问题描述:
内存泄漏积累过多最终会导致内存溢出,当内存占用过大,进程会被killed掉。
解决过程:
在代码的运行阶段输出内存占用量,观察在哪一块存在内存剧烈增加或者显存异常变化的情况。但是在这个过程中要分级确认问题点,也即如果存在三个文件main.py、train.py、model.py。
在此种思路下,应该先在main.py中确定问题点,然后,从main.py中进入到train.py中,再次输出显存占用量,确定问题点在哪。随后,再从train.py中的问题点,进入到model.py中,再次确认。如果还有更深层次的调用,可以继续追溯下去。
import psutil
process = psutil.Process()
current_memory = process.memory_info().rss
print(f"0--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")
具体使用的代码
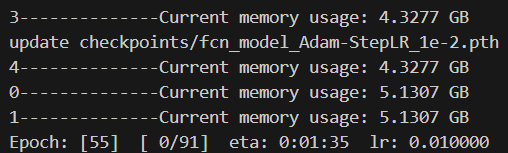
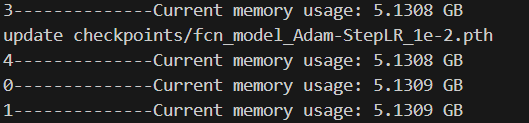
for epoch in range(start_epoch+1, args.epochs+1):process = psutil.Process()current_memory = process.memory_info().rssprint(f"0--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")count_step = (epoch-1)*len(train_loader) print(f"1--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch, count_step,writer,lr_scheduler,print_freq=args.print_freq)print(f"2--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")val_info = evaluate_vgg(model, epoch, val_loader, device, writer, num_classes=num_classes)print(f"3--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")with open(results_file, "a") as f:# 记录每个epoch对应的train_loss、lr以及验证集各指标 train_info = f"[epoch: {epoch}]\n" \f"train_loss: {mean_loss:.4f}\n" \f"lr: {lr:.6f}\n"f.write(train_info + val_info + "\n\n")save_vgg_file = {"model": model.state_dict(),"optimizer": optimizer.state_dict(),# "lr_scheduler": lr_scheduler.state_dict(),"epoch": epoch,"args": args}torch.save(save_vgg_file, 'checkpoints/fcn_model_Adam-StepLR_1e-2.pth')print(f"update checkpoints/fcn_model_Adam-StepLR_1e-2.pth")print(f"4--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")
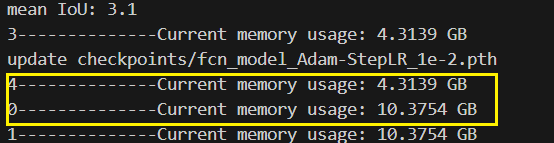
每个epoch训练完之后所占内存会不断增加,也就是说,每轮跑完之后会有冗余的数据一直在消耗内存。于是criterion、train_one_epoch、evaluate三个部分
criterion部分
Mem usage:5310 MiB
train_one_epoch部分
Mem usage:4439 MiB
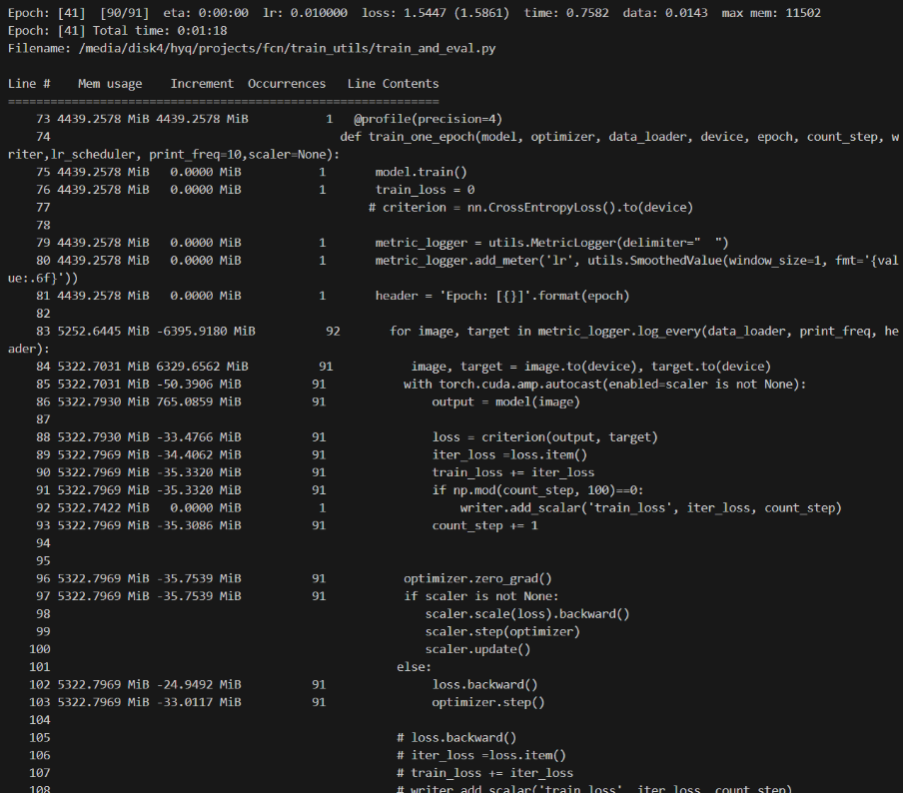
evaluate部分
Mem usage:10644
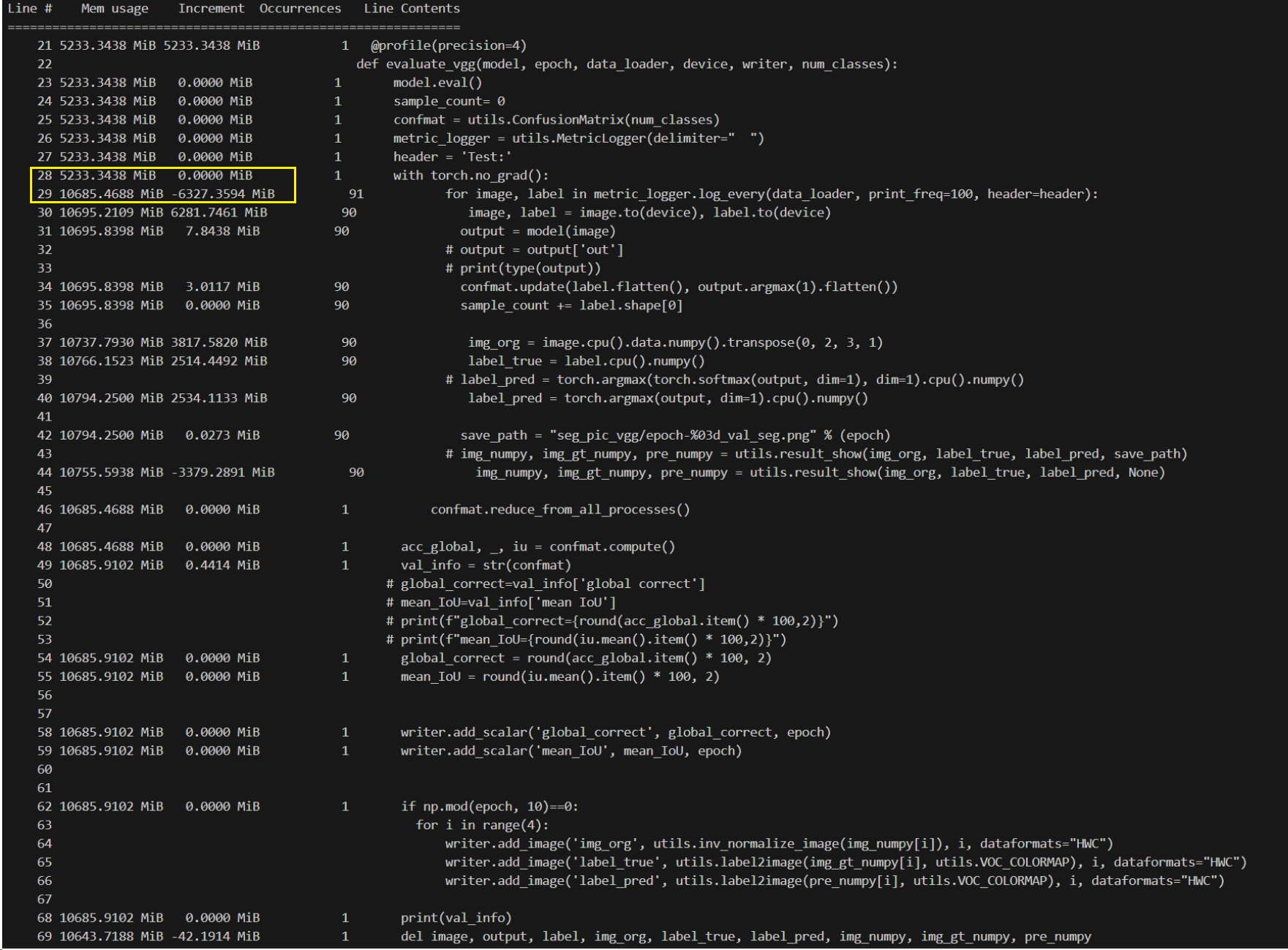
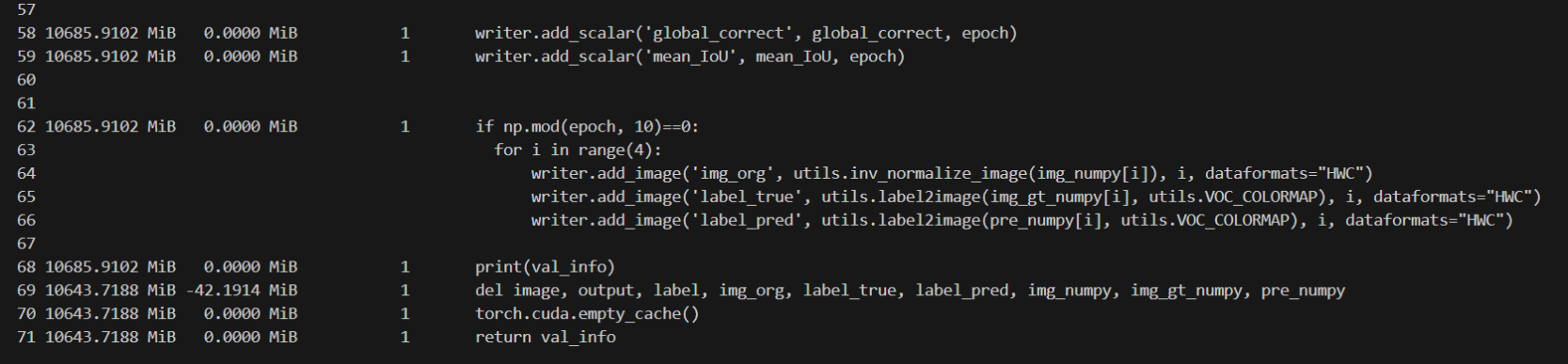
在evaluate部分可以看到,所占用内存突然增大,并且之后的代码也占用了大量内存,继续监控得知在下一个epoch中criterion部分占用内存也是16064MiB,由此推测出内存消耗在evaluate部分。
解决办法:
删除变量数据在for循环外,把暂时不用的可视化代码注释掉,发现占用内存变化很小
解决pytorch训练时的显存占用递增的问题
Pytorch训练过程中,显存(内存)爆炸解决方法
Python代码优化工具——memory_profiler





![[Mac软件]AutoCAD 2024 for Mac(cad2024) v2024.3.61.182中文版支持M1/M2/intel](https://img-blog.csdnimg.cn/img_convert/d6cc2c782509ca0d7d7207a1965850de.png)