流处理
批处理应用于有界数据流的处理,流处理则应用于无界数据流的处理。
有界数据流:输入数据有明确的开始和结束。
无界数据流:输入数据没有明确的开始和结束,或者说数据是无限的,数据通常会随着时间变化而更新。
在Flink中,应用程序由数据流组成,这些数据流可以经由用户自定义的算子进行转换。数据流最终形成有向图,这些图以一个或多个源(Source)开始,以一个或多个接收器(Sink)结束。
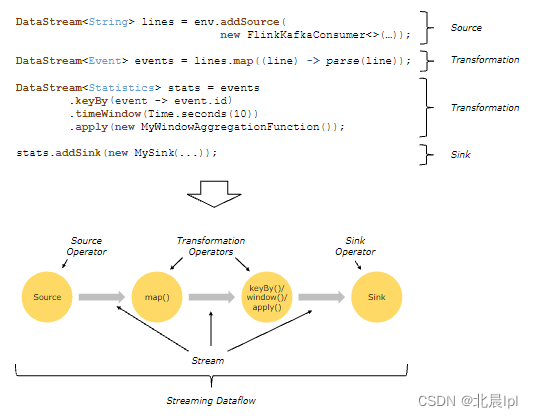
通常来说,转换(Transformation)与算子之间存在一对一的映射关系,但这并不是绝对的,一个转换也可以包含多个算子。
Flink可以处理来自数据流源(例如Kafka)的实时数据,同时也可以处理来自数据源的历史数据。
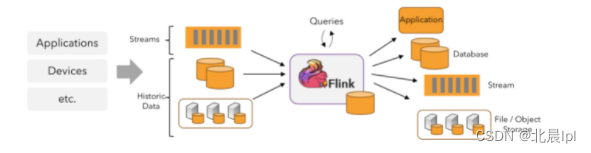
并行数据流
Flink中的程序本质上是并行和分布式的。在执行期间,流具有一个或多个流分区,每个算子都拥有一个或多个子任务。子任务之间彼此相互独立,在不同的线程、机器、或容器中执行。
子任务的数量就代表了该算子的并行度(parallelism),同一程序的不同算子可能会具有不同的并行度。
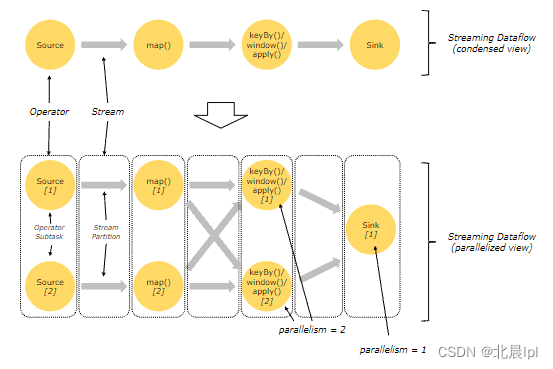
两个算子之间可以通过一对一或重新分发的方式传递数据。
-
一对一:该模式会保留元素的分区和排序。上图中Source到map()的过程就属于一对一
-
重新分发:
-
该模式会更改流的分区,上图中map()到keyBy()/window()的过程就属于重新分发
-
keyBy()-通过散列重新分区,broadcast()-广播,rebalance()-随即分发
-
及时流处理
对于大多数流应用程序来说,能够使用用于处理实时数据的相同代码重新处理历史数据,并无论如何都能产生确定性、一致性的结果,这是非常有价值的。
同等重要的是,注意事件发生的顺序,而不是交付处理的顺序,并能够推断一组事件何时(或应该)完成。
通过使用记录在数据流中的事件时间戳,而不是使用处理数据的机器的时钟,可以满足及时流处理的这些要求。
有状态流处理
Flink的操作是可以有状态的。这意味着如何处理一件事可能取决于之前所有事件的累积。
Flink 应用程序在分布式集群上并行运行。
有状态算子的并行实例集实际上是一个分片键值存储。每个并行实例负责处理一组特定键的事件,这些键的状态保存在本地。
下图显示了作业图中前三个算子以 2 的并行度运行的作业,最终由并行度为1的接收器结束。第三个算子是有状态的,第二个和第三个算子之间正在发生随机的网络连接。
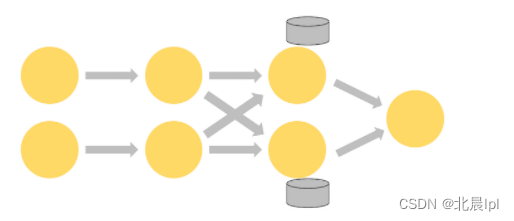
状态始终在本地访问,这有助于 Flink 应用程序实现高吞吐量和低延迟。 你可以选择将状态保留在 JVM 堆上,如果状态开销太大,可以选择将其存储于高效率的磁盘中。
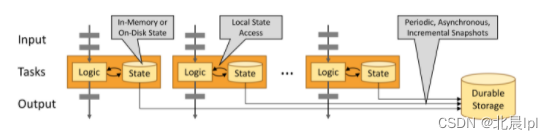
通过状态快照实现容错
Flink能够通过状态快照和流回溯的组合提供容错。这些快照将捕获分布式管道以及整个作业图的状态,将其记录在队列中,当发生故障时,进行回溯,恢复至最近的状态。快照的捕获是异步进行的,并不会影响正在处理的任务。