ENDP ; MutiplyOne
_TEXT ENDS
END
看汇编指令在某些需要极致性能优化的时候会很有用, 但一般很少没多少人会这样做.
3.2 链接
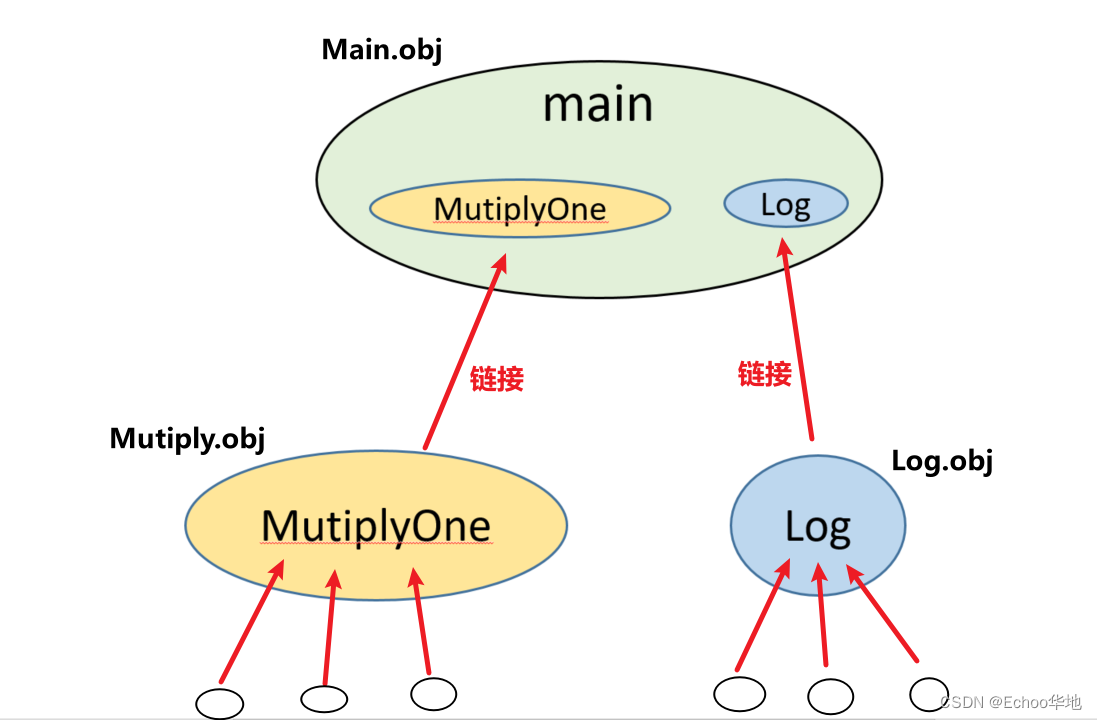
当源文件被编译成一个个.obj文件的时候, 它们实际上还是一个一个独立的文件, 彼此直接没有关系
链接就是把所有.obj文件链接在一起,形成一个完整的程序
而这个程序必须有一个起始函数,如果没有特殊指定,这个起始函数默认是main函数!
3.2.1 起始函数
所以当一个项目是没有main函数的时候,单独编译文件不会报错,但是build或者运行项目的时候会报错
例:
当前项目中只有两个源文件,都不包含main函数

单独编译这两个源文件都没问题
但是当我生成整个项目时,发生了报错LNK1120
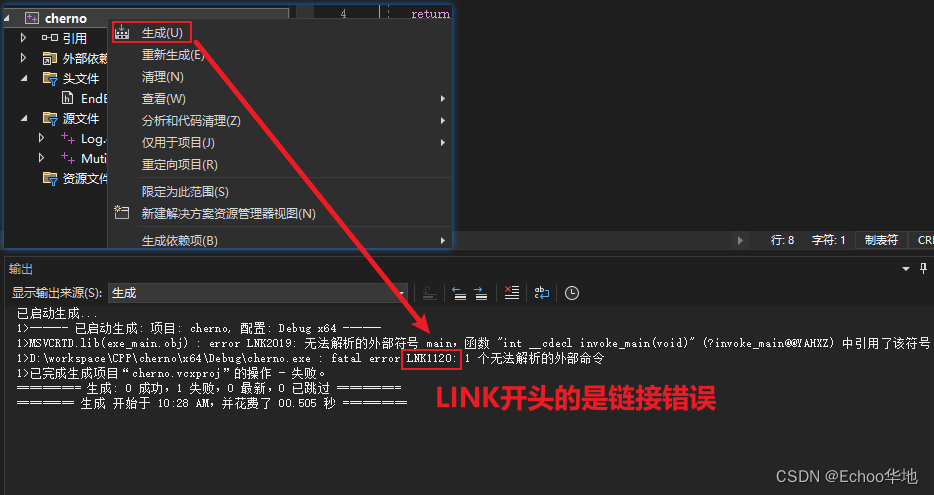
LNK 开头的错误是链接阶段发生的错误;
C 开头的错误是编译阶段发生的错误,比如语法错误;
现在我加一个源文件,里面声明了MutiplyOne和Log函数,定义了main函数
并且在main函数中调用MutiplyOne和Log函数
#include<iostream>int MutiplyOne(int a, int b);
void Log(const char* message);int main() {Log("Hello World!");std::cout << MutiplyOne(5, 18) << std::endl;std::cin.get();
}
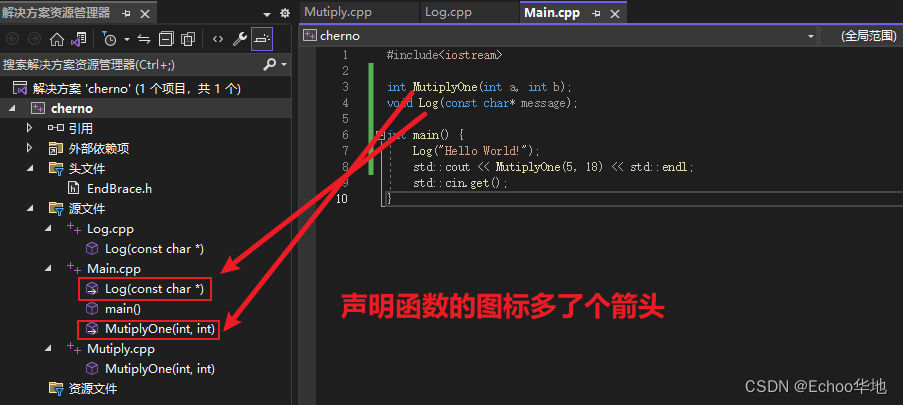
直接运行项目,成功
Hello World!
90
这就代表着程序编译成功,链接器也成功找到了程序的起始函数,并成功把相关的函数找到、链接起来了。
3.2.2 被调用的函数
如果被调用的函数没有在当前源文件中声明
#include<iostream>int MutiplyOne(int a, int b);
//void Log(const char* message);int main() {Log("Hello World!");std::cout << MutiplyOne(5, 18) << std::endl;std::cin.get();
}
会报编译错误,因为这个属于语法错误:

如果被调用的函数不存在
会报链接错误:

所以很明显,链接的作用是把以起始函数为根节点,所有被调用到的函数链接起来,形成一整条调用链(或者说一整棵调用树)
如果想要指定其他函数作为程序的起始函数,可以通过链接器的高级设置指定:
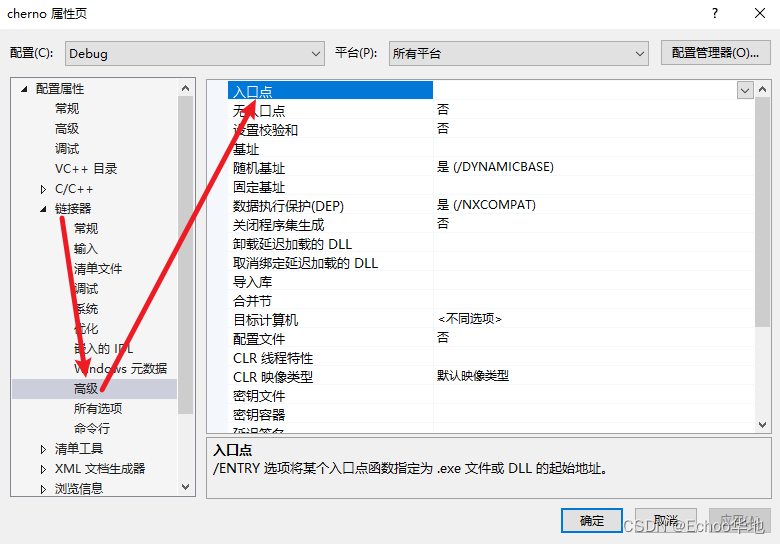
3.3 总结,编译和链接的区别
编译:是先对源文件进行预处理,引入头文件,把头文件内容copy到源文件中,然后再把这些源文件编译成.obj或其他格式的二进制文件
链接:是把编译好的.obj文件里面相互调用的函数链接起来,形成一个完整的程序
![[附源码]计算机毕业设计-JAVA火车票订票管理系统-springboot-论-文-ppt](https://img-blog.csdnimg.cn/293ace0bf2804103ad2fb9476bd207ac.png)