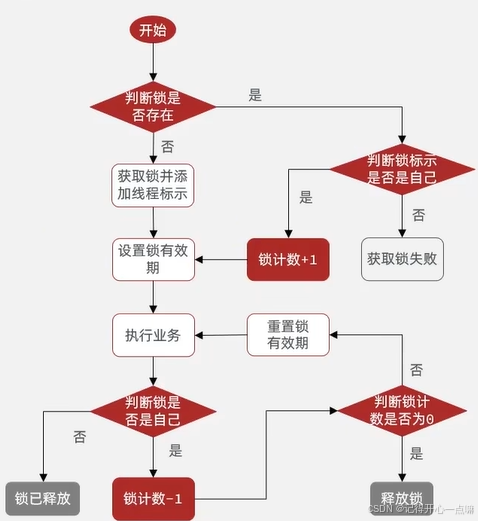
基于 NodeJs 一个后端接口的创建过程及其规范
一个接口的诞生:
流程简述:
- 首先通过
router-schema定义接口入参规则; - 然后在
router中定义接口; - 调用接口, 会经过一个
controller中间层处理业务逻辑,业务逻辑中的数据则是通过调用service来获取所需的数据; service则负责对数据的处理,中会封装一些对数据库增删改查的方法。
一、 router-schema: 请求规则
router-schema 中配置了每个接口所需的字段、类型、是否必填等信息。可以有效的规避掉客户端的一些无效请求,比如,下面这个接口中入参没有 ‘proj_key’ 的话,就无法通过校验会直接返回参数不合法的提示,节省了服务器资源。
'/api/project': {get: {query: {type: 'object',properties: { proj_key: { type: 'string' }, ...},required: ['proj_key']....}}}
他的配置需要遵循JSON schama 的规范;
而校验的是否符合规范的过程是由中间件去实现,本项目中通过 elpis-core 去实现,大概的思路就是:
- router-schema 中的配置会被挂载到全局的 app 实例上,可以通过
app.routerSchema['/api/project']去访问到每个接口的 schema 规则对象; - 然后借助一个中间件去实现校验:(如下是主要思路)
const Ajv = require('ajv'); // 需要安转ajv检验器const ajv = new Ajv();const $schema = "http://json-schema.org/draft-07/schema#" // 告知校验器(ajv),用什么规则去校验 const schema = app.routerSchema[path]schema.headers.$schema = $schema;let validate = ajv.compile(schema.query) // 读取path接口的schema,及其query的配置let valid = validate(query) // 校验数据
schema 配置文件示例:
--| router-schema--| project.js// 遵循 JSON schema 规范
module.exports = {'/api/project': {get: {query: {type: 'object',properties: {proj_key: {type: 'string'}},required: ['proj_key']}}},'/api/project/model_list': {get: {}}
}
JSON Schema 中文文档
二、 定义路由
使用koa-router 定义接口名称, 并传入一个 controller 中间件处理业务逻辑。
module.exports = (app, router) => {const { project: projectController } = app.controllerrouter.get('/api/project/list', projectController.getList.bind(projectController))router.get('/api/project/model_list', projectController.getModelList.bind(projectController))
}
三、 处理业务逻辑
对数据处理无非就是增删改查,而对数据库增删改查的方法是不变,而且是会被反复用到的。每个接口只是对增删改查的不同组合,所以为了保留这些方法的原子性。特地从接口和数据之间抽出一个中间层,用来处理不同接口的业务逻辑。由此 controller 中间层应孕而生。
可以在其中处理入参,构造响应数据等操作:
module.exports = (app) => {const BaseController = require('./base')(app)return class ProjectController extends BaseController {/*** 获取当前 projectKey 对应模型下的项目列表 (如果无 projectKey, 全量获取)*/async getList(ctx) {const { proj_key: projKey } = ctx.request.query;const { project: projectService } = app.service;const projectList = projectService.getList({ projKey })// 构造关键数据 listconst dtoProjectList = projectList.map(item => {// console.log('item', item)const { modelKey, key, name, desc, homePage } = item;return { modelKey, key, name, desc, homePage }});this.success(ctx, dtoProjectList)}}
}
四、 处理数据
目前还没有接入数据库,暂时引入本地 js文件模拟。
module.exports = (app) => {const BaseService = require('./base')(app)const modelList = require('../../model/index.js')(app)return class ProjectService extends BaseService {/*** 获取统一模型下的项目列表 (如果无 projkey, 取全量 )*/getList({ projKey }) {return modelList.reduce((preList, modelItem) => {const { project } = modelItem;// 如果存在 projectList 则只去当前同模型下的项目, 不传的情况下则取全量.if (projKey && !project[projKey]) {return preList};for (const pKey in project) {preList.push(project[pKey])}return preList;}, [])}async getModelList() {return modelList}}
}
全文特别鸣谢: 抖音“哲玄前端”,《全栈实践课》
![[Java]泛型(一)泛型类](https://i-blog.csdnimg.cn/direct/1fce8e38730f4fd8a0a7687971655c26.png)